Redesenhar a topologia de pesquisa empresarial para requisitos de desempenho específicos no SharePoint
APLICA-SE A: 2013 2016 2019 Subscription Edition
2013 2016 2019 Subscription Edition  SharePoint no Microsoft 365
SharePoint no Microsoft 365
Se seu ambiente de pesquisa tiver exigências de desempenho específicas que não foram atendidas seguindo a orientação em Planeje a arquitetura de pesquisa corporativa no SharePoint Server 2016, então, a solução será dimensionar a topologia da arquitetura de pesquisa de sua empresa:
Reconstruir sua topologia (este artigo)
Implemente a topologia reconstruída (Gerenciar a topologia de pesquisa no SharePoint Server)
Você está familiarizado com os componentes do sistema de pesquisa no SharePoint Server 2016 e com o modo como eles interagem? Ao ler Visão geral da arquitetura de pesquisa no SharePoint Server e Arquiteturas de pesquisa do SharePoint Server 2016 (ou Arquiteturas de pesquisa do SharePoint Server 2013) antes de começar, você se familiarizará com a arquitetura de pesquisa, os componentes de pesquisa, os bancos de dados de pesquisa e a topologia de pesquisa.
Neste artigo, mostraremos passo a passo como reconstruir a topologia de pesquisa para atender as exigências de desempenho específicas:
Etapa 3: Escolha executar servidores de modo físico ou virtual
Etapa 4: Qual servidor hospeda qual componente ou banco de dados de pesquisa?
Após ter seguido essas etapas, você saberá:
Quanto de cada tipo de componente de pesquisa e banco de dados de pesquisa sua topologia precisa.
Em quais servidores de aplicativo e de banco de dados implementar cada componente de pesquisa.
De quais recursos de hardware cada servidor de aplicativo e de banco de dados precisa.
Etapa 1: Quais são as exigências de desempenho específicas?
Compreenda as necessidades comerciais por trás das exigências de desempenho específicas. Por exemplo, a pesquisa de notícias e financeira requer dados atuais que são indexados praticamente em tempo real, enquanto os serviços de suporte de litígio requerem a inclusão de batches de dados que são indexados suma vez. Expresse as exigências de desempenho de uma dessas maneiras:
O número de itens indexados
Quantos itens a solução de pesquisa deve rastrear por segundo e com qual latência.
Quantas consultas a solução de pesquisa deve atender por segundo e com qual latência.
Além dessas exigências de desempenho, seu ambiente também pode ter exigências para a relevância dos resultados da consulta e para a topologia de pesquisa ser redundante. Algumas vezes, você não tem uma exigência de desempenho específica, mas identificou um afunilamento na arquitetura de pesquisa que pode afetar o desempenho. Trataremos isso também.
Etapa 2: Quais componentes de pesquisa devo dimensionar?
Para ter um desempenho mais alto ou remover um afunilamento, você pode adicionar mais componentes de pesquisa para fazer o serviço ou adicionar mais recursos aos servidores que hospedam os componentes de pesquisa. Adicionar mais componentes de pesquisa é conhecido como expandir, enquanto adicionar mais recursos aos servidores é conhecido como aumentar. Quais componentes de pesquisa aumentar ou quais servidores expandir depende da métrica do desempenho a melhorar ou o afunilamento a remover. Estes são alguns exemplos:
Se o ambiente requerer uma taxa de consulta mais alta e os recursos da CPU para indexar forem um afunilamento, adicione outra réplica do índice a cada partição do índice. Isto permitirá que a pesquisa atenda a mais consultas paralelamente.
Se os recursos da CPU para processar o conteúdo rastreado forem um afunilamento, expanda o número de componentes de processamento de conteúdo. Você também pode aumentar os componentes de processamento de conteúdo executando-os em servidores com mais CPUs ou CPUs mais rápidas. Qualquer modo de dimensionamento implica em mais recursos da CPU para processar o conteúdo.
Se os componentes de análise não terminarem sua análise rápido o bastante, aumente os recursos do processador, IOPS do disco ou largura de banda da rede dos servidores que hospedam os componentes de análise.
Note que não suportamos uma expansão ilimitada do número de componentes ou banco de dados de pesquisa. Pesquise os limites máximos em Limites da pesquisa e fique dentro desses limites para assegurar uma comunicação adequada e robusta entre os componentes e os bancos de dados de pesquisa. Se for necessário, reduza a capacidade da arquitetura de pesquisa reduzindo o número de componentes de pesquisa.
Nas seguintes seções, temos diretrizes para você sobre quais componentes ou bancos de dados de pesquisa dimensionar para atender cada exigência:
Como aumentar a taxa de inclusão e a atualização dos resultados
Como reduzir a latência da pesquisa e aumentar a taxa de transferência da consulta
Como tornar redundantes os componentes e os bancos de dados de pesquisa
Como lidar com mais itens no índice
Quando a quantidade de itens indexados aumentar enquanto os itens indexados mudam na mesma taxa como antes, aumente a capacidade da topologia de pesquisa expandindo esses componentes e bancos de dados de pesquisa:
| Componente ou banco de dados de pesquisa | Diretriz |
|---|---|
| Componente do índice | Use uma partição do índice para cada 20 milhões1 de itens indexados. Cada partição contém uma ou mais réplicas da partição. Todas as partições devem ter o mesmo número de réplicas. Um componente do índice representa uma réplica do índice. Portanto, se você quiser duas réplicas do índice, então, precisará duas vezes tantos componentes de índice quanto partições de índice. Por exemplo, um índice redundante com 80 milhões2 de itens requer quatro partições. Oito componentes de índice representam as quatro partições ao usar duas réplicas para cada partição. |
| Banco de dados de rastreamento | Use um banco de dados de rastreamento para cada 20 milhões de itens na coleção de conteúdo. Por exemplo, um índice com 10 milhões de itens requer cinco bancos de dados de rastreamento. Se a quantidade aumentada de itens indexados implicar em uma taxa de rastreamento mais alta, você também precisará de mais recursos de IOPS para atender os bancos de dados de rastreamento. Se sua taxa de rastreamento for de um documento por segundo, então, o banco de dados de rastreamento precisará de cerca de 10 IOPS. |
| Banco de dados de links | Use um banco de dados de links para cada 60 milhões de itens na coleção de conteúdo. Por exemplo, um índice com 100 milhões de itens requer dois bancos de dados de links. Se o conteúdo adicionado implicar em uma taxa de rastreamento mais alta, você poderá precisar de mais recursos de IOPS para atender os bancos de dados de links. |
| Banco de Dados de Relatório de Análise | De quantos bancos de dados de relatórios de análise você precisa depende de como o ambiente de pesquisa usa a análise e da frequência. Em geral, adicione um banco de dados de relatórios de análise quando o desempenho da análise começar a diminuir. Por exemplo, quando a atualização noturna do banco de dados começar a levar mais tempo. Isto pode acontecer quando o banco de dados atinge um tamanho de 250 GB ou 20 milhões de linhas no total, ou quando o número de exibições por dia atinge 500.000 itens únicos. |
110 milhões de itens com o SharePoint Server 2013 ou com o SharePoint Server 2016 em execução com menos recursos do que 500 GB de armazenamento, 32 GB de RAM e oito núcleos de CPU.
240 milhões de itens com o SharePoint Server 2013 ou com o SharePoint Server 2016 em execução com menos recursos do que 500 GB de armazenamento, 32 GB de RAM e oito núcleos de CPU.
Como aumentar a taxa de inclusão e a atualização dos resultados
Há algumas situações nas quais você pode precisar aumentar a taxa de inclusão. Um exemplo é se seu ambiente requerer resultados muito atuais e o volume do conteúdo estiver perto do limite superior de itens para a arquitetura de pesquisa ou o conteúdo mudar com frequência. Os conteúdos podem mudar frequentemente se as pessoas utilizassem para arquivar ficheiros num site de equipa, mas agora armazenam os respetivos ficheiros no OneDrive enquanto trabalham nos mesmos. A pesquisa indexa todas as alterações que as pessoas fazem em seus arquivos.
É útil compreender quais fatores influenciam a rapidez com a qual a pesquisa pode incluir os itens:
A rapidez com a qual a pesquisa pode rastrear os itens. Isto depende:
Da velocidade da conexão entre os componentes de rastreamento e as fontes de conteúdo.
Do tipo e do tamanho médio dos itens a rastrear.
Do desempenho do servidor SQL que hospeda os bancos de dados de rastreamento.
Da quantidade de recursos da CPU e de memória que os componentes de rastreamento têm.
De quanto processamento de conteúdo cada item requer antes de indexar.
De quantas partições o índice tem. Mais partições permitem que a pesquisa estenda a carga da indexação.
Eis como fazer:
Verifique a atualização dos resultados em seu farm vendo a distribuição de idade dos itens rastreados. Em site da Administração Central do SharePoint, vá para Relatórios de integridade da pesquisa e selecione Atualização do rastreamento. Qual distribuição de idade é aceitável para seu farm depende das exigências comerciais. Eis um exemplo: Se a página Atualização do rastreamento mostrar que leva quatro horas para indexar 90% do conteúdo, mas sua exigência é de 30 minutos, então, aumente a taxa de inclusão.
Na página Atualização do rastreamento, identifique quais períodos do dia os resultados não são atuais o bastante.
Siga as orientações para aumentar a velocidade de inclusão nesses períodos de tempo.
Melhorar a atualização para uma fonte de conteúdo específica
Verifique o agendamento de rastreamento e identifique quais fontes de conteúdo essa pesquisa rastreia nos períodos de tempo em que a atualização é baixa. Se a atualização for baixa para uma fonte de conteúdo específica, considere o seguinte:
Aumente a velocidade da conexão entre o servidor que hospeda o componente de rastreamento e a fonte de conteúdo. É a taxa de rastreamento, download de itens a partir das fontes de conteúdo e transferência de itens para o componente de processamento de conteúdo que orientam a necessidade de largura de banda da rede para o componente de rastreamento.
Se a fonte de conteúdo for o SharePoint, esse farm poderá precisar de mais destinos de rastreamento e dedicados. Leia sobre os destinos do rastreamento em Gerenciar carga de rastreamento (SharePoint 2010).
Melhore o desempenho do banco de dados de conteúdo. Saiba como em Melhores práticas para o SQL Server em um farm do SharePoint Server.
Aumentar os recursos de processamento para o rastreamento
Se o componente de rastreamento geralmente usa 100% dos recursos do processador, considere adicionar outro componente de rastreamento ou adicionar mais recursos do processador aos servidores que hospedam os componentes de rastreamento. É a taxa de rastreamento, descoberta de links e gerenciamento do rastreamento que orientam a necessidade de recursos do processador. Normalmente, o rastreamento é rápido o bastante quando você usa dois componentes de rastreamento nas arquiteturas de pesquisa, como arquiteturas de pesquisa de amostra pequena e média que a Microsoft testou. As arquiteturas de pesquisa, como as amostras grandes e extremamente grandes, podem ser necessários mais de dois componentes de rastreamento.
Aumentar os recursos do processamento para o banco de dados de rastreamento
Verifique se os servidores SQL que hospedam os bancos de dados de rastreamento têm recursos suficientes. Leia sobre como fazer isto em Melhores práticas para o SQL Server em um farm do SharePoint Server.
Se todos os bancos de dados de rastreamento usarem muitos recursos do processador, considere adicionar mais recursos do processador ao servidor SQL que hospeda os bancos de dados ou adicione outro servidor SQL com o mesmo número de bancos de dados de rastreamento dos servidores SQL existentes. Se você, por exemplo, tiver dois servidores SQL, cada um com três bancos de dados de rastreamento, adicione outro servidor SQL com três bancos de dados de rastreamento.
Se apenas um ou alguns bancos de dados de rastreamento usarem muitos recursos do processador, isto significa que a carga é desigual nesses bancos de dados. Considere equilibrar de novo o conteúdo em todos os bancos de dados de rastreamento. Note que durante o reequilíbrio, a pesquisa pausa o rastreamento, portanto, os resultados são menos atuais durante o reequilíbrio e até que o rastreamento acompanhe as alterações que ocorreram durante pausa. Você inicializa o reequilíbrio com o botão Equilibrar na página Bancos de dados. Em Administração da pesquisa, vá para Log de rastreamento e selecione Bancos de dados.
Aumentar os recursos de processamento e da memória para o processamento do conteúdo
Se o componente de processamento do conteúdo usar perto de 100% dos recursos da CPU, considere adicionar mais componentes de processamento de conteúdo ou adicionar mais recursos da CPU aos servidores que hospedam o componente de processamento do conteúdo.
Se você notar que a memória reinicia com frequência, considere aumentar a quantidade de memória nos servidores que hospedam os componentes de processamento do conteúdo. 2 GB de memória de trabalho por núcleo da CPU é uma boa regra prática.
Aumentar o número de partições do índice
Verifique a atividade de processamento do conteúdo. Você localiza isso indo para Administração da pesquisa selecionando Relatório de integridade do rastreamento, então, selecionando Atividade de processamento do conteúdo. Se a indexação for a atividade que leva mais tempo, considere dividir o índice em mais partições. Mais partições do índice permitem que a pesquisa estenda a carga da indexação.
Se você adicionar mais partições em uma instalação em execução, o índice reparticionará a si mesmo. Pode levar várias horas, ou dias, para o índice reparticionar. Quanto tempo leva depende do estado do farm quando o reparticionamento começa.
Como reduzir a latência da pesquisa e aumentar a taxa de transferência da consulta
Quantas consultas a pesquisa pode atender por segundo é conhecido como taxa de transferência da consulta. A taxa de transferência da consulta depende do tempo que a pesquisa usa para processar uma consulta e qualquer tempo que a consulta aguarda porque um recurso de processamento não está disponível. A soma dos tempos de processamento e de espera é conhecida como latência da consulta. Reduzir a latência da consulta aumenta a taxa de transferência da consulta. Para reduzir a latência da consulta, siga uma ou ambas as diretrizes:
| Diretriz |
|---|
| Reduzir o tempo de processamento para as consultas |
| Reduzir o tempo de espera para as consultas |
Reduzir o tempo de processamento para as consultas
Considere adicionar mais partições ao índice. Mais partições significam menos itens em cada partição. Menos itens significam que cada partição responde mais rapidamente às consultas. Porém, partições demais não é bom também. Como o componente de processamento da consulta tem que mesclar as respostas de cada partição para produzir uma resposta para uma consulta, uma mescla requer mais tempo quando o índice tem mais partições. Todas as partições devem ter o mesmo número de réplicas.
Quando você adiciona mais partições em uma instalação em execução, o índice reparticiona a si mesmo. Pode levar várias horas, ou dias, para o índice reparticionar. Quanto tempo leva depende do estado do farm quando o reparticionamento começa.
Reduzir o tempo de espera para as consultas
Considere estas ações:
Adicione mais réplicas do índice. Quando você adiciona mais réplicas, a pesquisa distribui as consultas nas réplicas e trabalha nelas paralelamente. Um componente do índice representa uma réplica do índice. Todas as partições devem ter o mesmo número de réplicas, portanto, adicione um componente do índice a cada partição do índice. Quando você adiciona componentes do índice como réplicas às partições existentes em uma instalação em execução, a pesquisa distribui automaticamente as novas réplicas com dados a partir da partição do índice. Pode levar várias horas antes das novas réplicas entrarem em operação.
Adicione mais memória aos servidores que hospedam os componentes do índice.
Nos servidores que hospedam os componentes do índice, troque para um armazenamento mais rápido do índice, por exemplo, uma Unidade de Estado Sólido (SSD).
Adicione mais recursos do processador aos servidores que hospedam os componentes do índice. Então, os componentes lidarão com mais consultas por segundo. Por exemplo, se o servidor tiver uma CPU de 2 GHz, um núcleo poderá lidar com:
5 consultas por segundo quando você tiver 1 milhão de itens no índice.
2 consultas por segundo quando você tiver 5 milhões de itens no índice.
1 consulta por segundo quando você tiver 10 milhões de itens no índice.
Adicione mais recursos do processador aos servidores que hospedam os componentes de processamento da consulta. Então, os componentes lidarão com mais consultas por segundo, especialmente quando as consultas não forem frequentes e complexas. É a taxa de consulta e o número de transformações da consulta que orientam a necessidade de recursos do processador para o componente de processamento da consulta. Um componente de processamento da consulta geralmente precisa de um núcleo da CPU por 4 consultas por segundo.
Como reduzir o tempo de processamento da análise
O processamento da análise ocorre toda noite. O componente de processamento da análise armazena os dados intermediários no servidor que hospeda o componente e armazena os resultados da análise no banco de dados de relatórios da análise. Se uma falha impedir o processamento da análise, isso não afetará as consultas de rastreamento ou de resposta do documento. Mas os resultados da consulta não terão a relevância ideal.
Considere estas ações:
Se seu ambiente requerer uma relevância ideal para os resultados da consulta e o processamento da análise não for rápido o bastante para atender isto, adicione mais discos (eixos) ou discos mais rápidos.
Se o processamento da análise iniciar levando mais tempo que o usual, adicione um banco de dados de relatórios da análise. Você pode ver tal aumento quando o banco de dados atinge um tamanho de 250 GB ou 20 milhões de linhas no total, ou quando o número de exibições por dia atinge 500.000 itens únicos.
Se o processamento da análise levar mais de 24 horas para terminar, adicione mais componentes de processamento da análise ou adicione mais recursos do processador aos servidores que hospedam os componentes de processamento da análise. É o número de itens no índice e a atividade no site que orientam a necessidade de recursos do processador.
Se o processamento da análise nunca terminar ou você vir alertas de integridade dos discos nos servidores que hospedam os componentes da análise, adicione mais espaço de disco aos servidores. Para o componente da análise processar uma quantidade maior de dados intermediários mais rapidamente, considere adicionar mais componentes de processamento da análise ou mais recursos do processador ao servidor que hospeda o componente de processamento da análise.
Como tornar redundantes os componentes e os bancos de dados de pesquisa
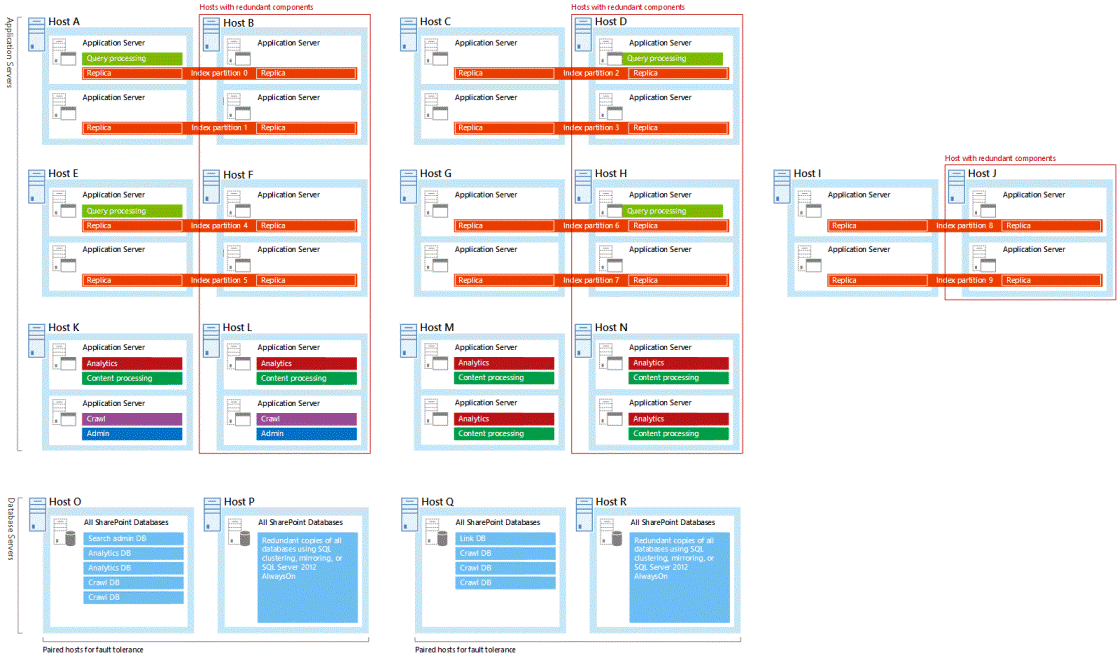
Sua arquitetura de pesquisa oferece suporte a alta disponibilidade quando você hospeda componentes e bancos de dados de pesquisa em domínios de falha separado. Recomendamos que crie a sua topologia de pesquisa com bases de dados e componentes de pesquisa redundantes. Todas as arquiteturas de pesquisa de exemplo testadas pela Microsoft têm bases de dados e componentes de pesquisa redundantes. Poderá considerar útil estudar estes exemplos ao trabalhar na sua própria topologia (consulte Arquiteturas de Pesquisa Empresarial para o SharePoint 2016).
Siga estas diretrizes:
Tornar redundante o índice
Seu índice será redundante se tiver duas ou mais réplicas de índice por partição do índice. Se um servidor que hospeda uma réplica do índice falhar, isto poderá reduzir o desempenho, mas a pesquisa ainda poderá atender as consultas e os itens do índice. Mas, se o ambiente requerer o mesmo desempenho sempre, a pesquisa precisará de mais componentes do índice redundantes. Por exemplo, você construiu sua topologia de pesquisa com duas réplicas por partição para reduzir o tempo de espera para as consultas e seu ambiente requer um tempo de espera pequeno para as consultas sempre. Aumente o número de réplicas do índice por partição.
Todas as partições devem ter o mesmo número de réplicas. Um componente do índice representa uma réplica do índice. Portanto, se você quiser duas réplicas do índice, precisará do dobro de componentes do índice em relação ao número de partições do índice. Por exemplo, com o SharePoint Server 2016, um índice redundante com 80 milhões de itens requer quatro partições. Oito componentes do índice representam as quatro partições ao usar duas réplicas para cada partição.
Se você adicionar componentes do índice como réplicas às partições existentes em uma instalação em execução, a pesquisa distribuirá automaticamente as novas réplicas com os dados a partir da partição do índice. Pode levar várias horas antes das novas réplicas entrarem em operação.
Torne redundantes o rastreamento, processamentos do conteúdo, da consulta, da análise e administração da pesquisa
Vamos usar o componente de rastreamento como um exemplo. Se você precisar desativar um dos servidores que hospedam um componente de rastreamento para a manutenção, isso poderá reduzir a atualização dos resultados, mas a pesquisa ainda poderá rastrear todo o conteúdo. Mas, se o ambiente requerer a mesma atualização dos resultados sempre, a pesquisa precisará de mais componentes de rastreamento redundantes. Por exemplo, você criou a topologia de pesquisa com três componentes de rastreamento e deseja a mesma atualização dos resultados, mesmo se dois servidores do componente de rastreamento falharem. Adicione mais dois componentes de rastreamento.
O componente de administração da pesquisa é uma exceção a este princípio. Um componente de administração da pesquisa tem capacidade suficiente para uma topologia de pesquisa de qualquer tamanho. Portanto, dois componentes de administração da pesquisa são suficientes para a redundância.
Os componentes de processamento do conteúdo equilibram a carga entre si, portanto, os componentes de processamento do conteúdo redundantes aumentam a capacidade para processar os itens.
Torne redundantes os bancos de dados de pesquisa
Para tornar seus bancos de dados de pesquisa redundantes, use as alternativas de alta disponibilidade que o servidor do SQL oferece (confira Crie uma arquitetura e uma estratégia de alta disponibilidade para o SharePoint Server).
Etapa 3: Escolha executar servidores de modo físico ou virtual
Quando você planejou originalmente a arquitetura de pesquisa, decidiu usar servidores físicos ou máquinas virtuais, ou uma mistura deles. Considere se essa decisão ainda é válida. Se você agora tiver muito mais componentes de pesquisa, poderá querer usar máquinas virtuais para facilitar o gerenciamento da arquitetura. Por exemplo, é mais fácil substituir uma máquina virtual com falha do que uma máquina física. Note também que embora um ambiente virtual seja mais fácil de gerenciar, o nível de seu desempenho pode, algumas vezes, ser um pouco inferior que de um ambiente físico. Um servidor físico pode hospedar mais componentes de pesquisa no mesmo servidor que um servidor virtual. Você encontrará uma orientação útil em Overview of farm virtualization and architectures for SharePoint 2013.
Etapa 4: Qual servidor hospeda qual componente ou banco de dados de pesquisa?
Agora que você reconstruiu a topologia de pesquisa, sua próxima etapa será atribuir os componentes de pesquisa e do banco de dados a servidores físicos ou virtuais. Não há uma maneira ideal de atribuir os componentes de pesquisa a serviços físicos ou máquinas virtuais, mas temos diretrizes para você:
Um tipo de componente de pesquisa por servidor
Cada servidor físico ou máquina virtual pode hospedar apenas um componente de pesquisa de cada tipo. O componente do índice é uma exceção. Os servidores físicos ou máquinas virtuais podem hospedar até quatro componentes de índice. Você pode ler sobre esses limites em Limites da pesquisa.
Separar os componentes de processamento em massa e de tempo real uns dos outros
Evite misturar os componentes de pesquisa de processamento em massa e de tempo real no mesmo servidor físico ou máquina virtual. Os componentes de rastreamento, processamentos de conteúdo e de análise realizam o processamento em massa. Os componentes de processamento de índice e de consulta realizam o processamento em tempo real.
Não misturar componentes de pesquisa concorrentes
Evite misturar os componentes de pesquisa em um servidor físico ou máquina se os componentes competirem pelos mesmos recursos. Eis uma tabela que mostra a quantidade relativa de recursos que cada componente precisa.
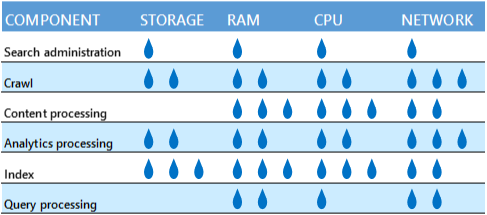
Por exemplo, pode não ser uma boa ideia colocar um componente de processamento de rastreamento e de análise no mesmo servidor porque eles usam muita largura de banda da rede. Mas, se o servidor físico ou a máquina virtual tiver bastante capacidade de rede, os componentes não irão competir.
Outro exemplo é a amostra de arquitetura de pesquisa extremamente grande que a Microsoft testou. Aqui, colocamos os componentes de rastreamento e de administração da pesquisa em máquinas virtuais separadas. Isso auxilia a velocidade do rastreamento já que, caso contrário, os dois componentes poderiam competir pelos recursos do processador.
Usar domínios de falha
Atribua os componentes de pesquisa redundantes a hosts em domínios com falha separados.
Etapa 5: Quais exigências de hardware devo conhecer?
A próxima etapa é planejar o hardware necessário:
Escolher a quantidade de recursos de hardware para os servidores de host
Recursos mínimos para o componente de processamento da análise
Escolher como sua arquitetura de pesquisa oferece suporte à alta disponibilidade
Escolher a quantidade de recursos de hardware para os servidores de host
Cada componente de pesquisa e banco de dados de pesquisa requer uma quantidade mínima de recursos de hardware do servidor de host para ser bem executado. Porém, quanto mais recursos de hardware você tiver, melhor será o desempenho da arquitetura de pesquisa. Portanto, é uma boa ideia ter mais do que a quantidade mínima de recursos de hardware. Os recursos que cada componente de pesquisa requer depende da carga de trabalho, em grande parte determinada pela taxa de rastreamento, taxa de consulta e número de itens indexados.
Por exemplo, ao hospedar máquinas virtuais no Windows Server 2008 R2 Service Pack 1 (SP1), você não pode usar mais de quatro núcleos da CPU por máquina virtual. Com o Windows Server 2012 ou mais recente, você usa oito ou mais núcleos da CPU por máquina virtual. Então, pode expandir com mais núcleos da CPU para cada máquina virtual, ao invés de aumentar com mais máquinas virtuais. Configure os servidores ou as máquinas virtuais que hospedam os mesmos componentes de pesquisa com os mesmos recursos de hardware. Usaremos o componente de índice como um exemplo. Quando você hospeda partições do índice nas máquinas virtuais, a máquina virtual com o desempenho mais fraco determina o desempenho da arquitetura de pesquisa geral.
Armazenamento geral
Verifique se cada servidor de host tem espaço em disco suficiente para a instalação básica do sistema operacional do Windows Server e para os arquivos de programa do SharePoint Server 2016. O servidor de host também precisa de espaço livre no disco rígido para fazer diagnósticos, como log, depuração e criação de despejos da memória para as operações diárias e para o arquivo de página. Normalmente, 80 GB de espaço em disco são suficientes para o sistema operacional do Windows Server e para os arquivos de programa do SharePoint Server 2016.
Adicione armazenamento para o espaço de log do SQL para cada servidor do banco de dados. Se você não definir o servidor do banco de dados para fazer backup dos bancos de dados com frequência, o espaço de log do SQL usará muito armazenamento. Para mais informações sobre como planejar os bancos de dados SQL, consulte Configuração e planejamento da capacidade de armazenamento do SQL Server (SharePoint Server).
O armazenamento mínimo que o banco de dados de relatórios da análise requer pode variar. É porque a quantidade de armazenamento depende de como os usuários interagem com o SharePoint Server 2016. Quando os usuários interagem com frequência, em geral há mais eventos a armazenar. Verifique a quantidade de armazenamento que sua arquitetura de pesquisa atual usa para o banco de dados de análise e atribua pelo menos essa quantidade para sua topologia reconstruída.
Recursos mínimos para o componente de índice
São os recursos mínimos que um servidor ou máquina virtual deve ter para hospedar um componente de índice ou hospedar um componente de índice e um componente de processamento de consulta:
| Armazenamento | Memória | Processador | Largura de banda da rede |
| 500 GB para o índice1 | 32 GB1 | 64 bits, 8 núcleos no mínimo1, 2. | 2 Gbps |
1Com o SharePoint Server 2013, a quantidade mínima de recursos é de 500 GB de armazenamento, 16 GB de RAM e quatro núcleos de CPU.
2É possível usar 16 GB de RAM e quatro núcleos da CPU com o SharePoint Server 2016, mas, desse modo, cada componente do índice poderá conter, no máximo, até 10 milhões itens (em vez de 20 milhões de itens).
Recursos mínimos para o componente de processamento da análise
São os recursos mínimos que um servidor ou máquina virtual deve ter para hospedar um componente de processamento da análise:
| Armazenamento | Memória | Processador | Largura de banda da rede |
| 300 GB para o processamento local da análise | 8 GB | 64 bits, 4 núcleos no mínimo, mas 8 núcleos recomendados. | 2 Gbps |
Se o servidor hospedar um componente de processamento da análise e um ou mais componentes de processamento em massa, aumente a memória para 16 GB.
Recursos mínimos para o rastreamento, processamentos do conteúdo e de consulta, e componente de administração da pesquisa
São os recursos mínimos que um servidor ou máquina virtual deve ter para hospedar um desses componentes:
| Armazenamento | Memória | Processador | Largura de banda da rede |
| Não requerido | 8 GB | 64 bits, 4 núcleos no mínimo, mas 8 núcleos recomendados. | 2 Gbps |
Se o servidor hospedar dois ou mais desses componentes, aumente a memória para 16 GB.
O componente de processamento da consulta requer uma boa largura de banda da rede. É o número de partições do índice, o tamanho das consultas e os resultados que orientam a necessidade por largura de banda da rede. Por exemplo, 20 consultas por segundo por componente de processamento da consulta (20 QPS/QPC) e um índice com 20 partições do índice resultam em 200 Mbps de tráfego de entrada e 100 Mbps de tráfego de saída para o servidor ou máquina virtual hospedando o componente de processamento da consulta.
Recursos mínimos para os bancos de dados de pesquisa
Veja os recursos mínimos que um servidor ou máquina virtual devem ter para hospedar um ou mais banco de dados de pesquisa:
| Armazenamento | Memória | Processador | Largura de banda da rede |
| O armazenamento que o banco de dados de relatórios de análise requer varia com o modo como o ambiente de pesquisa usa a análise e a frequência. Use a quantidade atual de armazenamento para o banco de dados de relatórios da análise como uma orientação. | 8 GB para pequenas implantações 16 GB para implantações médias |
64 bits, 4 núcleos. | 2 Gbps |
Planejar o desempenho do armazenamento
A velocidade do armazenamento afeta o desempenho da pesquisa. Verifique se o armazenamento de que você dispõe é rápido o bastante para lidar com o tráfego dos componentes e bancos de dados de pesquisa. A velocidade do disco é medida em operações de E/S por segundo (IOPS).
O modo como você decide distribuir os dados a partir dos componentes de pesquisa e do sistema operacional em seu armazenamento afeta o desempenho da pesquisa. É uma boa ideia:
Dividir os arquivos do sistema operacional do Windows Server, arquivos de programa do SharePoint Server 2016 e logs de diagnóstico em três volumes de armazenamento separados ou partições com desempenho normal.
Armazenar os dados do componente de pesquisa em um volume de armazenamento separado ou partição. Para os componentes do índice, esse armazenamento também deve ter um alto desempenho.
Observação
[!OBSERVAçãO] Você pode definir um local personalizado para os dados do componente de pesquisa quando instala o SharePoint Server 2016 em um host. Qualquer componente de pesquisa no host que precisar armazenar dados, irá armazená-los nesse local. Para mudar o local depois, você terá que reinstalar o SharePoint Server 2016.
Escolher o tipo de armazenamento
Para ter uma visão geral das arquiteturas de armazenamento e tipos de discos, confira Armazenamento, planejamento e configuração da capacidade do SQL Server (SharePoint Server 2016). Os servidores que hospedam os componentes do índice, processamento de análise e administração da pesquisa, ou bancos de dados de pesquisa, requerem um armazenamento que possa manter baixa latência, mantendo, ao mesmo tempo, operações de E/S por segundo (IOPS) suficientes. As tabelas seguintes mostram quantas IOPS são requeridas por cada um desses componentes e bancos de dados de pesquisa.
Se você implantar um armazenamento compartilhado como SAN/NAS, a carga de pico do disco de um componente de pesquisa geralmente coincidirá com a carga de pico do disco de outro componente de pesquisa. Para obter o número da pesquisa IOPS requerido no armazenamento compartilhado, é preciso adicionar o requisito de IOPS de cada um desses componentes.
Pesquisar os requisitos de IOPS do componente
| Nome do componente | Detalhes do componente | Requisitos de IOPS | Uso do volume/partição de armazenamento separado |
|---|---|---|---|
| Componente do índice | Usa o armazenamento ao mesclar o índice, ao lidar e responder a consultas. | 300 IOPS para 64 KB de leituras aleatórias. 100 IOPS para 256 KB de gravações aleatórias. 200 MB/s para leituras sequenciais. 200 MB/s para gravações sequenciais. |
Sim |
| Componente de análise | Analisa os dados localmente, no processamento em massa. | Não | Sim |
| Componente de rastreamento | Armazena o conteúdo baixado localmente, antes de enviar para um componente de processamento do conteúdo. O armazenamento é limitado pela largura de banda da rede. | Não | Sim |
Pesquisar requisitos de IOPS do banco de dados
| Nome do banco de dados | Requisitos de IOPS | Carga típica no subsistema de E/S. |
|---|---|---|
| Banco de dados de rastreamento | IOPS médio a alto | 10 IOPS por taxa de rastreamento de 1 documento por segundo (DPS). |
| Banco de dados de links | IOPS médio | 10 IOPS por 1 milhão de itens no índice da pesquisa. |
| Banco de dados de Administração de Pesquisa | IOPS baixo | Não aplicável. |
| Banco de Dados de Relatório de Análise | IOPS médio | Não aplicável. |
Escolher como sua arquitetura de pesquisa oferece suporte à alta disponibilidade
Se você não estiver familiarizado com as estratégias de alta disponibilidade, eis um artigo para começar: Crie uma arquitetura e uma estratégia de alta disponibilidade para o SharePoint Server. Quando você hospeda componentes e bancos de dados de pesquisa redundantes em domínios com falha separados, uma interrupção em uma parte do farm não deixa inativo o serviço inteiro. Mas, o desempenho da pesquisa diminuirá porque os componentes da pesquisa não poderão mais compartilhar a carga. Para reduzir a chance de perder um servidor, é uma boa ideia melhorar a redundância local. Para cada servidor de host na arquitetura de pesquisa:
Use um armazenamento RAID em cada servidor.
Instale diversas conexões de rede redundantes em cada servidor.
Instale diversas fontes de energia com fiação independente ou um no-break (UPS) para cada servidor.
Todas as arquiteturas de pesquisa de amostra hospedam componentes de pesquisa redundantes em servidores independentes. Nas arquiteturas de pesquisa de amostra, o host mais à direita em cada par de hosts é redundante. Eis uma arquitetura de pesquisa grande com os hosts redundantes descritos: