Copiar e transformar dados do Hive usando o Azure Data Factory
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve como usar a Atividade de Cópia em um pipeline do Azure Data Factory ou do Synapse Analytics para copiar dados do Hive. Ele se baseia no artigo de visão geral da atividade de cópia que apresenta uma visão geral da atividade de cópia.
Capacidades suportadas
Este conector Hive é suportado para os seguintes recursos:
| Capacidades suportadas | IR |
|---|---|
| Atividade de cópia (fonte/-) | (1) (2) |
| Mapeando o fluxo de dados (fonte/-) | (1) |
| Atividade de Pesquisa | (1) (2) |
(1) Tempo de execução de integração do Azure (2) Tempo de execução de integração auto-hospedado
Para obter uma lista de armazenamentos de dados suportados como fontes/coletores pela atividade de cópia, consulte a tabela Armazenamentos de dados suportados.
O serviço fornece um driver interno para habilitar a conectividade, portanto, você não precisa instalar manualmente nenhum driver usando esse conector.
O conector suporta as versões do Windows neste artigo.
Pré-requisitos
Se seu armazenamento de dados estiver localizado dentro de uma rede local, uma rede virtual do Azure ou a Amazon Virtual Private Cloud, você precisará configurar um tempo de execução de integração auto-hospedado para se conectar a ele.
Se o seu armazenamento de dados for um serviço de dados de nuvem gerenciado, você poderá usar o Tempo de Execução de Integração do Azure. Se o acesso for restrito a IPs aprovados nas regras de firewall, você poderá adicionar IPs do Azure Integration Runtime à lista de permissões.
Você também pode usar o recurso de tempo de execução de integração de rede virtual gerenciada no Azure Data Factory para acessar a rede local sem instalar e configurar um tempo de execução de integração auto-hospedado.
Para obter mais informações sobre os mecanismos de segurança de rede e as opções suportadas pelo Data Factory, consulte Estratégias de acesso a dados.
Introdução
Para executar a atividade Copiar com um pipeline, você pode usar uma das seguintes ferramentas ou SDKs:
- A ferramenta Copiar dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- Azure PowerShell
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado ao Hive usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado ao Hive na interface do usuário do portal do Azure.
Navegue até a guia Gerenciar em seu espaço de trabalho do Azure Data Factory ou Synapse e selecione Serviços Vinculados e clique em Novo:
Procure Hive e selecione o conector Hive.
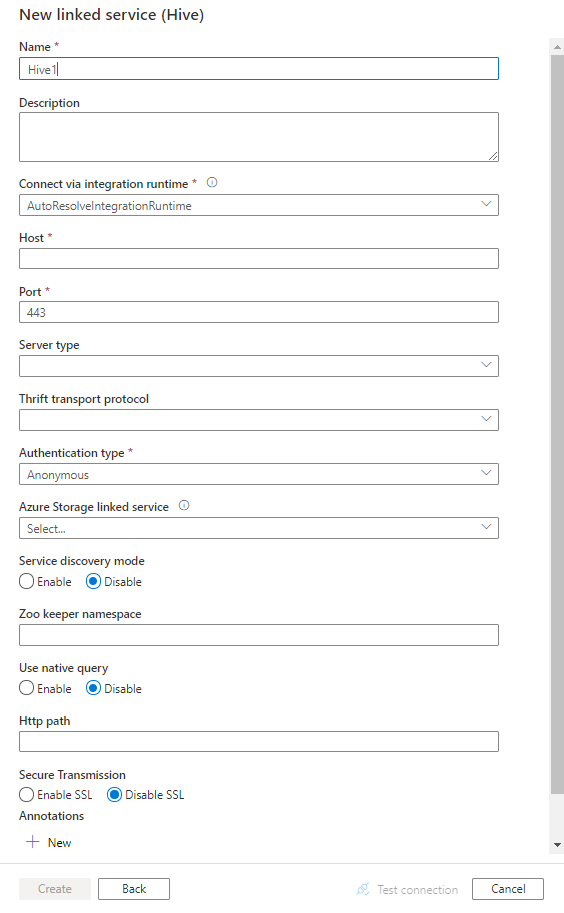
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
Detalhes de configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades usadas para definir entidades do Data Factory específicas para o conector do Hive.
Propriedades do serviço vinculado
As seguintes propriedades são suportadas para o serviço vinculado do Hive:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como: Hive | Sim |
| host | Endereço IP ou nome de host do servidor Hive, separados por ';' para vários hosts (somente quando serviceDiscoveryMode está habilitado). | Sim |
| porta | A porta TCP que o servidor Hive usa para escutar conexões de cliente. Se você se conectar ao Azure HDInsight, especifique a porta como 443. | Sim |
| Tipo de servidor | O tipo de servidor Hive. Os valores permitidos são: HiveServer1, HiveServer2, HiveThriftServer |
Não |
| thriftTransportProtocol | O protocolo de transporte a ser usado na camada Thrift. Os valores permitidos são: Binary, SASL, HTTP |
Não |
| authenticationType | O método de autenticação usado para acessar o servidor Hive. Os valores permitidos são: Anonymous, Username, UsernameAndPassword, WindowsAzureHDInsightService. A autenticação Kerberos não é suportada agora. |
Sim |
| serviceDiscoveryMode | true para indicar usando o serviço ZooKeeper, false not. | Não |
| zooKeeperNameSpace | O namespace no ZooKeeper sob o qual os nós do Hive Server 2 são adicionados. | Não |
| useNativeQuery | Especifica se o driver usa consultas HiveQL nativas ou as converte em um formulário equivalente no HiveQL. | Não |
| nome de utilizador | O nome de usuário que você usa para acessar o Hive Server. | Não |
| password | A senha correspondente ao usuário. Marque este campo como um SecureString para armazená-lo com segurança ou faça referência a um segredo armazenado no Cofre de Chaves do Azure. | Não |
| httpCaminho | A URL parcial correspondente ao servidor Hive. | Não |
| habilitarSsl | Especifica se as conexões com o servidor são criptografadas usando TLS. O valor predefinido é false. | Não |
| trustedCertPath | O caminho completo do arquivo .pem contendo certificados de CA confiáveis para verificar o servidor ao se conectar por TLS. Essa propriedade só pode ser definida ao usar TLS em IR auto-hospedado. O valor padrão é o arquivo cacerts.pem instalado com o IR. | Não |
| useSystemTrustStore | Especifica se um certificado de autoridade de certificação deve ser usado do armazenamento confiável do sistema ou de um arquivo PEM especificado. O valor predefinido é false. | Não |
| allowHostNameCNMismatch | Especifica se um nome de certificado TLS/SSL emitido pela CA deve corresponder ao nome do host do servidor ao se conectar por TLS. O valor predefinido é false. | Não |
| allowSelfSignedServerCert | Especifica se os certificados autoassinados do servidor devem ser permitidos. O valor predefinido é false. | Não |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Saiba mais na seção Pré-requisitos . Se não for especificado, ele usará o Tempo de Execução de Integração do Azure padrão. | Não |
| storageReference | Uma referência ao serviço vinculado da conta de armazenamento usada para preparar dados no mapeamento do fluxo de dados. Isso é necessário somente ao usar o serviço vinculado do Hive no mapeamento do fluxo de dados | Não |
Exemplo:
{
"name": "HiveLinkedService",
"properties": {
"type": "Hive",
"typeProperties": {
"host" : "<cluster>.azurehdinsight.net",
"port" : "<port>",
"authenticationType" : "WindowsAzureHDInsightService",
"username" : "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa de seções e propriedades disponíveis para definir conjuntos de dados, consulte o artigo sobre conjuntos de dados. Esta seção fornece uma lista de propriedades suportadas pelo conjunto de dados do Hive.
Para copiar dados do Hive, defina a propriedade type do conjunto de dados como HiveObject. As seguintes propriedades são suportadas:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do conjunto de dados deve ser definida como: HiveObject | Sim |
| esquema | Nome do esquema. | Não (se "consulta" na fonte da atividade for especificado) |
| tabela | Nome da tabela. | Não (se "consulta" na fonte da atividade for especificado) |
| tableName | Nome da tabela, incluindo a parte do esquema. Esta propriedade é suportada para compatibilidade com versões anteriores. Para nova carga de trabalho, use schema e table. |
Não (se "consulta" na fonte da atividade for especificado) |
Exemplo
{
"name": "HiveDataset",
"properties": {
"type": "HiveObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Hive linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propriedades da atividade Copy
Para obter uma lista completa de seções e propriedades disponíveis para definir atividades, consulte o artigo Pipelines . Esta seção fornece uma lista de propriedades suportadas pela fonte do Hive.
HiveSource como fonte
Para copiar dados do Hive, defina o tipo de origem na atividade de cópia como HiveSource. As seguintes propriedades são suportadas na seção de origem da atividade de cópia:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type da fonte de atividade de cópia deve ser definida como: HiveSource | Sim |
| query | Use a consulta SQL personalizada para ler dados. Por exemplo: "SELECT * FROM MyTable". |
Não (se "tableName" no conjunto de dados for especificado) |
Exemplo:
"activities":[
{
"name": "CopyFromHive",
"type": "Copy",
"inputs": [
{
"referenceName": "<Hive input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "HiveSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Mapeando propriedades de fluxo de dados
O conector hive é suportado como uma fonte de conjunto de dados embutido no mapeamento de fluxos de dados. Leia usando uma consulta ou diretamente de uma tabela do Hive no HDInsight. Os dados do Hive são preparados em uma conta de armazenamento como arquivos parquet antes de serem transformados como parte de um fluxo de dados.
Propriedades de origem
A tabela abaixo lista as propriedades suportadas por uma fonte de hive. Você pode editar essas propriedades na guia Opções de origem .
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script de fluxo de dados |
|---|---|---|---|---|
| Armazenamento | A loja deve ser hive |
sim | hive |
loja |
| Formato | Se você está lendo a partir de uma tabela ou consulta | sim | table ou query |
format |
| Nome do esquema | Se estiver lendo de uma tabela, o esquema da tabela de origem | Sim, se o formato for table |
String | schemaName |
| Nome da tabela | Se estiver lendo de uma tabela, o nome da tabela | Sim, se o formato for table |
String | tableName |
| Query | Se format for query, a consulta de origem no serviço vinculado do Hive |
Sim, se o formato for query |
String | query |
| Encenado | A mesa de colmeia será sempre encenada. | sim | true |
encenado |
| Contentor de Armazenamento | Recipiente de armazenamento usado para preparar dados antes de ler do Hive ou gravar no Hive. O cluster de hive deve ter acesso a esse contêiner. | sim | String | storageContainer |
| Banco de dados de preparo | O esquema/banco de dados ao qual a conta de usuário especificada no serviço vinculado tem acesso. Ele é usado para criar tabelas externas durante o preparo e descartado depois | não | true ou false |
stagingDatabaseName |
| Scripts pré-SQL | Código SQL a ser executado na tabela Hive antes de ler os dados | não | String | pré-SQLs |
Exemplo de fonte
Abaixo está um exemplo de uma configuração de origem do Hive:
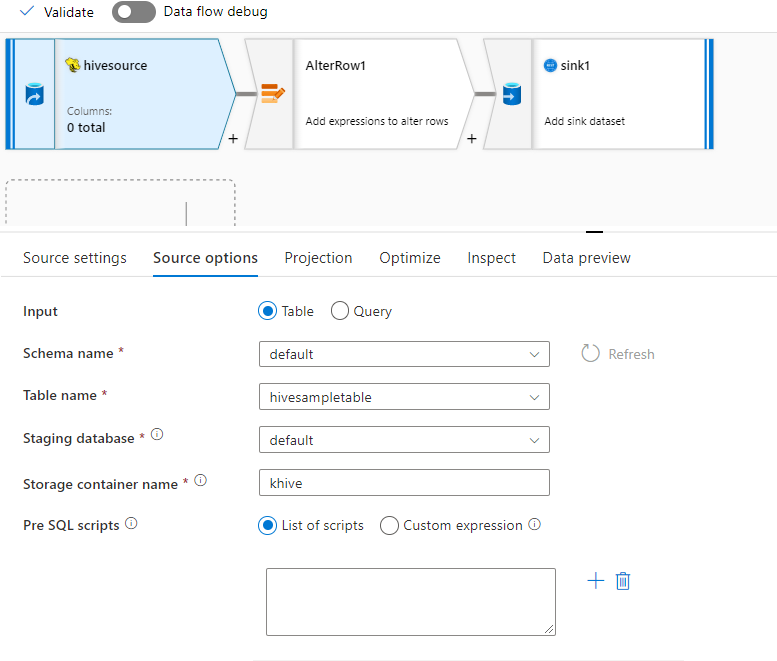
Essas configurações se traduzem no seguinte script de fluxo de dados:
source(
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
format: 'table',
store: 'hive',
schemaName: 'default',
tableName: 'hivesampletable',
staged: true,
storageContainer: 'khive',
storageFolderPath: '',
stagingDatabaseName: 'default') ~> hivesource
Limitações conhecidas
- Tipos complexos, como matrizes, mapas, estruturas e uniões não são suportados para leitura.
- O conector do Hive suporta apenas tabelas do Hive no Azure HDInsight da versão 4.0 ou superior (Apache Hive 3.1.0)
- Por padrão, o driver do Hive fornece "tableName.columnName" no coletor. Se você não deseja ver o nome da tabela no nome da coluna, então há duas maneiras de corrigir isso. a. Verifique a configuração "hive.resultset.use.unique.column.names" no lado do servidor Hive e defina-a como false. b. Use o mapeamento de coluna para renomear o nome da coluna.
Propriedades da atividade de pesquisa
Para saber detalhes sobre as propriedades, verifique Atividade de pesquisa.
Conteúdos relacionados
Para obter uma lista de armazenamentos de dados suportados como fontes e coletores pela atividade de cópia, consulte Armazenamentos de dados suportados.