Tutorial: Criar, avaliar e classificar um modelo de previsão de evasão de clientes
Este tutorial apresenta um exemplo de ponta a ponta de um fluxo de trabalho de Ciência de Dados do Synapse no Microsoft Fabric. O cenário cria um modelo para prever se os clientes vão desistir ou não do banco. A taxa de rotatividade, ou a taxa de desgaste, refere-se à taxa na qual os clientes bancários encerram seus relacionamentos com o banco.
Este tutorial aborda estas etapas:
- Instalar bibliotecas personalizadas
- Carregar os dados
- Entender e processar os dados por meio da análise de dados exploratória e mostrar o uso do recurso Fabric Data Wrangler
- Use scikit-learn e LightGBM para treinar modelos de machine learning e acompanhar experimentos com os recursos de registro automático do MLflow e do Fabric
- Avaliar e salvar o modelo final de machine learning
- Mostrar o desempenho do modelo com visualizações do Power BI
Pré-requisitos
Obtenha uma assinatura de Microsoft Fabric. Ou inscreva-se para um teste gratuito do Microsoft Fabric.
Entre no Microsoft Fabric.
Use o seletor de experiência no canto inferior esquerdo da página inicial para alternar para Fabric.
- Se necessário, crie um lakehouse no Microsoft Fabric, conforme descrito em Criar um lakehouse no Microsoft Fabric.
Acompanhe em um caderno de anotações
Você pode escolher uma destas opções para acompanhar em um caderno:
- Abra e execute o notebook integrado.
- Carregue seu bloco de anotações no GitHub.
Abrir o bloco de anotações interno
O notebook de exemplo Rotatividade de clientes acompanha este tutorial.
Para abrir o bloco de anotações de exemplo para este tutorial, siga as instruções em Preparar seu sistema para tutoriais de ciência de dados.
Não deixe de anexar um lakehouse ao notebook antes de começar a executar o código.
Importar o notebook do GitHub
O notebook AIsample – Bank Customer Churn.ipynb acompanha este tutorial.
Para abrir o bloco de anotações que acompanha este tutorial, siga as instruções em Prepare seu sistema para tutoriais de ciência de dados para importar o bloco de anotações para seu workspace.
Se você prefere copiar e colar o código desta página, crie um notebook.
Assegure-se de anexar um lakehouse ao notebook antes de começar a executar o código.
Etapa 1: Instalar bibliotecas personalizadas
Para desenvolvimento de modelo de machine learning ou análise de dados ad hoc, talvez seja necessário instalar rapidamente uma biblioteca personalizada para sua sessão do Apache Spark. Você tem duas opções para instalar bibliotecas.
- Use as capacidades de instalação inline (
%pipou%conda) do seu notebook para instalar uma biblioteca, somente no seu notebook atual. - Como alternativa, você pode criar um ambiente do Fabric, instalar bibliotecas de fontes públicas ou carregar bibliotecas personalizadas nele e, em seguida, o administrador do workspace pode anexar o ambiente como o padrão para o workspace. Todas as bibliotecas no ambiente ficarão disponíveis para uso em quaisquer notebooks e definições de trabalho do Spark no workspace. Para obter mais informações sobre ambientes, consulte criar, configurar e usar um ambiente no Microsoft Fabric.
Para este tutorial, use %pip install para instalar a biblioteca de imblearn em seu notebook.
Nota
O kernel do PySpark é reiniciado após a execução do %pip install. Instale as bibliotecas necessárias antes de executar outras células.
# Use pip to install libraries
%pip install imblearn
Etapa 2: Carregar os dados
O conjunto de dados em churn.csv contém o status de rotatividade de 10.000 clientes, juntamente com 14 atributos, que incluem:
- Pontuação de crédito
- Localização geográfica (Alemanha, França, Espanha)
- Gênero (masculino, feminino)
- Idade
- Tempo de posse (número de anos em que a pessoa foi cliente naquele banco)
- Saldo da conta
- Salário estimado
- Número de produtos que um cliente comprou por meio do banco
- Status do cartão de crédito (se um cliente tem ou não um cartão de crédito)
- Status do membro ativo (se a pessoa é ou não um cliente do banco ativo)
O conjunto de dados também inclui as colunas de número da linha, ID do cliente e sobrenome do cliente. Os valores nessas colunas não devem influenciar a decisão de um cliente de deixar o banco.
Um evento de fechamento de conta bancária do cliente define a taxa de rotatividade para esse cliente. A coluna Exited do banco de dados refere-se ao abandono do cliente. Como temos pouco contexto sobre esses atributos, não precisamos de informações em segundo plano sobre o conjunto de dados. Queremos entender como esses atributos contribuem para o status de Exited.
Desses 10.000 clientes, apenas 2.037 clientes (cerca de 20%) deixaram o banco. Devido à taxa de desequilíbrio de classe, recomendamos a geração de dados sintéticos. A precisão da matriz de confusão pode não ter relevância para a classificação desequilibrada. Talvez queiramos medir a precisão usando a área sob a curva de Precision-Recall (AUPRC).
- Esta tabela mostra uma visualização dos dados de
churn.csv:
| ID do Cliente | Sobrenome | Pontuação de Crédito | Geografia | Gênero | Idade | Mandato | Equilíbrio | NumOfProducts | HasCrCard | ÉMembroAtivo | SalárioEstimado | Saiu |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | Hargrave | 619 | França | Fêmea | 42 | 2 | 0,00 | 1 | 1 | 1 | 101348.88 | 1 |
| 15647311 | Hill | 608 | Espanha | Fêmea | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
Baixar o conjunto de dados e carregar no lakehouse
Defina esses parâmetros para que você possa usar este notebook com conjuntos de dados diferentes:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only SAMPLE_ROWS of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # Folder with data files
DATA_FILE = "churn.csv" # Data file name
Esse código baixa uma versão disponível publicamente do conjunto de dados e armazena esse conjunto de dados em um fabric lakehouse:
Importante
Adicione um lakehouse ao notebook antes de executá-lo. A falha ao fazer isso resultará em um erro.
import os, requests
if not IS_CUSTOM_DATA:
# With an Azure Synapse Analytics blob, this can be done in one line
# Download demo data files into the lakehouse if they don't exist
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/bankcustomerchurn"
file_list = ["churn.csv"]
download_path = "/lakehouse/default/Files/churn/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Inicie a contagem do tempo necessário para executar o notebook.
# Record the notebook running time
import time
ts = time.time()
Ler dados brutos do lakehouse
Esse código lê dados brutos da seção Arquivos do lakehouse e adiciona mais colunas para diferentes partes de data. A criação da tabela delta particionada usa essas informações.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Criar um DataFrame pandas com base no conjunto de dados
Esse código converte o DataFrame do Spark em um DataFrame pandas, para facilitar o processamento e a visualização:
df = df.toPandas()
Etapa 3: executar análise de dados exploratória
Exibir dados brutos
Explore os dados brutos com display, calcule algumas estatísticas básicas e mostre exibições de gráfico. Primeiro, você deve importar as bibliotecas necessárias para visualização de dados — por exemplo, seaborn . O Seaborn é uma biblioteca de visualização de dados do Python e fornece uma interface de alto nível para criar visuais em dataframes e matrizes.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Usar o Data Wrangler para executar a limpeza inicial de dados
Inicialize o Data Wrangler diretamente do notebook para explorar e transformar DataFrames do pandas. Selecione a lista suspensa Data Wrangler na barra de ferramentas horizontal para procurar os DataFrames do pandas ativados disponíveis para edição. Selecione o DataFrame que você deseja abrir no Data Wrangler.
Nota
O Data Wrangler não pode ser aberto enquanto o kernel do notebook estiver ocupado. A execução da célula deve ser concluída antes de iniciar o Data Wrangler. Saiba mais sobre o Data Wrangler.

Depois que o Data Wrangler é iniciado, uma visão geral descritiva do painel de dados é gerada, conforme mostrado nas imagens a seguir. A visão geral inclui informações sobre a dimensão do DataFrame, quaisquer valores ausentes etc. Você pode usar o Data Wrangler para gerar o script para remover as linhas com valores ausentes, as linhas duplicadas e as colunas com nomes específicos. Em seguida, você pode copiar o script para uma célula. A próxima célula mostra o script copiado.


def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
Determinar atributos
Esse código determina os atributos categóricos, numéricos e de destino:
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
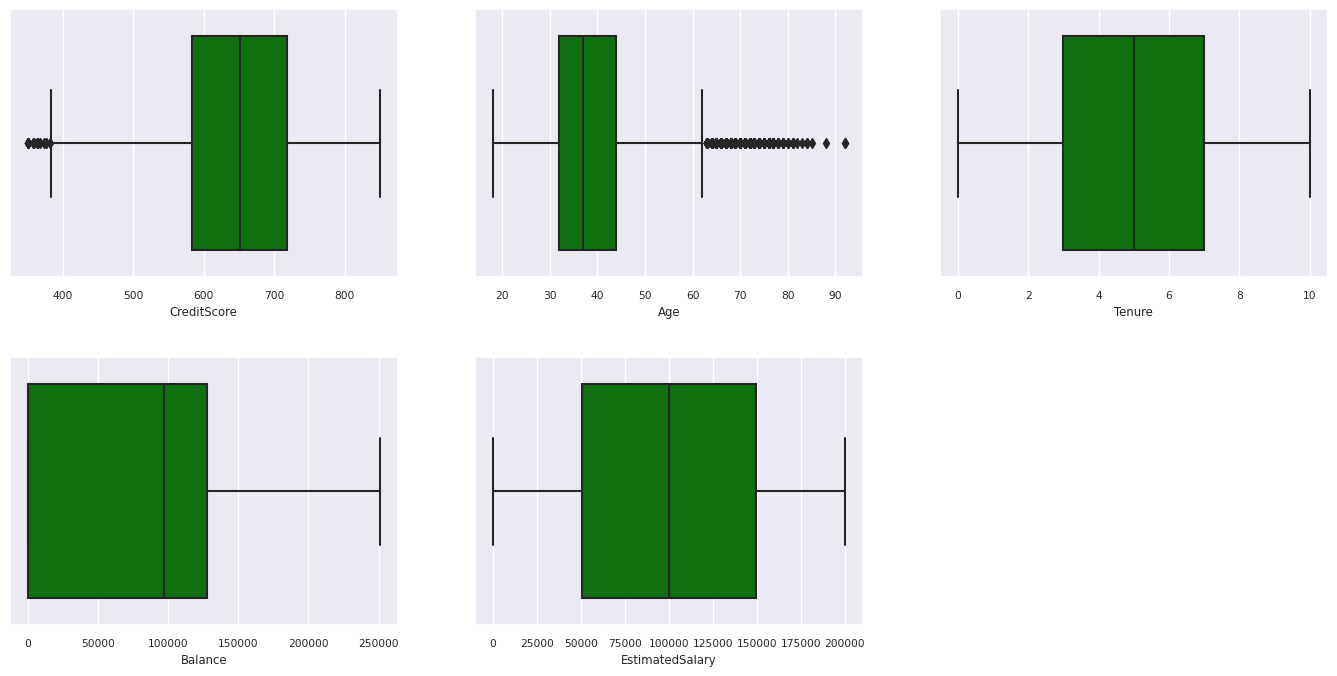
Mostrar o resumo de cinco números
Usar gráficos de caixa para mostrar o resumo de cinco números
- a pontuação mínima
- primeiro quartil
- mediana
- terceiro quartil
- pontuação máxima
para os atributos numéricos.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
# fig.suptitle('visualize and compare the distribution and central tendency of numerical attributes', color = 'k', fontsize = 12)
fig.delaxes(axes[1,2])
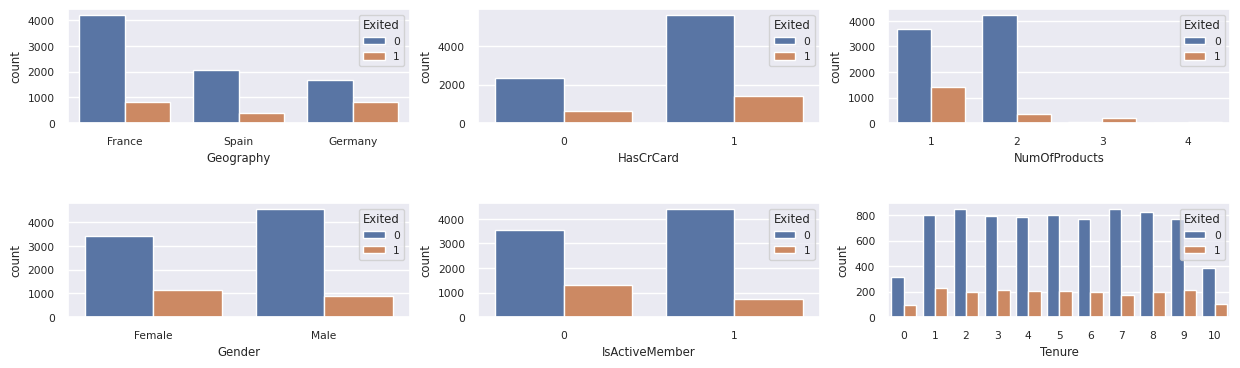
Mostrar a distribuição dos clientes que saíram e dos que não saíram
Mostre a distribuição dos clientes que saíram e dos que não saíram de acordo com os atributos categorizados:
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
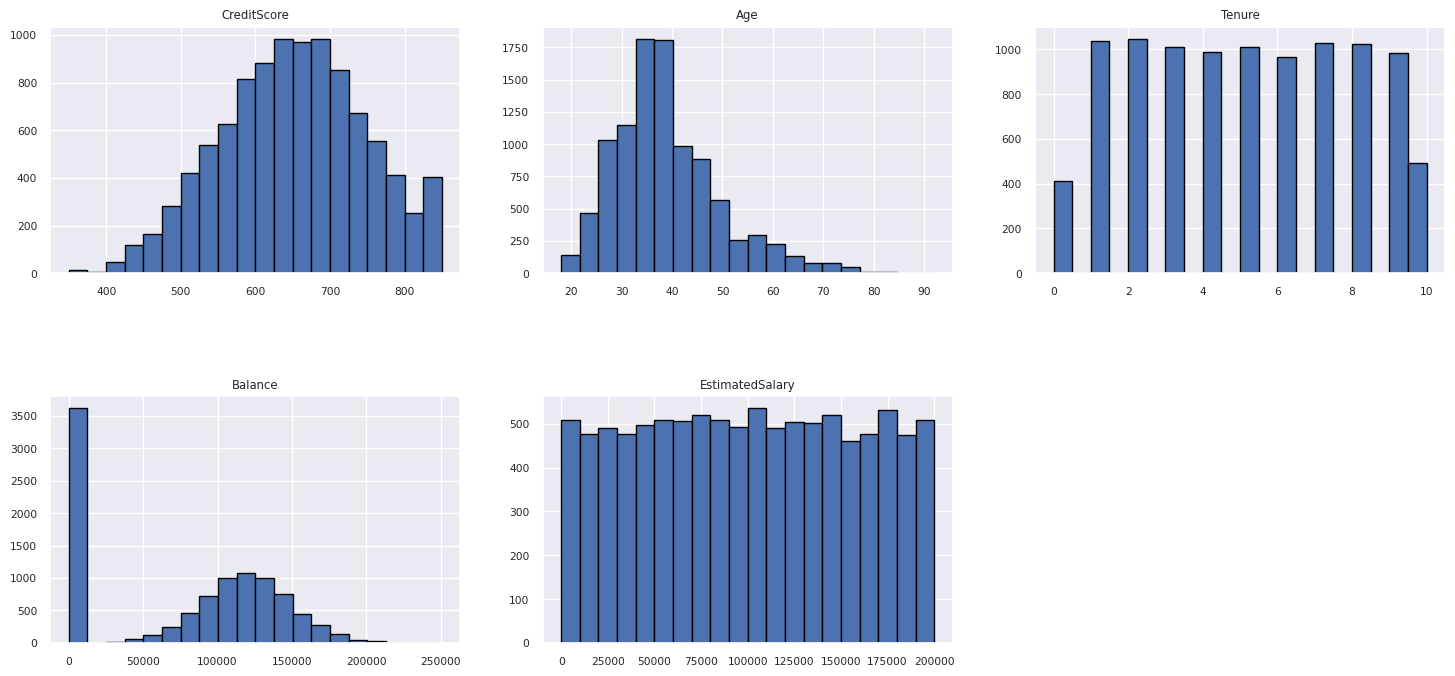
Mostrar a distribuição de atributos numéricos
Use um histograma para mostrar a distribuição de frequência de atributos numéricos:
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
# fig = fig.suptitle('distribution of numerical attributes', color = 'r' ,fontsize = 14)
plt.show()
Executar engenharia de características
Essa engenharia de recursos gera novos atributos com base nos atributos atuais:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Usar o Data Wrangler para executar a codificação one-hot
Com as mesmas etapas para iniciar o Data Wrangler, conforme discutido anteriormente, use o Data Wrangler para executar a codificação one-hot. Esta célula mostra o script gerado copiado para a codificação one-hot:


df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
Criar uma tabela delta para gerar o relatório do Power BI
table_name = "df_clean"
# Create a PySpark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Resumo das observações da análise de dados exploratórios
- A maioria dos clientes é da França. A Espanha tem a menor taxa de variação, em comparação com a França e a Alemanha.
- A maioria dos clientes tem cartões de crédito
- Alguns clientes têm mais de 60 anos e têm pontuações de crédito abaixo de 400. No entanto, eles não podem ser considerados como exceções
- Muito poucos clientes têm mais de dois produtos bancários
- Os clientes inativos têm uma taxa de variação mais alta
- Anos de gênero e posse têm pouco impacto na decisão de um cliente de fechar uma conta bancária
Etapa 4: Executar o treinamento e o acompanhamento do modelo
Com os dados em vigor, agora você pode definir o modelo. Aplique modelos de floresta aleatória e LightGBM neste notebook.
Use as bibliotecas scikit-learn e LightGBM para implementar os modelos, com algumas linhas de código. Além disso, use o MLfLow e o Fabric Autologging para acompanhar os experimentos.
Este código de exemplo carrega a tabela delta do lakehouse. Você pode usar outras tabelas delta que usam o lakehouse como origem.
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Gerar um experimento para acompanhar e registrar os modelos usando o MLflow
Esta seção mostra como gerar um experimento e especifica os parâmetros de modelo e treinamento e as métricas de pontuação. Além disso, ele mostra como treinar os modelos, registrá-los e salvar os modelos treinados para uso posterior.
import mlflow
# Set up the experiment name
EXPERIMENT_NAME = "sample-bank-churn-experiment" # MLflow experiment name
O registro automático captura automaticamente os valores de parâmetro de entrada e as métricas de saída de um modelo de machine learning, pois esse modelo é treinado. Em seguida, essas informações são registradas no workspace, onde as APIs do MLflow ou o experimento correspondente em seu workspace podem acessá-lo e visualizá-lo.
Quando concluído, o experimento se assemelha a esta imagem:

Todos os experimentos com seus respectivos nomes são registrados e você pode acompanhar seus parâmetros e métricas de desempenho. Para saber mais sobre o registro em log automático, confira Registro em log automático no Microsoft Fabric.
Definir especificações de experimento e registro automático
mlflow.set_experiment(EXPERIMENT_NAME) # Use a date stamp to append to the experiment
mlflow.autolog(exclusive=False)
Importar scikit-learn e LightGBM
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Preparar conjuntos de dados de treinamento e teste
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Train/test separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
Aplicar SMOTE aos dados de treinamento
A classificação desequilibrada tem um problema, pois tem poucos exemplos da classe minoritária para um modelo aprender efetivamente o limite de decisão. Para lidar com isso, a Técnica de Superamostragem de Minoria Sintética (SMOTE) é a técnica mais usada para sintetizar novas amostras para a classe minoritária. Acesse o SMOTE com a biblioteca de imblearn instalada na etapa 1.
Aplique SMOTE somente ao conjunto de dados de treinamento. Você deve deixar o conjunto de dados de teste em sua distribuição desequilibrada original para obter uma aproximação válida do desempenho do modelo nos dados originais. Este experimento representa a situação na produção.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Para saber mais, confira SMOTE e De amostragem excessiva aleatória a SMOTE e ADASYN. O site do imbalanced-learn hospeda esses recursos.
Treinar o modelo
Use a Floresta Aleatória para treinar o modelo, com uma profundidade máxima de quatro e com quatro recursos:
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_test, y_test)
y_pred = rfc1_sm.predict(X_test)
cr_rfc1_sm = classification_report(y_test, y_pred)
cm_rfc1_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
Use a Floresta Aleatória para treinar o modelo, com uma profundidade máxima de oito e com seis recursos:
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_test, y_test)
y_pred = rfc2_sm.predict(X_test)
cr_rfc2_sm = classification_report(y_test, y_pred)
cm_rfc2_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
Treine o modelo com LightGBM:
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cr_lgbm_sm = classification_report(y_test, y_pred)
cm_lgbm_sm = confusion_matrix(y_test, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Exibir o artefato do experimento para acompanhar o desempenho do modelo
As execuções do experimento são salvas automaticamente no artefato do experimento. Você pode encontrar esse artefato no workspace. Um nome de artefato é baseado no nome usado para definir o experimento. Todos os modelos treinados, suas execuções, métricas de desempenho e parâmetros de modelo são registrados na página de experimentos.
Para visualizar seus experimentos:
- No painel esquerdo, selecione seu workspace.
- Encontre e selecione o nome do experimento, neste caso, sample-bank-churn-experiment.
Etapa 5: Avaliar e salvar o modelo final de machine learning
Abra o experimento salvo no workspace para selecionar e salvar o melhor modelo:
# Define run_uri to fetch the model
# MLflow client: mlflow.model.url, list model
load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model")
load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model")
load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model")
Avaliar o desempenho dos modelos salvos no conjunto de dados de teste
ypred_rfc1_sm = load_model_rfc1_sm.predict(X_test) # Random forest with maximum depth of 4 and 4 features
ypred_rfc2_sm = load_model_rfc2_sm.predict(X_test) # Random forest with maximum depth of 8 and 6 features
ypred_lgbm1_sm = load_model_lgbm1_sm.predict(X_test) # LightGBM
Mostrar verdadeiros/falsos positivos/negativos usando uma matriz de confusão
Para avaliar a precisão da classificação, crie um script que plote a matriz de confusão. Você também pode gerar uma matriz de confusão usando as ferramentas do SynapseML, como demonstrado no exemplo de Detecção de Fraudes .
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
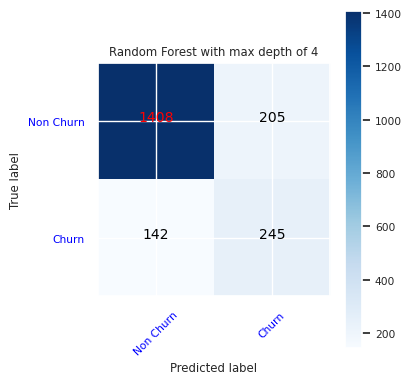
Crie uma matriz de confusão para o classificador de floresta aleatória, com uma profundidade máxima de quatro, com quatro recursos:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
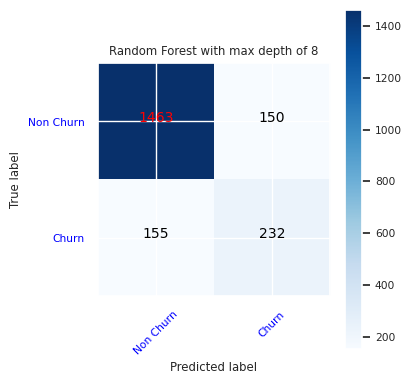
Crie uma matriz de confusão para o classificador de floresta aleatória com profundidade máxima de oito, com seis recursos:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc2_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
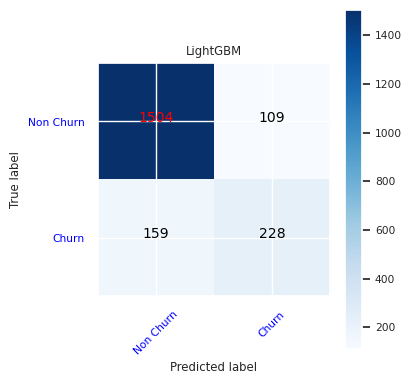
Crie uma matriz de confusão para LightGBM:
cfm = confusion_matrix(y_test, y_pred=ypred_lgbm1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()
Salvar resultados do Power BI
Salve o delta frame no lakehouse para transferir os resultados da previsão do modelo para uma visualização no Power BI.
df_pred = X_test.copy()
df_pred['y_test'] = y_test
df_pred['ypred_rfc1_sm'] = ypred_rfc1_sm
df_pred['ypred_rfc2_sm'] =ypred_rfc2_sm
df_pred['ypred_lgbm1_sm'] = ypred_lgbm1_sm
table_name = "df_pred_results"
sparkDF=spark.createDataFrame(df_pred)
sparkDF.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Etapa 6: Acessar visualizações no Power BI
Acesse sua tabela salva no Power BI:
- À esquerda, selecione OneLake.
- Selecione o lakehouse que você adicionou a este notebook.
- Na seção Abrir este Lakehouse, selecione Abrir.
- Na faixa de opções, selecione Novo modelo semântico. Selecione
df_pred_resultse selecione Confirmar para criar um novo modelo semântico do Power BI vinculado às previsões. - Abra um novo modelo semântico. Você pode encontrá-lo no OneLake.
- Selecione Criar novo relatório em arquivo a partir das ferramentas na parte superior da página de modelos semânticos, para abrir a página de criação de relatório do Power BI.
A captura de tela a seguir mostra alguns exemplos de visualizações. O painel de dados mostra as tabelas delta e as colunas a serem selecionadas em uma tabela. Após a seleção da categoria apropriada (x) e do eixo de valor (y), você pode escolher os filtros e as funções – por exemplo, soma ou média da coluna da tabela.
Nota
Nesta captura de tela, o exemplo ilustrado descreve a análise dos resultados de previsão salvos no Power BI:

No entanto, para um caso de uso real de rotatividade de clientes, o usuário pode precisar de um conjunto mais completo de requisitos para as visualizações a serem criadas, com base na especialização no assunto e no que a empresa e a equipe de análise de negócios padronizaram como métricas.
O relatório do Power BI mostra que os clientes que usam mais de dois produtos bancários têm uma taxa de variação mais alta. No entanto, poucos clientes tinham mais de dois produtos. (Consulte o gráfico no painel inferior esquerdo.) O banco deve coletar mais dados, mas também deve investigar outros recursos que se correlacionam com mais produtos.
Os clientes bancários na Alemanha têm uma taxa de abandono mais alta em comparação com os clientes na França e na Espanha. (Consulte o gráfico no painel inferior direito). Com base nos resultados do relatório, uma investigação sobre os fatores que incentivaram os clientes a sair pode ajudar.
Há mais clientes de meia-idade (entre 25 e 45 anos). Os clientes entre 45 e 60 tendem a sair mais.
Por fim, os clientes com pontuações de crédito mais baixas provavelmente deixariam o banco para outras instituições financeiras. O banco deve explorar maneiras de incentivar os clientes com pontuações de crédito e saldos de conta mais baixos a ficarem com o banco.
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")