Backups automatizados no Banco de Dados SQL do Azure
Aplica-se a:![]() do Banco de Dados SQL do Azure
do Banco de Dados SQL do Azure
Este artigo descreve o recurso de backup automatizado para o Banco de Dados SQL do Azure.
Para alterar as configurações de backup, consulte Alterar configurações. Para restaurar um backup, consulte Recuperar usando backups automatizados de banco de dados.
O que é um backup de banco de dados?
Os backups de banco de dados são uma parte essencial de qualquer estratégia de continuidade de negócios e recuperação de desastres, pois ajudam a proteger seus dados contra corrupção ou exclusão. Esses backups permitem a restauração do banco de dados para um ponto no tempo dentro do período de retenção configurado. Se as regras de proteção de dados exigirem que os backups estejam disponíveis por um período prolongado (até 10 anos), você poderá configurar de retenção de longo prazo (LTR) para bancos de dados únicos e em pool.
Para camadas de serviço diferentes da Hyperscale, o Banco de Dados SQL do Azure usa a tecnologia de mecanismo do SQL Server para fazer backup e restaurar dados. Os sistemas de bases de dados de hiperescala utilizam backup e restauração através de instantâneos de armazenamento . Com a tecnologia de backup tradicional do SQL Server, bancos de dados maiores têm longos tempos de backup/restauração. Com o uso de snapshots, o Hyperscale oferece backup instantâneo e recursos de restauração rápida, independentemente do tamanho do banco de dados. Para saber mais, consulte backups em hiperescala.
Frequência de backup
O Banco de Dados SQL do Azure cria:
- Backups completos todas as semanas.
- Backups diferenciais a cada 12 ou 24 horas.
- Os backups do log de transações aproximadamente a cada 10 minutos.
A frequência exata dos backups de log de transações é baseada no tamanho da computação e na quantidade de atividade do banco de dados. Quando você restaura um banco de dados, o serviço determina quais backups completos, diferenciais e de log de transações precisam ser restaurados.
A arquitetura Hyperscale não requer backups completos, diferenciais ou de log. Para saber mais, consulte backups em hiperescala.
Redundância de armazenamento de backup
O mecanismo de redundância de armazenamento armazena várias cópias de seus dados para que sejam protegidos contra eventos planejados e não planejados. Esses eventos podem incluir falhas transitórias de hardware, quedas de rede ou de energia ou desastres naturais maciços.
Por padrão, os novos bancos de dados no Banco de Dados SQL do Azure armazenam backups em blobs de armazenamento com redundância geográfica que são replicados para uma região emparelhada . A redundância geográfica ajuda a proteger contra interrupções que afetam o armazenamento de backup na região principal. Ele também permite que você restaure seus bancos de dados em uma região diferente no caso de uma interrupção regional.
O portal do Azure fornece uma opção de ambiente de carga de trabalho , que ajuda a predefinir algumas definições de configuração. Essas configurações podem ser substituídas. Esta opção aplica-se apenas à página Criar Base de Dados SQL portal.
- A escolha do ambiente de carga de trabalho de desenvolvimento define a opção de redundância de armazenamento de backup para usar armazenamento localmente redundante. O armazenamento com redundância local incorre em menos custos e é apropriado para ambientes de pré-produção que não exigem a redundância do armazenamento replicado por zona ou geograficamente.
- A escolha do ambiente de carga de trabalho de produção
define o de redundância de armazenamento de backup para armazenamento com redundância geográfica, o padrão. - A opção ambiente de carga de trabalho também altera a configuração inicial de cálculo, embora isso possa ser substituído. Caso contrário, a opção ambiente de carga de trabalho não terá impacto no licenciamento ou em outras definições de configuração do banco de dados.
Para garantir que os backups permaneçam na mesma região em que o banco de dados está implantado, você pode alterar a redundância do armazenamento de backup do armazenamento com redundância geográfica padrão para outros tipos de armazenamento que mantenham os dados dentro da região. A redundância de armazenamento de backup configurada é aplicada a backups de retenção de curto prazo (STR) e backups LTR. Para saber mais sobre redundância de armazenamento, consulte Redundância de dados.
Você pode configurar a redundância de armazenamento de backup ao criar seu banco de dados e atualizá-lo posteriormente. As alterações feitas em um banco de dados existente aplicam-se apenas a backups futuros. Depois de atualizar a redundância de armazenamento de backup de um banco de dados existente, as alterações podem levar até 48 horas para serem aplicadas.
Você pode escolher uma das seguintes redundâncias de armazenamento para backups:
Armazenamento com redundância local (LRS): copia seus backups de forma síncrona três vezes em um único local físico na região principal. O LRS é a opção de armazenamento menos dispendiosa, mas não o recomendamos para aplicações que exijam resiliência a interrupções regionais ou uma garantia de alta durabilidade dos dados.

de armazenamento com redundância de zona (ZRS): copia seus backups de forma síncrona em três zonas de disponibilidade do Azure na região primária. Atualmente, está disponível apenas em determinadas regiões.

de armazenamento com redundância geográfica (GRS): copia seus backups de forma síncrona três vezes em um único local físico na região principal usando o LRS. Em seguida, ele copia os seus dados de forma assíncrona três vezes para um único local físico na região secundária emparelhada
. O resultado é:
- Três cópias síncronas na região primária.
- Três cópias síncronas na região emparelhada que foram copiadas da região primária para a região secundária de forma assíncrona.

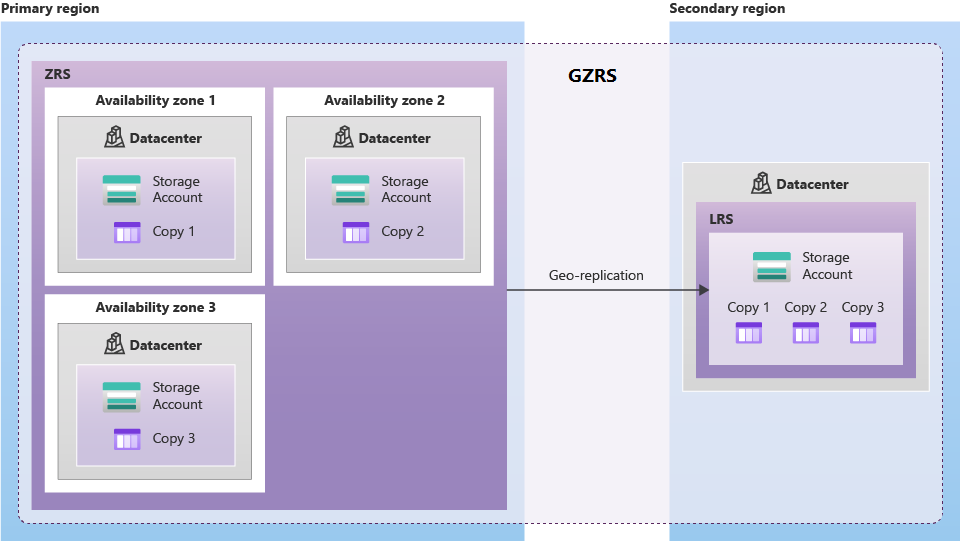
Geo-Zone armazenamento redundante (GZRS): o armazenamento com redundância de zona geográfica (GZRS) combina a alta disponibilidade fornecida pela redundância entre zonas de disponibilidade (ZRS) com a proteção contra interrupções regionais fornecidas pela replicação geográfica (GRS). Copia seus backups de forma síncrona em três zonas de disponibilidade do Azure na região primária e de forma assíncrona três vezes em um único local físico na região secundária emparelhada .
A Microsoft recomenda o uso do GZRS para aplicativos que exigem consistência, durabilidade e disponibilidade máximas, excelente desempenho e resiliência para recuperação de desastres.
O resultado é:
Três cópias síncronas em zonas de disponibilidade, na região primária.
Três cópias síncronas na região emparelhada, copiadas de forma assíncrona da região primária para a região secundária.
O diagrama a seguir mostra como seus dados são replicados com GZRS ou RA-GZRS:
Advertência
- A restauração geográfica é desabilitada assim que um banco de dados é atualizado para usar armazenamento localmente redundante ou com redundância de zona.
- Todos os diagramas de redundância de armazenamento mostram regiões com várias zonas de disponibilidade (multi-az). No entanto, existem algumas regiões que fornecem apenas uma única zona de disponibilidade e não suportam ZRS.
- A redundância de armazenamento de backup para bancos de dados Hyperscale pode ser definida somente durante a criação. Não é possível modificar essa configuração depois que o recurso é provisionado. Para atualizar as configurações de redundância de armazenamento de backup para um banco de dados Hyperscale existente com o mínimo de tempo de inatividade, use a replicação geográfica ativa . Como alternativa, pode usar a cópia de base de dados . Saiba mais em sobre backups em hiperescala e emsobre redundância de armazenamento.
Uso de backup
Você pode usar backups criados automaticamente nos seguintes cenários:
Restaure um banco de dados existente para um ponto no tempo dentro do período de retenção usando o portal Azure, o Azure PowerShell, a CLI do Azure ou a API REST. Essa operação cria um novo banco de dados no mesmo servidor que o banco de dados original, mas usa um nome diferente para evitar a substituição do banco de dados original.
Após a conclusão da restauração, você pode, opcionalmente, excluir o banco de dados original e renomear o banco de dados restaurado para o nome do banco de dados original. Como alternativa, em vez de excluir o banco de dados original, você pode renomeá-lo e, em seguida, renomear o banco de dados restaurado para o nome do banco de dados original.
Restaure uma base de dados eliminada para um momento específico dentro do período de retenção, incluindo o tempo de eliminação. O banco de dados excluído pode ser restaurado somente no mesmo servidor em que você criou o banco de dados original. Antes de excluir um banco de dados, o serviço faz um backup final do log de transações para evitar qualquer perda de dados.
Restaurar um banco de dados para outra região geográfica. A restauração geográfica permite que você se recupere de uma interrupção regional quando não é possível acessar seu banco de dados ou backups na região principal. Ele cria um novo banco de dados em qualquer servidor existente em qualquer região do Azure.
Importante
A restauração geográfica está disponível apenas para bancos de dados configurados com armazenamento de backup com redundância geográfica. Se você não estiver usando backups replicados geograficamente para um banco de dados, poderá alterar isso configurando a redundância de armazenamento de backup.
Restaure um banco de dados a partir de um de backup de longo prazo específico de um banco de dados único ou em pool, se o banco de dados tiver sido configurado com uma política LTR. O LTR permite que você restaure uma versão mais antiga do banco de dados usando o portal do Azure, a CLI do Azure ou o Azure PowerShell para satisfazer uma solicitação de conformidade ou executar uma versão mais antiga do aplicativo. Para obter mais informações, consulte retenção de longo prazo.
Advertência
Ao restaurar um banco de dados e a redundância de armazenamento de backup de origem é configurada como Geo-Zone GZRS (armazenamento redundante), a configuração de armazenamento de backup de origem é herdada pelo novo banco de dados se a configuração de redundância de armazenamento de backup para o banco de dados de destino não for especificada explicitamente. Isso inclui qualquer operação de restauração, como restauração a um momento específico, cópia de base de dados, restauração geo-localizada, de um backup de longo prazo. Durante esta operação, se a região do Azure de destino não suportar a redundância de armazenamento de backup específica, a operação de restauração falhará com a mensagem de erro apropriada. Isso pode ser atenuado especificando explicitamente as opções de armazenamento disponíveis para a região.
Backups automáticos em réplicas secundárias
Os backups automáticos agora são realizados a partir de uma réplica secundária no nível de serviço Business Critical. Como os dados são replicados entre processos do SQL Server em cada nó, o serviço de backup obtém o backup das réplicas secundárias não legíveis. Este design garante que a réplica primária permaneça dedicada à sua carga de trabalho principal e que a réplica secundária legível esteja dedicada a cargas de trabalho de leitura. Os backups automáticos na camada de serviço Business Critical são geralmente obtidos de uma réplica secundária. Se um backup automático falhar em uma réplica secundária, o serviço de backup tirará o backup da réplica primária.
Backups automáticos em réplicas secundárias:
- Estão habilitados por padrão.
- Estão incluídos sem custo adicional além do preço do nível de serviço.
- Traga melhor desempenho e previsibilidade para a camada de serviço crítica para os negócios.
Observação
- Crie um pedido de suporte da Microsoft para desativar a funcionalidade para a sua instância.
Recursos e funcionalidades de restauro
Esta tabela resume as capacidades e características da restauração point-in-time (PITR) , da restauração geográfica e da retenção de longo prazo .
Para obter informações sobre tempos de recuperação, consulte RTO e RPO.
1 Para aplicativos críticos para os negócios que exigem grandes bancos de dados e devem garantir a continuidade dos negócios, use grupos de failover.
2 Todos os backups PITR são armazenados em armazenamento com redundância geográfica por padrão, portanto, a restauração geográfica é habilitada por padrão.
3 Uma solução alternativa é restaurar para um novo servidor e usar o Resource Move para mover o servidor para outra assinatura, ou usar uma cópia de banco de dados entre assinaturas .
Restaurar um banco de dados a partir do backup
Para executar uma restauração, consulte Restaurar um banco de dados a partir de backups. Você pode explorar a configuração de backup e as operações de restauração usando os exemplos a seguir.
| Funcionamento | Portal do Azure | Azure CLI | Azure PowerShell |
|---|---|---|---|
| Alterar a retenção de backup |
Base de Dados SQL Instância Gerenciada SQL |
Base de Dados SQL Instância Gerenciada SQL |
Base de Dados SQL Instância Gerenciada SQL |
| Alterar a retenção de backup de longo prazo |
Base de Dados SQL Instância Gerenciada SQL |
Base de Dados SQL Instância Gerenciada SQL |
Base de Dados SQL Instância Gerenciada SQL |
| Restaurar um banco de dados a partir de um momento específico |
Base de Dados SQL Instância Gerenciada SQL |
Base de Dados SQL Instância Gerenciada SQL |
Base de Dados SQL Instância Gerenciada SQL |
| Restaurar um banco de dados excluído |
Base de Dados SQL Instância Gerenciada SQL |
Base de Dados SQL Instância Gerenciada SQL |
Base de Dados SQL Instância Gerenciada SQL |
Exportar um banco de dados
Os backups automáticos feitos pelo serviço do Azure não estão disponíveis para download ou acesso direto. Eles só podem ser usados para operações de restauração por meio do Azure.
Há alternativas para exportar um Banco de Dados SQL do Azure. Quando precisar exportar um banco de dados para arquivamento ou para mover para outra plataforma, você
Você também pode importar ou exportar um Banco de Dados SQL do Azure usando ligação privada ou importar ou exportar um Banco de Dados SQL do Azure sem permitir que os serviços do Azure tenham acesso ao servidor.
Agendamento de backup
O primeiro backup completo é agendado imediatamente após a criação ou restauração de um novo banco de dados. Esse backup geralmente termina em 30 minutos, mas pode levar mais tempo quando o banco de dados é grande. Por exemplo, o backup inicial pode levar mais tempo em um banco de dados restaurado ou em uma cópia de banco de dados, que normalmente seria maior do que um novo banco de dados.
Após o primeiro backup completo, todos os backups adicionais são agendados e gerenciados automaticamente. O tempo exato de todos os backups de banco de dados é determinado pelo serviço Banco de dados SQL, pois equilibra a carga de trabalho geral do sistema. Não é possível alterar o agendamento de trabalhos de backup ou desativá-los.
Importante
- Para um banco de dados novo, restaurado ou copiado, o recurso de restauração num ponto no tempo torna-se disponível quando o backup inicial do log de transações que segue o backup completo inicial for criado.
- Os bancos de dados de hiperescala são protegidos imediatamente após a criação, ao contrário de outros bancos de dados em que o backup inicial leva tempo. A proteção é imediata, mesmo que o banco de dados Hyperscale tenha sido criado com uma grande quantidade de dados via cópia ou restauração. Para saber mais, consulte de backups automatizados do Hyperscale .
Consumo de armazenamento de backup
Com a tecnologia de backup e restauração do SQL Server, a restauração de um banco de dados para um point-in-time requer uma cadeia de backup ininterrupta. Essa cadeia consiste em um backup completo, opcionalmente um backup diferencial e um ou mais backups de log de transações.
O Banco de Dados SQL do Azure agenda um backup completo por semana. Para fornecer PITR durante todo o período de retenção, o sistema deve armazenar backups adicionais completos, diferenciais e de log de transações por até uma semana a mais do que o período de retenção configurado.
Em outras palavras, para qualquer ponto no tempo durante o período de retenção, deve haver um backup completo mais antigo do que o tempo mais antigo do período de retenção. Também deve haver uma cadeia ininterrupta de backups diferenciais e de log de transações desde esse backup completo até o próximo backup completo.
Os bancos de dados de hiperescala usam um mecanismo de agendamento de backup diferente. Para mais informações, consulte a programação de backup em hiperescala.
Os backups que não são mais necessários para fornecer a funcionalidade PITR são excluídos automaticamente. Como os backups diferenciais e os backups de log exigem um backup completo anterior para serem restaurados, todos os três tipos de backup são eliminados juntos em conjuntos semanais.
Para todos os bancos de dados, incluindo bancos de dados criptografados TDE, todos os backups completos e diferenciais são compactados para reduzir a compactação e os custos do armazenamento de backup. A taxa média de compactação de backup é de 3 a 4 vezes. No entanto, pode ser menor ou maior, dependendo da natureza dos dados e se a compactação de dados é usada no banco de dados.
Importante
Para bancos de dados criptografados por TDE, os arquivos de backup de log não são compactados por motivos de desempenho. Os backups de log para bancos de dados não criptografados por TDE são compactados.
O Banco de Dados SQL do Azure calcula seu armazenamento de backup total usado como um valor cumulativo. A cada hora, esse valor é relatado para o pipeline de cobrança do Azure. O pipeline é responsável por agregar esse uso horário para calcular seu consumo no final de cada mês. Depois que o banco de dados é excluído, o consumo diminui à medida que os backups envelhecem e são excluídos. Depois que todos os backups são excluídos e o PITR não é mais possível, o faturamento é interrompido.
Importante
Os backups de um banco de dados são mantidos para fornecer PITR mesmo que o banco de dados tenha sido excluído. Embora excluir e recriar um banco de dados possa economizar custos de armazenamento e computação, isso pode aumentar os custos de armazenamento de backup. O motivo é que o serviço retém backups para cada banco de dados excluído, toda vez que ele é excluído.
Monitorize o consumo
Para bancos de dados vCore no Banco de Dados SQL do Azure, o armazenamento que cada tipo de backup (completo, diferencial e log) consome é relatado no painel de monitoramento de banco de dados como uma métrica separada. A captura de tela a seguir mostra como monitorar o consumo de armazenamento de backup para um único banco de dados.

Para obter instruções sobre como monitorar o consumo no Hyperscale, consulte Monitorar o consumo de backup do Hyperscale.
Ajuste o consumo de armazenamento de backup
O consumo de armazenamento de backup até ao tamanho máximo de dados de um banco de dados não é cobrado. O consumo excessivo de armazenamento de backup depende da carga de trabalho e do tamanho máximo dos bancos de dados individuais. Considere algumas das seguintes técnicas de ajuste para reduzir o consumo de armazenamento de backup:
- Reduza o período de retenção de backup ao mínimo para suas necessidades.
- Evite fazer grandes operações de gravação, como reconstruções de índice, com mais frequência do que o necessário.
- Para operações de carregamento de dados grandes, considere usar índices columnstore clusterizados e seguir as práticas recomendadas de relacionadas. Considere também reduzir o número de índices não agrupados.
- No nível de serviço de uso geral, o armazenamento de dados provisionado é mais barato do que o preço do armazenamento de backup. Se você tiver custos de armazenamento de backup em excesso continuamente altos, considere aumentar o armazenamento de dados para economizar no armazenamento de backup.
- Use
tempdbem vez de tabelas permanentes na lógica do aplicativo para armazenar resultados temporários ou dados transitórios. - Use armazenamento de backup localmente redundante sempre que possível (por exemplo, ambientes de desenvolvimento/teste).
Retenção de backup
O Banco de Dados SQL do Azure fornece retenção de backups de curto e longo prazo. A retenção de curto prazo permite o PITR dentro do período de retenção para o banco de dados. A retenção de longo prazo fornece backups para vários requisitos de conformidade.
Retenção a curto prazo
Para todos os bancos de dados novos, restaurados e copiados, o Banco de Dados SQL do Azure retém backups suficientes para permitir o PITR nos últimos 7 dias por padrão. O serviço realiza backups completos, diferenciais e de log regulares para garantir que as bases de dados sejam restauráveis em qualquer momento específico dentro do período de retenção definido para a base de dados.
Os backups diferenciais podem ser configurados para ocorrer uma vez em 12 horas ou uma vez em 24 horas. Uma frequência de backup diferencial de 24 horas pode aumentar o tempo necessário para restaurar o banco de dados, em comparação com a frequência de 12 horas. No modelo vCore, a frequência padrão para backups diferenciais é uma vez a cada 12 horas. No modelo DTU, a frequência padrão é uma vez em 24 horas.
Você pode especificar a opção de redundância de armazenamento de backup para STR ao criar seu banco de dados e, em seguida, alterá-la posteriormente. Se você alterar a opção de redundância de backup após a criação do banco de dados, os novos backups usarão a nova opção de redundância. As cópias de backup feitas com a opção de redundância STR anterior não são movidas ou copiadas. Eles são deixados na conta de armazenamento original até que o período de retenção expire, que pode ser de 1 a 35 dias.
Você pode alterar o período de retenção de backup para cada banco de dados ativo no intervalo de 1 a 35 dias, exceto para bancos de dados básicos, que são configuráveis de 1 a 7 dias. Conforme descrito em consumo de armazenamento de backup, os backups armazenados para habilitar o PITR podem ser mais antigos do que o período de retenção. Se precisar manter backups por mais tempo do que o período máximo de retenção a curto prazo de 35 dias, pode habilitar a retenção a longo prazo.
Se você excluir um banco de dados, o sistema manterá backups da mesma forma para um banco de dados on-line com seu período de retenção específico. Não é possível alterar o período de retenção de backup de um banco de dados excluído.
Importante
Se você excluir um servidor, todos os bancos de dados desse servidor também serão excluídos e não poderão ser recuperados. Não é possível restaurar um servidor excluído. Mas se você configurou a retenção de longo prazo para um banco de dados, os backups LTR não serão excluídos. Em seguida, você pode usar esses backups para restaurar bancos de dados em um servidor diferente na mesma assinatura, até um ponto no tempo em que um backup LTR foi feito. Para saber mais, consulte Restaurar backup de longo prazo.
Retenção a longo prazo
Para o Banco de Dados SQL, você pode configurar backups completos de retenção de longo prazo (LTR) por até 10 anos no Armazenamento de Blobs do Azure. Depois que a política LTR é configurada, os backups completos são copiados automaticamente para um contêiner de armazenamento diferente semanalmente.
Para atender a vários requisitos de conformidade, você pode selecionar diferentes períodos de retenção para backups completos semanais, mensais e/ou anuais. A frequência depende da política. Por exemplo, definir W=0, M=1 criaria uma cópia LTR mensalmente. Para obter mais informações sobre a retenção de longo prazo (LTR), consulte .
A atualização da redundância de armazenamento de backup para um banco de dados existente aplica a alteração somente aos backups subsequentes feitos no futuro e não aos backups existentes. Todos os backups LTR existentes para o banco de dados continuam a residir no blob de armazenamento existente. Novos backups são replicados com base na redundância de armazenamento de backup configurada.
O consumo de armazenamento depende da frequência e dos períodos de retenção selecionados dos backups LTR. Você pode usar a calculadora de preços LTR para estimar o custo do armazenamento LTR.
Ao restaurar um banco de dados Hyperscale a partir de um backup LTR, a propriedade de escala de leitura é desabilitada. Para habilitar a escala de leitura no banco de dados restaurado, atualize o banco de dados depois que ele tiver sido criado. Você precisa especificar o nível de serviço desejado ao restaurar a partir de um backup LTR.
A retenção de longo prazo pode ser habilitada para bancos de dados Hyperscale criados ou migrados de outras camadas de serviço. Se você tentar habilitar o LTR para um banco de dados Hyperscale onde ele ainda não é suportado, você receberá o seguinte erro: "Ocorreu um erro ao habilitar a retenção de backup de longo prazo para este banco de dados. Entre em contato com o suporte da Microsoft para habilitar a retenção de backup de longo prazo." Nesse caso, entre em contato com o suporte da Microsoft e crie um tíquete de suporte para resolver.
Custos de armazenamento de backup
O preço do armazenamento de backup varia e depende do seu modelo de compra de (DTU ou vCore), da opção de redundância de armazenamento de backup escolhida e da região. O armazenamento de backup é cobrado com base nos gigabytes consumidos por mês, com a mesma taxa para todos os backups.
Para obter preços, consulte a página de preços do Banco de Dados SQL do Azure.
Observação
Uma fatura do Azure mostra apenas o consumo excessivo de armazenamento de backup, não todo o consumo de armazenamento de backup. Por exemplo, em um cenário hipotético, se você tiver provisionado 4 TB de armazenamento de dados, obterá 4 TB de espaço livre de armazenamento de backup. Se você usar um total de 5,8 TB de espaço de armazenamento de backup, a fatura do Azure mostrará apenas 1,8 TB, porque você será cobrado apenas pelo excesso de armazenamento de backup usado.
Modelo DTU
No modelo DTU, para bancos de dados e pools elásticos, não há cobrança adicional para armazenamento de backup PITR para retenção padrão de 7 dias ou mais. O preço do armazenamento de backup PITR faz parte do preço do banco de dados ou do pool.
Importante
No modelo DTU, bancos de dados e pools elásticos são cobrados pelo backup armazenamento LTR com base no armazenamento real consumido pelos backups LTR.
Modelo vCore
A Base de Dados SQL do Azure calcula o seu armazenamento de backup total faturável como um valor cumulativo através de todos os ficheiros de backup. A cada hora, esse valor é relatado para o pipeline de cobrança do Azure. O pipeline agrega esse uso por hora para obter o consumo de armazenamento de backup no final de cada mês.
Se um banco de dados for excluído, o consumo de armazenamento de backup diminuirá gradualmente à medida que os backups mais antigos envelhecerem e forem excluídos. Como os backups diferenciais e os backups de log exigem um backup completo anterior para serem restaurados, todos os três tipos de backup são eliminados juntos em conjuntos semanais. Depois que todos os backups são excluídos, o faturamento é interrompido.
O custo do armazenamento de backup é calculado de forma diferente para bancos de dados Hyperscale. Para obter mais informações, consulte Custos de armazenamento de backup em hiperescala.
Para bancos de dados únicos, uma quantidade de armazenamento de backup igual a 100% do tamanho máximo de armazenamento de dados para o banco de dados é fornecida sem custo extra. A equação a seguir é usada para calcular o uso total do armazenamento de backup faturável:
Total billable backup storage size = (size of full backups + size of differential backups + size of log backups) – maximum data storage
Para pools elásticos, uma quantidade de armazenamento de backup igual a 100% do armazenamento máximo de dados para o tamanho de armazenamento do pool é fornecida sem custo adicional. Para bancos de dados em pool, o tamanho total do armazenamento de backup faturável é agregado no nível do pool e calculado da seguinte forma:
Total billable backup storage size = (total size of all full backups + total size of all differential backups + total size of all log backups) - maximum pool data storage
O armazenamento total de backup faturável, se houver, é cobrado em gigabytes por mês de acordo com a taxa de redundância de armazenamento de backup que você usou. Esse consumo de armazenamento de backup depende da carga de trabalho e do tamanho de bancos de dados individuais, pools elásticos e instâncias gerenciadas. Bancos de dados fortemente modificados têm backups diferenciais e de log maiores, porque o tamanho desses backups é proporcional à quantidade de dados alterados. Portanto, esses bancos de dados têm taxas de backup mais altas.
Como um exemplo simplificado, suponha que um banco de dados acumulou 744 GB de armazenamento de backup e que essa quantidade permanece constante durante um mês inteiro porque o banco de dados está completamente ocioso. Para converter esse consumo acumulado de armazenamento em uso por hora, divida-o por 744,0 (31 dias por mês vezes 24 horas por dia). O Banco de Dados SQL relata ao pipeline de cobrança do Azure que o banco de dados consumiu 1 GB de backup PITR a cada hora, a uma taxa constante. A faturação do Azure agrega este consumo e mostra uma utilização de 744 GB durante todo o mês. O custo é baseado na taxa de gigabytes por mês na sua região.
Aqui está outro exemplo. Suponha que o mesmo banco de dados ocioso tenha sua retenção aumentada de 7 dias para 14 dias no meio do mês. Esse aumento faz com que o armazenamento total de backup duplique para 1.488 GB. O Banco de dados SQL relataria 1 GB de uso por horas de 1 a 372 (a primeira quinzena do mês). Ele relataria o uso como 2 GB por horas 373 a 744 (a segunda metade do mês). Esse uso seria agregado a uma conta final de 1.116 GB por mês.
Os cenários reais de faturamento de backup são mais complexos. Como a taxa de alterações no banco de dados depende da carga de trabalho e é variável ao longo do tempo, o tamanho de cada backup diferencial e de log também varia. O consumo horário do armazenamento de backup varia em conformidade.
Cada backup diferencial também contém todas as alterações feitas no banco de dados desde o último backup completo. Assim, o tamanho total de todos os backups diferenciais aumenta gradualmente ao longo de uma semana. Em seguida, diminui acentuadamente depois que um conjunto antigo de backups completos, diferenciais e de log expira.
Por exemplo, suponha que uma atividade de gravação pesada, como uma reconstrução de índice, seja executada logo após a conclusão de um backup completo. As modificações que a reconstrução do índice faz serão então incluídas:
- Nos backups do log de transações realizados durante o tempo da reconstrução.
- No próximo backup diferencial.
- Em todos os backups diferenciais realizados até que ocorra o próximo backup completo.
Para o último cenário em bases de dados maiores, uma otimização no serviço cria um backup completo em vez de um backup diferencial, caso contrário, um backup diferencial seria excessivamente grande. Isso reduz o tamanho de todos os backups diferenciais até o seguinte backup completo.
Você pode monitorar o consumo total de armazenamento de backup para cada tipo de backup (completo, diferencial, log de transações) ao longo do tempo, conforme descrito em Monitorar o consumo.
Monitorizar os custos
Para entender os custos de armazenamento de backup, vá para Gerenciamento de Custos + Cobrança no portal do Azure. Selecione Gestão de Custose, em seguida, selecione Análise de Custos. Selecione a subscrição pretendida para Âmbitoe, em seguida, filtre o período de tempo e o serviço em que está interessado da seguinte forma:
Adicione um filtro para Nome do serviço.
Na lista suspensa, selecione base de dados SQL para uma única base de dados ou um grupo de bases de dados elásticas.
Adicione outro filtro para a subcategoria Medidor .
Para monitorizar os custos de backup do PITR, na lista suspensa, selecione armazenamento de backup PITR para pool único/elástico para um único banco de dados ou um pool de banco de dados elástico. Os medidores aparecem apenas caso haja utilização do armazenamento de backup.
Para monitorizar os custos de backup de LTR, na lista suspensa, selecione armazenamento de backup de LTR para uma única base de dados ou um pool de bases de dados elástico. Os medidores aparecem apenas caso haja utilização do armazenamento de backup.
As subcategorias Storage e compute também podem interessá-lo, mas não estão associadas aos custos de armazenamento de backup.

Importante
Os medidores são visíveis apenas para contadores que estão atualmente em uso. Se um contador não estiver disponível, é provável que a categoria não esteja sendo usada no momento. Por exemplo, os contadores de armazenamento não estarão visíveis para recursos que não estão consumindo armazenamento. Se não houver consumo de armazenamento de backup PITR ou LTR, esses medidores não serão visíveis.
Para obter mais informações, consulte gerenciamento de custos do Banco de Dados SQL do Azure.
Backups criptografados
Se o seu banco de dados for criptografado com TDE, os backups serão automaticamente criptografados em repouso, incluindo backups LTR. Todos os novos bancos de dados no SQL do Azure são configurados com TDE habilitado por padrão. Para obter mais informações sobre TDE, consulte Criptografia de dados transparente com SQL Database.
Integridade do backup
Continuamente, a equipe de engenharia do SQL do Azure testa automaticamente a restauração de backups automatizados de banco de dados. Após a restauração para um ponto específico no tempo, os bancos de dados também recebem verificações de integridade DBCC CHECKDB.
Qualquer problema encontrado durante uma verificação de integridade resulta em um alerta para a equipe de engenharia. Para obter mais informações, consulte integridade de dados na Base de dados SQL.
Todos os backups de banco de dados são feitos com a opção CHECKSUM para fornecer integridade de backup adicional.
Conformidade
Quando você migra seu banco de dados de uma camada de serviço baseada em DTU para uma camada de serviço baseada em vCore, a retenção PITR é preservada para garantir que a política de recuperação de dados do seu aplicativo não seja comprometida. Se a retenção padrão não atender aos seus requisitos de conformidade, você poderá alterar o período de retenção PITR. Para obter mais informações, consulte Alterar o período de retenção de backup do PITR.
Observação
O artigo
Usar a Política do Azure para impor redundância de armazenamento de backup
Se você tiver requisitos de residência de dados que exijam que você mantenha todos os seus dados em uma única região do Azure, convém impor backups redundantes de zona ou localmente redundantes para seu banco de dados SQL usando a Política do Azure.
O Azure Policy é um serviço que você pode usar para criar, atribuir e gerenciar políticas que aplicam regras aos recursos do Azure. O Azure Policy ajuda-o a manter estes recursos em conformidade com os seus padrões empresariais e contratos de nível de serviço. Para obter mais informações, consulte Visão geral do Azure Policy.
Políticas embutidas de redundância de armazenamento de backup
Para impor requisitos de residência de dados em um nível organizacional, você pode atribuir políticas a uma assinatura usando o portal do Azure ou Azure PowerShell.
Por exemplo, se você habilitar a política "O Banco de Dados SQL do Azure deve evitar o uso do backup GRS", os bancos de dados não poderão ser criados com o armazenamento padrão como armazenamento globalmente redundante e os usuários serão impedidos de usar o GRS com a mensagem de erro "Falha ao configurar o tipo de conta de armazenamento de backup para 'Standard_RAGRS' durante a criação ou atualização do Banco de Dados".
Para obter uma lista completa das definições de política incorporadas para a base de dados SQL, consulte a referência de política.
Importante
As políticas do Azure não são impostas quando você cria um banco de dados via T-SQL. Para especificar a residência de dados ao criar um banco de dados usando T-SQL, use LOCAL ou ZONE como entrada para o parâmetro BACKUP_STORAGE_REDUNDANCY na instrução CREATE DATABASE.
Conteúdo relacionado
- Para saber mais sobre outras soluções de continuidade de negócios do Banco de dados SQL, consulte Visão geral da continuidade de negócios.
- Para alterar as configurações de backup, consulte Alterar configurações.
- Para restaurar um backup, consulte Recuperar usando backups ou Restaurar um banco de dados para um ponto no tempo usando o PowerShell.
- Para obter informações sobre como configurar, gerenciar e restaurar a partir da retenção de longo prazo de backups automatizados no Armazenamento de Blobs do Azure, consulte Gerenciar retenção de backup de longo prazo.
- Para Instância Gerenciada SQL do Azure, consulte Backups automatizados para Instância Gerenciada SQL.