Índices Columnstore: Visão geral
Aplica-se a:![]() SQL Server
SQL Server![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure![]() Instância Gerenciada SQL do Azure
Instância Gerenciada SQL do Azure![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)![]() Banco de Dados SQL no Microsoft Fabric
Banco de Dados SQL no Microsoft Fabric
Os índices Columnstore são o padrão para armazenar e consultar tabelas de fatos em grandes sistemas de armazenamento de dados. Esse índice usa armazenamento de dados baseado em colunas e processamento de consultas para obter ganhos de até 10 vezes o desempenho da consulta em seu data warehouse em relação ao armazenamento tradicional orientado a linhas. Você também pode obter ganhos de até 10 vezes a compactação de dados em relação ao tamanho de dados não compactados. A partir do SQL Server 2016 (13.x) SP1, os índices columnstore permitem análises operacionais: a capacidade de executar análises de desempenho em tempo real em uma carga de trabalho transacional.
Saiba mais sobre um cenário relacionado:
- índices Columnstore em data warehousing
- Introdução ao columnstore para análise operacional em tempo real
O que é um índice columnstore?
Um índice de armazenamento em colunas é uma tecnologia para armazenar, recuperar e gerir dados usando um formato de dados colunar, chamado columnstore.
Palavras-chave e conceitos
Os seguintes termos-chave e conceitos estão relacionados com índices columnstore.
Armazenamento em colunas
Um columnstore é um conjunto de dados organizados logicamente como uma tabela com linhas e colunas, e armazenado fisicamente num formato de dados em colunas.
Armazenamento em Linha
Um armazenamento de linhas é um conjunto de dados organizados logicamente como uma tabela com linhas e colunas e armazenados fisicamente em um formato de dados por linha. Esse formato é a maneira tradicional de armazenar dados de tabelas relacionais. No SQL Server, rowstore refere-se a uma tabela em que o formato de armazenamento de dados subjacente é um heap, um índice clusterizado ou uma tabela com otimização de memória.
Observação
Nas discussões sobre índices columnstore, os termos rowstore e columnstore são usados para enfatizar o formato do armazenamento de dados.
Grupo de linhas
Um rowgroup é um agregado de linhas que são compactadas no formato columnstore ao mesmo tempo. Um grupo de linhas geralmente contém o número máximo de linhas por grupo de linhas, que é de 1.048.576 linhas.
Para alto desempenho e altas taxas de compactação, o índice columnstore divide a tabela em rowgroups e, em seguida, compacta cada rowgroup de maneira por coluna. O número de linhas no rowgroup deve ser grande o suficiente para melhorar as taxas de compressão e pequeno o suficiente para se beneficiar de operações em memória.
Um grupo de linhas de onde todos os dados foram excluídos transita do estado COMPRESSED para o estado TOMBSTONE e, posteriormente, é removido por um processo em segundo plano chamado tuple-mover. Para obter mais informações sobre os estados do grupo de linhas, consulte sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Dica
Ter muitos grupos de linhas pequenos diminui a qualidade do índice columnstore. Até o SQL Server 2017 (14.x), uma operação de reorganização é necessária para mesclar grupos de linhas COMPRESSED menores, seguindo uma política de limite interno que determina como remover linhas excluídas e combinar os grupos de linhas compactados.
A partir do SQL Server 2019 (15.x), uma tarefa de mesclagem em segundo plano também funciona para mesclar grupos de linhas COMPACTADOS de onde um grande número de linhas foi excluído.
Depois de mesclar grupos de linhas menores, a qualidade do índice deve ser melhorada.
Observação
A partir do SQL Server 2019 (15.x), do Banco de Dados SQL do Azure, da Instância Gerenciada SQL do Azure e de pools SQL dedicados no Azure Synapse Analytics, o tuple-mover é ajudado por uma tarefa de mesclagem em segundo plano que compacta automaticamente grupos de linhas delta OPEN menores que existem há algum tempo, conforme determinado por um limite interno, ou mescla grupos de linhas COMPACTADOS de onde um grande número de linhas foi excluído. Isso melhora a qualidade do índice columnstore ao longo do tempo.
Segmento da coluna
Um segmento de coluna é uma coluna de dados de dentro do grupo de linhas.
- Cada grupo de linhas contém um segmento de coluna para cada coluna da tabela.
- Cada segmento de coluna é compactado em conjunto e armazenado em mídia física.
- Há metadados com cada segmento para permitir a eliminação rápida de segmentos sem lê-los.
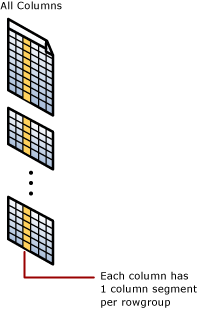
Índice columnstore agrupado
Um índice columnstore clusterizado representa o armazenamento físico de toda a tabela.
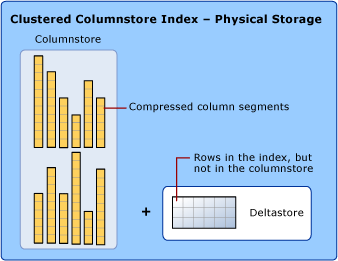
Para reduzir a fragmentação dos segmentos de coluna e melhorar o desempenho, o índice columnstore pode armazenar alguns dados temporariamente em um índice clusterizado chamado deltastore e uma lista de árvore B de IDs para linhas excluídas. As operações da deltastore são geridas nos bastidores. Para retornar os resultados corretos da consulta, o índice columnstore clusterizado combina os resultados da consulta do columnstore e do deltastore.
Observação
A documentação usa o termo árvore B geralmente em referência a índices. Em índices de armazenamento de linha, o Mecanismo de Banco de Dados implementa uma árvore B+. Isto não se aplica a índices em columnstore ou a índices em tabelas otimizadas para memória. Para obter mais informações, consulte o guia de arquitetura e design de índices do SQL Server e Azure SQL .
Grupo de linhas Delta
Um grupo de linhas delta é um índice de árvore B clusterizado que é usado apenas com índices columnstore. Ele melhora a compactação e o desempenho do armazenamento em coluna armazenando linhas até que o número de linhas atinja um limite de 1.048.576, momento em que são então movidas para o armazenamento em coluna.
Quando um grupo de linhas delta atinge o número máximo de linhas, ele passa de um estado OPEN para CLOSED. Um processo em segundo plano chamado tuple-mover verifica grupos de linhas fechadas. Se o processo encontrar um grupo de linhas fechado, ele compacta o grupo de linhas delta e o armazena no columnstore como um grupo de linhas COMPACTADO.
Quando um grupo de linhas delta é compactado, o grupo de linhas delta existente transita para o estado TOMBSTONE para ser removido posteriormente pelo tuple-mover quando já não há referências a ele.
Para obter mais informações sobre os status do grupo de linhas, consulte sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Observação
A partir do SQL Server 2019 (15.x), o tuple-mover é ajudado por uma tarefa de mesclagem em segundo plano que compacta automaticamente grupos de linhas delta OPEN menores que existem há algum tempo, conforme determinado por um limite interno, ou mescla grupos de linhas COMPACTADAS de onde um grande número de linhas foi excluído. Isso melhora a qualidade do índice columnstore ao longo do tempo.
Deltastore
Um índice columnstore pode ter mais de um grupo de linhas delta. Todos os grupos de linhas delta são chamados coletivamente de deltastore.
Durante uma carga em massa, a maioria das linhas vai diretamente para o columnstore sem passar pelo deltastore. Algumas linhas no final da carga em massa podem ser muito poucas em número para atender ao tamanho mínimo de um grupo de linhas, que é de 102.400 linhas. Como resultado, as linhas finais vão para o deltastore, em vez do columnstore. Para pequenas cargas a granel com menos de 102.400 linhas, todas as linhas vão diretamente para o deltastore.
Índice columnstore não clusterizado
Um índice de armazenamento em colunas não clusterizado e um índice de armazenamento em colunas clusterizado funcionam da mesma maneira. A diferença é que um índice não clusterizado é um índice secundário criado em uma tabela rowstore, mas um índice columnstore clusterizado é o armazenamento primário para toda a tabela.
O índice não clusterizado contém uma cópia de parte ou de todas as linhas e colunas na tabela subjacente. O índice é definido como uma ou mais colunas da tabela e tem uma condição opcional que filtra as linhas.
Um índice columnstore não clusterizado permite análises operacionais em tempo real em que a carga de trabalho OLTP usa o índice clusterizado subjacente enquanto a análise é executada simultaneamente no índice columnstore. Para obter mais informações, consulte Introdução ao columnstore para análise operacional em tempo real.
Execução em modo de lote
A execução em modo de lote é um método de processamento de consulta usado para processar várias linhas juntas. A execução do modo de lote é estreitamente integrada e otimizada em torno do formato de armazenamento columnstore. A execução em modo de lote é às vezes conhecida como execução baseada em vetor ou execução vetorizada . As consultas em índices columnstore usam a execução em modo de lote, o que melhora o desempenho da consulta normalmente em duas a quatro vezes. Para obter mais informações, consulte o guia de arquitetura de processamento de consultas .
Por que devo usar um índice columnstore?
Um índice columnstore pode fornecer um nível muito alto de compactação de dados, normalmente até 10 vezes, para reduzir significativamente os custos de armazenamento do seu data warehouse. Para análises, um índice columnstore oferece um desempenho de ordem de magnitude melhor do que um índice B-tree. Os índices Columnstore são o formato de armazenamento de dados preferido para cargas de trabalho de armazenamento de dados e análise. A partir do SQL Server 2016 (13.x), você pode usar índices columnstore para análises em tempo real sobre sua carga de trabalho operacional.
Razões pelas quais os índices columnstore são tão rápidos:
As colunas armazenam valores do mesmo domínio e geralmente têm valores semelhantes, o que resulta em altas taxas de compactação. Os gargalos de E/S em seu sistema são minimizados ou eliminados, e o espaço ocupado pela memória é reduzido significativamente.
Altas taxas de compactação melhoram o desempenho da consulta usando um menor espaço na memória. Por sua vez, o desempenho da consulta pode melhorar porque o SQL Server pode executar mais operações de consulta e dados na memória.
A execução em lote melhora o desempenho da consulta, normalmente em duas a quatro vezes, processando várias linhas juntas.
As consultas geralmente selecionam apenas algumas colunas de uma tabela, o que reduz a entrada/saída total dos suportes físicos.
Quando é que devo usar um índice de columnstore?
Casos de uso recomendados:
Use um índice columnstore clusterizado para armazenar tabelas de fatos e tabelas de grandes dimensões para cargas de trabalho de armazenamento de dados. Esse método melhora o desempenho da consulta e a compactação de dados em até 10 vezes. Para obter mais informações, consulte índices Columnstore para data warehousing.
Use um índice columnstore não clusterizado para executar análises em tempo real em uma carga de trabalho OLTP. Para obter mais informações, consulte Comece com columnstore para análise operacional em tempo real.
Para obter mais cenários de uso para índices columnstore, consulte Escolha o melhor índice columnstore para suas necessidades.
Como faço para escolher entre um índice rowstore e um índice columnstore?
Os índices de armazenamento de linhas têm melhor desempenho em consultas que buscam os dados, ao pesquisar um determinado valor ou em consultas em um pequeno intervalo de valores. Use índices rowstore com cargas de trabalho transacionais porque tendem a exigir principalmente buscas em tabelas em vez de varreduras de tabelas.
Os índices Columnstore oferecem altos ganhos de desempenho para consultas analíticas que examinam grandes quantidades de dados, especialmente em tabelas grandes. Utilize índices de armazenamento em colunas em cenários de armazenamento de dados e análise, especialmente em tabelas de fatos, porque eles tendem a exigir scans completos de tabelas em vez de pesquisas nas tabelas.
Os índices columnstore agrupados ordenados melhoram o desempenho de consultas com base em predicados de coluna ordenados. Os índices columnstore ordenados podem melhorar a eliminação de grupos de linhas, o que pode oferecer melhorias de desempenho ignorando completamente os grupos de linhas. Para obter mais informações, consulte Ajuste de desempenho com índices columnstore agrupados ordenados. Para ver a disponibilidade do índice columnstore ordenado, consulte Disponibilidade do índice de coluna ordenada.
Posso combinar rowstore e columnstore na mesma tabela?
Sim. A partir do SQL Server 2016 (13.x), você pode criar um índice columnstore não clusterizado atualizável em uma tabela rowstore. O índice columnstore armazena uma cópia das colunas selecionadas, portanto, você precisa de espaço extra para esses dados, mas os dados selecionados são compactados em média 10 vezes. Você pode executar análises no índice columnstore e transações no índice rowstore ao mesmo tempo. O columnstore é atualizado quando os dados são alterados na tabela rowstore, portanto, ambos os índices funcionam em relação aos mesmos dados.
A partir do SQL Server 2016 (13.x), você pode ter um ou mais índices de armazenamento de linha não clusterizados em um índice columnstore e executar pesquisas de tabela eficientes no columnstore subjacente. Outras opções também ficam disponíveis. Por exemplo, você pode impor uma restrição de chave primária usando uma restrição UNIQUE na tabela rowstore. Como um valor não exclusivo não é inserido na tabela rowstore, o SQL Server não pode inserir o valor no columnstore.
Índices columnstore ordenados
Ao permitir a eliminação eficiente de segmentos, os índices columnstore agrupados ordenados (CCI) fornecem um desempenho muito mais rápido ignorando grandes quantidades de dados ordenados que não correspondem ao predicado de consulta. O carregamento de dados em uma tabela CCI ordenada pode levar mais tempo do que uma tabela CCI não ordenada devido à operação de classificação de dados, no entanto, as consultas podem ser executadas mais rapidamente depois com a CCI ordenada.
- Para obter mais informações sobre o ajuste de desempenho de cargas de trabalho de armazenamento de dados no Mecanismo de Banco de Dados SQL com índices columnstore agrupados ordenados, consulte Ajuste de desempenho com índices columnstore agrupados ordenados.
- Para obter mais informações sobre quando usar qual tipo de índice columnstore, consulte Escolha o melhor índice columnstore para suas necessidades.
Disponibilidade ordenada do índice columnstore
Introduzidos pela primeira vez com o ![]() SQL Server 2022 (16.x), os índices columnstore ordenados estão disponíveis nas seguintes plataformas.
SQL Server 2022 (16.x), os índices columnstore ordenados estão disponíveis nas seguintes plataformas.
| Plataforma | Índices columnstore ordenados agrupados | Índices columnstore não agrupados ordenados de |
|---|---|---|
| Banco de Dados SQL do Azure | Sim | Sim |
| Banco de dados SQL no Microsoft Fabric | Sim* | Sim |
| SQL Server 2022 (16.x) | Sim | Não |
| Instância Gerenciada SQL do Azure | Sim | Sim |
| Pool SQL dedicado no Azure Synapse Analytics | Sim | Não |
* No banco de dados Fabric SQL, as tabelas com índices columnstore clusterizados não são espelhadas para o Fabric OneLake.
Metadados
Todas as colunas em um índice columnstore são armazenadas nos metadados como colunas incluídas. O índice columnstore não tem colunas-chave.
Tarefas relacionadas
Todas as tabelas relacionais, a menos que as especifique como um índice columnstore clusterizado, usam armazenamento de linhas como o formato de dados subjacente.
CREATE TABLE cria uma tabela rowstore, a menos que você especifique a opção WITH CLUSTERED COLUMNSTORE INDEX.
Ao criar uma tabela com a instrução CREATE TABLE, você pode criar a tabela como um columnstore especificando a opção WITH CLUSTERED COLUMNSTORE INDEX. Se você já tiver uma tabela rowstore e quiser convertê-la em columnstore, poderá usar a instrução CREATE COLUMNSTORE INDEX.
| Tarefa | Artigos de referência | Observações |
|---|---|---|
| Crie uma tabela como um columnstore. | CRIAR TABELA (Transact-SQL) | A partir do SQL Server 2016 (13.x), você pode criar a tabela como um índice columnstore clusterizado. Você não precisa primeiro criar uma tabela rowstore e, em seguida, convertê-la em columnstore. |
| Crie uma tabela com otimização de memória com um índice columnstore. | CRIAR TABELA (Transact-SQL) | A partir do SQL Server 2016 (13.x), você pode criar uma tabela com otimização de memória com um índice columnstore. O índice columnstore também pode ser adicionado depois que a tabela é criada usando a sintaxe ALTER TABLE ADD INDEX. |
| Converter uma tabela rowstore em columnstore. | CRIAR COLUMNSTORE INDEX (Transact-SQL) | Converta uma pilha ou árvore B existente em um columnstore. Os exemplos mostram como lidar com índices existentes e também o nome do índice ao executar essa conversão. |
| Converter uma tabela columnstore em um rowstore. | CRIAR ÍNDICE CLUSTERIZADO (Transact-SQL) ou Converter uma tabela columnstore de volta a um heap rowstore | Normalmente, essa conversão não é necessária, mas pode haver momentos em que você precisa converter. Os exemplos mostram como converter um columnstore em um heap ou índice clusterizado. |
| Crie um índice columnstore em uma tabela rowstore. | CRIAR COLUMNSTORE INDEX (Transact-SQL) | Uma tabela rowstore pode ter um índice columnstore. A partir do SQL Server 2016 (13.x), o índice columnstore pode ter uma condição filtrada. Os exemplos mostram a sintaxe básica. |
| Crie índices de desempenho para análise operacional. | Introdução ao columnstore para análise operacional em tempo real | Descreve como criar índices complementares B-tree e columnstore, para que as consultas OLTP usem índices B-tree e as consultas de análise usem índices columnstore. |
| Crie índices columnstore de alto desempenho para armazenamento de dados. | Índices de armazenamento em coluna para armazenamento de dados | Descreve como usar índices de árvore B em tabelas columnstore para criar consultas de armazenamento de dados de alto desempenho. |
| Utilize um índice B-tree para enforçar uma restrição de chave primária num índice columnstore. | Índices Columnstore para armazenamento de dados | Mostra como combinar índices de árvore B e columnstore para impor restrições de chave primária no índice columnstore. |
| Remova um índice columnstore. | ELIMINAR ÍNDICE (Transact-SQL) | Eliminar um índice columnstore usa a sintaxe padrão DROP INDEX que os índices B-tree usam. Remover um índice columnstore clusterizado converte a tabela columnstore numa heap. |
| Exclua uma linha de dados de um índice columnstore. | ELIMINAR (Transact-SQL) | Use DELETE (Transact-SQL) para excluir uma linha. linha columnstore: o SQL Server marca a linha como excluída logicamente, mas não recupera o armazenamento físico da linha até que o índice seja reconstruído. linha deltastore: o SQL Server elimina lógica e fisicamente a linha. |
| Atualizar uma linha no índice columnstore. | ATUALIZAÇÃO (Transact-SQL) | Use UPDATE (Transact-SQL) para atualizar uma linha. linha columnstore: o SQL Server marca a linha como excluída logicamente e insere a linha atualizada no deltastore. linha deltastore: o SQL Server atualiza a linha no deltastore. |
| Carregue dados em um índice columnstore. | Columnstore indexa o carregamento de dados | |
| Obrigue todas as linhas no deltastore a passarem para o columnstore. |
ALTER INDEX (Transact-SQL) ... REBUILDOtimize a manutenção do índice para melhorar o desempenho da consulta e reduzir o consumo de recursos |
ALTER INDEX com a opção REBUILD força todas as linhas a irem para o armazenamento em coluna. |
| Desfragmente um índice de columnstore. | ALTERAR ÍNDICE (Transact-SQL) |
ALTER INDEX ... REORGANIZE desfragmenta os índices columnstore online. |
| Mesclar tabelas com índices de armazenamento em colunas. | MERGE (Transact-SQL) |
Conteúdo relacionado
- O que há de novo nos índices columnstore
- Columnstore indexes - Guia de carregamento de dados
- Índices columnstore - Desempenho de consultas
- Introdução ao Columnstore para análise operacional em tempo real
- índices Columnstore em armazenamento de dados
- Desfragmentação de índices Columnstore
- Guia de arquitetura e design de índices do SQL Server e do Azure SQL
- Arquitetura de índice de Armazenamento em Coluna
- CRIAR ÍNDICE DE COLUMNSTORE (Transact-SQL)