Aplicações inteligentes
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure![]() Banco de Dados SQL no Fabric
Banco de Dados SQL no Fabric
Este artigo fornece uma visão geral do uso de opções de inteligência artificial (IA), como OpenAI e vetores, para criar aplicativos inteligentes com o Banco de Dados SQL do Azure e o Banco de Dados SQL Fabric, que compartilha muitos desses recursos do Banco de Dados SQL do Azure.
Por amostras e exemplos, visite o repositório SQL AI Samples.
Assista a este vídeo na série de fundamentos do Banco de Dados SQL do Azure para obter uma breve visão geral da criação de um aplicativo pronto para IA:
Visão geral
Os modelos de linguagem grande (LLMs) permitem que os desenvolvedores criem aplicativos baseados em IA com uma experiência de usuário familiar.
O uso de LLMs em aplicativos traz maior valor e uma experiência de usuário aprimorada quando os modelos podem acessar os dados certos, no momento certo, do banco de dados do seu aplicativo. Esse processo é conhecido como RAG (Geração Aumentada de Recuperação) e o Banco de Dados SQL do Azure e o banco de dados SQL de malha têm muitos recursos que dão suporte a esse novo padrão, tornando-o um ótimo banco de dados para criar aplicativos inteligentes.
Os links a seguir fornecem código de exemplo de várias opções para criar aplicativos inteligentes:
| Opção AI | Descrição |
|---|---|
| Azure OpenAI | Gere incorporações para RAG e integre com qualquer modelo suportado pelo Azure OpenAI. |
| Vetores | Saiba como armazenar e consultar vetores do banco de dados. |
| Pesquisa de IA do Azure | Utilize o seu banco de dados juntamente com a Pesquisa de Inteligência Artificial do Azure para treinar um LLM nos seus dados. |
| Aplicações inteligentes | Saiba como criar uma solução completa usando um padrão comum que pode ser replicado em qualquer cenário. |
| habilidades de Copilot na Base de Dados SQL do Azure | Saiba mais sobre o conjunto de experiências assistidas por IA projetadas para simplificar o design, a operação, a otimização e a integridade dos aplicativos orientados pelo Banco de Dados SQL do Azure. |
| habilidades de Copilot na base de dados Fabric SQL | Saiba mais sobre o conjunto de experiências assistidas por IA projetadas para simplificar o design, a operação, a otimização e a integridade dos aplicativos orientados por banco de dados SQL do Fabric. |
Principais conceitos para implementar o RAG com o Azure OpenAI
Esta seção inclui conceitos-chave que são críticos para implementar o RAG com o Azure OpenAI no Banco de Dados SQL do Azure ou no Banco de Dados SQL do Fabric.
Geração aumentada de recuperação (RAG)
RAG é uma técnica que aumenta a capacidade do LLM de produzir respostas relevantes e informativas, recuperando dados adicionais de fontes externas. Por exemplo, o RAG pode consultar artigos ou documentos que contenham conhecimento específico do domínio relacionado à pergunta ou prompt do usuário. O LLM pode então usar esses dados recuperados como referência ao gerar sua resposta. Por exemplo, um padrão RAG simples usando o Banco de Dados SQL do Azure pode ser:
- Insira dados em uma tabela.
- Vincule o Banco de Dados SQL do Azure à Pesquisa de IA do Azure.
- Crie um modelo do Azure OpenAI GPT4 e conecte-o ao Azure AI Search.
- Converse por chat e faça perguntas sobre seus dados usando o modelo treinado do Azure OpenAI do seu aplicativo e do Banco de Dados SQL do Azure.
O padrão RAG, com engenharia rápida, serve o propósito de melhorar a qualidade da resposta, oferecendo mais informações contextuais ao modelo. A RAG permite que o modelo aplique uma base de conhecimentos mais ampla, incorporando fontes externas relevantes no processo de geração, resultando em respostas mais abrangentes e informadas. Para obter mais informações sobre enraizamento LLMs, consulte Grounding LLMs - Microsoft Community Hub.
Prompts e engenharia de prompts
Um prompt refere-se a texto ou informações específicas que servem como uma instrução para um LLM, ou como dados contextuais nos quais o LLM pode se basear. Um prompt pode assumir várias formas, como uma pergunta, uma instrução ou até mesmo um trecho de código.
Exemplos de prompts que podem ser usados para gerar uma resposta de um LLM:
- Instruções: forneça orientações ao LLM
- Conteúdo primário: fornece informações ao LLM para processamento
- Exemplos: ajudar a condicionar o modelo a uma tarefa ou processo específico
- Indicações: direcione a saída do LLM na direção certa
- Conteúdo de apoio: representa informações suplementares que o LLM pode usar para gerar resultados
O processo de criação de bons prompts para um cenário é chamado de prompt engineering. Para obter mais informações sobre prompts e práticas recomendadas para engenharia de prompts, consulte Azure OpenAI Service.
Tokens
Os tokens são pequenos pedaços de texto gerados pela divisão do texto de entrada em segmentos menores. Esses segmentos podem ser palavras ou grupos de caracteres, variando em comprimento de um único caractere para uma palavra inteira. Por exemplo, a palavra hamburger seria dividida em tokens como ham, bure ger enquanto uma palavra curta e comum como pear seria considerada um único token.
No Azure OpenAI, o texto de entrada fornecido à API é transformado em tokens (tokenizado). O número de tokens processados em cada solicitação de API depende de fatores como o comprimento dos parâmetros de entrada, saída e solicitação. A quantidade de tokens que estão sendo processados também afeta o tempo de resposta e a taxa de transferência dos modelos. Há limites para o número de tokens que cada modelo pode receber em uma única solicitação/resposta do Azure OpenAI. Para informações adicionais, consulte Cotas e limites do Azure OpenAI Service.
Vetores
Vetores são matrizes ordenadas de números (normalmente flutuadores) que podem representar informações sobre alguns dados. Por exemplo, uma imagem pode ser representada como um vetor de valores de pixel ou uma cadeia de caracteres de texto pode ser representada como um vetor ou valores ASCII. O processo para transformar dados em um vetor é chamado de vetorização . Para obter mais informações, consulte Vectors.
Incorporações
As incorporações são vetores que representam características importantes dos dados. As incorporações geralmente são aprendidas usando um modelo de aprendizado profundo, e os modelos de aprendizado de máquina e IA os utilizam como recursos. As incorporações também podem capturar semelhança semântica entre conceitos semelhantes. Por exemplo, ao gerar uma incorporação para as palavras person e human, esperaríamos que suas incorporações (representação vetorial) fossem semelhantes em valor, uma vez que as palavras também são semanticamente semelhantes.
O Azure OpenAI apresenta modelos para criar incorporações a partir de dados de texto. O serviço divide o texto em tokens e gera incorporações usando modelos pré-treinados pela OpenAI. Para saber mais, consulte Criando incorporações com o Azure OpenAI.
Pesquisa vetorial
A pesquisa vetorial refere-se ao processo de encontrar todos os vetores em um conjunto de dados que são semanticamente semelhantes a um vetor de consulta específico. Portanto, um vetor de consulta para a palavra human pesquisa palavras semanticamente semelhantes em todo o dicionário e deve encontrar a palavra person como uma correspondência próxima. Essa proximidade, ou distância, é medida usando uma métrica de semelhança, como a semelhança de cosseno. Quanto mais próximos os vetores estiverem em semelhança, menor é a distância entre eles.
Considere um cenário em que você executa uma consulta sobre milhões de documentos para encontrar os documentos mais semelhantes em seus dados. Você pode criar incorporações para seus dados e consultar documentos usando o Azure OpenAI. Em seguida, você pode realizar uma pesquisa vetorial para encontrar os documentos mais semelhantes do seu conjunto de dados. No entanto, realizar uma pesquisa vetorial em alguns exemplos é trivial. Realizar essa mesma pesquisa em milhares, ou milhões, de pontos de dados torna-se um desafio. Também há compensações entre a pesquisa exaustiva e os métodos de pesquisa do vizinho mais próximo aproximado (ANN), incluindo latência, taxa de transferência, precisão e custo, todos os quais dependem dos requisitos da tua aplicação.
Os vetores no Banco de Dados SQL do Azure podem ser armazenados e consultados de forma eficiente, conforme descrito nas próximas seções, permitindo a pesquisa exata do vizinho mais próximo com ótimo desempenho. Você não precisa decidir entre precisão e velocidade: você pode ter ambos. Armazenar incorporações vetoriais ao lado dos dados em uma solução integrada minimiza a necessidade de gerenciar a sincronização de dados e acelera seu tempo de comercialização para o desenvolvimento de aplicativos de IA.
Azure OpenAI
A incorporação é o processo de representar o mundo real como dados. Texto, imagens ou sons podem ser convertidos em incorporações. Os modelos OpenAI do Azure são capazes de transformar informações do mundo real em incorporações. Os modelos estão disponíveis como endpoints REST e, assim, podem ser facilmente consumidos da Base de Dados SQL do Azure usando o procedimento armazenado no sistema sp_invoke_external_rest_endpoint.
DECLARE @retval INT, @response NVARCHAR(MAX);
DECLARE @payload NVARCHAR(MAX);
SET @payload = JSON_OBJECT('input': @text);
EXEC @retval = sp_invoke_external_rest_endpoint @url = 'https://<openai-url>/openai/deployments/<model-name>/embeddings?api-version=2023-03-15-preview',
@method = 'POST',
@credential = [https://<openai-url>/openai/deployments/<model-name>],
@payload = @payload,
@response = @response OUTPUT;
SELECT CAST([key] AS INT) AS [vector_value_id],
CAST([value] AS FLOAT) AS [vector_value]
FROM OPENJSON(JSON_QUERY(@response, '$.result.data[0].embedding'));
Usar uma chamada para um serviço REST para obter incorporações é apenas uma das opções de integração que você tem ao trabalhar com o Banco de dados SQL e OpenAI. Você pode permitir que qualquer um dos modelos disponíveis acesse dados armazenados no Banco de Dados SQL do Azure para criar soluções onde seus usuários possam interagir com os dados, como o exemplo a seguir.
Para obter exemplos adicionais sobre como usar o Banco de dados SQL e o OpenAI, consulte os seguintes artigos:
- Gerar imagens com o Serviço OpenAI do Azure (DALL-E) e o Banco de Dados SQL do Azure
- Usando Interfaces REST do OpenAI com a Base de Dados SQL do Azure
Vetores
Tipo de dados vetoriais
Em novembro de 2024, o novo tipo de dados vetorial foi introduzido na Base de Dados SQL do Azure.
O tipo dedicado vetorial permite armazenamento eficiente e otimizado de dados vetoriais e inclui um conjunto de funções para ajudar os desenvolvedores a agilizar a implementação de pesquisa vetorial e de similaridade. O cálculo da distância entre dois vetores pode ser feito em uma linha de código usando a nova função VECTOR_DISTANCE. Para obter mais informações sobre o vetor tipo de dados e funções relacionadas, consulte Visão geral de vetores no Mecanismo de Banco de Dados SQL.
Por exemplo:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[embedding] [vector](1536) NOT NULL,
)
GO
SELECT TOP(10)
*
FROM
[dbo].[wikipedia_articles_embeddings_titles_vector]
ORDER BY
VECTOR_DISTANCE('cosine', @my_reference_vector, embedding)
Vetores em versões mais antigas do SQL Server
Enquanto as versões mais antigas do mecanismo do SQL Server, até e incluindo o SQL Server 2022, não têm um tipo de vetor nativo, um vetor nada mais é do que uma tupla ordenada, e os bancos de dados relacionais são ótimos para gerenciar tuplas. Você pode pensar numa tupla como o termo usado formalmente para uma linha numa tabela.
O Banco de Dados SQL do Azure também dá suporte a índices columnstore e execução em modo de lote. Uma abordagem baseada em vetor é usada para processamento em modo de lote, o que significa que cada coluna em um lote tem seu próprio local de memória onde é armazenada como um vetor. Isso permite um processamento mais rápido e eficiente de dados em lotes.
O exemplo a seguir mostra como um vetor pode ser armazenado no Banco de dados SQL:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[vector_value_id] [int] NOT NULL,
[vector_value] [float] NOT NULL
)
GO
CREATE CLUSTERED COLUMNSTORE INDEX ixc
ON dbo.wikipedia_articles_embeddings_titles_vector
ORDER (article_id);
GO
Para obter um exemplo que usa um subconjunto comum de artigos da Wikipédia com incorporações já geradas usando OpenAI, consulte Pesquisa de semelhança vetorial com o Banco de Dados SQL do Azure e o OpenAI.
Outra opção para aproveitar a Pesquisa Vetorial no banco de dados SQL do Azure é a integração com a IA do Azure usando os recursos de vetorização integrados: Pesquisa Vetorial com o Banco de Dados SQL do Azure e o Azure AI Search
Azure AI Search
Implemente padrões RAG com o Banco de Dados SQL do Azure e o Azure AI Search. Pode executar modelos de chat suportados em dados armazenados na Base de Dados SQL do Azure, sem ter de treinar ou ajustar modelos, graças à integração do Azure AI Search com o Azure OpenAI e a Base de Dados SQL do Azure. A execução de modelos em seus dados permite que você converse e analise seus dados com maior precisão e velocidade.
- o Azure OpenAI nos seus dados
- Geração Aumentada de Recuperação (RAG) no Azure AI Search
- Pesquisa vetorial com o Banco de Dados SQL do Azure e o Azure AI Search
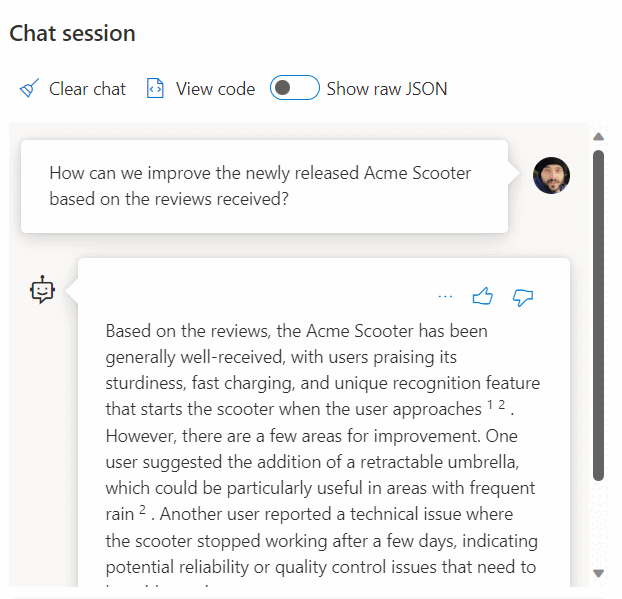
Aplicações inteligentes
O Banco de Dados SQL do Azure pode ser usado para criar aplicativos inteligentes que incluem recursos de IA, como recomendações e Geração Aumentada de Recuperação (RAG), como demonstra o diagrama a seguir:

Para obter um exemplo completo para criar um aplicativo habilitado para IA usando sessões abstratas como um conjunto de dados de exemplo, consulte:
- Como construí um recomendador de sessão em 1 hora usando OpenAI.
- Usando a Geração Aumentada por Recuperação para criar um assistente de sessões de conferência
Integração LangChain
LangChain é uma estrutura bem conhecida para o desenvolvimento de aplicações alimentadas por modelos de linguagem. Para obter exemplos que mostram como o LangChain pode ser usado para criar um Chatbot em seus próprios dados, consulte:
Alguns exemplos sobre como usar o SQL do Azure com LangChain:
- exemplos do LangChain com langchain_sqlserver
- Introdução ao LangChain e ao Banco de Dados SQL do Azure
Exemplos de ponta a ponta:
- Crie um chatbot em seus próprios dados em 1 hora com o Azure SQL, Langchain e Chainlit: Crie um chatbot usando o padrão RAG em seus próprios dados usando Langchain para orquestrar chamadas LLM e Chainlit para a interface do usuário.
- Criando seu próprio Copiloto de Banco de Dados para Azure SQL com o Azure OpenAI GPT-4: Crie uma experiência semelhante a um copiloto para consultar seus bancos de dados usando linguagem natural.
Integração com Kernel Semântico
Semantic Kernel é uma SDK de código aberto que permite criar facilmente agentes que podem chamar seu código existente. Como um SDK altamente extensível, você pode usar o Kernel Semântico com modelos do OpenAI, Azure OpenAI, Hugging Face e muito mais. Ao combinar seu código C#, Python e Java existente com esses modelos, você pode criar agentes que respondem a perguntas e automatizam processos.
Um exemplo de como o Kernel Semântico ajuda a construir uma solução habilitada para IA está aqui:
- O melhor chatbot?: Crie um chatbot em seus próprios dados usando os padrões NL2SQL e RAG para a melhor experiência do usuário.
Habilidades do Microsoft Copilot na Base de Dados SQL do Azure
habilidades do Microsoft Copilot no Azure SQL Database (pré-visualização) é um conjunto de experiências assistidas por IA projetadas para simplificar o design, a operação, a otimização e a integridade das aplicações baseadas em Azure SQL Database. O Copilot pode melhorar a produtividade oferecendo conversão de linguagem natural para SQL e autoajuda para administração de banco de dados.
O Copilot fornece respostas relevantes às perguntas dos usuários, simplificando o gerenciamento do banco de dados aproveitando o contexto do banco de dados, a documentação, as exibições de gerenciamento dinâmico, o Repositório de Consultas e outras fontes de conhecimento. Por exemplo:
- Os administradores de banco de dados podem gerenciar bancos de dados de forma independente e resolver problemas, ou saber mais sobre o desempenho e os recursos do seu banco de dados.
- Os desenvolvedores podem fazer perguntas sobre seus dados como fariam em texto ou conversa para gerar uma consulta T-SQL. Os desenvolvedores também podem aprender a escrever consultas mais rapidamente através de explicações detalhadas da consulta gerada.
Observação
As funcionalidades do Microsoft Copilot no Banco de Dados SQL do Azure estão atualmente em visualização para um número limitado de utilizadores iniciais. Para se inscrever neste programa, visite Solicitar acesso ao Copilot no Banco de Dados SQL do Azure: Pré-visualização.
A visualização do Copilot para a base de dados SQL do Azure inclui duas experiências no portal do Azure:
| Localização do portal | Experiências |
|---|---|
| Editor de Consultas do Portal Azure | Linguagem natural para SQL: essa experiência no editor de consultas do portal do Azure para o Banco de Dados SQL do Azure traduz consultas de linguagem natural em SQL, tornando as interações do banco de dados mais intuitivas. Para obter um tutorial e exemplos de recursos de linguagem natural para SQL, consulte Linguagem natural para SQL no editor de consultas do portal do Azure (visualização). |
| Microsoft Copilot para Azure | Integração do Azure Copilot: Esta experiência adiciona competências de SQL do Azure ao Microsoft Copilot para Azure. Fornece aos clientes assistência orientada por si mesmos, dando-lhes autonomia para gerirem as suas bases de dados e resolverem problemas de forma independente. |
Para obter mais informações, consulte Perguntas frequentes sobre as capacidades do Microsoft Copilot no Azure SQL Database (pré-visualização).
Habilidades do Microsoft Copilot na base de dados SQL do Fabric (pré-visualização)
Copilot para base de dados SQL no Microsoft Fabric (pré-visualização) inclui assistência de IA integrada com as seguintes funcionalidades:
Autocompletar código: Comece a escrever T-SQL no editor de consultas SQL e o Copilot gerará automaticamente uma sugestão de código para auxiliar na conclusão da sua consulta. A tecla Tab aceita a sugestão de código ou continua a escrever para ignorar a sugestão.
Ações rápidas: Na faixa de opções do editor de consultas SQL, as opções Corrigir e Explicar são ações rápidas. Realce uma consulta SQL de sua escolha e selecione um dos botões de ação rápida para executar a ação selecionada em sua consulta.
Correção: Copilot pode corrigir erros no seu código quando surgirem mensagens de erro. Os cenários de erro podem incluir código T-SQL incorreto/sem suporte, ortografias erradas e muito mais. O Copilot também fornecerá comentários que explicam as alterações e sugerem práticas recomendadas de SQL.
Explicar: Copilot pode fornecer explicações em linguagem natural de sua consulta SQL e esquema de banco de dados em formato de comentários.
Painel de bate-papo: Use o painel de bate-papo para fazer perguntas ao Copilot por meio de linguagem natural. O Copilot responde com uma consulta SQL gerada ou linguagem natural com base na pergunta feita.
Natural Language to SQL: Gere código T-SQL a partir de solicitações de texto simples e obtenha sugestões de perguntas a serem feitas para acelerar seu fluxo de trabalho.
Pergunta baseada em documento&Resposta: Faça perguntas ao Copilot sobre as capacidades gerais do banco de dados SQL, e ele responde em linguagem natural. O Copilot também ajuda a encontrar documentação relacionada ao seu pedido.
O copiloto para bases de dados SQL utiliza nomes de tabelas e vistas, nomes de colunas, chaves primárias e metadados de chaves estrangeiras para gerar código T-SQL. O Copilot para banco de dados SQL não usa dados em tabelas para gerar sugestões de T-SQL.
Conteúdo relacionado
- Criar e implantar um recurso do Serviço OpenAI do Azure
- Incorpora modelos
- Amostras e Exemplos de IA SQL
- Perguntas frequentes sobre as capacidades do Microsoft Copilot na Base de Dados SQL do Azure (versão preliminar)
- Perguntas frequentes sobre IA responsável para o Microsoft Copilot para Azure (versão prévia)