Instalar e habilitar a Eliminação de Duplicação de Dados
Este tópico explica como instalar a Eliminação de Duplicação de Dados, avaliar cargas de trabalho para eliminação de duplicação e habilitar a Eliminação de Duplicação de Dados em volumes específicos.
Observação
Se você estiver planejando executar a Eliminação de Duplicação de Dados em um Cluster de Failover, cada nó no cluster deve ter a função de servidor Eliminação de Duplicação de Dados instalada.
Instalar a Eliminação de Duplicação de Dados
Importante
O KB4025334 contém um pacote cumulativo de correções para Eliminação de Duplicação de Dados, incluindo correções de confiabilidade importantes; é altamente recomendável a instalação desse pacote durante o uso da Eliminação de Duplicação de Dados com o Windows Server 2016.
Instalar a Eliminação de Duplicação de Dados usando o Gerenciador do Servidor
- No assistente Adicionar Funções e Recursos, selecione Funções de Servidor e Eliminação de Duplicação de Dados.
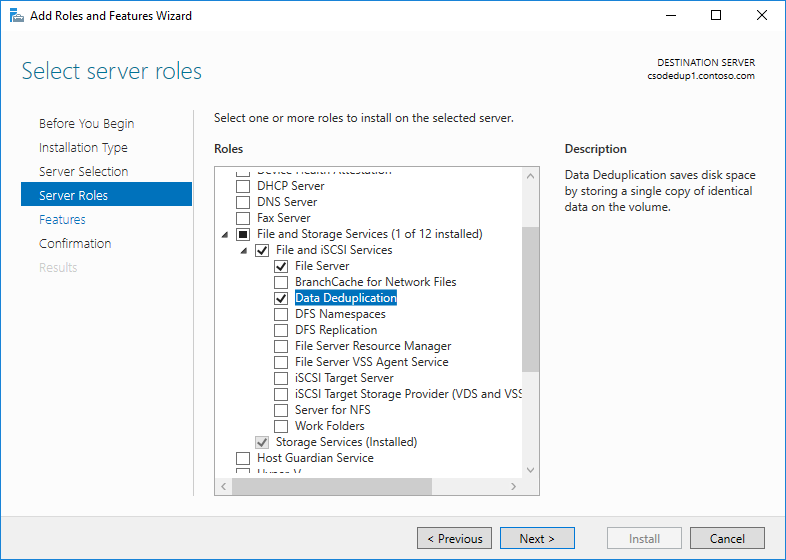
- Clique em Avançar até o botão Instalar ficar ativo e, em seguida, clique em Instalar.
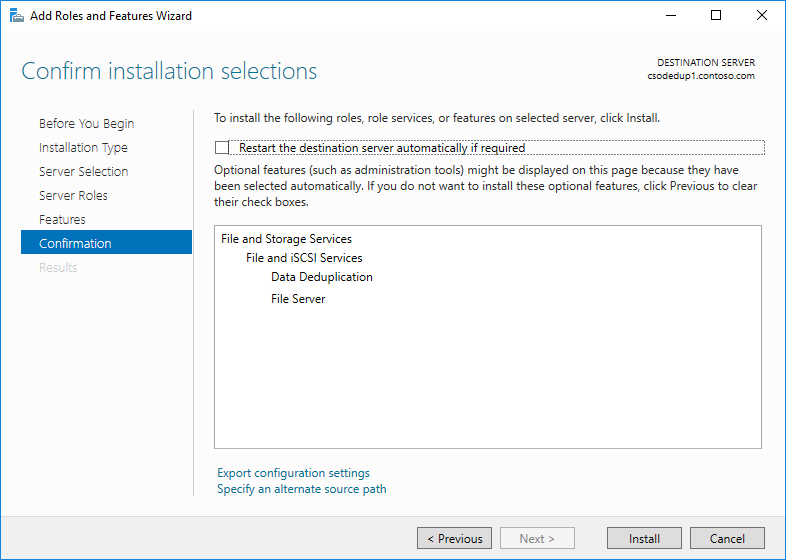
Instalar a Eliminação de Duplicação de Dados usando o PowerShell
Para instalar a Eliminação de Duplicação de Dados, execute o seguinte comando do PowerShell como administrador: Install-WindowsFeature -Name FS-Data-Deduplication
Para instalar a Eliminação de Duplicação de Dados:
Em um servidor com o Windows Server 2016 ou posterior ou em um computador Windows com as RSAT (Ferramentas de Administração de Servidor Remoto) instaladas, instale a Eliminação de Duplicação de Dados com uma referência explícita ao nome do servidor (substitua 'MyServer' pelo nome real da instância do servidor):
Install-WindowsFeature -ComputerName <MyServer> -Name FS-Data-DeduplicationOu
Conecte-se remotamente à instância do servidor com o PowerShell remoto e instale a Eliminação de Duplicação de Dados usando o DISM:
Enter-PSSession -ComputerName MyServer dism /online /enable-feature /featurename:dedup-core /all
Habilite a Eliminação de Duplicação de Dados
Determine quais cargas de trabalho são candidatas à Eliminação de Duplicação de Dados
A Eliminação de Duplicação de Dados pode minimizar de maneira eficaz os custos de consumo de dados de um aplicativo para servidores, reduzindo a quantidade de espaço em disco consumida por dados redundantes. Antes de habilitar a eliminação de duplicação, é importante entender as características da sua carga de trabalho para garantir que você obtenha o máximo desempenho de seu armazenamento. Há duas classes de cargas de trabalho a considerar:
- Cargas de trabalho recomendadas, que comprovadamente têm ambos os conjuntos de dados que se beneficiam altamente da eliminação de duplicação e têm padrões de consumo de recursos que são compatíveis com o modelo de pós-processamento da Eliminação de Duplicação de Dados. Recomendamos que você sempre habilite a Eliminação de Duplicação de Dados nessas cargas de trabalho:
- Os GPFS (Servidores de arquivos de finalidade geral) que atendem a compartilhamentos, como compartilhamentos de equipe, pastas pessoais de usuários, pastas de trabalho e compartilhamentos de desenvolvimento de software.
- Servidores VDI (Virtual Desktop Infrastructure).
- Aplicativos de backup virtualizado, como Microsoft DPM (Data Protection Manager).
- Cargas de trabalho que podem se beneficiar de eliminação de duplicação, mas nem sempre são boas candidatas para eliminação de duplicação. Por exemplo, as cargas de trabalho a seguir poderiam funcionar bem com eliminação de duplicação, mas primeiro você deve avaliar os benefícios da eliminação de duplicação:
- Hosts Hyper-V de finalidade geral
- Servidores SQL
- Servidores de linha de negócios (LOB)
Avaliar cargas de trabalho para a Eliminação de Duplicação de Dados
Importante
Se você estiver executando uma carga de trabalho recomendada, poderá ignorar esta seção e ir para Habilitar a Eliminação de Duplicação de Dados para sua carga de trabalho.
Para determinar se uma carga de trabalho funciona bem com eliminação de duplicação, responda às perguntas a seguir. Se não tiver certeza sobre uma carga de trabalho, faça uma implantação piloto da Eliminação de Duplicação de Dados em um conjunto de dados de teste para sua carga de trabalho para verificar o desempenho.
O conjunto de dados da minha carga de trabalho tem duplicação suficiente para se beneficiar de eliminação de duplicação? Antes de habilitar a Eliminação de Duplicação de Dados para uma carga de trabalho, investigue quanta duplicação o conjunto de dados de sua carga de trabalho tem usando a ferramenta de avaliação de economias de Eliminação de Duplicação de Dados, ou DDPEval. Depois de instalar a Eliminação de Duplicação de Dados, você encontra essa ferramenta em
C:\Windows\System32\DDPEval.exe. O DDPEval pode avaliar o potencial para a otimização em relação a volumes conectados diretamente (incluindo unidades locais ou Volumes Compartilhados Clusterizados) e compartilhamentos de rede mapeados ou não mapeados.Executar DDPEval.exe retornará uma saída semelhante à seguinte:
Data Deduplication Savings Evaluation Tool Copyright 2011-2012 Microsoft Corporation. All Rights Reserved. Evaluated folder: E:\Test Processed files: 34 Processed files size: 12.03MB Optimized files size: 4.02MB Space savings: 8.01MB Space savings percent: 66 Optimized files size (no compression): 11.47MB Space savings (no compression): 571.53KB Space savings percent (no compression): 4 Files with duplication: 2 Files excluded by policy: 20 Files excluded by error: 0Qual é a aparência dos padrões de E/S da minha carga de trabalho para seus conjunto de dados? Qual o desempenho para minha carga de trabalho? A Eliminação de Duplicação de Dados otimiza os arquivos como um trabalho periódico em vez de quando o arquivo é gravado em disco. Em decorrência disso, é importante examinar os padrões de leitura esperados da carga de trabalho para o volume com eliminação de duplicação. Como a Eliminação de Duplicação de Dados move o conteúdo do arquivo para o repositório de partes e tenta organizá-lo por arquivo o máximo possível, as operações de leitura apresentam o melhor desempenho quando são aplicadas em intervalos sequenciais de um arquivo.
As cargas de trabalho semelhantes a banco de dados normalmente têm padrões de leitura mais aleatórios do que padrões de leitura sequenciais, porque os bancos de dados geralmente não asseguram que o layout de banco de dados seja ideal para todas as consultas possíveis que podem ser executadas. Como as seções do repositório de partes podem existir em todo o volume, acessar os intervalos de dados no repositório de partes para as consultas de banco de dados pode introduzir latência adicional. As cargas de trabalho de alto desempenho são especialmente sensíveis à latência adicional, mas outras cargas de trabalho semelhantes a banco de dados podem não ser.
Observação
Essas questões aplicam-se principalmente a cargas de trabalho de armazenamento nos volumes compostos de mídia de armazenamento rotacional tradicional (também conhecida como unidades de disco rígido ou HDDs). Toda a infraestrutura de armazenamento em flash (também conhecido como unidades de estado sólido ou SSDs) é menos afetada por padrões de E/S aleatórios, porque uma das propriedades da mídia flash é igual ao tempo de acesso a todos os locais na mídia. Portanto, a eliminação de duplicação não apresentará a mesma quantidade de latência para leituras em conjuntos de dados de uma carga de trabalho armazenados em todas as mídias flash, como faria em mídias de armazenamento rotacional tradicionais.
Quais são os requisitos de recursos da minha carga de trabalho no servidor? Como a Eliminação de Duplicação de Dados usa um modelo de pós-processamento, a Eliminação de Duplicação de Dados precisa periodicamente ter recursos de sistema suficientes para concluir sua otimização e outros trabalhos. Isso significa que as cargas de trabalho que têm tempo ocioso, como à noite ou nos fins de semana, são excelentes candidatas à eliminação de duplicação e as cargas de trabalho executadas o dia todo, todos os dias podem não ser. As cargas de trabalho que não têm tempo ocioso poderão ainda ser boas candidatas para eliminação de duplicação se a carga de trabalho não tiver requisitos altos de recursos no servidor.
Habilite a Eliminação de Duplicação de Dados
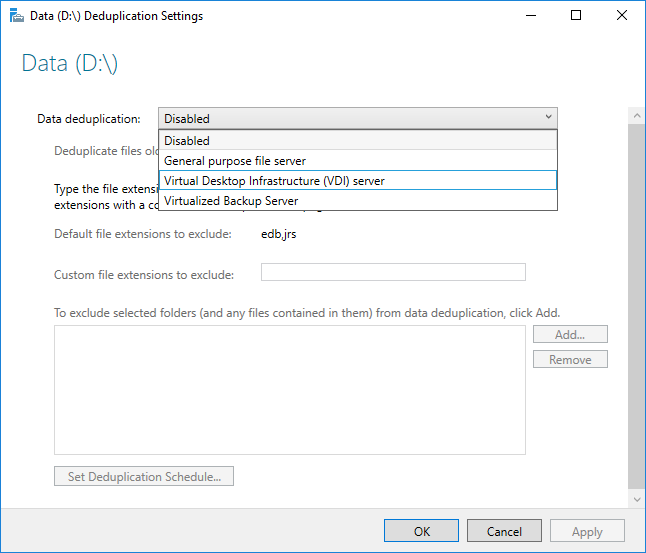
Antes de habilitar a Eliminação de Duplicação de Dados, você deverá escolher o Tipo de Uso que mais se assemelha a sua carga de trabalho. Há três tipos de uso na Eliminação de Duplicação de Dados.
- Padrão – ajustado especificamente para o servidor de arquivos de finalidade geral
- Hyper-V – ajustado especificamente para servidores VDI
- Backup – ajustado especificamente para aplicativos de backup virtualizado, como Microsoft DPM
Habilitar a Eliminação de Duplicação de Dados usando o Gerenciador do Servidor
- Selecione Serviços de Arquivo e Armazenamento no Gerenciador do Servidor.
- Selecione Volumes em Serviços de Arquivo e Armazenamento.
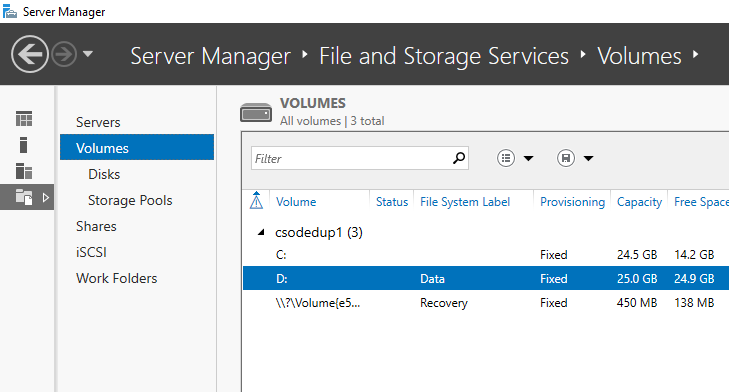
- Clique com o botão direito do mouse no volume desejado e selecione Configurar Eliminação de Duplicação de Dados.
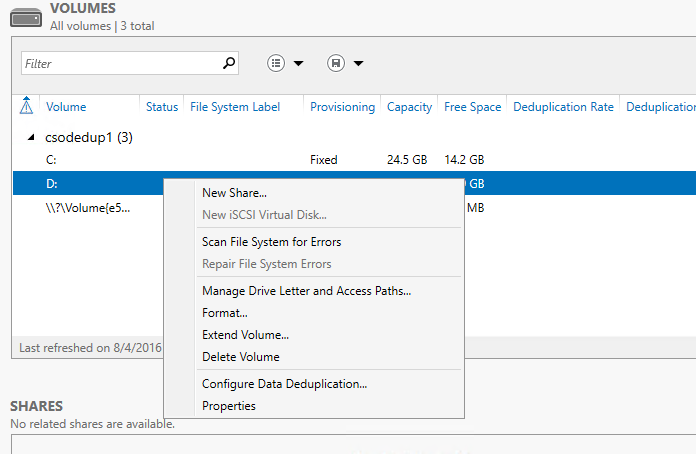
- Selecione o Tipo de Uso desejado na caixa suspensa e selecione OK.
- Se estiver executando uma carga de trabalho recomendada, você já terminou. Para outras cargas de trabalho, consulte Outras considerações.
Observação
Você pode encontrar mais informações sobre a exclusão de extensões de arquivos ou pastas e a seleção do plano de eliminação de duplicação, incluindo o motivo pelo qual você desejaria fazer isso, em Configuring Data Deduplication (Configurando a Eliminação de Duplicação de Dados).
Habilitar a Eliminação de Duplicação de Dados usando o PowerShell
Com um contexto de administrador, execute o seguinte comando do PowerShell:
Enable-DedupVolume -Volume <Volume-Path> -UsageType <Selected-Usage-Type>Se estiver executando uma carga de trabalho recomendada, você já terminou. Para outras cargas de trabalho, consulte Outras considerações.
Observação
Os cmdlets do PowerShell da Eliminação de Duplicação de Dados, incluindo Enable-DedupVolume, podem ser executados remotamente acrescentando o parâmetro -CimSession com uma sessão de CIM. Isso é particularmente útil para executar os cmdlets do PowerShell para Eliminação de Duplicação de Dados remotamente em uma instância do servidor. Para criar uma nova sessão do CIM, execute New-CimSession.
Outras considerações
Importante
Se você estiver executando uma carga de trabalho recomendada, poderá ignorar esta seção.
- Os tipos de uso da Eliminação de Duplicação de Dados oferecem padrões pertinentes para cargas de trabalho recomendadas, mas também fornecem um bom ponto de partida para todas as cargas de trabalho. Para cargas de trabalho diferentes das recomendadas, é possível alterar as Configurações avançadas de Eliminação de Duplicação de Dados para melhorar o desempenho da eliminação de duplicação.
- Se sua carga de trabalho tiver requisitos altos de recursos no seu servidor, os trabalhos de Eliminação de Duplicação de Dados devem ser agendados para execução durante os tempos ociosos esperados para essa carga de trabalho. Isso é particularmente importante ao executar a eliminação de duplicação em um host hiperconvergente, porque executar a Eliminação de Duplicação de Dados durante as horas de trabalho previstas pode enfraquecer as VMs.
- Se sua carga de trabalho não tiver requisitos altos de recursos, ou se for mais importante que os trabalhos de otimização sejam concluídos do que as solicitações de carga de trabalho sejam atendidas, a memória, a CPU e a prioridade dos trabalhos de Eliminação de Duplicação de Dados poderão ser ajustadas.
Perguntas frequentes (FAQ)
Quero executar a Eliminação de Duplicação de Dados no conjunto de dados para a carga de trabalho X. Há suporte para isso? Além das cargas de trabalho conhecidas por não terem interoperabilidade com a Eliminação de Duplicação de Dados, damos suporte total para a integridade dos dados da Eliminação de Duplicação de Dados com qualquer carga de trabalho. Também há suporte da Microsoft para o desempenho das cargas de trabalho recomendadas. O desempenho de outras cargas de trabalho depende muito do que elas estão fazendo no seu servidor. Você deve determinar quais impactos no desempenho a Eliminação de Duplicação de Dados tem na sua carga de trabalho e se isso é aceitável para essa carga de trabalho.
Quais são os requisitos de dimensionamento do volume para volumes com eliminação de duplicação? No Windows Server 2012 e no Windows Server 2012 R2, os volumes tinham que ser dimensionados com cuidado para assegurar que a Eliminação de Duplicação de Dados pudesse acompanhar a variação no volume. Normalmente, isso significava que o tamanho máximo médio de um volume com eliminação de duplicação para uma carga de trabalho de variação alta era 1 a 2 TB e o tamanho recomendado máximo absoluto era 10 TB. No Windows Server 2016, essas limitações foram removidas. Para obter mais informações, consulte Novidades na Eliminação de Duplicação de Dados.
É necessário modificar o agendamento ou outras configurações da Eliminação de Duplicação de Dados para cargas de trabalho recomendadas? Não, os Tipos de Uso fornecidos foram criados para fornecer padrões razoáveis para cargas de trabalho recomendadas.
Quais são os requisitos de memória para a Eliminação de Duplicação de Dados?
No mínimo, a Eliminação de Duplicação de Dados deve ter 300 MB + 50 MB para cada TB de dados lógicos. Por exemplo, se você estiver otimizando um volume de 10 TB, seria necessário um mínimo de 800 MB de memória alocada para a eliminação de duplicação (300 MB + 50 MB * 10 = 300 MB + 500 MB = 800 MB). Embora a Eliminação de Duplicação de Dados possa otimizar um volume com essa quantidade insuficiente de memória, esses recursos restritos retardarão os trabalhos da Eliminação de Duplicação de Dados.
O ideal seria que a Eliminação de Duplicação de Dados tivesse 1 GB de memória para cada 1 TB de dados lógicos. Por exemplo, se você estiver otimizando um volume de 10 TB, seria necessário 10 GB de memória alocada para a eliminação de duplicação (1 GB * 10). Essa proporção garantirá o desempenho máximo de trabalhos de Eliminação de Duplicação de Dados.
Quais são os requisitos de armazenamento para a Eliminação de Duplicação de Dados? No Windows Server 2016, a Eliminação de Duplicação de Dados pode dar suporte a tamanhos de volume de até 64 TB. Para saber mais, confira Novidades na Eliminação de Duplicação de Dados.