Copiar e transformar dados de/para um ponto final REST utilizando o Azure Data Factory
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve como utilizar a Atividade Copy no Azure Data Factory para copiar dados de/para um ponto final REST. O artigo baseia-se na Atividade Copy no Azure Data Factory, que apresenta uma descrição geral da Atividade Copy.
As diferenças entre este conector REST, o conector HTTP e o conector da tabela Web são:
- O conector REST suporta especificamente a cópia de dados de APIs RESTful.
- O conector HTTP é genérico para obter dados de qualquer ponto final HTTP, por exemplo, para transferir ficheiros. Antes deste conector REST, pode utilizar o conector HTTP para copiar dados de APIs RESTful, que é suportado, mas menos funcional comparativamente ao conector REST.
- O conector da tabela Web extrai o conteúdo da tabela de uma página Web HTML.
Capacidades suportadas
Este conector REST é suportado para os seguintes recursos:
| Capacidades suportadas | IR |
|---|---|
| Atividade de cópia (origem/coletor) | (1) (2) |
| Mapeando o fluxo de dados (origem/coletor) | (1) |
(1) Tempo de execução de integração do Azure (2) Tempo de execução de integração auto-hospedado
Para obter uma lista de armazenamentos de dados suportados como fontes/coletores, consulte Armazenamentos de dados suportados.
Especificamente, este conector REST genérico suporta:
- Copiar dados de um ponto de extremidade REST usando os métodos GET ou POST e copiar dados para um ponto de extremidade REST usando os métodos POST, PUT ou PATCH.
- Copiar dados usando uma das seguintes autenticações: Anônima, Básica, Entidade de Serviço, Credencial de Cliente OAuth2, Identidade Gerenciada Atribuída pelo Sistema e Identidade Gerenciada Atribuída pelo Usuário.
- Paginação nas APIs REST.
- Para REST como origem, copie a resposta JSON REST como está ou analise-a usando mapeamento de esquema. Somente a carga útil de resposta em JSON é suportada.
Gorjeta
Para testar uma solicitação de recuperação de dados antes de configurar o conector REST no Data Factory, saiba mais sobre a especificação da API para requisitos de cabeçalho e corpo. Você pode usar ferramentas como Visual Studio, Invoke-RestMethod do PowerShell ou um navegador da Web para validar.
Pré-requisitos
Se seu armazenamento de dados estiver localizado dentro de uma rede local, uma rede virtual do Azure ou a Amazon Virtual Private Cloud, você precisará configurar um tempo de execução de integração auto-hospedado para se conectar a ele.
Se o seu armazenamento de dados for um serviço de dados de nuvem gerenciado, você poderá usar o Tempo de Execução de Integração do Azure. Se o acesso for restrito a IPs aprovados nas regras de firewall, você poderá adicionar IPs do Azure Integration Runtime à lista de permissões.
Você também pode usar o recurso de tempo de execução de integração de rede virtual gerenciada no Azure Data Factory para acessar a rede local sem instalar e configurar um tempo de execução de integração auto-hospedado.
Para obter mais informações sobre os mecanismos de segurança de rede e as opções suportadas pelo Data Factory, consulte Estratégias de acesso a dados.
Começar agora
Para executar a atividade Copiar com um pipeline, você pode usar uma das seguintes ferramentas ou SDKs:
- A ferramenta Copiar dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- Azure PowerShell
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado REST usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado REST na interface do usuário do portal do Azure.
Navegue até a guia Gerenciar em seu espaço de trabalho do Azure Data Factory ou Synapse e selecione Serviços Vinculados e, em seguida, selecione Novo:
Procure REST e selecione o conector REST.
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
Detalhes de configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades que você pode usar para definir entidades do Data Factory que são específicas para o conector REST.
Propriedades do serviço vinculado
As seguintes propriedades são suportadas para o serviço vinculado REST:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como RestService. | Sim |
| url | A URL base do serviço REST. | Sim |
| enableServerCertificateValidation | Se o certificado TLS/SSL do lado do servidor deve ser validado ao se conectar ao ponto de extremidade. | Não (o padrão é true) |
| authenticationType | Tipo de autenticação usado para se conectar ao serviço REST. Os valores permitidos são Anonymous, Basic, AadServicePrincipal, OAuth2ClientCredential e ManagedServiceIdentity. Além disso, você pode configurar cabeçalhos de autenticação na authHeaders propriedade. Consulte as seções correspondentes abaixo sobre mais propriedades e exemplos, respectivamente. |
Sim |
| authCabeçalhos | Cabeçalhos de solicitação HTTP adicionais para autenticação. Por exemplo, para usar a autenticação de chave de API, você pode selecionar o tipo de autenticação como "Anônimo" e especificar a chave de API no cabeçalho. |
Não |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Saiba mais na seção Pré-requisitos . Se não for especificada, essa propriedade usará o Tempo de Execução de Integração do Azure padrão. | Não |
Para diferentes tipos de autenticação, consulte as seções correspondentes para obter detalhes.
- Autenticação básica
- Autenticação da entidade de serviço
- Autenticação de credenciais de cliente OAuth2
- Autenticação de identidade gerenciada atribuída pelo sistema
- Autenticação de identidade gerenciada atribuída pelo usuário
- Autenticação anónima
Usar autenticação básica
Defina a propriedade authenticationType como Basic. Além das propriedades genéricas descritas na seção anterior, especifique as seguintes propriedades:
| Property | Descrição | Obrigatório |
|---|---|---|
| nome de utilizador | O nome de usuário a ser usado para acessar o ponto de extremidade REST. | Sim |
| password | A senha do usuário (o valor userName ). Marque este campo como um tipo SecureString para armazená-lo com segurança no Data Factory. Você também pode fazer referência a um segredo armazenado no Cofre da Chave do Azure. | Sim |
Exemplo
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"authenticationType": "Basic",
"url" : "<REST endpoint>",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Usar a autenticação da entidade de serviço
Defina a propriedade authenticationType como AadServicePrincipal. Além das propriedades genéricas descritas na seção anterior, especifique as seguintes propriedades:
| Property | Descrição | Obrigatório |
|---|---|---|
| servicePrincipalId | Especifique a ID do cliente do aplicativo Microsoft Entra. | Sim |
| servicePrincipalCredentialType | Especifique o tipo de credencial a ser usado para autenticação da entidade de serviço. Os valores permitidos são ServicePrincipalKey e ServicePrincipalCert. |
Não |
| Para ServicePrincipalKey | ||
| servicePrincipalKey | Especifique a chave do aplicativo Microsoft Entra. Marque este campo como um SecureString para armazená-lo com segurança no Data Factory ou faça referência a um segredo armazenado no Cofre da Chave do Azure. | Não |
| Para ServicePrincipalCert | ||
| serviçoPrincipalEmbeddedCert | Especifique o certificado codificado base64 do seu aplicativo registrado no Microsoft Entra ID e verifique se o tipo de conteúdo do certificado é PKCS #12. Marque este campo como um SecureString para armazená-lo com segurança ou faça referência a um segredo armazenado no Cofre de Chaves do Azure. Vá para esta seção para saber como salvar o certificado no Cofre da Chave do Azure. | Não |
| servicePrincipalEmbeddedCertPassword | Especifique a senha do seu certificado se ele estiver protegido com uma senha. Marque este campo como um SecureString para armazená-lo com segurança ou faça referência a um segredo armazenado no Cofre de Chaves do Azure. | Não |
| tenant | Especifique as informações do locatário (nome de domínio ou ID do locatário) sob as quais seu aplicativo reside. Recupere-o passando o mouse no canto superior direito do portal do Azure. | Sim |
| aadResourceId | Especifique o recurso do Microsoft Entra que você está solicitando para autorização, por exemplo, https://management.core.windows.net. |
Sim |
| azureCloudType | Para autenticação da Entidade de Serviço, especifique o tipo de ambiente de nuvem do Azure no qual seu aplicativo Microsoft Entra está registrado. Os valores permitidos são AzurePublic, AzureChina, AzureUsGovernment e AzureGermany. Por padrão, o ambiente de nuvem do data factory é usado. |
Não |
Exemplo 1: Usando a autenticação de chave da entidade de serviço
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemplo 2: Usando a autenticação de certificado da entidade de serviço
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalEmbeddedCert": {
"type": "SecureString",
"value": "<the base64 encoded certificate of your application registered in Microsoft Entra ID>"
},
"servicePrincipalEmbeddedCertPassword": {
"type": "SecureString",
"value": "<password of your certificate>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Salvar o certificado da entidade de serviço no Cofre da Chave do Azure
Você tem duas opções para salvar o certificado da entidade de serviço no Cofre da Chave do Azure:
Opção 1
Converta o certificado da entidade de serviço em uma cadeia de caracteres base64. Saiba mais neste artigo.
Salve a cadeia de caracteres base64 como um segredo no Cofre de Chaves do Azure.
Opção 2
Se não conseguir transferir o certificado a partir do Cofre de Chaves do Azure, pode utilizar este modelo para guardar o certificado da entidade de serviço convertida como um segredo no Cofre de Chaves do Azure.

Usar autenticação de credenciais de cliente OAuth2
Defina a propriedade authenticationType como OAuth2ClientCredential. Além das propriedades genéricas descritas na seção anterior, especifique as seguintes propriedades:
| Property | Descrição | Obrigatório |
|---|---|---|
| tokenEndpoint | O ponto de extremidade de token do servidor de autorização para adquirir o token de acesso. | Sim |
| clientId | O ID do cliente associado ao seu aplicativo. | Sim |
| clientSecret | O segredo do cliente associado ao seu aplicativo. Marque este campo como um tipo SecureString para armazená-lo com segurança no Data Factory. Você também pode fazer referência a um segredo armazenado no Cofre da Chave do Azure. | Sim |
| âmbito | O âmbito do acesso necessário. Descreve o tipo de acesso que será solicitado. | Não |
| recurso | O serviço ou recurso de destino ao qual o acesso será solicitado. | Não |
Exemplo
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"enableServerCertificateValidation": true,
"authenticationType": "OAuth2ClientCredential",
"clientId": "<client ID>",
"clientSecret": {
"type": "SecureString",
"value": "<client secret>"
},
"tokenEndpoint": "<token endpoint>",
"scope": "<scope>",
"resource": "<resource>"
}
}
}
Usar autenticação de identidade gerenciada atribuída pelo sistema
Defina a propriedade authenticationType como ManagedServiceIdentity. Além das propriedades genéricas descritas na seção anterior, especifique as seguintes propriedades:
| Property | Descrição | Obrigatório |
|---|---|---|
| aadResourceId | Especifique o recurso do Microsoft Entra que você está solicitando para autorização, por exemplo, https://management.core.windows.net. |
Sim |
Exemplo
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<AAD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Usar autenticação de identidade gerenciada atribuída pelo usuário
Defina a propriedade authenticationType como ManagedServiceIdentity. Além das propriedades genéricas descritas na seção anterior, especifique as seguintes propriedades:
| Property | Descrição | Obrigatório |
|---|---|---|
| aadResourceId | Especifique o recurso do Microsoft Entra que você está solicitando para autorização, por exemplo, https://management.core.windows.net. |
Sim |
| credenciais | Especifique a identidade gerenciada atribuída pelo usuário como o objeto de credencial. | Sim |
Exemplo
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Usando cabeçalhos de autenticação
Além disso, você pode configurar cabeçalhos de solicitação para autenticação junto com os tipos de autenticação internos.
Exemplo: Usando a autenticação de chave de API
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint>",
"authenticationType": "Anonymous",
"authHeaders": {
"x-api-key": {
"type": "SecureString",
"value": "<API key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriedades do conjunto de dados
Esta seção fornece uma lista de propriedades suportadas pelo conjunto de dados REST.
Para obter uma lista completa de seções e propriedades disponíveis para definir conjuntos de dados, consulte Conjuntos de dados e serviços vinculados.
Para copiar dados do REST, as seguintes propriedades são suportadas:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do conjunto de dados deve ser definida como RestResource. | Sim |
| relativeUrl | Uma URL relativa ao recurso que contém os dados. Quando essa propriedade não é especificada, somente a URL especificada na definição de serviço vinculado é usada. O conector HTTP copia dados da URL combinada: [URL specified in linked service]/[relative URL specified in dataset]. |
Não |
Se você estava definindo requestMethod, additionalHeaderse requestBodypaginationRules no conjunto de dados, ele ainda é suportado como está, enquanto você é sugerido para usar o novo modelo em atividade no futuro.
Exemplo:
{
"name": "RESTDataset",
"properties": {
"type": "RestResource",
"typeProperties": {
"relativeUrl": "<relative url>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<REST linked service name>",
"type": "LinkedServiceReference"
}
}
}
Copiar propriedades da atividade
Esta seção fornece uma lista de propriedades suportadas pela fonte REST e pelo coletor.
Para obter uma lista completa de seções e propriedades disponíveis para definir atividades, consulte Pipelines.
REST como fonte
As seguintes propriedades são suportadas na seção de origem da atividade de cópia:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type da fonte de atividade de cópia deve ser definida como RestSource. | Sim |
| requestMethod | O método HTTP. Os valores permitidos são GET (padrão) e POST. | Não |
| additionalHeaders | Cabeçalhos de solicitação HTTP adicionais. | Não |
| requestBody [en] | O corpo da solicitação HTTP. | Não |
| paginaçãoRegras | As regras de paginação para compor solicitações de próxima página. Consulte a seção de suporte de paginação para obter detalhes. | Não |
| httpRequestTimeout | O tempo limite (o valor TimeSpan ) para a solicitação HTTP obter uma resposta. Esse valor é o tempo limite para obter uma resposta, não o tempo limite para ler os dados da resposta. O valor padrão é 00:01:40. | Não |
| requestInterval | O tempo de espera antes de enviar o pedido para a próxima página. O valor padrão é 00:00:01 | Não |
Nota
O conector REST ignora qualquer cabeçalho "Aceitar" especificado no additionalHeaders. Como o conector REST suporta apenas a resposta em JSON, ele gerará automaticamente um cabeçalho de Accept: application/json.
A matriz de objeto como o corpo da resposta não é suportada na paginação.
Exemplo 1: Usando o método Get com paginação
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"additionalHeaders": {
"x-user-defined": "helloworld"
},
"paginationRules": {
"AbsoluteUrl": "$.paging.next"
},
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Exemplo 2: Usando o método Post
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"requestMethod": "Post",
"requestBody": "<body for POST REST request>",
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
REST como pia
As seguintes propriedades são suportadas na seção coletor de atividade de cópia:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do coletor de atividade de cópia deve ser definida como RestSink. | Sim |
| requestMethod | O método HTTP. Os valores permitidos são POST (padrão), PUT e PATCH. | Não |
| additionalHeaders | Cabeçalhos de solicitação HTTP adicionais. | Não |
| httpRequestTimeout | O tempo limite (o valor TimeSpan ) para a solicitação HTTP obter uma resposta. Esse valor é o tempo limite para obter uma resposta, não o tempo limite para gravar os dados. O valor padrão é 00:01:40. | Não |
| requestInterval | O tempo de intervalo entre diferentes solicitações em milissegundos. O valor do intervalo de solicitação deve ser um número entre [10, 60000]. | Não |
| httpCompressionType | Tipo de compressão HTTP a utilizar durante o envio de dados com Nível de Compressão Ideal. Os valores permitidos são none e gzip. | Não |
| writeBatchSize | Número de registros a serem gravados no coletor REST por lote. O valor padrão é 10000. | Não |
O conector REST como coletor funciona com as APIs REST que aceitam JSON. Os dados serão enviados em JSON com o seguinte padrão. Conforme necessário, você pode usar o mapeamento do esquema de atividade de cópia para remodelar os dados de origem para que estejam em conformidade com a carga esperada pela API REST.
[
{ <data object> },
{ <data object> },
...
]
Exemplo:
"activities":[
{
"name": "CopyToREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<REST output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "RestSink",
"requestMethod": "POST",
"httpRequestTimeout": "00:01:40",
"requestInterval": 10,
"writeBatchSize": 10000,
"httpCompressionType": "none",
},
}
}
]
Mapeando propriedades de fluxo de dados
O REST é suportado em fluxos de dados para conjuntos de dados de integração e conjuntos de dados embutidos.
Transformação da fonte
| Property | Descrição | Obrigatório |
|---|---|---|
| requestMethod | O método HTTP. Os valores permitidos são GET e POST. | Sim |
| relativeUrl | Uma URL relativa ao recurso que contém os dados. Quando essa propriedade não é especificada, somente a URL especificada na definição de serviço vinculado é usada. O conector HTTP copia dados da URL combinada: [URL specified in linked service]/[relative URL specified in dataset]. |
Não |
| additionalHeaders | Cabeçalhos de solicitação HTTP adicionais. | Não |
| httpRequestTimeout | O tempo limite (o valor TimeSpan ) para a solicitação HTTP obter uma resposta. Esse valor é o tempo limite para obter uma resposta, não o tempo limite para gravar os dados. O valor padrão é 00:01:40. | Não |
| requestInterval | O tempo de intervalo entre diferentes solicitações em milissegundos. O valor do intervalo de solicitação deve ser um número entre [10, 60000]. | Não |
| QueryParameters. request_query_parameter OU QueryParameters['request_query_parameter'] | "request_query_parameter" é definido pelo usuário, que faz referência a um nome de parâmetro de consulta na próxima URL de solicitação HTTP. | Não |
Transformação do lavatório
| Property | Descrição | Obrigatório |
|---|---|---|
| additionalHeaders | Cabeçalhos de solicitação HTTP adicionais. | Não |
| httpRequestTimeout | O tempo limite (o valor TimeSpan ) para a solicitação HTTP obter uma resposta. Esse valor é o tempo limite para obter uma resposta, não o tempo limite para gravar os dados. O valor padrão é 00:01:40. | Não |
| requestInterval | O tempo de intervalo entre diferentes solicitações em milissegundos. O valor do intervalo de solicitação deve ser um número entre [10, 60000]. | Não |
| httpCompressionType | Tipo de compressão HTTP a utilizar durante o envio de dados com Nível de Compressão Ideal. Os valores permitidos são none e gzip. | Não |
| writeBatchSize | Número de registros a serem gravados no coletor REST por lote. O valor padrão é 10000. | Não |
Você pode definir os métodos delete, insert, update e upsert, bem como os dados de linha relativos a serem enviados ao coletor REST para operações CRUD.
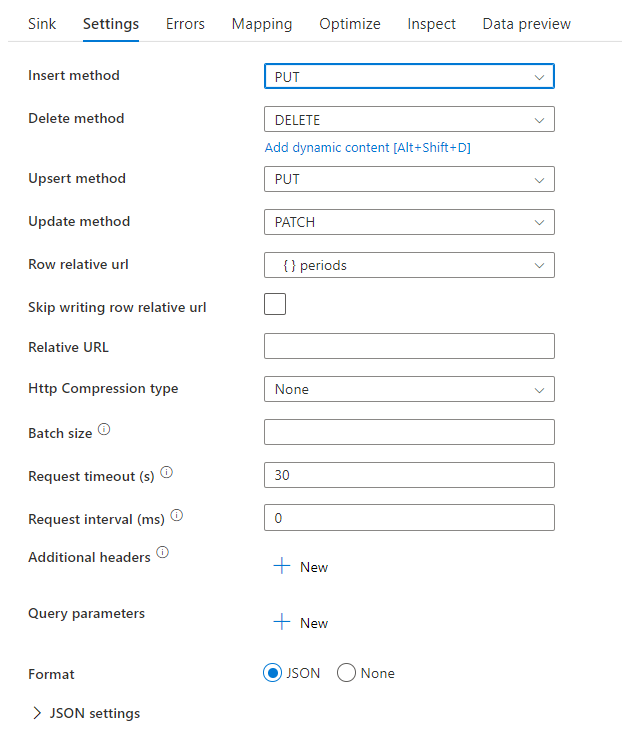
Script de fluxo de dados de exemplo
Observe o uso de uma transformação de linha de alteração antes do coletor para instruir o ADF sobre o tipo de ação a ser executada com o coletor REST. Ou seja, inserir, atualizar, atualizar, excluir.
AlterRow1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
rowRelativeUrl: 'periods',
insertHttpMethod: 'PUT',
deleteHttpMethod: 'DELETE',
upsertHttpMethod: 'PUT',
updateHttpMethod: 'PATCH',
timeout: 30,
requestFormat: ['type' -> 'json'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Nota
O Fluxo de Dados gera um total de chamadas de API N+1 ao processar N páginas. Isso inclui uma chamada inicial para inferir o esquema, seguida por N chamadas correspondentes ao número de páginas buscadas da fonte.
Suporte à paginação
Quando você copia dados de APIs REST, normalmente, a API REST limita o tamanho da carga útil de resposta de uma única solicitação sob um número razoável; enquanto retorna uma grande quantidade de dados, ele divide o resultado em várias páginas e exige que os chamadores enviem solicitações consecutivas para obter a próxima página do resultado. Normalmente, o pedido de uma página é dinâmico e composto pelas informações retornadas da resposta da página anterior.
Este conector REST genérico suporta os seguintes padrões de paginação:
- URL absoluto ou relativo da próxima solicitação = valor da propriedade no corpo da resposta atual
- URL absoluto ou relativo da próxima solicitação = valor do cabeçalho nos cabeçalhos de resposta atuais
- Parâmetro de consulta da próxima solicitação = valor da propriedade no corpo da resposta atual
- Parâmetro de consulta da próxima solicitação = valor do cabeçalho nos cabeçalhos de resposta atuais
- Cabeçalho da próxima solicitação = valor da propriedade no corpo da resposta atual
- Cabeçalho da próxima solicitação = valor do cabeçalho nos cabeçalhos de resposta atuais
As regras de paginação são definidas como um dicionário no conjunto de dados, que contém um ou mais pares chave-valor que diferenciam maiúsculas de minúsculas. A configuração será usada para gerar a solicitação a partir da segunda página. O conector irá parar de iterar quando ele recebe o código de status HTTP 204 (Sem Conteúdo), ou qualquer uma das expressões JSONPath em "paginationRules" retorna null.
Chaves suportadas em regras de paginação:
| Chave | Description |
|---|---|
| AbsoluteUrl | Indica a URL para emitir a próxima solicitação. Pode ser URL absoluto ou URL relativo. |
| QueryParameters. request_query_parameter OU QueryParameters['request_query_parameter'] | "request_query_parameter" é definido pelo usuário, que faz referência a um nome de parâmetro de consulta na próxima URL de solicitação HTTP. |
| Cabeçalhos. request_header OU Cabeçalhos['request_header'] | "request_header" é definido pelo usuário, que faz referência a um nome de cabeçalho na próxima solicitação HTTP. |
| EndCondition:end_condition | "end_condition" é definido pelo usuário, o que indica a condição que terminará o loop de paginação na próxima solicitação HTTP. |
| MaxRequestNumber | Indica o número máximo da solicitação de paginação. Deixá-lo vazio significa que não há limite. |
| SuporteRFC5988 | Por padrão, isso é definido como true se nenhuma regra de paginação for definida. Você pode desabilitar essa regra definindo supportRFC5988 como false ou remover essa propriedade do script. |
Valores suportados em regras de paginação:
| valor | Description |
|---|---|
| Cabeçalhos. response_header OU Cabeçalhos['response_header'] | "response_header" é definido pelo usuário, que faz referência a um nome de cabeçalho na resposta HTTP atual, cujo valor será usado para emitir a próxima solicitação. |
| Uma expressão JSONPath começando com "$" (representando a raiz do corpo da resposta) | O corpo da resposta deve conter apenas um objeto JSON e a matriz do objeto, pois o corpo da resposta não é suportado. A expressão JSONPath deve retornar um único valor primitivo, que será usado para emitir a próxima solicitação. |
Nota
As regras de paginação no mapeamento de fluxos de dados são diferentes dela na atividade de cópia nos seguintes aspetos:
- O intervalo não é suportado no mapeamento de fluxos de dados.
-
['']não é suportado no mapeamento de fluxos de dados. Em vez disso, use{}para escapar do caractere especial. Por exemplo,body.{@odata.nextLink}cujo nó@odata.nextLinkJSON contém caractere.especial. - A condição final é suportada no mapeamento de fluxos de dados, mas a sintaxe da condição é diferente dela na atividade de cópia.
bodyé utilizado para indicar o corpo da resposta em vez de$.headeré usado para indicar o cabeçalho de resposta em vez deheaders. Aqui estão dois exemplos que mostram essa diferença:- Exemplo 1:
Atividade de cópia: "EndCondition:$.data": "Vazio"
Mapeando fluxos de dados: "EndCondition:body.data": "Vazio" - Exemplo 2:
Atividade de cópia: "EndCondition:headers.complete": "Exist"
Mapeando fluxos de dados: "EndCondition:header.complete": "Exist"
- Exemplo 1:
Exemplos de regras de paginação
Esta seção fornece uma lista de exemplos de configurações de regras de paginação.
Exemplo 1: Variáveis em QueryParameters
Este exemplo fornece as etapas de configuração para enviar várias solicitações cujas variáveis estão em QueryParameters.
Vários pedidos:
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
......
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=10000
Passo 1: Insira sysparm_offset={offset} o URL Base ou o URL Relativo, conforme mostrado nas seguintes capturas de tela:
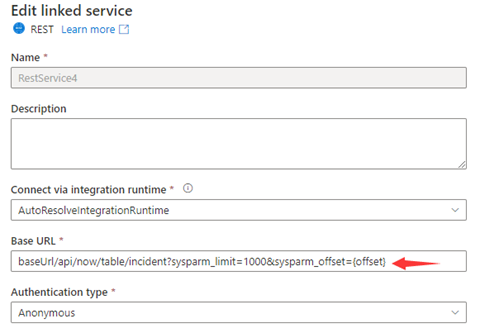
ou
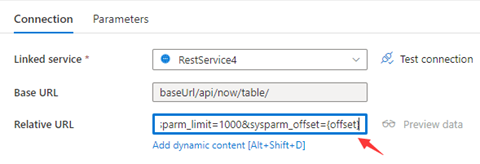
Etapa 2: Defina as regras de paginação como opção 1 ou opção 2:
Opção1: "QueryParameters.{ offset}" : "INTERVALO:0:10000:1000"
Opção2: "AbsoluteUrl.{ offset}" : "INTERVALO:0:10000:1000"
Exemplo 2:Variáveis em AbsoluteUrl
Este exemplo fornece as etapas de configuração para enviar várias solicitações cujas variáveis estão em AbsoluteUrl.
Vários pedidos:
BaseUrl/api/now/table/t1
BaseUrl/api/now/table/t2
......
BaseUrl/api/now/table/t100
Etapa 1: insira {id} a URL Base na página de configuração do serviço vinculado ou a URL relativa no painel de conexão do conjunto de dados.
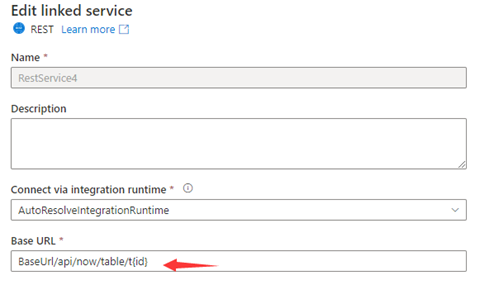
ou
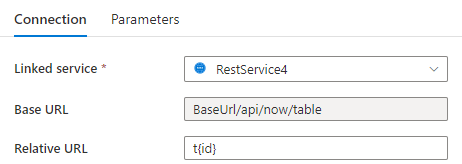
Etapa 2: Defina as regras de paginação como "AbsoluteUrl.{ id}" :"INTERVALO:1:100:1".
Exemplo 3:Variáveis em cabeçalhos
Este exemplo fornece as etapas de configuração para enviar várias solicitações cujas variáveis estão em Headers.
Vários pedidos:
RequestUrl: https://example/table
Pedido 1: Header(id->0)
Pedido 2: Header(id->10)
......
Pedido 100: Header(id->100)
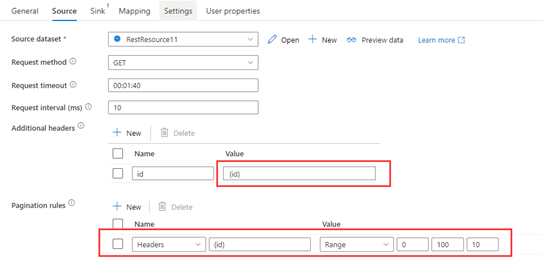
Passo 1: Entrada {id} em cabeçalhos adicionais.
Etapa 2: Definir regras de paginação como "Cabeçalhos.{ id}" : "INTERVALO:0:100:10".
Exemplo 4:As variáveis estão em AbsoluteUrl/QueryParameters/Headers, a variável final não é predefinida e a condição final é baseada na resposta
Este exemplo fornece etapas de configuração para enviar várias solicitações cujas variáveis estão em AbsoluteUrl/QueryParameters/Headers, mas a variável final não está definida. Para respostas diferentes, diferentes configurações de regra de condição final são mostradas no Exemplo 4.1-4.6.
Vários pedidos:
Request 1: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
Request 2: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
Request 3: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=2000,
......
Duas respostas encontradas neste exemplo:
Resposta 1:
{
Data: [
{key1: val1, key2: val2
},
{key1: val3, key2: val4
}
]
}
Resposta 2:
{
Data: [
{key1: val5, key2: val6
},
{key1: val7, key2: val8
}
]
}
Etapa 1: Defina o intervalo de regras de paginação como Exemplo 1 e deixe o final do intervalo vazio como "AbsoluteUrl.{ compensação}": "INTERVALO:0::1000".
Passo 2: Defina regras de condição final diferentes de acordo com diferentes últimas respostas. Veja abaixo exemplos:
Exemplo 4.1: A paginação termina quando o valor do nó específico em resposta está vazio
A API REST retorna a última resposta na seguinte estrutura:
{ Data: [] }Defina a regra de condição final como "EndCondition:$.data": "Vazio" para encerrar a paginação quando o valor do nó específico em resposta estiver vazio.

Exemplo 4.2: A paginação termina quando o valor do nó específico em resposta não existe
A API REST retorna a última resposta na seguinte estrutura:
{}Defina a regra de condição final como "EndCondition:$.data": "NonExist" para encerrar a paginação quando o valor do nó específico em resposta não existir.

Exemplo 4.3: A paginação termina quando o valor do nó específico em resposta existe
A API REST retorna a última resposta na seguinte estrutura:
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }Defina a regra de condição final como "EndCondition:$. Complete": "Exist " para terminar a paginação quando o valor do nó específico em resposta existir.

Exemplo 4.4: A paginação termina quando o valor do nó específico em resposta é um valor const definido pelo usuário
A API REST retorna a resposta na seguinte estrutura:
{ Data: [ {key1: val1, key2: val2 }, {key1: val3, key2: val4 } ], Complete: false }......
E a última resposta está na seguinte estrutura:
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }Defina a regra de condição final como "EndCondition:$. Complete": "Const:true" para finalizar a paginação quando o valor do nó específico em resposta for um valor const definido pelo usuário.

Exemplo 4.5: A paginação termina quando o valor da chave de cabeçalho em resposta é igual ao valor const definido pelo usuário
As teclas de cabeçalho nas respostas da API REST são mostradas na estrutura abaixo:
Cabeçalho de resposta 1:
header(Complete->0)
......
Cabeçalho da última resposta:header(Complete->1)Defina a regra de condição final como "EndCondition:headers. Complete": "Const:1" para terminar a paginação quando o valor da chave de cabeçalho em resposta for igual ao valor const definido pelo usuário.

Exemplo 4.6: A paginação termina quando a chave existe no cabeçalho da resposta
As teclas de cabeçalho nas respostas da API REST são mostradas na estrutura abaixo:
Cabeçalho de resposta 1:
header()
......
Cabeçalho da última resposta:header(CompleteTime->20220920)Defina a regra de condição final como "EndCondition:headers. CompleteTime": "Exist" para terminar a paginação quando a chave existir no cabeçalho da resposta.

Exemplo 5:Definir condição final para evitar solicitações intermináveis quando a regra de intervalo não estiver definida
Este exemplo fornece as etapas de configuração para enviar várias solicitações quando a regra de intervalo não é usada. A condição final pode ser definida consulte o Exemplo 4.1-4.6 para evitar solicitações intermináveis. A API REST retorna a resposta na estrutura a seguir, caso em que a URL da próxima página é representada em paging.next.
{
"data": [
{
"created_time": "2017-12-12T14:12:20+0000",
"name": "album1",
"id": "1809938745705498_1809939942372045"
},
{
"created_time": "2017-12-12T14:14:03+0000",
"name": "album2",
"id": "1809938745705498_1809941802371859"
},
{
"created_time": "2017-12-12T14:14:11+0000",
"name": "album3",
"id": "1809938745705498_1809941879038518"
}
],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "https://graph.facebook.com/me/albums?limit=25&after=MTAxNTExOTQ1MjAwNzI5NDE="
}
}
...
A última resposta é:
{
"data": [],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "Same with Last Request URL"
}
}
Passo 1: Defina as regras de paginação como "AbsoluteUrl": "$.paging.next".
Passo 2: Se next na última resposta for sempre o mesmo com o URL do último pedido e não estiver vazio, serão enviados pedidos intermináveis. A condição final pode ser usada para evitar pedidos intermináveis. Portanto, defina a regra de condição final consulte o Exemplo 4.1-4.6.
Exemplo 6:Defina o número máximo de solicitação para evitar solicitações intermináveis
Defina MaxRequestNumber para evitar solicitações intermináveis, conforme mostrado na captura de tela a seguir:

Exemplo 7:A regra de paginação RFC 5988 é suportada por padrão
O back-end obterá automaticamente o próximo URL com base nos links de estilo RFC 5988 no cabeçalho.

Gorjeta
Se você não quiser habilitar essa regra de paginação padrão, poderá defini-la supportRFC5988 ou false simplesmente excluí-la no script.
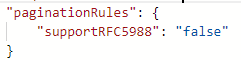
Exemplo 8a: A próxima URL de solicitação está no corpo da resposta ao usar paginação no mapeamento de fluxos de dados
Este exemplo indica como definir a regra de paginação e a regra de condição final no mapeamento de fluxos de dados quando a próxima URL de solicitação é do corpo da resposta.
O esquema de resposta é mostrado abaixo:
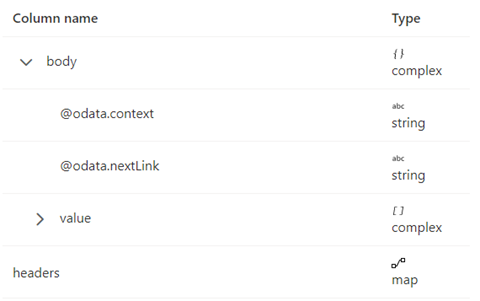
As regras de paginação devem ser definidas como a seguinte captura de tela:

Por padrão, a paginação será interrompida quando o corpo. {@odata.nextLink}** é nulo ou vazio.
Mas se o valor de @odata.nextLink no último corpo de resposta for igual ao URL da última solicitação, isso levará ao loop infinito. Para evitar essa condição, defina regras de condição final.
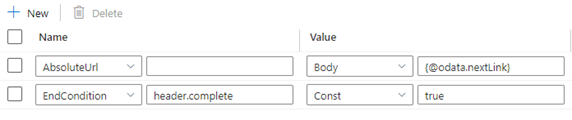
Se Valor na última resposta for Vazio, a regra de condição final pode ser definida como abaixo:

Se o valor da chave completa no cabeçalho da resposta for igual a true indicar o fim da paginação, a regra da condição final pode ser definida como abaixo:
Exemplo 8b: O URL da próxima solicitação está no corpo da resposta ao usar paginação na atividade de cópia
Este exemplo demonstra como definir a regra de paginação em uma atividade de cópia quando a próxima URL de solicitação está contida no corpo da resposta.
O esquema de resposta é mostrado abaixo:
As regras de paginação devem ser definidas como mostrado na captura de tela a seguir:

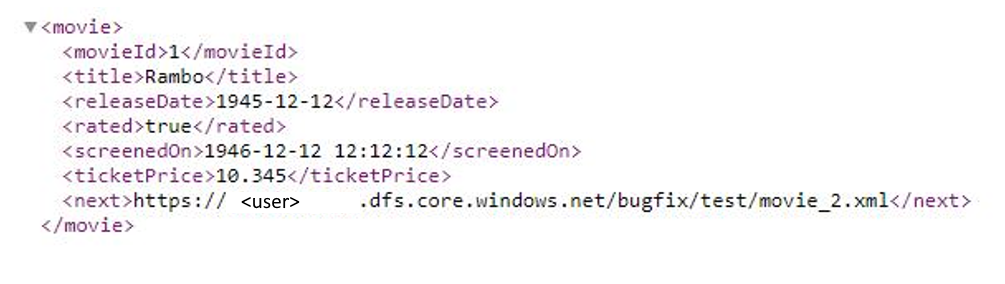
Exemplo 9: O formato de resposta é XML e a próxima URL de solicitação é do corpo da resposta quando usar paginação no mapeamento de fluxos de dados
Este exemplo indica como definir a regra de paginação no mapeamento de fluxos de dados quando o formato de resposta é XML e a próxima URL de solicitação é do corpo da resposta. Como mostrado na captura de tela a seguir, o primeiro URL é https://< user.dfs.core.windows.NET/bugfix/test/movie_1.xml>
O esquema de resposta é mostrado abaixo:
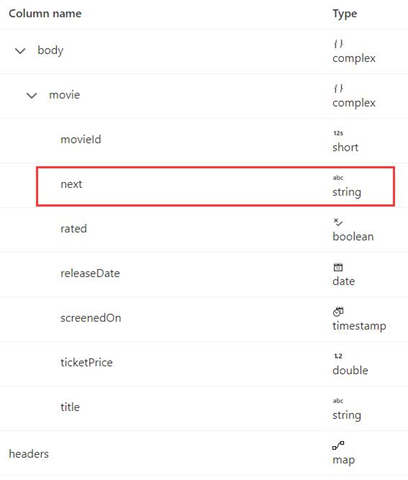
A sintaxe da regra de paginação é a mesma do Exemplo 8 e deve ser definida como abaixo neste exemplo:

Exportar resposta JSON no estado em que se encontra
Você pode usar esse conector REST para exportar a resposta REST API JSON como está para vários armazenamentos baseados em arquivos. Para obter essa cópia agnóstica de esquema, ignore a seção "estrutura" (também chamada de esquema) no conjunto de dados e o mapeamento de esquema na atividade de cópia.
Mapeamento de esquema
Para copiar dados do ponto de extremidade REST para o coletor tabular, consulte o mapeamento de esquema.
Conteúdos relacionados
Para obter uma lista de armazenamentos de dados que a Atividade de Cópia suporta como fontes e coletores no Azure Data Factory, consulte Armazenamentos e formatos de dados suportados.