Como modificar uma base de dados Lake
Neste artigo, irá aprender a modificar uma base de dados lake existente no Azure Synapse com o estruturador da base de dados. O estruturador de bases de dados permite-lhe criar e implementar facilmente uma base de dados sem escrever código.
Pré-requisitos
- São necessárias permissões de Administrador do Synapse ou Contribuidor do Synapse na área de trabalho do Synapse para criar uma base de dados lake.
- As permissões de Contribuidor de Dados de Blobs de Armazenamento são necessárias no data lake ao utilizar a opção criar tabela a partir do data lake .
Modificar propriedades da base de dados
No hub Base da área de trabalho do Azure Synapse Analytics, selecione o separador Dados à esquerda. O separador Dados será aberto. Verá a lista de bases de dados que já existem na sua área de trabalho.
Paire o cursor sobre a secção Bases de Dados e selecione as reticências ... junto à base de dados que pretende modificar e, em seguida, selecione Abrir.
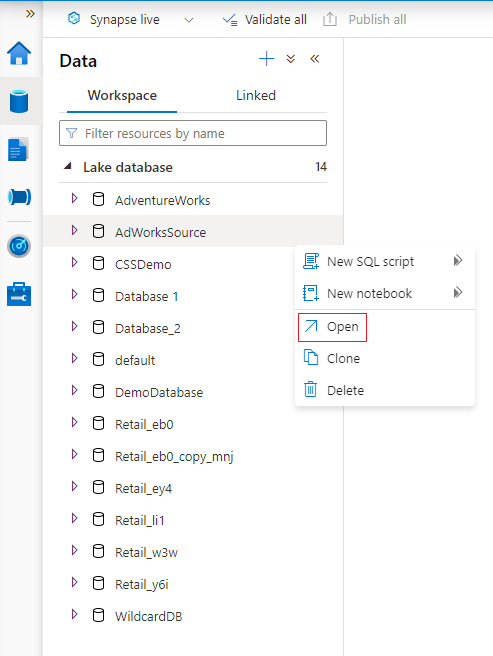
O separador estruturador da base de dados será aberto com a base de dados selecionada carregada na tela.
O estruturador da base de dados tem o painel Propriedades que pode ser aberto ao selecionar o ícone Propriedades no canto superior direito do separador.
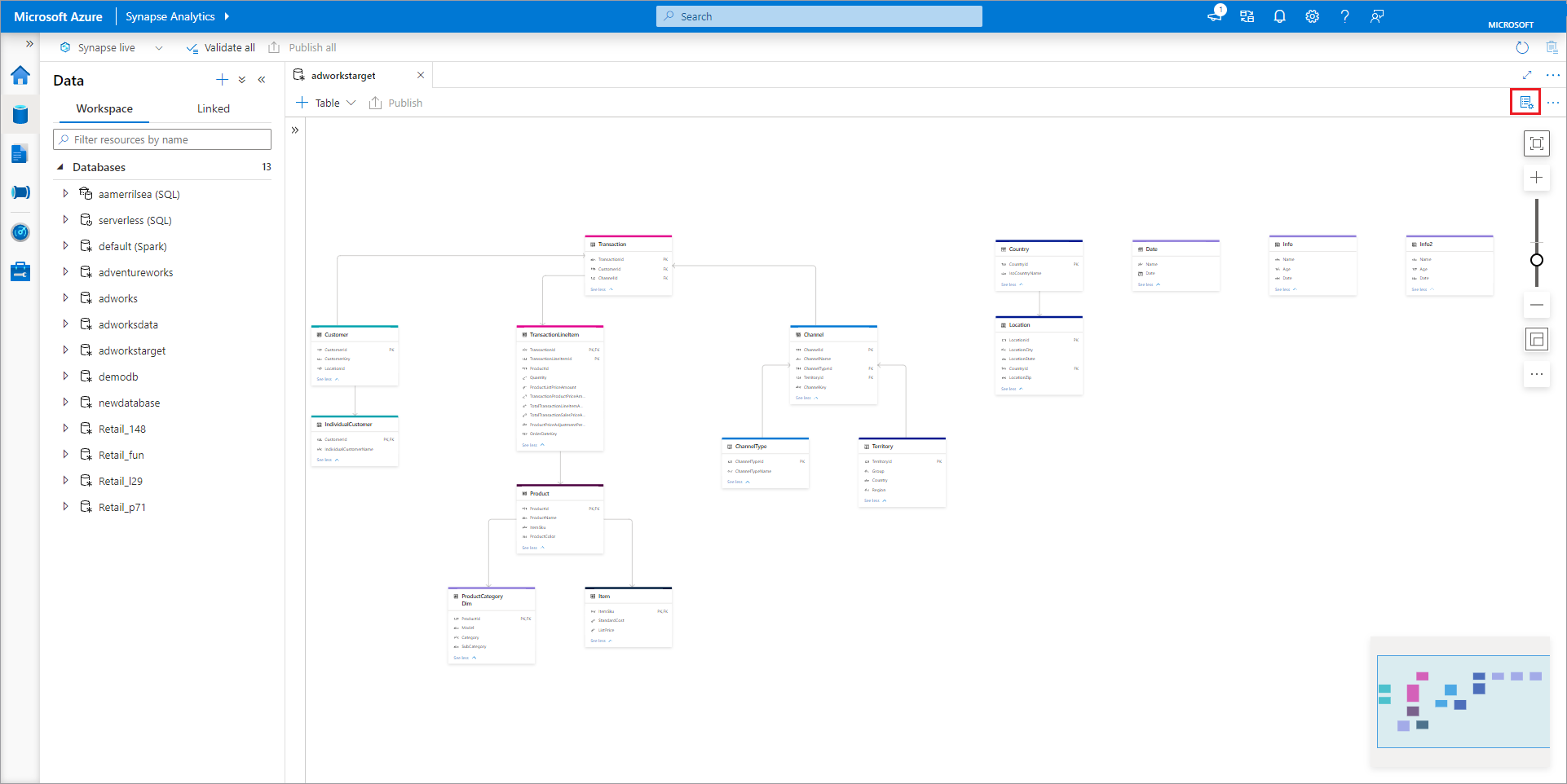
- Nome Os nomes não podem ser editados após a publicação da base de dados, por isso certifique-se de que o nome que escolher está correto.
- Descrição Dar uma descrição à base de dados é opcional, mas permite que os utilizadores compreendam o objetivo da base de dados.
- As definições de armazenamento da base de dados são uma secção que contém as informações de armazenamento predefinidas para tabelas na base de dados. As predefinições são aplicadas a cada tabela na base de dados, a menos que seja substituída na própria tabela.
- O serviço ligado é o serviço ligado predefinido utilizado para armazenar os seus dados no Azure Data Lake Storage. Será apresentado o serviço ligado predefinido associado à área de trabalho do Synapse, mas pode alterar o Serviço Ligado para qualquer conta de armazenamento do ADLS que quiser.
- Pasta de entrada utilizada para definir o caminho de contentor e pasta predefinido nesse serviço ligado com o browser de ficheiros ou editar manualmente o caminho com o ícone de lápis.
- As bases de dados de formatação de dados no Azure Synapse suportam texto parquet e delimitado como formatos de armazenamento para dados.
Para adicionar uma tabela à base de dados, selecione o botão + Tabela .
- Personalizar irá adicionar uma nova tabela à tela.
- A partir do modelo , irá abrir a galeria e permitir-lhe selecionar um modelo de base de dados a utilizar ao adicionar uma nova tabela. Para obter mais informações, veja Criar uma base de dados lake a partir do modelo de base de dados.
- A partir do data lake permite-lhe importar um esquema de tabela com dados já existentes no seu lago.
Selecione Personalizado. Será apresentada uma nova tabela na tela denominada Table_1.
Em seguida, pode personalizar Table_1, incluindo o nome da tabela, descrição, definições de armazenamento, colunas e relações. Veja a secção Personalizar tabelas numa base de dados abaixo.
Adicione uma nova tabela a partir do data lake ao selecionar + Tabela e, em seguida , A partir do data lake.
Será apresentado o painel Criar tabela externa a partir do data lake . Preencha o painel com os detalhes abaixo e selecione Continuar.
- Nome da tabela externa o nome que pretende dar à tabela que está a criar.
- Serviço ligado o serviço ligado que contém a localização Azure Data Lake Storage onde se encontra o ficheiro de dados.
-
O ficheiro ou pasta de entrada utiliza o browser de ficheiros para navegar e selecionar um ficheiro no seu lago com o qual pretende criar uma tabela.
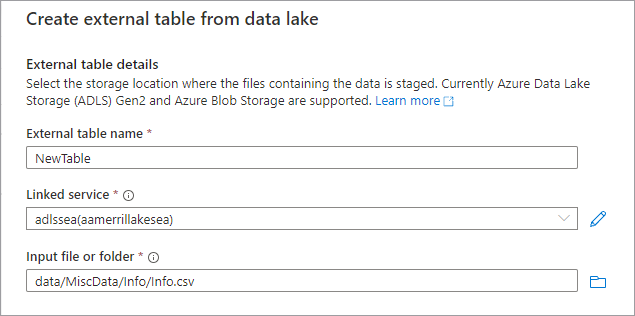
- No ecrã seguinte, Azure Synapse irá pré-visualizar o ficheiro e detetar o esquema.
- Irá aceder à página Nova tabela externa, onde pode atualizar quaisquer definições relacionadas com o formato de dados e Pré-visualizar Dados para verificar se Azure Synapse identificado corretamente o ficheiro.
- Quando estiver satisfeito com as definições, selecione Criar.
- Será adicionada uma nova tabela com o nome que selecionou à tela e a secção Definições de armazenamento da tabela mostrará o ficheiro que especificou.
Com a base de dados personalizada, está na altura de a publicar. Se estiver a utilizar a integração do Git com a sua área de trabalho do Synapse, tem de consolidar as suas alterações e intercalá-las no ramo de colaboração. Saiba mais sobre o controlo de origem no Azure Synapse. Se estiver a utilizar o modo Synapse Live, pode selecionar "publicar".
A base de dados será validada para erros antes de ser publicada. Quaisquer erros encontrados serão apresentados no separador notificações com instruções sobre como corrigir o erro.
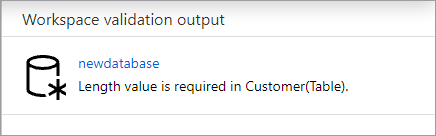
A publicação irá criar o esquema da base de dados no metastore Azure Synapse. Após a publicação, os objetos da base de dados e da tabela serão visíveis para outros serviços do Azure e permitirão que os metadados da base de dados fluam para aplicações como o Power BI ou o Microsoft Purview.
Personalizar tabelas numa base de dados
O estruturador de bases de dados permite-lhe personalizar totalmente qualquer uma das tabelas na sua base de dados. Quando seleciona uma tabela, existem três separadores disponíveis, cada um com definições relacionadas com o esquema ou metadados da tabela.
Geral
O separador Geral contém informações específicas da própria tabela.
Dê um nome ao nome da tabela. O nome da tabela pode ser personalizado para qualquer valor exclusivo na base de dados. Não são permitidas várias tabelas com o mesmo nome.
Herdado de (opcional) este valor estará presente se a tabela tiver sido criada a partir de um modelo de base de dados. Não é possível editá-la e indica ao utilizador de que tabela de modelo foi derivada.
Descrição de uma descrição da tabela. Se a tabela tiver sido criada a partir de um modelo de base de dados, esta ação conterá uma descrição do conceito representado por esta tabela. Este campo é editável e pode ser alterado para corresponder à descrição que corresponde aos seus requisitos comerciais.
A pasta de apresentação fornece o nome da pasta área de negócio na qual esta tabela foi agrupada como parte do modelo de base de dados. Para tabelas personalizadas, este valor será "Outro".
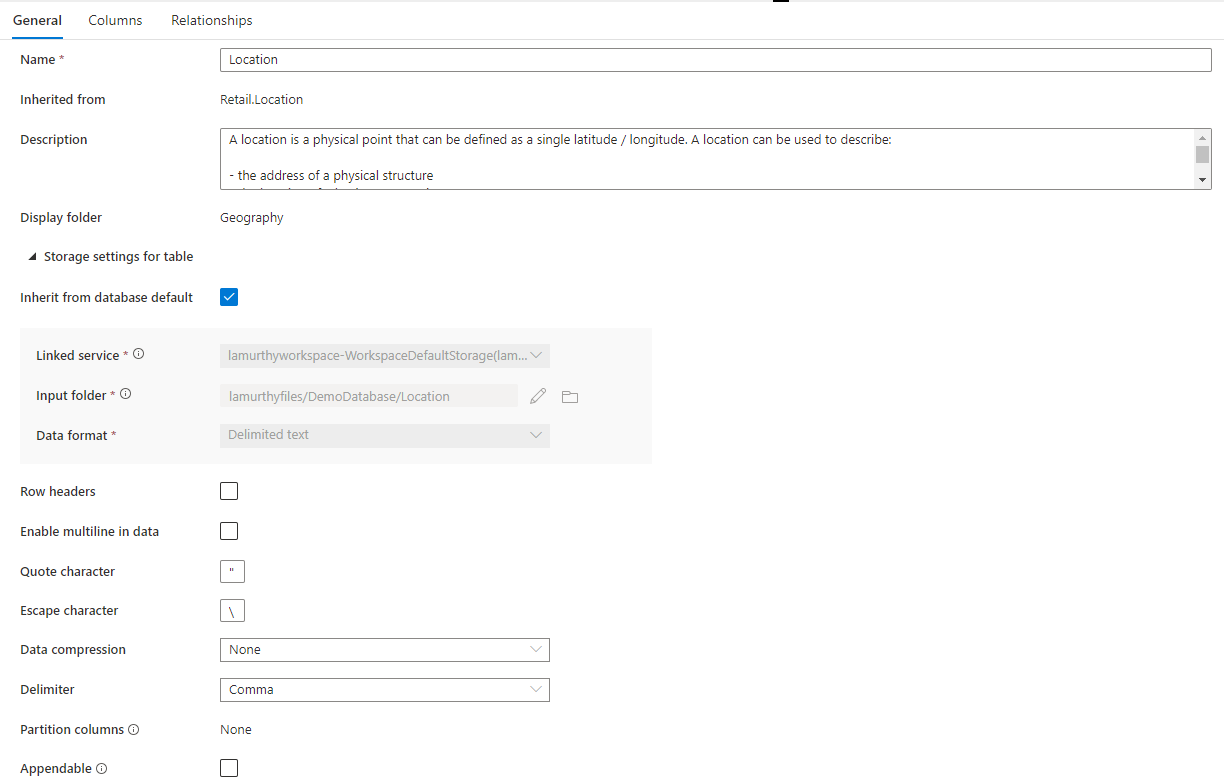
Além disso, existe uma secção desmontável denominada Definições de armazenamento para tabela que fornece definições para as informações de armazenamento subjacentes utilizadas pela tabela.
Herdar da predefinição da base de dados uma caixa de verificação que determina se as definições de armazenamento abaixo são herdadas dos valores definidos no separador Propriedades da base de dados ou se são definidas individualmente. Se quiser personalizar os valores de armazenamento, desmarque esta caixa.
- O serviço ligado é o serviço ligado predefinido utilizado para armazenar os seus dados no Azure Data Lake Storage. Altere esta opção para escolher uma conta do ADLS diferente.
- Pasta de entrada da pasta no ADLS onde os dados carregados para esta tabela irão residir. Pode procurar na localização da pasta ou editá-la manualmente com o ícone de lápis.
- Os dados formatam o formato de dados dos dados nas bases de dados input folder Lake no Azure Synapse suportam texto parquet e delimitado como formatos de armazenamento para dados. Se o formato de dados não corresponder aos dados na pasta, as consultas à tabela falharão.
Para um Formato de dados de texto delimitado, existem outras definições:
- Os cabeçalhos de linha verificam esta caixa se os dados têm cabeçalhos de linha.
- Ative a opção multiline nos dados , selecione esta caixa se os dados têm múltiplas linhas numa coluna de cadeia.
- Caráter de Citação especifique o caráter de cotação personalizado para um ficheiro de texto delimitado.
- O Caráter de Escape especifica o caráter de escape personalizado para um ficheiro de texto delimitado.
- Compressão de dados o tipo de compressão utilizado nos dados.
- Delimite o delimitador de campos utilizado nos ficheiros de dados. Os valores suportados são: Vírgula (,), tabulação (\t) e pipe (|).
- Colunas de partição a lista de colunas de partições será apresentada aqui.
- Selecione esta caixa se estiver a consultar dados do Dataverse a partir do SQL Sem Servidor.
Para dados parquet, existe a seguinte definição:
- Compressão de dados o tipo de compressão utilizado nos dados.
Colunas
O separador Colunas é onde as colunas da tabela estão listadas e podem ser modificadas. Neste separador encontram-se duas listas de colunas: colunas padrão e colunas partições.
As colunas padrão são qualquer coluna que armazene dados, é uma chave primária e, caso contrário, não é utilizada para a criação de partições dos dados.
As colunas de partição também armazenam dados, mas são utilizadas para dividir os dados subjacentes em pastas com base nos valores contidos na coluna. Cada coluna tem as seguintes propriedades.
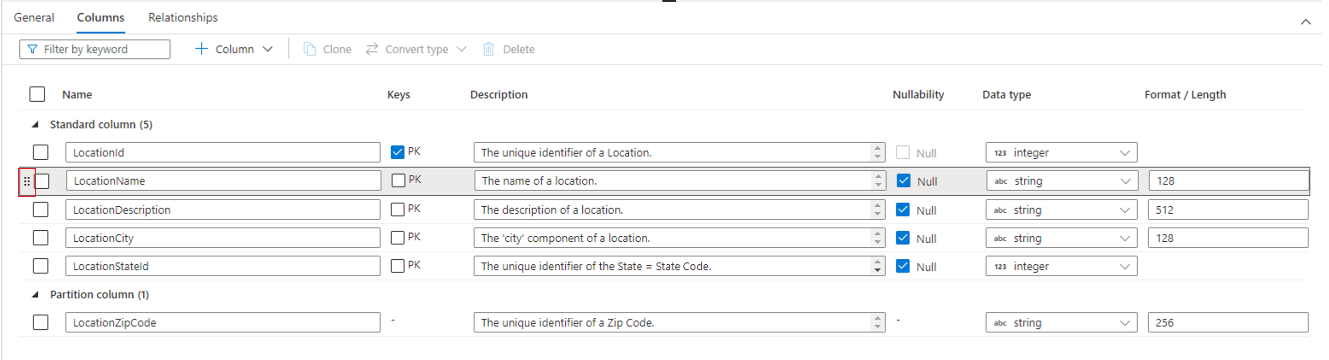
- Atribua o nome da coluna. Tem de ser exclusivo dentro da tabela.
- As chaves indicam se a coluna é uma chave primária (PK) e/ou chave externa (FK) para a tabela. Não aplicável às colunas de partição.
- Descrição de uma descrição da coluna. Se a coluna tiver sido criada a partir de um modelo de base de dados, será vista a descrição do conceito representado por esta coluna. Este campo é editável e pode ser alterado para corresponder à descrição que corresponde aos seus requisitos comerciais.
- A Nullability indica se podem existir valores nulos nesta coluna. Não aplicável a colunas de partição.
- O tipo de dados define o tipo de dados da Coluna com base na lista disponível de tipos de dados do Spark.
- O formato/comprimento permite personalizar o formato ou o comprimento máximo da coluna, consoante o tipo de dados. Os tipos de dados de data e carimbo de data/hora têm listas pendentes de formato e outros tipos, como a cadeia, têm um campo de comprimento máximo. Nem todos os tipos de dados têm um valor, uma vez que alguns tipos têm um comprimento fixo. Na parte superior do separador Colunas encontra-se uma barra de comandos que pode ser utilizada para interagir com as colunas.
- Filtrar por palavra-chave filtra a lista de colunas para itens que correspondem à palavra-chave especificada.
-
+ Coluna permite-lhe adicionar uma nova coluna. Existem três opções possíveis.
- A nova coluna cria uma nova coluna padrão personalizada.
- O modelo abre o painel de exploração e permite-lhe identificar colunas de um modelo de base de dados a incluir na sua tabela. Se a base de dados não tiver sido criada com um modelo de base de dados, esta opção não será apresentada.
- A coluna partição adiciona uma nova coluna de partição personalizada.
- Clonar duplica a coluna selecionada. As colunas clonadas são sempre do mesmo tipo que a coluna selecionada.
- O tipo de conversão é utilizado para alterar a coluna padrão selecionada para uma coluna de partição e para o contrário. Esta opção estará desativada se tiver selecionado várias colunas de diferentes tipos ou se a coluna selecionada não for elegível para ser convertida devido a um sinalizador PK ou Nulo definido na coluna.
- Eliminar elimina as colunas selecionadas da tabela. Esta ação é irreversível.
Também pode reorganizar a ordem das colunas ao arrastar e largar com as reticências verticais duplas que aparecem à esquerda do nome da coluna quando paira o cursor do rato ou clica na coluna, conforme mostrado na imagem acima.
Colunas de Partição
As colunas de partição são utilizadas para particionar os dados físicos na base de dados com base nos valores dessas colunas. As colunas de partição permitem uma forma fácil de distribuir dados no disco em segmentos mais eficazes. As colunas de partição no Azure Synapse estão sempre no fim do esquema da tabela. Além disso, são utilizadas de cima para baixo ao criar as pastas de partição. Por exemplo, se as colunas de partição fossem Ano e Mês, acabaria com uma estrutura no ADLS da seguinte forma:
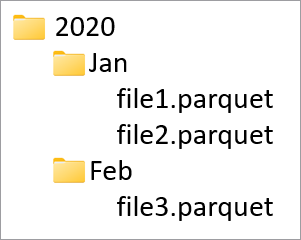
Em que file1 e file2 continham todas as linhas em que os valores de Ano e Mês eram 2020 e Jan, respetivamente. À medida que são adicionadas mais colunas de partição a uma tabela, mais ficheiros são adicionados a esta hierarquia, tornando o tamanho de ficheiro geral das partições mais pequeno.
Azure Synapse não impõe nem cria esta hierarquia ao adicionar colunas de partição a uma tabela. Os dados têm de ser carregados para a tabela com o Synapse Pipelines ou um bloco de notas do Spark para que a estrutura de partição seja criada.
Relações
O separador relações permite-lhe especificar relações entre tabelas na base de dados. As relações no estruturador de bases de dados são informativas e não impõem restrições aos dados subjacentes. São lidas por outras aplicações da Microsoft que podem ser utilizadas para acelerar transformações ou fornecer informações aos utilizadores empresariais sobre a forma como as tabelas estão ligadas. O painel relações tem as seguintes informações.
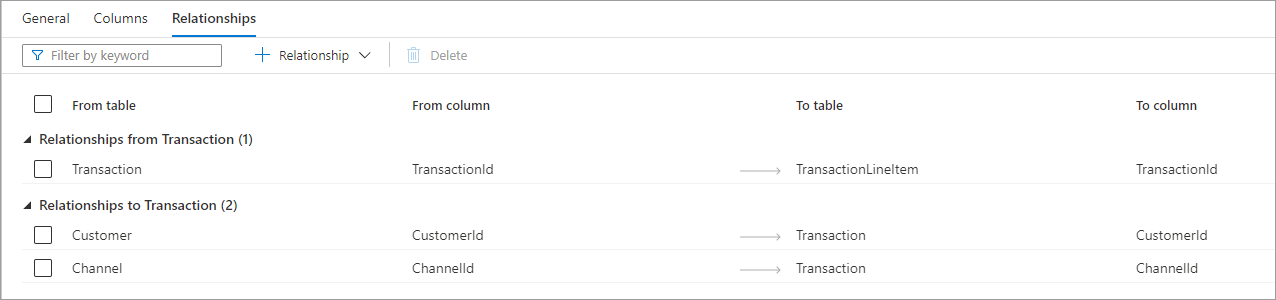
- As relações de (Tabela) são quando uma ou mais tabelas têm chaves externas ligadas a esta tabela. Por vezes, isto é chamado de relação principal.
- Relações com (Tabela) é quando uma tabela com chave externa e está ligada a outra tabela. Por vezes, isto é chamado de relação subordinada.
- Ambos os tipos de relação têm as seguintes propriedades.
- Na tabela da tabela principal na relação ou no lado "um".
- Na coluna da coluna na tabela principal, a relação baseia-se.
- Para colocar a tabela subordinada na relação ou o lado "muitos".
- Para colunar a coluna na tabela subordinada, a relação baseia-se. Na parte superior do separador Relações , encontra-se a barra de comandos que pode ser utilizada para interagir com as relações
- Filtrar por palavra-chave filtra a lista de colunas para itens que correspondem à palavra-chave especificada.
-
+ Relação permite-lhe adicionar uma nova relação. Existem duas opções.
- A tabela cria uma nova relação a partir da tabela em que está a trabalhar para uma tabela diferente.
- A tabela cria uma nova relação a partir de uma tabela diferente daquela em que está a trabalhar.
- A partir do modelo abre o painel de exploração e permite-lhe escolher entre relações no modelo de base de dados a incluir na sua base de dados. Se a base de dados não tiver sido criada com um modelo de base de dados, esta opção não será apresentada.
Passos seguintes
Continue a explorar as capacidades do estruturador de bases de dados com as ligações abaixo.