Implantação e teste para cargas de trabalho de missão crítica no Azure
A implantação e o teste do ambiente de missão crítica são uma peça crucial da arquitetura de referência geral. Os carimbos de aplicativo individuais são implantados usando a infraestrutura como código de um repositório de código-fonte. As atualizações da infraestrutura e da aplicação sobre ela devem ser implantadas com zero tempo de inatividade para a aplicação. Um pipeline de integração contínua de DevOps é recomendado para recuperar o código-fonte do repositório e implantar os carimbos individuais no Azure.
A implantação e as atualizações são o processo central na arquitetura. As atualizações relacionadas à infraestrutura e aos aplicativos devem ser implantadas em selos totalmente independentes. Somente os componentes de infraestrutura global na arquitetura são compartilhados entre os selos. Os carimbos existentes na infraestrutura não são alterados. As atualizações de infraestrutura são implantadas nesses novos selos. Da mesma forma, as novas versões do aplicativo são implantadas nesses novos selos.
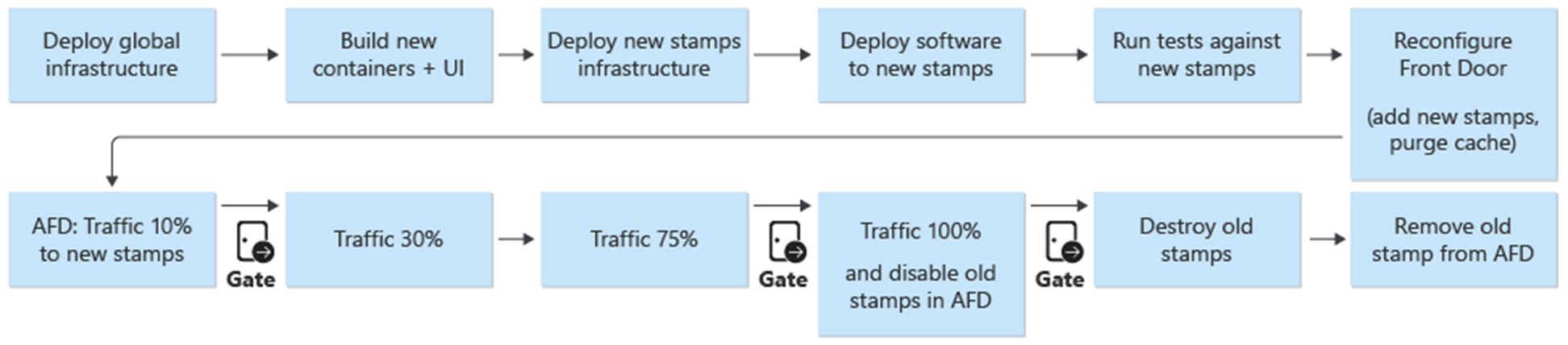
Os novos carimbos são adicionados ao Azure Front Door. O tráfego é gradualmente transferido para os novos selos. Quando o tráfego é servido a partir dos novos selos sem emissão, os carimbos anteriores são excluídos.
Testes de penetração, caos e estresse são recomendados para o ambiente implantado. O teste proativo da infraestrutura deteta pontos fracos e como o aplicativo implantado se comporta se houver uma falha.
Implantação
A implantação da infraestrutura na arquitetura de referência depende dos seguintes processos e componentes:
DevOps - O código-fonte do GitHub e os pipelines para a infraestrutura.
Atualizações de zero tempo de inatividade - As atualizações e upgrades são implementados no ambiente sem interrupção para a aplicação implantada.
Ambientes - Ambientes de curta duração e permanentes utilizados para a arquitetura.
Recursos compartilhados e dedicados - Recursos do Azure que são dedicados e compartilhados para os carimbos e a infraestrutura geral.
Para obter mais informações, consulte Implantação e teste para cargas de trabalho de missão crítica no Azure: considerações de design
Implantação: DevOps
Os componentes de DevOps fornecem o repositório de código-fonte e pipelines de CI/CD para implantação da infraestrutura e atualizações. O GitHub e o Azure Pipelines foram escolhidos como componentes.
GitHub - Contém os repositórios de código-fonte para o aplicativo e a infraestrutura.
Azure Pipelines - Os pipelines usados pela arquitetura para todas as tarefas de compilação, teste e lançamento.
Um componente extra no design usado para a implantação são os agentes de compilação. Os agentes de compilação hospedados pela Microsoft são usados como parte dos Pipelines do Azure para implantar a infraestrutura e as atualizações. O uso de agentes de compilação hospedados pela Microsoft remove a carga de gerenciamento para os desenvolvedores manterem e atualizarem o agente de compilação.
Para obter mais informações sobre o Azure Pipelines, consulte O que é o Azure Pipelines?.

Para obter mais informações, consulte Implantação e teste para cargas de trabalho de missão crítica no Azure: implantações de infraestrutura como código
Implantação: atualizações sem interrupção
A estratégia de atualização sem interrupções na arquitetura de referência é fundamental para a aplicação de missão crítica geral. A metodologia de substituição em vez de atualização dos selos garante uma nova instalação do aplicativo em um selo de infraestrutura. A arquitetura de referência utiliza uma abordagem azul/verde e permite ambientes de teste e desenvolvimento separados.
Existem dois componentes principais da arquitetura de referência:
Infrastructure - Serviços e recursos do Azure. Implantado com o Terraform e a sua configuração associada.
Application - O serviço hospedado ou aplicativo que atende aos usuários. Com base em contêineres do Docker e npm construiu artefatos em HTML e JavaScript para a interface do usuário do aplicativo de página única (SPA).
Em muitos sistemas, há uma suposição de que as atualizações de aplicativos são mais frequentes do que as atualizações de infraestrutura. Como resultado, diferentes procedimentos de atualização são desenvolvidos para cada um. Com uma infraestrutura de nuvem pública, as mudanças podem acontecer em um ritmo mais rápido. Foi escolhido um processo de implantação para atualizações de aplicativos e atualizações de infraestrutura. Uma abordagem garante que as atualizações de infraestrutura e aplicativos estejam sempre sincronizadas. Esta abordagem permite:
Um processo consistente - Menos chances de erros se as atualizações de infraestrutura e aplicativo forem misturadas em uma versão, intencionalmente ou não.
Habilita a implantação Blue/Green - Cada atualização é implementada usando uma migração gradual de tráfego para a nova versão.
Implantação e depuração mais fáceis do do aplicativo - O carimbo inteiro nunca hospeda várias versões do aplicativo lado a lado.
Reversão simples - O tráfego pode ser redirecionado para as versões que executam a anterior, caso sejam encontrados erros ou problemas.
Eliminação de alterações manuais e desvios de configuração - Cada ambiente é uma nova implantação.
Para obter mais informações, consulte Implantação e teste para cargas de trabalho de missão crítica no Azure: implantações azuis/verdes efêmeras
Estratégia de ramificação
A base da estratégia de atualização é o uso de ramificações dentro do repositório Git. A arquitetura de referência usa três tipos de ramificações:
| Sucursal | Descrição |
|---|---|
feature/* e fix/* |
Os pontos de entrada para qualquer alteração. Os desenvolvedores criam essas ramificações e devem receber um nome descritivo, como feature/catalog-update ou fix/worker-timeout-bug. Quando as alterações estão prontas para serem mescladas, uma solicitação pull (PR) contra a ramificação main é criada. Pelo menos um revisor deve aprovar todos os pull requests. Com exceções limitadas, todas as alterações propostas em um RP devem passar pelo pipeline de validação de ponta a ponta (E2E). Os desenvolvedores devem usar o pipeline E2E para testar e depurar alterações em um ambiente completo. |
main |
O ramo que avança continuamente e é estável. Usado principalmente para testes de integração. As alterações ao main são feitas apenas por meio de solicitações de pull. Uma política de ramo proíbe as gravações diretas. As liberações noturnas no ambiente de integration (int) permanente são executadas automaticamente a partir da ramificação main. O ramo main é considerado estável. Deve ser seguro assumir que, a qualquer momento, um lançamento pode ser criado a partir disso. |
release/* |
As ramificações de liberação são criadas apenas a partir da ramificação main. As ramificações seguem o formato release/2021.7.X. As políticas de ramificação são usadas para que apenas os administradores de repositório tenham permissão para criar release/* ramificações. Somente essas ramificações são usadas para implantar no ambiente prod. |
Para obter mais informações, consulte Implantação e teste para cargas de trabalho críticas para a missão no Azure: estratégia de ramificação
Correções Rápidas
Quando um hotfix é necessário com urgência devido a um bug ou outro problema e não pode passar pelo processo de lançamento regular, um caminho de hotfix está disponível. Atualizações de segurança críticas e correções para a experiência do usuário que não foram descobertas durante o teste inicial são consideradas exemplos válidos de hotfixes.
O hotfix deve ser criado em uma nova ramificação fix e, em seguida, mesclado em main usando uma RP regular. Em vez de criar uma nova ramificação de versão, o hotfix é "escolhido a dedo" em uma ramificação de versão existente. Essa ramificação já está implantada no ambiente prod. O pipeline de CI/CD que originalmente implantou a ramificação de versão com todos os testes é executado novamente e implanta o hotfix como parte do pipeline.
Para evitar problemas maiores, é importante que o hotfix contenha algumas confirmações isoladas que podem ser facilmente selecionadas e integradas no ramo de lançamento. Se confirmações isoladas não puderem ser escolhidas a dedo para integração na ramificação de versão, é uma indicação de que a alteração não se qualifica como um hotfix. Implante a alteração como uma nova versão completa. Combine-o com uma reversão para uma versão estável anterior até que a nova versão possa ser implantada.
Implantação: Ambientes
A arquitetura de referência usa dois tipos de ambientes para a infraestrutura:
De curta duração - O pipeline de validação E2E é utilizado para implantar ambientes temporários. Ambientes de curta duração são usados para ambientes puros de validação ou depuração para desenvolvedores. Os ambientes de validação podem ser criados a partir da ramificação
feature/*, submetidos a testes e, em seguida, destruídos se todos os testes forem bem-sucedidos. Os ambientes de depuração são implantados da mesma forma que a validação, mas não são destruídos imediatamente. Esses ambientes não devem existir por mais do que alguns dias e devem ser excluídos quando o PR correspondente da ramificação do recurso é mesclado.Permanente - Nos ambientes permanentes existem versões
integration (int)eproduction (prod). Esses ambientes vivem continuamente e não são destruídos. Os ambientes usam nomes de domínio fixos comoint.mission-critical.app. Em uma implementação do mundo real da arquitetura de referência, um ambientestaging(preprod) deve ser adicionado. O ambientestagingé utilizado para implementar e validar as branchesreleasecom o mesmo processo de atualização doprod(deployment Blue/Green).Integration (int) - A versão
inté implantada todas as noites a partir da ramificaçãomaincom o mesmo processo queprod. A transição de tráfego é mais rápida do que a unidade de lançamento anterior. Em vez de alternar gradualmente o tráfego ao longo de vários dias, como noprod, o processo parainté concluído em poucos minutos ou horas. Essa transição mais rápida garante que o ambiente atualizado esteja pronto na manhã seguinte. Os carimbos antigos são excluídos automaticamente se todos os testes no pipeline forem bem-sucedidos.Production (prod) - A versão
prodsó é implementada a partir de ramificaçõesrelease/*. A comutação de tráfego usa etapas mais granulares. Uma porta de aprovação manual está entre cada etapa. Cada versão cria novos selos regionais e implanta a nova versão do aplicativo nos selos. Os selos existentes não são alterados no processo. A consideração mais importante paraprodé que ele deve ser "sempre ligado". Nenhum tempo de inatividade planejado ou não planejado deve ocorrer. A única exceção são as alterações fundamentais na camada de banco de dados. Poderá ser necessária uma janela de manutenção planeada.
Implantação: recursos compartilhados e dedicados
Os ambientes permanentes (int e prod) dentro da arquitetura de referência têm diferentes tipos de recursos, dependendo se eles são compartilhados com toda a infraestrutura ou dedicados a um selo individual. Os recursos podem ser dedicados a uma versão específica e existem apenas até que a próxima unidade de versão assuma o controle.
Unidades de liberação
Uma unidade de lançamento é composta por vários selos regionais por versão de lançamento específica. Os selos contêm todos os recursos que não são compartilhados com os outros selos. Esses recursos são redes virtuais, cluster do Serviço Kubernetes do Azure, Hubs de Eventos e Cofre de Chaves do Azure. O Azure Cosmos DB e o ACR são configurados com fontes de dados Terraform.
Recursos partilhados globalmente
Todos os recursos compartilhados entre as unidades de liberação são definidos em um modelo Terraform independente. Esses recursos são Front Door, Azure Cosmos DB, Registro de contêiner (ACR) e os espaços de trabalho do Log Analytics e outros recursos relacionados ao monitoramento. Esses recursos são implantados antes que o primeiro carimbo regional de uma unidade de liberação seja implantado. Os recursos são referenciados nos modelos Terraform para os selos.
Porta da frente
Embora o Front Door seja um recurso compartilhado globalmente entre selos, sua configuração é ligeiramente diferente dos outros recursos globais. A porta frontal deve ser reconfigurada após a implantação de um novo carimbo. A porta da frente deve ser reconfigurada para mudar gradualmente o tráfego para os novos selos.
A configuração de back-end do Front Door não pode ser definida diretamente no modelo Terraform. A configuração é inserida com as variáveis do Terraform. Os valores das variáveis são construídos antes do início da implantação do Terraform.
A configuração de componente individual para a implantação da Front Door é definida como:
Frontend - A afinidade de sessão é configurada para garantir que os utilizadores não alternem entre diferentes versões da interface no decorrer de uma única sessão.
Origins - o Front Door está configurado com dois tipos de grupos de origem:
Um grupo de origem para armazenamento estático que serve a interface do usuário. O grupo contém as contas de armazenamento do site de todas as unidades de lançamento ativas no momento. Diferentes pesos podem ser atribuídos às origens de diferentes unidades de liberação para mover gradualmente o tráfego para uma unidade mais nova. Cada origem de uma unidade de liberação deve ter o mesmo peso atribuído.
Um grupo de origem para a API, que está hospedado no Serviço Kubernetes do Azure. Se houver unidades de liberação com diferentes versões de API, então um grupo de origem de API existe para cada unidade de versão. Se todas as unidades de lançamento oferecerem a mesma API compatível, todas as origens serão adicionadas ao mesmo grupo e receberão pesos diferentes.
Regras de roteamento - Existem dois tipos de regras de roteamento:
Uma regra de encaminhamento para a IU vinculada ao grupo de armazenamento de origem da IU.
Uma regra de roteamento para cada API atualmente suportada pelas origens. Por exemplo:
/api/1.0/*e/api/2.0/*.
Se uma versão introduzir uma nova versão das APIs de back-end, as alterações refletirão na interface do usuário implantada como parte da versão. Uma versão específica da interface do usuário sempre chama uma versão específica da URL da API. Os usuários atendidos por uma versão da interface do usuário usam automaticamente a respetiva API de back-end. São necessárias regras de roteamento específicas para diferentes instâncias da versão da API. Estas regras estão ligadas aos grupos de origem correspondentes. Se uma nova API não for introduzida, todas as regras de roteamento relacionadas à API serão vinculadas ao grupo de origem único. Nesse caso, não importa se um usuário recebe a interface do usuário de uma versão diferente da API.
Implantação: processo de implantação
Uma implantação azul/verde é o objetivo do processo de implantação. Uma nova versão de uma ramificação release/* é implantada no ambiente prod. O tráfego de usuários é gradualmente deslocado para os selos da nova versão.
Como primeiro passo no processo de implantação de uma nova versão, a infraestrutura para a nova unidade de lançamento é implantada com o Terraform. A execução do pipeline de implantação de infraestrutura implanta a nova infraestrutura a partir de uma ramificação de versão selecionada. Em paralelo ao provisionamento de infraestrutura, as imagens de contentor são criadas ou importadas e enviadas para o registro de contentor globalmente partilhado (ACR). Quando os processos anteriores são concluídos, o aplicativo é implantado nos selos. Do ponto de vista da implementação, é um pipeline com vários estágios dependentes. O mesmo pipeline pode ser reexecutado para implementações de hotfix.
Depois de a nova unidade de lançamento ser implantada e validada, a nova unidade é adicionada ao Front Door para receber o tráfego de utilizadores.
Um switch/parâmetro que distinga entre versões que introduzem e não introduzem uma nova versão da API deve ser planejado. Com base em se a versão introduzir uma nova versão da API, um novo grupo de origem com os back-ends da API deve ser criado. Como alternativa, novos back-ends de API podem ser adicionados a um grupo de origem existente. Novas contas de armazenamento da interface do usuário são adicionadas ao grupo de origem existente correspondente. Os pesos para novas origens devem ser definidos de acordo com a divisão desejada de tráfego. Uma nova regra de roteamento, conforme descrito anteriormente, deve ser criada que corresponda ao grupo de origem apropriado.
Como parte da adição da nova unidade de lançamento, os pesos das novas origens devem ser definidos para o tráfego mínimo de usuário desejado. Se nenhum problema for detetado, a quantidade de tráfego de usuário deve ser aumentada para o novo grupo de origem durante um período de tempo. Para ajustar os parâmetros de peso, as mesmas etapas de implantação devem ser executadas novamente com os valores desejados.
Desmontagem da unidade de liberação
Como parte do pipeline de implantação de uma unidade de liberação, há um estágio de destruição que remove todos os carimbos quando uma unidade de liberação não é mais necessária. Todo o tráfego é movido para a nova versão. Esta etapa inclui a remoção das referências da unidade de release da Front Door. Essa remoção é fundamental para permitir o lançamento de uma nova versão em uma data posterior. Front Door deve apontar para uma única unidade de lançamento, a fim de estar preparado para a próxima versão no futuro.
Listas de verificação
Como parte da cadência de lançamento, uma lista de verificação pré e pós-lançamento deve ser usada. O exemplo a seguir é de itens que devem estar em qualquer lista de verificação, no mínimo.
Lista de verificação de pré-lançamento - Antes de iniciar uma versão, verifique o seguinte:
Verifique se o estado mais recente da ramificação
mainfoi implantado e testado com êxito no ambienteint.Atualize o arquivo changelog por meio de um PR em relação à ramificação
main.Crie uma ramificação
release/a partir da ramificaçãomain.
Lista de verificação pós-lançamento - Antes que selos antigos sejam destruídos e suas referências sejam removidas da Front Door, verifique se:
Os clusters não estão mais recebendo tráfego de entrada.
Os Hubs de Eventos e outras filas de mensagens não contêm mensagens não processadas.
Implantação: Limitações e riscos da estratégia de atualização
A estratégia de atualização descrita nesta arquitetura de referência tem algumas limitações e riscos que devem ser mencionados:
Custo mais alto - Ao lançar atualizações, muitos dos componentes de infraestrutura ficam ativos duas vezes durante o período de lançamento.
Complexidade do Front Door - O processo de atualização no Front Door é complexo de implementar e manter. A capacidade de executar implantações azuis/verdes eficazes com zero tempo de inatividade depende do funcionamento adequado.
Pequenas alterações demoradas - O processo de atualização resulta em um processo de liberação mais longo para pequenas alterações. Essa limitação pode ser parcialmente atenuada com o processo de hotfix descrito na seção anterior.
Implantação: considerações sobre compatibilidade futura de dados de aplicação
A estratégia de atualização pode suportar várias versões de uma API e componentes de trabalho executados simultaneamente. Como o Azure Cosmos DB é compartilhado entre duas ou mais versões, há uma possibilidade de que os elementos de dados alterados por uma versão nem sempre correspondam à versão da API ou aos trabalhadores que a consomem. As camadas de API e os trabalhadores devem implementar o design de compatibilidade direta. Versões anteriores da API ou componentes de trabalho processam dados inseridos por uma API posterior ou uma versão do componente de trabalho. Ignora partes que não compreende.
Testes
A arquitetura de referência contém diferentes testes usados em diferentes estágios dentro da implementação de teste.
Estes testes incluem:
Testes de unidade - Esses testes validam se a lógica de negócios do aplicativo funciona conforme o esperado. A arquitetura de referência contém um conjunto de exemplos de testes de unidade executados automaticamente antes de cada compilação de contêiner pelo Azure Pipelines. Se algum teste falhar, a pipeline interrompe-se. A compilação e a implantação são interrompidas. O desenvolvedor deve corrigir o problema antes que o pipeline possa ser executado novamente.
Testes de carga - Esses testes ajudam a avaliar a capacidade, a escalabilidade e os gargalos potenciais para uma determinada carga de trabalho ou pilha. A implementação de referência contém um gerador de carga do usuário para criar padrões de carga sintéticos que podem ser usados para simular o tráfego real. O gerador de carga também pode ser usado independentemente da implementação de referência.
Testes de fumaça - Esses testes identificam se a infraestrutura e a carga de trabalho estão disponíveis e agem conforme o esperado. Testes de fumaça são executados como parte de cada implantação.
testes de interface do usuário - Esses testes validam se a interface do usuário foi implantada e funciona conforme o esperado. A implementação atual captura apenas capturas de tela de várias páginas após a implantação, sem nenhum teste real.
Testes de injeção de falhas - Estes testes podem ser automatizados ou executados manualmente. O teste automatizado na arquitetura integra o Azure Chaos Studio como parte dos pipelines de implantação.
Para obter mais informações, consulte Implantação e teste para cargas de trabalho de missão crítica no Azure: validação e teste contínuos
Testagem: Frameworks
As capacidades de teste e frameworks da implementação de referência online existente devem ser utilizadas sempre que possível.
| Enquadramento | Teste | Descrição |
|---|---|---|
| NUnit | Unidade | Essa estrutura é usada para testar a unidade da parte .NET Core da implementação. O Azure Pipelines executa testes de unidade automaticamente antes das compilações de contêiner. |
| JMeter com o Azure Load Testing | Carregar | de Teste de Carga do Azure é um serviço gerenciado usado para executar definições de teste de carga do Apache JMeter. |
| Gafanhoto | Carregar | Locust é uma estrutura de teste de carga de código aberto escrita em Python. |
| Dramaturgia | Interface de Utilizador e Testes de Fumaça | Playwright é uma biblioteca de Node.js de código aberto para automatizar o Chromium, Firefox e WebKit com uma única API. A definição de teste do Playwright também pode ser usada independentemente da implementação de referência. |
| Azure Chaos Studio | Falha na injeção | A implementação de referência usa o Azure Chaos Studio como uma etapa opcional no pipeline de validação E2E para injetar falhas para validação de resiliência. |
Testes: Testes de injeção de falhas e Engenharia do Caos
Os aplicativos distribuídos devem ser resilientes a interrupções de serviços e componentes. O teste de injeção de falhas (também conhecido como injeção de falhas ou engenharia do caos) é a prática de submeter aplicativos e serviços a tensões e falhas do mundo real.
A resiliência é uma propriedade de todo um sistema e injetar falhas ajuda a encontrar problemas no aplicativo. Resolver esses problemas ajuda a validar a resiliência do aplicativo para condições não confiáveis, dependências ausentes e outros erros.
Testes manuais e automáticos podem ser executados na infraestrutura para encontrar falhas e problemas na implementação.
Automático
A arquitetura de referência integra do Azure Chaos Studio para implantar e executar um conjunto de experimentos do Azure Chaos Studio para injetar várias falhas no nível de carimbo. Os experimentos de caos podem ser executados como uma parte opcional do pipeline de implantação do E2E. Quando os testes são executados, o teste de carga opcional é sempre executado em paralelo. O teste de carga é usado para criar carga no cluster para validar o efeito das falhas injetadas.
Manual
O teste manual de injeção de falha deve ser feito em um ambiente de validação E2E. Este ambiente garante testes totalmente representativos sem risco de interferência de outros ambientes. A maioria das falhas geradas com os testes pode ser observada diretamente na visualização de métricas ao vivo do Application Insights. As falhas restantes estão disponíveis na visualização Falhas e nas tabelas de log correspondentes. Outras falhas exigem depuração mais profunda, como o uso de kubectl para observar o comportamento dentro do Serviço Kubernetes do Azure.
Dois exemplos de testes de injeção de falha realizados em relação à arquitetura de referência são:
DNS (Domain Name Service) - Injeção de Falhas Baseada em DNS - Um caso de teste que pode simular vários problemas. Falhas de resolução de DNS devido à falha de um servidor DNS ou do DNS do Azure. Os testes baseados em DNS podem ajudar a simular problemas gerais de conexões entre um cliente e um serviço, por exemplo, quando o BackgroundProcessor do
não consegue se conectar aos Hubs de Eventos. Em cenários de host único, você pode modificar o arquivo
hostslocal para substituir a resolução DNS. Em um ambiente maior com vários servidores dinâmicos como o AKS, um arquivohostsnão é viável. Zonas DNS Privadas do Azure podem ser usadas como uma alternativa para testar cenários de falha.Os Hubs de Eventos do Azure e o Azure Cosmos DB são dois dos serviços do Azure usados na implementação de referência que podem ser usados para injetar falhas baseadas em DNS. A resolução DNS dos Hubs de Eventos pode ser manipulada com uma zona DNS Privada do Azure vinculada à rede virtual de um dos selos. O Azure Cosmos DB é um serviço replicado globalmente com pontos de extremidade regionais específicos. A manipulação dos registros DNS para esses pontos de extremidade pode simular uma falha para uma região específica e testar o failover de clientes.
Bloqueio de firewall - A maioria dos serviços do Azure oferece suporte a restrições de acesso de firewall com base em redes virtuais e/ou endereços IP. Na infraestrutura de referência, essas restrições são usadas para restringir o acesso ao Azure Cosmos DB ou Hubs de Eventos. Um procedimento simples é remover regras existentes de Permitir ou adicionar novas regras de Bloquear. Este procedimento pode simular configurações incorretas de firewall ou interrupções de serviço.
Os seguintes serviços de exemplo na implementação de referência podem ser testados com um teste de firewall:
Serviço Resultado Key Vault Quando o acesso ao Key Vault é bloqueado, o efeito mais direto é a falha na criação de novos pods. O driver CSI do Key Vault que busca segredos na inicialização do pod não consegue executar as suas tarefas e impede o pod de iniciar. Mensagens de erro correspondentes podem ser observadas com kubectl describe po CatalogService-deploy-my-new-pod -n workload. Os pods existentes continuam a funcionar, ainda que a mesma mensagem de erro seja observada. Os resultados da verificação periódica de atualização de segredos geram a mensagem de erro. Embora não tenha sido testada, a execução de uma implantação não funciona enquanto o Cofre da Chave estiver inacessível. As tarefas Terraform e CLI do Azure durante a execução do pipeline fazem solicitações ao Cofre de Chaves.Hubs de Eventos Quando o acesso aos Hubs de Eventos é bloqueado, novas mensagens enviadas pelo CatalogService e pelo HealthService falham. As recuperações de mensagens pelo BackgroundProcess falham lentamente, com falha total em poucos minutos. Azure Cosmos DB A remoção da política de firewall existente para uma rede virtual leva a que o Serviço de Saúde comece a falhar com um atraso mínimo. Este procedimento simula apenas um caso específico, uma interrupção inteira do Azure Cosmos DB. A maioria dos casos de falha que ocorrem em nível regional são atenuados automaticamente com failover transparente do cliente para uma região diferente do Azure Cosmos DB. O teste de injeção de falha baseado em DNS descrito anteriormente é um teste mais significativo para o Azure Cosmos DB. Registro de contêiner (ACR) Quando o acesso ao ACR é bloqueado, a criação de novos pods que são transferidos e armazenados em cache anteriormente num nó AKS continua a funcionar. A criação ainda funciona devido ao K8s bandeira de implantação pullPolicy=IfNotPresent. Os nós não podem gerar um novo pod e falham imediatamente com erros deErrImagePullse o nó não puxar e armazenar em cache uma imagem antes do bloco.kubectl describe podexibe a mensagem correspondente de403 Forbidden.AKS ingress Load Balancer A alteração das regras de entrada para HTTP(S) (portas 80 e 443) no NSG (Network Security Group) gerido pelo AKS para Negar resulta na falha do tráfego de utilizadores ou das sondas de monitorização em alcançar o cluster. O teste desta falha é difícil de identificar a causa raiz, que foi simulada como bloqueio entre o caminho de rede da Front Door e um carimbo regional. O Front Door deteta imediatamente esta falha e retira o carimbo da rotação.