Transformar dados na Rede Virtual do Azure com a atividade do Hive no Azure Data Factory
APLICA-SE A:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Neste tutorial, vai utilizar o Azure PowerShell para criar um pipeline do Data Factory que transforma os dados com a Atividade do Hive num cluster HDInsight que se encontra numa Rede Virtual do Azure (VNet). Vai executar os seguintes passos neste tutorial:
- Criar uma fábrica de dados.
- Criar e configurar o integration runtime autoalojado.
- Criar e implementar serviços ligados.
- Criar e implementar um pipeline que contém uma atividade do Hive.
- Iniciar uma execução de pipeline.
- Monitorizar a execução do pipeline.
- Verificar a saída.
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
Nota
Recomendamos que utilize o módulo Azure Az do PowerShell para interagir com o Azure. Para começar, consulte Instalar o Azure PowerShell. Para saber como migrar para o módulo do Az PowerShell, veja Migrar o Azure PowerShell do AzureRM para o Az.
Conta do Armazenamento do Azure. Tem de criar um script do Hive e carregá-lo para o armazenamento do Azure. A saída do script do Hive é armazenada nesta conta de armazenamento. Neste exemplo, o cluster HDInsight utiliza esta conta de Armazenamento do Azure como armazenamento primário.
Rede virtual do Azure. Se não tiver uma rede virtual do Azure, crie-a seguindo estas instruções. Neste exemplo, o HDInsight está numa Rede Virtual do Azure. Eis um exemplo de configuração da Rede Virtual do Azure.
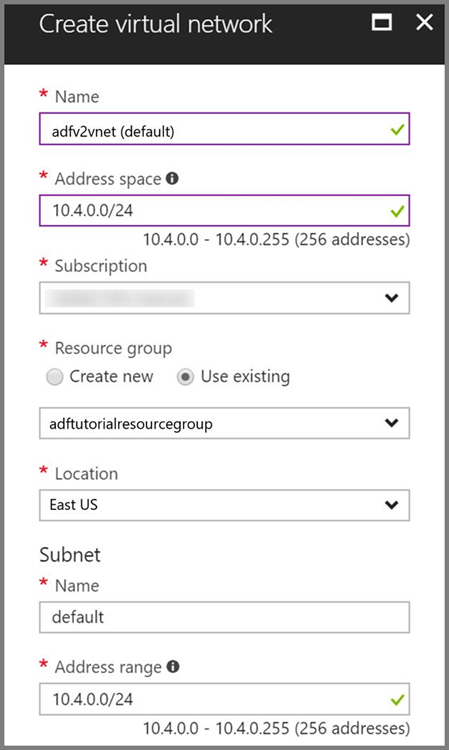
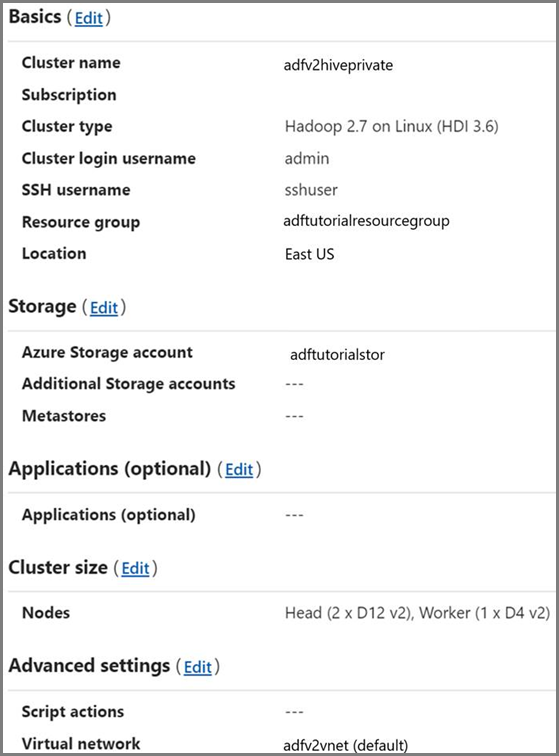
Cluster HDInsight. Crie um cluster HDInsight e associe-o à rede virtual que criou no passo anterior, seguindo este artigo: Extend Azure HDInsight using an Azure Virtual Network (Expandir o Azure HDInsight com uma Rede Virtual do Azure). Eis um exemplo de configuração do HDInsight numa rede virtual.
Azure PowerShell. Siga as instruções em How to install and configure Azure PowerShell (Como instalar e configurar o Azure PowerShell).
Carregar o script do Hive para uma conta de Armazenamento de Blobs
Crie um ficheiro SQL do Hive com o nome hivescript.hql com o seguinte conteúdo:
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletableNo Armazenamento de Blobs do Azure, crie um contentor com o nome adftutorial, caso ainda não exista.
Crie uma pasta com o nome hiverscripts.
Carregue o ficheiro hivescript.hql para a sub-pasta hivescripts.
Criar uma fábrica de dados
Defina o nome do grupo de recursos. Crie um grupo de recursos como parte deste tutorial. No entanto, pode utilizar um grupo de recursos existente se assim o desejar.
$resourceGroupName = "ADFTutorialResourceGroup"Especifique o nome da fábrica de dados. Tem de ser globalmente exclusivo.
$dataFactoryName = "MyDataFactory09142017"Especifique um nome para o pipeline.
$pipelineName = "MyHivePipeline" #Especifique um nome para o integration runtime autoalojado. Precisa de um untegration runtime autoalojado quando o Data Factory tem de aceder a recursos (por exemplo, à Base de Dados SQL do Azure) dentro de uma VNet.
$selfHostedIntegrationRuntimeName = "MySelfHostedIR09142017"Inicie o Azure PowerShell. Mantenha o Azure PowerShell aberto até ao fim deste início rápido. Se o fechar e reabrir, terá de executar os comandos novamente. Para obter uma lista de regiões do Azure em que o Data Factory está atualmente disponível, selecione as regiões que lhe interessam na página seguinte e, em seguida, expanda Analytics para localizar Data Factory: Produtos disponíveis por região. Os arquivos de dados (Armazenamento do Azure, Base de Dados SQL do Azure, etc.) e as computações (HDInsight, etc.) utilizados pela fábrica de dados podem estar noutras regiões.
Execute o comando seguinte e introduza o nome de utilizador e a palavra-passe que utiliza para iniciar sessão no Portal do Azure:
Connect-AzAccountExecute o comando seguinte para ver todas as subscrições desta conta:
Get-AzSubscriptionExecute o comando seguinte para selecionar a subscrição com a qual pretende trabalhar. Substitua SubscriptionId pelo ID da sua subscrição do Azure:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"Crie o grupo de recursos: ADFTutorialResourceGroup, caso ainda não exista na sua subscrição.
New-AzResourceGroup -Name $resourceGroupName -Location "East Us"Crie a fábrica de dados.
$df = Set-AzDataFactoryV2 -Location EastUS -Name $dataFactoryName -ResourceGroupName $resourceGroupNameExecute o seguinte comando para ver a saída:
$df
Criar o IR autoalojado
Nesta secção, vai criar um integration runtime autoalojado e associá-lo a uma VM do Azure na mesma Rede Virtual do Azure onde o cluster HDInsight se encontra.
Crie o integration runtime autoalojado. Utilize um nome exclusivo no caso de já existir outro integration runtime com o mesmo nome.
Set-AzDataFactoryV2IntegrationRuntime -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $selfHostedIntegrationRuntimeName -Type SelfHostedEste comando cria um registo lógico do integration runtime autoalojado.
Utilize o PowerShell para obter chaves de autenticação para registar o integration runtime autoalojado. Copie uma das chaves para registar o integration runtime autoalojado.
Get-AzDataFactoryV2IntegrationRuntimeKey -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $selfHostedIntegrationRuntimeName | ConvertTo-JsonSegue-se o resultado do exemplo:
{ "AuthKey1": "IR@0000000000000000000000000000000000000=", "AuthKey2": "IR@0000000000000000000000000000000000000=" }Tome nota do valor de AuthKey1 sem a aspa.
Crie uma VM do Azure e associe-a à mesma rede virtual que contém o cluster HDInsight. Para obter mais detalhes, veja Como criar máquinas virtuais. Associe-as a uma Rede Virtual do Azure.
Na VM do Azure, transfira o integration runtime autoalojado. Utilize a Chave de Autenticação que obteve no passo anterior para registar manualmente o integration runtime autoalojado.
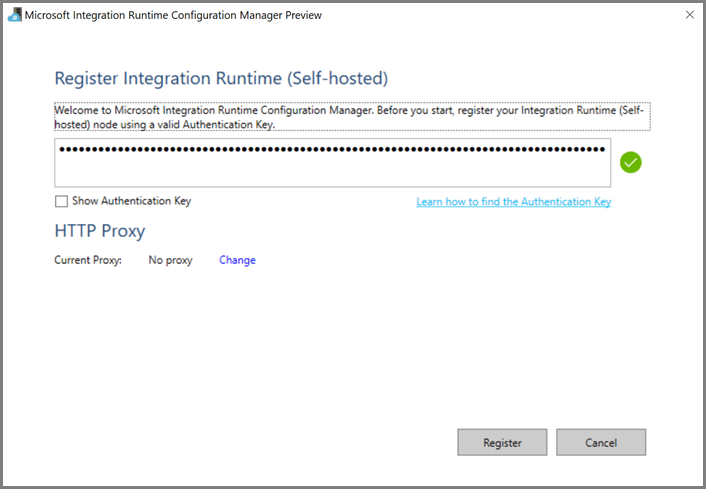
Você vê a seguinte mensagem quando o tempo de execução de integração auto-hospedado é registrado com êxito:
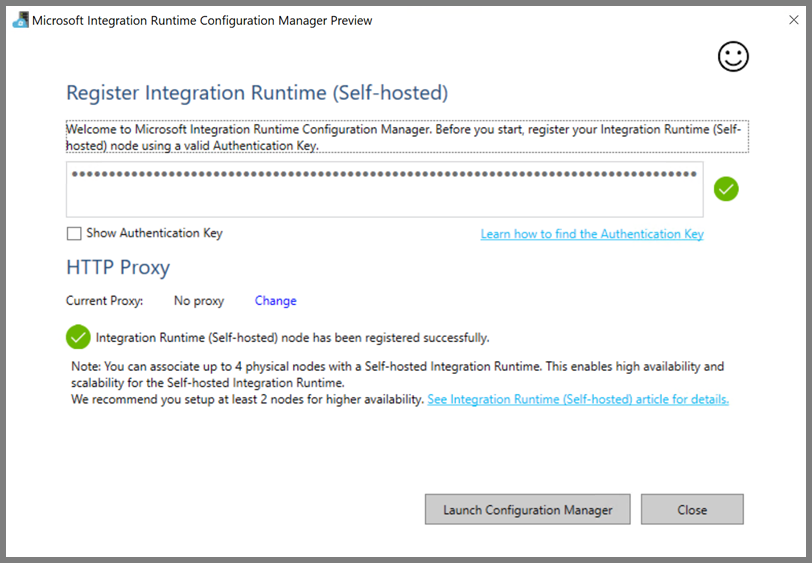
Você vê a seguinte página quando o nó está conectado ao serviço de nuvem:
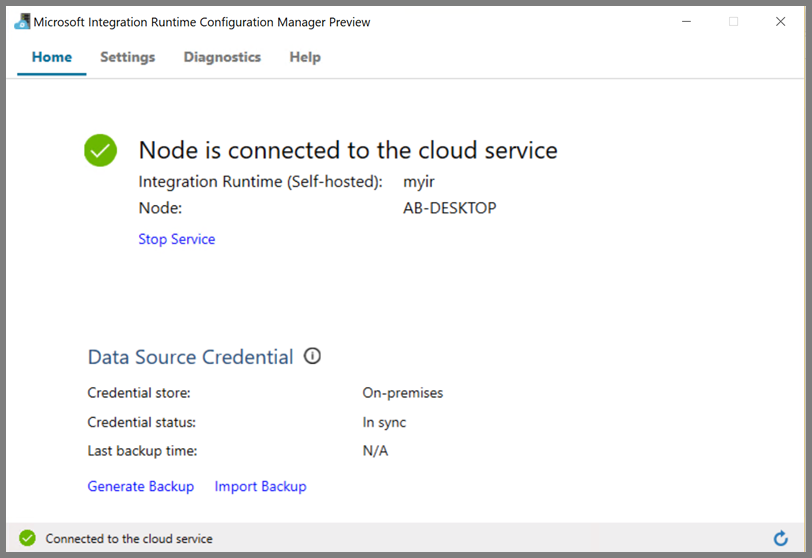
Criar serviços ligados
Nesta secção, vai criar e implementar dois Serviços Ligados:
- Um Serviço Ligado do Armazenamento do Azure que liga uma conta de Armazenamento do Azure à fábrica de dados. Este armazenamento é o armazenamento primário utilizado pelo cluster HDInsight. Neste caso, também utilizamos esta conta de Armazenamento do Azure para manter o script do Hive e a saída do script.
- Um Serviço Ligado do HDInsight. O Azure Data Factory envia o script do Hive a este cluster HDInsight para execução.
Serviço ligado do Storage do Azure
Crie um ficheiro JSON com o seu editor preferencial, copie a seguinte definição JSON de um serviço ligado do Armazenamento do Azure e, em seguida, guarde o ficheiro como MyStorageLinkedService.json.
{
"name": "MyStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<storageAccountName>;AccountKey=<storageAccountKey>"
},
"connectVia": {
"referenceName": "MySelfhostedIR",
"type": "IntegrationRuntimeReference"
}
}
}
Substitua <accountname> e <accountkey> pelo nome e chave da sua conta de Armazenamento do Azure.
Serviço ligado do HDInsight
Crie um ficheiro JSON com o seu editor preferencial, copie a seguinte definição JSON de um serviço ligado do Azure HDInsight e guarde o ficheiro como MyHDInsightLinkedService.json.
{
"name": "MyHDInsightLinkedService",
"properties": {
"type": "HDInsight",
"typeProperties": {
"clusterUri": "https://<clustername>.azurehdinsight.net",
"userName": "<username>",
"password": {
"value": "<password>",
"type": "SecureString"
},
"linkedServiceName": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
}
},
"connectVia": {
"referenceName": "MySelfhostedIR",
"type": "IntegrationRuntimeReference"
}
}
}
Atualize os valores para as seguintes propriedades na definição de serviço ligado:
userName. Nome do utilizador de início de sessão do cluster que especificou quando criou o cluster.
password. A palavra-passe do utilizador.
clusterUri. Especifique a URL do cluster HDInsight no seguinte formato:
https://<clustername>.azurehdinsight.net. Este artigo pressupõe que tem acesso ao cluster através da Internet. Por exemplo, pode ligar ao cluster emhttps://clustername.azurehdinsight.net. Este endereço utiliza o gateway público, que não está disponível se tiver utilizado grupos de segurança de rede (NSGs) ou rotas definidas pelo utilizador (UDRs) para restringir o acesso a partir da Internet. Para que o Data Factory consiga submeter tarefas ao cluster HDInsight na Rede Virtual do Azure, a Rede Virtual do Azure precisa de ser configurada de forma a que o URL possa ser resolvido para o endereço IP privado do gateway utilizado pelo HDInsight.A partir do portal do Azure, abra a Rede Virtual onde o HDInsight se encontra. Abra a interface de rede com o nome começado por
nic-gateway-0. Tome nota do endereço IP privado. Por exemplo, 10.6.0.15.Se a sua Rede Virtual do Azure tiver um servidor DNS, atualize o registo DNS de forma a que o URL do cluster HDInsight
https://<clustername>.azurehdinsight.netpossa ser resolvido para10.6.0.15. Esta é a abordagem recomendada. Se não tiver um servidor DNS na sua Rede Virtual do Azure, pode solucionar temporariamente este problema, editando o ficheiro de anfitriões (C:\Windows\System32\drivers\etc) de todas as VMs registadas como nós de integration runtime autoalojado, adicionando uma entrada semelhante a:10.6.0.15 myHDIClusterName.azurehdinsight.net
Criar serviços ligados
No PowerShell, mude para a pasta onde criou os ficheiros JSON e execute o seguinte comando para implementar os serviços ligados:
No PowerShell, mude para a pasta onde criou os ficheiros JSON.
Execute o seguinte comando para criar um serviço ligado do Armazenamento do Azure.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "MyStorageLinkedService" -File "MyStorageLinkedService.json"Execute o seguinte comando para criar um serviço ligado do Azure SDInsight.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "MyHDInsightLinkedService" -File "MyHDInsightLinkedService.json"
Criar um pipeline
Neste passo, vai criar um novo pipeline com uma atividade do Hive. A atividade executa o script do Hive para devolver dados de uma tabela de exemplo e guardá-los no caminho que definiu. Crie um ficheiro JSON no seu editor preferencial, copie a seguinte definição de JSON de uma definição de pipeline e guarde-a como MyHivePipeline.json.
{
"name": "MyHivePipeline",
"properties": {
"activities": [
{
"name": "MyHiveActivity",
"type": "HDInsightHive",
"linkedServiceName": {
"referenceName": "MyHDILinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptPath": "adftutorial\\hivescripts\\hivescript.hql",
"getDebugInfo": "Failure",
"defines": {
"Output": "wasb://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/"
},
"scriptLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
}
}
}
]
}
}
Tenha em conta os seguintes pontos:
- scriptPath aponta para o caminho do script do Hive na Conta de Armazenamento do Azure que utilizou para MyStorageLinkedService. O caminho é sensível a maiúsculas e minúsculas.
- Output é um argumento utilizado no script do Hive. Utilize o formato
wasb://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/para apontá-lo para uma pasta existente no seu Armazenamento do Azure. O caminho é sensível a maiúsculas e minúsculas.
Mude para a pasta onde criou os ficheiros JSON e execute o seguinte comando para implementar o pipeline:
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name $pipelineName -File "MyHivePipeline.json"
Iniciar o pipeline
Iniciar uma execução de pipeline. Também captura o ID de execução do pipeline para monitorização futura.
$runId = Invoke-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineName $pipelineNameExecute o script seguinte para verificar continuamente o estado de execução do pipeline até terminar.
while ($True) { $result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineRunId $runId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) if(!$result) { Write-Host "Waiting for pipeline to start..." -foregroundcolor "Yellow" } elseif (($result | Where-Object { $_.Status -eq "InProgress" } | Measure-Object).count -ne 0) { Write-Host "Pipeline run status: In Progress" -foregroundcolor "Yellow" } else { Write-Host "Pipeline '"$pipelineName"' run finished. Result:" -foregroundcolor "Yellow" $result break } ($result | Format-List | Out-String) Start-Sleep -Seconds 15 } Write-Host "Activity `Output` section:" -foregroundcolor "Yellow" $result.Output -join "`r`n" Write-Host "Activity `Error` section:" -foregroundcolor "Yellow" $result.Error -join "`r`n"Eis o resultado da execução de exemplo:
Pipeline run status: In Progress ResourceGroupName : ADFV2SampleRG2 DataFactoryName : SampleV2DataFactory2 ActivityName : MyHiveActivity PipelineRunId : 000000000-0000-0000-000000000000000000 PipelineName : MyHivePipeline Input : {getDebugInfo, scriptPath, scriptLinkedService, defines} Output : LinkedServiceName : ActivityRunStart : 9/18/2017 6:58:13 AM ActivityRunEnd : DurationInMs : Status : InProgress Error : Pipeline ' MyHivePipeline' run finished. Result: ResourceGroupName : ADFV2SampleRG2 DataFactoryName : SampleV2DataFactory2 ActivityName : MyHiveActivity PipelineRunId : 0000000-0000-0000-0000-000000000000 PipelineName : MyHivePipeline Input : {getDebugInfo, scriptPath, scriptLinkedService, defines} Output : {logLocation, clusterInUse, jobId, ExecutionProgress...} LinkedServiceName : ActivityRunStart : 9/18/2017 6:58:13 AM ActivityRunEnd : 9/18/2017 6:59:16 AM DurationInMs : 63636 Status : Succeeded Error : {errorCode, message, failureType, target} Activity Output section: "logLocation": "wasbs://adfjobs@adfv2samplestor.blob.core.windows.net/HiveQueryJobs/000000000-0000-47c3-9b28-1cdc7f3f2ba2/18_09_2017_06_58_18_023/Status" "clusterInUse": "https://adfv2HivePrivate.azurehdinsight.net" "jobId": "job_1505387997356_0024" "ExecutionProgress": "Succeeded" "effectiveIntegrationRuntime": "MySelfhostedIR" Activity Error section: "errorCode": "" "message": "" "failureType": "" "target": "MyHiveActivity"Verifique na pasta
outputfoldera existência do novo ficheiro criado como o resultado da consulta do Hive. Deverá ser semelhante à saída de exemplo seguinte:8 en-US SCH-i500 California 23 en-US Incredible Pennsylvania 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 246 en-US SCH-i500 District Of Columbia 246 en-US SCH-i500 District Of Columbia
Conteúdos relacionados
Neste tutorial, executou os passos seguintes:
- Criar uma fábrica de dados.
- Criar e configurar o integration runtime autoalojado.
- Criar e implementar serviços ligados.
- Criar e implementar um pipeline que contém uma atividade do Hive.
- Iniciar uma execução de pipeline.
- Monitorizar a execução do pipeline.
- Verificar a saída.
Avance para o tutorial seguinte para saber como transformar dados através de um cluster do Spark no Azure: