Ligar e gerir o Azure Databricks no Microsoft Purview
Este artigo descreve como registar o Azure Databricks e como autenticar e interagir com o Azure Databricks no Microsoft Purview. Para obter mais informações sobre o Microsoft Purview, leia o artigo introdutório.
Recursos compatíveis
| Extração de Metadados | Verificação Completa | Análise Incremental | Análise de Âmbito | Classificação | Rotulamento | Política de Acesso | Linhagem | Compartilhamento de Dados | Modo de exibição ao vivo |
|---|---|---|---|---|---|---|---|---|---|
| Sim | Sim | Não | Sim | Não | Não | Não | Sim | Não | Não |
Observação
Este conector traz metadados do metastore do Hive no âmbito da área de trabalho do Azure Databricks. Para analisar metadados no Catálogo unity do Azure Databricks, veja Conector do Catálogo unity do Azure Databricks.
Ao analisar o metastore do Hive do Azure Databricks, o Microsoft Purview suporta:
Extrair metadados técnicos, incluindo:
- Área de trabalho do Azure Databricks
- Servidor do Hive
- Bancos de dados
- Tabelas, incluindo as colunas, chaves externas, restrições exclusivas e descrição do armazenamento
- Vistas, incluindo as colunas e a descrição do armazenamento
Obter a relação entre tabelas externas e Azure Data Lake Storage Gen2/Recursos de Blobs do Azure (localizações externas).
Obter linhagem estática entre tabelas e vistas com base na definição de vista.
Ao configurar a análise, pode optar por analisar todo o metastore do Hive ou definir o âmbito da análise para um subconjunto de esquemas.
Comparar com a análise através do conector genérico do Metastore do Hive , caso o utilize para analisar o Azure Databricks anteriormente:
- Pode configurar diretamente a análise de áreas de trabalho do Azure Databricks sem acesso direto ao HMS. Utiliza o token de acesso pessoal do Databricks para autenticação e liga-se a um cluster para efetuar a análise.
- As informações da área de trabalho do Databricks são capturadas.
- A relação entre tabelas e recursos de armazenamento é capturada.
Limitações conhecidas
Quando o objeto é eliminado da origem de dados, atualmente a análise subsequente não remove automaticamente o recurso correspondente no Microsoft Purview.
Pré-requisitos
Tem de ter uma conta do Azure com uma subscrição ativa. Crie uma conta gratuitamente.
Tem de ter uma conta ativa do Microsoft Purview.
Precisa de uma Key Vault do Azure e de conceder permissões ao Microsoft Purview para aceder a segredos.
Precisa de permissões de Administrador de Origem de Dados e Leitor de Dados para registar uma origem e geri-la no portal de governação do Microsoft Purview. Para obter mais informações sobre permissões, consulte Controlo de acesso no Microsoft Purview.
Configure o runtime de integração autoalojado mais recente. Para obter mais informações, veja Criar e configurar um runtime de integração autoalojado. A versão mínima de Integration Runtime autoalojada suportada é a 5.20.8227.2.
Certifique-se de que o JDK 11 está instalado no computador onde o runtime de integração autoalojado está instalado. Reinicie o computador depois de instalar recentemente o JDK para que este entre em vigor.
Certifique-se de que Pacote Redistribuível do Visual C++ (versão Visual Studio 2012 Update 4 ou mais recente) está instalado no computador onde o runtime de integração autoalojado está em execução. Se não tiver esta atualização instalada, transfira-a agora.
Na sua área de trabalho do Azure Databricks:
Gere um token de acesso pessoal e armazene-o como um segredo no Azure Key Vault.
Criar um cluster. Anote o ID do cluster - pode encontrá-lo na área de trabalho do Azure Databricks -> Computação -> o cluster -> Etiquetas -> Etiquetas adicionadas automaticamente ->
ClusterId.Confirme que o utilizador tem as seguintes permissões para se ligar ao cluster do Azure Databricks:
- Pode Anexar a permissão para ligar ao cluster em execução.
- Pode Reiniciar a permissão para acionar automaticamente o cluster para iniciar se o respetivo estado for terminado durante a ligação.
Registrar
Esta secção descreve como registar uma área de trabalho do Azure Databricks no Microsoft Purview com o portal de governação do Microsoft Purview.
Aceda à sua conta do Microsoft Purview.
Selecione Mapa de Dados no painel esquerdo.
Selecione Registrar.
Em Registar origens, selecione Azure Databricks>Continuar.
No ecrã Registar origens (Azure Databricks), faça o seguinte:
Em Nome, introduza um nome que o Microsoft Purview irá listar como a origem de dados.
Para a subscrição do Azure e o nome da área de trabalho do Databricks, selecione a subscrição e a área de trabalho que pretende analisar na lista pendente. O URL da área de trabalho do Databricks é preenchido automaticamente.
Selecione uma coleção na lista.
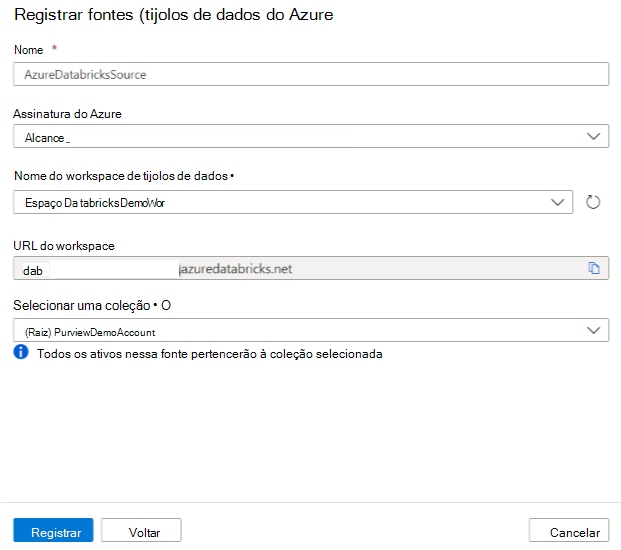
Selecione Concluir.
Examinar
Dica
Para resolver problemas com a análise:
- Confirme que seguiu todos os pré-requisitos.
- Veja a nossa documentação de resolução de problemas de análise.
Utilize os seguintes passos para analisar o Azure Databricks para identificar automaticamente os recursos. Para obter mais informações sobre a análise em geral, consulte Análises e ingestão no Microsoft Purview.
No Centro de Gestão, selecione runtimes de integração. Certifique-se de que está configurado um runtime de integração autoalojado. Se não estiver configurado, utilize os passos em Criar e gerir um runtime de integração autoalojado.
Aceda a Origens.
Selecione o Azure Databricks registado.
Selecione + Nova análise.
Forneça os seguintes detalhes:
Nome: introduza um nome para a análise.
Método de extração: Indique para extrair metadados do Metastore do Hive ou catálogo do Unity. Selecione Metastore do Hive.
Ligar através do runtime de integração: selecione o runtime de integração autoalojado configurado.
Credencial: selecione a credencial para ligar à sua origem de dados. Certifique-se de que:
- Selecione Autenticação de Token de Acesso ao criar uma credencial.
- Indique o nome secreto do token de acesso pessoal que criou em Pré-requisitos na caixa adequada.
Para obter mais informações, veja Credenciais para autenticação de origem no Microsoft Purview.
ID do Cluster: especifique o ID do cluster ao qual o Microsoft Purview se liga e alimenta a análise. Pode encontrá-lo na área de trabalho do Azure Databricks –> Computação –> o cluster –> Etiquetas –> Etiquetas adicionadas automaticamente –>
ClusterIdPontos de montagem: indique o ponto de montagem e a cadeia de localização da origem do Armazenamento do Azure quando tiver o armazenamento externo montado manualmente no Databricks. Utilize o formato
/mnt/<path>=abfss://<container>@<adls_gen2_storage_account>.dfs.core.windows.net/;/mnt/<path>=wasbs://<container>@<blob_storage_account>.blob.core.windows.net. É utilizado para capturar a relação entre as tabelas e os recursos de armazenamento correspondentes no Microsoft Purview. Esta definição é opcional, se não for especificada, essa relação não é obtida.Pode obter a lista de pontos de montagem na área de trabalho do Databricks ao executar o seguinte comando python num bloco de notas:
dbutils.fs.mounts()Imprime todos os pontos de montagem, como abaixo:
[MountInfo(mountPoint='/databricks-datasets', source='databricks-datasets', encryptionType=''), MountInfo(mountPoint='/mnt/ADLS2', source='abfss://samplelocation1@azurestorage1.dfs.core.windows.net/', encryptionType=''), MountInfo(mountPoint='/databricks/mlflow-tracking', source='databricks/mlflow-tracking', encryptionType=''), MountInfo(mountPoint='/mnt/Blob', source='wasbs://samplelocation2@azurestorage2.blob.core.windows.net', encryptionType=''), MountInfo(mountPoint='/databricks-results', source='databricks-results', encryptionType=''), MountInfo(mountPoint='/databricks/mlflow-registry', source='databricks/mlflow-registry', encryptionType=''), MountInfo(mountPoint='/', source='DatabricksRoot', encryptionType='')]Neste exemplo, especifique o seguinte como pontos de montagem:
/mnt/ADLS2=abfss://samplelocation1@azurestorage1.dfs.core.windows.net/;/mnt/Blob=wasbs://samplelocation2@azurestorage2.blob.core.windows.netEsquema: o subconjunto de esquemas a importar expressos como uma lista separada por ponto e vírgula de esquemas. Por exemplo,
schema1;schema2. Todos os esquemas de utilizador são importados se essa lista estiver vazia. Todos os esquemas e objetos do sistema são ignorados por predefinição.Os padrões de nome de esquema aceitáveis podem ser nomes estáticos ou conter carateres universais %. Por exemplo:
A%;%B;%C%;D- Começar com A ou
- Terminar com B ou
- Contenham C ou
- Igual a D
A utilização de NÃO e carateres especiais não é aceitável.
Observação
Este filtro de esquema é suportado na versão 5.32.8597.1 e posterior Integration Runtime autoalojado.
Memória máxima disponível: memória máxima (em gigabytes) disponível no computador do cliente para os processos de análise a utilizar. Este valor depende do tamanho do Azure Databricks a analisar.
Observação
Como regra de polegar, forneça 1 GB de memória para cada 1000 tabelas.
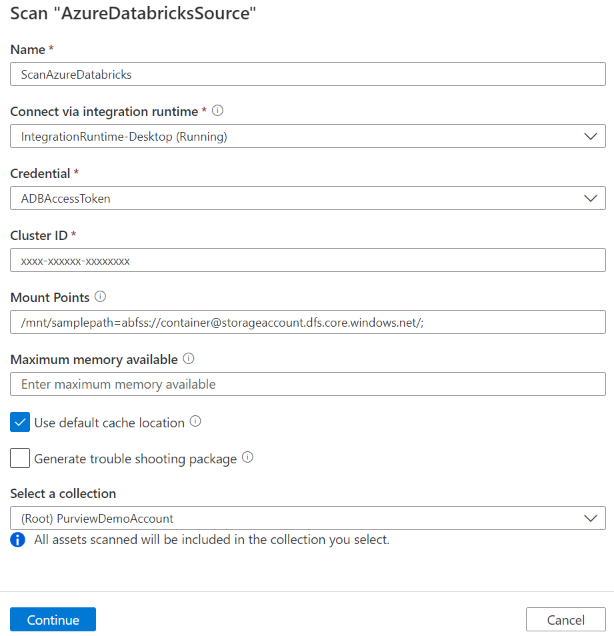
Selecione Continuar.
Em Acionador de análise, escolha se pretende configurar um agendamento ou executar a análise uma vez.
Reveja a análise e selecione Guardar e Executar.
Assim que a análise for concluída com êxito, veja como procurar e pesquisar recursos do Azure Databricks.
Ver as suas análises e execuções de análise
Para ver as análises existentes:
- Aceda ao portal do Microsoft Purview. No painel esquerdo, selecione Mapa de dados.
- Selecione a origem de dados. Pode ver uma lista de análises existentes nessa origem de dados em Análises recentes ou pode ver todas as análises no separador Análises .
- Selecione a análise que tem os resultados que pretende ver. O painel mostra-lhe todas as execuções de análise anteriores, juntamente com as status e as métricas de cada execução de análise.
- Selecione o ID de execução para marcar os detalhes da execução da análise.
Gerir as suas análises
Para editar, cancelar ou eliminar uma análise:
Aceda ao portal do Microsoft Purview. No painel esquerdo, selecione Mapa de Dados.
Selecione a origem de dados. Pode ver uma lista de análises existentes nessa origem de dados em Análises recentes ou pode ver todas as análises no separador Análises .
Selecione a análise que pretende gerir. Você poderá:
- Edite a análise ao selecionar Editar análise.
- Cancele uma análise em curso ao selecionar Cancelar execução de análise.
- Elimine a análise ao selecionar Eliminar análise.
Observação
- Eliminar a análise não elimina os recursos de catálogo criados a partir de análises anteriores.
Procurar e pesquisar recursos
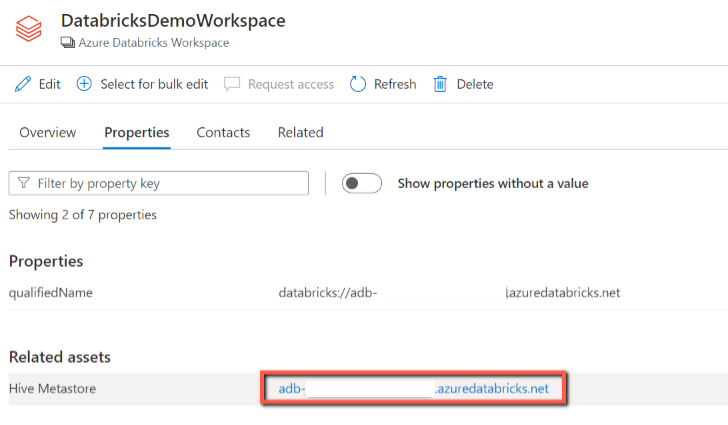
Depois de analisar o Azure Databricks, pode procurar Catálogo unificado ou procurar Catálogo unificado para ver os detalhes do recurso.
A partir do recurso da área de trabalho do Databricks, pode encontrar o Metastore do Hive associado e as tabelas/vistas, que também é invertido.
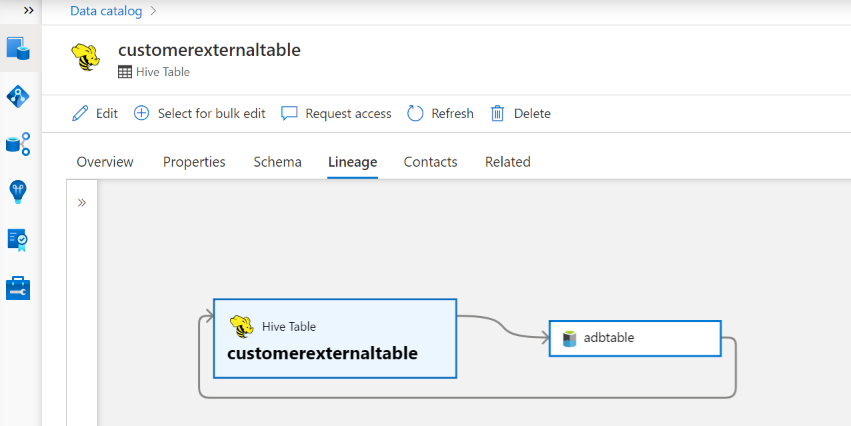
Linhagem
Veja a secção de capacidades suportadas nos cenários suportados do Azure Databricks. Para obter mais informações sobre a linhagem em geral, veja Guia do utilizador da linhagem e linhagem de dados.
Aceda à tabela/elemento de vista do Hive –> separador linhagem, pode ver a relação de recursos quando aplicável. Para a relação entre recursos de armazenamento externo e tabela, pode ver que o recurso de tabela do Hive e o recurso de armazenamento estão diretamente ligados bidirecionalmente, uma vez que afetam mutuamente uns aos outros. Se utilizar o ponto de montagem na instrução create table, terá de fornecer as informações do ponto de montagem nas definições de análise para extrair essa relação.
Próximas etapas
Agora que registou a sua origem, utilize os seguintes guias para saber mais sobre o Microsoft Purview e os seus dados: