Como treinar um modelo de classificação de texto personalizado
Artigo
O treinamento é o processo em que o modelo aprende com seus dados rotulados. Após a conclusão do treinamento, você poderá visualizar o desempenho do modelo para determinar se precisa melhorar seu modelo.
Para treinar um modelo, inicie um trabalho de treinamento. Apenas trabalhos concluídos com êxito criam um modelo utilizável. Os trabalhos de formação expiram ao fim de sete dias. Após esse período, você não poderá recuperar os detalhes do trabalho. Se o trabalho de treinamento for concluído com êxito e um modelo tiver sido criado, ele não será afetado pela expiração do trabalho. Você só pode ter um trabalho de treinamento em execução de cada vez, e você não pode iniciar outros trabalhos no mesmo projeto.
Os tempos de treinamento podem ser de alguns minutos ao lidar com poucos documentos, até várias horas, dependendo do tamanho do conjunto de dados e da complexidade do seu esquema.
Pré-requisitos
Antes de treinar seu modelo, você precisa:
Um projeto criado com êxito com uma conta de armazenamento de blob do Azure configurada,
Dados de texto que foram carregados para a sua conta de armazenamento.
Antes de iniciar o processo de treinamento, os documentos rotulados em seu projeto são divididos em um conjunto de treinamento e um conjunto de testes. Cada um deles tem uma função diferente.
O conjunto de treinamento é usado no treinamento do modelo, este é o conjunto a partir do qual o modelo aprende a classe/classes atribuídas a cada documento.
O conjunto de testes é um conjunto cego que não é introduzido no modelo durante o treinamento, mas apenas durante a avaliação.
Depois que o modelo é treinado com sucesso, ele é usado para fazer previsões a partir dos documentos no conjunto de testes. Com base nessas previsões, serão calculadas as métricas de avaliação do modelo.
Recomenda-se certificar-se de que todas as suas aulas estão adequadamente representadas no conjunto de treinamento e teste.
A classificação de texto personalizada suporta dois métodos para divisão de dados:
Dividir automaticamente o conjunto de testes dos dados de treinamento: o sistema dividirá seus dados rotulados entre os conjuntos de treinamento e teste, de acordo com as porcentagens que você escolher. O sistema tentará ter uma representação de todas as classes do seu conjunto de treinamento. A divisão percentual recomendada é de 80% para treinamento e 20% para testes.
Nota
Se você escolher a opção Dividir automaticamente o conjunto de testes dos dados de treinamento , somente os dados atribuídos ao conjunto de treinamento serão divididos de acordo com as porcentagens fornecidas.
Use uma divisão manual de dados de treinamento e teste: esse método permite que os usuários definam quais documentos rotulados devem pertencer a qual conjunto. Esta etapa só será habilitada se você tiver adicionado documentos ao conjunto de testes durante a rotulagem de dados.
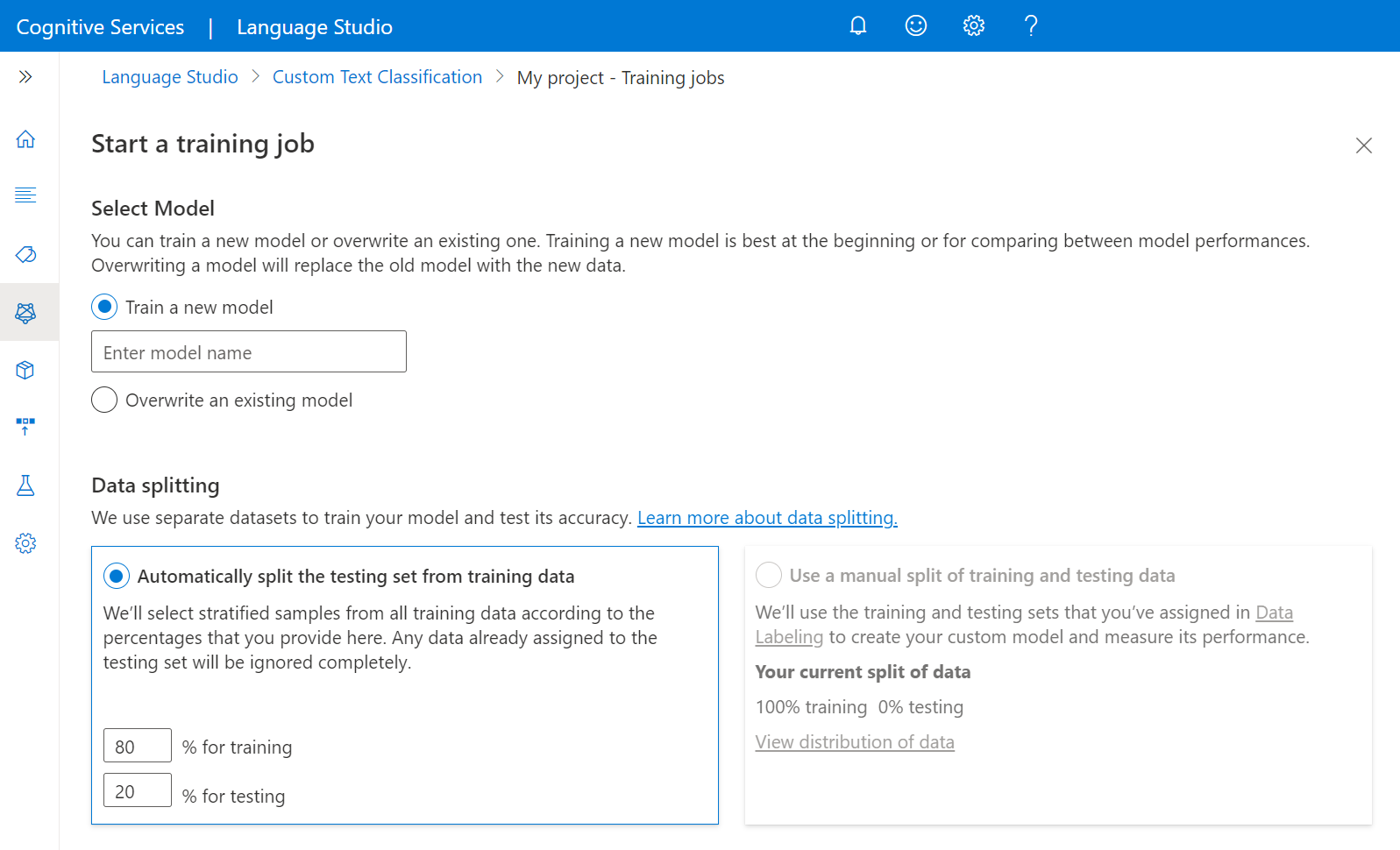
Selecione Trabalhos de treinamento no menu do lado esquerdo.
Selecione Iniciar um trabalho de treinamento no menu superior.
Selecione Treinar um novo modelo e digite o nome do modelo na caixa de texto. Você também pode substituir um modelo existente selecionando essa opção e escolhendo o modelo que deseja substituir no menu suspenso. A substituição de um modelo treinado é irreversível, mas não afetará os modelos implantados até que você implante o novo modelo.
Selecione o método de divisão de dados. Você pode escolher Dividir automaticamente o conjunto de testes dos dados de treinamento, onde o sistema dividirá seus dados rotulados entre os conjuntos de treinamento e teste, de acordo com as porcentagens especificadas. Ou você pode usar uma divisão manual de dados de treinamento e teste, essa opção só é habilitada se você tiver adicionado documentos ao seu conjunto de testes durante a rotulagem de dados. Consulte Como treinar um modelo para obter mais informações sobre a divisão de dados.
Selecione o botão Trem .
Se você selecionar o ID do trabalho de treinamento na lista, um painel lateral aparecerá onde você pode verificar o progresso do treinamento, o status do trabalho e outros detalhes para este trabalho.
Nota
Apenas trabalhos de formação concluídos com sucesso gerarão modelos.
O tempo para treinar o modelo pode levar entre alguns minutos a várias horas com base no tamanho dos dados rotulados.
Só pode ter um trabalho de preparação em execução de cada vez. Não pode iniciar outro trabalho de preparação no mesmo projeto sem que o trabalho em execução esteja concluído.
Iniciar trabalho de formação
Envie uma solicitação POST usando a seguinte URL, cabeçalhos e corpo JSON para enviar um trabalho de treinamento. Substitua os valores de espaço reservado abaixo pelos seus próprios valores.
O nome do seu projeto. Esse valor diferencia maiúsculas de minúsculas.
myProject
{API-VERSION}
A versão da API que você está chamando. O valor referenciado aqui é para a última versão lançada. Saiba mais sobre outras versões de API disponíveis
2022-05-01
Cabeçalhos
Use o cabeçalho a seguir para autenticar sua solicitação.
Key
valor
Ocp-Apim-Subscription-Key
A chave para o seu recurso. Usado para autenticar suas solicitações de API.
Corpo do pedido
Use o JSON a seguir no corpo da solicitação. O modelo será dado assim que o {MODEL-NAME} treinamento for concluído. Só empregos de formação bem sucedidos produzirão modelos.
O nome do modelo que será atribuído ao seu modelo depois de treinado com sucesso.
myModel
trainingConfigVersion
{CONFIG-VERSION}
Esta é a versão do modelo que será usada para treinar o modelo.
2022-05-01
avaliaçãoOpções
Opção para dividir seus dados entre conjuntos de treinamento e teste.
{}
variante
percentage
Métodos de divisão. Os valores possíveis são percentage ou manual. Consulte Como treinar um modelo para obter mais informações.
percentage
formaçãoSplitPercentage
80
Porcentagem dos dados marcados a serem incluídos no conjunto de treinamento. O valor recomendado é 80.
80
testingSplitPercentage
20
Porcentagem dos dados marcados a serem incluídos no conjunto de testes. O valor recomendado é 20.
20
Nota
O trainingSplitPercentage e testingSplitPercentage só são necessários se Kind for definido como percentage e a soma de ambas as percentagens deve ser igual a 100.
Depois de enviar sua solicitação de API, você receberá uma 202 resposta indicando que o trabalho foi enviado corretamente. Nos cabeçalhos de resposta, extraia o location valor. Será formatado da seguinte forma:
{JOB-ID} é utilizado para identificar o seu pedido, uma vez que esta operação é assíncrona. Você pode usar essa URL para obter o status de treinamento.
Obter status de trabalho de treinamento
O treinamento pode levar algum tempo, dependendo do tamanho dos dados de treinamento e da complexidade do esquema. Você pode usar a solicitação a seguir para continuar pesquisando o status do trabalho de treinamento até que ele seja concluído com êxito.
Use a seguinte solicitação GET para obter o status do progresso do treinamento do seu modelo. Substitua os valores de espaço reservado abaixo pelos seus próprios valores.
O nome do seu projeto. Esse valor diferencia maiúsculas de minúsculas.
myProject
{JOB-ID}
O ID para localizar o status de treinamento do seu modelo. Esse valor está no valor do location cabeçalho que você recebeu na etapa anterior.
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx
{API-VERSION}
A versão da API que você está chamando. O valor referenciado aqui é para a última versão lançada. Consulte o ciclo de vida do modelo para saber mais sobre outras versões de API disponíveis.
2022-05-01
Cabeçalhos
Use o cabeçalho a seguir para autenticar sua solicitação.
Key
valor
Ocp-Apim-Subscription-Key
A chave para o seu recurso. Usado para autenticar suas solicitações de API.
Organismo de resposta
Depois de enviar a solicitação, você receberá a seguinte resposta.
Para cancelar um trabalho de formação no Language Studio, aceda à página Trabalhos de formação. Selecione o trabalho de treinamento que deseja cancelar e selecione Cancelar no menu superior.
Crie uma solicitação POST usando a seguinte URL, cabeçalhos e corpo JSON para cancelar um trabalho de treinamento.
URL do Pedido
Use a seguinte URL ao criar sua solicitação de API. Substitua os valores de espaço reservado abaixo pelos seus próprios valores.
Use o cabeçalho a seguir para autenticar sua solicitação.
Key
valor
Ocp-Apim-Subscription-Key
A chave para o seu recurso. Usado para autenticar suas solicitações de API.
Depois de enviar sua solicitação de API, você receberá uma resposta 202 com um Operation-Location cabeçalho usado para verificar o status do trabalho.
Próximos passos
Após a conclusão do treinamento, você poderá visualizar o desempenho do modelo para, opcionalmente, melhorar seu modelo, se necessário. Quando estiver satisfeito com seu modelo, você poderá implantá-lo, disponibilizando-o para uso na classificação de texto.