Transformações de pesquisa no mapeamento do fluxo de dados
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Os fluxos de dados estão disponíveis no Azure Data Factory e no Azure Synapse Pipelines. Este artigo aplica-se ao mapeamento de fluxos de dados. Se você é novo em transformações, consulte o artigo introdutório Transformar dados usando um fluxo de dados de mapeamento.
Use a transformação de pesquisa para fazer referência a dados de outra fonte em um fluxo de fluxo de dados. A transformação de pesquisa acrescenta colunas de dados correspondentes aos dados de origem.
Uma transformação de pesquisa é semelhante a uma junção externa esquerda. Todas as linhas do fluxo primário existirão no fluxo de saída com colunas adicionais do fluxo de pesquisa.
Configuração
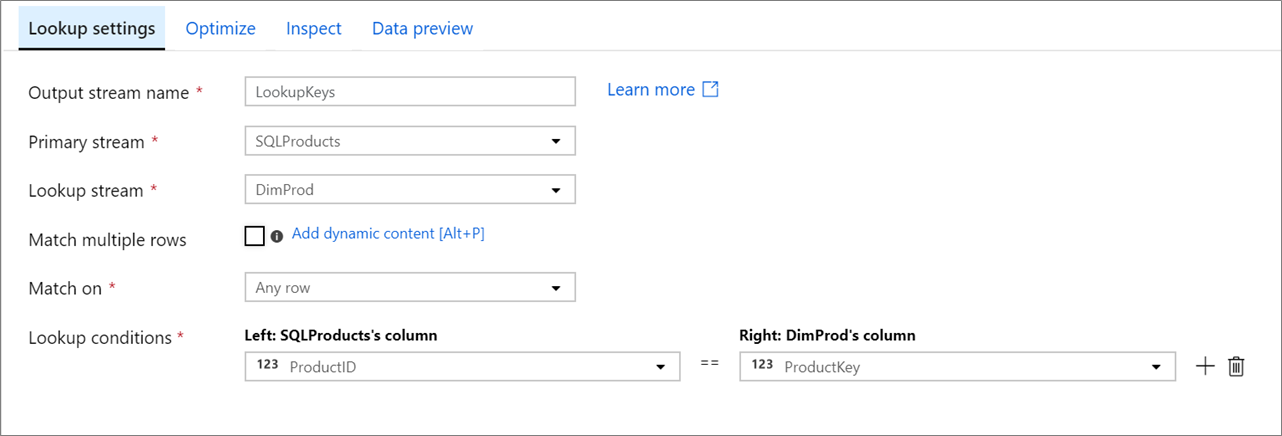
Fluxo primário: o fluxo de entrada de dados. Este fluxo é equivalente ao lado esquerdo de uma junção.
Fluxo de pesquisa: os dados que são anexados ao fluxo primário. Os dados adicionados são determinados pelas condições de pesquisa. Este fluxo é equivalente ao lado direito de uma junção.
Corresponder várias linhas: se habilitado, uma linha com várias correspondências no fluxo primário retornará várias linhas. Caso contrário, apenas uma única linha será retornada com base na condição 'Match on'.
Corresponder em: visível apenas se a opção 'Corresponder a várias linhas' não estiver selecionada. Escolha se deseja corresponder em qualquer linha, na primeira partida ou na última partida. Qualquer linha é recomendada, pois executa o mais rápido. Se a primeira ou a última linha estiver selecionada, será necessário especificar as condições de classificação.
Condições de pesquisa: escolha em quais colunas corresponder. Se a condição de igualdade for cumprida, as linhas serão consideradas uma correspondência. Passe o mouse e selecione 'Coluna computada' para extrair um valor usando a linguagem de expressão de fluxo de dados.
Todas as colunas de ambos os fluxos são incluídas nos dados de saída. Para soltar colunas duplicadas ou indesejadas, adicione uma transformação select após a transformação de pesquisa. As colunas também podem ser descartadas ou renomeadas em uma transformação de coletor.
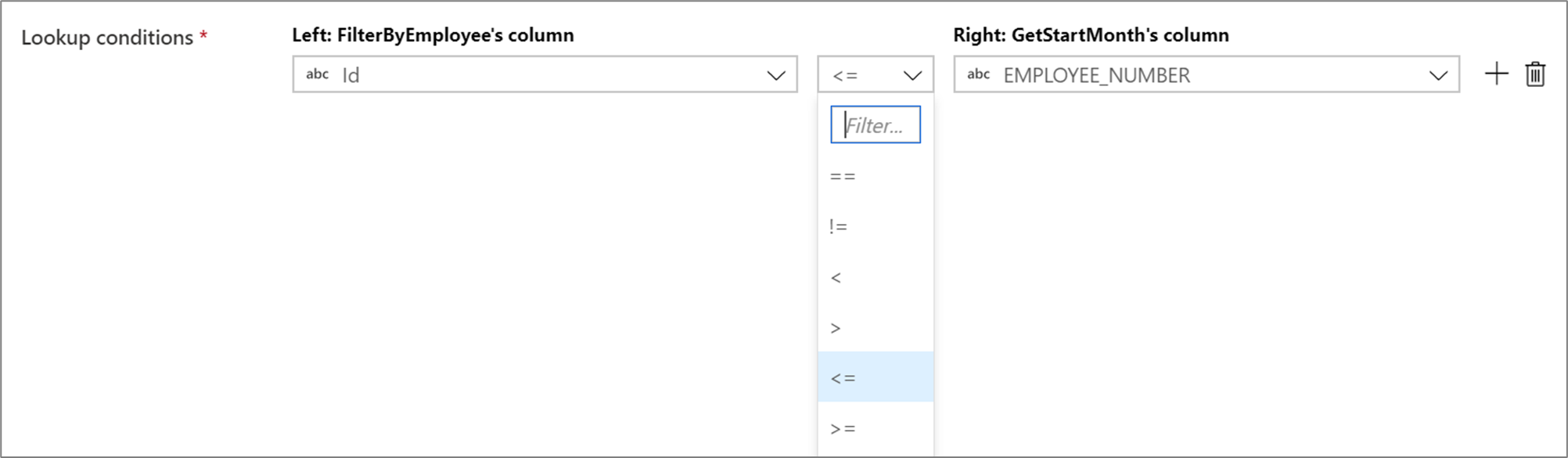
Adesões não equi
Para usar um operador condicional como não igual a (!=) ou maior que (>) em suas condições de pesquisa, altere a lista suspensa do operador entre as duas colunas. As junções não equi exigem que pelo menos um dos dois fluxos seja transmitido usando a transmissão fixa na guia Otimizar .
Analisando linhas correspondentes
Após a transformação da pesquisa, a função isMatch() pode ser usada para ver se a pesquisa corresponde a linhas individuais.
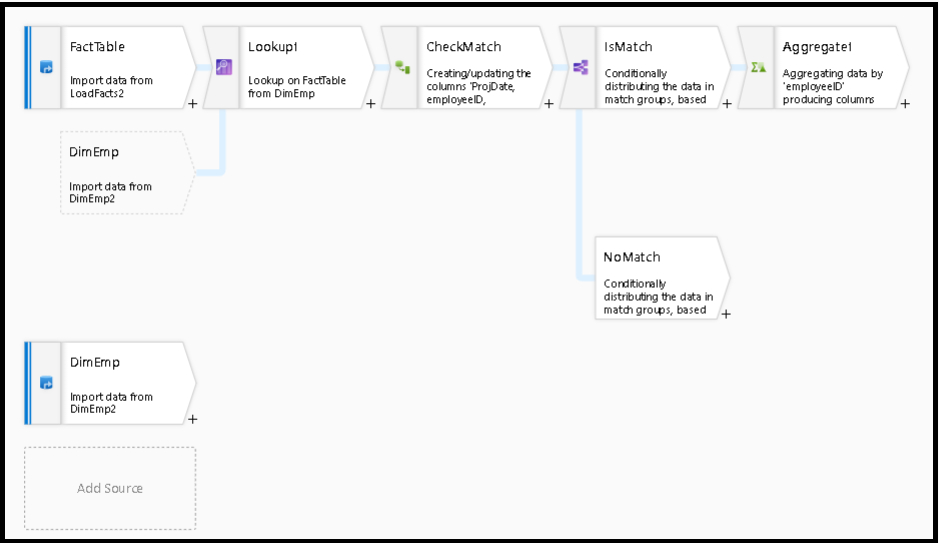
Um exemplo desse padrão é usar a transformação de divisão condicional para dividir a isMatch() função. No exemplo acima, as linhas correspondentes passam pelo fluxo superior e as linhas não correspondentes fluem pelo NoMatch fluxo.
Condições de pesquisa de teste
Ao testar a transformação de pesquisa com visualização de dados no modo de depuração, use um pequeno conjunto de dados conhecidos. Ao fazer a amostragem de linhas de um grande conjunto de dados, não é possível prever quais linhas e chaves serão lidas para teste. O resultado é não determinístico, o que significa que as suas condições de adesão podem não devolver quaisquer correspondências.
Otimização de transmissão
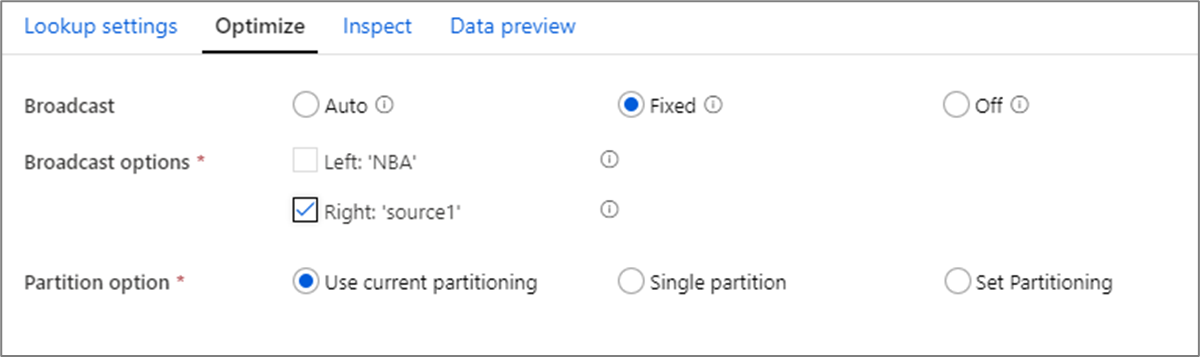
Na transformação de junções, pesquisas e existências, se um ou ambos os fluxos de dados se ajustarem à memória do nó de trabalho, você poderá otimizar o desempenho habilitando a Difusão. Por padrão, o mecanismo de ignição decidirá automaticamente se transmite ou não um lado. Para escolher manualmente o lado da transmissão, selecione Fixo.
Não é recomendável desativar a transmissão por meio da opção Desativado, a menos que suas junções estejam enfrentando erros de tempo limite.
Pesquisa em cache
Se você estiver fazendo várias pesquisas menores na mesma fonte, um coletor e uma pesquisa em cache talvez sejam um caso de uso melhor do que a transformação de pesquisa. Exemplos comuns em que um coletor de cache pode ser melhor são a pesquisa de um valor máximo em um armazenamento de dados e a correspondência de códigos de erro com um banco de dados de mensagens de erro. Para obter mais informações, saiba mais sobre coletores de cache e pesquisas em cache.
Script de fluxo de dados
Sintaxe
<leftStream>, <rightStream>
lookup(
<lookupConditionExpression>,
multiple: { true | false },
pickup: { 'first' | 'last' | 'any' }, ## Only required if false is selected for multiple
{ desc | asc }( <sortColumn>, { true | false }), ## Only required if 'first' or 'last' is selected. true/false determines whether to put nulls first
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <lookupTransformationName>
Exemplo
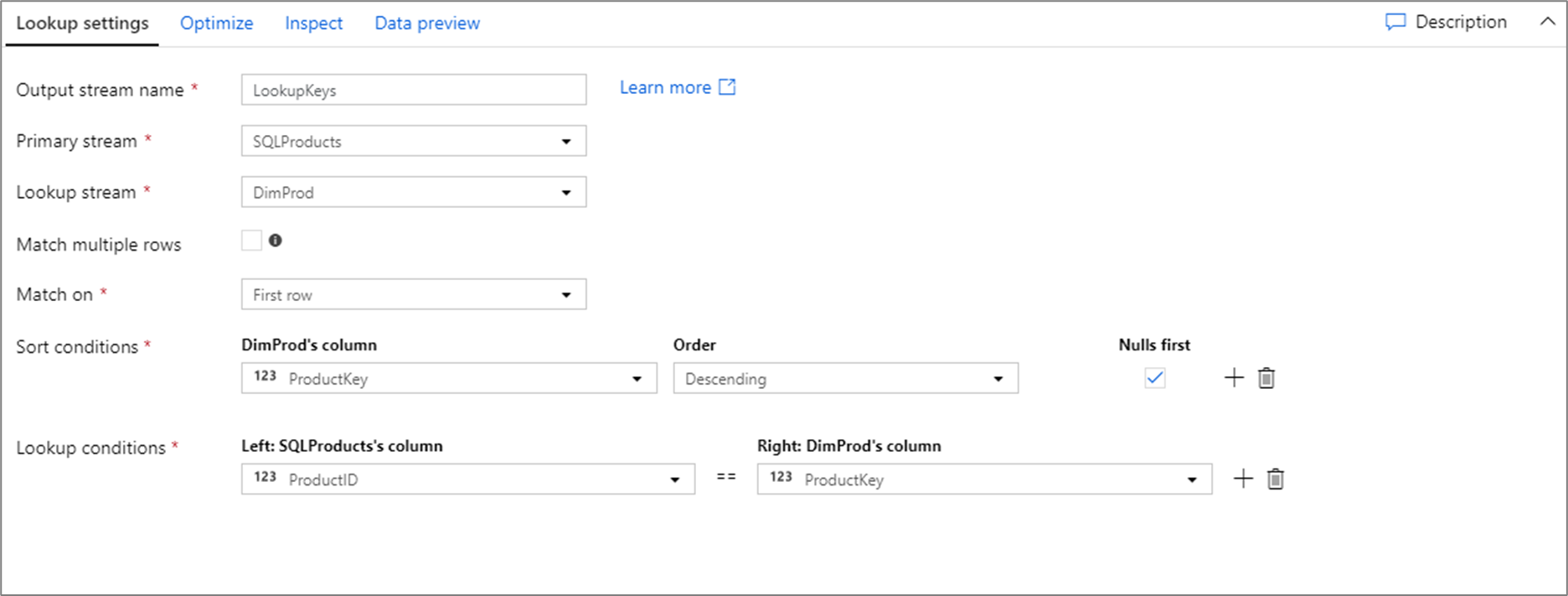
O script de fluxo de dados para a configuração de pesquisa acima está no trecho de código abaixo.
SQLProducts, DimProd lookup(ProductID == ProductKey,
multiple: false,
pickup: 'first',
asc(ProductKey, true),
broadcast: 'auto')~> LookupKeys
Conteúdos relacionados
- As transformações de junção e de existência absorvem várias entradas de fluxo
- Use uma transformação de divisão condicional com
isMatch()para dividir linhas em valores correspondentes e não correspondentes