O que são continuidade de negócios, alta disponibilidade e recuperação de desastres?
Este artigo define e descreve a continuidade de negócios e o planejamento de continuidade de negócios em termos de gerenciamento de riscos por meio de design de alta disponibilidade e recuperação de desastres. Embora este artigo não forneça orientação explícita sobre como atender às suas próprias necessidades de continuidade de negócios, ele ajuda você a entender os conceitos usados nas diretrizes de confiabilidade da Microsoft.
A continuidade de negócios é o estado no qual uma empresa pode continuar as operações durante falhas, interrupções ou desastres. A continuidade dos negócios requer planejamento, preparação e implementação proativos de sistemas e processos resilientes.
O planejamento da continuidade de negócios requer identificação, compreensão, classificação e gerenciamento de riscos. Com base nos riscos e suas probabilidades, projete para alta disponibilidade (HA) e recuperação de desastres (DR).
Alta disponibilidade consiste em projetar uma solução para ser resiliente aos problemas do dia a dia e atender às necessidades de disponibilidade dos negócios.
A recuperação de desastres consiste em planejar como lidar com riscos incomuns e interrupções catastróficas que podem resultar.
Continuidade do negócio
Em geral, as soluções em nuvem estão diretamente ligadas às operações de negócios. Sempre que uma solução de nuvem não está disponível ou enfrenta um problema sério, o impacto nas operações de negócios pode ser grave. Um impacto severo pode interromper a continuidade dos negócios.
Os impactos severos na continuidade dos negócios podem incluir:
- Perda de receitas empresariais.
- A incapacidade de prestar um serviço importante aos utilizadores.
- Violação de um compromisso assumido com um cliente ou outra parte.
É importante entender e comunicar as expectativas de negócios e as consequências de falhas para partes interessadas importantes, incluindo aquelas que projetam, implementam e operam a carga de trabalho. Essas partes interessadas respondem partilhando os custos envolvidos na concretização dessa visão. Normalmente, há um processo de negociação e revisões dessa visão com base no orçamento e outras restrições.
Planejamento de continuidade de negócios
Para controlar ou evitar completamente um impacto negativo na continuidade dos negócios, é importante criar proativamente um plano de continuidade de negócios. Um plano de continuidade das atividades baseia-se na avaliação dos riscos e no desenvolvimento de métodos de controlo desses riscos através de várias abordagens. Os riscos específicos e as abordagens para mitigar variam para cada organização e carga de trabalho.
Um plano de continuidade de negócios não leva em consideração apenas os recursos de resiliência da própria plataforma de nuvem, mas também os recursos do aplicativo. Um plano robusto de continuidade de negócios também incorpora todos os aspetos do suporte no negócio, incluindo pessoas, processos manuais ou automatizados relacionados ao negócio e outras tecnologias.
O planejamento da continuidade de negócios deve incluir as seguintes etapas sequenciais:
Identificação de riscos. Identificar riscos para a disponibilidade ou funcionalidade de uma carga de trabalho. Os possíveis riscos podem ser problemas de rede, falhas de hardware, erro humano, interrupção de região, etc. Entenda o impacto de cada risco.
Classificação de risco. Classifique cada risco como um risco comum, que deve ser levado em conta nos planos de HA, ou um risco incomum, que deve fazer parte do planejamento de DR.
Mitigação de riscos. Projete estratégias de mitigação para HA ou DR para minimizar ou mitigar riscos, como o uso de redundância, replicação, failover e backups. Além disso, considere mitigações e controles não técnicos e baseados em processos.
O planejamento de continuidade de negócios é um processo, não um evento único. Qualquer plano de continuidade de negócios criado deve ser revisado e atualizado regularmente para garantir que permaneça relevante e eficaz e que suporte as necessidades atuais dos negócios.
Identificação dos riscos
A fase inicial do planejamento de continuidade de negócios é identificar riscos à disponibilidade ou funcionalidade de uma carga de trabalho. Cada risco deve ser analisado para compreender a sua probabilidade e gravidade. A gravidade precisa incluir qualquer tempo de inatividade potencial ou perda de dados, bem como se quaisquer aspetos do restante do design da solução podem compensar os efeitos negativos.
O quadro seguinte é uma lista não exaustiva de riscos, ordenados por probabilidade decrescente:
| Exemplo de risco | Description | Regularidade (probabilidade) |
|---|---|---|
| Problema transitório de rede | Uma falha temporária em um componente da pilha de rede, que é recuperável após um curto período de tempo (geralmente alguns segundos ou menos). | Normal |
| Reinicialização da máquina virtual | Uma reinicialização de uma máquina virtual que você usa ou que um serviço dependente usa. As reinicializações podem ocorrer porque a máquina virtual falha ou precisa aplicar um patch. | Normal |
| Falha de hardware | Uma falha de um componente em um datacenter, como um nó de hardware, rack ou cluster. | Ocasionais |
| Interrupção do datacenter | Uma interrupção que afeta a maior parte ou a totalidade de um datacenter, como uma falha de energia, problema de conectividade de rede ou problemas com aquecimento e resfriamento. | Incomum |
| Interrupção da região | Uma interrupção que afeta toda uma área metropolitana ou uma área mais ampla, como um grande desastre natural. | Muito incomum |
O planejamento de continuidade de negócios não diz respeito apenas à plataforma e infraestrutura em nuvem. É importante considerar o risco de erros humanos. Além disso, alguns riscos que tradicionalmente podem ser considerados riscos de segurança, desempenho ou operacionais também devem ser considerados riscos de confiabilidade porque afetam a disponibilidade da solução.
Seguem-se alguns exemplos:
| Exemplo de risco | Description |
|---|---|
| Perda ou corrupção de dados | Os dados foram excluídos, substituídos ou corrompidos por um acidente ou por uma violação de segurança, como um ataque de ransomware. |
| Bug de software | Uma implantação de código novo ou atualizado introduz um bug que afeta a disponibilidade ou a integridade, deixando a carga de trabalho em um estado de mau funcionamento. |
| Implantações com falha | Uma implantação de um novo componente ou versão falhou, deixando a solução em um estado inconsistente. |
| Ataques de negação de serviço | O sistema foi atacado numa tentativa de impedir o uso legítimo da solução. |
| Administradores fraudulentos | Um usuário com privilégios administrativos executou intencionalmente uma ação prejudicial contra o sistema. |
| Entrada inesperada de tráfego para um aplicativo | Um aumento no tráfego sobrecarregou os recursos do sistema. |
A análise de modo de falha (FMA) é o processo de identificar possíveis maneiras pelas quais uma carga de trabalho ou seus componentes podem falhar e como a solução se comporta nessas situações. Para saber mais, consulte Recomendações para executar a análise do modo de falha.
Classificação de risco
Os planos de continuidade de negócios devem abordar riscos comuns e incomuns.
Os riscos comuns são planeados e esperados. Por exemplo, em um ambiente de nuvem, é comum que haja falhas transitórias, incluindo breves interrupções de rede, reinicializações de equipamentos devido a patches, tempos limite quando um serviço está ocupado e assim por diante. Como esses eventos acontecem regularmente, as cargas de trabalho precisam ser resilientes a eles.
Uma estratégia de alta disponibilidade deve considerar e controlar cada risco deste tipo.
Os riscos incomuns são geralmente o resultado de um evento imprevisível, como um desastre natural ou um grande ataque à rede, que pode levar a uma interrupção catastrófica.
Os processos de recuperação de desastres lidam com esses riscos raros.
A alta disponibilidade e a recuperação de desastres estão inter-relacionadas e, por isso, é importante planejar estratégias para ambas juntas.
É importante entender que a classificação de risco depende da arquitetura da carga de trabalho e dos requisitos de negócios, e alguns riscos podem ser classificados como HA para uma carga de trabalho e DR para outra carga de trabalho. Por exemplo, uma interrupção completa da região do Azure geralmente seria considerada um risco de DR para cargas de trabalho nessa região. Mas para cargas de trabalho que usam várias regiões do Azure em uma configuração ativa-ativa com replicação completa, redundância e failover automático de região, uma interrupção de região é classificada como um risco de HA.
Mitigação de riscos
A mitigação de riscos consiste no desenvolvimento de estratégias para HA ou DR para minimizar ou mitigar riscos para a continuidade de negócios. A mitigação dos riscos pode ser baseada na tecnologia ou no ser humano.
Redução de riscos baseada em tecnologia
A redução de riscos baseada em tecnologia usa controles de risco baseados em como a carga de trabalho é implementada e configurada, como:
- Redundância
- Replicação de dados
- Ativação pós-falha
- Cópias de Segurança
Os controlos de risco baseados na tecnologia devem ser considerados no contexto do plano de continuidade das atividades.
Por exemplo:
Requisitos de baixo tempo de inatividade. Alguns planos de continuidade de negócios não são capazes de tolerar qualquer forma de risco de tempo de inatividade devido aos rigorosos requisitos de alta disponibilidade . Existem certos controlos baseados na tecnologia que podem exigir tempo para que um ser humano seja notificado e, em seguida, responda. É provável que os controlos de risco baseados na tecnologia que incluam processos manuais lentos não sejam adequados para inclusão na sua estratégia de redução dos riscos.
Tolerância a falhas parciais. Alguns planos de continuidade de negócios são capazes de tolerar um fluxo de trabalho executado em um estado degradado. Quando uma solução opera em um estado degradado, alguns componentes podem estar desativados ou não funcionais, mas as operações principais de negócios podem continuar a ser executadas. Para saber mais, consulte Recomendações para autorrecuperação e autopreservação.
Redução dos riscos com base no ser humano
A mitigação de riscos baseada em humanos usa controles de risco baseados em processos de negócios, como:
- Acionar um manual de resposta.
- Voltando às operações manuais.
- Formação e mudanças culturais.
Importante
Os indivíduos que projetam, implementam, operam e evoluem a carga de trabalho devem ser competentes, encorajados a falar se tiverem preocupações e sentir um senso de responsabilidade pelo sistema.
Como os controles de risco baseados em humanos geralmente são mais lentos do que os controles baseados em tecnologia e mais propensos a erros humanos, um bom plano de continuidade de negócios deve incluir um processo formal de controle de alterações para qualquer coisa que altere o estado do sistema em execução. Por exemplo, considere a implementação dos seguintes processos:
- Teste rigorosamente suas cargas de trabalho de acordo com a criticidade da carga de trabalho. Para evitar problemas relacionados a alterações, certifique-se de testar todas as alterações feitas na carga de trabalho.
- Introduza portas de qualidade estratégicas como parte das práticas de implantação seguras da sua carga de trabalho. Para saber mais, consulte Recomendações para práticas de implantação seguras.
- Formalizar procedimentos para acesso à produção ad-hoc e manipulação de dados. Essas atividades, por menores que sejam, podem apresentar um alto risco de causar incidentes de confiabilidade. Os procedimentos podem incluir o emparelhamento com outro engenheiro, o uso de listas de verificação e a obtenção de revisões por pares antes de executar scripts ou aplicar alterações.
Elevada disponibilidade
Alta disponibilidade é o estado no qual uma carga de trabalho específica pode manter seu nível necessário de tempo de atividade no dia-a-dia, mesmo durante falhas transitórias e falhas intermitentes. Como esses eventos acontecem regularmente, é importante que cada carga de trabalho seja projetada e configurada para alta disponibilidade de acordo com os requisitos do aplicativo específico e as expectativas do cliente. O HA de cada carga de trabalho contribui para o seu plano de continuidade de negócios.
Como o HA pode variar com cada carga de trabalho, é importante entender os requisitos e as expectativas do cliente ao determinar a alta disponibilidade. Por exemplo, um aplicativo que sua organização usa para solicitar suprimentos de escritório pode exigir um nível relativamente baixo de tempo de atividade, enquanto um aplicativo financeiro crítico pode exigir um tempo de atividade muito maior. Mesmo dentro de uma carga de trabalho, fluxos diferentes podem ter requisitos diferentes. Por exemplo, em um aplicativo de comércio eletrônico, os fluxos que suportam a navegação e a colocação de pedidos pelos clientes podem ser mais importantes do que o atendimento de pedidos e os fluxos de processamento de back-office. Para saber mais sobre fluxos, consulte Recomendações para identificar e classificar fluxos.
Comumente, o tempo de atividade é medido com base no número de "nove" na porcentagem de tempo de atividade. A porcentagem de tempo de atividade está relacionada a quanto tempo de inatividade você está permitindo durante um determinado período de tempo. Seguem-se alguns exemplos:
- Um requisito de 99,9% de tempo de atividade (três noves) permite aproximadamente 43 minutos de inatividade em um mês.
- Um requisito de 99,95% de tempo de atividade (três nove anos e meio) permite aproximadamente 21 minutos de inatividade em um mês.
Quanto maior o requisito de tempo de atividade, menos tolerância você tem para interrupções e mais trabalho você tem que fazer para atingir esse nível de disponibilidade. O tempo de atividade não é medido pelo tempo de atividade de um único componente, como um nó, mas pela disponibilidade geral de toda a carga de trabalho.
Importante
Não faça engenharia excessiva da sua solução para atingir níveis de fiabilidade mais elevados do que os justificados. Use os requisitos de negócios para orientar suas decisões.
Elementos de design de alta disponibilidade
Para atingir os requisitos de HA, uma carga de trabalho pode incluir vários elementos de design. Alguns dos elementos comuns estão listados e descritos abaixo nesta seção.
Nota
Algumas cargas de trabalho são de missão crítica, o que significa que qualquer tempo de inatividade pode ter consequências graves para a vida e a segurança humanas ou grandes perdas financeiras. Se você estiver projetando uma carga de trabalho de missão crítica, há coisas específicas nas quais você precisa pensar ao projetar sua solução e gerenciar sua continuidade de negócios. Para obter mais informações, consulte Azure Well-Architected Framework: cargas de trabalho de missão crítica.
Serviços e camadas do Azure que suportam alta disponibilidade
Muitos serviços do Azure são projetados para serem altamente disponíveis e podem ser usados para criar cargas de trabalho altamente disponíveis. Seguem-se alguns exemplos:
- Os Conjuntos de Dimensionamento de Máquina Virtual do Azure fornecem alta disponibilidade para máquinas virtuais (VMs) criando e gerenciando automaticamente instâncias de VM e distribuindo essas instâncias de VM para reduzir o impacto de falhas de infraestrutura.
- O Serviço de Aplicativo do Azure fornece alta disponibilidade por meio de uma variedade de abordagens, incluindo a movimentação automática de trabalhadores de um nó não íntegro para um nó íntegro e o fornecimento de recursos para autorrecuperação de muitos tipos de falhas comuns.
Use cada guia de confiabilidade de serviço para entender os recursos do serviço, decidir quais camadas usar e determinar quais recursos incluir em sua estratégia de alta disponibilidade.
Analise os contratos de nível de serviço (SLAs) de cada serviço para entender os níveis esperados de disponibilidade e as condições que você precisa atender. Talvez seja necessário selecionar ou evitar níveis específicos de serviços para atingir determinados níveis de disponibilidade. Alguns serviços da Microsoft são oferecidos com o entendimento de que nenhum SLA é fornecido, como camadas de desenvolvimento ou básicas, ou que o recurso pode ser recuperado do seu sistema em execução, como ofertas baseadas em spot. Além disso, algumas camadas adicionaram recursos de confiabilidade, como suporte para zonas de disponibilidade.
Tolerância a falhas
A tolerância a falhas é a capacidade de um sistema continuar a funcionar, em alguma capacidade definida, em caso de falha. Por exemplo, um aplicativo Web pode ser projetado para continuar operando mesmo se um único servidor Web falhar. A tolerância a falhas pode ser alcançada por meio de redundância, failover, particionamento, degradação normal e outras técnicas.
A tolerância a falhas também requer que seus aplicativos lidem com falhas transitórias. Quando você cria seu próprio código, talvez seja necessário habilitar o tratamento de falhas transitórias por conta própria. Alguns serviços do Azure fornecem tratamento de falhas transitórias interno para algumas situações. Por exemplo, por padrão, os Aplicativos Lógicos do Azure retentam automaticamente solicitações com falha para outros serviços. Para saber mais, consulte Recomendações para lidar com falhas transitórias.
Redundância
Redundância é a prática de duplicar instâncias ou dados para aumentar a confiabilidade da carga de trabalho.
A redundância pode ser obtida distribuindo réplicas ou instâncias redundantes de mais uma das seguintes maneiras:
- Dentro de um datacenter (redundância local)
- Entre zonas de disponibilidade dentro de uma região (redundância de zona)
- Entre regiões (redundância geográfica).
Aqui estão alguns exemplos de como alguns serviços do Azure fornecem opções de redundância:
- O Serviço de Aplicativo do Azure permite que você execute várias instâncias do seu aplicativo, para garantir que o aplicativo permaneça disponível mesmo se uma instância falhar. Se você habilitar a redundância de zona, essas instâncias serão distribuídas por várias zonas de disponibilidade na região do Azure que você usa.
- O Armazenamento do Azure fornece alta disponibilidade replicando dados automaticamente pelo menos três vezes. Você pode distribuir essas réplicas entre zonas de disponibilidade habilitando o armazenamento com redundância de zona (ZRS) e, em muitas regiões, também pode replicar seus dados de armazenamento entre regiões usando o GRS (armazenamento com redundância geográfica).
- O Banco de Dados SQL do Azure tem várias réplicas para garantir que os dados permaneçam disponíveis mesmo se uma réplica falhar.
Para saber mais sobre redundância, consulte Recomendações para projetar redundância e Recomendações para usar zonas e regiões de disponibilidade.
Escalabilidade e elasticidade
Escalabilidade e elasticidade são as habilidades de um sistema para lidar com o aumento da carga adicionando e removendo recursos (escalabilidade), e para fazê-lo rapidamente à medida que seus requisitos mudam (elasticidade). A escalabilidade e a elasticidade podem ajudar um sistema a manter a disponibilidade durante picos de carga.
Muitos serviços do Azure oferecem suporte à escalabilidade. Seguem-se alguns exemplos:
- Os Conjuntos de Dimensionamento de Máquina Virtual do Azure, o Gerenciamento de API do Azure e vários outros serviços oferecem suporte ao dimensionamento automático do Azure Monitor. Com o dimensionamento automático do Azure Monitor, você pode especificar políticas como "quando minha CPU estiver consistentemente acima de 80%, adicionar outra instância".
- O Azure Functions pode provisionar instâncias dinamicamente para atender às suas solicitações.
- O Azure Cosmos DB dá suporte à taxa de transferência de dimensionamento automático, onde o serviço pode gerenciar automaticamente os recursos atribuídos aos seus bancos de dados com base nas políticas especificadas.
A escalabilidade é um fator-chave a ser considerado durante o mau funcionamento parcial ou completo. Se uma réplica ou instância de computação não estiver disponível, os componentes restantes talvez precisem suportar mais carga para lidar com a carga que estava sendo manipulada anteriormente pelo nó com defeito. Considere o provisionamento excessivo se o sistema não puder ser dimensionado com rapidez suficiente para lidar com as alterações de carga esperadas.
Para obter mais informações sobre como projetar um sistema escalável e elástico, consulte Recomendações para projetar uma estratégia de dimensionamento confiável.
Técnicas de implantação sem tempo de inatividade
Implantações e outras alterações no sistema introduzem um risco significativo de tempo de inatividade. Como o risco de tempo de inatividade é um desafio para os requisitos de alta disponibilidade, é importante usar práticas de implantação sem tempo de inatividade para fazer atualizações e alterações de configuração sem qualquer tempo de inatividade necessário.
As técnicas de implantação sem tempo de inatividade podem incluir:
- Atualizar um subconjunto dos seus recursos de cada vez.
- Controlando a quantidade de tráfego que atinge a nova implantação.
- Monitorização de qualquer impacto nos seus utilizadores ou sistema.
- Corrigir rapidamente o problema, por exemplo, revertendo para uma implantação anterior em boas condições.
Para saber mais sobre técnicas de implantação sem tempo de inatividade, consulte Práticas de implantação seguras.
O próprio Azure usa abordagens de implantação de tempo de inatividade zero para nossos próprios serviços. Ao criar seus próprios aplicativos, você pode adotar implantações sem tempo de inatividade por meio de uma variedade de abordagens, como:
- Os Aplicativos de Contêiner do Azure fornecem várias revisões do seu aplicativo, que podem ser usadas para obter implantações sem tempo de inatividade.
- O Serviço Kubernetes do Azure (AKS) dá suporte a uma variedade de técnicas de implantação sem tempo de inatividade.
Embora as implantações sem tempo de inatividade sejam frequentemente associadas a implantações de aplicativos, elas também devem ser usadas para alterações de configuração. Aqui estão algumas maneiras de aplicar as alterações de configuração com segurança:
- O Armazenamento do Azure permite alterar as chaves de acesso da sua conta de armazenamento em vários estágios, o que evita o tempo de inatividade durante as operações de rotação de chaves.
- A Configuração de Aplicativo do Azure fornece sinalizadores de recursos, instantâneos e outros recursos para ajudá-lo a controlar como as alterações de configuração são aplicadas.
Se você decidir não implementar implantações sem tempo de inatividade, certifique-se de definir janelas de manutenção para que possa fazer alterações no sistema no momento em que os usuários esperam.
Testes automatizados
É importante testar a capacidade da sua solução para resistir às interrupções e falhas que você considera estarem no escopo do HA. Muitas dessas falhas podem ser simuladas em ambientes de teste. Testar a capacidade da sua solução de tolerar ou recuperar automaticamente de uma variedade de tipos de falhas é chamado de engenharia do caos. A engenharia do caos é fundamental para organizações maduras com padrões rigorosos de HA. O Azure Chaos Studio é uma ferramenta de engenharia de caos que pode simular alguns tipos de falhas comuns.
Para saber mais, consulte Recomendações para projetar uma estratégia de teste de confiabilidade.
Monitorização e alertas
O monitoramento permite que você saiba a integridade do seu sistema, mesmo quando mitigações automatizadas ocorrem. O monitoramento é fundamental para entender como sua solução está se comportando e para observar os primeiros sinais de falhas, como aumento das taxas de erro ou alto consumo de recursos. Com os alertas, você pode receber proativamente alterações importantes em seu ambiente.
O Azure fornece uma variedade de recursos de monitoramento e alerta, incluindo o seguinte:
- O Azure Monitor coleta logs e métricas de recursos e aplicativos do Azure e pode enviar alertas e exibir dados em painéis.
- O Azure Monitor Application Insights fornece monitoramento detalhado de seus aplicativos.
- O Azure Service Health e o Azure Resource Health monitorizam o estado de funcionamento da plataforma Azure e os seus recursos.
- Os Eventos Agendados informam quando a manutenção é planejada para máquinas virtuais.
Para obter mais informações, consulte Recomendações para projetar uma estratégia confiável de monitoramento e alerta.
Recuperação após desastre
Um desastre é um evento distinto, incomum e importante que tem um impacto maior e mais duradouro do que um aplicativo pode mitigar através do aspeto de alta disponibilidade de seu projeto. Exemplos de catástrofes incluem:
- Desastres naturais, como furacões, terremotos, inundações ou incêndios.
- Erros humanos que resultam em um grande impacto, como a exclusão acidental de dados de produção ou um firewall mal configurado que expõe dados confidenciais.
- Grandes incidentes de segurança, como negação de serviço ou ataques de ransomware que levam à corrupção de dados, perda de dados ou interrupções de serviço.
A recuperação de desastres consiste em planejar como você responde a esses tipos de situações.
Nota
Você deve seguir as práticas recomendadas em toda a solução para minimizar a probabilidade desses eventos. No entanto, mesmo após um planejamento proativo cuidadoso, é prudente planejar como você responderia a essas situações se elas surgirem.
Requisitos de recuperação de desastres
Devido à raridade e gravidade dos eventos de desastre, o planejamento de DR traz diferentes expectativas para sua resposta. Muitas organizações aceitam o fato de que, em um cenário de desastre, algum nível de tempo de inatividade ou perda de dados é inevitável. Um plano de DR completo deve especificar os seguintes requisitos críticos de negócios para cada fluxo:
O RPO (Recovery Point Objetive, objetivo de ponto de recuperação) é a duração máxima aceitável da perda de dados em caso de desastre. O RPO é medido em unidades de tempo, como "30 minutos de dados" ou "quatro horas de dados".
O RTO (Recovery Time Objetive, objetivo de tempo de recuperação) é a duração máxima aceitável do tempo de inatividade em caso de desastre, em que o "tempo de inatividade" é definido pela sua especificação. O RTO também é medido em unidades de tempo, como "oito horas de tempo de inatividade".
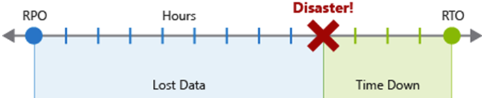
Cada componente ou fluxo na carga de trabalho pode ter valores individuais de RPO e RTO. Examine os riscos do cenário de desastre e as possíveis estratégias de recuperação ao decidir sobre os requisitos. O processo de especificação de um RPO e RTO cria efetivamente requisitos de DR para sua carga de trabalho como resultado de suas preocupações comerciais exclusivas (custos, impacto, perda de dados, etc.).
Nota
Embora seja tentador almejar um RTO e RPO de zero (sem tempo de inatividade e sem perda de dados em caso de desastre), na prática é difícil e caro implementá-lo. É importante que as partes interessadas técnicas e de negócios discutam esses requisitos juntos e decidam sobre requisitos realistas. Para obter mais informações, consulte Recomendações para definir metas de confiabilidade.
Planos de recuperação de desastres
Independentemente da causa do desastre, é importante que você crie um plano de DR bem definido e testável. Esse plano será usado como parte do projeto de infraestrutura e aplicativo para apoiá-lo ativamente. Você pode criar vários planos de DR para diferentes tipos de situações. Os planos de DR geralmente dependem de controles de processo e intervenção manual.
A DR não é um recurso automático do Azure. No entanto, muitos serviços fornecem recursos e capacidades que você pode usar para dar suporte às suas estratégias de DR. Você deve revisar os guias de confiabilidade para cada serviço do Azure para entender como o serviço funciona e seus recursos e, em seguida, mapear esses recursos para seu plano de DR.
As seções a seguir listam alguns elementos comuns de um plano de recuperação de desastres e descrevem como o Azure pode ajudá-lo a alcançá-los.
Ativação pós-falha e reativação pós-falha
Alguns planos de recuperação de desastres envolvem o provisionamento de uma implantação secundária em outro local. Se um desastre afetar a implantação principal da solução, o tráfego poderá ser transferido para o outro site. O failover requer planejamento e implementação cuidadosos. O Azure fornece uma variedade de serviços para ajudar com failover, como:
- O Azure Site Recovery fornece failover automatizado para ambientes locais e soluções hospedadas em máquinas virtuais no Azure.
- O Azure Front Door e o Azure Traffic Manager oferecem suporte a failover automatizado de tráfego de entrada entre diferentes implantações de sua solução, como em regiões diferentes.
Normalmente, leva algum tempo para que um processo de failover detete que a instância primária falhou e alterne para a instância secundária. Verifique se o RTO da carga de trabalho está alinhado com o tempo de failover.
Também é importante considerar o failback, que é o processo pelo qual você restaura as operações na região primária depois que ela é recuperada. O failback pode ser complexo de planejar e implementar. Por exemplo, os dados na região primária podem ter sido gravados após o início do failover. Você precisará tomar decisões de negócios cuidadosas sobre como lidar com esses dados.
Cópias de Segurança
Os backups envolvem fazer uma cópia dos seus dados e armazená-los com segurança por um período de tempo definido. Com os backups, você pode se recuperar de desastres quando o failover automático para outra réplica não é possível ou quando ocorre corrupção de dados.
Ao usar backups como parte de um plano de recuperação de desastres, é importante levar em consideração o seguinte:
Local de armazenamento. Quando você usa backups como parte de um plano de recuperação de desastres, eles devem ser armazenados separadamente nos dados principais. Normalmente, os backups são armazenados em outra região do Azure.
Perda de dados. Como os backups geralmente são feitos com pouca frequência, a restauração de backup geralmente envolve perda de dados. Por esse motivo, a recuperação de backup deve ser usada como último recurso e um plano de recuperação de desastres deve especificar a sequência de etapas e tentativas de recuperação que devem ocorrer antes da restauração a partir de um backup. É importante garantir que o RPO da carga de trabalho esteja alinhado com o intervalo de backup.
Tempo de recuperação. A restauração de backup geralmente leva tempo, por isso é fundamental testar seus backups e processos de restauração para verificar sua integridade e entender quanto tempo o processo de restauração leva. Certifique-se de que o RTO da carga de trabalho contabiliza o tempo necessário para restaurar o backup.
Muitos serviços de dados e armazenamento do Azure oferecem suporte a backups, como os seguintes:
- O Backup do Azure fornece backups automatizados para discos de máquina virtual, contas de armazenamento, AKS e uma variedade de outras fontes.
- Muitos serviços de banco de dados do Azure, incluindo o Banco de Dados SQL do Azure e o Azure Cosmos DB, têm um recurso de backup automatizado para seus bancos de dados.
- O Azure Key Vault fornece recursos para fazer backup de seus segredos, certificados e chaves.
Implantações automatizadas
Para implantar e configurar rapidamente os recursos necessários em caso de desastre, use ativos de infraestrutura como código (IaC), como arquivos Bicep, modelos ARM ou arquivo de configuração Terraform. O uso do IaC reduz o tempo de recuperação e o potencial de erro, em comparação com a implantação e configuração manual de recursos.
Testes e exercícios
É fundamental validar e testar rotineiramente seus planos de DR, bem como sua estratégia de confiabilidade mais ampla. Inclua todos os processos humanos em suas brocas e não se concentre apenas nos processos técnicos.
Se você não testou seus processos de recuperação em uma simulação de desastre, é mais provável que enfrente grandes problemas ao usá-los em um desastre real. Além disso, testando seus planos de DR e processos necessários, você pode validar a viabilidade do seu RTO.
Para saber mais, consulte Recomendações para projetar uma estratégia de teste de confiabilidade.
Conteúdos relacionados
- Use os guias de confiabilidade de serviço do Azure para entender como cada serviço do Azure dá suporte à confiabilidade em seu design e para saber mais sobre os recursos que você pode criar em seus planos de HA e DR.
- Use o pilar Azure Well-Architected Framework: Reliability para saber mais sobre como projetar uma carga de trabalho confiável no Azure.
- Use a perspetiva Well-Architected Framework nos serviços do Azure para saber mais sobre como configurar cada serviço do Azure para atender aos seus requisitos de confiabilidade e nos outros pilares do Well-Architected Framework.
- Para saber mais sobre o planejamento de recuperação de desastres, consulte Recomendações para projetar uma estratégia de recuperação de desastres.