Desenvolva aplicações com o LlamaIndex e o Azure AI Foundry
Neste artigo, você aprenderá a usar o LlamaIndex com modelos implantados a partir do catálogo de modelos do Azure AI no portal do Azure AI Foundry.
Os modelos implantados no Azure AI Foundry podem ser usados com o LlamaIndex de duas maneiras:
Usando a API de inferência de modelo de IA do Azure: todos os modelos implantados no Azure AI Foundry dão suporte à API de inferência de modelo de IA do Azure, que oferece um conjunto comum de funcionalidades que podem ser usadas para a maioria dos modelos no catálogo. O benefício dessa API é que, como é a mesma para todos os modelos, mudar de um para outro é tão simples quanto alterar a implantação do modelo que está sendo usado. Não são necessárias mais alterações no código. Ao trabalhar com LlamaIndex, instale as extensões
llama-index-llms-azure-inferenceellama-index-embeddings-azure-inference.Usando a API específica do provedor do modelo: Alguns modelos, como OpenAI, Cohere ou Mistral, oferecem seu próprio conjunto de APIs e extensões para LlamaIndex. Essas extensões podem incluir funcionalidades específicas que o modelo suporta e, portanto, são adequadas se você quiser explorá-las. Ao trabalhar com
llama-indexo , instale a extensão específica para o modelo que você deseja usar, comollama-index-llms-openaioullama-index-llms-cohere.
Neste exemplo, estamos trabalhando com a API de inferência de modelo de IA do Azure.
Pré-requisitos
Para executar este tutorial, você precisa:
Uma subscrição do Azure.
Um projeto de IA do Azure, conforme explicado em Criar um projeto no portal do Azure AI Foundry.
Um modelo que suporta a API de inferência de modelo de IA do Azure implantada. Neste exemplo, usamos uma
Mistral-Largeimplantação, mas usamos qualquer modelo de sua preferência. Para usar recursos de incorporação no LlamaIndex, você precisa de um modelo de incorporação comocohere-embed-v3-multilingualo .- Você pode seguir as instruções em Implantar modelos como APIs sem servidor.
Python 3.8 ou posterior instalado, incluindo pip.
LlamaIndex instalado. Pode fazê-lo com:
pip install llama-indexNeste exemplo, estamos trabalhando com a API de inferência de modelo de IA do Azure, portanto, instalamos os seguintes pacotes:
pip install -U llama-index-llms-azure-inference pip install -U llama-index-embeddings-azure-inferenceImportante
Usar o serviço de inferência de modelo de IA do Azure requer versão
0.2.4parallama-index-llms-azure-inferenceoullama-index-embeddings-azure-inference.
Configurar o ambiente
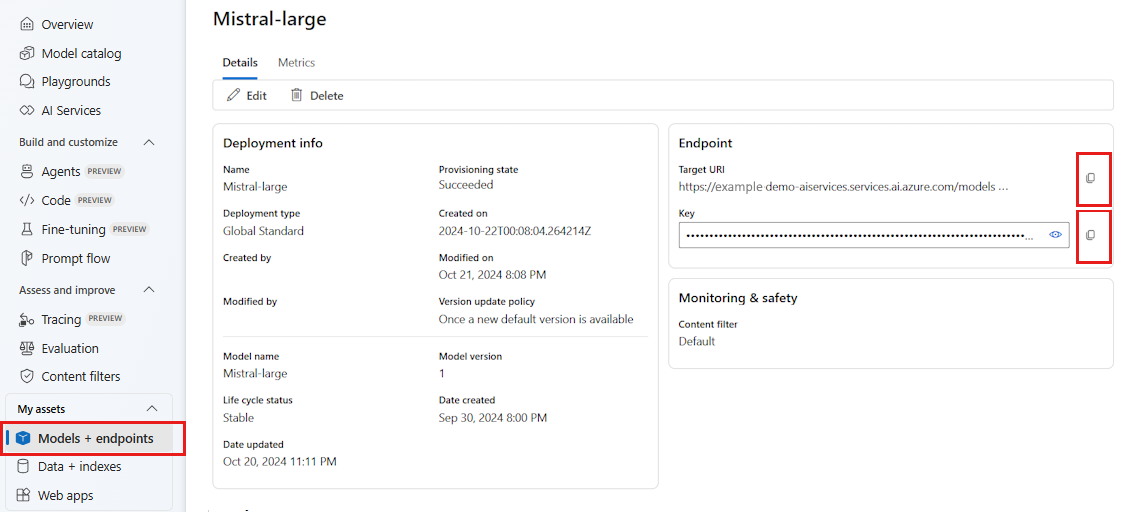
Para usar LLMs implantados no portal do Azure AI Foundry, você precisa do ponto de extremidade e das credenciais para se conectar a ele. Siga estas etapas para obter as informações necessárias do modelo que deseja usar:
Vá para o Azure AI Foundry.
Abra o projeto onde o modelo está implantado, se ainda não estiver aberto.
Vá para Modelos + pontos de extremidade e selecione o modelo implantado conforme indicado nos pré-requisitos.
Copie o URL do ponto de extremidade e a chave.
Gorjeta
Se o seu modelo foi implantado com suporte ao Microsoft Entra ID, você não precisa de uma chave.

Nesse cenário, colocamos a URL do ponto de extremidade e a chave nas seguintes variáveis de ambiente:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
Uma vez configurado, crie um cliente para se conectar ao ponto de extremidade.
import os
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
)
Gorjeta
Se a implantação do seu modelo estiver hospedada no serviço OpenAI do Azure ou no recurso dos Serviços de IA do Azure, configure o cliente conforme indicado em Modelos do Azure OpenAI e no serviço de inferência de modelo do Azure AI.
Se seu ponto de extremidade estiver servindo mais de um modelo, como com o serviço de inferência de modelo de IA do Azure ou Modelos GitHub, você precisará indicar model_name o parâmetro:
import os
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2407",
)
Como alternativa, se o seu ponto de extremidade suportar o Microsoft Entra ID, você pode usar o seguinte código para criar o cliente:
import os
from azure.identity import DefaultAzureCredential
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
)
Nota
Ao usar o Microsoft Entra ID, verifique se o ponto de extremidade foi implantado com esse método de autenticação e se você tem as permissões necessárias para invocá-lo.
Se você estiver planejando usar chamadas assíncronas, é uma prática recomendada usar a versão assíncrona para as credenciais:
from azure.identity.aio import (
DefaultAzureCredential as DefaultAzureCredentialAsync,
)
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredentialAsync(),
)
Modelos OpenAI do Azure e serviço de inferência de modelo de IA do Azure
Se você estiver usando o serviço Azure OpenAI ou o serviço de inferência de modelo do Azure AI, certifique-se de ter pelo menos a versão 0.2.4 da integração LlamaIndex. Use api_version o parâmetro caso precise selecionar um api_versionarquivo .
Para o serviço de inferência de modelo de IA do Azure, você precisa passar model_name o parâmetro:
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2407",
)
Para o serviço Azure OpenAI:
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint="https://<resource>.openai.azure.com/openai/deployments/<deployment-name>",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
api_version="2024-05-01-preview",
)
Gorjeta
Verifique qual é a versão da API que sua implantação está usando. Usar um errado api_version ou um não suportado pelo modelo resulta em uma ResourceNotFound exceção.
Parâmetros de inferência
Você pode configurar como a inferência é executada para todas as operações que estão usando esse cliente definindo parâmetros extras. Isso ajuda a evitar indicá-los em cada chamada que você faz para o modelo.
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
temperature=0.0,
model_kwargs={"top_p": 1.0},
)
Parâmetros não suportados na API de inferência de modelo de IA do Azure (referência), mas disponíveis no modelo subjacente, você pode usar o model_extras argumento. No exemplo a seguir, o parâmetro safe_prompt, disponível apenas para modelos Mistral, está sendo passado.
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
temperature=0.0,
model_kwargs={"model_extras": {"safe_prompt": True}},
)
Usar modelos LLMs
Você pode usar o cliente diretamente ou Configurar os modelos usados pelo seu código no LlamaIndex. Para usar o modelo diretamente, use o método para modelos de chat instrução de chat:
from llama_index.core.llms import ChatMessage
messages = [
ChatMessage(
role="system", content="You are a pirate with colorful personality."
),
ChatMessage(role="user", content="Hello"),
]
response = llm.chat(messages)
print(response)
Você também pode transmitir as saídas:
response = llm.stream_chat(messages)
for r in response:
print(r.delta, end="")
O complete método ainda está disponível para o modelo do tipo chat-completions. Nesses casos, o texto de entrada é convertido em uma mensagem com role="user".
Usar modelos de incorporação
Da mesma forma que você cria um cliente LLM, você pode se conectar a um modelo de incorporações. No exemplo a seguir, estamos definindo a variável de ambiente para agora apontar para um modelo de incorporações:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
Em seguida, crie o cliente:
from llama_index.embeddings.azure_inference import AzureAIEmbeddingsModel
embed_model = AzureAIEmbeddingsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ['AZURE_INFERENCE_CREDENTIAL'],
)
O exemplo a seguir mostra um teste simples para verificar se ele funciona:
from llama_index.core.schema import TextNode
nodes = [
TextNode(
text="Before college the two main things I worked on, "
"outside of school, were writing and programming."
)
]
response = embed_model(nodes=nodes)
print(response[0].embedding)
Configure os modelos usados pelo seu código
Você pode usar o LLM ou incorpora o cliente de modelo individualmente no código que você desenvolve com LlamaIndex ou você pode configurar toda a sessão usando as Settings opções. Configurar a sessão tem a vantagem de todo o seu código usar os mesmos modelos para todas as operações.
from llama_index.core import Settings
Settings.llm = llm
Settings.embed_model = embed_model
No entanto, há cenários em que você deseja usar um modelo geral para a maioria das operações, mas um modelo específico para uma determinada tarefa. Nesses casos, é útil definir o LLM ou o modelo de incorporação que você está usando para cada construção LlamaIndex. No exemplo a seguir, definimos um modelo específico:
from llama_index.core.evaluation import RelevancyEvaluator
relevancy_evaluator = RelevancyEvaluator(llm=llm)
Em geral, você usa uma combinação de ambas as estratégias.