Transformar dados executando uma definição de trabalho do Synapse Spark
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
A definição de trabalho do Azure Synapse Spark Activity em um pipeline executa uma definição de trabalho do Synapse Spark em seu espaço de trabalho do Azure Synapse Analytics. Este artigo baseia-se no artigo de atividades de transformação de dados, que apresenta uma visão geral da transformação de dados e das atividades de transformação suportadas.
Definir tela de definição de trabalho do Apache Spark
Para usar uma atividade de definição de trabalho do Spark para Synapse em um pipeline, conclua as seguintes etapas:
Definições gerais
Procure a definição de trabalho do Spark no painel Atividades do pipeline e arraste uma atividade de definição de trabalho do Spark sob a Sinapse para a tela do pipeline.
Selecione a nova atividade de definição de trabalho do Spark na tela, se ainda não estiver selecionada.
Na guia Geral, insira o exemplo para Nome.
(Opção) Você também pode inserir uma descrição.
Tempo limite: quantidade máxima de tempo que uma atividade pode ser executada. O padrão é de sete dias, que também é a quantidade máxima de tempo permitida. O formato está em D.HH:MM:SS.
Repetir: número máximo de tentativas de repetição.
Intervalo de novas tentativas: o número de segundos entre cada tentativa de repetição.
Saída segura: Quando marcada, a saída da atividade não será capturada no registro.
Entrada segura: quando marcada, a entrada da atividade não será capturada no registro.
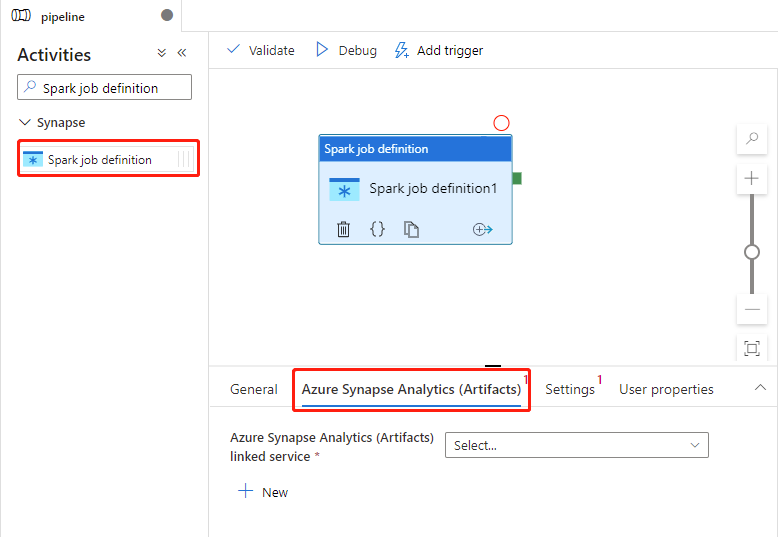
Configurações do Azure Synapse Analytics (Artefatos)
Selecione a nova atividade de definição de trabalho do Spark na tela, se ainda não estiver selecionada.
Selecione a guia Azure Synapse Analytics (Artefatos) para selecionar ou criar um novo serviço vinculado do Azure Synapse Analytics que executará a atividade de definição de trabalho do Spark.
Separador Definições
Selecione a nova atividade de definição de trabalho do Spark na tela, se ainda não estiver selecionada.
Selecione o separador Definições.
Expanda a lista de definições de trabalho do Spark, você pode selecionar uma definição de trabalho existente do Apache Spark no espaço de trabalho vinculado do Azure Synapse Analytics.
(Opcional) Você pode preencher as informações para a definição de trabalho do Apache Spark. Se as configurações a seguir estiverem vazias, as configurações da própria definição de trabalho de faísca serão usadas para executar; Se as configurações a seguir não estiverem vazias, elas substituirão as configurações da própria definição de trabalho do Spark.
Property Description Ficheiro de definição principal O arquivo principal usado para o trabalho. Selecione um arquivo PY/JAR/ZIP do seu armazenamento. Você pode selecionar Carregar arquivo para carregar o arquivo em uma conta de armazenamento.
Exemplo:abfss://…/path/to/wordcount.jarReferências de subpastas Verificando subpastas da pasta raiz do arquivo de definição principal, esses arquivos serão adicionados como arquivos de referência. As pastas denominadas "jars", "pyFiles", "files" ou "archives" serão verificadas, e o nome das pastas diferencia maiúsculas de minúsculas. Nome da classe principal O identificador totalmente qualificado ou a classe principal que está no arquivo de definição principal.
Exemplo:WordCountArgumentos de linha de comando Você pode adicionar argumentos de linha de comando clicando no botão Novo . Deve-se notar que a adição de argumentos de linha de comando substituirá os argumentos de linha de comando definidos pela definição de trabalho do Spark.
Amostra:abfss://…/path/to/shakespeare.txtabfss://…/path/to/resultPiscina Apache Spark Você pode selecionar Apache Spark pool na lista. Referência de código Python Arquivos de código python adicionais usados para referência no arquivo de definição principal.
Ele suporta a passagem de arquivos (.py, .py3, .zip) para a propriedade "pyFiles". Ele substituirá a propriedade "pyFiles" definida na definição de trabalho do Spark.Ficheiros de referência Arquivos adicionais usados para referência no arquivo de definição principal. Piscina Apache Spark Você pode selecionar Apache Spark pool na lista. Alocar executores dinamicamente Essa configuração é mapeada para a propriedade de alocação dinâmica na configuração do Spark para alocação de executores do Spark Application. Executores Min Número mínimo de executores a serem alocados no pool Spark especificado para o trabalho. Max executores Número máximo de executores a serem alocados no pool de faíscas especificado para o trabalho. Tamanho do driver Número de núcleos e memória a serem usados para o driver fornecido no pool Apache Spark especificado para o trabalho. Configuração do Spark Especifique valores para as propriedades de configuração do Spark listadas no tópico: Configuração do Spark - Propriedades do aplicativo. Os usuários podem usar a configuração padrão e a configuração personalizada. 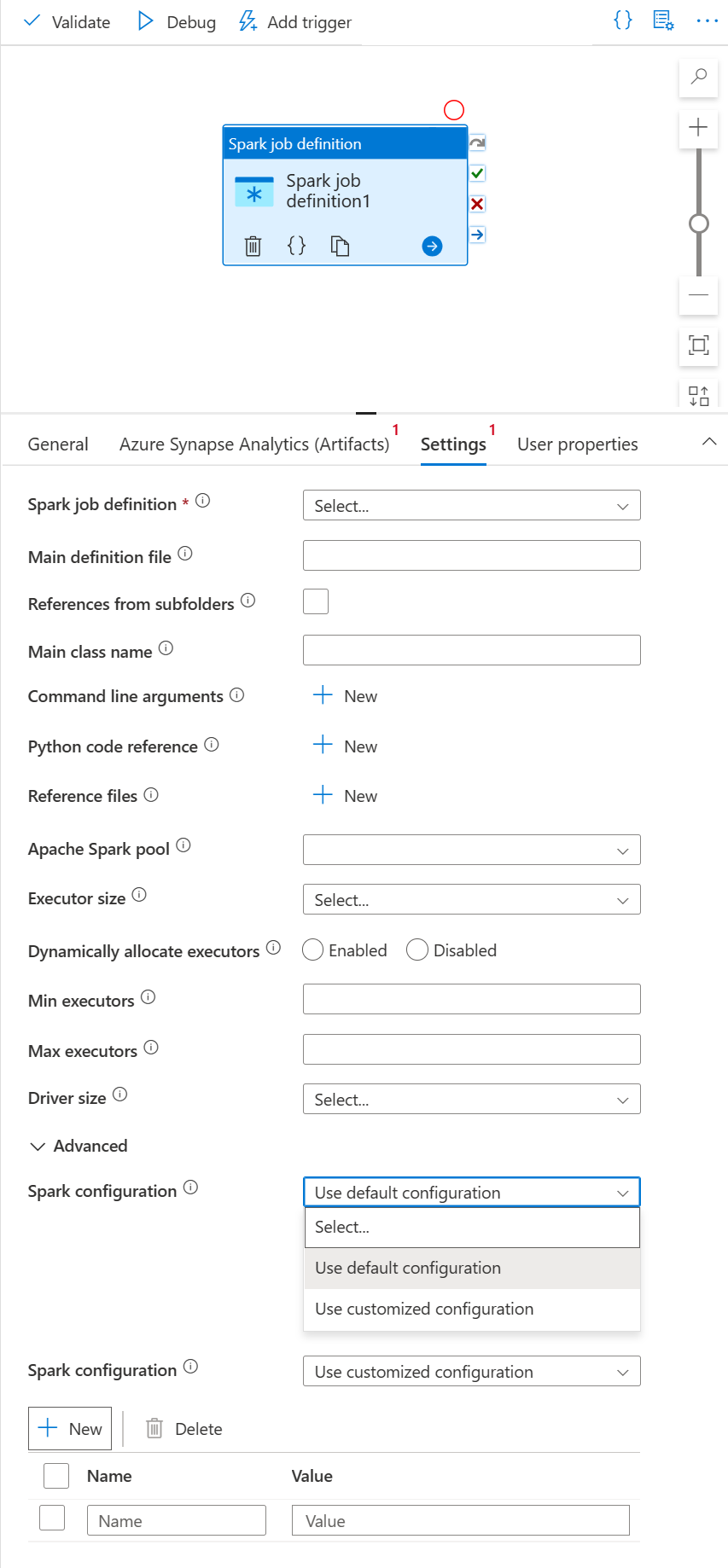
Você pode adicionar conteúdo dinâmico clicando no botão Adicionar conteúdo dinâmico ou pressionando a tecla de atalho Alt+Shift+D. Na página Adicionar Conteúdo Dinâmico, você pode usar qualquer combinação de expressões, funções e variáveis do sistema para adicionar ao conteúdo dinâmico.
Guia Propriedades do usuário
Você pode adicionar propriedades para a atividade de definição de trabalho do Apache Spark neste painel.
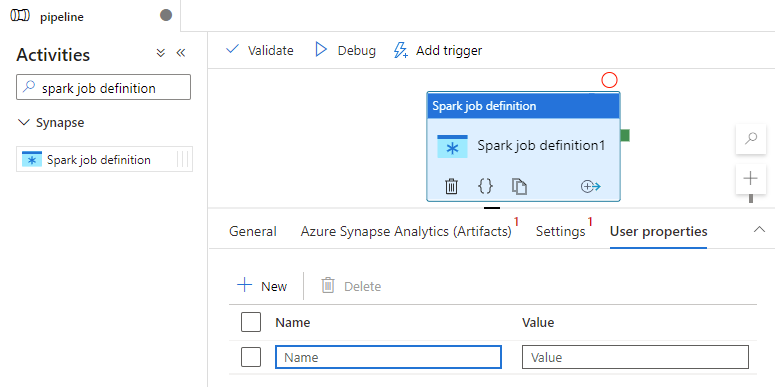
Definição de atividade de definição de trabalho de faísca do Azure Synapse
Aqui está a definição JSON de exemplo de uma atividade do Bloco de Anotações do Azure Synapse Analytics:
{
"activities": [
{
"name": "Spark job definition1",
"type": "SparkJob",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"typeProperties": {
"sparkJob": {
"referenceName": {
"value": "Spark job definition 1",
"type": "Expression"
},
"type": "SparkJobDefinitionReference"
}
},
"linkedServiceName": {
"referenceName": "AzureSynapseArtifacts1",
"type": "LinkedServiceReference"
}
}
],
}
Propriedades de definição de trabalho do Azure Synapse Spark
A tabela a seguir descreve as propriedades JSON usadas na definição JSON:
| Property | Descrição | Obrigatório |
|---|---|---|
| nome | Nome da atividade no pipeline. | Sim |
| descrição | Texto descrevendo o que a atividade faz. | Não |
| tipo | Para a Atividade de definição de trabalho de faísca do Azure Synapse, o tipo de atividade é SparkJob. | Sim |
Consulte o histórico de execução da atividade de definição de trabalho do Azure Synapse Spark
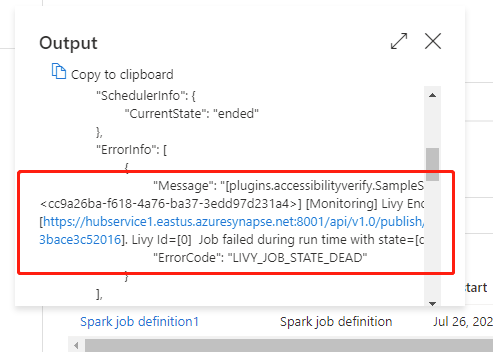
Vá para Pipeline executa na guia Monitor , você verá o pipeline que acionou. Abra o pipeline que contém a atividade de definição de trabalho do Azure Synapse Spark para ver o histórico de execução.
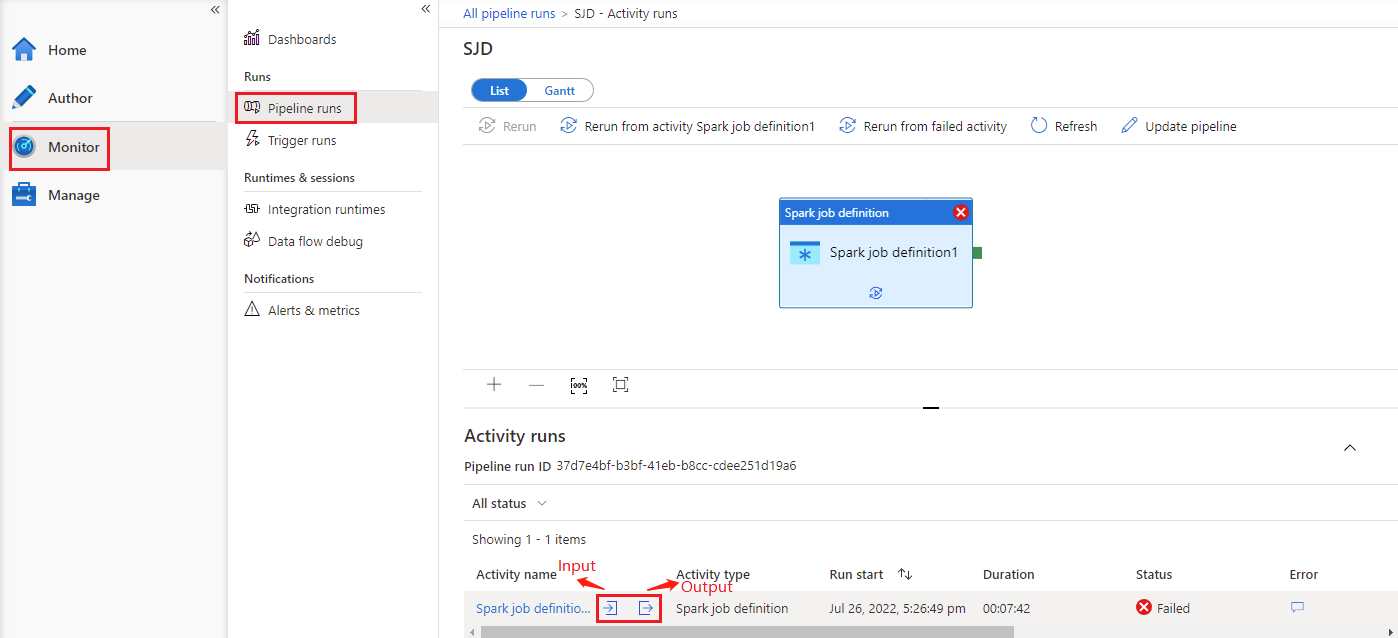
Você pode ver a entrada ou saída da atividade do notebook selecionando o botão de entrada ou Saída. Se o pipeline falhou com um erro do usuário, selecione a saída para verificar o campo de resultado para ver o rastreio detalhado do erro do usuário.