Carregue dados incrementalmente do Banco de Dados SQL do Azure para o Armazenamento de Blobs do Azure usando informações de controle de alterações usando o PowerShell
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Neste tutorial, você cria uma fábrica de dados do Azure com um pipeline que carrega dados delta com base em informações de controle de alterações no banco de dados de origem no Banco de Dados SQL do Azure para um armazenamento de blob do Azure.
Vai executar os seguintes passos neste tutorial:
- Preparar o arquivo de dados de origem
- Criar uma fábrica de dados.
- Criar serviços ligados.
- Crie uma origem, sink e conjuntos de dados de registo de alterações.
- Criar, executar e monitorizar o pipeline da cópia completa
- Adicionar ou atualizar os dados na tabela de origem
- Criar, executar e monitorizar o pipeline da cópia incremental
Nota
Recomendamos que utilize o módulo Azure Az do PowerShell para interagir com o Azure. Para começar, consulte Instalar o Azure PowerShell. Para saber como migrar para o módulo do Az PowerShell, veja Migrar o Azure PowerShell do AzureRM para o Az.
Descrição geral
Uma solução de integração de dados, que carrega dados incrementalmente após os carregamentos de dados iniciais é um cenário bastante utilizado. Em alguns casos, os dados alterados durante um período no seu arquivo de dados de origem podem ser facilmente segmentados (por exemplo, LastModifyTime, CreationTime). Em alguns casos, não há nenhuma forma explícita para identificar os dados delta da última vez que processou os dados. A tecnologia Controlo de Alterações suportada por arquivos de dados como a Base de Dados SQL do Azure e o SQL Server podem ser utilizados para identificar os dados delta. Este tutorial descreve como utilizar o Azure Data Factory com a tecnologia de Controlo de Alterações do SQL Server para carregar dados delta incrementalmente da Base de Dados SQL do Azure para o Armazenamento de Blobs do Azure. Para obter informações mais concretas sobre a tecnologia de Controlo de Alterações do SQL Server, consulte Controlo de alterações no SQL Server.
Fluxo de trabalho ponto a ponto
Eis os passos de fluxo de trabalho ponto-a-ponto normais para carregar dados incrementalmente com recurso à tecnologia de Controlo de Alterações.
Nota
Ambos a Base de Dados SQL do Azure e o SQL Server suportam a tecnologia de Controlo de Alterações. Este tutorial utiliza a Base de Dados SQL do Azure como o arquivo de dados de origem. Você também pode usar uma instância do SQL Server.
- Carregamento inicial de dados históricos (executado uma vez):
- Habilite a tecnologia de Controle de Alterações no banco de dados de origem no Banco de Dados SQL do Azure.
- Obtenha o valor inicial de SYS_CHANGE_VERSION no banco de dados como a linha de base para capturar dados alterados.
- Carregue dados completos do banco de dados de origem em um armazenamento de blob do Azure.
- Carregamento incremental de dados delta em um cronograma (executado periodicamente após o carregamento inicial de dados):
- Obter os valores SYS_CHANGE_VERSION novos e antigos.
- Carregar os dados delta ao associar as chaves primárias das linhas alteradas (entre dois valores SYS_CHANGE_VERSION) de change_tracking_tables com dados da tabela de origem, e em seguida, mover os dados delta para o destino.
- Atualize o SYS_CHANGE_VERSION para o carregamento delta da próxima vez.
Solução de alto nível
Neste tutorial, vai criar dois pipelines que realizam as seguintes duas operações:
Carga inicial: cria um pipeline com uma atividade de cópia que copia os dados inteiros do arquivo de dados de origem (Base de Dados SQL do Azure) para o arquivo de dados de destino (Armazenamento de Blobs do Azure).

Carga incremental: cria um pipeline com as seguintes atividades e execute-o periodicamente.
- Crie duas atividades de pesquisa para obter os SYS_CHANGE_VERSION antigo e novo da Base de Dados SQL do Azure e passe-o para a atividade de cópia.
- Crie uma atividade de cópia para copiar os dados inseridos/atualizados/eliminados entre os dois valores de SYS_CHANGE_VERSION da Base de Dados SQL do Azure para o Armazenamento de Blobs do Azure.
- Crie uma atividade de procedimentos armazenados para atualizar o valor de SYS_CHANGE_VERSION para a próxima execução de pipeline.

Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
- Azure PowerShell. Instale os módulos do Azure PowerShell mais recentes ao seguir as instruções em How to install and configure Azure PowerShell (Como instalar e configurar o Azure PowerShell).
- Base de Dados SQL do Azure. A base de dados é utilizada como o arquivo de dados de origem. Se você não tiver um banco de dados no Banco de Dados SQL do Azure, consulte o artigo Criar um banco de dados no Banco de Dados SQL do Azure para conhecer as etapas para criar um.
- Conta do Armazenamento do Azure. O armazenamento de blobs é utilizado como arquivo de dados de sink. Se não tiver uma conta de armazenamento do Azure, veja o artigo Criar uma conta de armazenamento para obter os passos para criar uma. Crie um contentor com o nome adftutorial.
Criar uma tabela de fonte de dados em seu banco de dados
Inicie o SQL Server Management Studio e conecte-se ao Banco de dados SQL.
No Explorador de Servidores, clique com botão direito do rato em base de dados e escolha Nova Consulta.
Execute o seguinte comando SQL em seu banco de dados para criar uma tabela nomeada
data_source_tablecomo armazenamento da fonte de dados.create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);Ative o mecanismo de Controlo de Alterações na sua base de dados e na tabela de origem (data_source_table) ao executar a seguinte consulta SQL:
Nota
- Substitua <o nome> do banco de dados pelo nome do banco de dados que tem o data_source_table.
- Os dados alterados são mantidos por dois dias no exemplo atual. Se carregar os dados alterados a cada três ou mais dias, alguns dados alterados não são incluídos. Precisa ou de alterar o valor de CHANGE_RETENTION para um número maior. Em alternativa, certifique-se de que o período para carregar os dados alterados se encontra dentro dos dois dias. Para obter mais informações, consulte Ativar o registo de alterações para uma base de dados
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)Criar uma nova tabela e armazenar ChangeTracking_version com um valor predefinido ao executar a seguinte consulta:
create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)Nota
Se os dados não estiverem alterados após ativar o controlo de alterações da Base de Dados SQL, o valor da versão do controlo de alterações é 0.
Execute a consulta a seguir para criar um procedimento armazenado em seu banco de dados. O pipeline invoca este procedimento armazenado para atualizar a versão de controlo de alterações na tabela que criou no passo anterior.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Azure PowerShell
Instale os módulos do Azure PowerShell mais recentes ao seguir as instruções em How to install and configure Azure PowerShell (Como instalar e configurar o Azure PowerShell).
Criar uma fábrica de dados
Defina uma variável para o nome do grupo de recursos que vai utilizar nos comandos do PowerShell mais tarde. Copie o texto do comando seguinte para o PowerShell, especifique um nome para o Grupo de recursos do Azure com aspas duplas e execute o comando. Por exemplo:
"adfrg".$resourceGroupName = "ADFTutorialResourceGroup";Se o grupo de recursos já existir, pode não substituí-lo. Atribua outro valor à variável
$resourceGroupNamee execute novamente o comandoDefina uma variável para a localização da fábrica de dados:
$location = "East US"Para criar o grupo de recursos do Azure, execute o comando abaixo:
New-AzResourceGroup $resourceGroupName $locationSe o grupo de recursos já existir, pode não substituí-lo. Atribua outro valor à variável
$resourceGroupNamee execute novamente o comando.Defina uma variável para o nome da fábrica de dados.
Importante
Atualize o nome da fábrica de dados para que seja globalmente exclusivo.
$dataFactoryName = "IncCopyChgTrackingDF";Para criar o data factory, execute o seguinte cmdlet Set-AzDataFactoryV2 :
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Tenha em conta os seguintes pontos:
O nome do Azure Data Factory deve ser globalmente exclusivo. Se receber o erro seguinte, altere o nome e tente novamente.
The specified Data Factory name 'ADFIncCopyChangeTrackingTestFactory' is already in use. Data Factory names must be globally unique.Para criar instâncias do Data Factory, a conta de utilizador que utiliza para iniciar sessão no Azure tem de ser um membro das funções contribuidor ou proprietário, ou um administrador da subscrição do Azure.
Para obter uma lista de regiões do Azure em que o Data Factory está atualmente disponível, selecione as regiões que lhe interessam na página seguinte e, em seguida, expanda Analytics para localizar Data Factory: Produtos disponíveis por região. Os arquivos de dados (Armazenamento do Azure, Base de Dados SQL do Azure, etc.) e as computações (HDInsight, etc.) utilizados pela fábrica de dados podem estar noutras regiões.
Criar serviços ligados
Os serviços ligados são criados numa fábrica de dados para ligar os seus arquivos de dados e serviços de computação a essa fábrica de dados. Nesta seção, você cria serviços vinculados à sua conta de Armazenamento do Azure e ao seu banco de dados no Banco de Dados SQL do Azure.
Criar o serviço ligado do Armazenamento do Azure.
Neste passo, vai ligar a sua Conta de Armazenamento do Azure à fábrica de dados.
Crie um ficheiro JSON com o nome AzureStorageLinkedService.json na pasta C:\ADFTutorials\IncCopyChangeTrackingTutorial com o seguinte conteúdo: (crie a pasta, caso ainda não exista). Substitua
<accountName>,<accountKey>pelo nome e chave da sua conta de armazenamento do Azure antes de salvar o arquivo.{ "name": "AzureStorageLinkedService", "properties": { "type": "AzureStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>" } } }No Azure PowerShell, alterne para a pasta C:\ADFTutorials\IncCopyChangeTrackingTutorial .
Execute o cmdlet Set-AzDataFactoryV2LinkedService para criar o serviço vinculado: AzureStorageLinkedService. No exemplo seguinte, vai transmitir os valores para os parâmetros ResourceGroupName e DataFactoryName.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureStorageLinkedService" -File ".\AzureStorageLinkedService.json"Segue-se o resultado do exemplo:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureStorageLinkedService
Criar o serviço ligado da Base de Dados SQL do Azure.
Nesta etapa, você vincula seu banco de dados ao data factory.
Crie um arquivo JSON chamado AzureSQLDatabaseLinkedService.json na pasta C:\ADFTutorials\IncCopyChangeTrackingTutorial com o seguinte conteúdo: Substitua <your-server-name> e <your-database-name> pelo nome do servidor e do banco de dados antes de salvar o arquivo. Você também deve configurar o SQL Server do Azure para conceder acesso à identidade gerenciada do data factory.
{ "name": "AzureSqlDatabaseLinkedService", "properties": { "type": "AzureSqlDatabase", "typeProperties": { "connectionString": "Server=tcp:<your-server-name>.database.windows.net,1433;Database=<your-database-name>;" }, "authenticationType": "ManagedIdentity", "annotations": [] } }No Azure PowerShell, execute o cmdlet Set-AzDataFactoryV2LinkedService para criar o serviço vinculado: AzureSQLDatabaseLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"Segue-se o resultado do exemplo:
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
Criar conjuntos de dados
Neste passo, vai criar conjuntos de dados para representar a origem de dados e o destino dos dados. e o local para armazenar o SYS_CHANGE_VERSION.
Criar um conjunto de dados de origem
Neste passo, vai criar um conjunto de dados para representar os dados de origem.
Crie um ficheiro JSON com o nome SourceDataset.json na mesma pasta com o seguinte conteúdo:
{ "name": "SourceDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "data_source_table" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Execute o cmdlet Set-AzDataFactoryV2Dataset para criar o conjunto de dados: SourceDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"Eis a saída de exemplo do cmdlet:
DatasetName : SourceDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Criar um conjunto de dados de sink
Neste passo, cria um conjunto de dados para representar os dados que são copiados do arquivo de dados de origem.
Crie um ficheiro JSON com o nome SinkDataset.json na mesma pasta com o seguinte conteúdo:
{ "name": "SinkDataset", "properties": { "type": "AzureBlob", "typeProperties": { "folderPath": "adftutorial/incchgtracking", "fileName": "@CONCAT('Incremental-', pipeline().RunId, '.txt')", "format": { "type": "TextFormat" } }, "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" } } }Crie o contentor adftutorial no seu Armazenamento de Blobs do Azure como parte dos pré-requisitos. Crie o contentor se ainda não existir ou defina-o com o nome de um contentor existente. Neste tutorial, o nome do arquivo de saída é gerado dinamicamente usando a expressão: @CONCAT('Incremental-', pipeline(). RunId, '.txt').
Execute o cmdlet Set-AzDataFactoryV2Dataset para criar o conjunto de dados: SinkDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"Eis a saída de exemplo do cmdlet:
DatasetName : SinkDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobDataset
Crie um conjunto de dados de controlo de alterações
Neste passo, vai criar um conjunto de dados para armazenar a versão de controlo de alterações.
Crie um ficheiro JSON com o nome ChangeTrackingDataset.json na mesma pasta com o seguinte conteúdo:
{ "name": " ChangeTrackingDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "table_store_ChangeTracking_version" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Crie a tabela table_store_ChangeTracking_version como parte dos pré-requisitos.
Execute o cmdlet Set-AzDataFactoryV2Dataset para criar o conjunto de dados: ChangeTrackingDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "ChangeTrackingDataset" -File ".\ChangeTrackingDataset.json"Eis a saída de exemplo do cmdlet:
DatasetName : ChangeTrackingDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Criar um pipeline para a cópia completa
Neste passo, cria um pipeline com uma atividade de cópia que copia os dados inteiros do arquivo de dados de origem (Base de Dados SQL do Azure) para o arquivo de dados de destino (Armazenamento de Blobs do Azure).
Crie um ficheiro JSON: FullCopyPipeline.json na mesma pasta com o seguinte conteúdo:
{ "name": "FullCopyPipeline", "properties": { "activities": [{ "name": "FullCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource" }, "sink": { "type": "BlobSink" } }, "inputs": [{ "referenceName": "SourceDataset", "type": "DatasetReference" }], "outputs": [{ "referenceName": "SinkDataset", "type": "DatasetReference" }] }] } }Execute o cmdlet Set-AzDataFactoryV2Pipeline para criar o pipeline: FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "FullCopyPipeline" -File ".\FullCopyPipeline.json"Segue-se o resultado do exemplo:
PipelineName : FullCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {FullCopyActivity} Parameters :
Execute o pipeline da cópia completa
Execute o pipeline: FullCopyPipeline usando o cmdlet Invoke-AzDataFactoryV2Pipeline .
Invoke-AzDataFactoryV2Pipeline -PipelineName "FullCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
Monitorize o pipeline da cópia completa
Inicie sessão no portal do Azure.
Clique em Todos os serviços, pesquise com a palavra-chave
data factoriese selecione Fábricas de dados.
Pesquise pela sua fábrica de dados na lista de fábricas de dados e selecione-a para iniciar a página da Fábrica de dados.
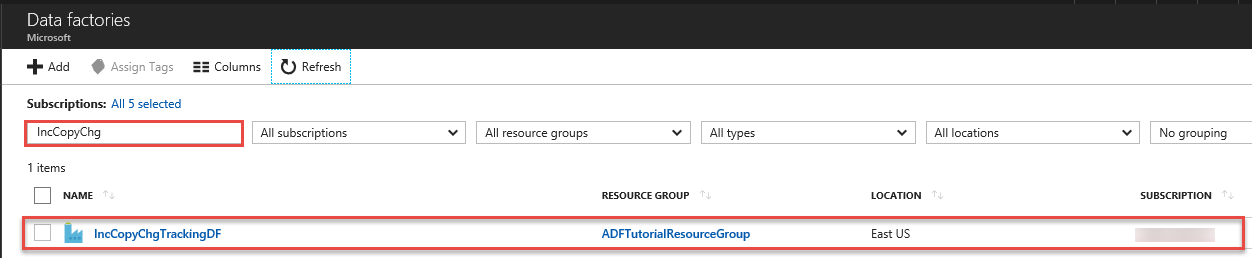
Na página Fábrica de dados, clique no mosaico Monitorizar e Gerir.
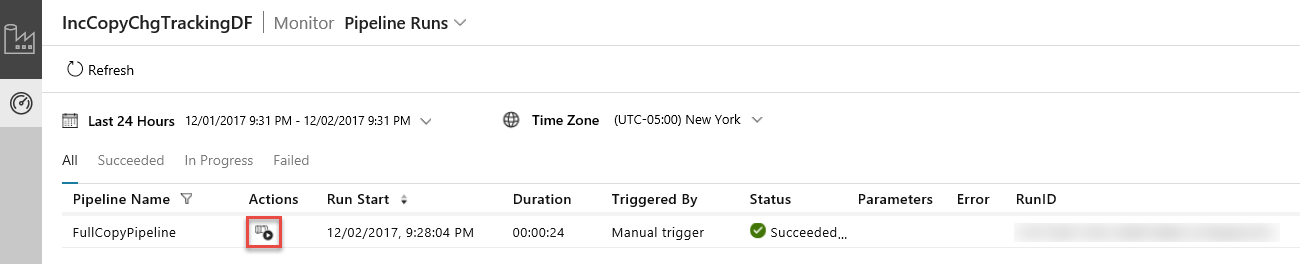
O Aplicativo de Integração de Dados é iniciado em uma guia separada. Você pode ver todas as execuções de pipeline e seus status. Note que no seguinte exemplo, o estado da execução do pipeline é Com Êxito. Pode verificar os parâmetros transmitidos para o pipeline ao clicar na ligação na coluna Parâmetros. Se tiver ocorrido um erro, pode ver uma ligação na coluna Erro. Clique na ligação na coluna Ações.
Ao clicar na ligação na coluna Ações, verá a seguinte página que mostra todas as execuções de atividade no pipeline.
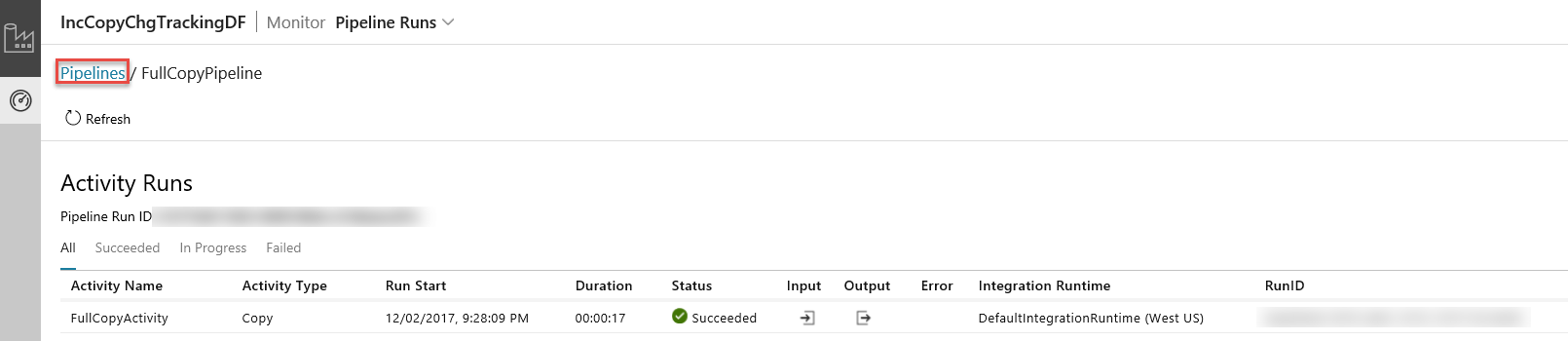
Para mudar de volta para a visualização Execuções do pipeline, clique em Pipelines conforme mostrado na imagem.
Rever os resultados
Vai ver um ficheiro chamado incremental-<GUID>.txt na pasta incchgtracking do contentor adftutorial.
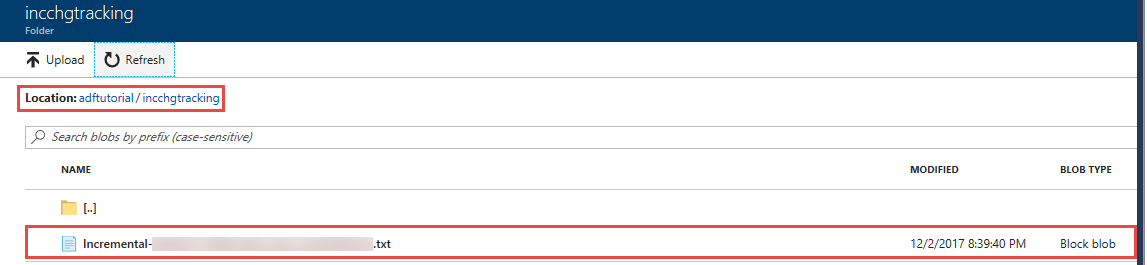
O ficheiro deve conter os dados da sua base de dados:
1,aaaa,21
2,bbbb,24
3,cccc,20
4,dddd,26
5,eeee,22
Adicione mais dados à tabela de origem
Execute a seguinte consulta em seu banco de dados para adicionar uma linha e atualizar uma linha.
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
Criar um pipeline para a cópia do delta
Neste passo, cria um pipeline com as seguintes atividades e execute-o periodicamente. As duas atividades de pesquisa obtêm os SYS_CHANGE_VERSION antigo e novo da Base de Dados SQL do Azure e passe-o para a atividade de cópia. A atividade de cópia copia os dados inseridos/atualizados/eliminados entre os dois valores de SYS_CHANGE_VERSION da Base de Dados SQL do Azure para o Armazenamento de Blobs do Azure. A atividade de procedimentos armazenados atualiza o valor de SYS_CHANGE_VERSION para a próxima execução de pipeline.
Crie um ficheiro JSON: IncrementalCopyPipeline.json na mesma pasta com o seguinte conteúdo:
{ "name": "IncrementalCopyPipeline", "properties": { "activities": [ { "name": "LookupLastChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select * from table_store_ChangeTracking_version" }, "dataset": { "referenceName": "ChangeTrackingDataset", "type": "DatasetReference" } } }, { "name": "LookupCurrentChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion" }, "dataset": { "referenceName": "SourceDataset", "type": "DatasetReference" } } }, { "name": "IncrementalCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) as CT on data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}" }, "sink": { "type": "BlobSink" } }, "dependsOn": [ { "activity": "LookupLastChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] }, { "activity": "LookupCurrentChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] } ], "inputs": [ { "referenceName": "SourceDataset", "type": "DatasetReference" } ], "outputs": [ { "referenceName": "SinkDataset", "type": "DatasetReference" } ] }, { "name": "StoredProceduretoUpdateChangeTrackingActivity", "type": "SqlServerStoredProcedure", "typeProperties": { "storedProcedureName": "Update_ChangeTracking_Version", "storedProcedureParameters": { "CurrentTrackingVersion": { "value": "@{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}", "type": "INT64" }, "TableName": { "value": "@{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}", "type": "String" } } }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" }, "dependsOn": [ { "activity": "IncrementalCopyActivity", "dependencyConditions": [ "Succeeded" ] } ] } ] } }Execute o cmdlet Set-AzDataFactoryV2Pipeline para criar o pipeline: FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"Segue-se o resultado do exemplo:
PipelineName : IncrementalCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {LookupLastChangeTrackingVersionActivity, LookupCurrentChangeTrackingVersionActivity, IncrementalCopyActivity, StoredProceduretoUpdateChangeTrackingActivity} Parameters :
Executar o pipeline da cópia incremental
Execute o pipeline: IncrementalCopyPipeline usando o cmdlet Invoke-AzDataFactoryV2Pipeline .
Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
Monitorizar o pipeline da cópia incremental
Na Aplicação de Integração de Dados, atualize a vista de execuções de pipeline. Confirme que vê o IncrementalCopyPipeline na lista. Clique na ligação na coluna Ações.
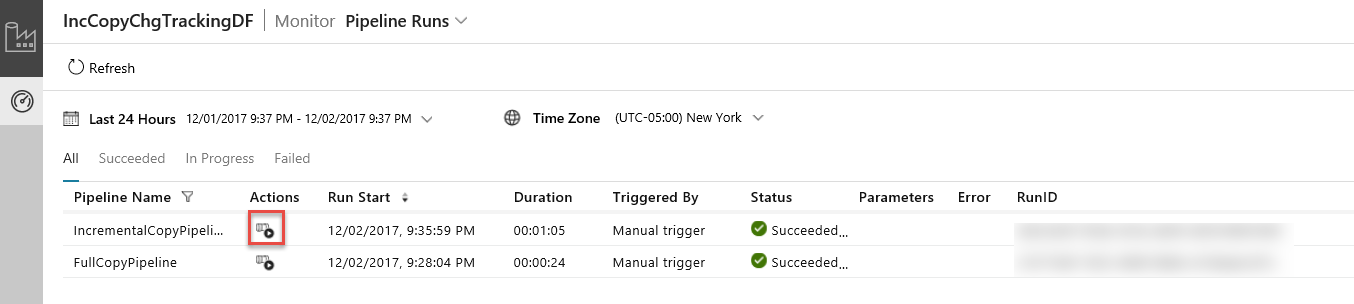
Ao clicar na ligação na coluna Ações, verá a seguinte página que mostra todas as execuções de atividade no pipeline.
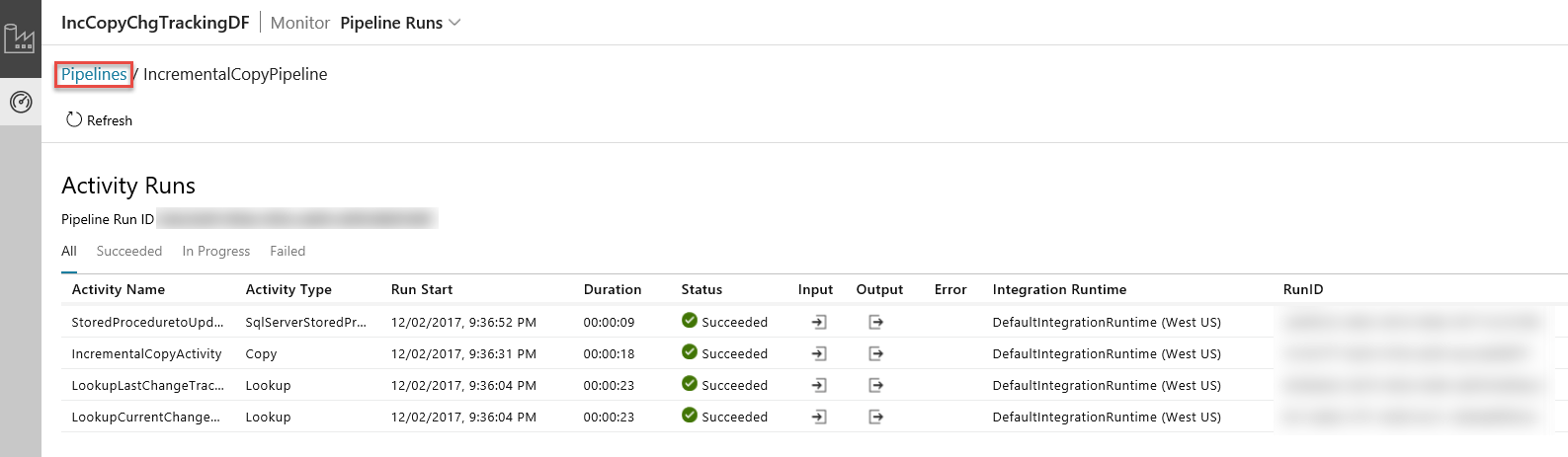
Para mudar de volta para a visualização Execuções do pipeline, clique em Pipelines conforme mostrado na imagem.
Rever os resultados
Vai ver um segundo ficheiro na pasta incchgtracking do contentor adftutorial.
O arquivo deve ter apenas os dados delta do seu banco de dados. O registo com U é a linha atualizada na base de dados e I é a linha adicionada.
1,update,10,2,U
6,new,50,1,I
As primeiros três colunas são dados alterados de data_source_table. As últimas duas colunas são os metadados da tabela do sistema de controlo de alterações. A quarta coluna é o SYS_CHANGE_VERSION para cada linha alterada. A quinta coluna é a operação: U = atualizar, I = inserir. Para obter detalhes sobre as informações do registo de alterações, consulte CHANGETABLE.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
Conteúdos relacionados
Avance para o tutorial a seguir para saber como copiar arquivos novos e alterados somente com base em sua LastModifiedDate: