Processo de indexação na Pesquisa do Windows
Este tópico descreve os três estágios do processo de indexação e os componentes primários envolvidos em cada um, explica o tempo da atividade de indexação e fornece algumas anotações para desenvolvedores de terceiros que desejam indexar seus armazenamentos de dados ou formatos de arquivo.
Este tópico é organizado da seguinte maneira:
- Visão geral
- Estágio 1: URLs de enfileiramento para indexação
- Estágio 2: URLs de rastreamento
- Estágio 3: atualizando o índice
- Como a indexação é agendada
- Notas aos Implementadores
- Tópicos relacionados
Visão geral
O Windows Search dá suporte à indexação de propriedades e conteúdo de arquivos de diferentes formatos de arquivo, como formatos .doc ou .jpeg e armazenamentos de dados, como o sistema de arquivos ou caixas de correio do Windows Outlook. Há dois tipos de índices: índices de valor que permitem filtragem e classificação por todo o valor de uma propriedade e índices invertidos que indexam palavras dentro de propriedades textuais ou conteúdo. Se você tiver um formato de arquivo ou armazenamento de dados personalizado, precisará entender como os índices da Pesquisa do Windows para obter seus itens indexados corretamente.
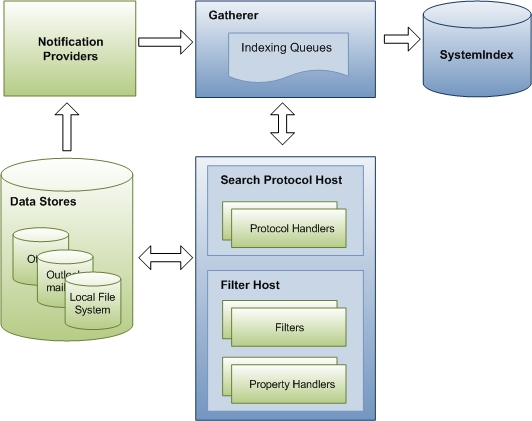
O processo de indexação ocorre em três estágios controlados por um componente do Windows Search chamado gatherer. No primeiro estágio, o coletor adiciona URLs às filas. As URLs identificam os itens a serem indexados e as filas são apenas listas priorizadas de URLs. No segundo estágio, o coletor coordena outros componentes do Windows Search e de terceiros para acessar os itens e coletar dados sobre eles. Por fim, no terceiro estágio, os dados coletados são adicionados ao índice.
O diagrama a seguir mostra os componentes principais e o fluxo de dados por meio do processo de indexação. Vários componentes estão envolvidos na coleta de dados para o índice. Algumas delas fazem parte da Pesquisa do Windows e outras vêm de aplicativos de terceiros. Se você tiver um armazenamento de dados personalizado ou um formato de arquivo, o Windows Search dependerá do manipulador de protocolo e do filtro para acessar URLs e emitir propriedades para indexação. Os componentes da Pesquisa do Windows são mostrados em azul e os componentes de terceiros são mostrados em verde.
Estágio 1: URLs de enfileiramento para indexação
No primeiro estágio de indexação, o coletor coleta informações sobre atualizações para armazenamentos de dados, compara essas informações com o escopo de rastreamento conhecido e, em seguida, cria uma fila de URLs para percorrer para coletar dados para o índice. Para fontes que não se baseiam em notificação, como unidades FAT, o coletor inicia periodicamente uma passagem completa do escopo de rastreamento para que os dados no índice sejam mantidos atualizados. Para fontes como o NTFS, há apenas um único rastreamento e todo o resto é tratado por notificações do Diário de Alterações da USN. Também não há rastreamento do Microsoft Outlook. O diagrama a seguir mostra uma exibição de alto nível do processo de enfileiramento para indexação sem rastreamento.
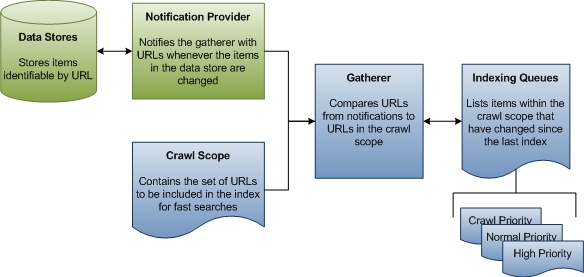
O restante desta seção explica como a Pesquisa do Windows determina quais URLs rastrear e define alguns termos importantes ao longo do caminho.
Escopo do Rastreamento O escopo do rastreamento é um conjunto de URLs que o Windows Search atravessa para coletar dados sobre itens que o usuário deseja indexar para pesquisas mais rápidas. A Pesquisa do Windows adiciona algumas URLs ao escopo do rastreamento por padrão, como caminhos para as pastas Documentos e Imagens dos usuários. Outras URLs podem ser adicionadas por aplicativos, usuários e Política de Grupo de terceiros. Por fim, os usuários e Política de Grupo podem excluir explicitamente URLs. A Pesquisa do Windows usa todas as URLs adicionadas e remove as URLs excluídas para determinar o escopo do rastreamento. Esse é o conjunto de trabalho de URLs do qual o coletor inicia seu trabalho.
Coletor O coletor é um componente da Pesquisa do Windows que coleta informações sobre URLs dentro do escopo do rastreamento e cria uma fila de URLs para o indexador rastrear. Quando um item no escopo de rastreamento é adicionado, excluído ou atualizado, o coletor é notificado pelo provedor de notificações do repositório de dados. Há um rastreamento inicial em que o coletor começa na raiz do escopo do rastreamento. A URL é passada para o manipulador de protocolo e, em seguida, para o IFilter apropriado. O filtro geralmente é uma enumeração de diretório que produz mais URLs. As notificações são o estado estável. Normalmente, cada armazenamento de dados tem seu próprio manipulador de protocolo que fornece essas notificações. Por exemplo, no sistema de arquivos local, o Diário de Alterações da USN atua como um provedor de notificações para todas as URLs no protocolo file://. Da mesma forma, o Microsoft Outlook atua como um provedor de notificações para todas as URLs no protocolo mapi://. Quando um usuário recebe, move ou exclui emails, o Outlook notifica o coletor do status alterado do email. A partir dessas notificações, o coletor cria filas de indexação de URLs para rastrear.
Filas de indexação As filas de indexação são listas de URLs que identificam itens que precisam ser indexados ou indexados novamente. O coletor compara as URLs recebidas dos provedores de notificações com as URLs no escopo do rastreamento. Cada URL de provedores de notificações que se enquadra no escopo de rastreamento é adicionada a uma fila que o coletor usa para priorizar quais URLs processar em seguida.
Há três filas: notificações de alta prioridade, notificações normais e rastreamentos periódicos. A fila de alta prioridade é para notificações que devem ser processadas imediatamente. Por exemplo, quando um usuário altera a propriedade de título de um item no Windows Explorer, a exibição do Windows Explorer precisa ser atualizada imediatamente após a alteração. A fila de notificação normal é para todas as notificações de alteração restantes. As filas de notificação são processadas antes da fila de rastreamento porque os itens alterados têm maior probabilidade de interessar a um usuário. O coletor acessa dados para as URLs em cada fila na ordem FIFO (primeiro a entrar e sair).
Para obter mais informações sobre priorização e APIs eventing introduzidas no Windows 7, consulte Indexando eventos de priorização e conjunto de linhas no Windows 7. Para obter mais informações sobre gerenciamento e notificações de escopo de rastreamento, consulte Fornecendo notificações de alteração e usando o Gerenciador de Escopo de Rastreamento.
Estágio 2: URLs de rastreamento
No segundo estágio de indexação, o coletor rasteja pelas filas, acessando armazenamentos de dados e recuperando fluxos de itens. Primeiro, o coletor localiza o manipulador de protocolo apropriado para cada URL. Em seguida, o coletor passa a URL para o manipulador de protocolo. O manipulador de protocolo acessa o item e passa os metadados do item de volta para o coletor. O coletor usa os metadados para identificar o filtro correto.
O diagrama a seguir mostra uma exibição de alto nível do processo de rastreamento de URL. Esse estágio inclui uma coordenação considerável e comunicação entre componentes.
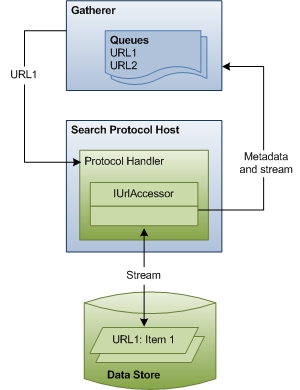
O restante desta seção descreve como a Pesquisa do Windows acessa itens para indexação e explica as funções de cada um dos componentes envolvidos.
Coletor No estágio 2, o estágio de rastreamento, o coletor processa as URLs nas filas, começando com a fila de alta prioridade. Cada URL é examinada para identificar seu protocolo. Em seguida, o coletor procura o manipulador de protocolo registrado para esse protocolo e o instancia no processo de host do protocolo de pesquisa.
Host do Protocolo de Pesquisa O host do protocolo de pesquisa é apenas um processo de host em caixa para manipuladores de protocolo. Normalmente, o Windows Search cria dois desses processos de host, um que é executado no contexto de segurança do sistema e outro executado no contexto de segurança do usuário. Essa separação garante que dados específicos de um usuário nunca sejam executados no contexto do sistema.
O Windows Search também usa o processo de host para isolar uma instância de um manipulador de protocolo de outros processos ou aplicativos. Dessa forma, nenhum aplicativo externo pode acessar essa instância específica do manipulador de protocolo e, se o manipulador de protocolo falhar inesperadamente, somente o processo de indexação será afetado. Como o processo de host executa código de terceiros (manipuladores de protocolo), o Windows Search recicla periodicamente o processo para minimizar o tempo que um ataque bem-sucedido tem para explorar informações no processo. Além disso, o host do protocolo de pesquisa não afeta o rastreamento de URLs ou a indexação de itens.
Manipuladores de protocolo Os manipuladores de protocolo fornecem acesso a itens em um armazenamento de dados usando o protocolo do repositório de dados. Por exemplo, o manipulador de protocolo NTFS fornece acesso a arquivos em uma unidade local usando o protocolo file://. O manipulador de protocolo sabe como percorrer o armazenamento de dados, identificar itens novos ou atualizados e notificar o coletor. Em seguida, quando o rastreamento começa, o manipulador de protocolo fornece um objeto IUrlAccessor ao coletor para associar ao fluxo subjacente do item e retornar metadados de item, como restrições de segurança e hora da última modificação.
Observação
Manipuladores de protocolo não são componentes do Windows Search; são componentes do protocolo específico e do armazenamento de dados que foram projetados para acessar. Se você tiver um armazenamento de dados personalizado que deseja indexar, será necessário implementar um manipulador de protocolo. Para obter mais informações sobre manipuladores de protocolo e como implementar um, consulte Desenvolvendo manipuladores de protocolo.
Metadados e Stream Usando metadados retornados pelo objeto IUrlAccessor do manipulador de protocolo, o coletor identifica o filtro correto para a URL. O coletor analisa a extensão de nome de arquivo do item e procura o filtro registrado para essa extensão. Se o coletor não conseguir encontrar um filtro, o Windows Search usará os metadados para derivar um conjunto mínimo de informações de propriedade do sistema (como System.ItemName) e atualizará o índice. Caso contrário, se o coletor encontrar o filtro, o terceiro estágio de indexação será iniciado.
Estágio 3: atualizando o índice
No terceiro estágio de indexação, o coletor cria uma instância do filtro correto para a URL e inicializa o filtro com o fluxo do objeto IUrlAccessor . Em seguida, o filtro acessa o item e retorna conteúdo para o índice. Se você tiver um formato de arquivo personalizado, o Windows Search dependerá do filtro para acessar URLs e emitir conteúdo e propriedades para indexação.
O diagrama a seguir mostra uma exibição de alto nível do processo de acesso a dados. Esse estágio inclui uma coordenação considerável e comunicação entre componentes.
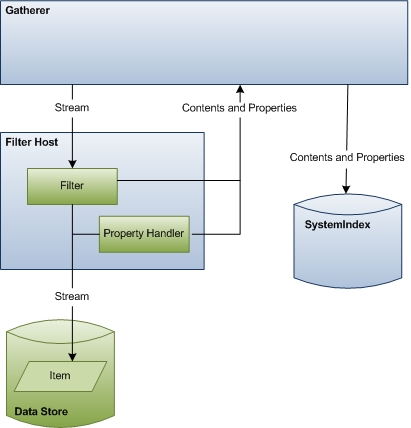
O restante desta seção descreve como o Windows Search acessa dados de item para indexação e explica as funções de cada um dos componentes envolvidos.
Coletor No início dessa fase, a função do coletor é instanciar o filtro correto para o item e passá-lo pelo fluxo de item. No final desta fase, o coletor usa o conteúdo e as propriedades emitidas pelo manipulador de filtro e propriedade e atualiza o índice.
Filtrar Host O host de filtro é apenas um processo de host para filtros e manipuladores de propriedades e serve a uma finalidade semelhante ao host do protocolo de pesquisa. O processo de host isola filtros e manipuladores de propriedades do restante do sistema pelos mesmos motivos de segurança e estabilidade que o host de protocolo de pesquisa processa manipuladores de protocolo isolados. O processo de host é executado com direitos mínimos (ele não pode sequer acessar o sistema de arquivos) e ocasionalmente é reciclado para proteger contra ataques de segurança. O Windows Search também monitora o uso de recursos para que, se um filtro consumir muitos recursos, o processo de host seja reciclado.
Filtros Os filtros são componentes críticos no processo de indexação que emitem informações de item para o coletor. Os filtros são nomeados após a interface principal usada em sua implementação, a interface IFilter e, consequentemente, às vezes são chamados de IFilters. Há dois tipos de filtros: um que interage com itens individuais, como arquivos, e outro que interage com contêineres como pastas. Ambos fornecem dados para o índice.
Usando metadados retornados pelo objeto IUrlAccessor do manipulador de protocolo, o coletor identifica o filtro correto para uma URL específica e o passa para o fluxo. O coletor identifica o filtro correto por meio de um manipulador de protocolo ou pela extensão de nome de arquivo, tipo MIME ou CLSID (identificador de classe). Se a URL apontar para um contêiner, o filtro emitirá propriedades para o contêiner e enumerará os itens no contêiner (URLs filho). Se a URL apontar para um item, o filtro retornará o conteúdo textual, se houver uma leitura das propriedades e for mais complexo do que os manipuladores de propriedade. Em geral, recomendamos que os filtros emitam conteúdo do item enquanto os manipuladores de propriedade emitem propriedades de item. No entanto, se o filtro precisar trabalhar com aplicativos mais antigos que não reconhecem manipuladores de propriedade, você também poderá implementar o filtro para emitir propriedades.
Observação
Os filtros não são componentes do Windows Search; são componentes relacionados ao formato de arquivo ou contêiner específico que foram projetados para acessar. Para obter mais informações sobre filtros e como implementar um para um formato de arquivo ou contêiner personalizado, consulte Práticas recomendadas para criar manipuladores de filtro na Pesquisa do Windows.
A tabela a seguir lista os resultados que o coletor recebe de um filtro (IFilter) e um manipulador de propriedades (IPropertyStore) durante o processo de indexação.
| Ifilter | Ipropertystore | |
|---|---|---|
| Permitir gravação | Não | Sim |
| Misturar conteúdo e propriedades | Sim | Não |
| Multilingue | Sim | Não |
| Emitir links | Sim | Não |
| MIME | Sim | Não |
| Limites de texto | Frase, parágrafo, capítulo | Nenhum |
| Cliente/servidor | Ambos | Cliente |
| Implementação | Complex | Simples |
Manipuladores de propriedades Manipuladores de propriedade são componentes que leem e gravam propriedades para um formato de arquivo específico. Eles acessam itens e emitem propriedades para o coletor da mesma forma que os filtros fazem para o conteúdo. Manipuladores de propriedade são mais fáceis de implementar do que filtros. Se um formato de arquivo baseado em texto for muito simples ou se espera-se que os arquivos sejam muito pequenos, o manipulador de propriedades poderá emitir propriedades e conteúdo.
Observação
Manipuladores de propriedade não são componentes do Windows Search; são componentes relacionados ao formato de arquivo específico que foram projetados para acessar. Para obter mais informações sobre manipuladores de propriedades e como implementar um para um formato de arquivo personalizado, consulte Desenvolvendo manipuladores de propriedades para o Windows Search.
Propriedades O Windows Search fornece um sistema de propriedades que inclui uma grande biblioteca de propriedades. Qualquer propriedade pode aparecer em qualquer item, conforme definido pelo manipulador de filtro ou propriedade. Se você tiver um formato de arquivo personalizado, poderá mapear as propriedades do formato de arquivo para essas propriedades do sistema e criar novas propriedades personalizadas. Quando seu filtro ou manipulador de propriedades emite essas propriedades, o coletor atualiza o índice para que os usuários possam pesquisar usando suas propriedades. Para obter mais informações sobre como criar e registrar propriedades personalizadas para um formato de arquivo, consulte Sistema de Propriedades.
SystemIndex O índice, chamado SystemIndex, armazena dados indexados e é composto por um repositório de propriedades e índices sobre as propriedades e o conteúdo das propriedades do item e um índice invertido para conteúdo textual e propriedades. Depois que o coletor atualizar o índice, o índice poderá ser consultado pela Pesquisa do Windows e outros aplicativos. Para obter mais informações sobre maneiras de consultar o índice, consulte Consultando o índice programaticamente.
Observação
Lembre-se de que, ao registrar novamente um esquema, as alterações feitas em atributos de propriedades definidas anteriormente podem não ser respeitadas pelo indexador. A solução é recriar o índice ou introduzir novas propriedades que refletem as alterações em vez de atualizar as antigas (não recomendadas). Para obter mais informações, consulte Observação aos implementadores em Visão geral do sistema de propriedades.
Como a indexação é agendada
Quando a Pesquisa do Windows é instalada pela primeira vez, ela executa uma indexação completa do escopo de rastreamento, pausando durante períodos de alta E/S e atividade do usuário. O escopo de rastreamento padrão consiste nos locais de biblioteca padrão, como Documentos, Músicas, Imagens e Vídeos. As notificações são processadas antes mesmo da conclusão do rastreamento inicial. Ocasionalmente, o coletor rastreia as URLs do escopo completo do rastreamento. Esses rastreamentos completos garantem que os dados no índice sejam atualizados. Por exemplo, se um provedor de notificação não enviar notificações ou se o serviço Pesquisa do Windows for encerrado inesperadamente, o coletor não terá conhecimento de itens novos ou alterados e não indexaria esses itens. Há dois tipos de fontes: somente notificação e notificação habilitadas. Em ambas as fontes, o coletor inicialmente rastreia o índice. Após o rastreamento inicial, as fontes somente de notificação nunca mais farão um rastreamento completo, a menos que haja uma falha, como o Diário de Alterações do USN que está rolando. As fontes habilitadas para notificação fazem um rastreamento incremental quando o indexador é iniciado, mas escutam as notificações durante a execução. NTFS e Microsoft Outlook são somente notificação. O Explorer da Internet e o FAT estão habilitados para notificação.
Notas aos Implementadores
A qualidade dos dados no índice e a eficiência do processo de indexação dependem em grande parte da implementação do filtro e do manipulador de propriedades. Como o filtro é chamado sempre que uma URL identifica o formato do arquivo, o processo de indexação pode diminuir drasticamente se o filtro for ineficiente. Se o manipulador de propriedades não mapear corretamente todas as propriedades do arquivo para as propriedades do sistema ou não emitir corretamente essas propriedades, os dados no índice estarão incorretos e pesquisas posteriores por essas propriedades retornarão resultados incorretos. Se o filtro ou o manipulador de propriedades falhar, o indexador não poderá indexar dados.
Aplicativos e processos diferentes do Windows Search dependem de manipuladores de protocolo, filtros e manipuladores de propriedades. Suas implementações podem afetar esses aplicativos de maneiras que talvez você não espere. O Guia de Desenvolvimento de Pesquisa do Windows fornece conselhos sobre opções de design e sobre como testar cada um desses componentes.
Tópicos relacionados
Indexação, consulta e notificações na Pesquisa do Windows
Processo de consulta na Pesquisa do Windows