Resolver Problemas de Desempenho da Atividade Copy
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve como solucionar problemas de desempenho de atividade de cópia no Azure Data Factory.
Depois de executar uma atividade de cópia, você pode coletar o resultado da execução e as estatísticas de desempenho no modo de exibição de monitoramento da atividade de cópia. A imagem seguinte mostra um exemplo.
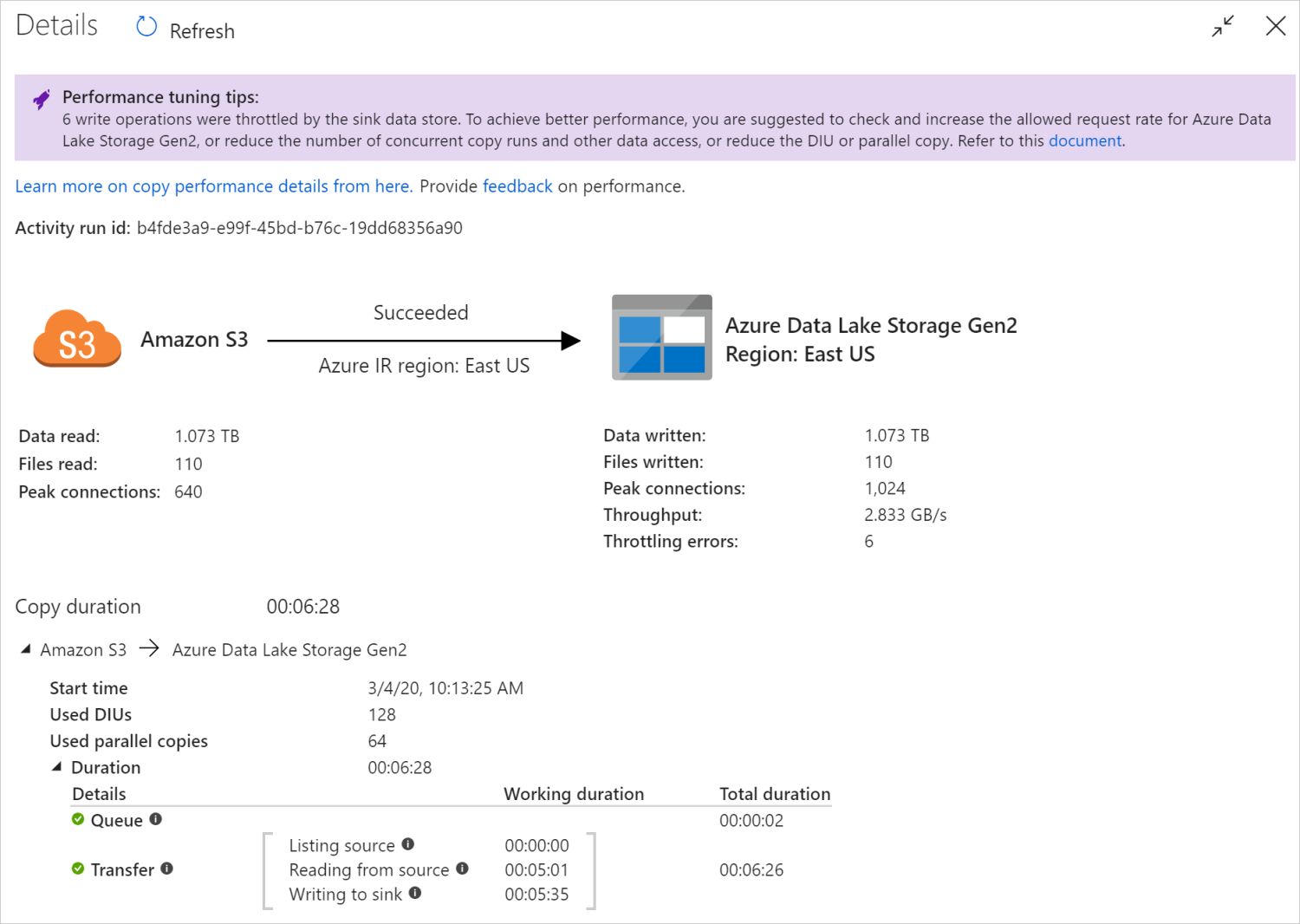
Sugestões de otimização do desempenho
Em alguns cenários, quando você executa uma atividade de cópia, você vê "Dicas de ajuste de desempenho" na parte superior, conforme mostrado na imagem anterior. As dicas informam o gargalo identificado pelo serviço para essa execução de cópia específica, juntamente com sugestões sobre como aumentar a taxa de transferência da cópia. Tente fazer a alteração recomendada e execute a cópia novamente.
Como referência, atualmente as dicas de ajuste de desempenho fornecem sugestões para os seguintes casos:
| Categoria | Sugestões de otimização do desempenho |
|---|---|
| Específico do armazenamento de dados | Carregando dados no Azure Synapse Analytics: sugira o uso da instrução PolyBase ou COPY se ela não for usada. |
| Copiando dados de/para o Banco de Dados SQL do Azure: quando a DTU estiver em alta utilização, sugira a atualização para a camada mais alta. | |
| Copiando dados de/para o Azure Cosmos DB: quando a RU estiver sob alta utilização, sugira a atualização para uma RU maior. | |
| Copiar dados do SAP Table: ao copiar uma grande quantidade de dados, sugira o uso da opção de partição do conector SAP para habilitar a carga paralela e aumentar o número máximo de partições. | |
| Ingerir dados do Amazon Redshift: sugira o uso do UNLOAD se ele não for usado. | |
| Limitação do armazenamento de dados | Se muitas operações de leitura/gravação forem limitadas pelo armazenamento de dados durante a cópia, sugira verificar e aumentar a taxa de solicitação permitida para o armazenamento de dados ou reduzir a carga de trabalho simultânea. |
| Integration runtime (Runtime de integração) | Se você usar um Self-hosted Integration Runtime (IR) e a atividade de cópia esperar muito tempo na fila até que o IR tenha recurso disponível para executar, sugira dimensionar/aumentar seu IR. |
| Se você usar um Tempo de Execução de Integração do Azure que esteja em uma região não ideal, resultando em leitura/gravação lenta, sugira configurar para usar uma RI em outra região. | |
| Tolerância a falhas | Se você configurar a tolerância a falhas e pular linhas incompatíveis resultar em desempenho lento, sugira garantir que os dados de origem e coletor sejam compatíveis. |
| Cópia faseada | Se a cópia em estágios estiver configurada, mas não for útil para o par fonte-coletor, sugira removê-la. |
| Retomar | Quando a atividade de cópia é retomada a partir do último ponto de falha, mas você altera a configuração da DIU após a execução original, observe que a nova configuração da DIU não entra em vigor. |
Compreender os detalhes de execução da atividade de cópia
Os detalhes e durações de execução na parte inferior da exibição de monitoramento da atividade de cópia descrevem os principais estágios pelos quais sua atividade de cópia passa (veja o exemplo no início deste artigo), o que é especialmente útil para solucionar problemas de desempenho da cópia. O gargalo da sua execução de cópia é aquele com maior duração. Consulte a tabela a seguir sobre a definição de cada estágio e saiba como Solucionar problemas de atividade de cópia no IR do Azure e Solucionar problemas de atividade de cópia no IR auto-hospedado com essas informações.
| Fase | Description |
|---|---|
| Queue | O tempo decorrido até que a atividade de cópia realmente comece no tempo de execução da integração. |
| Script de pré-cópia | O tempo decorrido entre o início da atividade de cópia no IR e a conclusão da execução do script de pré-cópia no armazenamento de dados do coletor. Aplique quando você configura o script de pré-cópia para coletores de banco de dados, por exemplo, ao gravar dados no Banco de Dados SQL do Azure, limpe antes de copiar novos dados. |
| Transferência | O tempo decorrido entre o final da etapa anterior e o IR transferindo todos os dados da fonte para o coletor. Observe que as subetapas em transferência são executadas em paralelo e algumas operações não são mostradas agora, por exemplo, analisando/gerando formato de arquivo. - Tempo até o primeiro byte: o tempo decorrido entre o final da etapa anterior e o momento em que o IR recebe o primeiro byte do armazenamento de dados de origem. Aplica-se a fontes não baseadas em arquivos. - Listando fonte: a quantidade de tempo gasto na enumeração de arquivos de origem ou partições de dados. Este último se aplica quando você configura opções de partição para fontes de banco de dados, por exemplo, ao copiar dados de bancos de dados como Oracle/SAP HANA/Teradata/Netezza/etc. - Leitura da fonte: a quantidade de tempo gasto na recuperação de dados do armazenamento de dados de origem. - Gravando para afundar: a quantidade de tempo gasto na gravação de dados para coletar armazenamento de dados. Observe que alguns conectores não têm essa métrica no momento, incluindo Azure AI Search, Azure Data Explorer, Azure Table storage, Oracle, SQL Server, Common Data Service, Dynamics 365, Dynamics CRM, Salesforce/Salesforce Service Cloud. |
Solucionar problemas de atividade de cópia no Azure IR
Siga as etapas de ajuste de desempenho para planejar e conduzir testes de desempenho para seu cenário.
Quando o desempenho da atividade de cópia não atender às suas expectativas, para solucionar problemas de atividade de cópia única em execução no Tempo de Execução de Integração do Azure, se você vir dicas de ajuste de desempenho exibidas no modo de exibição de monitoramento de cópia, aplique a sugestão e tente novamente. Caso contrário, entenda os detalhes de execução da atividade de cópia, verifique qual estágio tem a maior duração e aplique as orientações abaixo para aumentar o desempenho da cópia:
O "script de pré-cópia" experimentou longa duração: significa que o script de pré-cópia em execução no banco de dados do coletor leva muito tempo para ser concluído. Ajuste a lógica de script de pré-cópia especificada para melhorar o desempenho. Se precisar de mais ajuda para melhorar o script, entre em contato com a equipe do banco de dados.
"Transfer - Time to first byte" experimentou longa duração de trabalho: significa que sua consulta de origem leva muito tempo para retornar quaisquer dados. Verifique e otimize a consulta ou o servidor. Se precisar de mais ajuda, entre em contato com sua equipe de armazenamento de dados.
"Transfer - Listing source" experimentou longa duração de trabalho: significa que enumerar arquivos de origem ou partições de dados de banco de dados de origem é lento.
Ao copiar dados da fonte baseada em arquivo, se você usar o filtro curinga no caminho da pasta ou no nome do arquivo (
wildcardFolderPathouwildcardFileName), ou usar o filtro de tempo da última modificação do arquivo (modifiedDatetimeStartoumodifiedDatetimeEnd), observe que esse filtro resultaria na atividade de cópia listando todos os arquivos na pasta especificada para o lado do cliente e, em seguida, aplicar o filtro. Essa enumeração de arquivos pode se tornar o gargalo, especialmente quando apenas um pequeno conjunto de arquivos atende à regra de filtro.Verifique se você pode copiar arquivos com base no caminho ou nome do arquivo particionado datetime. Dessa forma, não traz ônus para listar o lado da fonte.
Verifique se você pode usar o filtro nativo do armazenamento de dados, especificamente "prefixo" para Amazon S3/Azure Blob storage/Azure Files e "listAfter/listBefore" para ADLS Gen1. Esses filtros são filtros do lado do servidor de armazenamento de dados e teriam melhor desempenho.
Considere dividir um único conjunto de dados grande em vários conjuntos de dados menores e permitir que esses trabalhos de cópia sejam executados simultaneamente em cada parte dos dados. Você pode fazer isso com Lookup/GetMetadata + ForEach + Copy. Consulte Copiar arquivos de vários contêineres ou Migrar dados do Amazon S3 para modelos de solução ADLS Gen2 como exemplo geral.
Verifique se o serviço relata algum erro de limitação na origem ou se o armazenamento de dados está em estado de alta utilização. Em caso afirmativo, reduza as cargas de trabalho no armazenamento de dados ou tente entrar em contato com o administrador do repositório de dados para aumentar o limite de limitação ou o recurso disponível.
Use o IR do Azure na mesma região ou perto da sua região de armazenamento de dados de origem.
"Transferência - leitura a partir da fonte" experimentou longa duração de trabalho:
Adote as melhores práticas de carregamento de dados específicas do conector, se aplicável. Por exemplo, ao copiar dados do Amazon Redshift, configure para usar o Redshift UNLOAD.
Verifique se o serviço relata algum erro de limitação na origem ou se o armazenamento de dados está sob alta utilização. Em caso afirmativo, reduza as cargas de trabalho no armazenamento de dados ou tente entrar em contato com o administrador do repositório de dados para aumentar o limite de limitação ou o recurso disponível.
Verifique a origem da cópia e o padrão do coletor:
Se o seu padrão de cópia suportar mais de quatro Unidades de Integração de Dados (DIUs) - consulte esta seção sobre detalhes, geralmente você pode tentar aumentar as DIUs para obter um melhor desempenho.
Caso contrário, considere dividir um único conjunto de dados de grandes dimensões em vários conjuntos de dados mais pequenos e permitir que esses trabalhos de cópia sejam executados simultaneamente, sendo que cada um aborda uma parte dos dados. Você pode fazer isso com Lookup/GetMetadata + ForEach + Copy. Consulte Copiar arquivos de vários contêineres, Migrar dados do Amazon S3 para o ADLS Gen2 ou Copiar em massa com modelos de solução de tabela de controle como exemplo geral.
Use o IR do Azure na mesma região ou perto da sua região de armazenamento de dados de origem.
"Transfer - writing to sink" experimentou longa duração de trabalho:
Adote as melhores práticas de carregamento de dados específicas do conector, se aplicável. Por exemplo, ao copiar dados para o Azure Synapse Analytics, use a instrução PolyBase ou COPY.
Verifique se o serviço relata algum erro de limitação no coletor ou se o armazenamento de dados está sob alta utilização. Em caso afirmativo, reduza as cargas de trabalho no armazenamento de dados ou tente entrar em contato com o administrador do repositório de dados para aumentar o limite de limitação ou o recurso disponível.
Verifique a origem da cópia e o padrão do coletor:
Se o seu padrão de cópia suportar mais de quatro Unidades de Integração de Dados (DIUs) - consulte esta seção sobre detalhes, geralmente você pode tentar aumentar as DIUs para obter um melhor desempenho.
Caso contrário, ajuste gradualmente as cópias paralelas. Muitas cópias paralelas podem até prejudicar o desempenho.
Use o IR do Azure na mesma região de armazenamento de dados do coletor ou perto dela.
Solucionar problemas de atividade de cópia no IR auto-hospedado
Siga as etapas de ajuste de desempenho para planejar e conduzir testes de desempenho para seu cenário.
Quando o desempenho da cópia não atender às suas expectativas, para solucionar problemas de atividade de cópia única em execução no Tempo de Execução de Integração do Azure, se você vir dicas de ajuste de desempenho exibidas no modo de exibição de monitoramento de cópia, aplique a sugestão e tente novamente. Caso contrário, entenda os detalhes de execução da atividade de cópia, verifique qual estágio tem a maior duração e aplique as orientações abaixo para aumentar o desempenho da cópia:
"Fila" experimentou longa duração: significa que a atividade de cópia espera muito tempo na fila até que seu IR auto-hospedado tenha recurso para executar. Verifique a capacidade e o uso de RI e aumente ou diminua a escala de acordo com sua carga de trabalho.
"Transfer - Time to first byte" experimentou longa duração de trabalho: significa que sua consulta de origem leva muito tempo para retornar quaisquer dados. Verifique e otimize a consulta ou o servidor. Se precisar de mais ajuda, entre em contato com sua equipe de armazenamento de dados.
"Transfer - Listing source" experimentou longa duração de trabalho: significa que enumerar arquivos de origem ou partições de dados de banco de dados de origem é lento.
Verifique se a máquina IR auto-hospedada tem baixa latência conectando-se ao armazenamento de dados de origem. Se sua fonte estiver no Azure, você poderá usar essa ferramenta para verificar a latência da máquina de IR auto-hospedada para a região do Azure, quanto menos, melhor.
Ao copiar dados da fonte baseada em arquivo, se você usar o filtro curinga no caminho da pasta ou no nome do arquivo (
wildcardFolderPathouwildcardFileName), ou usar o filtro de tempo da última modificação do arquivo (modifiedDatetimeStartoumodifiedDatetimeEnd), observe que esse filtro resultaria na atividade de cópia listando todos os arquivos na pasta especificada para o lado do cliente e, em seguida, aplicar o filtro. Essa enumeração de arquivos pode se tornar o gargalo, especialmente quando apenas um pequeno conjunto de arquivos atende à regra de filtro.Verifique se você pode copiar arquivos com base no caminho ou nome do arquivo particionado datetime. Dessa forma, não traz ônus para listar o lado da fonte.
Verifique se você pode usar o filtro nativo do armazenamento de dados, especificamente "prefixo" para Amazon S3/Azure Blob storage/Azure Files e "listAfter/listBefore" para ADLS Gen1. Esses filtros são filtros do lado do servidor de armazenamento de dados e teriam melhor desempenho.
Considere dividir um único conjunto de dados grande em vários conjuntos de dados menores e permitir que esses trabalhos de cópia sejam executados simultaneamente em cada parte dos dados. Você pode fazer isso com Lookup/GetMetadata + ForEach + Copy. Consulte Copiar arquivos de vários contêineres ou Migrar dados do Amazon S3 para modelos de solução ADLS Gen2 como exemplo geral.
Verifique se o serviço relata algum erro de limitação na origem ou se o armazenamento de dados está em estado de alta utilização. Em caso afirmativo, reduza as cargas de trabalho no armazenamento de dados ou tente entrar em contato com o administrador do repositório de dados para aumentar o limite de limitação ou o recurso disponível.
"Transferência - leitura a partir da fonte" experimentou longa duração de trabalho:
Verifique se a máquina IR auto-hospedada tem baixa latência conectando-se ao armazenamento de dados de origem. Se sua fonte estiver no Azure, você poderá usar essa ferramenta para verificar a latência da máquina de IR auto-hospedada para as regiões do Azure, quanto menos, melhor.
Verifique se a máquina de IR auto-hospedada tem largura de banda de entrada suficiente para ler e transferir os dados de forma eficiente. Se o armazenamento de dados de origem estiver no Azure, você poderá usar essa ferramenta para verificar a velocidade de download.
Verifique a tendência de uso de CPU e memória do IR auto-hospedado no portal do Azure -> sua fábrica de dados ou espaço de trabalho Synapse -> página de visão geral. Considere aumentar ou reduzir o IR se o uso da CPU for alto ou a memória disponível for baixa.
Adote as melhores práticas de carregamento de dados específicas do conector, se for aplicável. Por exemplo:
Ao copiar dados do Oracle, Netezza, Teradata, SAP HANA, SAP Table e SAP Open Hub), habilite as opções de partição de dados para copiar dados em paralelo.
Ao copiar dados do HDFS, configure para usar o DistCp.
Ao copiar dados do Amazon Redshift, configure para usar o Redshift UNLOAD.
Verifique se o serviço relata algum erro de limitação na origem ou se o armazenamento de dados está sob alta utilização. Em caso afirmativo, reduza as cargas de trabalho no armazenamento de dados ou tente entrar em contato com o administrador do repositório de dados para aumentar o limite de limitação ou o recurso disponível.
Verifique a origem da cópia e o padrão do coletor:
Se você copiar dados de armazenamentos de dados habilitados para opção de partição, considere ajustar gradualmente as cópias paralelas. Muitas cópias paralelas podem até prejudicar o desempenho.
Caso contrário, considere dividir um único conjunto de dados de grandes dimensões em vários conjuntos de dados mais pequenos e permitir que esses trabalhos de cópia sejam executados simultaneamente, sendo que cada um aborda uma parte dos dados. Você pode fazer isso com Lookup/GetMetadata + ForEach + Copy. Consulte Copiar arquivos de vários contêineres, Migrar dados do Amazon S3 para o ADLS Gen2 ou Copiar em massa com modelos de solução de tabela de controle como exemplo geral.
"Transfer - writing to sink" experimentou longa duração de trabalho:
Adote as melhores práticas de carregamento de dados específicas do conector, se aplicável. Por exemplo, ao copiar dados para o Azure Synapse Analytics, use a instrução PolyBase ou COPY.
Verifique se a máquina IR auto-hospedada tem baixa latência conectando-se ao armazenamento de dados do coletor. Se o coletor estiver no Azure, você poderá usar essa ferramenta para verificar a latência da máquina de IR auto-hospedada para a região do Azure, quanto menos, melhor.
Verifique se a máquina IR auto-hospedada tem largura de banda de saída suficiente para transferir e gravar os dados de forma eficiente. Se o armazenamento de dados do coletor estiver no Azure, você poderá usar essa ferramenta para verificar a velocidade de carregamento.
Verifique se a tendência de uso de CPU e memória do IR auto-hospedado no portal do Azure -> sua fábrica de dados ou espaço de trabalho Synapse -> página de visão geral. Considere aumentar ou reduzir o IR se o uso da CPU for alto ou a memória disponível for baixa.
Verifique se o serviço relata algum erro de limitação no coletor ou se o armazenamento de dados está sob alta utilização. Em caso afirmativo, reduza as cargas de trabalho no armazenamento de dados ou tente entrar em contato com o administrador do repositório de dados para aumentar o limite de limitação ou o recurso disponível.
Considere ajustar gradualmente as cópias paralelas. Muitas cópias paralelas podem até prejudicar o desempenho.
Desempenho do conector e IR
Esta seção explora alguns guias de solução de problemas de desempenho para determinado tipo de conector ou tempo de execução de integração.
O tempo de execução da atividade varia usando o IR do Azure vs o IR da rede virtual do Azure
O tempo de execução da atividade varia quando o conjunto de dados é baseado em diferentes Integration Runtime.
Sintomas: simplesmente alternar a lista suspensa Serviço Vinculado no conjunto de dados executa as mesmas atividades de pipeline, mas tem tempos de execução drasticamente diferentes. Quando o conjunto de dados é baseado no Managed Virtual Network Integration Runtime, leva mais tempo, em média, do que a execução quando baseada no Default Integration Runtime.
Causa: verificando os detalhes das execuções de pipeline, você pode ver que o pipeline lento está sendo executado no IR da rede virtual gerenciada (Rede Virtual) enquanto o normal está sendo executado no IR do Azure. Por design, o IR de rede virtual gerenciado leva mais tempo de fila do que o IR do Azure, pois não estamos reservando um nó de computação por instância de serviço, portanto, há um aquecimento para cada atividade de cópia iniciar, e isso ocorre principalmente na associação de rede virtual em vez do IR do Azure.
Baixo desempenho ao carregar dados no Banco de Dados SQL do Azure
Sintomas: a cópia de dados para o Banco de Dados SQL do Azure torna-se lenta.
Causa: a causa raiz do problema é acionada principalmente pelo afunilamento do lado do Banco de Dados SQL do Azure. Seguem-se algumas causas possíveis:
A camada do Banco de Dados SQL do Azure não é alta o suficiente.
O uso da DTU do Banco de Dados SQL do Azure está próximo de 100%. Você pode monitorar o desempenho e considerar atualizar a camada do Banco de Dados SQL do Azure.
Os índices não estão definidos corretamente. Remova todos os índices antes do carregamento de dados e recrie-os após a conclusão do carregamento.
WriteBatchSize não é grande o suficiente para se ajustar ao tamanho da linha do esquema. Tente ampliar o imóvel para o problema.
Em vez de inserção em massa, o procedimento armazenado está sendo usado, o que deve ter pior desempenho.
Tempo limite ou desempenho lento ao analisar arquivos grandes do Excel
Sintomas:
Quando você cria o conjunto de dados do Excel e importa o esquema de conexão/armazenamento, visualiza dados, lista ou atualiza planilhas, você pode encontrar um erro de tempo limite se o arquivo do Excel for grande em tamanho.
Quando você usa a atividade de cópia para copiar dados de arquivo grande do Excel (>= 100 MB) para outro armazenamento de dados, você pode enfrentar desempenho lento ou problema de OOM.
Causa:
Para operações como importação de esquema, visualização de dados e listagem de planilhas no conjunto de dados do Excel. O tempo limite é de 100 s e estático. Para arquivos grandes do Excel, essas operações podem não ser concluídas dentro do valor de tempo limite.
A atividade de cópia lê todo o arquivo do Excel na memória e, em seguida, localiza a planilha especificada e as células para ler os dados. Esse comportamento é devido ao SDK subjacente que o serviço usa.
Resolução:
Para importar o esquema, você pode gerar um arquivo de exemplo menor, que é um subconjunto do arquivo original, e escolher "importar esquema do arquivo de exemplo" em vez de "importar esquema da conexão/armazenamento".
Para listar a planilha, na lista suspensa da planilha, você pode selecionar "Editar" e inserir o nome/índice da planilha.
Para copiar um arquivo grande do Excel (>100 MB) para outra loja, você pode usar a fonte do Data Flow Excel, que lê e executa melhor o streaming de esportes.
A questão OOM de ler grandes arquivos JSON / Excel / XML
Sintomas: Quando você lê arquivos JSON/Excel/XML grandes, você encontra o problema de falta de memória (OOM) durante a execução da atividade.
Causa:
- Para arquivos XML grandes: O problema OOM de ler arquivos XML grandes é por design. A causa é que todo o arquivo XML deve ser lido na memória, pois é um único objeto, então o esquema é inferido e os dados são recuperados.
- Para arquivos grandes do Excel: A questão OOM de ler arquivos grandes do Excel é por design. A causa é que o SDK (POI/NPOI) usado deve ler todo o arquivo excel na memória, em seguida, inferir o esquema e obter dados.
- Para arquivos JSON grandes: O problema OOM de ler arquivos JSON grandes é por design quando o arquivo JSON é um único objeto.
Recomendação: Aplique uma das seguintes opções para resolver o problema.
- Opção-1: Registre um tempo de execução de integração auto-hospedado on-line com máquina poderosa (alta CPU/memória) para ler dados de seu arquivo grande através de sua atividade de cópia.
- Opção-2: Use memória otimizada e cluster de tamanho grande (por exemplo, 48 núcleos) para ler dados de seu arquivo grande através da atividade de fluxo de dados de mapeamento.
- Opção-3: Divida o arquivo grande em arquivos pequenos e, em seguida, use a atividade de fluxo de dados de cópia ou mapeamento para ler a pasta.
- Opção-4: Se você estiver preso ou encontrar o problema OOM durante a cópia da pasta XML/Excel/JSON, use a atividade foreach + atividade de fluxo de dados de cópia/mapeamento em seu pipeline para lidar com cada arquivo ou subpasta.
-
Opção-5: Outros:
- Para XML, use a atividade do Bloco de Anotações com cluster otimizado para memória para ler dados de arquivos se cada arquivo tiver o mesmo esquema. Atualmente, o Spark tem diferentes implementações para lidar com XML.
- Para JSON, use diferentes formulários de documento (por exemplo, Documento único, Documento por linha e Matriz de documentos) nas configurações JSON em Mapeamento da fonte de fluxo de dados. Se o conteúdo do arquivo JSON for Documento por linha, ele consome pouca memória.
Outras referências
Aqui estão as referências de monitoramento e ajuste de desempenho para alguns dos armazenamentos de dados suportados:
- Armazenamento de Blobs do Azure: metas de escalabilidade e desempenho para armazenamento de Blob e lista de verificação de desempenho e escalabilidade para armazenamento de Blob.
- Armazenamento de tabela do Azure: metas de escalabilidade e desempenho para armazenamento de tabela e lista de verificação de desempenho e escalabilidade para armazenamento de tabela.
- Banco de Dados SQL do Azure: você pode monitorar o desempenho e verificar a porcentagem da Unidade de Transação de Banco de Dados (DTU).
- Azure Synapse Analytics: sua capacidade é medida em DWUs (Data Warehouse Units). Consulte Gerenciar poder de computação no Azure Synapse Analytics (Visão geral).
- Azure Cosmos DB: Níveis de desempenho no Azure Cosmos DB.
- SQL Server: monitore e ajuste o desempenho.
- Servidor de arquivos local: ajuste de desempenho para servidores de arquivos.
Conteúdos relacionados
Veja os outros artigos da atividade de cópia: