Um bom design de API é importante em uma arquitetura de microsserviços, porque toda a troca de dados entre serviços acontece por meio de mensagens ou chamadas de API. As APIs devem ser eficientes para evitar a criação de E/S tagarelas. Como os serviços são projetados por equipes que trabalham de forma independente, as APIs devem ter semântica e esquemas de controle de versão bem definidos, para que as atualizações não interrompam outros serviços.
É importante distinguir entre dois tipos de API:
- APIs públicas que os aplicativos cliente chamam.
- APIs de back-end que são usadas para comunicação entre serviços.
Estes dois casos de uso têm requisitos um pouco diferentes. Uma API pública deve ser compatível com aplicativos cliente, geralmente aplicativos de navegador ou aplicativos móveis nativos. Na maioria das vezes, isso significa que a API pública usará REST sobre HTTP. Para as APIs de back-end, no entanto, você precisa levar em conta o desempenho da rede. Dependendo da granularidade dos seus serviços, a comunicação entre serviços pode resultar em muito tráfego de rede. Os serviços podem rapidamente se tornar vinculados a E/S. Por esse motivo, considerações como velocidade de serialização e tamanho da carga útil tornam-se mais importantes. Algumas alternativas populares ao uso de REST sobre HTTP incluem gRPC, Apache Avro e Apache Thrift. Esses protocolos suportam serialização binária e geralmente são mais eficientes do que HTTP.
Considerações
Aqui estão algumas coisas sobre as quais pensar ao escolher como implementar uma API.
REST versus RPC. Considere as compensações entre usar uma interface no estilo REST versus uma interface no estilo RPC.
Recursos de modelos REST, que podem ser uma maneira natural de expressar seu modelo de domínio. Ele define uma interface uniforme baseada em verbos HTTP, o que incentiva a capacidade de evolução. Tem semântica bem definida em termos de idempotência, efeitos colaterais e códigos de resposta. E impõe a comunicação sem estado, o que melhora a escalabilidade.
O RPC é mais orientado em torno de operações ou comandos. Como as interfaces RPC se parecem com chamadas de método local, isso pode levá-lo a projetar APIs excessivamente tagarelas. No entanto, isso não significa que a RPC deva ser tagarela. Isso significa apenas que você precisa ter cuidado ao projetar a interface.
Para uma interface RESTful, a opção mais comum é REST sobre HTTP usando JSON. Para uma interface no estilo RPC, existem várias estruturas populares, incluindo gRPC, Apache Avro e Apache Thrift.
Eficiência. Considere a eficiência em termos de velocidade, memória e tamanho da carga útil. Normalmente, uma interface baseada em gRPC é mais rápida do que REST sobre HTTP.
Linguagem de definição de interface (IDL). Um IDL é usado para definir os métodos, parâmetros e valores de retorno de uma API. Um IDL pode ser usado para gerar código de cliente, código de serialização e documentação de API. Os IDLs também podem ser consumidos por ferramentas de teste de API. Frameworks como gRPC, Avro e Thrift definem suas próprias especificações IDL. REST sobre HTTP não tem um formato IDL padrão, mas uma escolha comum é OpenAPI (anteriormente Swagger). Você também pode criar uma API REST HTTP sem usar uma linguagem de definição formal, mas perde os benefícios da geração e teste de código.
Serialização. Como os objetos são serializados através do fio? As opções incluem formatos baseados em texto (principalmente JSON) e formatos binários, como buffer de protocolo. Os formatos binários são geralmente mais rápidos do que os formatos baseados em texto. No entanto, JSON tem vantagens em termos de interoperabilidade, porque a maioria das linguagens e estruturas suportam a serialização JSON. Alguns formatos de serialização requerem um esquema fixo e outros requerem a compilação de um arquivo de definição de esquema. Nesse caso, você precisará incorporar essa etapa ao seu processo de compilação.
Suporte a estruturas e idiomas. HTTP é suportado em quase todas as estruturas e linguagens. gRPC, Avro e Thrift têm bibliotecas para C++, C#, Java e Python. Thrift e gRPC também suportam Go.
Compatibilidade e interoperabilidade. Se você escolher um protocolo como gRPC, talvez precise de uma camada de tradução de protocolo entre a API pública e o back-end. Um gateway pode executar essa função. Se você estiver usando uma malha de serviço, considere quais protocolos são compatíveis com a malha de serviço. Por exemplo, o Linkerd tem suporte interno para HTTP, Thrift e gRPC.
Nossa recomendação de linha de base é escolher REST em vez de HTTP, a menos que você precise dos benefícios de desempenho de um protocolo binário. REST sobre HTTP não requer bibliotecas especiais. Ele cria um acoplamento mínimo, porque os chamadores não precisam de um esboço de cliente para se comunicar com o serviço. Existem ecossistemas ricos de ferramentas para dar suporte a definições de esquema, testes e monitoramento de pontos de extremidade HTTP RESTful. Finalmente, o HTTP é compatível com clientes de navegador, portanto, você não precisa de uma camada de tradução de protocolo entre o cliente e o back-end.
No entanto, se você escolher REST em vez de HTTP, deverá fazer testes de desempenho e carga no início do processo de desenvolvimento, para validar se ele funciona bem o suficiente para o seu cenário.
Design de API RESTful
Há muitos recursos para projetar APIs RESTful. Aqui estão alguns que você pode achar úteis:
Aqui estão algumas considerações específicas a ter em mente.
Fique atento às APIs que vazam detalhes de implementação interna ou simplesmente espelham um esquema de banco de dados interno. A API deve modelar o domínio. É um contrato entre serviços e, idealmente, só deve mudar quando uma nova funcionalidade é adicionada, não apenas porque você refatorou algum código ou normalizou uma tabela de banco de dados.
Diferentes tipos de cliente, como aplicativo móvel e navegador da Web para desktop, podem exigir diferentes tamanhos de carga útil ou padrões de interação. Considere usar o padrão Backends for Frontends para criar backends separados para cada cliente, que expõem uma interface ideal para esse cliente.
Para operações com efeitos colaterais, considere torná-los idempotentes e implementá-los como métodos PUT. Isso permitirá novas tentativas seguras e pode melhorar a resiliência. O artigo Comunicação interserviços discute esta questão em mais detalhes.
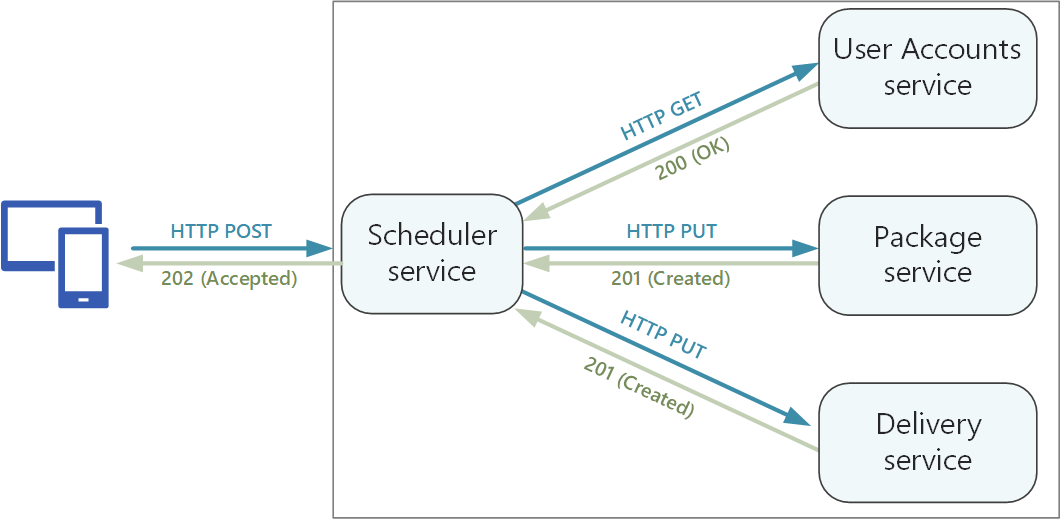
Os métodos HTTP podem ter semântica assíncrona, onde o método retorna uma resposta imediatamente, mas o serviço executa a operação de forma assíncrona. Nesse caso, o método deve retornar um código de resposta HTTP 202 , que indica que a solicitação foi aceita para processamento, mas o processamento ainda não foi concluído. Para obter mais informações, consulte Padrão de solicitação-resposta assíncrona.
Mapeando REST para padrões DDD
Padrões como entidade, agregação e objeto de valor são projetados para colocar certas restrições nos objetos em seu modelo de domínio. Em muitas discussões sobre DDD, os padrões são modelados usando conceitos de linguagem orientada a objetos (OO), como construtores ou getters e setters de propriedade. Por exemplo, os objetos de valor devem ser imutáveis. Em uma linguagem de programação OO, você imporia isso atribuindo os valores no construtor e tornando as propriedades somente leitura:
export class Location {
readonly latitude: number;
readonly longitude: number;
constructor(latitude: number, longitude: number) {
if (latitude < -90 || latitude > 90) {
throw new RangeError('latitude must be between -90 and 90');
}
if (longitude < -180 || longitude > 180) {
throw new RangeError('longitude must be between -180 and 180');
}
this.latitude = latitude;
this.longitude = longitude;
}
}
Esses tipos de práticas de codificação são particularmente importantes ao criar um aplicativo monolítico tradicional. Com uma base de código grande, muitos subsistemas podem usar o objeto, por isso é importante que o objeto imponha o Location comportamento correto.
Outro exemplo é o padrão Repository, que garante que outras partes do aplicativo não façam leituras ou gravações diretas no armazenamento de dados:
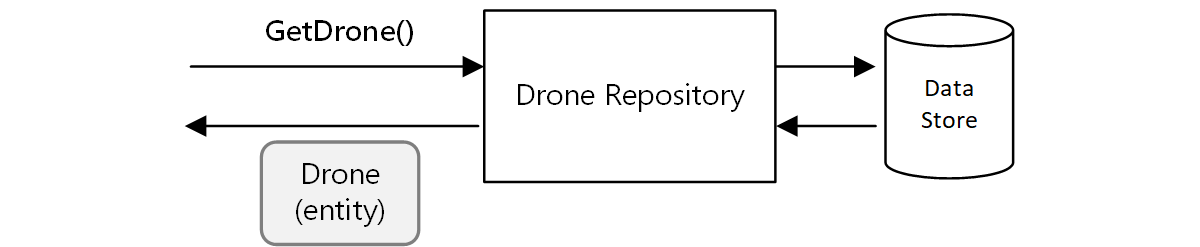
Em uma arquitetura de microsserviços, no entanto, os serviços não compartilham a mesma base de código e não compartilham armazenamentos de dados. Em vez disso, eles se comunicam por meio de APIs. Considere o caso em que o serviço Agendador solicita informações sobre um drone do serviço Drone. O serviço de Drone tem o seu modelo interno de um drone, expresso através de código. Mas o Scheduler não vê isso. Em vez disso, ele recebe de volta uma representação da entidade do drone — talvez um objeto JSON em uma resposta HTTP.
Este exemplo é ideal para as indústrias aeronáutica e aeroespacial.
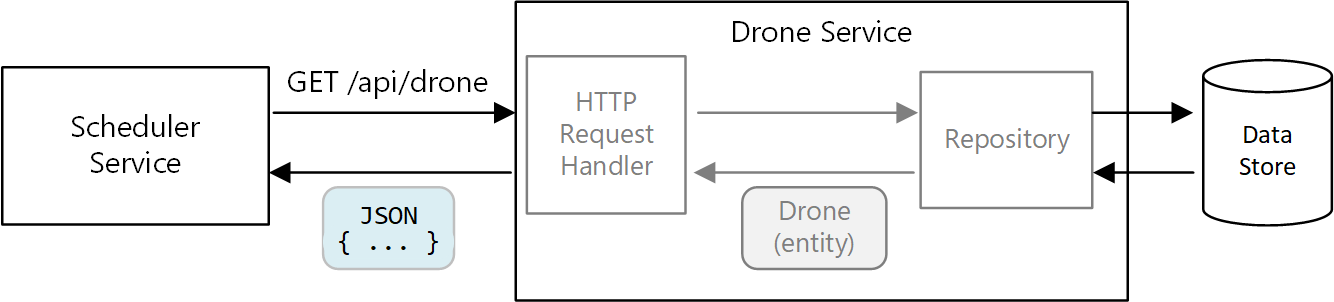
O serviço Agendador não pode modificar os modelos internos do serviço Drone nem escrever no armazenamento de dados do serviço Drone. Isso significa que o código que implementa o serviço Drone tem uma área de superfície exposta menor, em comparação com o código em um monólito tradicional. Se o serviço Drone definir uma classe Location, o escopo dessa classe será limitado — nenhum outro serviço consumirá diretamente a classe.
Por estas razões, esta orientação não se concentra muito nas práticas de codificação, uma vez que se relacionam com os padrões táticos de DDD. Mas acontece que você também pode modelar muitos dos padrões DDD por meio de APIs REST.
Por exemplo:
Os agregados são mapeados naturalmente para os recursos em REST. Por exemplo, a agregação Delivery seria exposta como um recurso pela API de Entrega.
Os agregados são limites de consistência. As operações em agregados nunca devem deixar um agregado num estado inconsistente. Portanto, você deve evitar a criação de APIs que permitam que um cliente manipule o estado interno de uma agregação. Em vez disso, prefira APIs de grão grosso que expõem agregados como recursos.
As entidades têm identidades únicas. No REST, os recursos têm identificadores exclusivos na forma de URLs. Crie URLs de recursos que correspondam à identidade de domínio de uma entidade. O mapeamento da URL para a identidade do domínio pode ser opaco para o cliente.
As entidades filhas de uma agregação podem ser alcançadas navegando a partir da entidade raiz. Se você seguir os princípios HATEOAS , as entidades filhas podem ser acessadas por meio de links na representação da entidade pai.
Como os objetos value são imutáveis, as atualizações são executadas substituindo todo o objeto value. Em REST, implemente atualizações por meio de solicitações PUT ou PATCH.
Um repositório permite que os clientes consultem, adicionem ou removam objetos em uma coleção, abstraindo os detalhes do armazenamento de dados subjacente. Em REST, uma coleção pode ser um recurso distinto, com métodos para consultar a coleção ou adicionar novas entidades à coleção.
Ao projetar suas APIs, pense em como elas expressam o modelo de domínio, não apenas os dados dentro do modelo, mas também as operações de negócios e as restrições nos dados.
| Conceito DDD | Equivalente REST | Exemplo |
|---|---|---|
| Agregação | Recurso | { "1":1234, "status":"pending"... } |
| Identidade | URL | https://delivery-service/deliveries/1 |
| Entidades filhas | Ligações | { "href": "/deliveries/1/confirmation" } |
| Atualizar objetos de valor | COLOCAR ou REMENDAR | PUT https://delivery-service/deliveries/1/dropoff |
| Repositório | Coleção | https://delivery-service/deliveries?status=pending |
Controlo de versões de API
Uma API é um contrato entre um serviço e clientes ou consumidores desse serviço. Se uma API for alterada, há um risco de quebrar clientes que dependem da API, sejam eles clientes externos ou outros microsserviços. Portanto, é uma boa ideia minimizar o número de alterações de API que você faz. Muitas vezes, as alterações na implementação subjacente não exigem nenhuma alteração na API. Realisticamente, no entanto, em algum momento você vai querer adicionar novos recursos ou novos recursos que exigem a alteração de uma API existente.
Sempre que possível, faça alterações de API compatíveis com versões anteriores. Por exemplo, evite remover um campo de um modelo, porque isso pode quebrar os clientes que esperam que o campo esteja lá. Adicionar um campo não quebra a compatibilidade, porque os clientes devem ignorar quaisquer campos que não entendam em uma resposta. No entanto, o serviço deve lidar com o caso em que um cliente mais antigo omite o novo campo em uma solicitação.
Suporte ao controle de versão em seu contrato de API. Se você introduzir uma alteração de API de quebra, introduza uma nova versão da API. Continue a oferecer suporte à versão anterior e permita que os clientes selecionem qual versão chamar. Existem algumas maneiras de fazer isso. Uma delas é simplesmente expor ambas as versões no mesmo serviço. Outra opção é executar duas versões do serviço lado a lado e rotear solicitações para uma ou outra versão, com base em regras de roteamento HTTP.
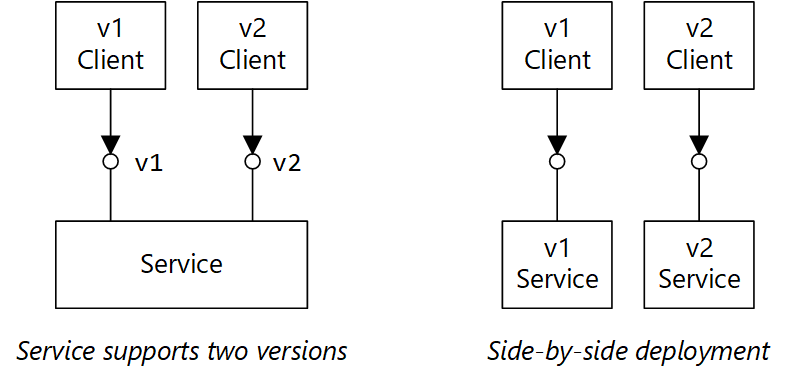
O diagrama tem duas partes. "O serviço suporta duas versões" mostra o cliente v1 e o cliente v2, ambos apontando para um serviço. "Implantação lado a lado" mostra o Cliente v1 apontando para um Serviço v1 e o Cliente v2 apontando para um Serviço v2.
Há um custo para suportar várias versões, em termos de tempo do desenvolvedor, testes e sobrecarga operacional. Portanto, é bom descartar versões antigas o mais rápido possível. Para APIs internas, a equipe proprietária da API pode trabalhar com outras equipes para ajudá-las a migrar para a nova versão. É quando ter um processo de governança entre equipes é útil. Para APIs externas (públicas), pode ser mais difícil substituir uma versão da API, especialmente se a API for consumida por terceiros ou por aplicativos cliente nativos.
Quando uma implementação de serviço é alterada, é útil marcar a alteração com uma versão. A versão fornece informações importantes ao solucionar erros. Pode ser muito útil para a análise de causa raiz saber exatamente qual versão do serviço foi chamada. Considere o uso de controle de versão semântico para versões de serviço. O controle de versão semântico usa um MAJOR. MENOR. Formato PATCH . No entanto, os clientes só devem selecionar uma API pelo número da versão principal ou, possivelmente, pela versão secundária se houver alterações significativas (mas ininterruptas) entre as versões secundárias. Em outras palavras, é razoável que os clientes selecionem entre a versão 1 e a versão 2 de uma API, mas não selecionem a versão 2.1.3. Se você permitir esse nível de granularidade, corre o risco de ter que suportar uma proliferação de versões.
Para obter mais discussões sobre o controle de versão da API, consulte Versionamento de uma API da Web RESTful.
Operações idempotentes
Uma operação é idempotente se puder ser chamada várias vezes sem produzir efeitos colaterais adicionais após a primeira chamada. A idempotência pode ser uma estratégia de resiliência útil, porque permite que um serviço upstream invoque com segurança uma operação várias vezes. Para uma discussão sobre este ponto, consulte Transações distribuídas.
A especificação HTTP afirma que os métodos GET, PUT e DELETE devem ser idempotentes. Não é garantido que os métodos POST sejam idempotentes. Se um método POST cria um novo recurso, geralmente não há garantia de que essa operação seja idempotente. A especificação define idempotente desta forma:
Um método de solicitação é considerado "idempotente" se o efeito pretendido no servidor de várias solicitações idênticas com esse método for o mesmo que o efeito para uma única solicitação desse tipo. (RFC 7231)
É importante entender a diferença entre a semântica PUT e POST ao criar uma nova entidade. Em ambos os casos, o cliente envia uma representação de uma entidade no corpo do pedido. Mas o significado do URI é diferente.
Para um método POST, o URI representa um recurso pai da nova entidade, como uma coleção. Por exemplo, para criar uma nova entrega, o URI pode ser
/api/deliveries. O servidor cria a entidade e atribui-lhe um novo URI, como/api/deliveries/39660. Esse URI é retornado no cabeçalho Location da resposta. Cada vez que o cliente envia uma solicitação, o servidor criará uma nova entidade com um novo URI.Para um método PUT, o URI identifica a entidade. Se já existir uma entidade com esse URI, o servidor substituirá a entidade existente pela versão na solicitação. Se nenhuma entidade existir com esse URI, o servidor criará uma. Por exemplo, suponha que o cliente envie uma solicitação PUT para
api/deliveries/39660. Supondo que não haja entrega com esse URI, o servidor cria um novo. Agora, se o cliente enviar a mesma solicitação novamente, o servidor substituirá a entidade existente.
Aqui está a implementação do método PUT pelo serviço de Entrega.
[HttpPut("{id}")]
[ProducesResponseType(typeof(Delivery), 201)]
[ProducesResponseType(typeof(void), 204)]
public async Task<IActionResult> Put([FromBody]Delivery delivery, string id)
{
logger.LogInformation("In Put action with delivery {Id}: {@DeliveryInfo}", id, delivery.ToLogInfo());
try
{
var internalDelivery = delivery.ToInternal();
// Create the new delivery entity.
await deliveryRepository.CreateAsync(internalDelivery);
// Create a delivery status event.
var deliveryStatusEvent = new DeliveryStatusEvent { DeliveryId = delivery.Id, Stage = DeliveryEventType.Created };
await deliveryStatusEventRepository.AddAsync(deliveryStatusEvent);
// Return HTTP 201 (Created)
return CreatedAtRoute("GetDelivery", new { id= delivery.Id }, delivery);
}
catch (DuplicateResourceException)
{
// This method is mainly used to create deliveries. If the delivery already exists then update it.
logger.LogInformation("Updating resource with delivery id: {DeliveryId}", id);
var internalDelivery = delivery.ToInternal();
await deliveryRepository.UpdateAsync(id, internalDelivery);
// Return HTTP 204 (No Content)
return NoContent();
}
}
Espera-se que a maioria das solicitações crie uma nova entidade, de modo que o método chame CreateAsync o objeto de repositório de forma otimista e, em seguida, lide com quaisquer exceções de recursos duplicados atualizando o recurso.
Próximos passos
Saiba mais sobre como usar um gateway de API no limite entre aplicativos cliente e microsserviços.