Transformação de classificação no mapeamento do fluxo de dados
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Os fluxos de dados estão disponíveis no Azure Data Factory e no Azure Synapse Pipelines. Este artigo aplica-se ao mapeamento de fluxos de dados. Se você é novo em transformações, consulte o artigo introdutório Transformar dados usando um fluxo de dados de mapeamento.
A transformação de classificação permite classificar as linhas de entrada no fluxo de dados atual. Você pode escolher colunas individuais e classificá-las em ordem crescente ou decrescente.
Nota
Os fluxos de dados de mapeamento são executados em clusters de faísca que distribuem dados entre vários nós e partições. Se você optar por reparticionar seus dados em uma transformação subsequente, poderá perder sua classificação devido à reorganização dos dados. A melhor maneira de manter a ordem de classificação em seu fluxo de dados é definir uma única partição na guia Otimizar na transformação e manter a transformação Classificar o mais próximo possível do coletor.
Configuração
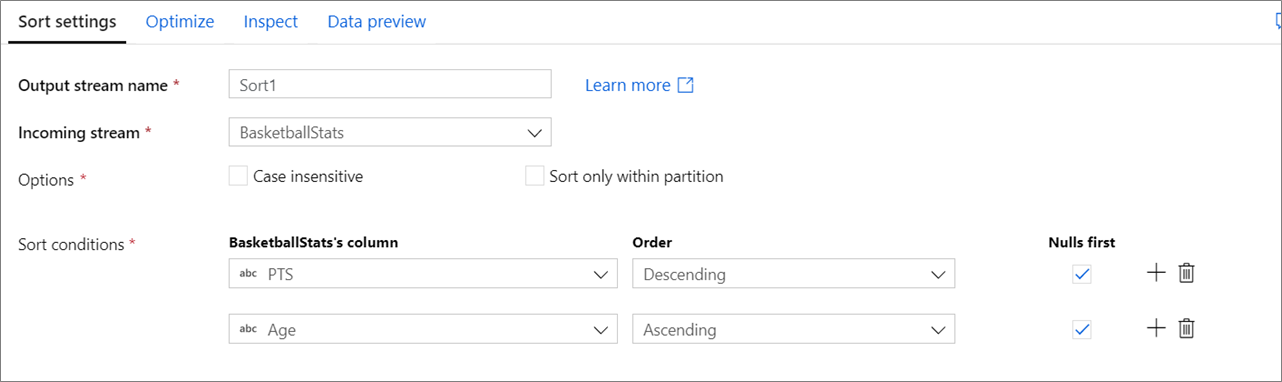
Não diferencia maiúsculas de minúsculas: se você deseja ou não ignorar maiúsculas e minúsculas ao classificar campos de cadeia de caracteres ou de texto
Classificar somente dentro de partições: Como os fluxos de dados são executados no spark, cada fluxo de dados é dividido em partições. Essa configuração classifica os dados somente dentro das partições de entrada, em vez de classificar todo o fluxo de dados.
Condições de classificação: escolha por quais colunas você está classificando e em que ordem a classificação acontece. A ordem determina a prioridade de classificação. Escolha se os nulos aparecerão ou não no início ou no final do fluxo de dados.
Colunas computadas
Para modificar ou extrair um valor de coluna antes de aplicar a classificação, passe o mouse sobre a coluna e selecione "coluna computada". Isso abrirá o construtor de expressões para criar uma expressão para a operação de classificação em vez de usar um valor de coluna.
Script de fluxo de dados
Sintaxe
<incomingStream>
sort(
desc(<sortColumn1>, { true | false }),
asc(<sortColumn2>, { true | false }),
...
) ~> <sortTransformationName<>
Exemplo
O script de fluxo de dados para a configuração de classificação acima está no trecho de código abaixo.
BasketballStats sort(desc(PTS, true),
asc(Age, true)) ~> Sort1
Conteúdos relacionados
Após a classificação, convém usar a Transformação Agregada