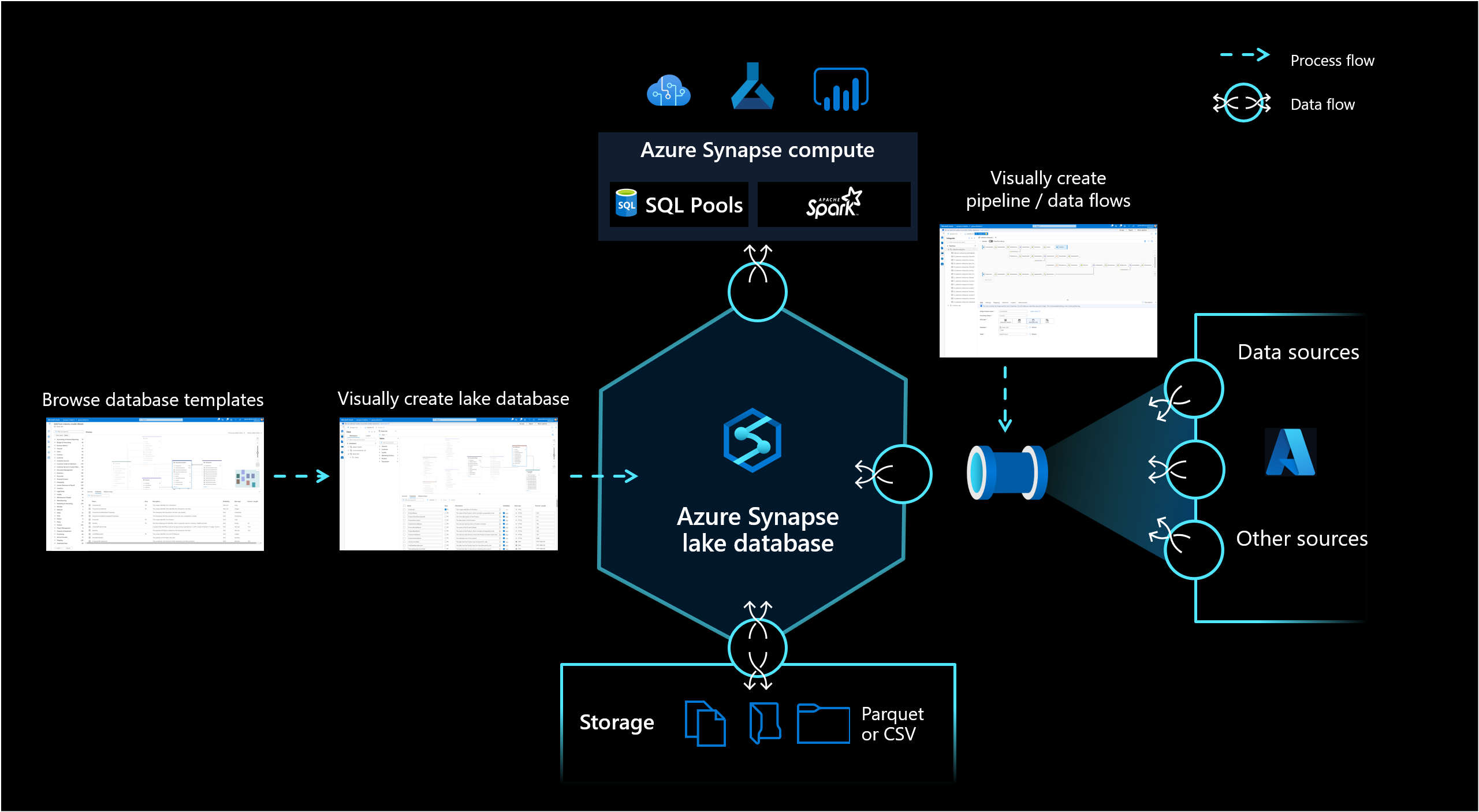
Base de dados Lake
O banco de dados lake no Azure Synapse Analytics permite que os clientes reúnam o design do banco de dados, meta-informações sobre os dados armazenados e a possibilidade de descrever como e onde os dados devem ser armazenados. O banco de dados Lake aborda o desafio dos data lakes atuais, onde é difícil entender como os dados são estruturados.
Designer de banco de dados
O novo designer de banco de dados no Synapse Studio oferece a possibilidade de criar um modelo de dados para seu banco de dados lake e adicionar informações adicionais a ele. Cada Entidade e Atributo pode ser descrito para fornecer mais informações sobre o modelo, que não contém apenas Entidades, mas também relacionamentos. Em particular, a incapacidade de modelar relacionamentos tem sido um desafio para a interação no data lake. Este desafio é agora abordado com um designer integrado que fornece possibilidades que estiveram disponíveis em bases de dados, mas não no lago. Além disso, a capacidade de adicionar descrições e possíveis valores de demonstração ao modelo permite que as pessoas que estão interagindo com ele no futuro tenham informações onde precisam para obter uma melhor compreensão sobre os dados.
Nota
O tamanho máximo dos metadados em um banco de dados lake é de 10 GB. A tentativa de publicar ou atualizar um modelo que exceda 10 GB de tamanho falhará. Para resolver esse problema, reduza o tamanho do modelo removendo tabelas e colunas. Considere dividir modelos grandes em vários bancos de dados de lago para evitar esse limite.
Armazenamento de dados
Os bancos de dados Lake usam um data lake na conta de Armazenamento do Azure para armazenar os dados do banco de dados. Os dados podem ser armazenados no formato Parquet, Delta ou CSV e diferentes configurações podem ser usadas para otimizar o armazenamento. Cada banco de dados lake usa um serviço vinculado para definir o local da pasta de dados raiz. Para cada entidade, pastas separadas são criadas por padrão dentro dessa pasta de banco de dados no data lake. Por padrão, todas as tabelas dentro de um banco de dados lake usam o mesmo formato, mas os formatos e a localização dos dados podem ser alterados por entidade, se isso for solicitado.
Nota
A publicação de um banco de dados lake não cria nenhuma das estruturas ou esquemas subjacentes necessários para consultar os dados no Spark ou SQL. Depois de publicar, carregue os dados em seu banco de dados do lago usando pipelines para começar a consultá-los.
Atualmente, o suporte ao formato Delta para bancos de dados lake não é suportado no Synapse Studio.
A sincronização de objetos de banco de dados lake entre o armazenamento e o Synapse é unidirecional. Certifique-se de executar qualquer criação ou modificação de esquema de objetos de banco de dados lake usando o designer de banco de dados no Synapse Studio. Se, em vez disso, você fizer essas alterações a partir do Spark ou diretamente no armazenamento, as definições dos bancos de dados do lago ficarão fora de sincronia. Se isso acontecer, você poderá ver definições antigas de banco de dados de lago no designer de banco de dados. Você precisará replicar e publicar essas alterações no designer de banco de dados para trazer seus bancos de dados lake de volta em sincronia.
Computação de banco de dados
O banco de dados lake é exposto no Synapse SQL, pool SQL sem servidor e Apache Spark, fornecendo aos usuários a capacidade de dissociar o armazenamento da computação. Os metadados associados ao banco de dados lake facilitam que diferentes mecanismos de computação não apenas forneçam uma experiência integrada, mas também usem informações adicionais (por exemplo, relacionamentos) que não eram originalmente suportadas no data lake.
Conteúdos relacionados
Continue a explorar os recursos do designer de banco de dados usando os links abaixo.