Transformação com o Azure Databricks
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
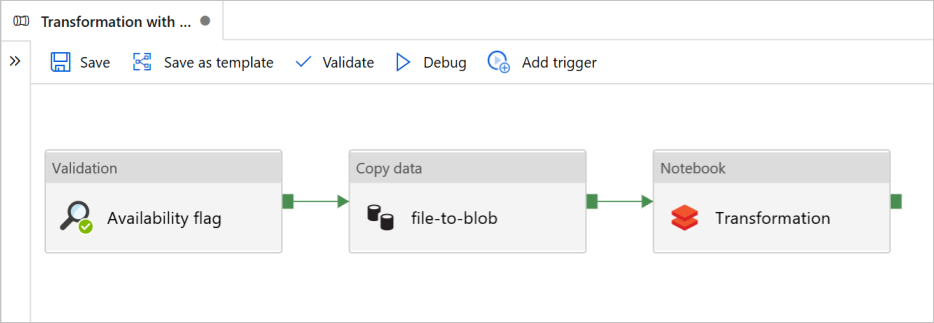
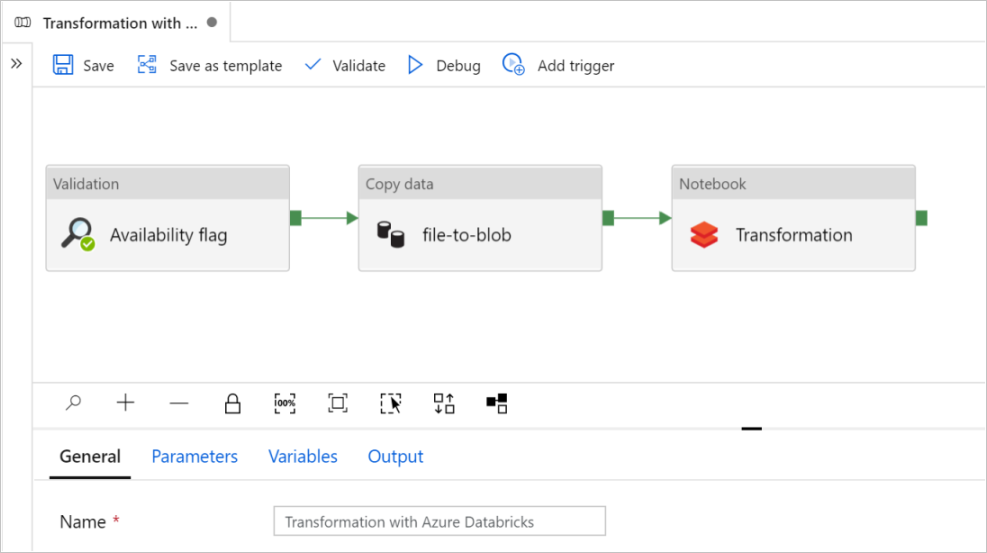
Neste tutorial, você cria um pipeline de ponta a ponta que contém as atividades de Validação, Cópia de dados e Bloco de Anotações no Azure Data Factory.
A validação garante que seu conjunto de dados de origem esteja pronto para consumo downstream antes de acionar o trabalho de cópia e análise.
Copiar dados duplica o conjunto de dados de origem para o armazenamento do coletor, que é montado como DBFS no bloco de anotações do Azure Databricks. Desta forma, o conjunto de dados pode ser consumido diretamente pelo Spark.
O bloco de anotações aciona o bloco de anotações Databricks que transforma o conjunto de dados. Ele também adiciona o conjunto de dados a uma pasta processada ou ao Azure Synapse Analytics.
Para simplificar, o modelo neste tutorial não cria um gatilho agendado. Você pode adicionar um, se necessário.
Pré-requisitos
Uma conta de armazenamento de Blob do Azure com um contêiner chamado
sinkdatapara uso como coletor.Anote o nome da conta de armazenamento, o nome do contêiner e a chave de acesso. Você precisará desses valores posteriormente no modelo.
Um espaço de trabalho do Azure Databricks.
Importar um bloco de notas para transformação
Para importar um bloco de anotações de transformação para seu espaço de trabalho Databricks:
Entre no seu espaço de trabalho do Azure Databricks e selecione Importar.
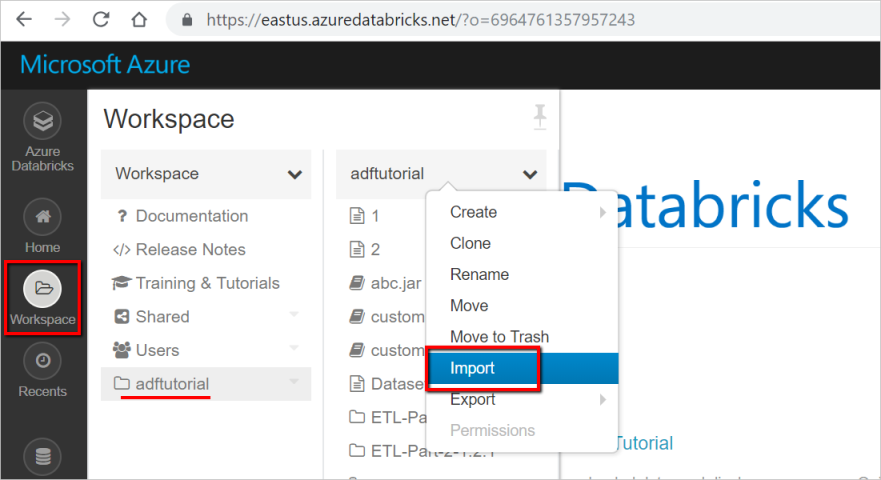 O caminho do espaço de trabalho pode ser diferente do mostrado, mas lembre-se dele para mais tarde.
O caminho do espaço de trabalho pode ser diferente do mostrado, mas lembre-se dele para mais tarde.Selecione Importar de: URL. Na caixa de texto, digite
https://adflabstaging1.blob.core.windows.net/share/Transformations.html.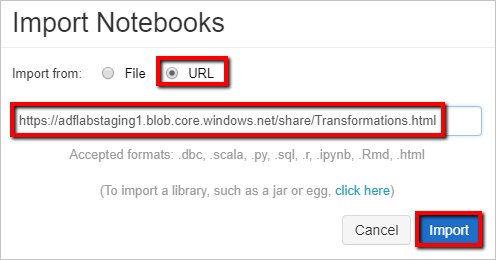
Agora vamos atualizar o bloco de anotações de transformação com suas informações de conexão de armazenamento.
No bloco de anotações importado, vá para o comando 5 , conforme mostrado no trecho de código a seguir.
- Substitua
<storage name>e<access key>por suas próprias informações de conexão de armazenamento. - Use a conta de armazenamento com o
sinkdatacontêiner.
# Supply storageName and accessKey values storageName = "<storage name>" accessKey = "<access key>" try: dbutils.fs.mount( source = "wasbs://sinkdata\@"+storageName+".blob.core.windows.net/", mount_point = "/mnt/Data Factorydata", extra_configs = {"fs.azure.account.key."+storageName+".blob.core.windows.net": accessKey}) except Exception as e: # The error message has a long stack track. This code tries to print just the relevant line indicating what failed. import re result = re.findall(r"\^\s\*Caused by:\s*\S+:\s\*(.*)\$", e.message, flags=re.MULTILINE) if result: print result[-1] \# Print only the relevant error message else: print e \# Otherwise print the whole stack trace.- Substitua
Gere um token de acesso Databricks para o Data Factory acessar o Databricks.
- No espaço de trabalho Databricks, selecione o ícone do seu perfil de usuário no canto superior direito.
- Selecione Configurações do usuário.
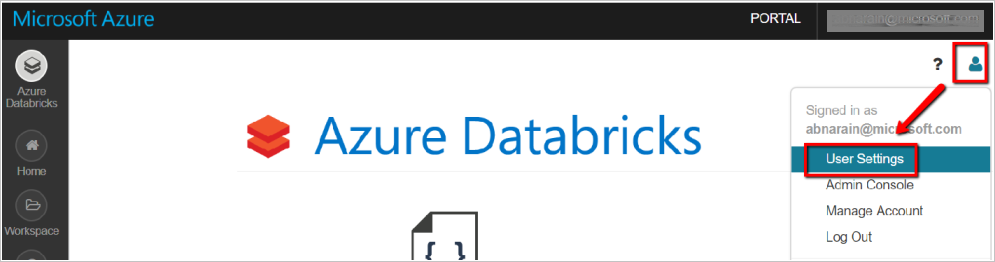
- Selecione Gerar novo token na guia Tokens de acesso .
- Selecione Gerar.

Salve o token de acesso para uso posterior na criação de um serviço vinculado Databricks. O token de acesso se parece com
dapi32db32cbb4w6eee18b7d87e45exxxxxx.
Como usar este modelo
Vá para o modelo Transformação com o Azure Databricks e crie novos serviços vinculados para as seguintes conexões.
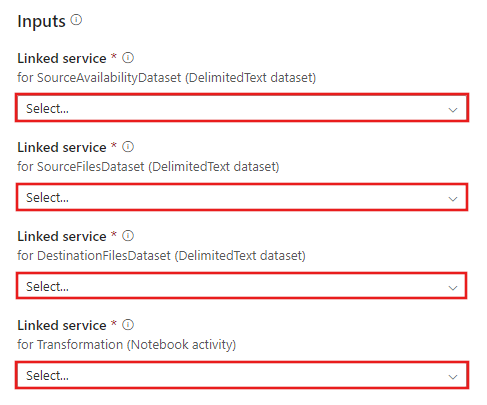
Conexão de Blob de Origem - para acessar os dados de origem.
Para este exercício, você pode usar o armazenamento de blob público que contém os arquivos de origem. Consulte a captura de tela a seguir para a configuração. Use a seguinte URL SAS para se conectar ao armazenamento de origem (acesso somente leitura):
https://storagewithdata.blob.core.windows.net/data?sv=2018-03-28&si=read%20and%20list&sr=c&sig=PuyyS6%2FKdB2JxcZN0kPlmHSBlD8uIKyzhBWmWzznkBw%3D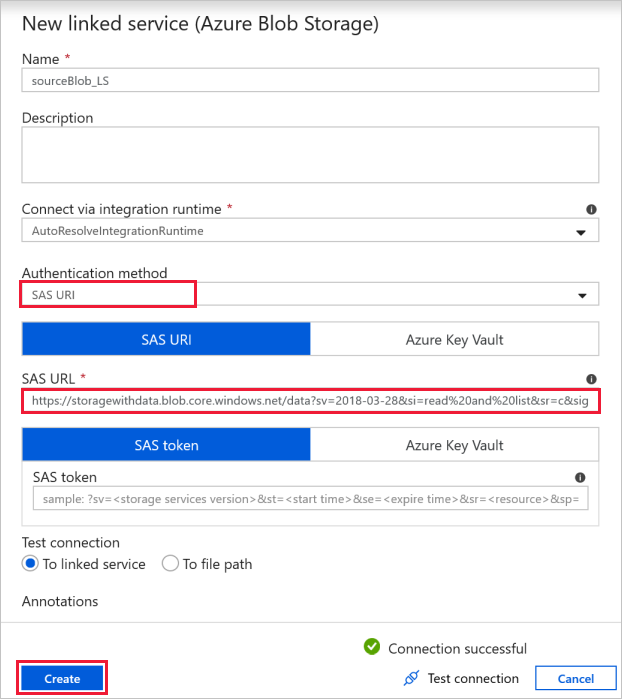
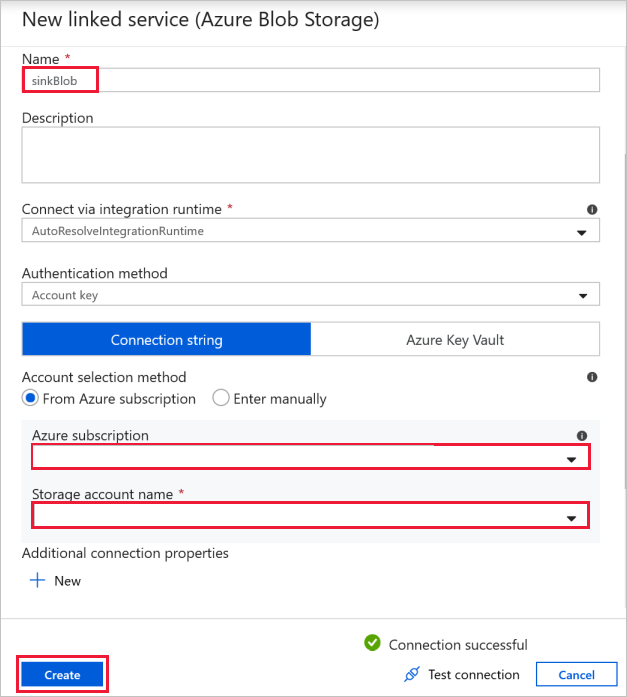
Conexão de Blob de Destino - para armazenar os dados copiados.
Na janela Novo serviço vinculado, selecione o blob de armazenamento do coletor.
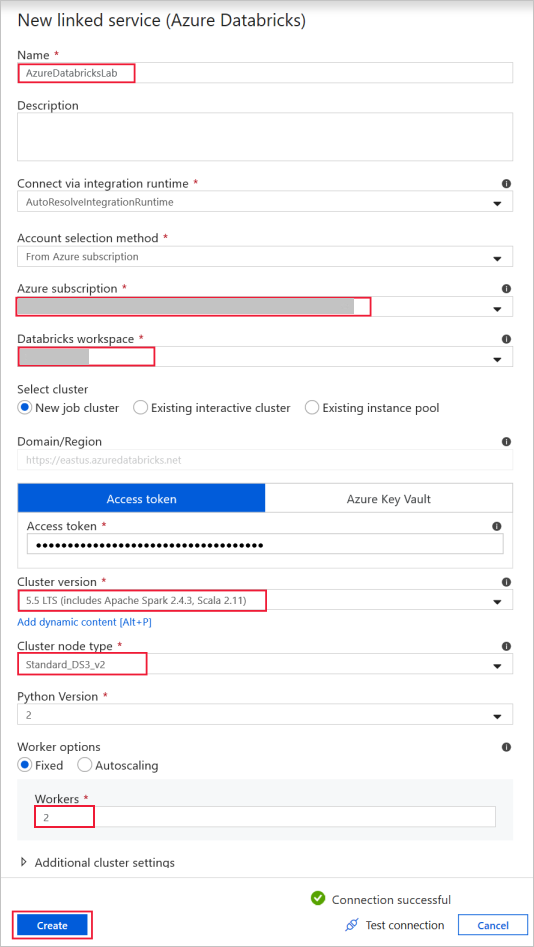
Azure Databricks - para se conectar ao cluster Databricks.
Crie um serviço vinculado ao Databricks usando a chave de acesso gerada anteriormente. Você pode optar por selecionar um cluster interativo, se tiver um. Este exemplo usa a opção Novo cluster de trabalho.
Selecione Utilizar este modelo. Você verá um pipeline criado.
Introdução e configuração de pipeline
No novo pipeline, a maioria das configurações é configurada automaticamente com valores padrão. Revise as configurações do seu pipeline e faça as alterações necessárias.
No sinalizador Disponibilidade da atividade de validação, verifique se o valor do Conjunto de Dados de origem está definido como
SourceAvailabilityDataseto que você criou anteriormente.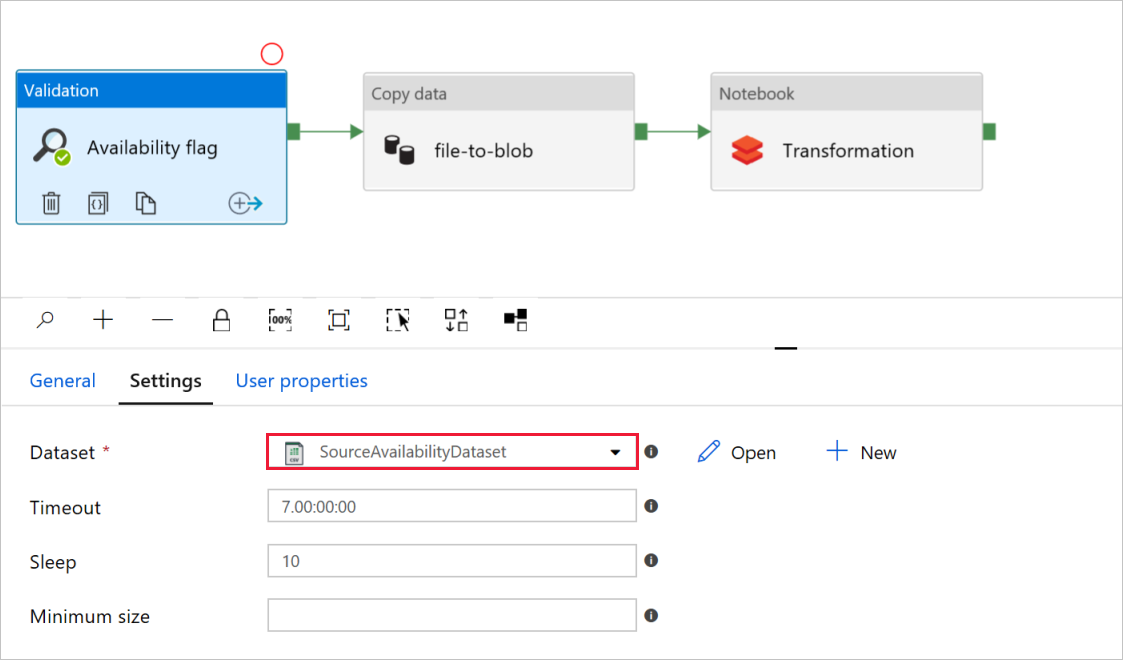
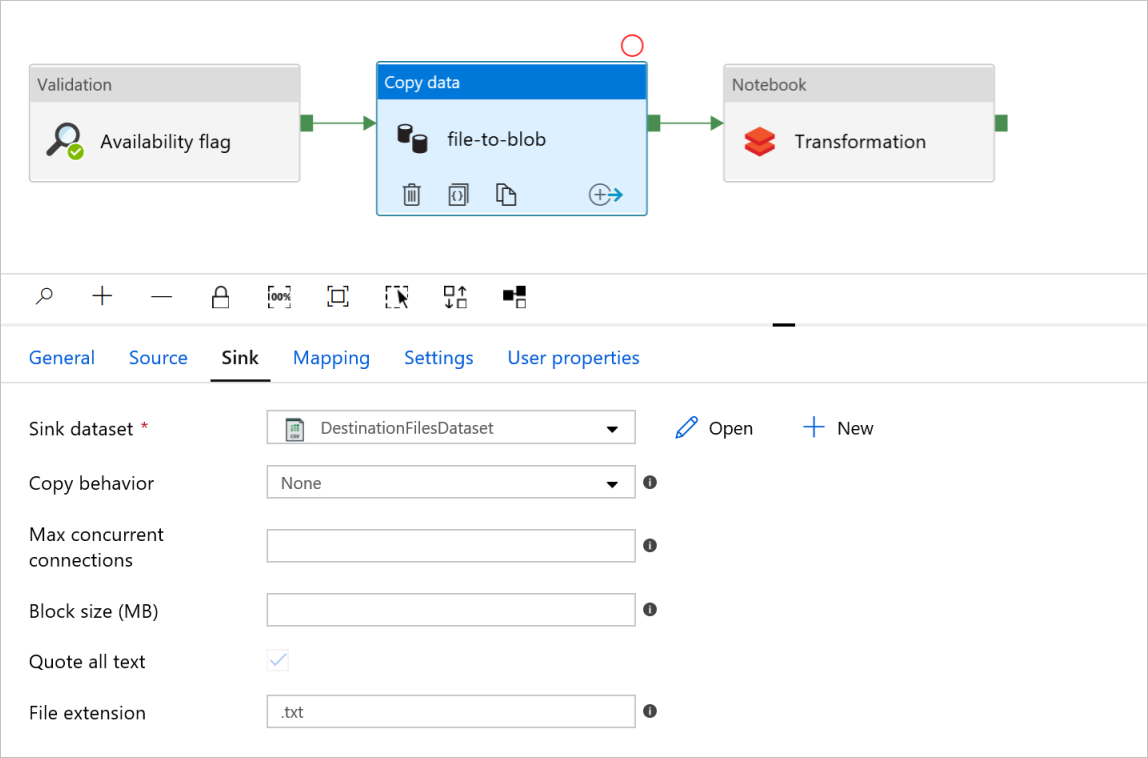
Em Copiar arquivo de atividade de dados para blob, marque as guias Origem e Coletor. Altere as configurações, se necessário.
Guia Fonte
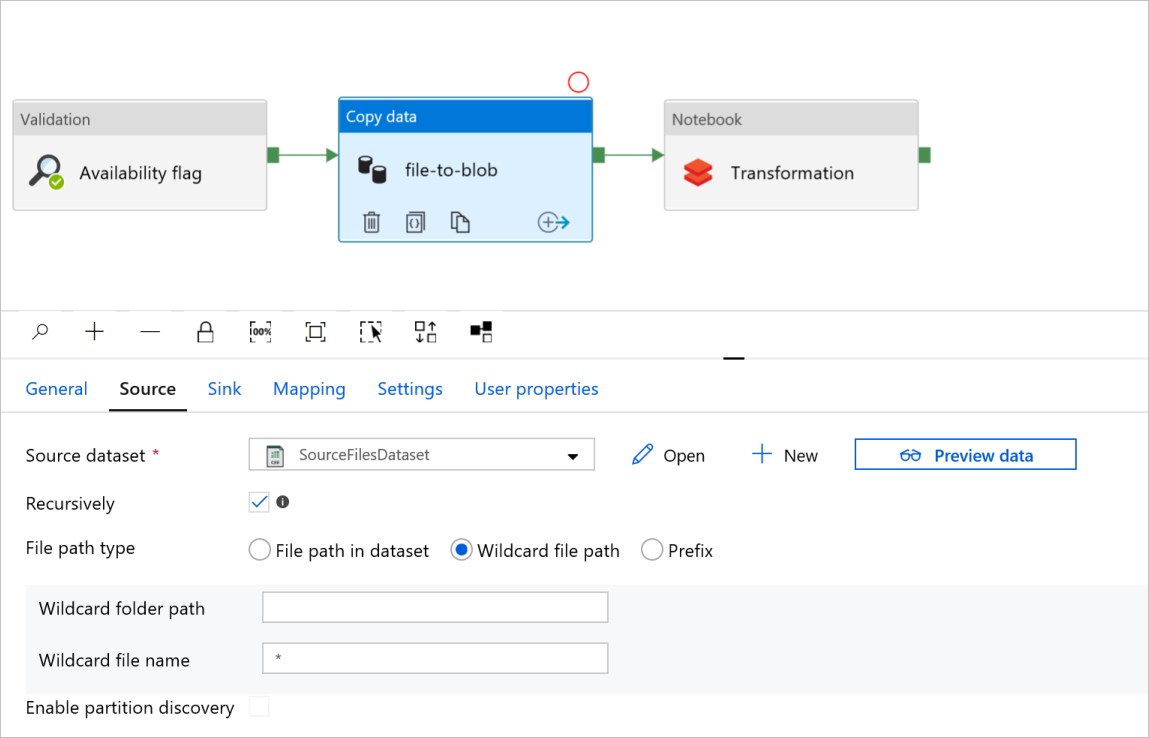
Aba Pia
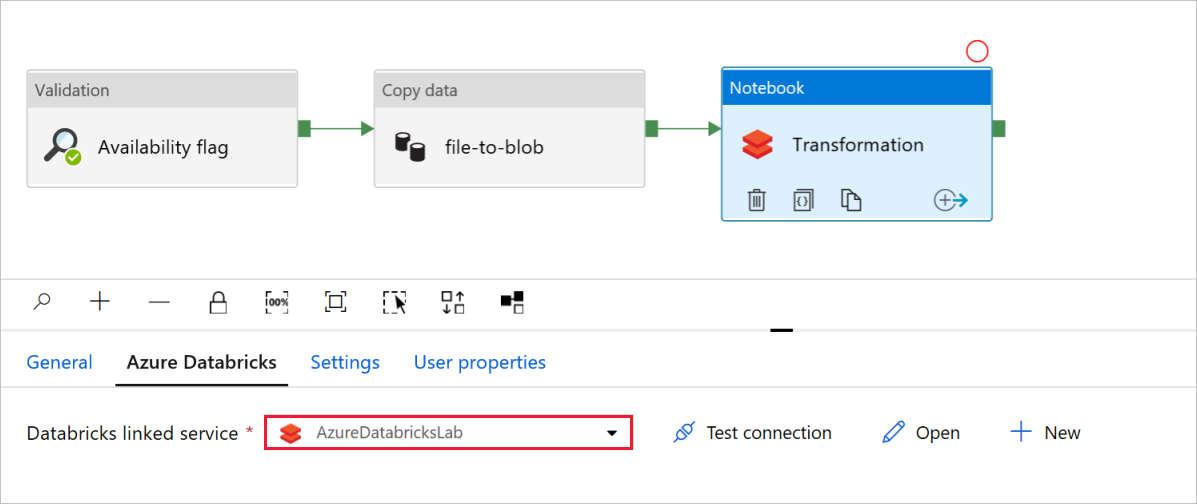
Na atividade Transformação do Bloco de Notas, reveja e atualize os caminhos e as definições conforme necessário.
O serviço vinculado Databricks deve ser pré-preenchido com o valor de uma etapa anterior, conforme mostrado:
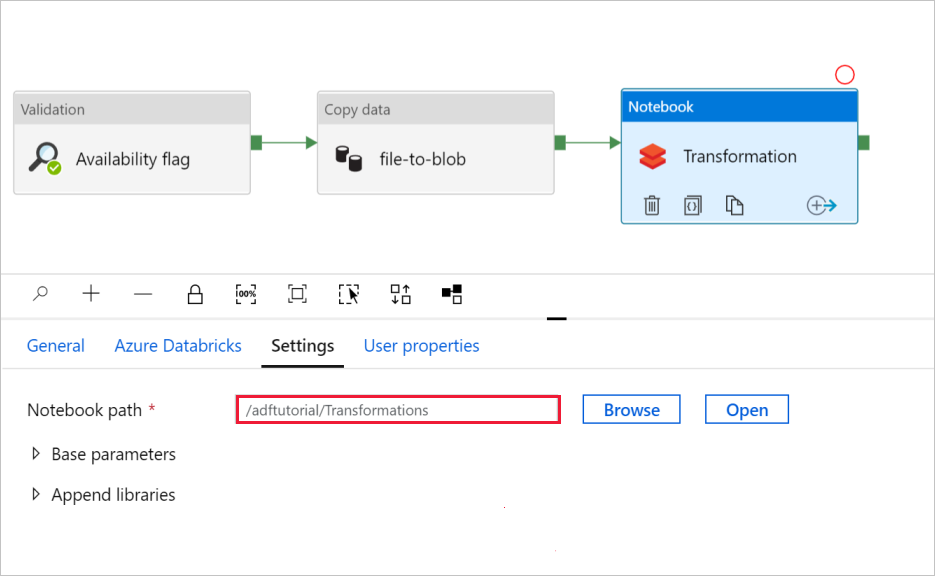
Para verificar as configurações do Bloco de Anotações :
Selecione a guia Configurações . Para Caminho do bloco de anotações, verifique se o caminho padrão está correto. Talvez seja necessário navegar e escolher o caminho correto do bloco de anotações.
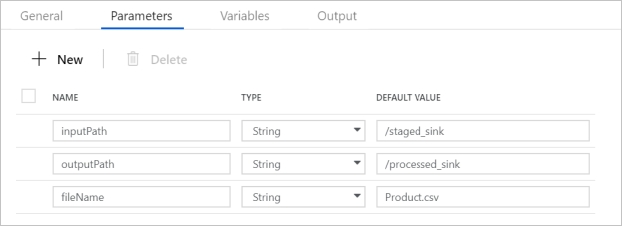
Expanda o seletor Parâmetros básicos e verifique se os parâmetros correspondem ao que é mostrado na captura de tela a seguir. Esses parâmetros são passados para o notebook Databricks do Data Factory.
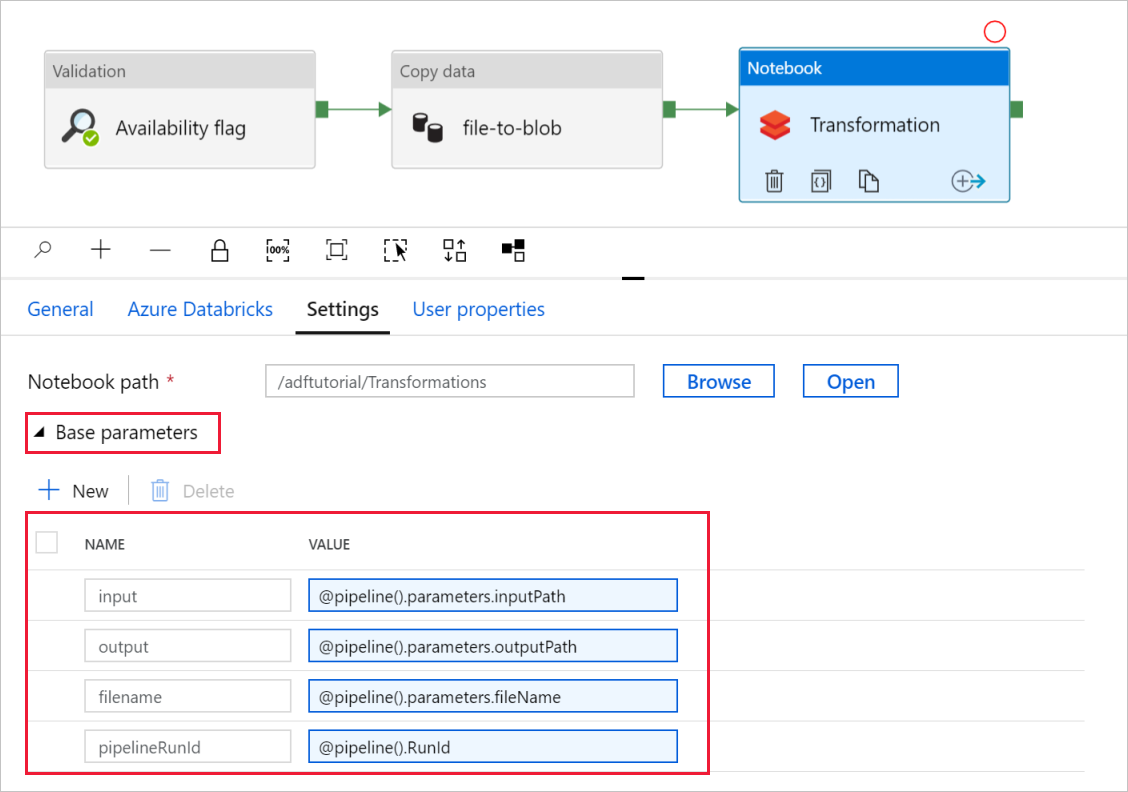
Verifique se os parâmetros do pipeline correspondem ao que é mostrado na captura de tela a seguir:
Conecte-se aos seus conjuntos de dados.
Nota
Nos conjuntos de dados abaixo, o caminho do arquivo foi especificado automaticamente no modelo. Se alguma alteração for necessária, certifique-se de especificar o caminho para o contêiner e o diretório em caso de erro de conexão.
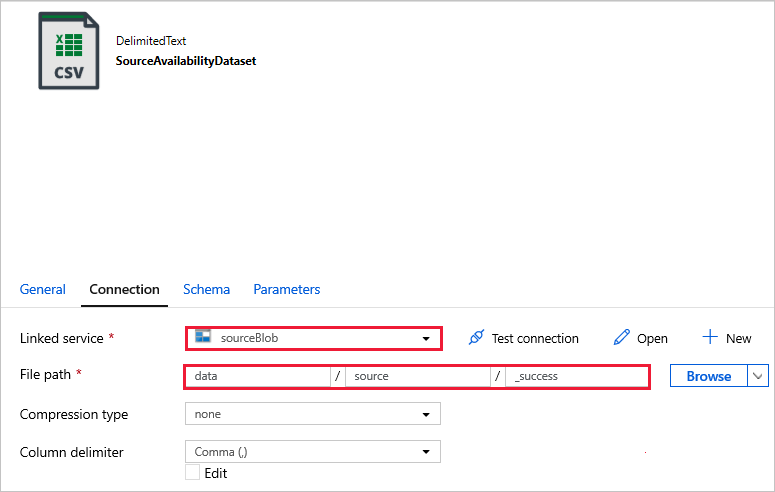
SourceAvailabilityDataset - para verificar se os dados de origem estão disponíveis.
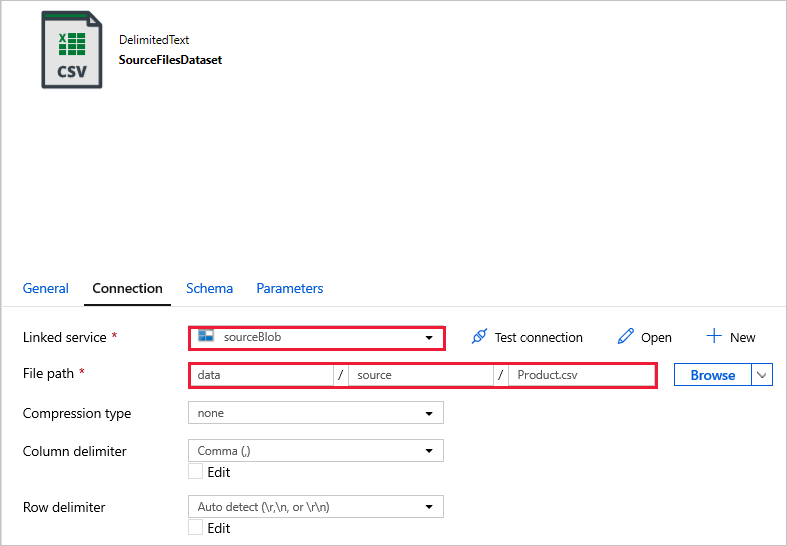
SourceFilesDataset - para acessar os dados de origem.
DestinationFilesDataset - para copiar os dados para o local de destino do coletor. Utilize os seguintes valores:
Serviço -
sinkBlob_LSvinculado, criado em uma etapa anterior.Caminho do arquivo -
sinkdata/staged_sink.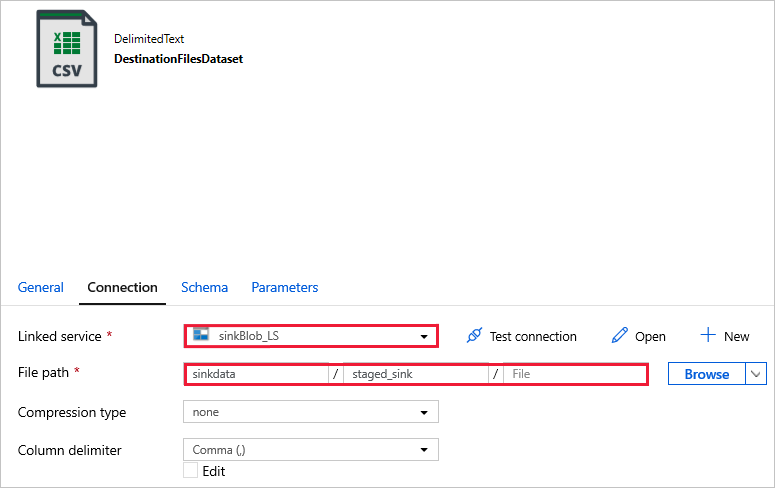
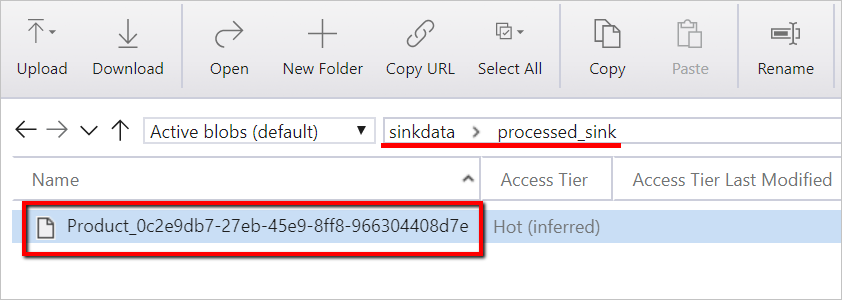
Selecione Depurar para executar o pipeline. Você pode encontrar o link para os logs do Databricks para obter logs do Spark mais detalhados.
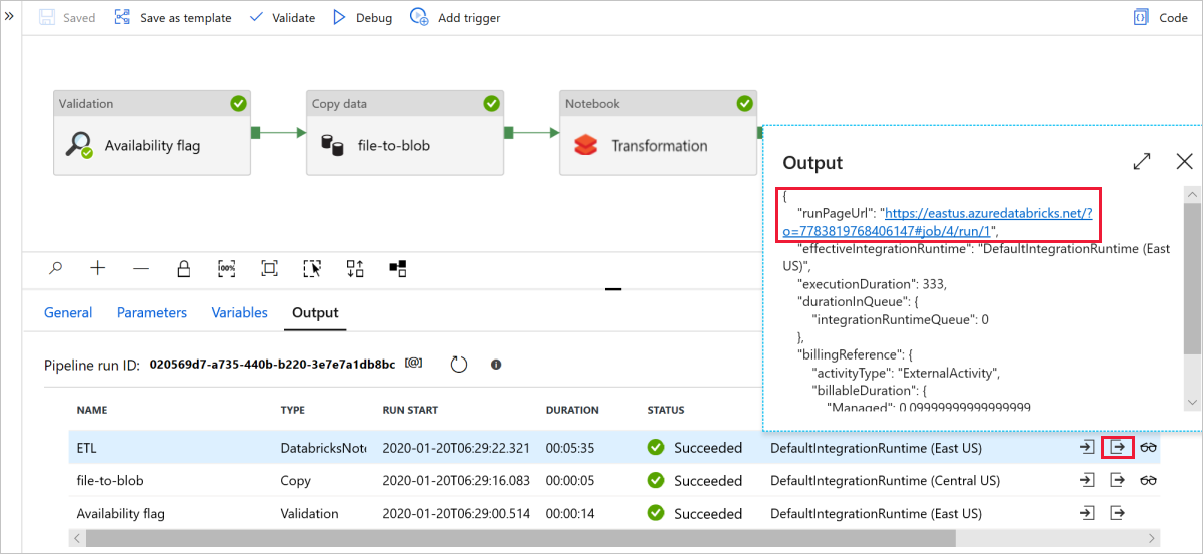
Você também pode verificar o arquivo de dados usando o Gerenciador de Armazenamento do Azure.
Nota
Para correlacionar com execuções de pipeline do Data Factory, este exemplo acrescenta a ID de execução do pipeline do data factory à pasta de saída. Isso ajuda a manter o controle dos arquivos gerados por cada execução.