Usar o recurso Enriquecimento de anotações clínicas não estruturadas (versão preliminar) nas soluções de dados de serviços de saúde
[Este artigo faz parte da documentação de pré-lançamento e está sujeito a alterações.]
Observação
Esse conteúdo está sendo atualizado no momento.
O Enriquecimento de anotações clínicas não estruturadas (versão preliminar) usa o serviço Text Analytics for Health da Linguagem de IA do Azure para extrair as principais entidades FHIR (Fast Healthcare Interoperability Resources) de anotações clínicas não estruturadas. Ele cria dados estruturados a partir dessas anotações clínicas. Em seguida, você pode analisar esses dados estruturados para obter insights, previsões e medidas de qualidade destinadas a melhorar os resultados de saúde do paciente.
Para saber mais sobre o recurso e entender como implantá-lo e configurá-lo, consulte:
- Visão geral de Enriquecimento de anotações clínicas não estruturadas (versão preliminar)
- Implantar e configurar o Enriquecimento de anotações clínicas não estruturadas (versão preliminar)
O Enriquecimento de anotações clínicas não estruturadas (versão preliminar) tem uma dependência direta do recurso Bases de dados de serviços de saúde. Certifique-se de configurar e executar com êxito os pipelines de Bases de dados de serviços de saúde primeiro.
Pré-requisitos
- Implantar soluções de dados de serviços de saúde no Microsoft Fabric
- Instale os notebooks e pipelines fundamentais em Implantar Bases de dados de serviços de saúde.
- Configure o serviço de linguagem do Azure conforme explicado em Configurar o serviço de linguagem do Azure.
- Implantar e configurar o Enriquecimento de anotações clínicas não estruturadas (versão preliminar)
- Implante e configure as transformações OMOP. Esta etapa é opcional.
Serviço de ingestão de NLP
O notebook healthcare#_msft_ta4h_silver_ingestion executa o módulo NLPIngestionService na biblioteca de soluções de dados de serviços de saúde para invocar o serviço Text Analytics for Health. Esse serviço extrai anotações clínicas não estruturadas do recurso FHIR DocumentReference.Content para criar uma saída nivelada. Para saber mais, consulte Revisar a configuração do notebook.
Armazenamento de dados na camada prata
Após a análise da API de NLP (processamento de linguagem natural), a saída estruturada e nivelada é armazenada nas seguintes tabelas nativas no lakehouse healthcare#_msft_silver:
- nlpentity: contém as entidades niveladas extraídas das anotações clínicas não estruturadas. Cada linha é um único termo extraído do texto não estruturado após a realização da análise de texto.
- nlprelationship: fornece o relacionamento entre as entidades extraídas.
- nlpfhir: contém o pacote de saída FHIR como uma cadeia de caracteres JSON.
Para rastrear o carimbo de data/hora da última atualização, o NLPIngestionService usa o campo parent_meta_lastUpdated em todas as três tabelas do lakehouse prata. Esse acompanhamento garante que o documento de origem DocumentReference, que é o recurso pai, seja armazenado primeiro para manter a integridade referencial. Esse processo ajuda a evitar inconsistências nos dados e recursos órfãos.
Importante
No momento, Text Analytics for Health retorna vocabulários listados na Documentação de Vocabulário do Metathesaurus UMLS. Para obter orientações sobre esses vocabulários, consulte Importar dados do UMLS.
Para a versão preliminar, usamos as terminologias SNOMED-CT (Systematized Nomenclature of Medicine - Clinical Terms), LOINC (Logical Observation Identifiers, Names, and Codes) e RxNorm que estão incluídas no conjunto de dados de exemplo OMOP com base nas orientações da Observational Health Data Sciences and Informatics (OHDSI).
Transformação OMOP
As soluções de dados de serviços de saúde no Microsoft Fabric também fornecem outro recurso para transformações OMOP (Observational Medical Outcomes Partnership). Quando você executa esse recurso, a transformação subjacente do lakehouse prata para o lakehouse ouro OMOP também transforma a saída estruturada e nivelada da análise de anotações clínicas não estruturadas. A transformação lê a tabela nlpentity no lakehouse prata e mapeia a saída para a tabela NOTE_NLP no lakehouse ouro OMOP.
Para obter mais informações, consulte Visão geral de transformações OMOP.
Veja o esquema para as saídas de NLP estruturadas, com o mapeamento de colunas de NOTE_NLP correspondente para o OMOP Common Data Model:
| Referência do documento nivelada | Descrição | Mapeamento d e Note_NLP | Dados de exemplo |
|---|---|---|---|
| id | Identificador exclusivo para a entidade. Chave composta de parent_id, offset e length. |
note_nlp_id |
1380 |
| parent_id | Uma chave estrangeira para o texto nivelado documentreferencecontent do qual o termo foi extraído. | note_id |
625 |
| texto | Texto da entidade como aparece no documento. | lexical_variant |
Sem alergias conhecidas |
| Deslocamento | Deslocamento de caracteres do termo extraído no texto de entrada documentreferencecontent. | offset |
294 |
| data_source_entity_id | ID da entidade no catálogo de origem especificado. | note_nlp_concept_id e note_nlp_source_concept_id |
37396387 |
| nlp_last_executed | A data do processamento da análise do texto documentreferencecontent. | nlp_date_time e nlp_date |
2023-05-17T00:00:00.0000000 |
| modelo | Nome e versão do sistema de NLP (Nome do sistema de NLP do Text Analytics for Health e a versão). | nlp_system |
MSFT TA4H |

Limites de serviço para Text Analytics for Health
- O número máximo de caracteres por documento é limitado a 125.000.
- O tamanho máximo dos documentos contidos em toda a solicitação é limitado a 1 MB.
- O número máximo de documentos por solicitação é limitado a:
- 25 para a API baseada na Web.
- 1.000 para o contêiner.
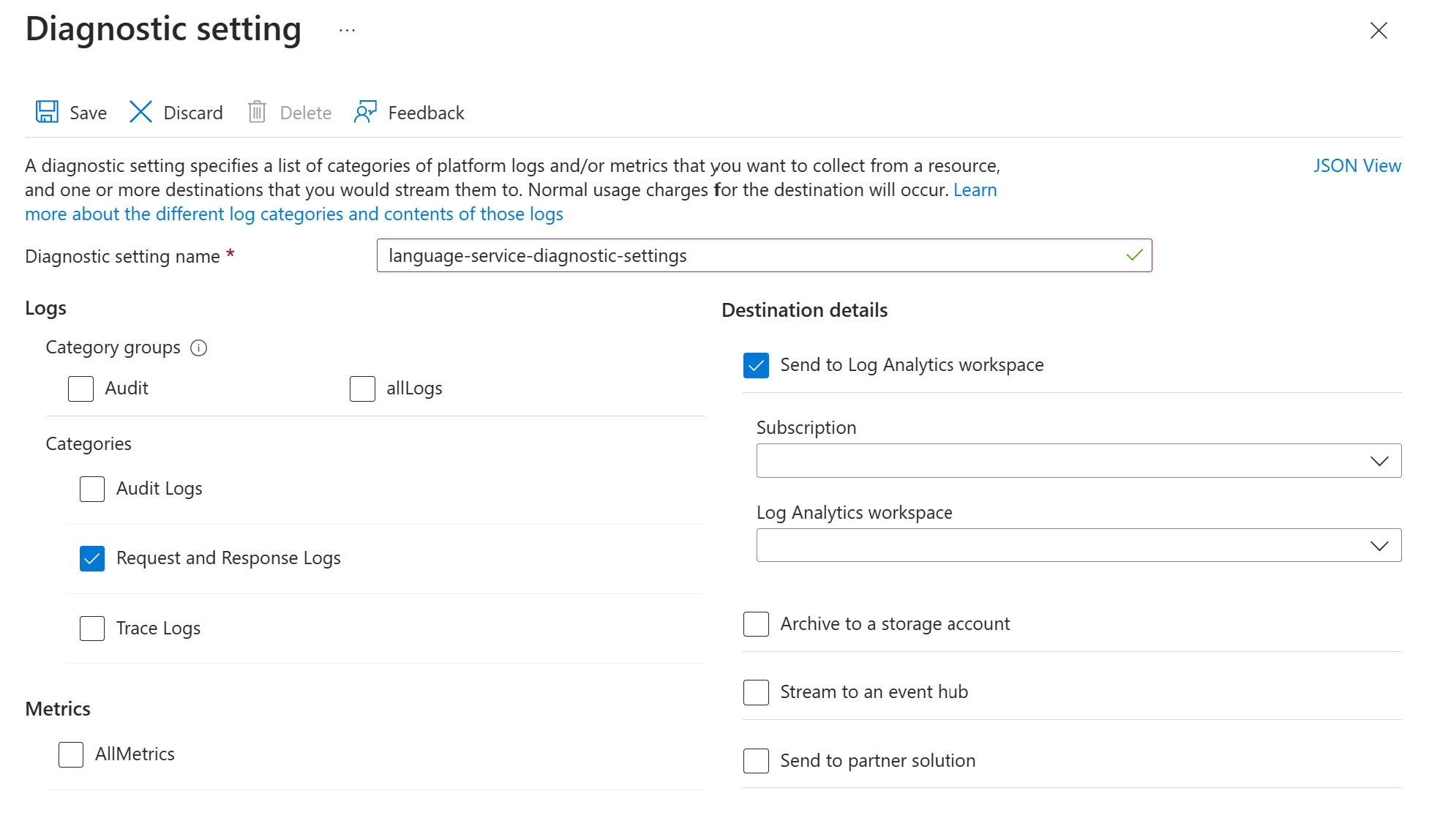
Habilitar logs
Siga estas etapas para habilitar o log de solicitações e respostas para a API do Text Analytics for Health:
Habilite as configurações de diagnóstico para seu recurso Serviço de Linguagem do Azure usando as instruções em Habilitar log de diagnóstico para serviços de IA do Azure. Esse recurso é o mesmo serviço de linguagem que você criou durante a etapa de implantação do Configurar o serviço de linguagem do Azure.
- Insira um nome de configuração de diagnóstico.
- Defina a categoria como Logs de Solicitação e Resposta.
- Para obter detalhes de destino, selecione Enviar para o workspace do Log Analytics e selecione o workspace necessário do Log Analytics. Se você não tiver um workspace, siga as instruções para criar um.
- Salve as configurações.
Acesse a seção Configuração de NLP no notebook do serviço de ingestão de NLP. Atualize o valor do parâmetro de configuração
enable_text_analytics_logsparaTrue. Para obter mais informações sobre este notebook, consulte Revisar a configuração do notebook.

Exibir logs no Azure Log Analytics
Para explorar os dados de análise de log:
- Navegue até seu workspace do Log Analytics.
- Localize e selecione Logs. Nessa página, você pode executar consultas em seus logs.
Consulta de exemplo
Veja a seguir uma consulta básica do Kusto que você pode usar para explorar seus dados de log. Essa consulta de exemplo recupera todas as solicitações com falha do provedor de recursos dos Serviços Cognitivos Azure no dia anterior, agrupadas por tipo de erro:
AzureDiagnostics
| where TimeGenerated > ago(1d)
| where Category == "RequestResponse"
| where ResourceProvider == "MICROSOFT.COGNITIVESERVICES"
| where tostring(ResultSignature) startswith "4" or tostring(ResultSignature) startswith "5"
| summarize NumberOfFailedRequests = count() by ResultSignature