Carregue dados incrementalmente de várias tabelas no SQL Server para um banco de dados no Banco de Dados SQL do Azure usando o portal do Azure
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Neste tutorial, você cria um Azure Data Factory com um pipeline que carrega dados delta de várias tabelas em um banco de dados do SQL Server para um banco de dados no Banco de Dados SQL do Azure.
Vai executar os seguintes passos neste tutorial:
- Prepare os arquivos de dados de origem e de destino.
- Criar uma fábrica de dados.
- Criar um integration runtime autoalojado.
- Instalar o integration runtime.
- Criar serviços ligados.
- Crie conjuntos de dados de origem, de sink e de marca d'água.
- Criar, executar e monitorizar um pipeline.
- Reveja os resultados.
- Adicionou ou atualizou os dados nas tabelas de origem.
- Voltou a executar e a monitorizar o pipeline.
- Reviu os resultados finais.
Descrição geral
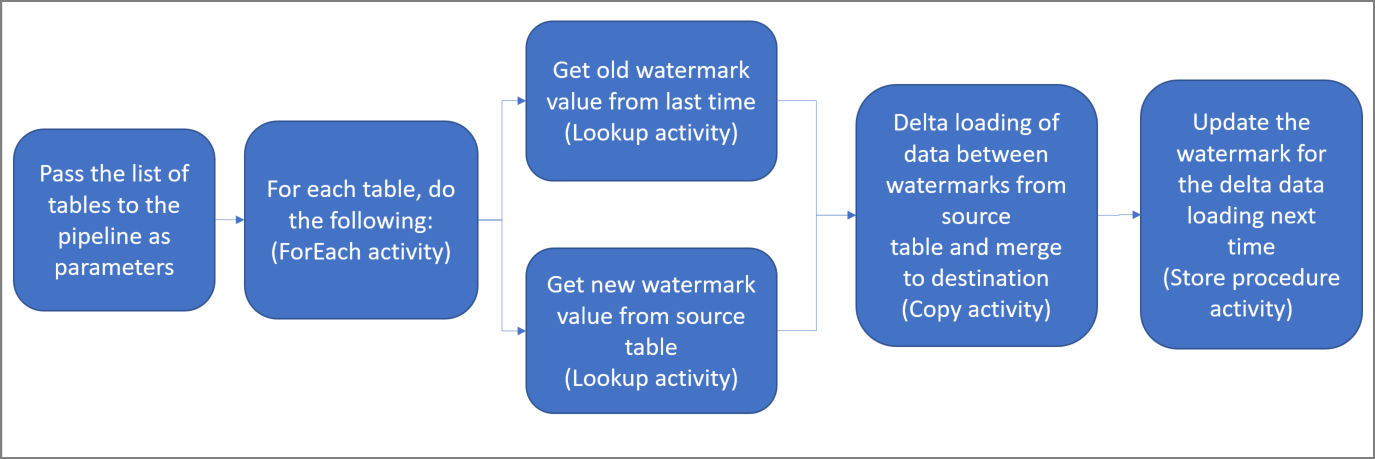
Eis os passos importantes para criar esta solução:
Selecionar a coluna de limite de tamanho.
Selecione uma coluna por cada tabela no arquivo de dados de origem, que pode ser utilizada para identificar os registos novos ou atualizados para cada execução. Normalmente, os dados nesta coluna selecionada (por exemplo, last_modify_time ou ID) continuam a aumentar quando as linhas são criadas ou atualizadas. O valor máximo nesta coluna é utilizado como limite de tamanho.
Preparar um arquivo de dados para armazenar o valor de limite de tamanho.
Neste tutorial, vai armazenar o valor de marca d'água numa base de dados SQL.
Criar um pipeline com as seguintes atividades:
a. Criar uma atividade ForEach que itera através de uma lista de nomes de tabelas de origem que é transmitida como um parâmetro para o pipeline. Para cada tabela de origem, este invoca as seguintes atividades para efetuar o carregamento de diferenças para essa tabela.
b. Criar duas atividades de pesquisa. Utilize a primeira atividade Pesquisa para obter o último valor de limite de tamanho. Utilize a segunda para obter o valor de limite de tamanho novo. Estes valores de limite de tamanho são transmitidos para a atividade Copy.
c. Criar uma atividade Cópia que copia linhas do arquivo de dados de origem com o valor da coluna de limite de tamanho superior ao valor de limite de tamanho antigo e inferior ao valor novo. Em seguida, copia os dados delta do arquivo de dados de origem para o armazenamento de Blobs do Azure como um ficheiro novo.
d. Crie uma atividade StoredProcedure, que atualiza o valor de marca d'água do pipeline que vai ser executado da próxima vez.
Eis o diagrama de nível elevado da solução:
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
- SQL Server. Você usa um banco de dados do SQL Server como o armazenamento de dados de origem neste tutorial.
- Base de Dados SQL do Azure. Você usa um banco de dados no Banco de Dados SQL do Azure como o armazenamento de dados do coletor. Se você não tiver um banco de dados no Banco de Dados SQL, consulte Criar um banco de dados no Banco de Dados SQL do Azure para conhecer as etapas para criar um.
Criar tabelas de origem na base de dados do SQL Server
Abra o SQL Server Management Studio e ligue-se à base de dados do SQL Server.
No Explorador de Servidores, clique com botão direito do rato na base de dados e escolha Nova Consulta.
Execute o seguinte comando SQL na base de dados para criar tabelas com o nome
customer_tableeproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
Criar tabelas de destino em seu banco de dados
Abra o SQL Server Management Studio e conecte-se ao seu banco de dados no Banco de Dados SQL do Azure.
No Explorador de Servidores, clique com botão direito do rato na base de dados e escolha Nova Consulta.
Execute o seguinte comando SQL na base de dados para criar tabelas com o nome
customer_tableeproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
Crie outra tabela em seu banco de dados para armazenar o alto valor da marca d'água
Execute o seguinte comando SQL em seu banco de dados para criar uma tabela nomeada
watermarktablepara armazenar o valor da marca d'água:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Inserir valores de marca d'água iniciais para ambas as tabelas de origem na tabela de marca d'água.
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
Criar um procedimento armazenado em seu banco de dados
Execute o seguinte comando para criar um procedimento armazenado em seu banco de dados. Este procedimento armazenado atualiza o valor de limite de tamanho após cada execução de pipeline.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Criar tipos de dados e procedimentos armazenados adicionais em seu banco de dados
Execute a consulta a seguir para criar dois procedimentos armazenados e dois tipos de dados em seu banco de dados. São utilizados para intercalar os dados das tabelas de origem nas tabelas de destino.
Para facilitar o início da jornada, usamos diretamente esses Procedimentos Armazenados passando os dados delta por meio de uma variável de tabela e, em seguida, mesclando-os no armazenamento de destino. Tenha cuidado para não esperar que um número "grande" de linhas delta (mais de 100) seja armazenado na variável de tabela.
Se você precisar mesclar um grande número de linhas delta no repositório de destino, sugerimos que você use a atividade de cópia para copiar todos os dados delta em uma tabela temporária de "preparação" no repositório de destino primeiro e, em seguida, crie seu próprio procedimento armazenado sem usar a variável de tabela para mesclá-los da tabela de "preparação" para a tabela "final".
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Criar uma fábrica de dados
Abra o browser Microsoft Edge ou Google Chrome. Atualmente, a IU do Data Factory é suportada apenas nos browsers Microsoft Edge e Google Chrome.
No menu à esquerda, selecione Criar um recurso>Integration>Data Factory:
Na página Nova fábrica de dados, introduza ADFMultiIncCopyTutorialDF em nome.
O nome do Azure Data Factory deve ser globalmente exclusivo. Se vir um ponto de exclamação vermelho com o seguinte erro, altere o nome da fábrica de dados (por exemplo, oseunomeADFIncCopyTutorialDF) e tente criá-la novamente. Veja o artigo Data Factory – Naming Rules (Data Factory – Regras de Nomenclatura) para obter as regras de nomenclatura dos artefactos do Data Factory.
Data factory name "ADFIncCopyTutorialDF" is not availableSelecione a sua subscrição do Azure na qual pretende criar a fábrica de dados.
No Grupo de Recursos, siga um destes passos:
- Selecione Utilizar existente e selecione um grupo de recursos já existente na lista pendente.
- Selecione Criar novo e introduza o nome de um grupo de recursos.
Para saber mais sobre os grupos de recursos, veja Utilizar grupos de recursos para gerir os recursos do Azure.
Selecione V2 para a versão.
Selecione a localização da fábrica de dados. Só aparecem na lista pendente as localizações que são suportadas. Os arquivos de dados (Armazenamento do Azure, Base de Dados SQL do Azure, etc.) e as computações (HDInsight, etc.) utilizados pela fábrica de dados podem estar noutras regiões.
Clique em Criar.
Depois de concluída a criação, vai ver a página Data Factory, conforme mostrado na imagem.
Selecione Abrir no bloco Abrir o Estúdio do Azure Data Factory para iniciar a interface do usuário (UI) do Azure Data Factory em uma guia separada.
Criar um integration runtime autoalojado
Como está a mover dados de um arquivo de dados numa rede privada (no local) para um arquivo de dados do Azure, instale um runtime de integração autoalojado (IR) no seu ambiente no local. O IR autoalojado move os dados entre a sua rede privada e o Azure.
Na home page da interface do usuário do Azure Data Factory, selecione a guia Gerenciar no painel mais à esquerda.
Selecione Tempos de execução de integração no painel esquerdo e, em seguida, selecione +Novo.
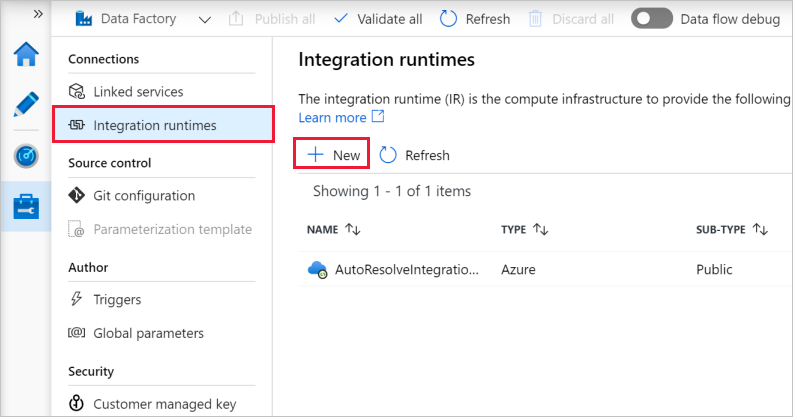
Na janela Configuração do Integration Runtime, selecione Executar movimentação de dados e enviar atividades para cálculos externos e clique em Continuar.
Selecione Auto-Hospedado e clique em Continuar.
Digite MySelfHostedIR para Nome e clique em Criar.
Clique em Clique aqui para iniciar a configuração rápida neste computador, na secção Opção 1: Configuração Rápida.
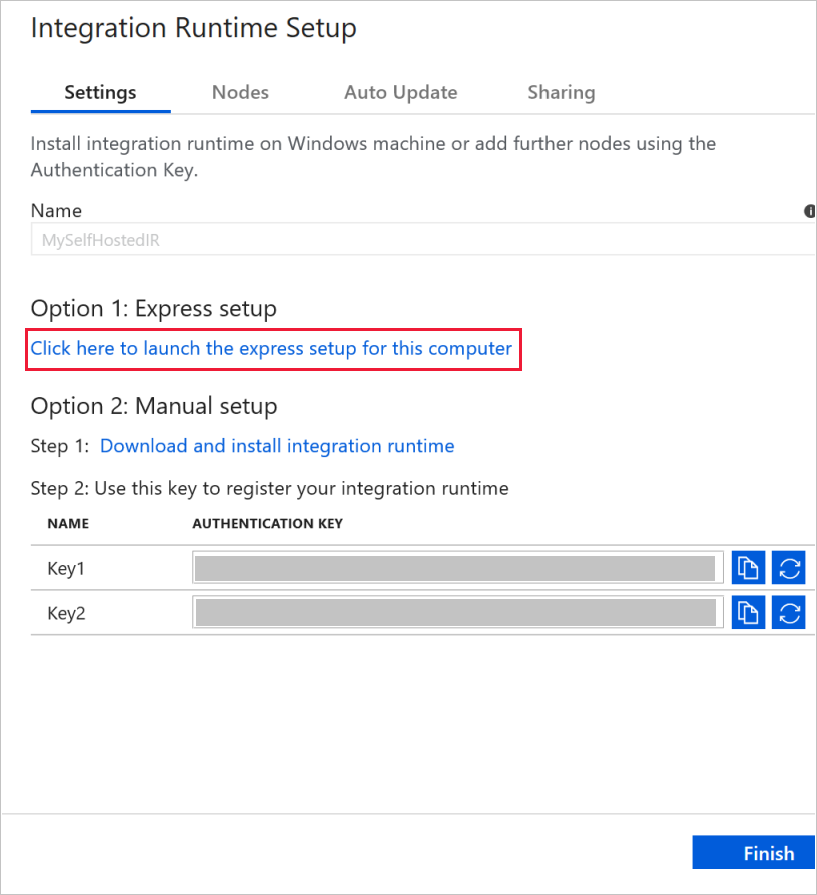
Na janela Configuração Rápida do Integration Runtime (Autoalojado), clique em Fechar.
No browser, na janela Configuração do Runtime de Integração, clique em Concluir.
Confirme que vê MySelfHostedIR na lista de runtimes de integração.
Criar serviços ligados
Os serviços ligados são criados numa fábrica de dados para ligar os seus arquivos de dados e serviços de computação a essa fábrica de dados. Nesta seção, você cria serviços vinculados ao seu banco de dados do SQL Server e ao seu banco de dados no Banco de Dados SQL do Azure.
Criar o serviço ligado do SQL Server
Nesta etapa, você vincula seu banco de dados do SQL Server ao data factory.
Na janela Ligações, mude do separador Runtimes de Integração para o separador Serviços Ligados e clique em + Novo.
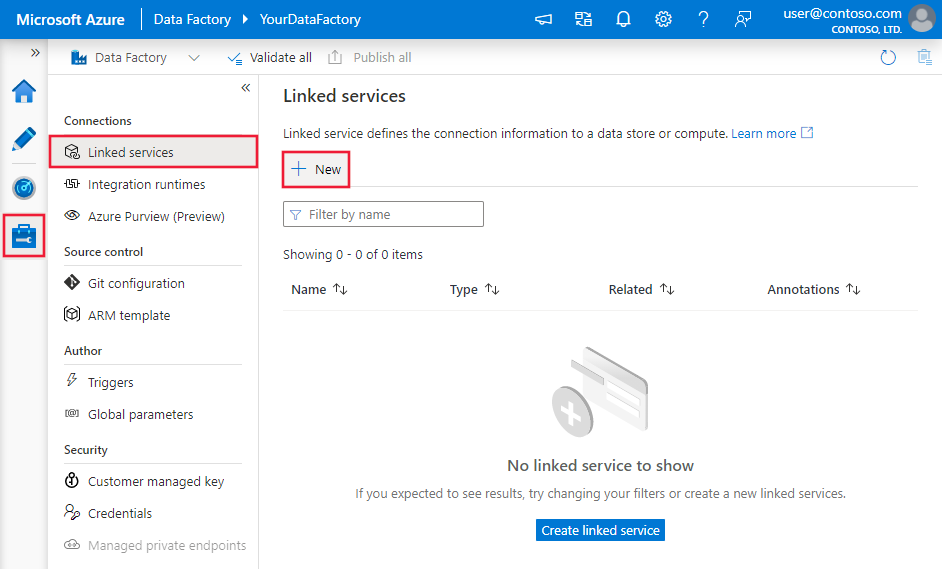
Na janela Novo Serviço Ligado, selecione SQL Server e clique em Continuar.
Na janela Novo Serviço Ligado, siga os passos abaixo:
- Introduza SqlServerLinkedService em Nome.
- Selecione MySelfHostedIR em Ligar através do runtime de integração. Este é um passo importante. O runtime de integração predefinido não consegue ligar a um arquivo de dados no local. Utilize o runtime de integração autoalojado que criou anteriormente.
- Em Nome do servidor, introduza o nome do computador que tem a base de dados do SQL Server.
- Em Nome da base de dados, introduza o nome da base de dados no SQL Server que tem a origem de dados. Criou uma tabela e inseriu dados nesta base de dados como parte dos pré-requisitos.
- Em Tipo de autenticação, selecione o tipo de autenticação que pretende utilizar para ligar à base de dados.
- Em Nome do utilizador, introduza o nome do utilizador que tem acesso à base de dados do SQL Server. Se precisar de utilizar um caráter de barra invertida (
\) no nome da sua conta de utilizador ou no nome do seu servidor, utilize o caráter de escape (\). Um exemplo émydomain\\myuser. - Em Palavra-passe,introduza a palavra-passe do utilizador.
- Para testar se o Data Factory consegue ligar à base de dados do SQL Server, clique em Testar ligação. Corrija os erros até que a ligação seja bem-sucedida.
- Para salvar o serviço vinculado, clique em Concluir.
Criar o serviço ligado da Base de Dados SQL do Azure
Neste último passo, vai criar um serviço ligado para ligar a sua base de dados do SQL Server à fábrica de dados. Nesta etapa, você vincula seu banco de dados de destino/coletor ao data factory.
Na janela Ligações, mude do separador Runtimes de Integração para o separador Serviços Ligados e clique em + Novo.
Na janela Novo Serviço Ligado, selecione Base de Dados SQL do Azure e clique em Continuar.
Na janela Novo Serviço Ligado, siga os passos abaixo:
- Introduza AzureSqlDatabaseLinkedService em Nome.
- Em Nome do servidor, selecione o nome do servidor na lista suspensa.
- Em Nome do banco de dados, selecione o banco de dados no qual você criou customer_table e project_table como parte dos pré-requisitos.
- Em Nome de usuário, insira o nome do usuário que tem acesso ao banco de dados.
- Em Palavra-passe,introduza a palavra-passe do utilizador.
- Para testar se o Data Factory consegue ligar à base de dados do SQL Server, clique em Testar ligação. Corrija os erros até que a ligação seja bem-sucedida.
- Para salvar o serviço vinculado, clique em Concluir.
Verifique se vê dois serviços ligados na lista.
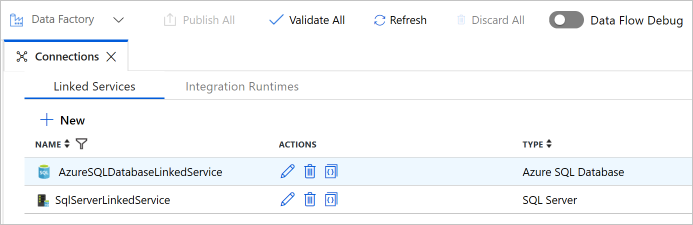
Criar conjuntos de dados
Neste passo, vai criar conjuntos de dados para representar a origem de dados, o destino de dados e o local para armazenar o limite de tamanho.
Criar um conjunto de dados de origem
No painel esquerdo, clique em + (mais) e clique em Conjunto de Dados.
Na janela Novo Conjunto de Dados, selecione SQL Server, clique em Continuar.
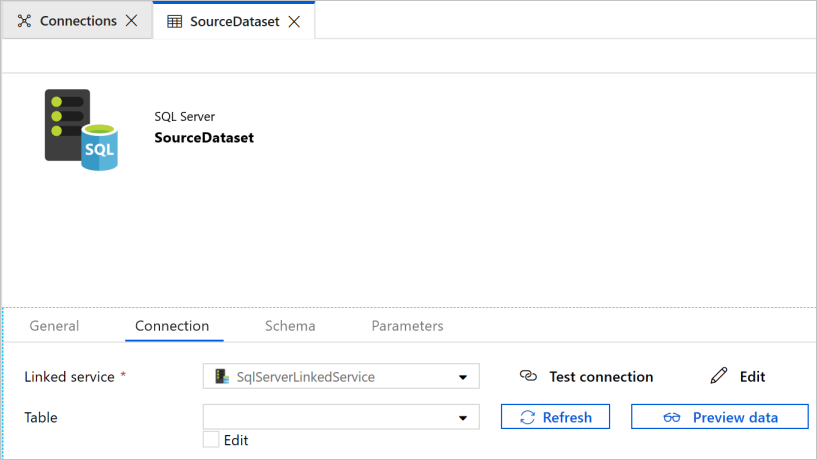
Verá um novo separador aberto no browser para configurar o conjunto de dados. Você também vê um conjunto de dados na exibição em árvore. No separador Geral da janela Propriedades ao fundo, introduza SourceDataset em Nome.
Mude para o separador Ligação, na janela Propriedades e clique emSqlServerLinkedService em Serviço ligado. Não selecione uma tabela aqui. A atividade Cópia no pipeline utiliza uma consulta SQL para carregar os dados em vez de carregar a tabela inteira.
Criar um conjunto de dados de sink
No painel esquerdo, clique em + (mais) e clique em Conjunto de Dados.
Na janela Novo Conjunto de Dados, selecione Banco de Dados SQL do Azure e clique em Continuar.
Verá um novo separador aberto no browser para configurar o conjunto de dados. Você também vê um conjunto de dados na exibição em árvore. No separador Geral da janela Propriedades ao fundo, introduza SinkDataset em Nome.
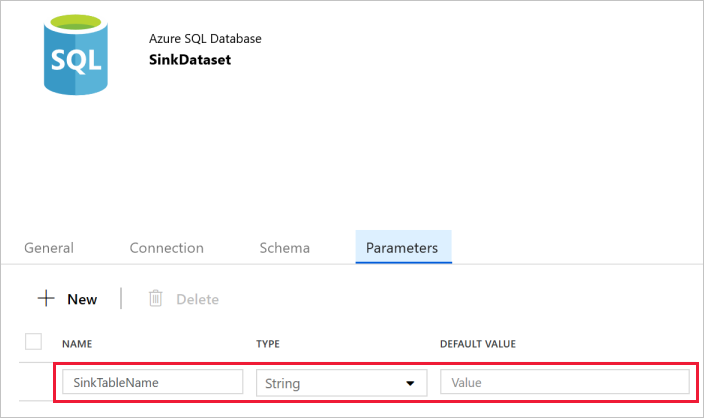
Mude para o separador Parâmetros da janela Propriedades, e siga os seguintes abaixo:
Clique em Novo na secção Criar/atualizar parâmetros.
Introduza SinkTableName em nome e Cadeia em tipo. Este conjunto de dados assume SinkTableName como um parâmetro. O parâmetro SinkTableName é definido pelo pipeline dinamicamente durante o runtime. A atividade ForEach no pipeline itera através de uma lista de nomes de tabelas e transmite o nome da tabela para este conjunto de dados em cada iteração.
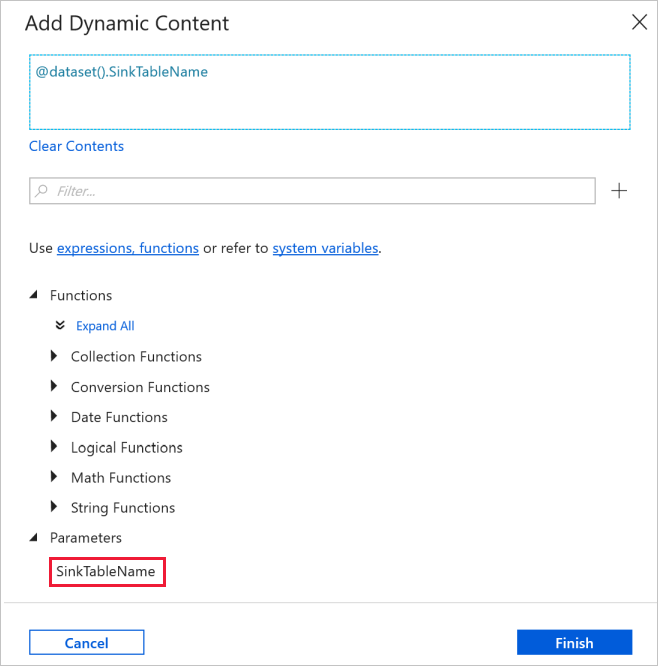
Alterne para a guia Conexão na janela Propriedades e selecione AzureSqlDatabaseLinkedService para serviço vinculado. Na propriedade Tabela, clique em Adicionar conteúdo dinâmico.
Na janela Adicionar conteúdo dinâmico, selecione SinkTableName na seção Parâmetros.
Depois de clicar em Concluir, você verá "@dataset(). SinkTableName" como o nome da tabela.
Criar um conjunto de dados para uma marca d'água
Neste passo, vai criar um conjunto de dados para armazenar um valor de limite superior de tamanho.
No painel esquerdo, clique em + (mais) e clique em Conjunto de Dados.
Na janela Novo Conjunto de Dados, selecione Banco de Dados SQL do Azure e clique em Continuar.
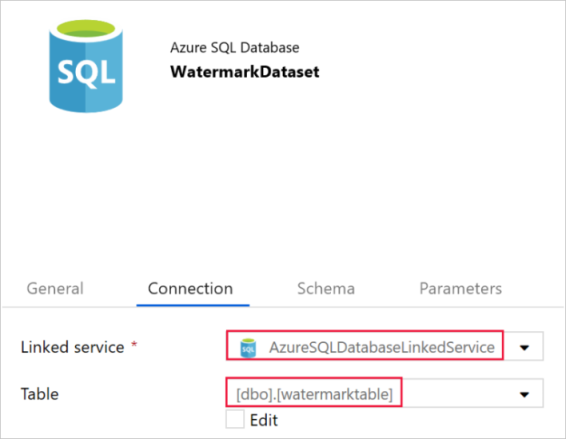
No separador Geral da janela Propriedades ao fundo, introduza WatermarkDataset em Nome.
Mude para o separador Ligação e siga os passos abaixo:
Selecione AzureSqlDatabaseLinkedService em Serviço ligado.
Selecione [dbo].[watermarktable] em Tabela.
Criar um pipeline
O pipeline aceita uma lista de nomes de tabela como parâmetro. A atividade ForEach itera através da lista de nomes de tabelas e realiza as seguintes operações:
Utilize a atividade Pesquisa para obter o valor do limite de tamanho antigo (o valor inicial ou o que foi utilizado na última iteração).
Utilize a atividade Pesquisa para obter o valor do limite de tamanho novo (o valor máximo da coluna de limites de tamanho na tabela de origem).
Utilize a atividade Cópia para copiar dados entre estes dois valores de limite de tamanho da base de dados de origem para a base de dados de destino.
Utilize a atividade StoredProcedure para atualizar o valor de limite de tamanho antigo a ser utilizado no primeiro passo da iteração seguinte.
Criar o pipeline
No painel do lado esquerdo, clique em + (mais) e clique em Pipeline.
No painel Geral, em Propriedades, especifique IncrementalCopyPipeline para Name. Em seguida, feche o painel clicando no ícone Propriedades no canto superior direito.
Na guia Parâmetros, execute as seguintes etapas:
- Clique em + Novo.
- Introduza tableList no parâmetro Nome.
- Selecione Array para o tipo de parâmetro.
Na caixa de ferramentas Atividades, expanda Iteração e Condições e arraste e largue a atividade ForEach na superfície de estruturador do pipeline. No separador Geral da janela Propriedades, introduza IterateSQLTables.
Mude para o separador Definições e introduza
@pipeline().parameters.tableListem itens. A atividade ForEach itera através da lista de tabelas e realiza a operação de cópia incremental.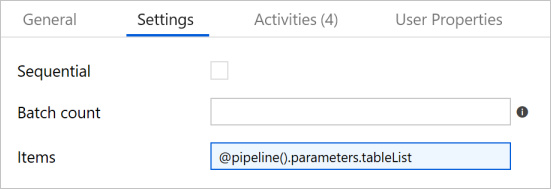
Selecione a atividade ForEach no pipeline, se ainda não estiver selecionada. Clique no botão Editar (Ícone de lápis).
Na caixa de ferramentas Atividades, expanda Geral, arraste e largue a atividade Lookup na superfície de estruturador do pipeline e introduza LookupOldWaterMarkActivity em Nome.
Mude para o separador Definições da janela Propriedades e siga os passos seguintes:
Selecione WatermarkDataset em Conjunto de Dados de Origem.
Selecione Consulta em Utilize Consulta.
Introduza a seguinte consulta SQL em consulta.
select * from watermarktable where TableName = '@{item().TABLE_NAME}'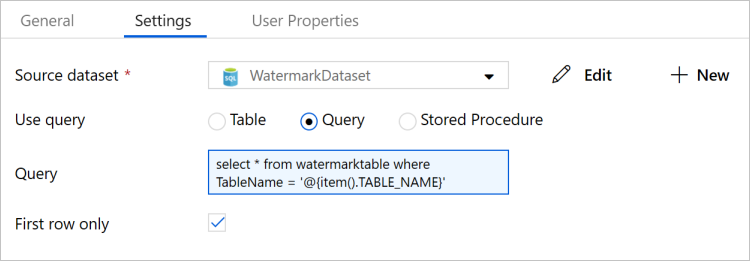
Arraste e largue a atividade Pesquisar da caixa de ferramentas Atividades e introduza LookupNewWaterMarkActivity em Nome.
Mudar para o separador Definições.
Selecione SourceDataset em Conjunto de Dados de Origem.
Selecione Consulta em Utilize Consulta.
Introduza a seguinte consulta SQL em consulta.
select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}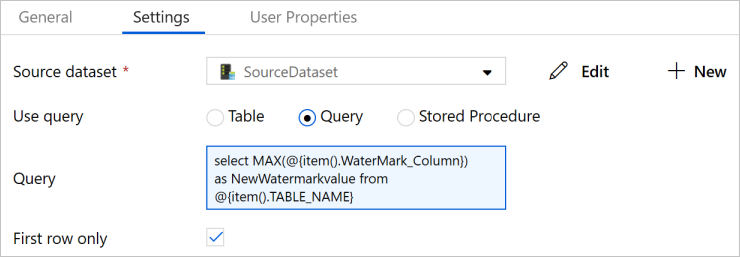
Arraste e largue a atividade Copiar da caixa de ferramentas Atividades e introduza IncrementalCopyActivity em Nome.
Ligue as atividades Pesquisar à atividade Copiar, uma a uma. Para ligar, comece a arrastar a caixa verde anexada à atividade Pesquisar e largue-a na atividade Copiar. Largue o botão do rato quando a cor do limite da atividade Copiar mudar para azul.
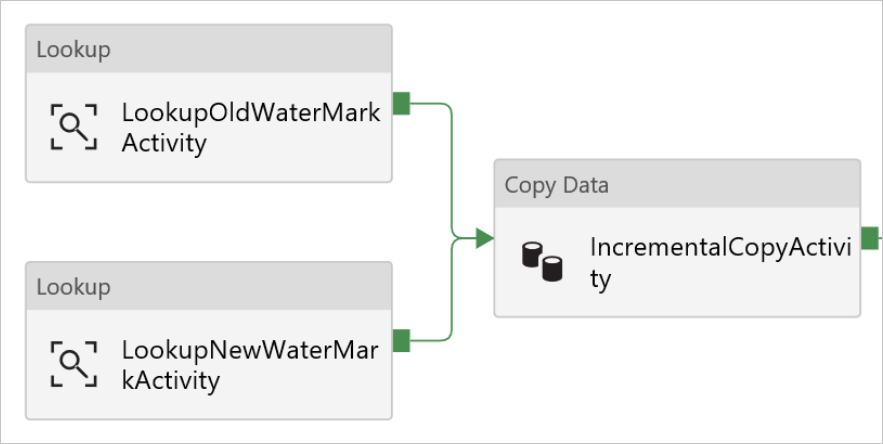
Selecione a atividade Copiar no pipeline. Mude para o separador Origem na janela Propriedades.
Selecione SourceDataset em Conjunto de Dados de Origem.
Selecione Consulta em Utilize Consulta.
Introduza a seguinte consulta SQL em consulta.
select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'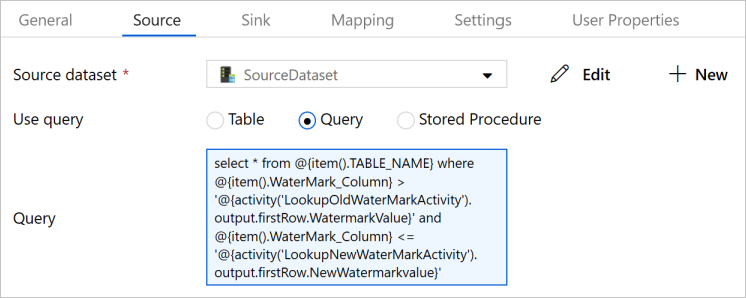
Mude para o separador Sink e selecione SinkDataset em Conjunto de Dados de Sink.
Efetue os seguintes passos:
Nas propriedades do conjunto de dados, para o parâmetro SinkTableName, digite
@{item().TABLE_NAME}.Para a propriedade Nome do Procedimento Armazenado, digite
@{item().StoredProcedureNameForMergeOperation}.Para a propriedade Tipo de tabela, digite
@{item().TableType}.Para Nome do parâmetro Tipo de tabela, digite
@{item().TABLE_NAME}.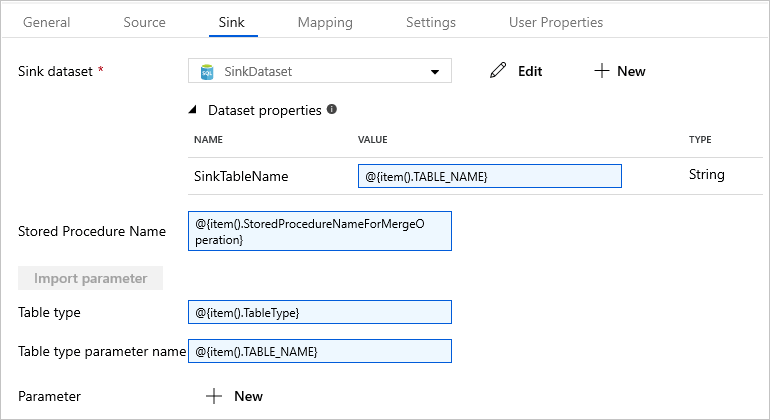
Arraste e largue a atividade Stored Procedure da caixa de ferramentas Atividades para a superfície de desenho do pipeline. Ligue a atividade Copiar à atividade Procedimento Armazenado.
Selecione a atividade Procedimento Armazenado no pipeline e introduza StoredProceduretoWriteWatermarkActivity em Nome, no separador Geral da janela Propriedades.
Mude para o separador Conta do SQL e selecione AzureSqlDatabaseLinkedService em Serviço Ligado.

Mude para o separador Procedimento Armazenado e siga os passos abaixo:
Para Nome do procedimento armazenado , selecione
[dbo].[usp_write_watermark].Selecione Parâmetro de importação.
Especifique os seguintes valores para os parâmetros:
Nome Tipo valor LastModifiedtime DateTime @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}TableName String @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}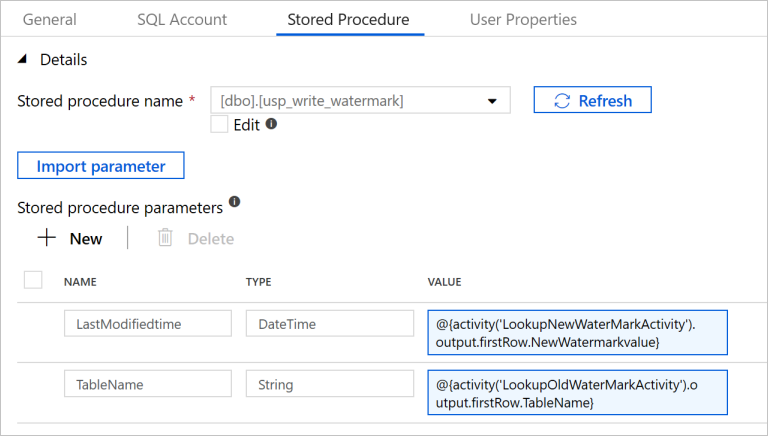
Selecione Publicar tudo para publicar as entidades criadas no serviço Data Factory.
Aguarde até ver a mensagem Publicação com êxito. Para ver as notificações, clique na ligação Mostrar Notificações. Clique em X para fechar a janela de notificações.
Executar o pipeline
Na barra de ferramentas do pipeline, clique em Adicionar gatilho e clique em Disparar Agora.
Na janela Execução de Pipeline, introduza o seguinte valor no parâmetro tableList e clique em Concluir.
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]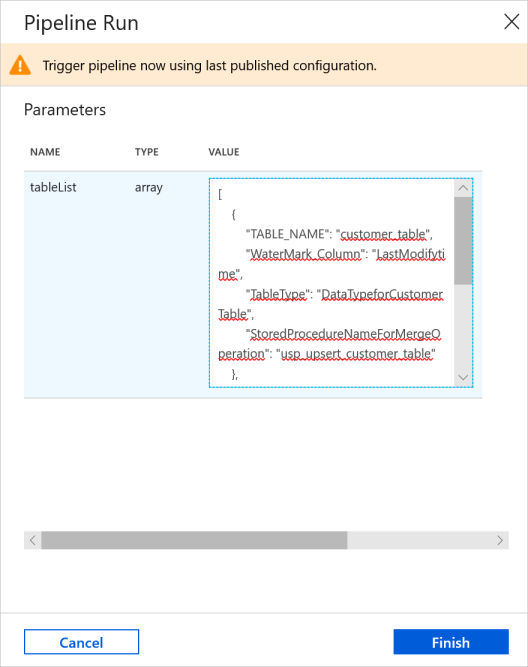
Monitorizar o pipeline
Mude para o separador Monitorizar, no lado esquerdo. Irá ver o estado da execução do pipeline acionada pelo acionador manual. Você pode usar links na coluna NOME DO PIPELINE para exibir detalhes da atividade e executar novamente o pipeline.
Para ver as execuções de atividade associadas à execução do pipeline, selecione o link na coluna NOME DO PIPELINE. Para obter detalhes sobre a atividade executada, selecione o link Detalhes (ícone de óculos) na coluna NOME DA ATIVIDADE.
Selecione Todas as execuções de pipeline na parte superior para voltar à visualização Execuções de pipeline. Para atualizar a vista, selecione Atualizar.
Rever os resultados
No SQL Server Management Studio, execute as seguintes consultas na base de dados SQL de destino para verificar que os dados foram copiados das tabelas de origem para as tabelas de destino.
Consulta
select * from customer_table
Saída
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Consulta
select * from project_table
Saída
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
Consulta
select * from watermarktable
Saída
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
Tenha em atenção que os valores de limite de tamanho de ambas as tabelas foram atualizados.
Adicione mais dados às tabelas de origem
Execute a seguinte consulta na base de dados do SQL Server de origem para atualizar uma linha existente em customer_table. Insira uma linha nova em project_table.
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
Volte a executar o pipeline
Na janela do browser, mude para o separador Editar no lado esquerdo.
Na barra de ferramentas do pipeline, clique em Adicionar gatilho e clique em Disparar Agora.
Na janela Execução de Pipeline, introduza o seguinte valor no parâmetro tableList e clique em Concluir.
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]
Monitorizar o pipeline novamente
Mude para o separador Monitorizar, no lado esquerdo. Irá ver o estado da execução do pipeline acionada pelo acionador manual. Você pode usar links na coluna NOME DO PIPELINE para exibir detalhes da atividade e executar novamente o pipeline.
Para ver as execuções de atividade associadas à execução do pipeline, selecione o link na coluna NOME DO PIPELINE. Para obter detalhes sobre a atividade executada, selecione o link Detalhes (ícone de óculos) na coluna NOME DA ATIVIDADE.
Selecione Todas as execuções de pipeline na parte superior para voltar à visualização Execuções de pipeline. Para atualizar a vista, selecione Atualizar.
Rever os resultados finais
No SQL Server Management Studio, execute as seguintes consultas no banco de dados SQL de destino para verificar se os dados atualizados/novos foram copiados das tabelas de origem para as tabelas de destino.
Consulta
select * from customer_table
Saída
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Repare nos valores novos de Name e LastModifytime para PersonID relativamente ao número 3.
Consulta
select * from project_table
Saída
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
Repare que a entrada NewProject foi adicionada a project_table.
Consulta
select * from watermarktable
Saída
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
Tenha em atenção que os valores de limite de tamanho de ambas as tabelas foram atualizados.
Conteúdos relacionados
Neste tutorial, executou os passos seguintes:
- Prepare os arquivos de dados de origem e de destino.
- Criar uma fábrica de dados.
- Criou um integration runtime autoalojado (IR).
- Instalar o integration runtime.
- Criar serviços ligados.
- Crie conjuntos de dados de origem, de sink e de marca d'água.
- Criar, executar e monitorizar um pipeline.
- Reveja os resultados.
- Adicionou ou atualizou os dados nas tabelas de origem.
- Voltou a executar e a monitorizar o pipeline.
- Reviu os resultados finais.
Avance para o tutorial seguinte para saber como transformar dados através de um cluster do Spark no Azure: