Desenvolva aplicativos com LangChain e Azure AI Foundry
LangChain é um ecossistema de desenvolvimento que torna o mais fácil possível para os desenvolvedores criarem aplicativos que raciocinam. O ecossistema é composto por múltiplos componentes. A maioria deles pode ser usada por si mesmos, permitindo que você escolha os componentes que você mais gosta.
Os modelos implantados no Azure AI Foundry podem ser usados com o LangChain de duas maneiras:
Usando a API de inferência de modelo de IA do Azure: todos os modelos implantados no Azure AI Foundry dão suporte à API de inferência de modelo de IA do Azure, que oferece um conjunto comum de funcionalidades que podem ser usadas para a maioria dos modelos no catálogo. O benefício dessa API é que, como é a mesma para todos os modelos, mudar de um para outro é tão simples quanto alterar a implantação do modelo que está sendo usado. Não são necessárias mais alterações no código. Ao trabalhar com LangChain, instale as extensões
langchain-azure-ai.Usando a API específica do provedor do modelo: Alguns modelos, como OpenAI, Cohere ou Mistral, oferecem seu próprio conjunto de APIs e extensões para LlamaIndex. Essas extensões podem incluir funcionalidades específicas que o modelo suporta e, portanto, são adequadas se você quiser explorá-las. Ao trabalhar com LangChain, instale a extensão específica para o modelo que você deseja usar, como
langchain-openaioulangchain-cohere.
Neste tutorial, você aprenderá a usar os pacotes langchain-azure-ai para criar aplicativos com LangChain.
Pré-requisitos
Para executar este tutorial, você precisa:
Uma subscrição do Azure.
Uma implantação de modelo que dá suporte à API de inferência de modelo de IA do Azure implantada. Neste exemplo, usamos uma
Mistral-Large-2407implantação na inferência de modelo de IA do Azure.Python 3.9 ou posterior instalado, incluindo pip.
LangChain instalado. Pode fazê-lo com:
pip install langchain-coreNeste exemplo, estamos trabalhando com a API de inferência de modelo de IA do Azure, portanto, instalamos os seguintes pacotes:
pip install -U langchain-azure-ai
Configurar o ambiente
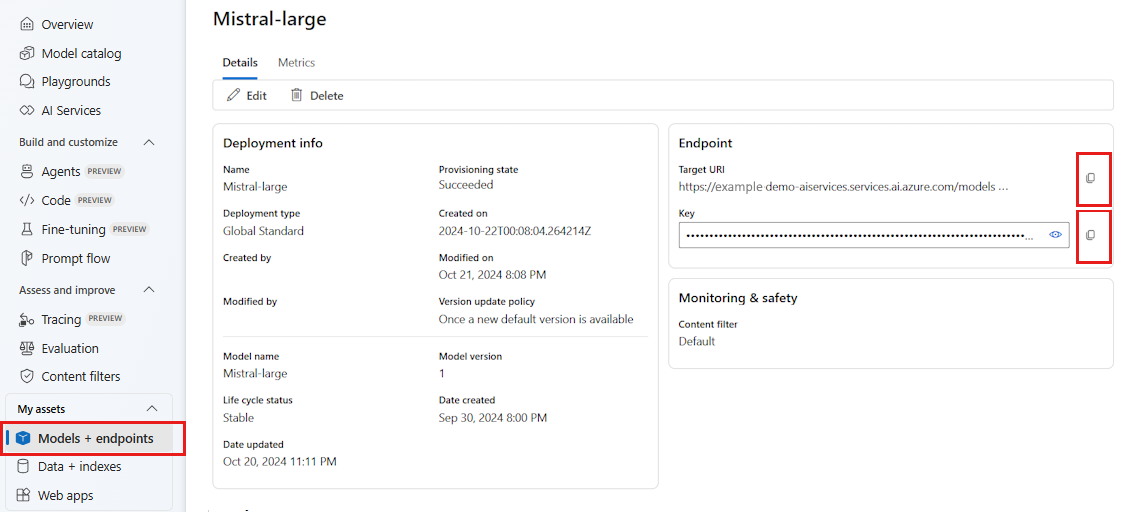
Para usar LLMs implantados no portal do Azure AI Foundry, você precisa do ponto de extremidade e das credenciais para se conectar a ele. Siga estas etapas para obter as informações necessárias do modelo que deseja usar:
Vá para o Azure AI Foundry.
Abra o projeto onde o modelo está implantado, se ainda não estiver aberto.
Vá para Modelos + pontos de extremidade e selecione o modelo implantado conforme indicado nos pré-requisitos.
Copie o URL do ponto de extremidade e a chave.
Gorjeta
Se o seu modelo foi implantado com suporte ao Microsoft Entra ID, você não precisa de uma chave.

Nesse cenário, colocamos a URL do ponto de extremidade e a chave nas seguintes variáveis de ambiente:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
Uma vez configurado, crie um cliente para se conectar ao ponto de extremidade. Neste caso, estamos trabalhando com um modelo de conclusão de bate-papo, portanto, importamos a classe AzureAIChatCompletionsModel.
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model="mistral-large-2407",
)
Gorjeta
Para modelos do Azure OpenAI, configure o cliente conforme indicado em Usando modelos do Azure OpenAI.
Você pode usar o seguinte código para criar o cliente se seu ponto de extremidade suportar o Microsoft Entra ID:
import os
from azure.identity import DefaultAzureCredential
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model_name="mistral-large-2407",
)
Nota
Ao usar o Microsoft Entra ID, verifique se o ponto de extremidade foi implantado com esse método de autenticação e se você tem as permissões necessárias para invocá-lo.
Se você estiver planejando usar chamadas assíncronas, é uma prática recomendada usar a versão assíncrona para as credenciais:
from azure.identity.aio import (
DefaultAzureCredential as DefaultAzureCredentialAsync,
)
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredentialAsync(),
model_name="mistral-large-2407",
)
Se o seu ponto de extremidade estiver servindo um modelo, como com os pontos de extremidade da API sem servidor, você não precisa indicar model_name o parâmetro:
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
)
Usar modelos de conclusão de bate-papo
Vamos primeiro usar o modelo diretamente.
ChatModels são instâncias de LangChain Runnable, o que significa que expõem uma interface padrão para interagir com elas. Para simplesmente chamar o modelo, podemos passar uma lista de mensagens para o invoke método.
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="Translate the following from English into Italian"),
HumanMessage(content="hi!"),
]
model.invoke(messages)
Você também pode compor operações conforme necessário no que é chamado de cadeias. Vamos agora usar um modelo de prompt para traduzir frases:
from langchain_core.output_parsers import StrOutputParser
system_template = "Translate the following into {language}:"
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
Como você pode ver no modelo de prompt, essa cadeia tem um language e text entrada. Agora, vamos criar um analisador de saída:
from langchain_core.prompts import ChatPromptTemplate
parser = StrOutputParser()
Agora podemos combinar o modelo, o modelo e o analisador de saída de cima usando o operador de tubo (|):
chain = prompt_template | model | parser
Para invocar a cadeia, identifique as entradas necessárias e forneça valores usando o invoke método:
chain.invoke({"language": "italian", "text": "hi"})
'ciao'
Encadeamento de vários LLMs juntos
Os modelos implantados no Azure AI Foundry dão suporte à API de inferência de modelo de IA do Azure, que é padrão em todos os modelos. Encadeie várias operações de LLM com base nos recursos de cada modelo para que você possa otimizar para o modelo certo com base nos recursos.
No exemplo a seguir, criamos dois clientes modelo, um é um produtor e outro é um verificador. Para deixar a distinção clara, estamos usando um ponto de extremidade de vários modelos como o serviço de inferência de modelo de IA do Azure e, portanto, estamos passando o parâmetro model_name para usar um Mistral-Large e um Mistral-Small modelo, citando o fato de que produzir conteúdo é mais complexo do que verificá-lo.
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
producer = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2407",
)
verifier = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-small",
)
Gorjeta
Explore o cartão modelo de cada um dos modelos para entender os melhores casos de uso para cada modelo.
O exemplo a seguir gera um poema escrito por um poeta urbano:
from langchain_core.prompts import PromptTemplate
producer_template = PromptTemplate(
template="You are an urban poet, your job is to come up \
verses based on a given topic.\n\
Here is the topic you have been asked to generate a verse on:\n\
{topic}",
input_variables=["topic"],
)
verifier_template = PromptTemplate(
template="You are a verifier of poems, you are tasked\
to inspect the verses of poem. If they consist of violence and abusive language\
report it. Your response should be only one word either True or False.\n \
Here is the lyrics submitted to you:\n\
{input}",
input_variables=["input"],
)
Agora vamos encadear as peças:
chain = producer_template | producer | parser | verifier_template | verifier | parser
A cadeia anterior retorna apenas a saída da etapa verifier . Como queremos acessar o resultado intermediário gerado pelo producer, em LangChain você precisa usar um RunnablePassthrough objeto para também produzir essa etapa intermediária. O código a seguir mostra como fazê-lo:
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
generate_poem = producer_template | producer | parser
verify_poem = verifier_template | verifier | parser
chain = generate_poem | RunnableParallel(poem=RunnablePassthrough(), verification=RunnablePassthrough() | verify_poem)
Para invocar a cadeia, identifique as entradas necessárias e forneça valores usando o invoke método:
chain.invoke({"topic": "living in a foreign country"})
{
"peom": "...",
"verification: "false"
}
Usar modelos de incorporação
Da mesma forma, você cria um cliente LLM, você pode se conectar a um modelo de incorporações. No exemplo a seguir, estamos definindo a variável de ambiente para agora apontar para um modelo de incorporações:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
Em seguida, crie o cliente:
from langchain_azure_ai.embeddings import AzureAIEmbeddingsModel
embed_model = AzureAIEmbeddingsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ['AZURE_INFERENCE_CREDENTIAL'],
model_name="text-embedding-3-large",
)
O exemplo a seguir mostra um exemplo simples usando um armazenamento de vetor na memória:
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embed_model)
Vamos adicionar alguns documentos:
from langchain_core.documents import Document
document_1 = Document(id="1", page_content="foo", metadata={"baz": "bar"})
document_2 = Document(id="2", page_content="thud", metadata={"bar": "baz"})
documents = [document_1, document_2]
vector_store.add_documents(documents=documents)
Vamos pesquisar por semelhança:
results = vector_store.similarity_search(query="thud",k=1)
for doc in results:
print(f"* {doc.page_content} [{doc.metadata}]")
Usando modelos do Azure OpenAI
Se você estiver usando o serviço OpenAI do Azure ou o serviço de inferência de modelo do Azure AI com modelos OpenAI com langchain-azure-ai pacote, talvez seja necessário usar api_version o parâmetro para selecionar uma versão específica da API. O exemplo a seguir mostra como se conectar a uma implantação de modelo do Azure OpenAI no serviço Azure OpenAI:
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
llm = AzureAIChatCompletionsModel(
endpoint="https://<resource>.openai.azure.com/openai/deployments/<deployment-name>",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
api_version="2024-05-01-preview",
)
Importante
Verifique qual é a versão da API que sua implantação está usando. Usar um errado api_version ou um não suportado pelo modelo resulta em uma ResourceNotFound exceção.
Se a implantação estiver hospedada nos Serviços de IA do Azure, você poderá usar o serviço de inferência de modelo de IA do Azure:
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
llm = AzureAIChatCompletionsModel(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="<model-name>",
api_version="2024-05-01-preview",
)
Depuração e solução de problemas
Se você precisar depurar seu aplicativo e entender as solicitações enviadas aos modelos no Azure AI Foundry, poderá usar os recursos de depuração da integração da seguinte maneira:
Primeiro, configure o registro em log para o nível em que você está interessado:
import sys
import logging
# Acquire the logger for this client library. Use 'azure' to affect both
# 'azure.core` and `azure.ai.inference' libraries.
logger = logging.getLogger("azure")
# Set the desired logging level. logging.INFO or logging.DEBUG are good options.
logger.setLevel(logging.DEBUG)
# Direct logging output to stdout:
handler = logging.StreamHandler(stream=sys.stdout)
# Or direct logging output to a file:
# handler = logging.FileHandler(filename="sample.log")
logger.addHandler(handler)
# Optional: change the default logging format. Here we add a timestamp.
formatter = logging.Formatter("%(asctime)s:%(levelname)s:%(name)s:%(message)s")
handler.setFormatter(formatter)
Para ver as cargas úteis das solicitações, ao instanciar o cliente, passe o argumento logging_enable=True para o :client_kwargs
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2407",
client_kwargs={"logging_enable": True},
)
Use o cliente como de costume em seu código.
Rastreio
Você pode usar os recursos de rastreamento no Azure AI Foundry criando um rastreador. Os logs são armazenados no Azure Application Insights e podem ser consultados a qualquer momento usando o Azure Monitor ou o portal do Azure AI Foundry. Cada Hub de IA tem um Azure Application Insights associado a ele.
Obtenha a sua corda de conexão de instrumentação
Você pode configurar seu aplicativo para enviar telemetria para o Azure Application Insights da seguinte forma:
Usando a cadeia de conexão para o Azure Application Insights diretamente:
Vá para o portal do Azure AI Foundry e selecione Rastreamento.
Selecione Gerenciar fonte de dados. Nesta tela, você pode ver a instância associada ao projeto.
Copie o valor em Cadeia de conexão e defina-o com a seguinte variável:
import os application_insights_connection_string = "instrumentation...."
Usando o SDK do Azure AI Foundry e a cadeia de conexão do projeto.
Certifique-se de ter o pacote
azure-ai-projectsinstalado em seu ambiente.Vá para o portal do Azure AI Foundry.
Copie a cadeia de conexão do seu projeto e defina-a com o seguinte código:
from azure.ai.projects import AIProjectClient from azure.identity import DefaultAzureCredential project_client = AIProjectClient.from_connection_string( credential=DefaultAzureCredential(), conn_str="<your-project-connection-string>", ) application_insights_connection_string = project_client.telemetry.get_connection_string()
Configurar o rastreamento para o Azure AI Foundry
O código a seguir cria um rastreador conectado ao Azure Application Insights por trás de um projeto no Azure AI Foundry. Observe que o parâmetro enable_content_recording está definido como True. Isso permite a captura das entradas e saídas de toda a aplicação, bem como as etapas intermediárias. Isso é útil ao depurar e criar aplicativos, mas talvez você queira desativá-lo em ambientes de produção. O padrão é a variável AZURE_TRACING_GEN_AI_CONTENT_RECORDING_ENABLEDde ambiente :
from langchain_azure_ai.callbacks.tracers import AzureAIInferenceTracer
tracer = AzureAIInferenceTracer(
connection_string=application_insights_connection_string,
enable_content_recording=True,
)
Para configurar o rastreamento com sua cadeia, indique a invoke configuração de valor na operação como um retorno de chamada:
chain.invoke({"topic": "living in a foreign country"}, config={"callbacks": [tracer]})
Para configurar a própria cadeia para rastreamento, use o .with_config() método:
chain = chain.with_config({"callbacks": [tracer]})
Em seguida, use o invoke() método como de costume:
chain.invoke({"topic": "living in a foreign country"})
Ver rastreios
Para ver vestígios:
Vá para o portal do Azure AI Foundry.
Navegue até a seção Rastreamento .
Identifique o rastreamento que você criou. Pode levar alguns segundos para que o rastreamento apareça.


Saiba mais sobre como visualizar e gerenciar rastreamentos.