Query Apache Hive through the JDBC driver in HDInsight (Consultar o Apache Hive através do controlador JDBC no HDInsight)
Saiba como usar o driver JDBC de um aplicativo Java. Para enviar consultas do Apache Hive para o Apache Hadoop no Azure HDInsight. As informações neste documento demonstram como se conectar programaticamente e a partir do SQuirreL SQL cliente.
Para obter mais informações sobre a interface JDBC do Hive, consulte HiveJDBCInterface.
Pré-requisitos
- Um cluster Hadoop do HDInsight. Para criar um, consulte Introdução ao Azure HDInsight. Verifique se o serviço HiveServer2 está em execução.
- O Java Developer Kit (JDK) versão 11 ou superior.
- SQuirreL SQL. SQuirreL é um aplicativo cliente JDBC.
Cadeia de ligação JDBC
As conexões JDBC com um cluster HDInsight no Azure são feitas pela porta 443. O tráfego é protegido usando TLS/SSL. O gateway público que os clusters ficam atrás redireciona o tráfego para a porta na qual o HiveServer2 está realmente escutando. A cadeia de conexão a seguir mostra o formato a ser usado para o HDInsight:
jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2
Substitua CLUSTERNAME pelo nome do seu cluster do HDInsight.
Nome do host na cadeia de conexão
O nome do host 'CLUSTERNAME.azurehdinsight.net' na cadeia de conexão é o mesmo que a URL do cluster. Você pode obtê-lo através do portal do Azure.
Porta na cadeia de conexão
Você só pode usar a porta 443 para se conectar ao cluster de alguns locais fora da rede virtual do Azure. O HDInsight é um serviço gerenciado, o que significa que todas as conexões com o cluster são gerenciadas por meio de um Gateway seguro. Você não pode se conectar ao HiveServer 2 diretamente nas portas 10001 ou 10000. Estas portas não estão expostas ao exterior.
Autenticação
Ao estabelecer a conexão, use o nome de administrador e a senha do cluster HDInsight para autenticar. Em clientes JDBC, como o SQuirreL SQL, insira o nome do administrador e a senha nas configurações do cliente.
A partir de uma aplicação Java, você deve usar o nome e a senha ao estabelecer uma conexão. Por exemplo, o seguinte código Java abre uma nova conexão:
DriverManager.getConnection(connectionString,clusterAdmin,clusterPassword);
Conecte-se com o cliente SQL SQuirreL
O SQuirreL SQL é um cliente JDBC que pode ser usado para executar remotamente consultas do Hive com seu cluster HDInsight. As etapas a seguir pressupõem que você já tenha instalado o SQuirreL SQL.
Crie um diretório para conter determinados arquivos a serem copiados do cluster.
No script a seguir, substitua
sshuserpelo nome da conta de usuário SSH para o cluster. SubstituaCLUSTERNAMEpelo nome do cluster HDInsight. Em uma linha de comando, altere seu diretório de trabalho para o criado na etapa anterior e digite o seguinte comando para copiar arquivos de um cluster HDInsight:scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/log4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . -> scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/reload4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hive-client/lib/{commons-codec*.jar,commons-logging-*.jar,hive-*-*.jar,httpclient-*.jar,httpcore-*.jar,libfb*.jar,libthrift-*.jar} .Inicie o aplicativo SQL SQuirreL. À esquerda da janela, selecione Drivers.

Nos ícones na parte superior da caixa de diálogo Drivers , selecione o + ícone para criar um driver.
Na caixa de diálogo Driver adicionado, adicione as seguintes informações:
Property valor Nome Ramo de registo URL de exemplo jdbc:hive2://localhost:443/default;transportMode=http;ssl=true;httpPath=/hive2Caminho de classe extra Use o botão Adicionar para adicionar todos os arquivos jar baixados anteriormente. Nome da classe org.apache.hive.jdbc.HiveDriver 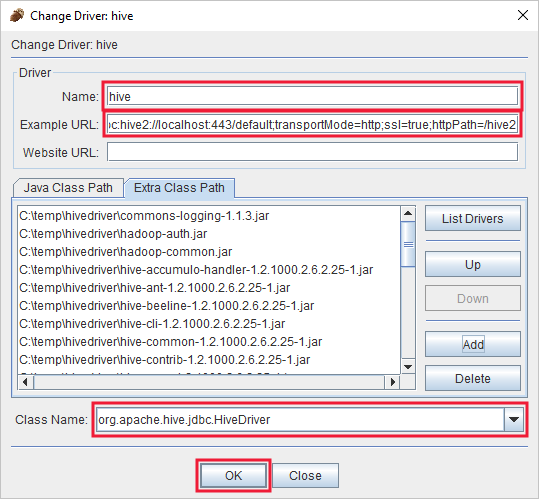
Selecione OK para salvar essas configurações.
À esquerda da janela SQL do SQuirreL, selecione Aliases. Em seguida, selecione o + ícone para criar um alias de conexão.
Use os seguintes valores para a caixa de diálogo Adicionar alias :
Property valor Nome Hive no HDInsight Controlador Use a lista suspensa para selecionar o driver Hive. URL jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2. Substitua CLUSTERNAME pelo nome do cluster do HDInsight.Nome de Utilizador O nome da conta de login do cluster para o cluster HDInsight. O padrão é admin. Palavra-passe A senha para a conta de login do cluster. 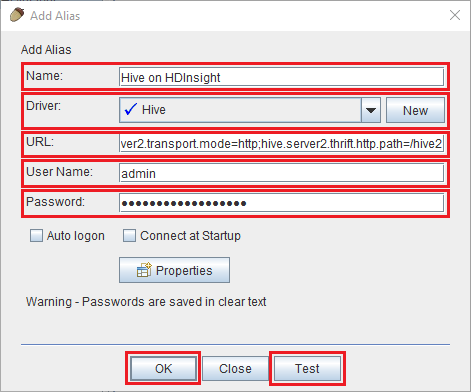
Importante
Use o botão Testar para verificar se a conexão funciona. Quando a caixa de diálogo Conectar a: Hive no HDInsight for exibida, selecione Conectar para executar o teste. Se o teste for bem-sucedido, você verá uma caixa de diálogo Conexão bem-sucedida . Se ocorrer um erro, consulte Resolução de problemas.
Para salvar o alias de conexão, use o botão Ok na parte inferior da caixa de diálogo Adicionar alias .
Na lista suspensa Conectar a , na parte superior do SQuirreL SQL, selecione Hive no HDInsight. Quando solicitado, selecione Conectar.
Uma vez conectado, insira a seguinte consulta na caixa de diálogo de consulta SQL e selecione o ícone Executar (uma pessoa em execução). A área de resultados deve mostrar os resultados da consulta.
select * from hivesampletable limit 10;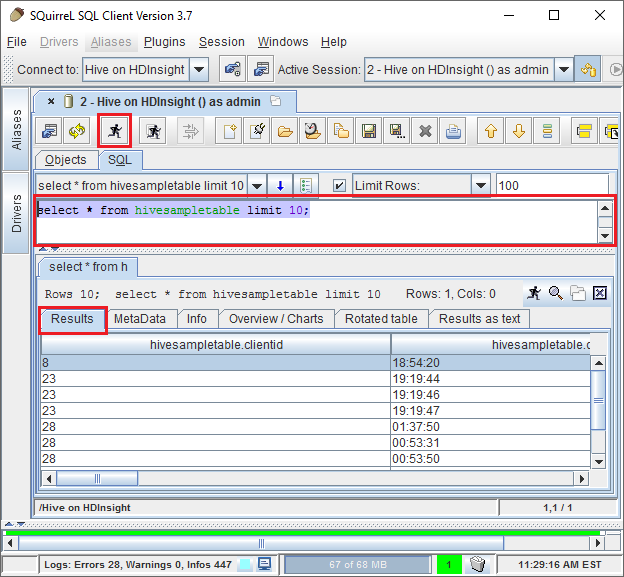
Conectar-se a partir de um exemplo de aplicação Java
Um exemplo de uso de um cliente Java para consultar o Hive no HDInsight está disponível em https://github.com/Azure-Samples/hdinsight-java-hive-jdbc. Siga as instruções no repositório para criar e executar o exemplo.
Resolução de Problemas
Ocorreu um erro inesperado ao tentar abrir uma ligação SQL
Sintomas: ao conectar-se a um cluster HDInsight versão 3.3 ou superior, você pode receber um erro informando que ocorreu um erro inesperado. O rastreamento de pilha para esse erro começa com as seguintes linhas:
java.util.concurrent.ExecutionException: java.lang.RuntimeException: java.lang.NoSuchMethodError: org.apache.commons.codec.binary.Base64.<init>(I)V
at java.util.concurrent.FutureTas...(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:206)
Causa: Este erro é causado por uma versão mais antiga commons-codec.jar ficheiro incluído no SQuirreL.
Resolução: para corrigir esse erro, use as seguintes etapas:
Saia do SQuirreL e, em seguida, vá para o diretório onde o SQuirreL está instalado no seu sistema, talvez
C:\Program Files\squirrel-sql-4.0.0\lib. No diretório SquirreL, no diretório, substitualibo commons-codec.jar existente pelo baixado do cluster HDInsight.Reinicie o SQuirreL. O erro não deve mais ocorrer ao se conectar ao Hive no HDInsight.
Ligação desligada pelo HDInsight
Sintomas: o HDInsight desconecta inesperadamente a conexão ao tentar baixar uma enorme quantidade de dados (digamos, vários GBs) por meio de JDBC/ODBC.
Causa: A limitação nos nós do Gateway causa esse erro. Quando você obtém dados do JDBC/ODBC, todos os dados precisam passar pelo nó Gateway. No entanto, um gateway não foi projetado para baixar uma grande quantidade de dados, portanto, o Gateway pode fechar a conexão se não puder lidar com o tráfego.
Resolução: evite usar o driver JDBC/ODBC para baixar grandes quantidades de dados. Em vez disso, copie dados diretamente do armazenamento de blobs.
Próximos passos
Agora que você aprendeu como usar o JDBC para trabalhar com o Hive, use os links a seguir para explorar outras maneiras de trabalhar com o Azure HDInsight.
- Visualize dados do Apache Hive com o Microsoft Power BI no Azure HDInsight.
- Visualize dados do Hive de Consulta Interativa com o Power BI no Azure HDInsight.
- Conecte o Excel ao HDInsight com o driver ODBC do Microsoft Hive.
- Conecte o Excel ao Apache Hadoop usando o Power Query.
- Usar o Apache Hive com o HDInsight
- Usar o Apache Pig com o HDInsight
- Utilizar tarefas de MapReduce com o HDInsight