Explore dados em seu banco de dados espelhado com blocos de anotações
É possível explorar os dados duplicados do banco de dados espelhado com consultas do Spark em blocos de anotações.
Os blocos de anotações são um item de código poderoso para você desenvolver trabalhos do Apache Spark e experimentos de aprendizado de máquina em seus dados. É possível usar blocos de anotações no Fabric Lakehouse para explorar as tabelas espelhadas.
Pré-requisitos
- Conclua o tutorial para criar um banco de dados espelhado usando o banco de dados de origem.
- Tutorial: Configurar o banco de dados espelhado do Microsoft Fabric para o Azure Cosmos DB (Versão prévia)
- Tutorial: Configurar os bancos de dados espelhados no Microsoft Fabric usando o Azure Databricks (versão prévia)
- Tutorial: configurar bancos de dados espelhados do Microsoft Fabric a partir do Banco de Dados SQL do Azure
- Tutorial: Configurar bancos de dados espelhados do Microsoft Fabric a partir da Instância Gerenciada de SQL do Azure (versão prévia)
- Tutorial: configurar bancos de dados espelhados do Microsoft Fabric a partir do Snowflake
Criar um atalho
Primeiro, você precisa criar um atalho de suas tabelas espelhadas para o Lakehouse e, em seguida, criar blocos de anotações com consultas do Spark em seu Lakehouse.
No portal Fabric, abra Engenharia de Dados.
Se você ainda não tem uma Lakehouse criada, selecione Lakehouse e crie uma nova Lakehouse dando-lhe um nome.
Selecione Obter dados -> Novo atalho.
Selecione Microsoft OneLake.
É possível ver todos os bancos de dados espelhados no espaço de trabalho do Fabric.
Selecione o banco de dados espelhado que você deseja adicionar ao seu Lakehouse, como um atalho.
Selecione as tabelas desejadas no banco de dados espelhado.
Selecione Avançar e, em seguida, Criar.
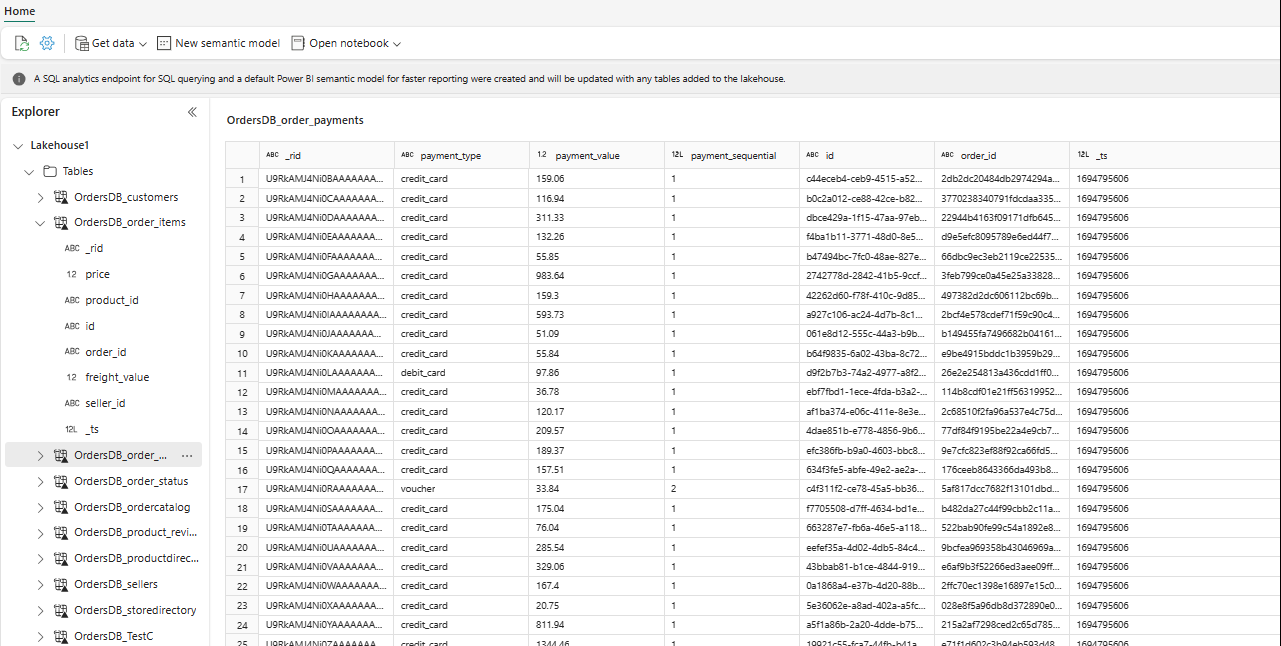
No Explorer, agora é possível ver os dados da tabela selecionada no Lakehouse.
Dica
É possível adicionar outros dados no Lakehouse diretamente ou usar atalhos como S3, ADLS Gen2. É possível navegar até o ponto de extremidade de análise SQL do Lakehouse e unir os dados em todas essas fontes com dados espelhados perfeitamente.
Para explorar esses dados no Spark, selecione os
...pontos ao lado de qualquer tabela. Selecione Novo bloco de anotações ou Bloco de anotações existente para iniciar a análise.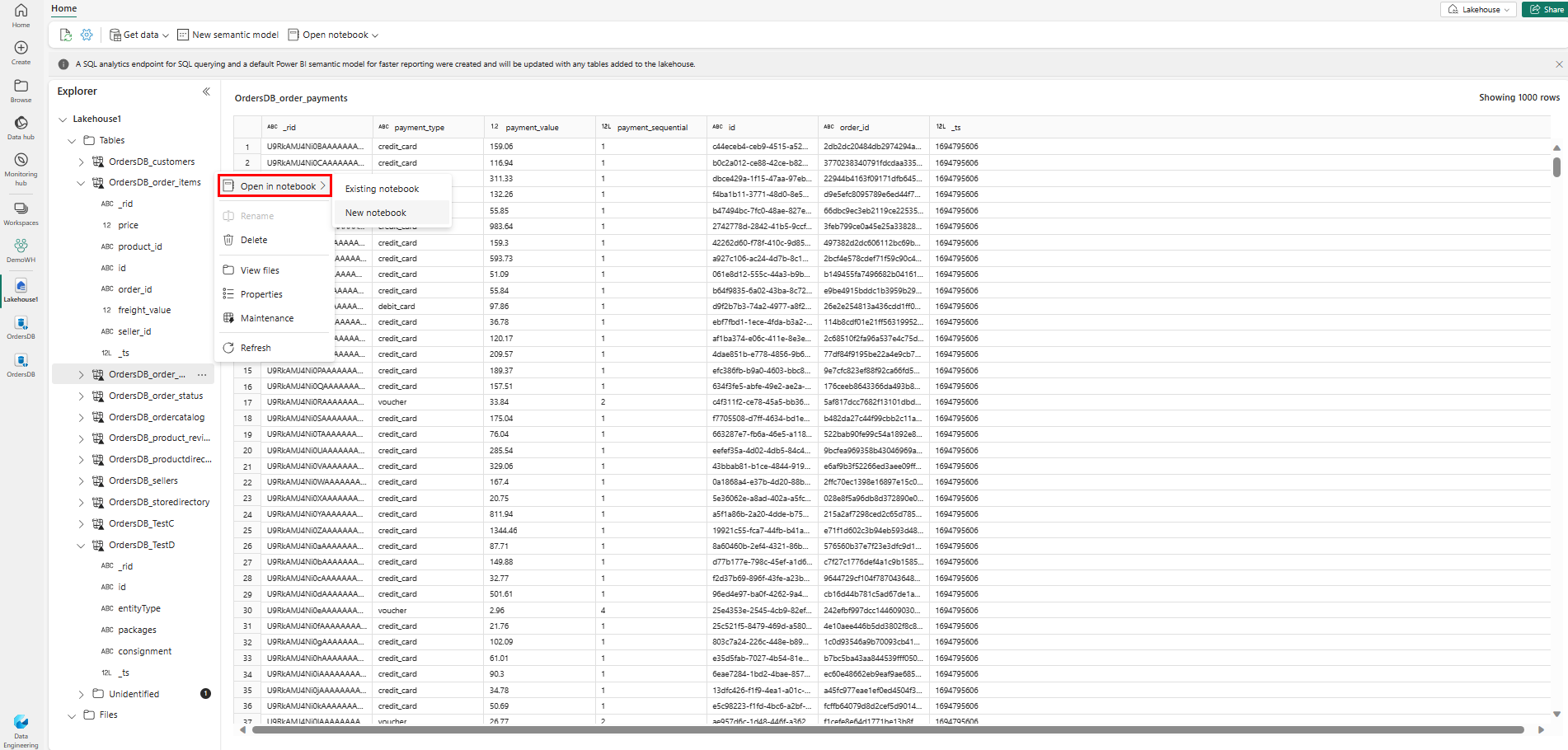
O bloco de anotações será aberto automaticamente e carregará o dataframe com uma consulta Spark SQL
SELECT ... LIMIT 1000.- Os novos blocos de anotações podem levar até dois minutos para carregar completamente. É possível evitar esse atraso usando um bloco de anotações existente com uma sessão ativa.
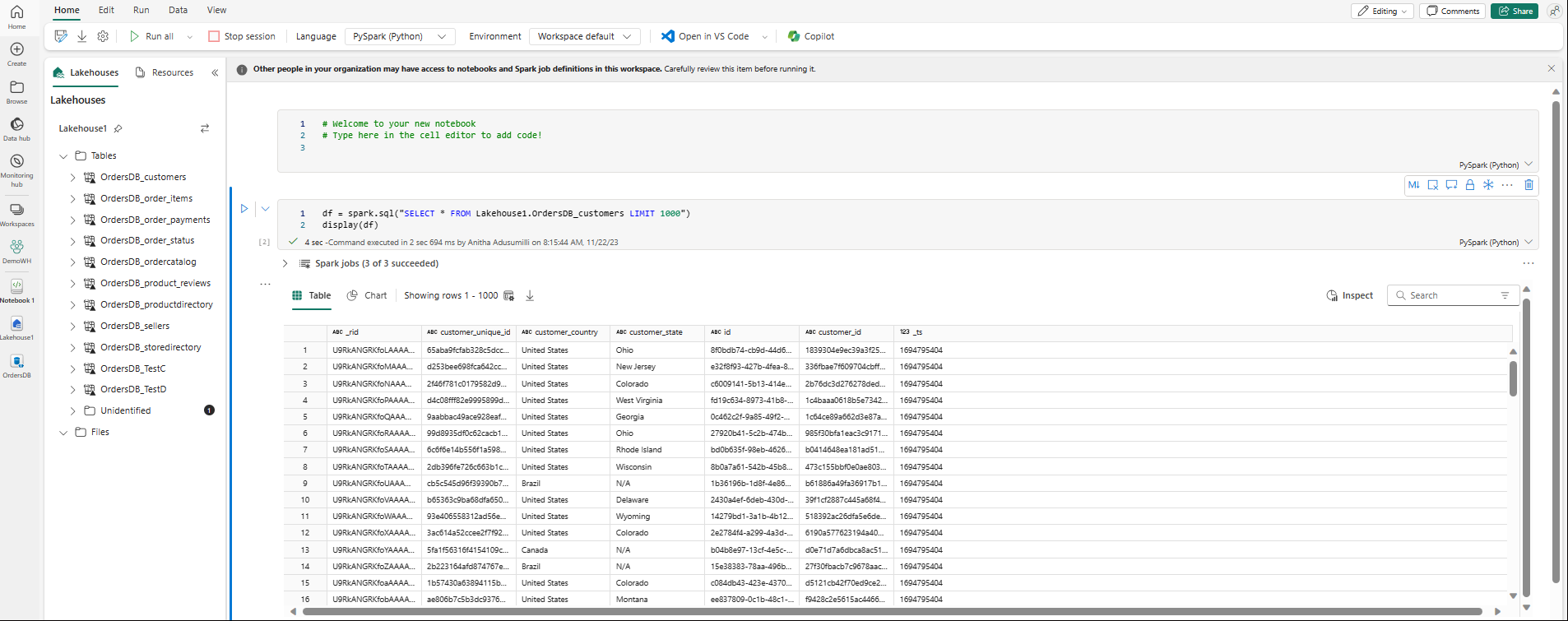
- Os novos blocos de anotações podem levar até dois minutos para carregar completamente. É possível evitar esse atraso usando um bloco de anotações existente com uma sessão ativa.


