Azure OpenAI em seus dados
Use este artigo para saber mais sobre o Azure OpenAI On Your Data, que torna mais fácil para os desenvolvedores conectar, ingerir e aterrar seus dados corporativos para criar copilots personalizados (visualização) rapidamente. Ele melhora a compreensão do usuário, agiliza a conclusão de tarefas, melhora a eficiência operacional e ajuda na tomada de decisões.
O que é o Azure OpenAI em seus dados
O Azure OpenAI On Your Data permite que você execute modelos avançados de IA, como GPT-35-Turbo e GPT-4, em seus próprios dados corporativos, sem a necessidade de treinar ou ajustar modelos. Você pode conversar e analisar seus dados com maior precisão. Você pode especificar fontes para dar suporte às respostas com base nas informações mais recentes disponíveis nas fontes de dados designadas. Você pode acessar o Azure OpenAI On Your Data usando uma API REST, por meio do SDK ou da interface baseada na Web no portal do Azure AI Foundry. Você também pode criar um aplicativo Web que se conecta aos seus dados para habilitar uma solução de bate-papo aprimorada ou implantá-lo diretamente como um copiloto no Copilot Studio (visualização).
Desenvolvendo com o Azure OpenAI em seus dados
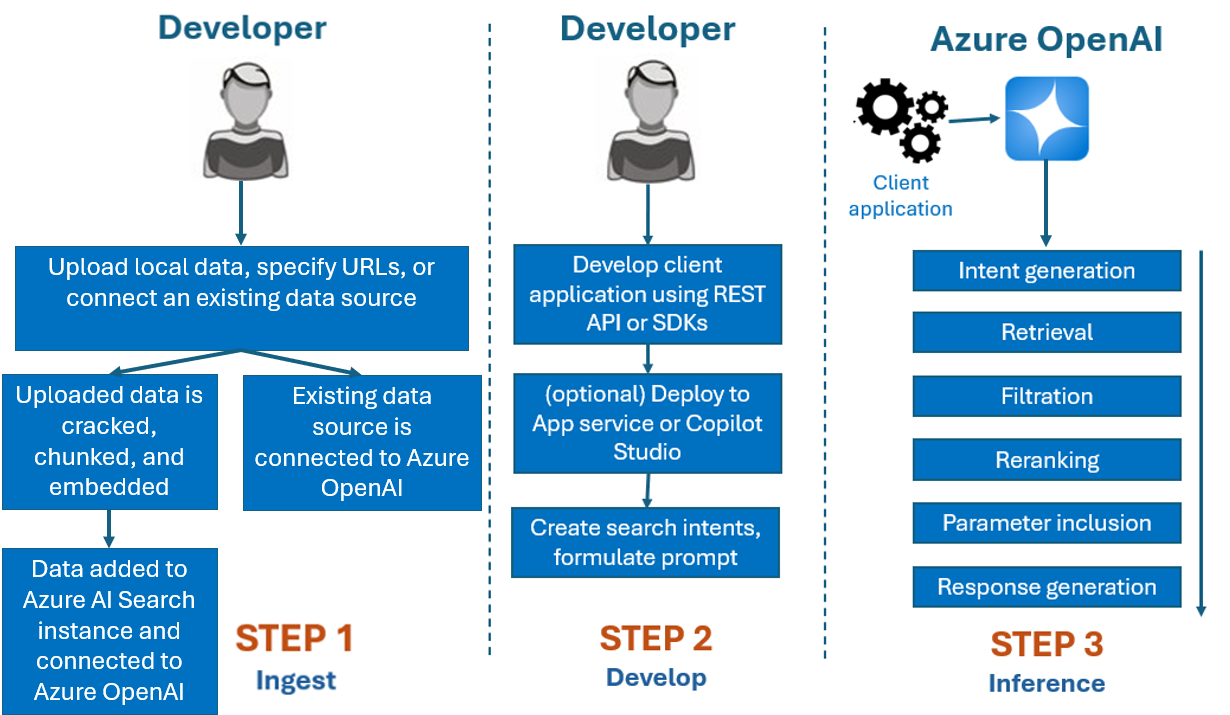
Normalmente, o processo de desenvolvimento que você usaria com o Azure OpenAI On Your Data é:
Ingerir: carregue arquivos usando o portal do Azure AI Foundry ou a API de ingestão. Isso permite que seus dados sejam quebrados, fragmentados e incorporados em uma instância do Azure AI Search que pode ser usada por modelos do Azure OpenAI. Se você tiver uma fonte de dados suportada, também poderá conectá-la diretamente.
Desenvolver: Depois de experimentar o Azure OpenAI On Your Data, comece a desenvolver seu aplicativo usando a API REST e os SDKs disponíveis, que estão disponíveis em vários idiomas. Ele criará prompts e intenções de pesquisa para passar para o serviço Azure OpenAI.
Inferência: Depois que seu aplicativo for implantado em seu ambiente preferido, ele enviará prompts para o Azure OpenAI, que executará várias etapas antes de retornar uma resposta:
Geração de intenção: o serviço determinará a intenção do prompt do usuário para determinar uma resposta adequada.
Recuperação: o serviço recupera partes relevantes de dados disponíveis da fonte de dados conectada consultando-a. Por exemplo, usando uma pesquisa semântica ou vetorial. Parâmetros como rigor e número de documentos a recuperar são utilizados para influenciar a recuperação.
Filtragem e reclassificação: os resultados da pesquisa da etapa de recuperação são melhorados classificando e filtrando dados para refinar a relevância.
Geração de resposta: Os dados resultantes são enviados juntamente com outras informações, como a mensagem do sistema para o Large Language Model (LLM) e a resposta é enviada de volta para o aplicativo.
Para começar, conecte sua fonte de dados usando o portal do Azure AI Foundry e comece a fazer perguntas e conversar sobre seus dados.
Controles de acesso baseados em função do Azure (Azure RBAC) para adicionar fontes de dados
Para usar o Azure OpenAI em seus dados completamente, você precisa definir uma ou mais funções do Azure RBAC. Consulte Configuração do Azure OpenAI On Your Data para obter mais informações.
Formatos de dados e tipos de ficheiro
O Azure OpenAI On Your Data suporta os seguintes tipos de ficheiro:
.txt.md.html.docx.pptx.pdf
Há um limite de upload e há algumas ressalvas sobre a estrutura do documento e como isso pode afetar a qualidade das respostas do modelo:
Se você estiver convertendo dados de um formato sem suporte em um formato suportado, otimize a qualidade da resposta do modelo garantindo a conversão:
- Não leva a perda significativa de dados.
- Não adiciona ruído inesperado aos seus dados.
Se os seus ficheiros tiverem formatação especial, como tabelas e colunas ou marcadores, prepare os seus dados com o script de preparação de dados disponível no GitHub.
Para documentos e conjuntos de dados com texto longo, deve utilizar o script de preparação de dados disponível. O script segmenta dados para que as respostas do modelo sejam mais precisas. Este script também suporta ficheiros PDF digitalizados e imagens.
Supported data sources (Origens de dados suportadas)
Você precisa se conectar a uma fonte de dados para carregar seus dados. Quando você deseja usar seus dados para conversar com um modelo OpenAI do Azure, seus dados são agrupados em um índice de pesquisa para que os dados relevantes possam ser encontrados com base nas consultas do usuário.
O Banco de Dados Vetorial Integrado no Azure Cosmos DB para MongoDB baseado em vCore oferece suporte nativo à integração com o Azure OpenAI On Your Data.
Para algumas fontes de dados, como carregar arquivos de sua máquina local (visualização) ou dados contidos em uma conta de armazenamento de blob (visualização), o Azure AI Search é usado. Quando você escolhe as seguintes fontes de dados, seus dados são ingeridos em um índice do Azure AI Search.
| Dados ingeridos através da Pesquisa de IA do Azure | Description |
|---|---|
| Azure AI Search | Use um índice existente do Azure AI Search com o Azure OpenAI On Your Data. |
| Carregar ficheiros (pré-visualização) | Carregue arquivos de sua máquina local para serem armazenados em um banco de dados do Armazenamento de Blobs do Azure e ingeridos no Azure AI Search. |
| URL/Endereço Web (pré-visualização) | O conteúdo da Web das URLs é armazenado no Armazenamento de Blobs do Azure. |
| Armazenamento de Blobs do Azure (visualização) | Carregue arquivos do Armazenamento de Blobs do Azure para serem ingeridos em um índice do Azure AI Search. |

- Azure AI Search
- Banco de dados vetorial no Azure Cosmos DB para MongoDB
- Armazenamento de Blobs do Azure (visualização)
- Carregar ficheiros (pré-visualização)
- URL/Endereço Web (pré-visualização)
- Elasticsearch (visualização)
- MongoDB Atlas (visualização)
Talvez você queira considerar o uso de um índice do Azure AI Search quando quiser:
- Personalize o processo de criação do índice.
- Reutilize um índice criado anteriormente ingerindo dados de outras fontes de dados.
Nota
- Para usar um índice existente, ele deve ter pelo menos um campo pesquisável.
- Defina a opção CORS Allow Origin Type como
alle a opção Allowed origins como*.
Tipos de pesquisa
O Azure OpenAI On Your Data fornece os seguintes tipos de pesquisa que você pode usar ao adicionar sua fonte de dados.
Pesquisa vetorial usando modelos de incorporação Ada, disponíveis em regiões selecionadas
Para habilitar a pesquisa vetorial, você precisa de um modelo de incorporação existente implantado em seu recurso do Azure OpenAI. Selecione sua implantação de incorporação ao conectar seus dados e, em seguida, selecione um dos tipos de pesquisa vetorial em Gerenciamento de dados. Se estiver a utilizar o Azure AI Search como origem de dados, certifique-se de que tem uma coluna de vetor no índice.
Se você estiver usando seu próprio índice, poderá personalizar o mapeamento de campo ao adicionar sua fonte de dados para definir os campos que serão mapeados ao responder a perguntas. Para personalizar o mapeamento de campos, selecione Usar mapeamento de campo personalizado na página Fonte de Dados ao adicionar sua fonte de dados.
Importante
- A pesquisa semântica está sujeita a preços adicionais. Você precisa escolher SKU básico ou superior para habilitar a pesquisa semântica ou a pesquisa vetorial. Consulte a diferença de nível de preço e os limites de serviço para obter mais informações.
- Para ajudar a melhorar a qualidade da recuperação de informações e da resposta do modelo, recomendamos ativar a pesquisa semântica para os seguintes idiomas de origem de dados: inglês, francês, espanhol, português, italiano, alemão, chinês (zh), japonês, coreano, russo e árabe.
| Opção de pesquisa | Tipo de recuperação | Preços adicionais? | Benefícios |
|---|---|---|---|
| palavra-chave | Pesquisa de palavra-chave | Sem preços adicionais. | Realiza análise e correspondência de consultas rápidas e flexíveis em campos pesquisáveis, usando termos ou frases em qualquer idioma suportado, com ou sem operadores. |
| semântica | Pesquisa semântica | Preços adicionais para uso de pesquisa semântica. | Melhora a precisão e a relevância dos resultados da pesquisa usando um reranker (com modelos de IA) para entender o significado semântico dos termos de consulta e documentos retornados pelo classificador de pesquisa inicial |
| vetor | Pesquisa vetorial | Preços adicionais na sua conta do Azure OpenAI ao chamar o modelo de incorporação. | Permite localizar documentos semelhantes a uma determinada entrada de consulta com base nas incorporações vetoriais do conteúdo. |
| híbrido (vetor + palavra-chave) | Um híbrido de pesquisa vetorial e pesquisa por palavra-chave | Preços adicionais na sua conta do Azure OpenAI ao chamar o modelo de incorporação. | Realiza pesquisa de semelhança em campos vetoriais usando incorporações vetoriais, ao mesmo tempo em que oferece suporte à análise flexível de consultas e pesquisa de texto completo em campos alfanuméricos usando consultas de termos. |
| híbrido (vetor + palavra-chave) + semântica | Um híbrido de pesquisa vetorial, pesquisa semântica e pesquisa por palavra-chave. | Preços adicionais na sua conta do Azure OpenAI ao chamar o modelo de incorporação e preços adicionais para uso de pesquisa semântica. | Usa incorporações vetoriais, compreensão de linguagem e análise de consulta flexível para criar experiências de pesquisa avançadas e aplicativos de IA generativa que podem lidar com cenários complexos e diversos de recuperação de informações. |
Pesquisa inteligente
O Azure OpenAI On Your Data tem a pesquisa inteligente ativada para os seus dados. A pesquisa semântica é habilitada por padrão se você tiver pesquisa semântica e pesquisa por palavra-chave. Se você tiver modelos de incorporação, a pesquisa inteligente assume como padrão a pesquisa híbrida + semântica.
Controle de acesso no nível do documento
Nota
O controle de acesso no nível de documento é suportado quando você seleciona o Azure AI Search como sua fonte de dados.
O Azure OpenAI On Your Data permite restringir os documentos que podem ser usados em respostas para diferentes usuários com os filtros de segurança do Azure AI Search. Quando você habilita o acesso no nível do documento, os resultados da pesquisa retornados da Pesquisa de IA do Azure e usados para gerar uma resposta são cortados com base na associação do usuário ao grupo Microsoft Entra. Você só pode habilitar o acesso no nível do documento em índices existentes do Azure AI Search. Consulte Azure OpenAI On Your Data network and access configuration para obter mais informações.
Mapeamento de campo de índice
Se você estiver usando seu próprio índice, será solicitado no portal do Azure AI Foundry para definir quais campos deseja mapear para responder a perguntas quando adicionar sua fonte de dados. Você pode fornecer vários campos para dados de conteúdo e deve incluir todos os campos que têm texto pertencente ao seu caso de uso.

Neste exemplo, os campos mapeados para Dados de conteúdo e Título fornecem informações ao modelo para responder a perguntas. O título também é usado para o texto de citação do título. O campo mapeado para Nome do arquivo gera os nomes das citações na resposta.
Mapear esses campos corretamente ajuda a garantir que o modelo tenha melhor qualidade de resposta e citação. Além disso, você pode configurá-lo na API usando o fieldsMapping parâmetro.
Filtro de pesquisa (API)
Se quiser implementar critérios adicionais baseados em valor para a execução da consulta, você pode configurar um filtro de pesquisa usando o filter parâmetro na API REST.
Como os dados são ingeridos na pesquisa de IA do Azure
A partir de setembro de 2024, as APIs de ingestão mudaram para vetorização integrada. Esta atualização não altera os contratos de API existentes. A vetorização integrada, uma nova oferta do Azure AI Search, utiliza habilidades pré-criadas para fragmentar e incorporar os dados de entrada. O serviço de ingestão do Azure OpenAI On Your Data não emprega mais habilidades personalizadas. Após a migração para a vetorização integrada, o processo de ingestão sofreu algumas modificações e, como resultado, apenas os seguintes ativos são criados:
{job-id}-index-
{job-id}-indexer, se for especificada uma programação horária ou diária, caso contrário, o indexador será limpo no final do processo de ingestão. {job-id}-datasource
O contêiner de partes não está mais disponível, pois essa funcionalidade agora é inerentemente gerenciada pelo Azure AI Search.
Conexão de dados
Você precisa selecionar como deseja autenticar a conexão do Azure OpenAI, Azure AI Search e armazenamento de blob do Azure. Você pode escolher uma identidade gerenciada atribuída ao sistema ou uma chave de API. Ao selecionar a chave de API como o tipo de autenticação, o sistema preencherá automaticamente a chave de API para que você se conecte aos recursos do Azure AI Search, Azure OpenAI e Azure Blob Storage. Ao selecionar Identidade gerenciada atribuída ao sistema, a autenticação será baseada na atribuição de função que você tem. A identidade gerenciada atribuída ao sistema é selecionada por padrão para segurança.

Depois de selecionar o botão seguinte , ele validará automaticamente sua configuração para usar o método de autenticação selecionado. Se você encontrar um erro, consulte o artigo atribuições de função para atualizar sua configuração.
Depois de corrigir a configuração, selecione Next novamente para validar e prosseguir. Os usuários da API também podem configurar a autenticação com identidade gerenciada atribuída e chaves de API.









Implantar em um copiloto (visualização), aplicativo do Teams (visualização) ou aplicativo Web
Depois de conectar o Azure OpenAI aos seus dados, você pode implantá-lo usando o botão Implantar em no portal do Azure AI Foundry.

Isso oferece várias opções para implantar sua solução.
Você pode implantar em um copiloto no Copilot Studio (visualização) diretamente do portal do Azure AI Foundry, permitindo que você traga experiências de conversação para vários canais, como: Microsoft Teams, sites, Dynamics 365 e outros canais do Serviço de Bot do Azure. O locatário usado no serviço Azure OpenAI e no Copilot Studio (visualização) deve ser o mesmo. Para obter mais informações, consulte Usar uma conexão com o Azure OpenAI em seus dados.
Nota
A implantação em um copiloto no Copilot Studio (visualização) só está disponível em regiões dos EUA.
Configurar o acesso e a rede para o Azure OpenAI On Your Data
Você pode usar o Azure OpenAI On Your Data e proteger dados e recursos com o controle de acesso baseado em função do Microsoft Entra ID, redes virtuais e pontos de extremidade privados. Você também pode restringir os documentos que podem ser usados em respostas para diferentes usuários com os filtros de segurança do Azure AI Search. Consulte Azure OpenAI On Your Data access and network configuration.
Melhores práticas
Use as seções a seguir para saber como melhorar a qualidade das respostas dadas pelo modelo.
Parâmetro de ingestão
Quando seus dados são ingeridos no Azure AI Search, você pode modificar as seguintes configurações adicionais no estúdio ou na API de ingestão.
Tamanho do bloco (visualização)
O Azure OpenAI On Your Data processa seus documentos dividindo-os em partes antes de ingeri-los. O tamanho do bloco é o tamanho máximo em termos do número de tokens de qualquer bloco no índice de pesquisa. O tamanho do bloco e o número de documentos recuperados juntos controlam a quantidade de informações (tokens) incluídas no prompt enviado ao modelo. Em geral, o tamanho do bloco multiplicado pelo número de documentos recuperados é o número total de tokens enviados para o modelo.
Definindo o tamanho do bloco para seu caso de uso
O tamanho de bloco padrão é 1.024 tokens. No entanto, dada a exclusividade de seus dados, você pode achar um tamanho de bloco diferente (como 256, 512 ou 1.536 tokens) mais eficaz.
Ajustar o tamanho do bloco pode melhorar o desempenho do seu chatbot. Embora encontrar o tamanho ideal do bloco exija alguma tentativa e erro, comece considerando a natureza do seu conjunto de dados. Um tamanho de bloco menor geralmente é melhor para conjuntos de dados com fatos diretos e menos contexto, enquanto um tamanho de bloco maior pode ser benéfico para mais informações contextuais, embora possa afetar o desempenho da recuperação.
Um pedaço pequeno como 256 produz pedaços mais granulares. Esse tamanho também significa que o modelo utilizará menos tokens para gerar sua saída (a menos que o número de documentos recuperados seja muito alto), potencialmente custando menos. Pedaços menores também significam que o modelo não precisa processar e interpretar seções longas de texto, reduzindo o ruído e a distração. Esta granularidade e foco, no entanto, representam um problema potencial. Informações importantes podem não estar entre os principais blocos recuperados, especialmente se o número de documentos recuperados estiver definido como um valor baixo, como 3.
Gorjeta
Lembre-se de que alterar o tamanho do bloco requer que seus documentos sejam reingeridos, por isso é útil primeiro ajustar os parâmetros de tempo de execução, como rigor e o número de documentos recuperados. Considere alterar o tamanho do bloco se ainda não estiver obtendo os resultados desejados:
- Se você estiver encontrando um grande número de respostas, como "Não sei" para perguntas com respostas que deveriam estar em seus documentos, considere reduzir o tamanho do bloco para 256 ou 512 para melhorar a granularidade.
- Se o chatbot estiver fornecendo alguns detalhes corretos, mas faltando outros, o que se torna aparente nas citações, aumentar o tamanho do bloco para 1.536 pode ajudar a capturar mais informações contextuais.
Runtime parameters (Parâmetros de runtime)
Você pode modificar as seguintes configurações adicionais na seção Parâmetros de dados no portal do Azure AI Foundry e na API. Você não precisa reingest seus dados quando atualizar esses parâmetros.
| Nome do parâmetro | Description |
|---|---|
| Limitar as respostas aos seus dados | Esse sinalizador configura a abordagem do chatbot para lidar com consultas não relacionadas à fonte de dados ou quando os documentos de pesquisa são insuficientes para uma resposta completa. Quando essa configuração é desativada, o modelo complementa suas respostas com seu próprio conhecimento, além de seus documentos. Quando essa configuração está ativada, o modelo tenta confiar apenas em seus documentos para obter respostas. Este é o inScope parâmetro na API e definido como true por padrão. |
| Documentos recuperados | Este parâmetro é um número inteiro que pode ser definido como 3, 5, 10 ou 20 e controla o número de blocos de documento fornecidos ao modelo de linguagem grande para formular a resposta final. Por padrão, isso é definido como 5. O processo de pesquisa pode ser barulhento e, às vezes, devido ao fragmentamento, informações relevantes podem ser espalhadas por vários blocos no índice de pesquisa. Selecionar um número de topo K, como 5, garante que o modelo possa extrair informações relevantes, apesar das limitações inerentes de pesquisa e fragmentação. No entanto, aumentar o número muito alto pode distrair o modelo. Além disso, o número máximo de documentos que podem ser efetivamente usados depende da versão do modelo, pois cada um tem um tamanho de contexto diferente e capacidade para lidar com documentos. Se você achar que as respostas estão faltando contexto importante, tente aumentar esse parâmetro. Este é o topNDocuments parâmetro na API e é 5 por padrão. |
| Rigor | Determina a agressividade do sistema na filtragem de documentos de pesquisa com base em suas pontuações de similaridade. O sistema consulta a Pesquisa do Azure ou outros armazenamentos de documentos e, em seguida, decide quais documentos fornecer a modelos de linguagem grandes, como o ChatGPT. Filtrar documentos irrelevantes pode melhorar significativamente o desempenho do chatbot de ponta a ponta. Alguns documentos são excluídos dos resultados do top-K se tiverem baixas pontuações de similaridade antes de serem encaminhados para o modelo. Isso é controlado por um valor inteiro que varia de 1 a 5. Definir esse valor como 1 significa que o sistema filtrará minimamente os documentos com base na semelhança da pesquisa com a consulta do usuário. Por outro lado, uma configuração de 5 indica que o sistema filtrará agressivamente os documentos, aplicando um limite de similaridade muito alto. Se você achar que o chatbot omite informações relevantes, diminua o rigor do filtro (defina o valor mais próximo de 1) para incluir mais documentos. Por outro lado, se documentos irrelevantes distraírem as respostas, aumente o limite (defina o valor mais próximo de 5). Este é o strictness parâmetro na API e definido como 3 por padrão. |
Referências não citadas
É possível que o modelo retorne "TYPE":"UNCITED_REFERENCE" em vez de "TYPE":CONTENT na API para documentos recuperados da fonte de dados, mas não incluídos na citação. Isso pode ser útil para depuração, e você pode controlar esse comportamento modificando o rigor e os parâmetros de tempo de execução de documentos recuperados descritos acima.
Mensagem do sistema
Você pode definir uma mensagem do sistema para orientar a resposta do modelo ao usar o Azure OpenAI On Your Data. Esta mensagem permite que você personalize suas respostas sobre o padrão de geração aumentada de recuperação (RAG) que o Azure OpenAI On Your Data usa. A mensagem do sistema é usada além de um prompt de base interno para fornecer a experiência. Para dar suporte a isso, truncamos a mensagem do sistema após um número específico de tokens para garantir que o modelo possa responder a perguntas usando seus dados. Se você estiver definindo um comportamento extra sobre a experiência padrão, certifique-se de que o prompt do sistema seja detalhado e explique exatamente a personalização esperada.
Depois de selecionar adicionar seu conjunto de dados, você pode usar a seção Mensagem do sistema no portal do Azure AI Foundry ou o role_informationparâmetro na API.

Padrões de utilização potenciais
Definir uma função
Você pode definir uma função que deseja que seu assistente. Por exemplo, se você estiver criando um bot de suporte, poderá adicionar "Você é um assistente especializado de suporte a incidentes que ajuda os usuários a resolver novos problemas".
Definir o tipo de dados que estão sendo recuperados
Também pode adicionar a natureza dos dados que está a fornecer ao assistente.
- Defina o tópico ou o escopo do seu conjunto de dados, como "relatório financeiro", "artigo acadêmico" ou "relatório de incidente". Por exemplo, para suporte técnico, você pode adicionar "Você responde a consultas usando informações de incidentes semelhantes nos documentos recuperados".
- Se os seus dados tiverem determinadas características, pode adicionar estes detalhes à mensagem do sistema. Por exemplo, se seus documentos estiverem em japonês, você pode adicionar "Você recupera documentos japoneses e deve lê-los cuidadosamente em japonês e responder em japonês".
- Se seus documentos incluírem dados estruturados, como tabelas de um relatório financeiro, você também poderá adicionar esse fato ao prompt do sistema. Por exemplo, se seus dados tiverem tabelas, você pode adicionar "Você recebe dados na forma de tabelas referentes a resultados financeiros e deve ler a tabela linha por linha para executar cálculos para responder às perguntas do usuário".
Definir o estilo de saída
Você também pode alterar a saída do modelo definindo uma mensagem do sistema. Por exemplo, se você quiser garantir que as respostas do assistente estejam em francês, você pode adicionar um prompt como "Você é um assistente de IA que ajuda os usuários que entendem francês a encontrar informações. As perguntas dos utilizadores podem ser formuladas em inglês ou francês. Por favor, leia atentamente os documentos recuperados e responda-os em francês. Por favor, traduza o conhecimento dos documentos para o francês para garantir que todas as respostas estejam em francês."
Reafirmar o comportamento crítico
O Azure OpenAI On Your Data funciona enviando instruções para um modelo de linguagem grande na forma de prompts para responder a consultas do usuário usando seus dados. Se houver um determinado comportamento que é crítico para o aplicativo, você pode repetir o comportamento na mensagem do sistema para aumentar sua precisão. Por exemplo, para orientar o modelo a responder apenas a partir de documentos, você pode adicionar "Por favor, responda usando apenas documentos recuperados e sem usar seu conhecimento. Por favor, gere citações para documentos recuperados para cada reivindicação em sua resposta. Se a pergunta do usuário não puder ser respondida usando documentos recuperados, explique o motivo pelo qual os documentos são relevantes para as consultas do usuário. Em qualquer caso, não responda usando seu próprio conhecimento."
Truques de engenharia rápidos
Há muitos truques na engenharia de prompt que você pode tentar melhorar a saída. Um exemplo é o aviso em cadeia de pensamento, onde você pode adicionar "Vamos pensar passo a passo sobre as informações em documentos recuperados para responder às perguntas dos usuários. Extraia conhecimento relevante para as consultas dos usuários a partir de documentos passo a passo e forme uma resposta de baixo para cima a partir das informações extraídas de documentos relevantes."
Nota
A mensagem do sistema é usada para modificar como o assistente GPT responde a uma pergunta do usuário com base na documentação recuperada. Isso não afeta o processo de recuperação. Se você quiser fornecer instruções para o processo de recuperação, é melhor incluí-las nas perguntas. A mensagem do sistema é apenas orientação. O modelo pode não aderir a todas as instruções especificadas porque foi preparado com certos comportamentos, como objetividade e evitar declarações controversas. Comportamento inesperado pode ocorrer se a mensagem do sistema contradiz com esses comportamentos.
Resposta máxima
Defina um limite para o número de tokens por resposta do modelo. O limite superior para o Azure OpenAI On Your Data é 1500. Isso equivale a definir o max_tokens parâmetro na API.
Limitar as respostas aos seus dados
Essa opção incentiva o modelo a responder usando apenas seus dados e é selecionada por padrão. Se você desmarcar essa opção, o modelo poderá aplicar mais prontamente seu conhecimento interno para responder. Determine a seleção correta com base no seu caso de uso e cenário.
Interagindo com o modelo
Use as práticas a seguir para obter melhores resultados ao conversar com o modelo.
Histórico de conversas
- Antes de iniciar uma nova conversa (ou fazer uma pergunta que não esteja relacionada com as anteriores), limpe o histórico de chat.
- A obtenção de respostas diferentes para a mesma pergunta entre o primeiro turno de conversação e os turnos subsequentes pode ser esperada porque o histórico de conversas altera o estado atual do modelo. Se você receber respostas incorretas, reporte-o como um bug de qualidade.
Modelo de resposta
Se você não estiver satisfeito com a resposta do modelo para uma pergunta específica, tente tornar a pergunta mais específica ou mais genérica para ver como o modelo responde e reformule sua pergunta de acordo.
O estímulo da cadeia de pensamento tem se mostrado eficaz para fazer com que o modelo produza os resultados desejados para perguntas/tarefas complexas.
Comprimento da pergunta
Evite fazer perguntas longas e divida-as em várias perguntas, se possível. Os modelos GPT têm limites no número de tokens que podem aceitar. Os limites de token são contados para: a pergunta do usuário, a mensagem do sistema, os documentos de pesquisa recuperados (partes), prompts internos, o histórico de conversas (se houver) e a resposta. Se a pergunta exceder o limite de token, ela será truncada.
Suporte multilingue
Atualmente, a pesquisa por palavra-chave e a pesquisa semântica no Azure OpenAI On Your Data dão suporte a consultas no mesmo idioma que os dados no índice. Por exemplo, se seus dados estiverem em japonês, as consultas de entrada também precisarão estar em japonês. Para a recuperação de documentos multilingues, recomendamos a criação do índice com a pesquisa vetorial ativada.
Para ajudar a melhorar a qualidade da recuperação de informações e da resposta do modelo, recomendamos habilitar a pesquisa semântica para os seguintes idiomas: inglês, francês, espanhol, português, italiano, alemão, chinês (zh), japonês, coreano, russo, árabe
Recomendamos o uso de uma mensagem do sistema para informar o modelo de que seus dados estão em outro idioma. Por exemplo:
*"*Você é um assistente de IA projetado para ajudar os usuários a extrair informações de documentos japoneses recuperados. Por favor, examine cuidadosamente os documentos japoneses antes de formular uma resposta. A consulta do usuário estará em japonês, e você deve responder também em japonês."
Se você tiver documentos em vários idiomas, recomendamos criar um novo índice para cada idioma e conectá-los separadamente ao Azure OpenAI.
Transmissão em fluxo de dados
Você pode enviar uma solicitação de streaming usando o stream parâmetro, permitindo que os dados sejam enviados e recebidos incrementalmente, sem esperar pela resposta completa da API. Isso pode melhorar o desempenho e a experiência do usuário, especialmente para dados grandes ou dinâmicos.
{
"stream": true,
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "'$AZURE_AI_SEARCH_ENDPOINT'",
"key": "'$AZURE_AI_SEARCH_API_KEY'",
"indexName": "'$AZURE_AI_SEARCH_INDEX'"
}
}
],
"messages": [
{
"role": "user",
"content": "What are the differences between Azure Machine Learning and Azure AI services?"
}
]
}
Histórico de conversas para melhores resultados
Quando você conversa com um modelo, fornecer um histórico do bate-papo ajudará o modelo a retornar resultados de maior qualidade. Você não precisa incluir a propriedade das mensagens do assistente em suas solicitações de API para melhorar a context qualidade da resposta. Consulte a documentação de referência da API para obter exemplos.
Chamada de função
Alguns modelos do Azure OpenAI permitem definir ferramentas e tool_choice parâmetros para habilitar a chamada de função. Você pode configurar a chamada de função através da API/chat/completionsREST. Se ambas as tools fontes de dados estiverem na solicitação, a política a seguir será aplicada.
- Se
tool_choicefornone, as ferramentas são ignoradas e apenas as fontes de dados são usadas para gerar a resposta. - Caso contrário, se
tool_choicenão for especificado, ou especificado comoautoou um objeto, as fontes de dados serão ignoradas e a resposta conterá o nome das funções selecionadas e os argumentos, se houver. Mesmo que o modelo decida que nenhuma função é selecionada, as fontes de dados ainda são ignoradas.
Se a política acima não atender às suas necessidades, considere outras opções, por exemplo: fluxo imediato ou API de assistentes.
Estimativa de uso de token para o Azure OpenAI On Your Data
O Azure OpenAI On Your Data Retrieval Augmented Generation (RAG) é um serviço que aproveita um serviço de pesquisa (como o Azure AI Search) e a geração (modelos do Azure OpenAI) para permitir que os usuários obtenham respostas para suas perguntas com base nos dados fornecidos.
Como parte desse pipeline RAG, há três etapas em um alto nível:
Reformular a consulta do usuário em uma lista de intenções de pesquisa. Isso é feito fazendo uma chamada para o modelo com um prompt que inclui instruções, a pergunta do usuário e o histórico de conversas. Vamos chamar isso de prompt de intenção.
Para cada intenção, vários blocos de documentos são recuperados do serviço de pesquisa. Depois de filtrar blocos irrelevantes com base no limite de rigor especificado pelo usuário e reclassificar/agregar os blocos com base na lógica interna, o número especificado pelo usuário de blocos de documento é escolhido.
Esses blocos de documento, juntamente com a pergunta do usuário, histórico de conversas, informações de função e instruções, são enviados ao modelo para gerar a resposta final do modelo. Vamos chamar isso de prompt de geração.
No total, são feitas duas chamadas para o modelo:
Para processar a intenção: A estimativa de token para o prompt de intenção inclui aquelas para a pergunta do usuário, o histórico de conversas e as instruções enviadas ao modelo para geração de intenção.
Para gerar a resposta: A estimativa de token para o prompt de geração inclui aqueles para a pergunta do usuário, histórico de conversas, a lista recuperada de partes do documento, informações de função e as instruções enviadas a ele para geração.
Os tokens de saída gerados pelo modelo (intenções e respostas) precisam ser levados em conta para a estimativa total do token. Somando todas as quatro colunas abaixo, obtém-se a média total de tokens usados para gerar uma resposta.
| Modelo | Contagem de tokens de prompt de geração | Contagem de tokens de prompt de intenção | Contagem de tokens de resposta | Contagem de tokens de intenção |
|---|---|---|---|---|
| GPT-35-Turbo-16K | 4297 | 1366 | 111 | 25 |
| GPT-4-0613 | 3997 | 1385 | 118 | 18 |
| gpt-4-1106-pré-visualização | 4538 | 811 | 119 | 27 |
| GPT-35-Turbo-1106 | 4854 | 1372 | 110 | 26 |
Os números acima são baseados em testes em um conjunto de dados com:
- 191 conversas
- 250 questões
- 10 tokens médios por pergunta
- 4 voltas de conversação por conversa, em média
E os seguintes parâmetros.
| Definição | Value |
|---|---|
| Número de documentos recuperados | 5 |
| Rigor | 3 |
| Tamanho do bloco | 1024 |
| Limitar as respostas aos dados ingeridos? | True |
Estas estimativas variam com base nos valores definidos para os parâmetros acima. Por exemplo, se o número de documentos recuperados for definido como 10 e o rigor for definido como 1, a contagem de tokens aumentará. Se as respostas retornadas não se limitarem aos dados ingeridos, haverá menos instruções dadas ao modelo e o número de tokens diminuirá.
As estimativas dependem igualmente da natureza dos documentos e das perguntas colocadas. Por exemplo, se as perguntas forem abertas, é provável que as respostas sejam mais longas. Da mesma forma, uma mensagem de sistema mais longa contribuiria para um prompt mais longo que consome mais tokens e, se o histórico de conversas for longo, o prompt será mais longo.
| Modelo | Max tokens para mensagem do sistema |
|---|---|
| GPT-35-0301 | 400 |
| GPT-35-0613-16K | 1000 |
| GPT-4-0613-8K | 400 |
| GPT-4-0613-32K | 2000 |
| GPT-35-turbo-0125 | 2000 |
| GPT-4-turbo-0409 | 4000 |
| GPT-4O | 4000 |
| GPT-4o-mini | 4000 |
A tabela acima mostra o número máximo de tokens que podem ser usados para a mensagem do sistema. Para ver o máximo de tokens para a resposta do modelo, consulte o artigo modelos. Além disso, os seguintes também consomem tokens:
O prompt meta: se você limitar as respostas do modelo ao conteúdo de dados de aterramento (
inScope=Truena API), o número máximo de tokens será maior. Caso contrário (por exemplo, seinScope=False) o máximo é menor. Esse número é variável dependendo do comprimento do token da pergunta do usuário e do histórico de conversas. Essa estimativa inclui o prompt base e os prompts de reconfiguração de consulta para recuperação.Pergunta do usuário e histórico: Variável, mas limitado a 2.000 tokens.
Documentos recuperados (partes): O número de tokens usados pelos blocos de documentos recuperados depende de vários fatores. O limite superior para isso é o número de blocos de documentos recuperados multiplicado pelo tamanho do bloco. No entanto, ele será truncado com base nos tokens disponíveis para o modelo específico que está sendo usado após a contagem do resto dos campos.
20% dos tokens disponíveis são reservados para a resposta do modelo. Os 80% restantes dos tokens disponíveis incluem o meta prompt, a pergunta do usuário e o histórico de conversas e a mensagem do sistema. O orçamento de token restante é usado pelos blocos de documento recuperados.
Para calcular o número de tokens consumidos pela sua entrada (como sua pergunta, as informações de mensagem/função do sistema), use o exemplo de código a seguir.
import tiktoken
class TokenEstimator(object):
GPT2_TOKENIZER = tiktoken.get_encoding("gpt2")
def estimate_tokens(self, text: str) -> int:
return len(self.GPT2_TOKENIZER.encode(text))
token_output = TokenEstimator.estimate_tokens(input_text)
Resolução de Problemas
Para solucionar problemas de operações com falha, esteja sempre atento a erros ou avisos especificados na resposta da API ou no portal do Azure AI Foundry. Aqui estão alguns dos erros e avisos comuns:
Trabalhos de ingestão falhados
Problemas de limitações de cota
Não foi possível criar um índice com o nome X no serviço Y. A quota de índice foi excedida para este serviço. Você deve excluir índices não utilizados primeiro, adicionar um atraso entre as solicitações de criação de índice ou atualizar o serviço para limites mais altos.
A quota de indexador padrão de X foi excedida para este serviço. Atualmente, você tem indexadores padrão X. Você deve excluir indexadores não utilizados primeiro, alterar o indexador 'executionMode' ou atualizar o serviço para limites mais altos.
Resolução:
Atualize para um nível de preço mais alto ou exclua ativos não utilizados.
Problemas de tempo limite de pré-processamento
Não foi possível executar a habilidade porque a solicitação da API da Web falhou
Não foi possível executar a habilidade porque a resposta da habilidade da API da Web é inválida
Resolução:
Divida os documentos de entrada em documentos menores e tente novamente.
Problemas de Permissões
Esta solicitação não está autorizada a executar esta operação
Resolução:
Isso significa que a conta de armazenamento não está acessível com as credenciais fornecidas. Nesse caso, revise as credenciais da conta de armazenamento passadas para a API e verifique se a conta de armazenamento não está oculta atrás de um ponto de extremidade privado (se um ponto de extremidade privado não estiver configurado para este recurso).
503 erros ao enviar consultas com o Azure AI Search
Cada mensagem de usuário pode se traduzir em várias consultas de pesquisa, todas as quais são enviadas para o recurso de pesquisa em paralelo. Isso pode produzir um comportamento de limitação quando o número de réplicas e partições de pesquisa é baixo. O número máximo de consultas por segundo que uma única partição e uma única réplica podem suportar pode não ser suficiente. Nesse caso, considere aumentar suas réplicas e partições ou adicionar lógica de suspensão/repetição em seu aplicativo. Consulte a documentação do Azure AI Search para obter mais informações.
Disponibilidade regional e suporte a modelos
| País/Região | gpt-35-turbo-16k (0613) |
gpt-35-turbo (1106) |
gpt-4-32k (0613) |
gpt-4 (1106-preview) |
gpt-4 (0125-preview) |
gpt-4 (0613) |
gpt-4o** |
gpt-4 (turbo-2024-04-09) |
|---|---|---|---|---|---|---|---|---|
| Leste da Austrália | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Leste do Canadá | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| E.U.A. Leste | ✅ | ✅ | ✅ | |||||
| E.U.A. Leste 2 | ✅ | ✅ | ✅ | ✅ | ||||
| França Central | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Leste do Japão | ✅ | |||||||
| E.U.A. Centro-Norte | ✅ | ✅ | ✅ | |||||
| Leste da Noruega | ✅ | ✅ | ||||||
| E.U.A. Centro-Sul | ✅ | ✅ | ||||||
| Sul da Índia | ✅ | ✅ | ||||||
| Suécia Central | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| Norte da Suíça | ✅ | ✅ | ✅ | |||||
| Sul do Reino Unido | ✅ | ✅ | ✅ | ✅ | ||||
| E.U.A. Oeste | ✅ | ✅ | ✅ |
**Esta é uma implementação somente texto
Se seu recurso do Azure OpenAI estiver em outra região, você não poderá usar o Azure OpenAI em seus dados.