Integração de dados usando o Azure Data Factory e o Azure Data Share
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
À medida que os clientes embarcam em seus projetos modernos de data warehouse e análise, eles precisam não apenas de mais dados, mas também de mais visibilidade em seus dados em todo o seu patrimônio de dados. Este workshop analisa como as melhorias no Azure Data Factory e no Azure Data Share simplificam a integração e o gerenciamento de dados no Azure.
Desde habilitar ETL/ELT sem código até criar uma visão abrangente sobre seus dados, as melhorias no Azure Data Factory capacitam seus engenheiros de dados a trazer com confiança mais dados e, portanto, mais valor para sua empresa. O Compartilhamento de Dados do Azure permite que você faça o compartilhamento de negócios para empresas de maneira controlada.
Neste workshop, você usa o Azure Data Factory (ADF) para ingerir dados do Banco de Dados SQL do Azure no Azure Data Lake Storage Gen2 (ADLS Gen2). Depois de colocar os dados no lago, você os transforma por meio de fluxos de dados de mapeamento, o serviço de transformação nativo do data factory e os afunda no Azure Synapse Analytics. Em seguida, você compartilha a tabela com dados transformados junto com alguns dados extras usando o Compartilhamento de Dados do Azure.
Os dados usados neste laboratório são dados de táxi da cidade de Nova York. Para importá-lo para seu banco de dados no Banco de dados SQL, baixe o arquivo bacpac taxi-data. Selecione a opção Baixar arquivo raw no GitHub.
Pré-requisitos
Subscrição do Azure: se não tem uma subscrição do Azure, crie uma conta gratuita antes de começar.
Banco de Dados SQL do Azure: se você não tiver um Banco de Dados SQL do Azure, saiba como criar um Banco de Dados SQL.
Conta de armazenamento do Azure Data Lake Storage Gen2: se você não tiver uma conta de armazenamento do ADLS Gen2, saiba como criar uma conta de armazenamento do ADLS Gen2.
Azure Synapse Analytics: Se você não tiver um espaço de trabalho do Azure Synapse Analytics, saiba como começar a usar o Azure Synapse Analytics.
Azure Data Factory: Se você não tiver um data factory, veja como criar um data factory.
Partilha de Dados do Azure: se não tiver uma partilha de dados, veja como criar uma partilha de dados.
Configurar o ambiente do Azure Data Factory
Nesta seção, você aprenderá a acessar a experiência do usuário do Azure Data Factory (ADF UX) a partir do portal do Azure. Uma vez na UX do ADF, você configura três serviços vinculados para cada um dos armazenamentos de dados que estamos usando: Banco de Dados SQL do Azure, ADLS Gen2 e Azure Synapse Analytics.
Nos serviços vinculados do Azure Data Factory, defina as informações de conexão com recursos externos. Atualmente, o Azure Data Factory suporta mais de 85 conectores.
Abra a experiência do usuário do Azure Data Factory
Abra o portal do Azure no Microsoft Edge ou no Google Chrome.
Usando a barra de pesquisa na parte superior da página, procure por "Data Factories".
Selecione seu recurso de fábrica de dados para abrir seus recursos no painel esquerdo.
Selecione Abrir o Azure Data Factory Studio. O Data Factory Studio também pode ser acessado diretamente no adf.azure.com.

Você será redirecionado para a página inicial do ADF no portal do Azure. Esta página contém inícios rápidos, vídeos instrutivos e links para tutoriais para aprender conceitos de data factory. Para iniciar a criação, selecione o ícone de lápis na barra lateral esquerda.


Criar um serviço ligado da Base de Dados SQL do Azure
Para criar um serviço vinculado, selecione Gerenciar hub na barra lateral esquerda, no painel Conexões, selecione Serviços vinculados e selecione Novo para adicionar um novo serviço vinculado.
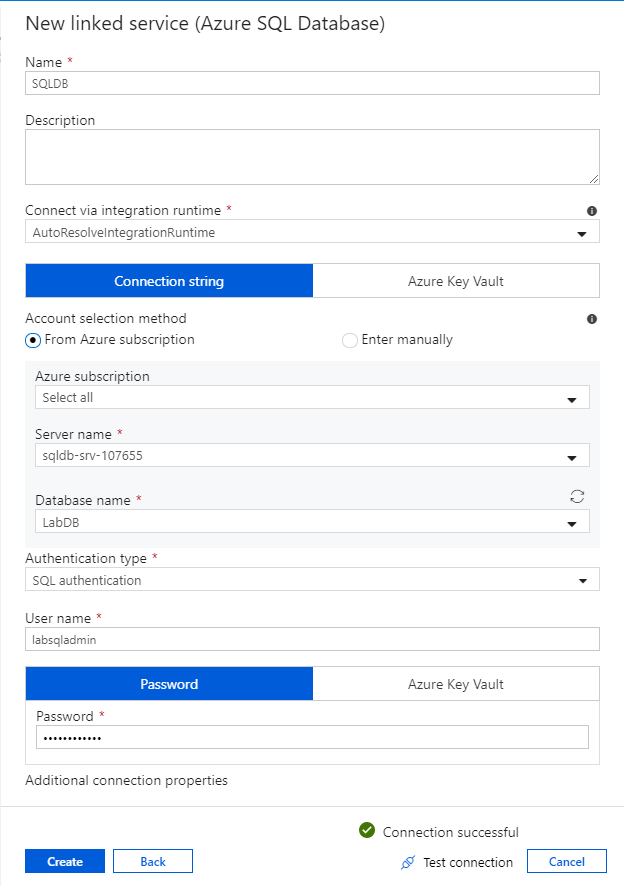
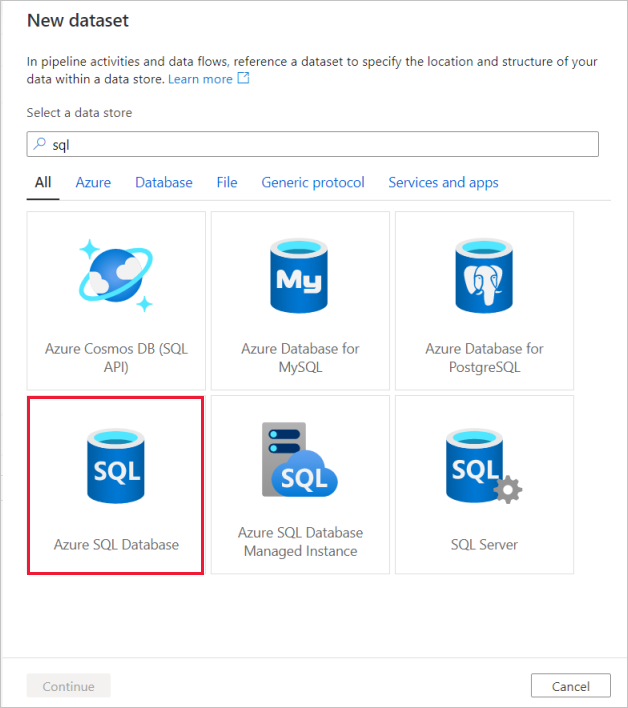
O primeiro serviço vinculado que você configura é um Banco de Dados SQL do Azure. Você pode usar a barra de pesquisa para filtrar a lista de armazenamento de dados. Selecione no bloco Banco de Dados SQL do Azure e selecione continuar.

No painel de configuração do Banco de dados SQL, digite 'SQLDB' como o nome do serviço vinculado. Insira suas credenciais para permitir que o data factory se conecte ao seu banco de dados. Se você estiver usando a autenticação SQL, insira o nome do servidor, o banco de dados, seu nome de usuário e senha. Você pode verificar se as informações de conexão estão corretas selecionando Testar conexão. Quando terminar, selecione Criar.

Criar um serviço vinculado do Azure Synapse Analytics
Repita o mesmo processo para adicionar um serviço vinculado do Azure Synapse Analytics. Na guia conexões, selecione Novo. Selecione o bloco Azure Synapse Analytics e selecione continuar.
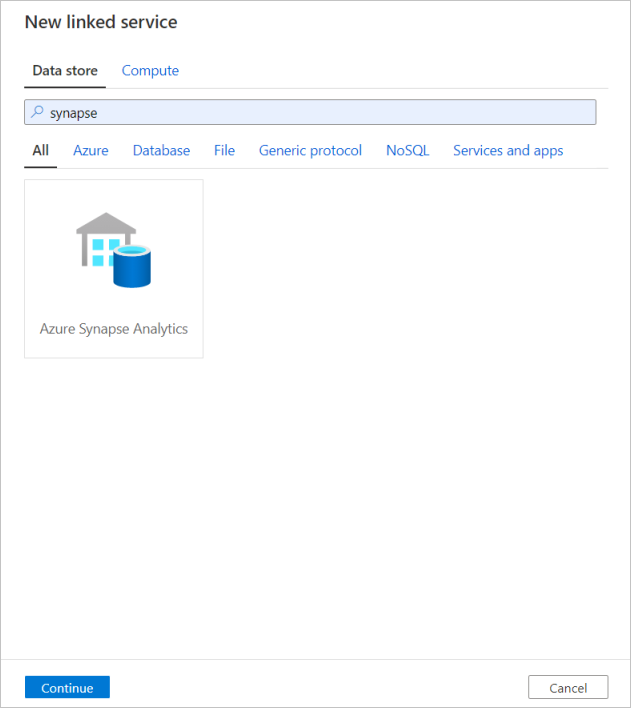
No painel de configuração do serviço vinculado, digite 'SQLDW'' como o nome do serviço vinculado. Insira suas credenciais para permitir que o data factory se conecte ao seu banco de dados. Se você estiver usando a autenticação SQL, insira o nome do servidor, o banco de dados, seu nome de usuário e senha. Você pode verificar se as informações de conexão estão corretas selecionando Testar conexão. Quando terminar, selecione Criar.
Criar um serviço vinculado do Azure Data Lake Storage Gen2
O último serviço vinculado necessário para este laboratório é um Azure Data Lake Storage Gen2. Na guia conexões, selecione Novo. Selecione o bloco Azure Data Lake Storage Gen2 e selecione continuar.
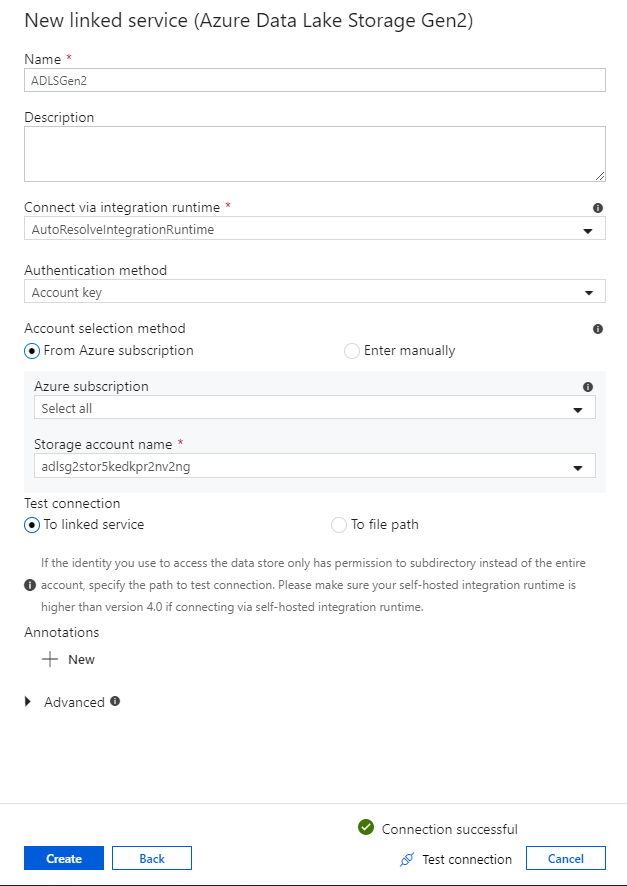
No painel de configuração do serviço vinculado, digite 'ADLSGen2' como o nome do serviço vinculado. Se você estiver usando a autenticação de chave de conta, selecione sua conta de armazenamento ADLS Gen2 na lista suspensa Nome da conta de armazenamento. Você pode verificar se as informações de conexão estão corretas selecionando Testar conexão. Quando terminar, selecione Criar.
Ativar o modo de depuração de fluxo de dados
Na seção Transformar dados usando o fluxo de dados de mapeamento, você está criando fluxos de dados de mapeamento. Uma prática recomendada antes de criar fluxos de dados de mapeamento é ativar o modo de depuração, que permite testar a lógica de transformação em segundos em um cluster de faísca ativo.
Para ativar a depuração, selecione o controle deslizante Depuração de fluxo de dados na barra superior da tela de fluxo de dados ou tela de pipeline quando tiver atividades de fluxo de dados. Selecione OK quando a caixa de diálogo de confirmação for mostrada. O cluster arranca em cerca de 5 a 7 minutos. Continue para Ingerir dados do Banco de Dados SQL do Azure no ADLS Gen2 usando a atividade de cópia durante a inicialização.

Ingerir dados usando a atividade de cópia
Nesta seção, você cria um pipeline com uma atividade de cópia que ingere uma tabela de um Banco de Dados SQL do Azure em uma conta de armazenamento ADLS Gen2. Você aprende como adicionar um pipeline, configurar um conjunto de dados e depurar um pipeline por meio da UX do ADF. O padrão de configuração usado nesta seção pode ser aplicado à cópia de um armazenamento de dados relacional para um armazenamento de dados baseado em arquivo.
No Azure Data Factory, um pipeline é um agrupamento lógico de atividades que, juntas, executam uma tarefa. Uma atividade define uma operação a ser executada em seus dados. Um conjunto de dados aponta para os dados que você deseja usar em um serviço vinculado.
Criar um pipeline com uma atividade de cópia
No painel de recursos de fábrica, selecione no ícone de adição para abrir o novo menu de recursos. Selecione Pipeline.
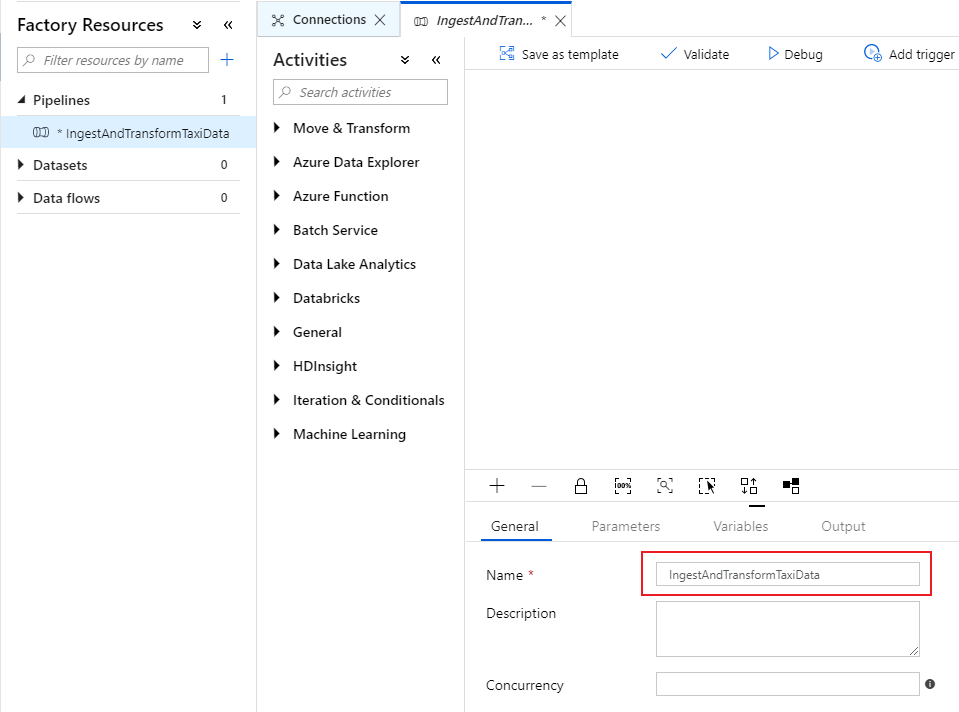
Na guia Geral da tela do pipeline, nomeie seu pipeline como algo descritivo, como 'IngestAndTransformTaxiData'.
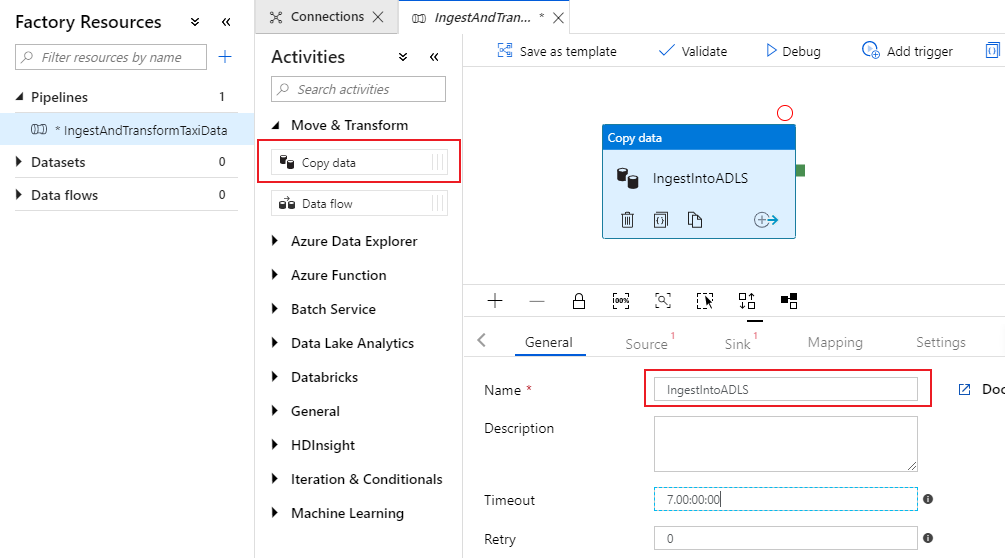
No painel de atividades da tela do pipeline, abra o acordeão Mover e Transformar e arraste a atividade Copiar dados para a tela. Dê à atividade de cópia um nome descritivo, como 'IngestIntoADLS'.


Configurar o conjunto de dados de origem do Banco de Dados SQL do Azure
Selecione na guia Origem da atividade de cópia. Para criar um novo conjunto de dados, selecione Novo. Sua fonte será a tabela
dbo.TripDatalocalizada no serviço vinculado 'SQLDB' configurado anteriormente.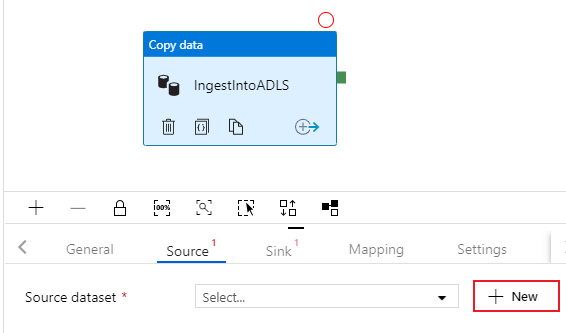
Procure o Banco de Dados SQL do Azure e selecione continuar.
Chame seu conjunto de dados de 'TripData'. Selecione 'SQLDB' como seu serviço vinculado. Selecione o nome
dbo.TripDatada tabela na lista suspensa Nome da tabela. Importe o esquema Da conexão/armazenamento. Selecione OK quando terminar.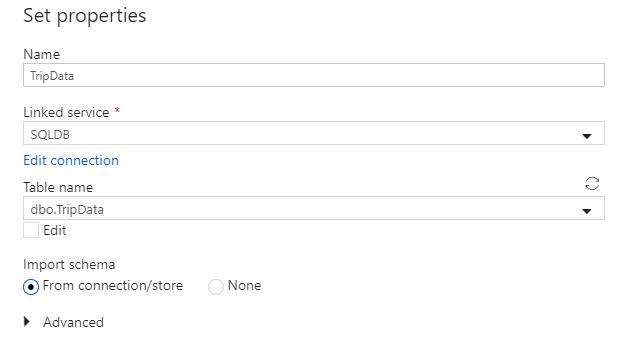
Você criou com êxito seu conjunto de dados de origem. Verifique se nas configurações de origem, o valor padrão Tabela está selecionado no campo de consulta de uso.
Configurar o conjunto de dados do coletor ADLS Gen2
Selecione na guia Coletor da atividade de cópia. Para criar um novo conjunto de dados, selecione Novo.
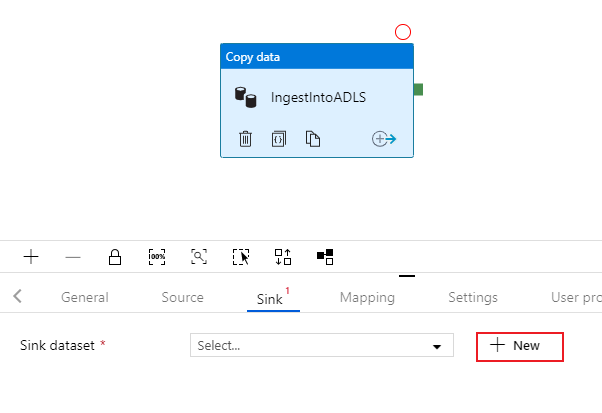
Procure o Azure Data Lake Storage Gen2 e selecione continuar.
No painel de seleção de formato, selecione DelimitedText enquanto grava em um arquivo csv. Selecione continuar.

Nomeie seu conjunto de dados de coletor como 'TripDataCSV'. Selecione 'ADLSGen2' como seu serviço vinculado. Digite onde você deseja escrever seu arquivo csv. Por exemplo, você pode gravar seus dados no arquivo
trip-data.csvno contêinerstaging-container. Defina Primeira linha como cabeçalho como true como você deseja que seus dados de saída tenham cabeçalhos. Como ainda não existe nenhum arquivo no destino, defina Importar esquema como Nenhum. Selecione OK quando terminar.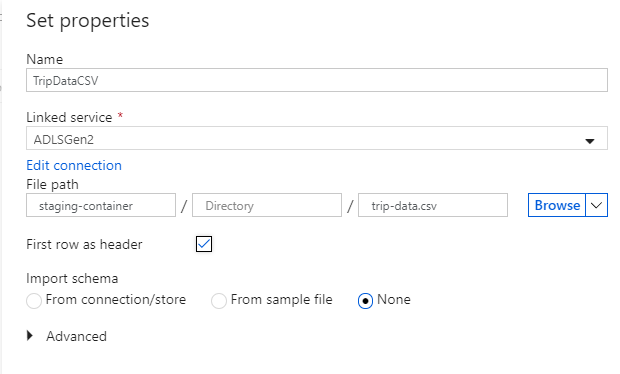
Testar a atividade de cópia com uma execução de depuração de pipeline
Para verificar se a atividade de cópia está funcionando corretamente, selecione Depurar na parte superior da tela do pipeline para executar uma execução de depuração. Uma execução de depuração permite que você teste seu pipeline de ponta a ponta ou até um ponto de interrupção antes de publicá-lo no serviço de data factory.
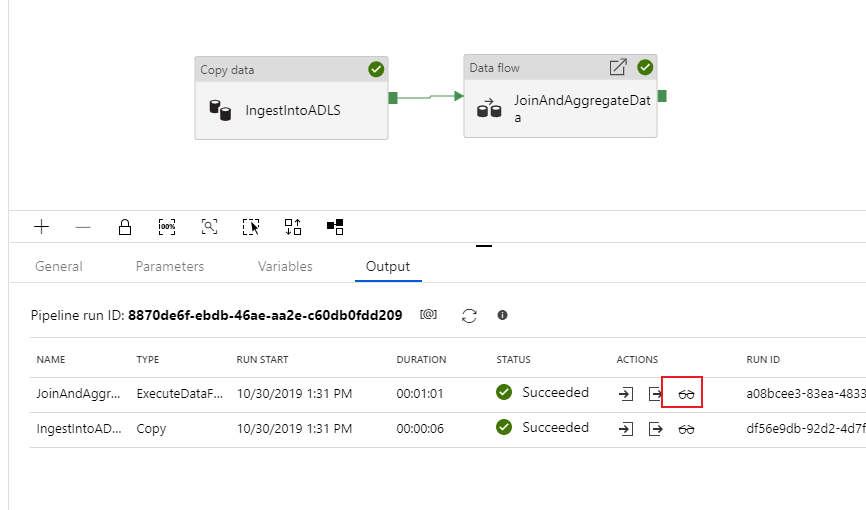
Para monitorar sua execução de depuração, vá para a guia Saída da tela do pipeline. A tela de monitoramento é atualizada automaticamente a cada 20 segundos ou quando você seleciona manualmente o botão de atualização. A atividade de cópia tem uma visão de monitoramento especial, que pode ser acessada selecionando o ícone de óculos na coluna Ações .
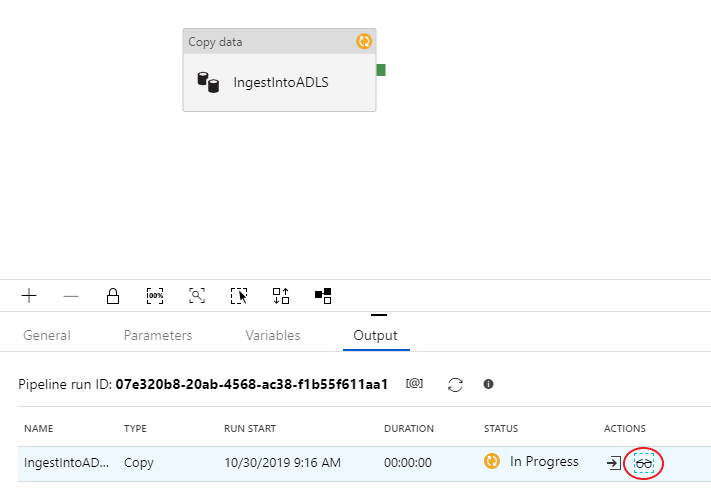
A visualização de monitoramento de cópia fornece os detalhes de execução da atividade e as características de desempenho. Você pode ver informações como dados lidos/gravados, linhas lidas/gravadas, arquivos lidos/gravados e taxa de transferência. Se você configurou tudo corretamente, verá 49.999 linhas gravadas em um arquivo no coletor ADLS.
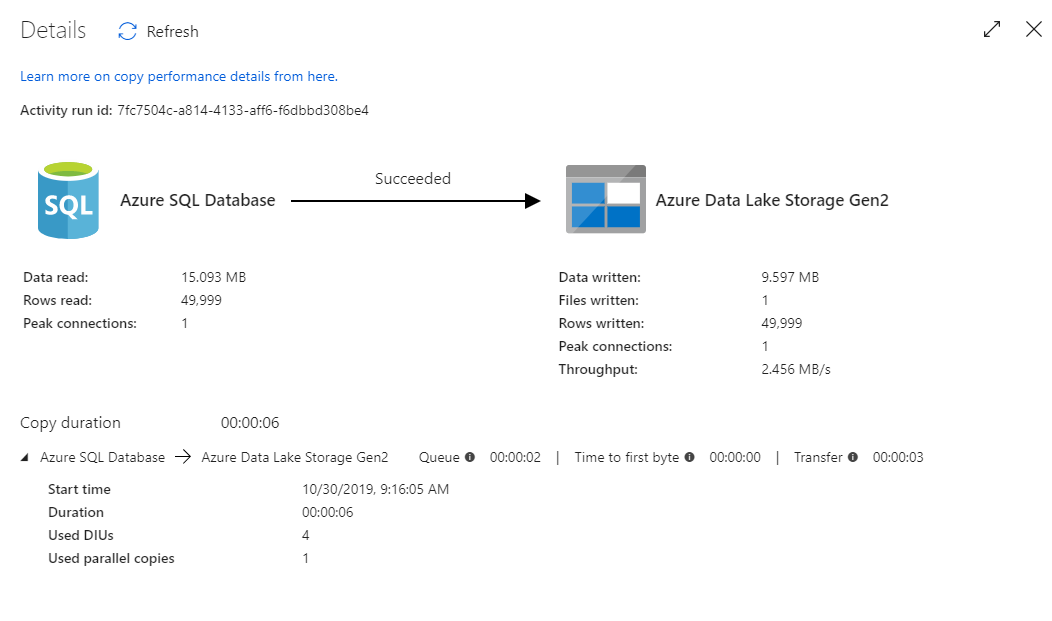
Antes de passar para a próxima seção, é sugerido que você publique suas alterações no serviço de fábrica de dados selecionando Publicar tudo na barra superior de fábrica. Embora não seja abordado neste laboratório, o Azure Data Factory oferece suporte à integração total do git. A integração com o Git permite o controle de versão, o salvamento iterativo em um repositório e a colaboração em uma fábrica de dados. Para obter mais informações, consulte Controle do código-fonte no Azure Data Factory.


Transformar dados com o fluxo de dados de mapeamento
Agora que você copiou com êxito os dados para o Armazenamento do Azure Data Lake, é hora de unir e agregar esses dados em um data warehouse. Usamos o fluxo de dados de mapeamento, o serviço de transformação projetado visualmente do Azure Data Factory. O mapeamento de fluxos de dados permite que os usuários desenvolvam lógica de transformação sem código e os executem em clusters de faísca gerenciados pelo serviço ADF.
O fluxo de dados criado nesta etapa interna une o conjunto de dados 'TripDataCSV' criado na seção anterior com uma tabela dbo.TripFares armazenada em 'SQLDB' com base em quatro colunas principais. Em seguida, os dados são agregados com base na coluna payment_type para calcular a média de determinados campos e escritos em uma tabela do Azure Synapse Analytics.
Adicionar uma atividade de fluxo de dados ao seu pipeline
No painel de atividades da tela do pipeline, abra o acordeão Mover e Transformar e arraste a atividade Fluxo de dados para a tela.
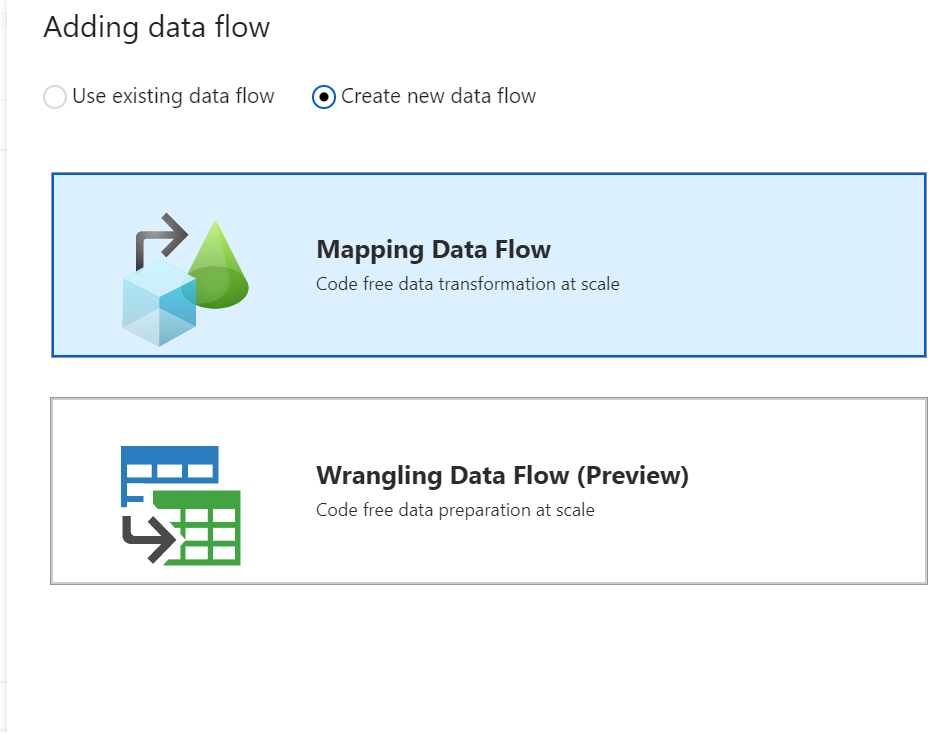
No painel lateral que se abre, selecione Criar novo fluxo de dados e escolha Mapeando fluxo de dados. Selecione OK.
Você é direcionado para a tela de fluxo de dados onde está construindo sua lógica de transformação. Na guia geral, nomeie seu fluxo de dados como 'JoinAndAggregateData'.


Configurar a origem CSV dos dados da viagem
A primeira coisa que você deseja fazer é configurar suas duas transformações de origem. A primeira fonte aponta para o conjunto de dados DelimitedText 'TripDataCSV'. Para adicionar uma transformação de origem, selecione na caixa Adicionar fonte na tela.
Nomeie sua fonte como 'TripDataCSV' e selecione o conjunto de dados 'TripDataCSV' na lista suspensa de fontes. Se você se lembrar, não importou um esquema inicialmente ao criar esse conjunto de dados, pois não havia dados lá. Uma vez que
trip-data.csvexiste agora, selecione Editar para ir para a guia de configurações do conjunto de dados.
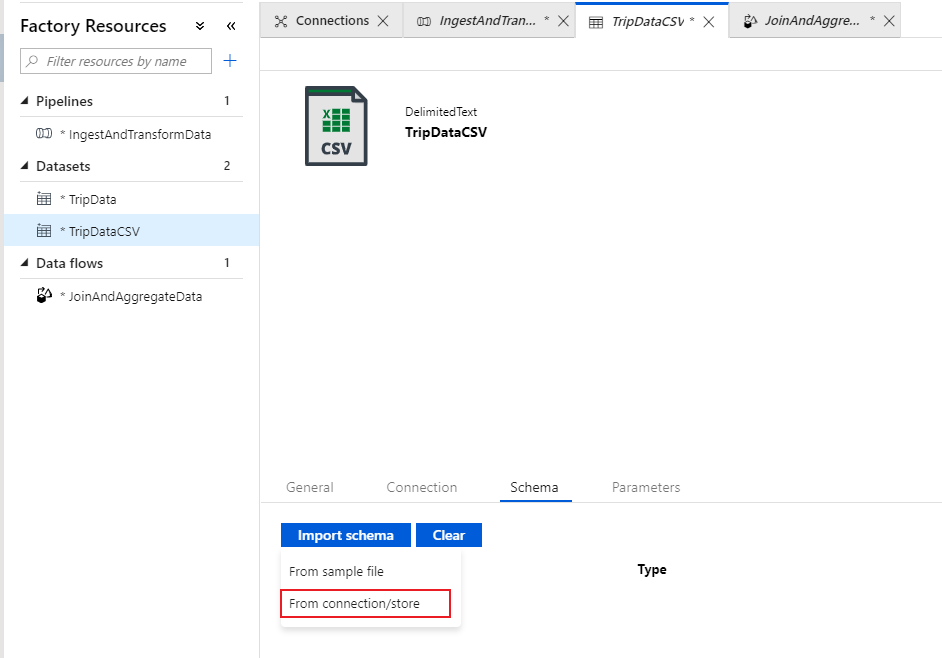
Vá para a guia Esquema e selecione Importar esquema. Selecione Da conexão/armazenamento para importar diretamente do armazenamento de arquivos. 14 colunas do tipo string devem aparecer.
Volte para o fluxo de dados 'JoinAndAggregateData'. Se o cluster de depuração tiver sido iniciado (indicado por um círculo verde ao lado do controle deslizante de depuração), você poderá obter um instantâneo dos dados na guia Visualização de dados . Selecione Atualizar para obter uma visualização de dados.


Nota
A visualização de dados não grava dados.
Configurar as tarifas da sua viagem Origem da Base de Dados SQL
A segunda fonte que você está adicionando aponta na tabela
dbo.TripFaresdo Banco de dados SQL. Na fonte "TripDataCSV", há outra caixa Adicionar fonte . Selecione-o para adicionar uma nova transformação de origem.
Nomeie esta fonte como 'TripFaresSQL'. Selecione Novo ao lado do campo do conjunto de dados de origem para criar um novo conjunto de dados do Banco de dados SQL.
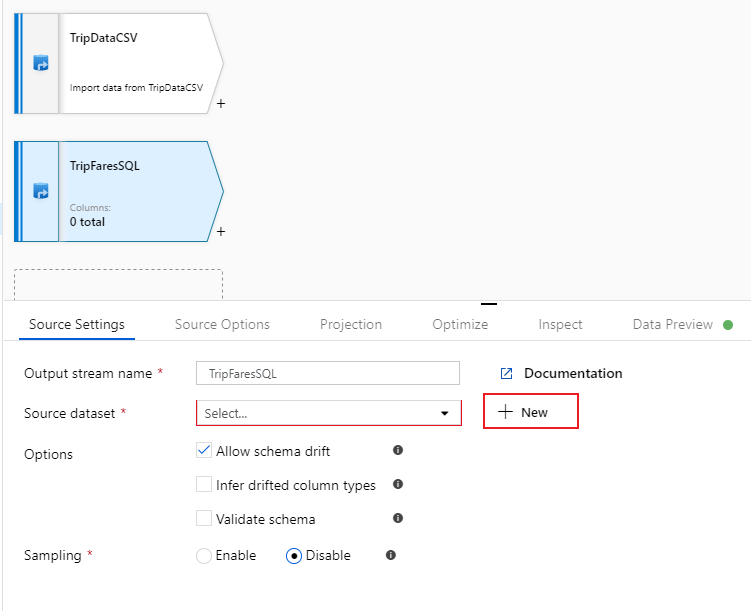
Selecione o bloco Banco de Dados SQL do Azure e selecione continuar. Você pode notar que muitos dos conectores no data factory não são suportados no mapeamento do fluxo de dados. Para transformar dados de uma dessas fontes, ingeri-los em uma fonte suportada usando a atividade de cópia.

Chame seu conjunto de dados de 'TripFares'. Selecione 'SQLDB' como seu serviço vinculado. Selecione o nome
dbo.TripFaresda tabela na lista suspensa Nome da tabela. Importe o esquema Da conexão/armazenamento. Selecione OK quando terminar.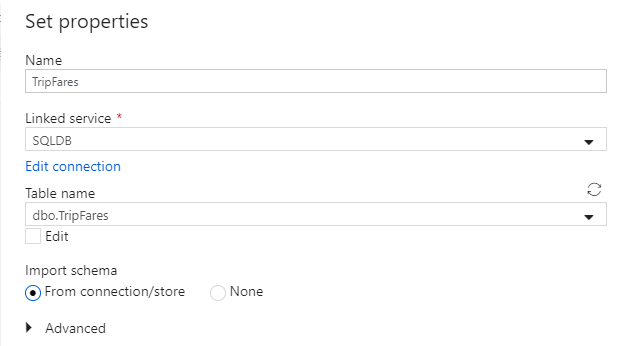
Para verificar seus dados, busque uma visualização de dados na guia Visualização de dados .
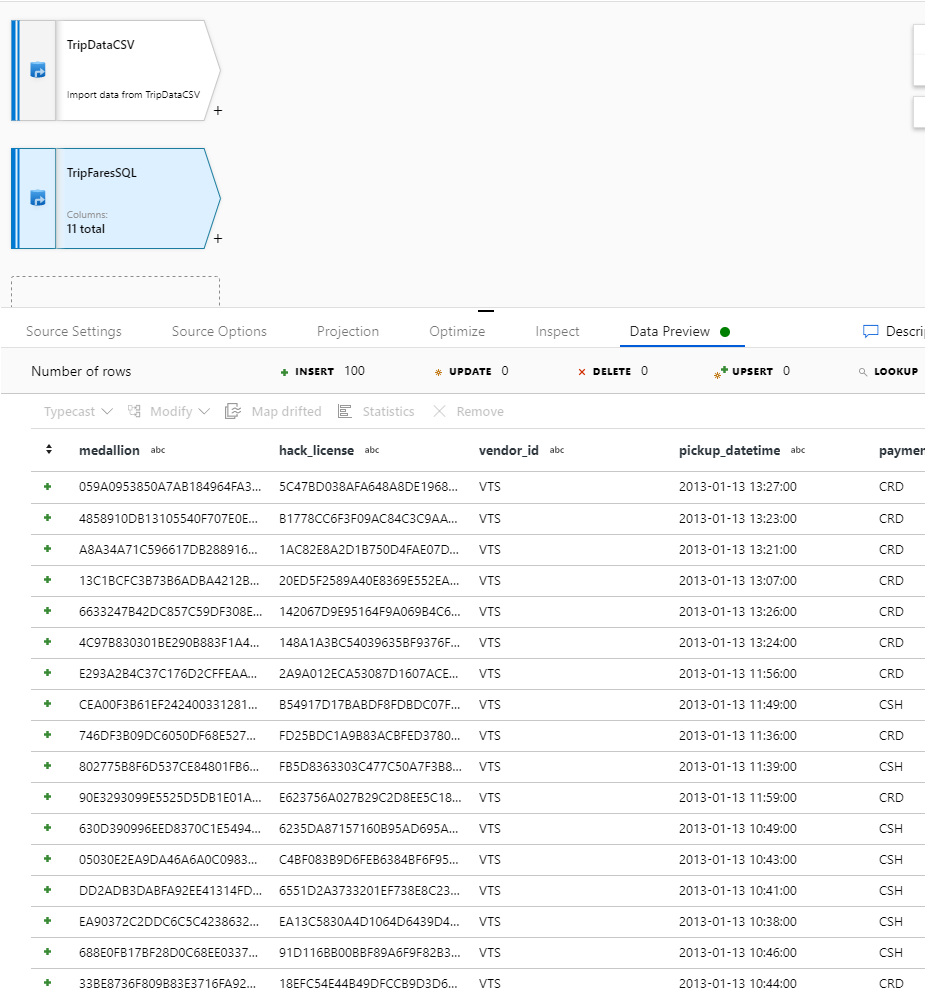

Junte-se ao TripDataCSV e ao TripFaresSQL
Para adicionar uma nova transformação, selecione o ícone de adição no canto inferior direito de 'TripDataCSV'. Em Várias entradas/saídas, selecione Ingressar.
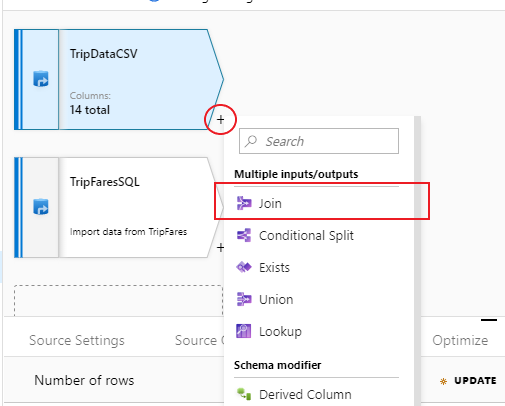
Nomeie sua transformação de ingresso como 'InnerJoinWithTripFares'. Selecione 'TripFaresSQL' na lista suspensa à direita. Selecione Interno como o tipo de junção. Para saber mais sobre os diferentes tipos de junção no mapeamento do fluxo de dados, consulte Tipos de junção.
Selecione as colunas que deseja corresponder em cada fluxo através da lista suspensa Condições de adesão . Para adicionar uma condição de associação adicional, selecione no ícone de adição ao lado de uma condição existente. Por padrão, todas as condições de junção são combinadas com um operador AND, o que significa que todas as condições devem ser atendidas para uma correspondência. Neste laboratório, queremos corresponder nas colunas
medallion,hack_license,vendor_id, epickup_datetime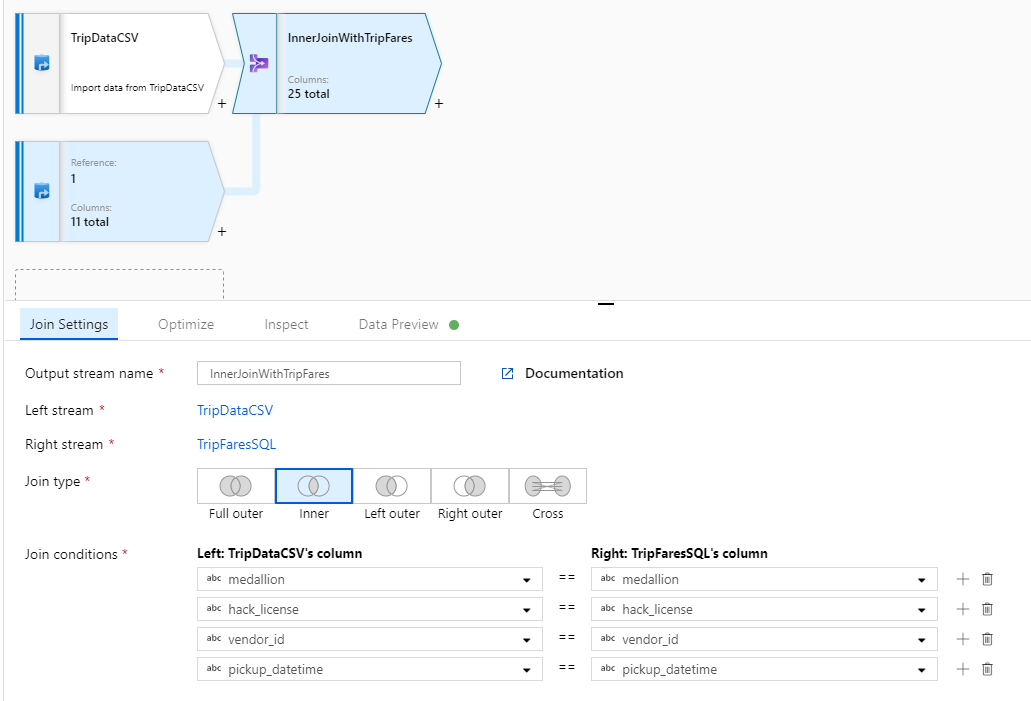
Verifique se você juntou com êxito 25 colunas junto com uma visualização de dados.


Agregado por payment_type
Depois de concluir a transformação de junção, adicione uma transformação agregada selecionando o ícone de adição ao lado de InnerJoinWithTripFares. Escolha Agregar em Modificador de esquema.
Nomeie sua transformação agregada como 'AggregateByPaymentType'. Selecione
payment_typecomo o grupo por coluna.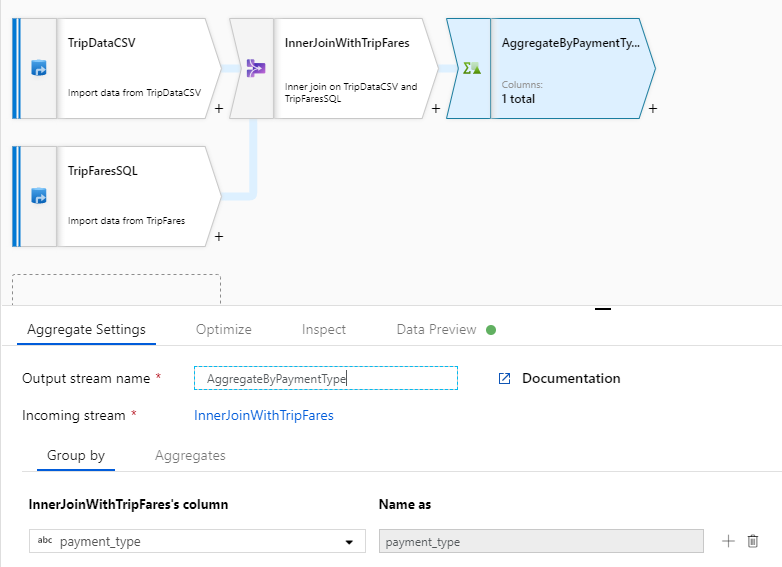
Vá para a guia Agregações . Especifique duas agregações:
- A tarifa média agrupada por tipo de pagamento
- A distância total da viagem agrupada por tipo de pagamento
Primeiro, você cria a expressão de tarifa média. Na caixa de texto Adicionar ou selecionar uma coluna, digite 'average_fare'.
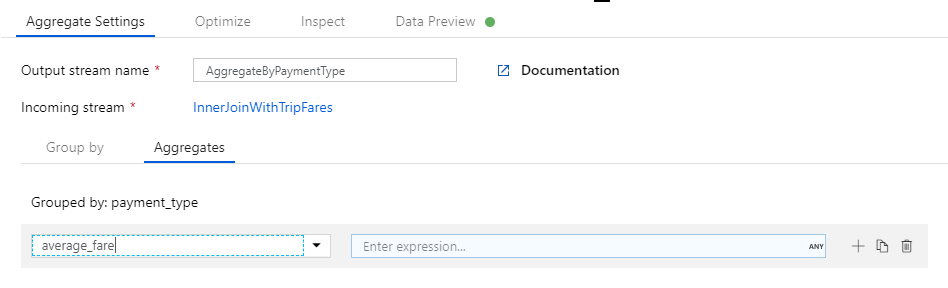
Para inserir uma expressão de agregação, selecione a caixa azul chamada Enter expression, que abre o construtor de expressões de fluxo de dados, uma ferramenta usada para criar visualmente expressões de fluxo de dados usando esquema de entrada, funções e operações internas e parâmetros definidos pelo usuário. Para obter mais informações sobre os recursos do construtor de expressões, consulte a documentação do construtor de expressões.
Para obter a tarifa média, use a
avg()função de agregação para agregar atotal_amountcoluna convertida em um inteiro comtoInteger(). Na linguagem de expressão de fluxo de dados, isso é definido comoavg(toInteger(total_amount)). Selecione Salvar e concluir quando terminar.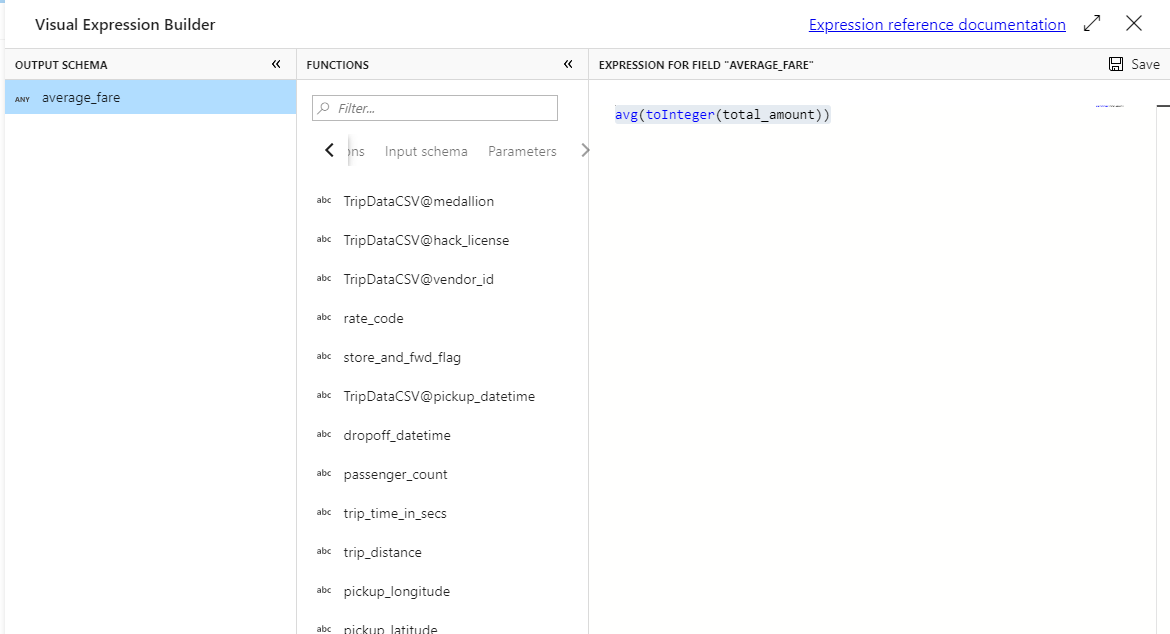
Para adicionar uma expressão de agregação extra, selecione no ícone de adição ao lado de
average_fare. Selecione Adicionar coluna.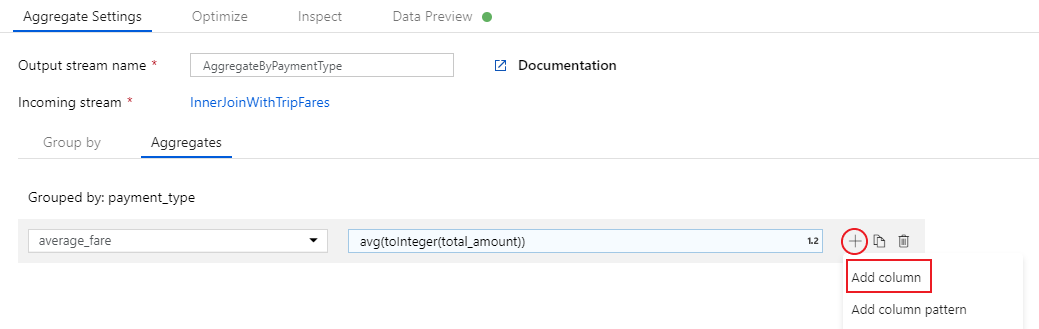
Na caixa de texto Adicionar ou selecionar uma coluna, digite 'total_trip_distance'. Como na última etapa, abra o construtor de expressões para entrar na expressão.
Para obter a distância total da viagem, use a
sum()função de agregação para agregar a coluna convertidatrip_distanceem um inteiro comtoInteger(). Na linguagem de expressão de fluxo de dados, isso é definido comosum(toInteger(trip_distance)). Selecione Salvar e concluir quando terminar.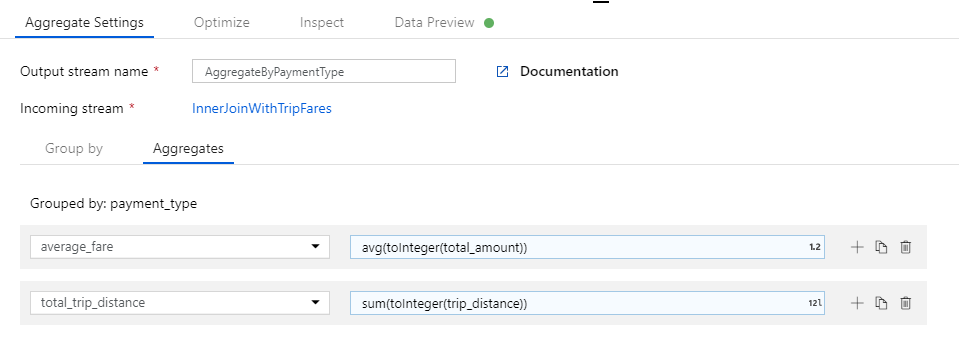
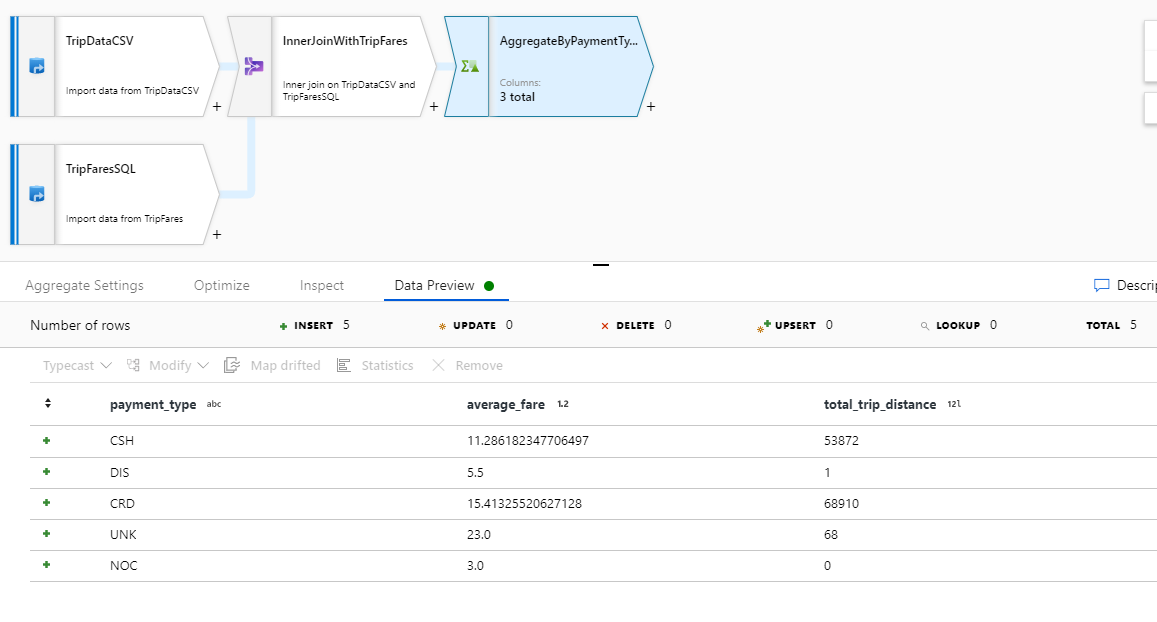
Teste sua lógica de transformação na guia Visualização de dados . Como você pode ver, há menos linhas e colunas do que anteriormente. Apenas os três grupos por e colunas de agregação definidos nesta transformação continuam a jusante. Como há apenas cinco grupos de tipos de pagamento na amostra, apenas cinco linhas são produzidas.





Configurar o coletor do Azure Synapse Analytics
Agora que terminamos nossa lógica de transformação, estamos prontos para reunir nossos dados em uma tabela do Azure Synapse Analytics. Adicione uma transformação de coletor na seção Destino .
Nomeie sua pia como 'SQLDWSink'. Selecione Novo ao lado do campo do conjunto de dados do coletor para criar um novo conjunto de dados do Azure Synapse Analytics.
Selecione o bloco Azure Synapse Analytics e selecione continuar.
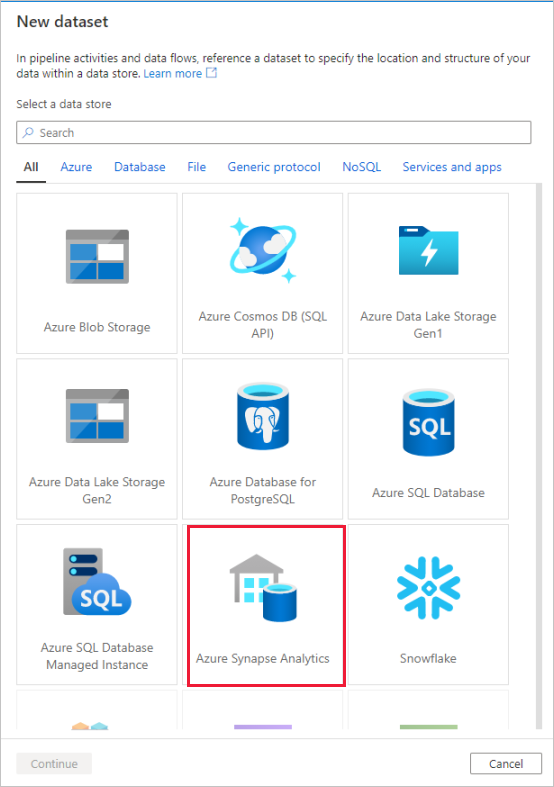
Chame seu conjunto de dados de 'AggregatedTaxiData'. Selecione 'SQLDW' como seu serviço vinculado. Selecione Criar nova tabela e nomeie a nova tabela
dbo.AggregateTaxiData. Selecione OK quando terminar.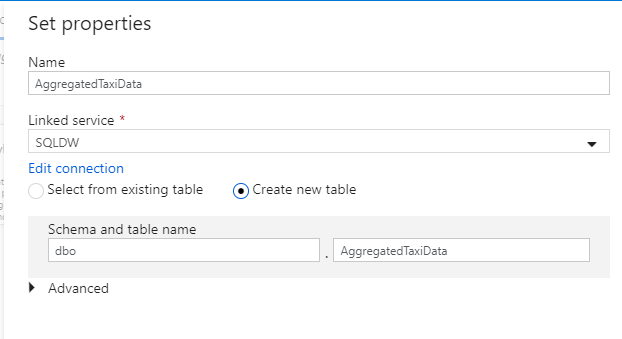
Vá para a guia Configurações do coletor. Como estamos criando uma nova tabela, precisamos selecionar Recriar tabela em ação de tabela. Desmarque Ativar preparo, que alterna se estamos inserindo linha por linha ou em lote.
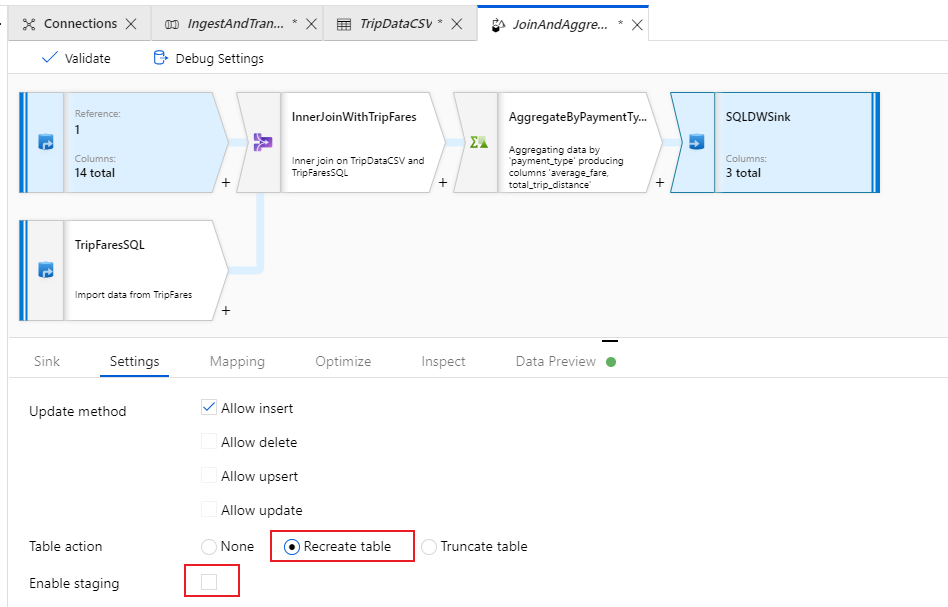


Você criou com sucesso seu fluxo de dados. Agora é hora de executá-lo em uma atividade de pipeline.
Depurar seu pipeline de ponta a ponta
Volte para a guia do pipeline IngestAndTransformData . Observe a caixa verde na atividade de cópia 'IngestIntoADLS'. Arraste-o para a atividade de fluxo de dados 'JoinAndAggregateData'. Isso cria um 'on success', que faz com que a atividade de fluxo de dados só seja executada se a cópia for bem-sucedida.
Como fizemos para a atividade de cópia, selecione Depurar para executar uma execução de depuração. Para execuções de depuração, a atividade de fluxo de dados usa o cluster de depuração ativo em vez de girar um novo cluster. Esse pipeline leva pouco mais de um minuto para ser executado.
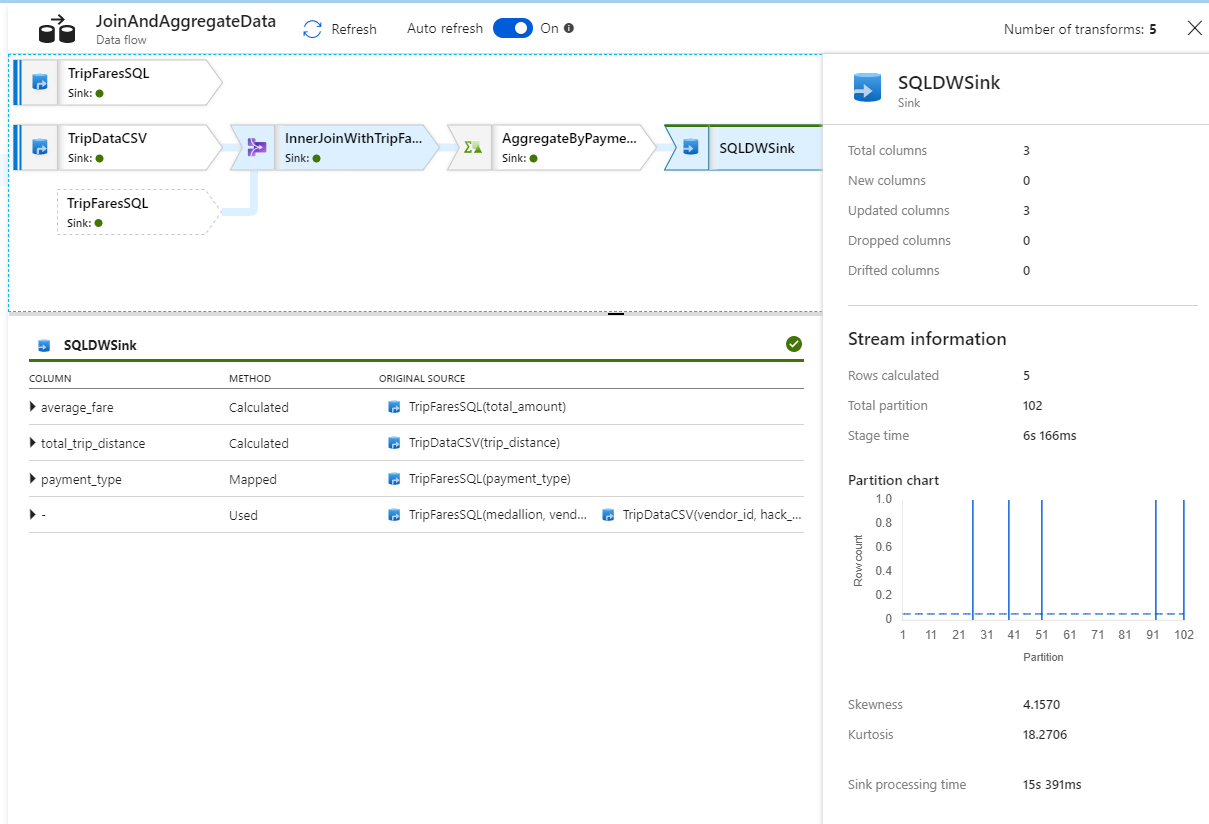
Como a atividade de cópia, o fluxo de dados tem uma visão de monitoramento especial acessada pelo ícone de óculos na conclusão da atividade.
Na visualização de monitoramento, você pode ver um gráfico de fluxo de dados simplificado, juntamente com os tempos de execução e linhas em cada estágio de execução. Se feito corretamente, você deve ter agregado 49.999 linhas em cinco linhas nesta atividade.
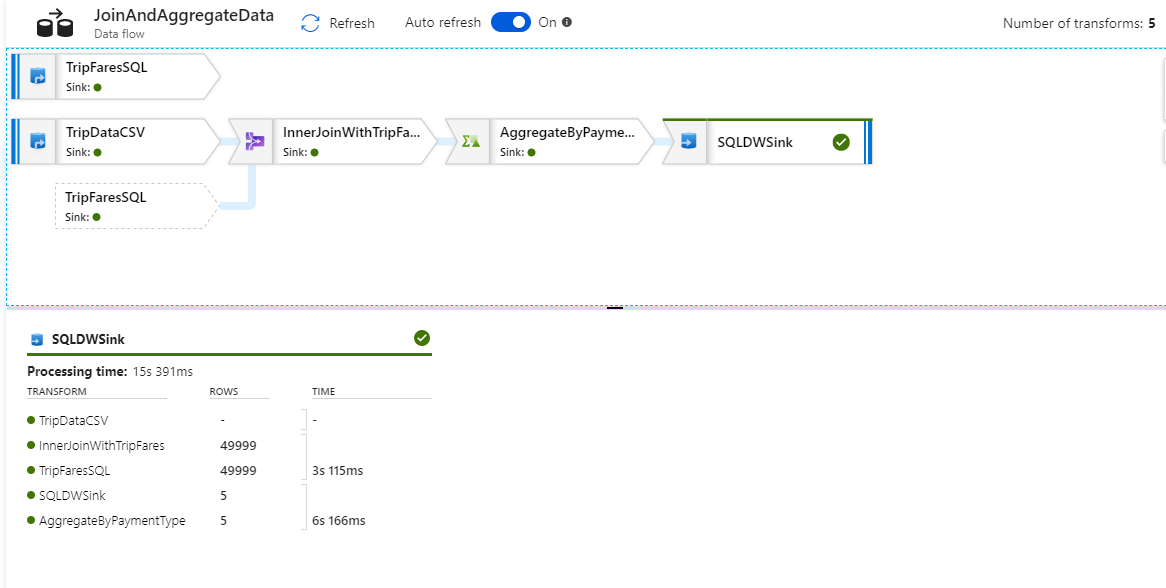
Você pode selecionar uma transformação para obter detalhes adicionais sobre sua execução, como informações de particionamento e colunas novas/atualizadas/descartadas.




Agora você concluiu a parte de fábrica de dados deste laboratório. Publique seus recursos se desejar operacionalizá-los com gatilhos. Você executou com êxito um pipeline que ingeriu dados do Banco de Dados SQL do Azure para o Armazenamento do Azure Data Lake usando a atividade de cópia e, em seguida, agregou esses dados em um Azure Synapse Analytics. Você pode verificar se os dados foram gravados com êxito examinando o próprio SQL Server.
Partilhar dados com o Azure Data Share
Nesta seção, você aprenderá a configurar um novo compartilhamento de dados usando o portal do Azure. Isso envolve a criação de um novo compartilhamento de dados que contém conjuntos de dados do Azure Data Lake Storage Gen2 e do Azure Synapse Analytics. Em seguida, você configurará um agendamento de instantâneo, que dará aos consumidores de dados uma opção para atualizar automaticamente os dados que estão sendo compartilhados com eles. Em seguida, você convidará destinatários para seu compartilhamento de dados.
Depois de criar um compartilhamento de dados, você trocará de chapéu e se tornará o consumidor de dados. Como consumidor de dados, você percorrerá o fluxo de aceitação de um convite de compartilhamento de dados, configurando onde deseja que os dados sejam recebidos e mapeando conjuntos de dados para diferentes locais de armazenamento. Em seguida, você acionará um instantâneo, que copiará os dados compartilhados com você para o destino especificado.
Compartilhar dados (fluxo do provedor de dados)
Abra o portal do Azure no Microsoft Edge ou no Google Chrome.
Usando a barra de pesquisa na parte superior da página, pesquise por Compartilhamentos de Dados
Selecione a conta de compartilhamento de dados com 'Provedor' no nome. Por exemplo, DataProvider0102.
Selecione Começar a partilhar os seus dados
Selecione +Criar para começar a configurar seu novo compartilhamento de dados.
Em Nome do compartilhamento, especifique um nome de sua escolha. Este é o nome da partilha que será visto pelo seu consumidor de dados, por isso certifique-se de que lhe dá um nome descritivo, como TaxiData.
Em Descrição, coloque uma frase, que descreve o conteúdo do compartilhamento de dados. O compartilhamento de dados contém dados de viagem de táxi em todo o mundo que são armazenados em uma variedade de lojas, incluindo o Azure Synapse Analytics e o Azure Data Lake Storage.
Em Termos de utilização, especifique um conjunto de termos aos quais pretende que o consumidor de dados respeite. Alguns exemplos incluem "Não distribuir estes dados fora da sua organização" ou "Consulte o contrato legal".

Selecione Continuar.
Selecione Adicionar conjuntos de dados

Selecione Azure Synapse Analytics para selecionar uma tabela do Azure Synapse Analytics na qual suas transformações do ADF chegaram.
Você recebe um script para ser executado antes de poder continuar. O script fornecido cria um usuário no banco de dados SQL para permitir que o MSI do Compartilhamento de Dados do Azure se autentique em seu nome.
Importante
Antes de executar o script, você deve se definir como o administrador do Ative Directory para o servidor SQL lógico do Banco de Dados SQL do Azure.
Abra uma nova guia e navegue até o portal do Azure. Copie o script fornecido para criar um usuário no banco de dados do qual você deseja compartilhar dados. Faça isso entrando no banco de dados EDW usando o editor de Consultas do portal do Azure, usando a autenticação do Microsoft Entra. Você precisa modificar o usuário no seguinte script de exemplo:
CREATE USER [dataprovider-xxxx@contoso.com] FROM EXTERNAL PROVIDER; ALTER ROLE db_owner ADD MEMBER [wiassaf@microsoft.com];Volte para o Compartilhamento de Dados do Azure onde você estava adicionando conjuntos de dados ao seu compartilhamento de dados.
Selecione EDW e, em seguida, selecione AggregatedTaxiData para a tabela.
Selecione Adicionar conjunto de dados
Agora temos uma tabela SQL que faz parte do nosso conjunto de dados. Em seguida, adicionaremos conjuntos de dados adicionais do Armazenamento do Azure Data Lake.
Selecione Adicionar conjunto de dados e selecione Azure Data Lake Storage Gen2
Selecione Seguinte
Expanda wwtaxidata. Expanda os dados do Boston Taxi. Você pode compartilhar até o nível do arquivo.
Selecione a pasta Boston Taxi Data para adicionar toda a pasta ao seu compartilhamento de dados.
Selecione Adicionar conjuntos de dados
Analise os conjuntos de dados que foram adicionados. Você deve ter uma tabela SQL e uma pasta ADLS Gen2 adicionadas ao seu compartilhamento de dados.
Selecione Continuar
Nesta tela, você pode adicionar destinatários ao seu compartilhamento de dados. Os destinatários que você adicionar receberão convites para seu compartilhamento de dados. Para este laboratório, você deve adicionar dois endereços de e-mail:
O endereço de email da assinatura do Azure em que você está.
Adicione os dados fictícios do consumidor chamado janedoe@fabrikam.com.
Nesta tela, você pode definir uma configuração de instantâneo para seu consumidor de dados. Isto permite-lhes receber atualizações regulares dos seus dados num intervalo definido por si.
Verifique o Snapshot Schedule e configure uma atualização horária dos seus dados usando a lista suspensa Recorrência .
Selecione Criar.
Agora você tem um compartilhamento de dados ativo. Vamos analisar o que você pode ver como um provedor de dados ao criar um compartilhamento de dados.
Selecione o compartilhamento de dados que você criou, intitulado DataProvider. Você pode navegar até ele selecionando Compartilhamentos enviados no compartilhamento de dados.
Selecione em Agenda de instantâneo. Você pode desativar o agendamento de instantâneo, se desejar.
Em seguida, selecione a guia Conjuntos de dados. Você pode adicionar conjuntos de dados adicionais a esse compartilhamento de dados depois que ele for criado.
Selecione a guia Compartilhar assinaturas . Ainda não existem subscrições de partilha porque o consumidor de dados ainda não aceitou o convite.
Navegue até a guia Convites . Aqui, você verá uma lista de convite(s) pendente(s).
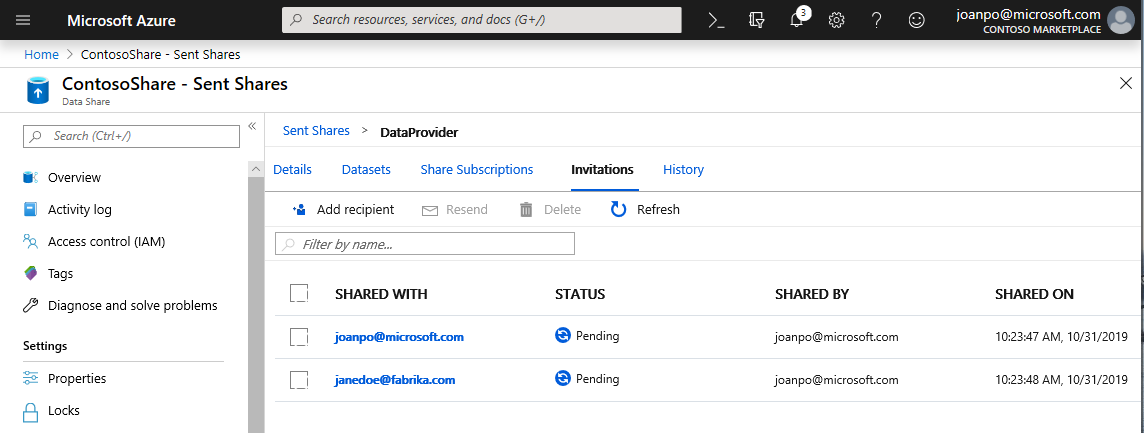
Selecione o convite para janedoe@fabrikam.com. Selecione Eliminar. Se o destinatário ainda não aceitou o convite, ele não poderá mais fazê-lo.
Selecione a guia Histórico. Nada é exibido ainda porque seu consumidor de dados ainda não aceitou seu convite e acionou um instantâneo.






Receber dados (fluxo do consumidor de dados)
Agora que revisamos nosso compartilhamento de dados, estamos prontos para mudar de contexto e vestir nosso chapéu de consumidor de dados.
Agora você deve ter um convite de Compartilhamento de Dados do Azure em sua caixa de entrada do Microsoft Azure. Inicie o Outlook Web Access (outlook.com) e entre usando as credenciais fornecidas para sua assinatura do Azure.
No e-mail que deveria ter recebido, selecione "Ver convite >". Neste ponto, você estará simulando a experiência do consumidor de dados ao aceitar um convite de provedores de dados para seu compartilhamento de dados.

Poderá ser-lhe pedido para selecionar uma subscrição. Certifique-se de selecionar a assinatura em que você está trabalhando para este laboratório.
Selecione no convite intitulado DataProvider.
Nesta tela Convite , observe vários detalhes sobre o compartilhamento de dados que você configurou anteriormente como um provedor de dados. Reveja os detalhes e aceite os termos de utilização, se fornecidos.
Selecione o Grupo de Assinaturas e Recursos que já existe para seu laboratório.
Em Conta de compartilhamento de dados, selecione DataConsumer. Você também pode criar uma nova conta de compartilhamento de dados.
Ao lado de Nome do compartilhamento recebido, observe que o nome do compartilhamento padrão é o nome especificado pelo provedor de dados. Dê ao compartilhamento um nome amigável que descreva os dados que você está prestes a receber, por exemplo , TaxiDataShare.
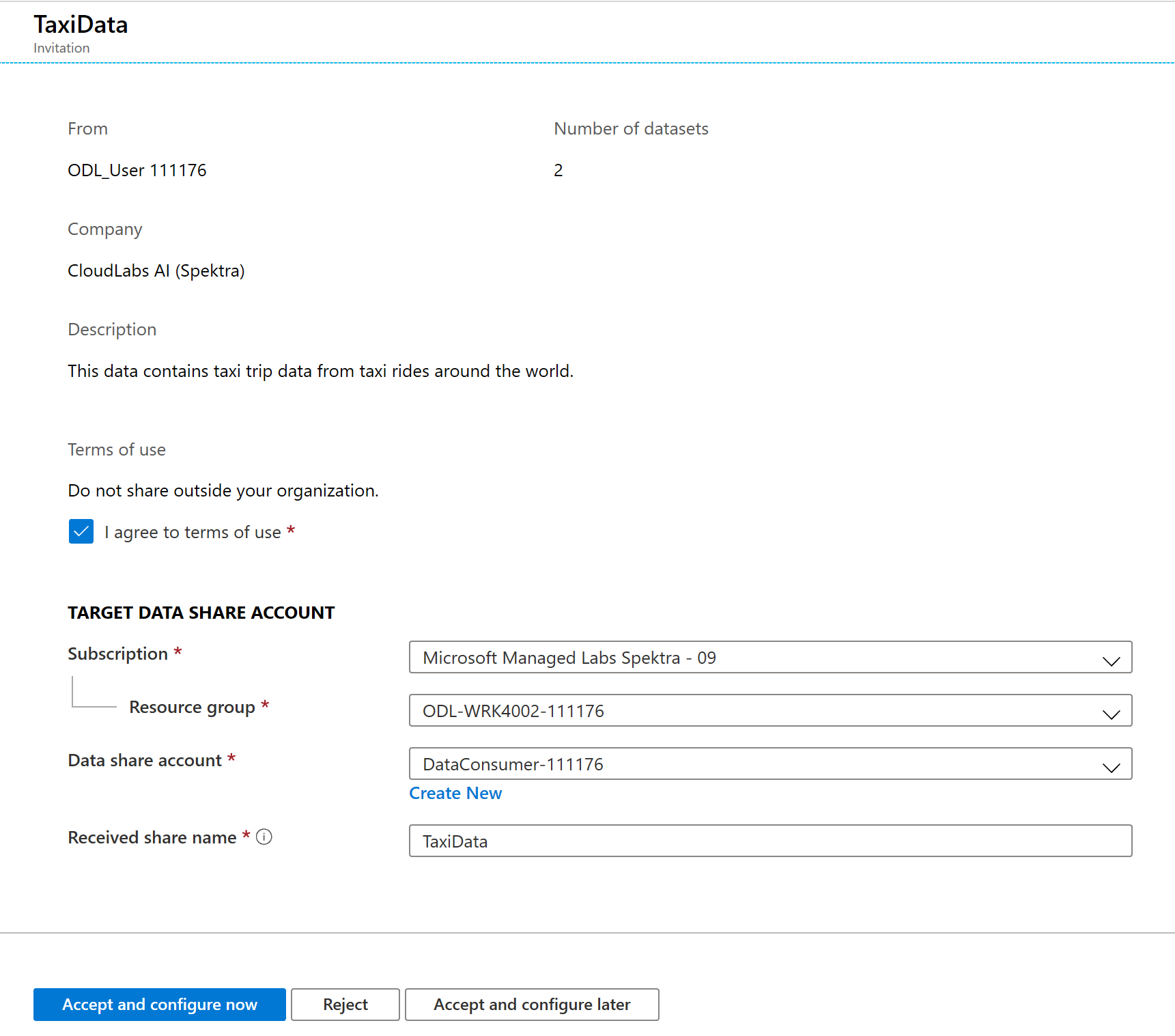
Você pode optar por Aceitar e configurar agora ou Aceitar e configurar mais tarde. Se você optar por aceitar e configurar agora, especifique uma conta de armazenamento onde todos os dados devem ser copiados. Se você optar por aceitar e configurar mais tarde, os conjuntos de dados no compartilhamento não serão mapeados e você precisará mapeá-los manualmente. Optaremos por isso mais tarde.
Selecione Aceitar e configurar mais tarde.
Ao configurar essa opção, uma assinatura de compartilhamento é criada, mas não há nenhum lugar para os dados chegarem, pois nenhum destino foi mapeado.
Em seguida, configure mapeamentos de conjunto de dados para o compartilhamento de dados.
Selecione o Compartilhamento recebido (o nome especificado na etapa 5).
O instantâneo do gatilho está acinzentado, mas o compartilhamento está Ativo.
Selecione a guia Conjuntos de dados. Cada conjunto de dados é Unmapped, o que significa que ele não tem destino para copiar dados.
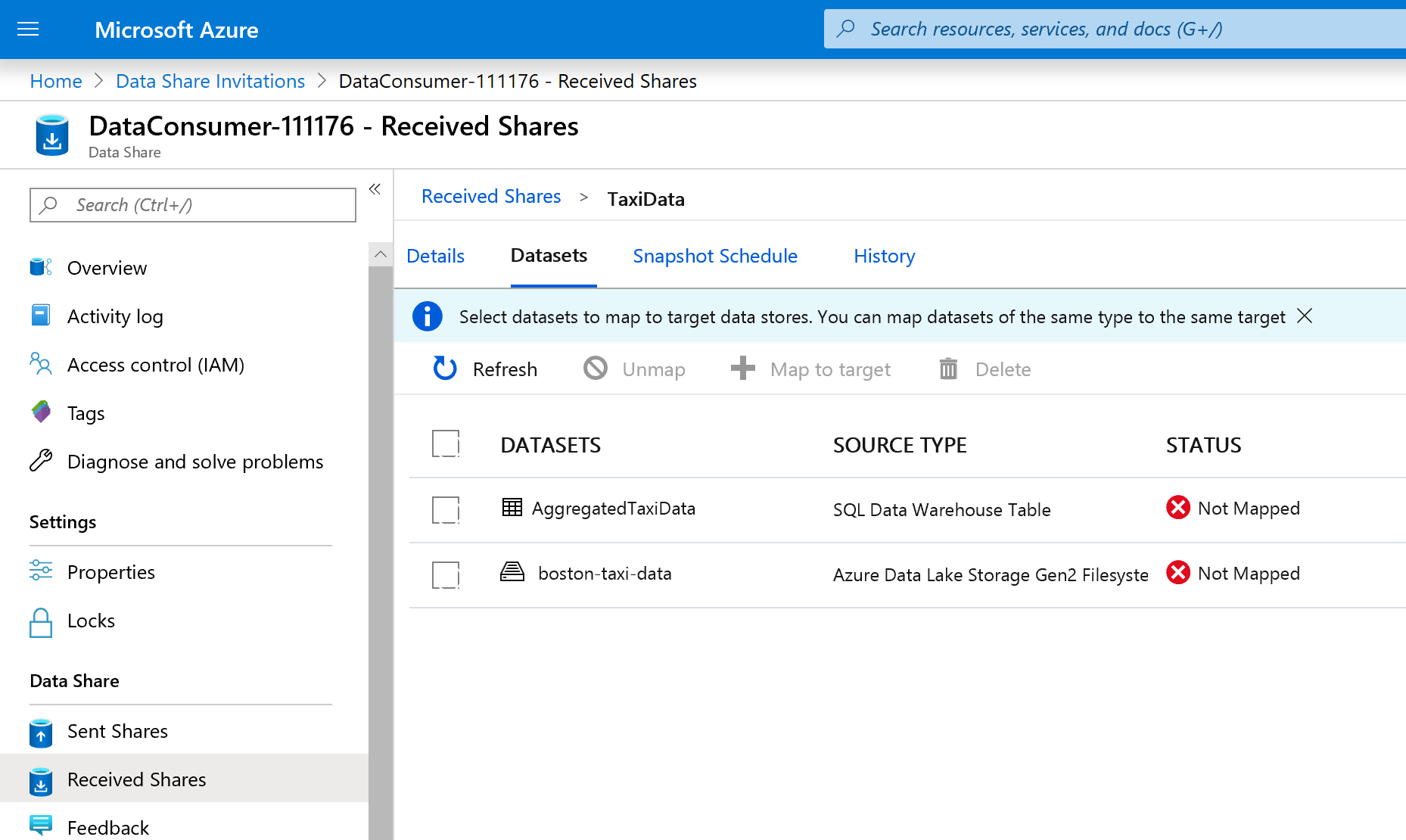
Selecione a Tabela do Azure Synapse Analytics e, em seguida, selecione + Mapear para o destino.
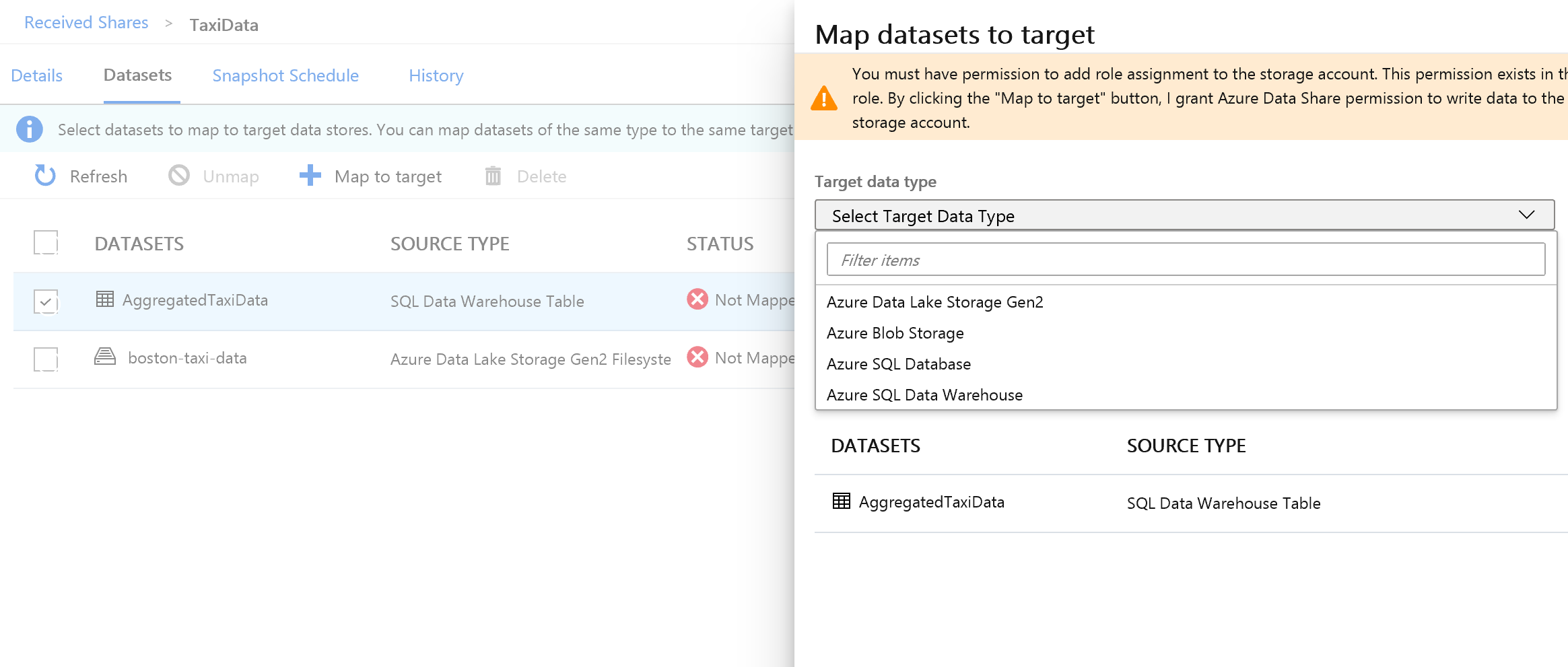
No lado direito da tela, selecione a lista suspensa Tipo de dados de destino.
Você pode mapear os dados SQL para uma ampla variedade de armazenamentos de dados. Nesse caso, estaremos mapeando para um Banco de Dados SQL do Azure.
(Opcional) Selecione Azure Data Lake Storage Gen2 como o tipo de dados de destino.
(Opcional) Selecione a conta de Subscrição, Grupo de Recursos e Armazenamento em que tem estado a trabalhar.
(Opcional) Você pode optar por receber os dados em seu data lake no formato csv ou parquet.
Ao lado de Tipo de dados de destino, selecione Banco de Dados SQL do Azure.
Selecione a conta de Subscrição, Grupo de Recursos e Armazenamento em que tem estado a trabalhar.
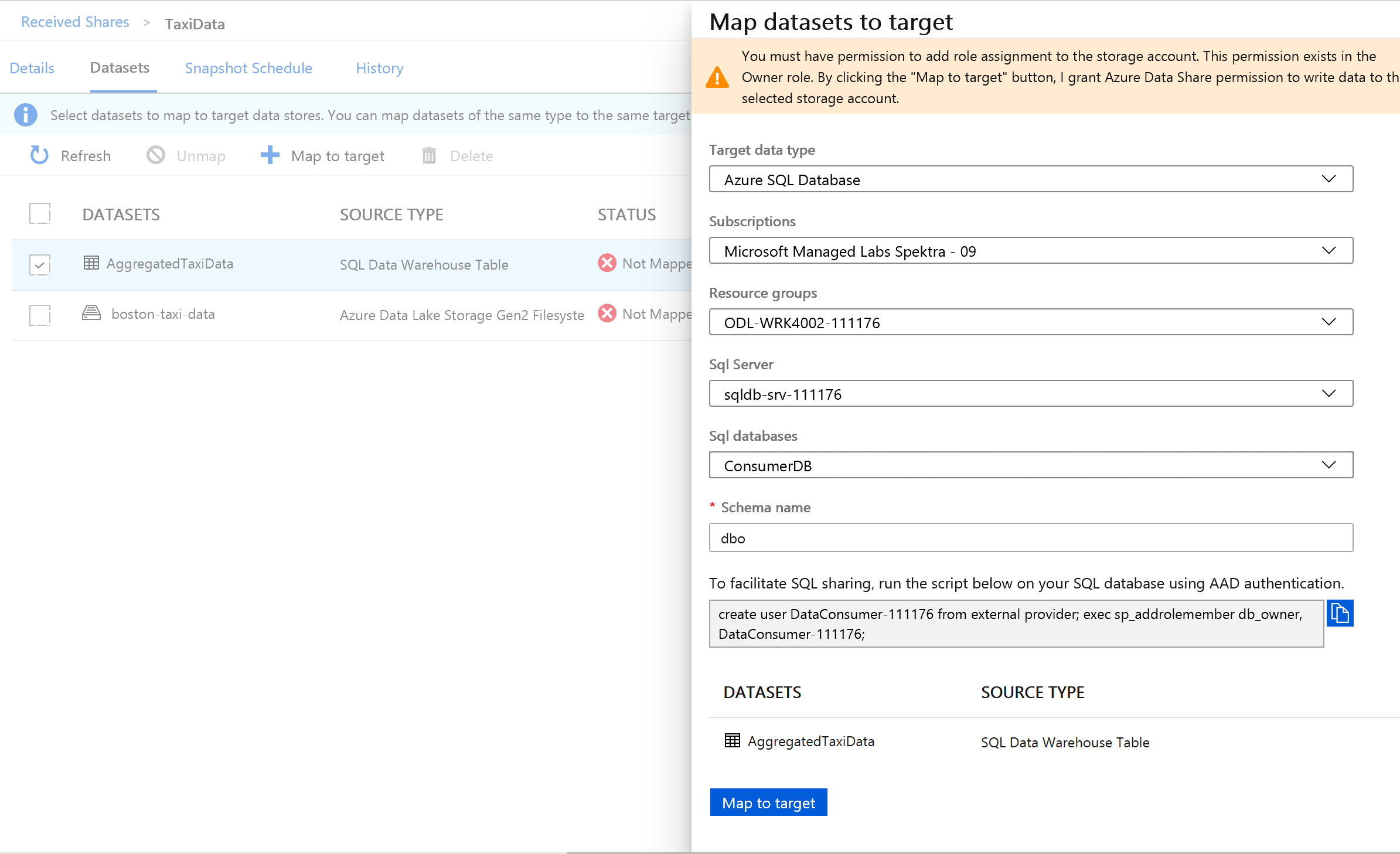
Antes de continuar, você precisará criar um novo usuário no SQL Server executando o script fornecido. Primeiro, copie o script fornecido para a área de transferência.
Abra uma nova guia do portal do Azure. Não feche a guia existente, pois você precisará voltar a ela em um momento.
Na nova guia aberta, navegue até bancos de dados SQL.
Selecione o banco de dados SQL (deve haver apenas um em sua assinatura). Tenha cuidado para não selecionar o armazém de dados.
Selecione Editor de consultas (visualização)
Use a autenticação do Microsoft Entra para entrar no editor de consultas.
Execute a consulta fornecida em seu compartilhamento de dados (copiada para a área de transferência na etapa 14).
Este comando permite que o serviço de Compartilhamento de Dados do Azure use Identidades Gerenciadas para Serviços do Azure para autenticar no SQL Server para poder copiar dados para ele.
Volte para a guia original e selecione Mapa para destino.
Em seguida, selecione a pasta Azure Data Lake Storage Gen2 que faz parte do conjunto de dados e mapeie-a para uma conta de Armazenamento de Blob do Azure.
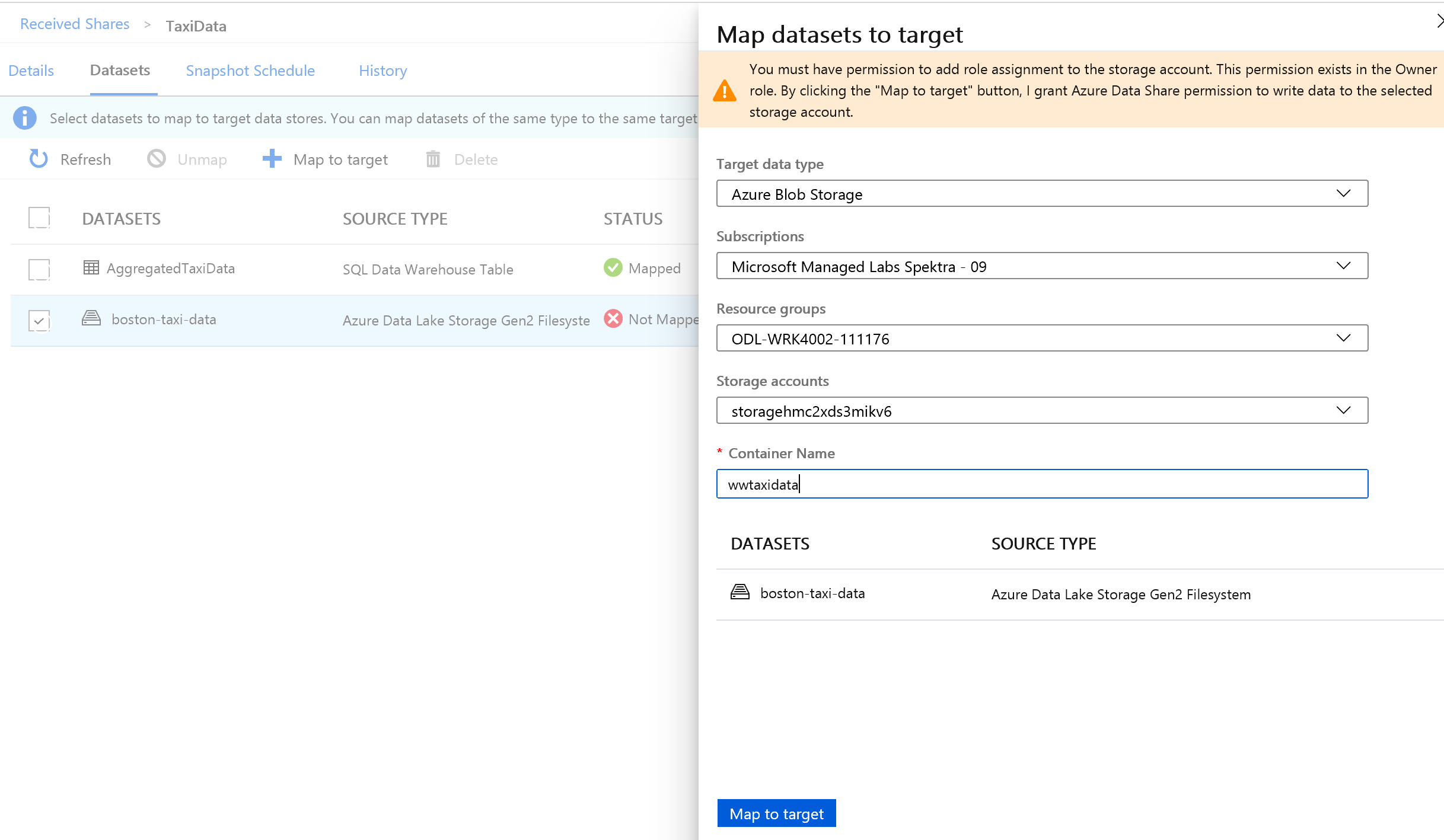
Com todos os conjuntos de dados mapeados, você está pronto para começar a receber dados do provedor de dados.
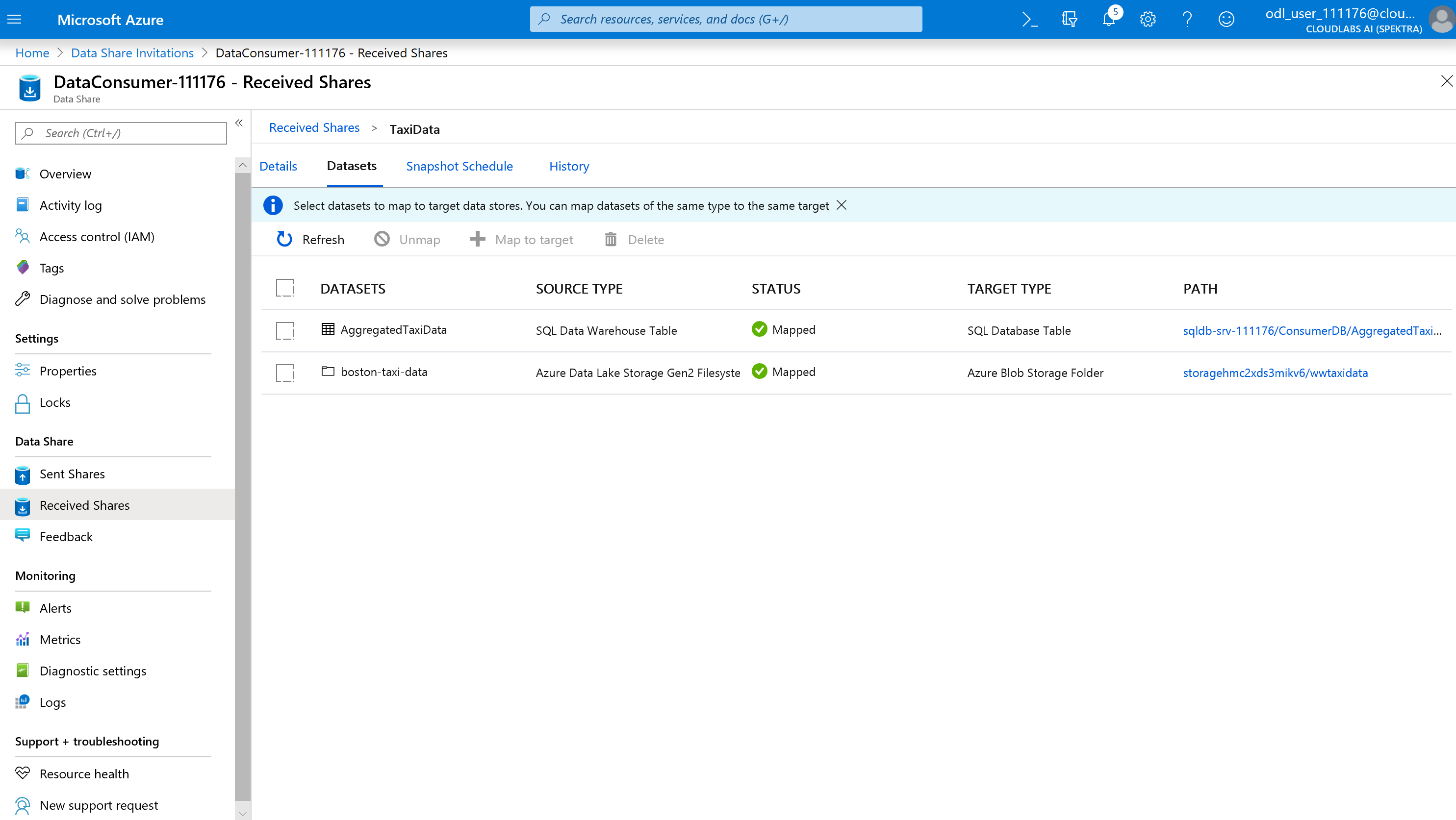
Selecione Detalhes.
O instantâneo de gatilho não está mais acinzentado, já que o compartilhamento de dados agora tem destinos para copiar.
Selecione Trigger snapshot ->Full copy.
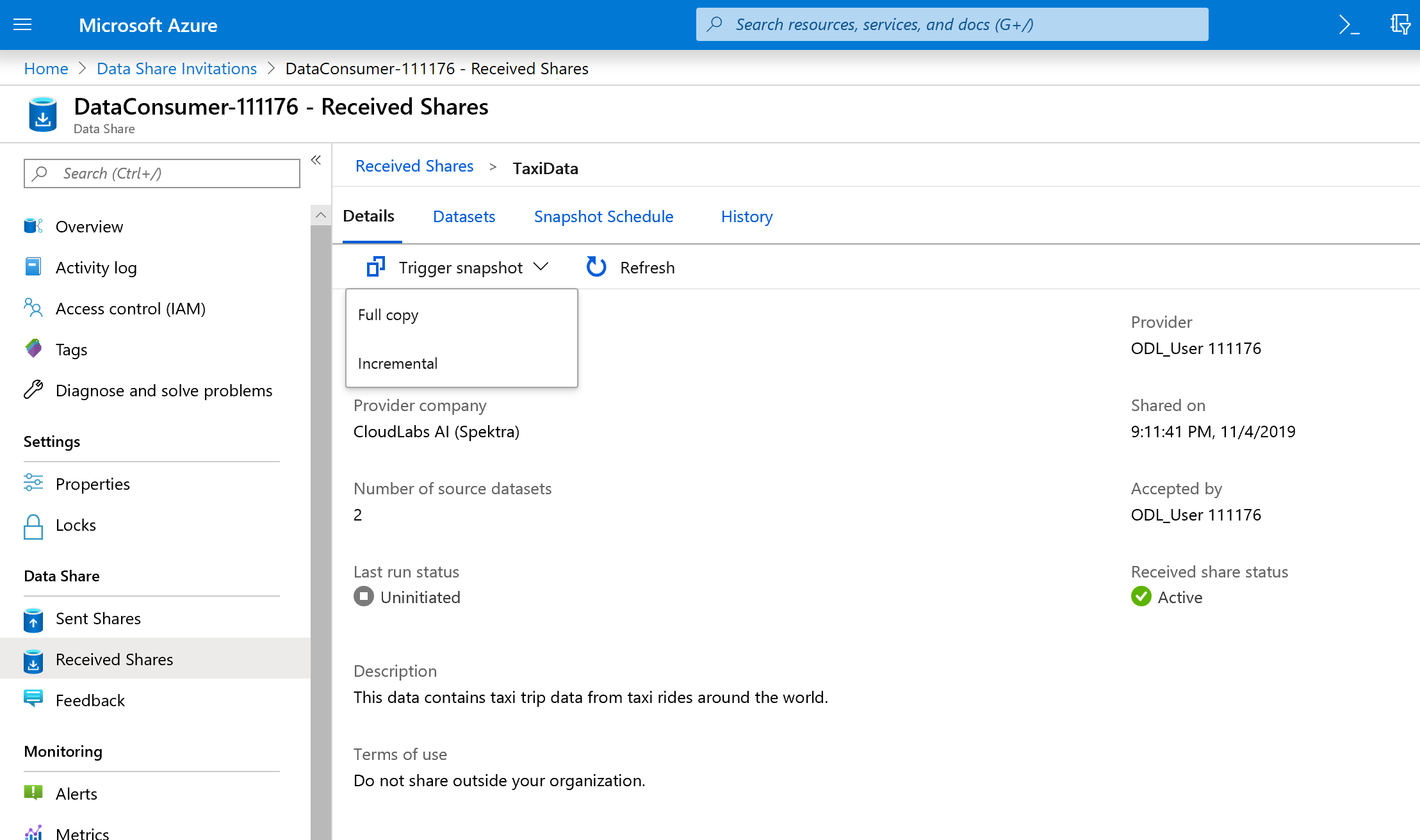
Isso começa a copiar dados para sua nova conta de compartilhamento de dados. Em um cenário do mundo real, esses dados seriam provenientes de terceiros.
Demora aproximadamente 3-5 minutos para os dados chegarem. Você pode monitorar o progresso selecionando na guia Histórico .
Enquanto espera, navegue até o compartilhamento de dados original (DataProvider) e exiba o status da guia Compartilhar assinaturas e histórico . Agora há uma assinatura ativa e, como provedor de dados, você também pode monitorar quando o consumidor de dados começou a receber os dados compartilhados com ele.
Navegue de volta para o compartilhamento de dados do consumidor de dados. Quando o status do gatilho for bem-sucedido, navegue até o banco de dados SQL e o data lake de destino para ver se os dados chegaram aos respetivos armazenamentos.







Parabéns, você concluiu o laboratório!