O que é o Azure Chaos Studio?
O Azure Chaos Studio é um serviço gerenciado que usa engenharia de caos para ajudá-lo a medir, entender e melhorar sua resiliência de aplicativos e serviços na nuvem. A engenharia do caos é uma metodologia pela qual você injeta falhas do mundo real em seu aplicativo para executar experimentos controlados de injeção de falhas.
Resiliência é a capacidade de um sistema de lidar e se recuperar de interrupções. As interrupções de aplicativos podem causar erros e falhas que podem afetar adversamente seus negócios ou missão. Quer esteja a desenvolver, migrar ou operar aplicações do Azure, é importante validar e melhorar a resiliência da sua aplicação.
O Chaos Studio ajuda você a evitar consequências negativas, validando que seu aplicativo responde efetivamente a interrupções e falhas. Você pode usar o Chaos Studio para testar a resiliência contra incidentes do mundo real, como interrupções ou alta utilização da CPU em máquinas virtuais (VMs).
O vídeo a seguir fornece mais informações sobre o Chaos Studio:
Cenários do Chaos Studio
Você pode usar a engenharia de caos para vários cenários de validação de resiliência que abrangem o ciclo de vida de operações e desenvolvimento de serviços. Existem dois tipos de cenários:
- Deslocar para a direita: estes cenários utilizam um ambiente de produção ou de pré-produção. Normalmente, você faz cenários de turno certo com tráfego real de clientes ou carga simulada.
- Deslocar para a esquerda: esses cenários podem usar um ambiente de desenvolvimento ou de teste compartilhado. Você pode fazer cenários de deslocamento para a esquerda sem qualquer tráfego real de clientes.
Você pode usar o Chaos Studio para os seguintes cenários comuns de engenharia de caos:
- Reproduza um incidente que afetou seu aplicativo para entender melhor a falha. Certifique-se de que os reparos pós-incidente evitem que o incidente se repita.
- Prepare-se para um grande evento ou temporada com a validação de carga, escala, desempenho e resiliência do "dia de jogo".
- Faça exercícios de continuidade de negócios e recuperação de desastres para garantir que seu aplicativo possa se recuperar rapidamente e preservar dados críticos em caso de desastre.
- Execute exercícios de alta disponibilidade para testar a resiliência do aplicativo contra interrupções de região, erros de configuração de rede, eventos de alta tensão ou problemas de vizinhos barulhentos.
- Desenvolva benchmarks de desempenho de aplicativos.
- Planeje as necessidades de capacidade para ambientes de produção.
- Execute testes de esforço ou testes de carga.
- Certifique-se de que os serviços migrados de um ambiente local ou de outro ambiente de nuvem permaneçam resilientes a falhas conhecidas.
- Crie confiança em serviços baseados em arquiteturas nativas da nuvem.
- Valide se as ferramentas do site em tempo real, os dados de observabilidade e os processos de plantão ainda funcionam em condições inesperadas.
Para muitos desses cenários, você primeiro cria resiliência usando experimentos de caos ad-hoc. Em seguida, você valida continuamente que as novas implantações não regredirão a resiliência. Para verificar, você executa experimentos de caos como portas de implantação em seus pipelines de integração contínua/implantação contínua.
Como funciona o Chaos Studio
Com o Chaos Studio, você pode orquestrar a injeção de falhas segura e controlada em seus recursos do Azure. As experiências do caos são o núcleo do Chaos Studio. Um experimento de caos descreve as falhas a serem executadas e os recursos a serem executados. Você pode organizar falhas para serem executadas em paralelo ou em sequência, dependendo de suas necessidades.
O Chaos Studio suporta dois tipos de falhas:
- Service-direct: essas falhas são executadas diretamente em um recurso do Azure, sem qualquer instalação ou instrumentação. Os exemplos incluem a reinicialização de um cluster do Cache do Azure para Redis ou a adição de latência de rede aos pods do Serviço Kubernetes do Azure.
- Baseado em agente: essas falhas são executadas em VMs ou conjuntos de dimensionamento de máquinas virtuais para fazer falhas no convidado. Exemplos incluem aplicar pressão de memória virtual ou matar um processo.
Cada falha tem parâmetros específicos que você pode configurar, como qual processo matar ou quanta pressão de memória gerar.
Ao criar um experimento de caos, você define uma ou mais etapas que são executadas sequencialmente. Cada etapa contém uma ou mais ramificações que são executadas em paralelo dentro da etapa. Cada ramo contém uma ou mais ações, como injetar uma falha ou esperar por uma determinada duração.
Você organiza destinos de recursos para executar falhas em grupos chamados seletores para que possa facilmente fazer referência a um grupo de recursos em cada ação.
O diagrama a seguir mostra o layout de um experimento de caos no Chaos Studio:
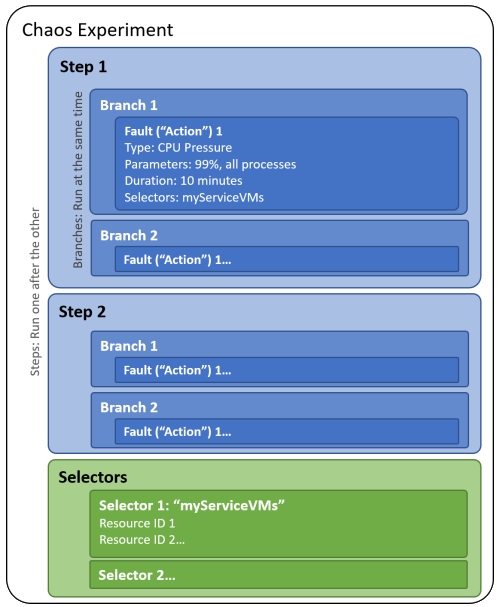
Um experimento de caos é um recurso do Azure em uma assinatura e grupo de recursos. Você pode usar o portal do Azure ou a API REST do Chaos Studio para criar, atualizar, iniciar, cancelar e exibir o status dos experimentos.
Próximos passos
Agora que você já entendeu como usar a engenharia do caos, está pronto para: