Migrar pools do Spark do Azure Synapse Analytics para o Fabric
Enquanto o Azure Synapse fornece pools do Spark, o Fabric oferece Pools iniciais e Pools personalizados. O pool inicial pode ser uma boa opção se você tiver um único pool sem configurações ou bibliotecas personalizadas no Azure Synapse e se o tamanho do nó médio atender às suas necessidades. No entanto, se você busca mais flexibilidade nas configurações do pool do Spark, recomendamos usar pools personalizados. Há duas opções:
- Opção 1: mover o pool do Spark para o pool padrão de um workspace.
- Opção 2: mover o pool do Spark para um ambiente personalizado no Fabric.
Se você tiver mais de um pool do Spark e planeja movê-los para o mesmo workspace do Fabric, recomendamos usar a opção 2, criando vários ambientes e pools personalizados.
Para considerações sobre pool do Spark, confira diferenças entre o Spark do Azure Synapse e o Fabric.
Pré-requisitos
Se você ainda não tiver um, crie um workspace do Fabric em seu locatário.
Opção 1: do pool do Spark para o pool padrão do workspace
Você pode criar um pool do Spark personalizado do workspace do Fabric e usá-lo como o pool padrão no workspace. O pool padrão é usado por todos os notebooks e definições de trabalho do Spark no mesmo workspace.
Para mover de um pool do Spark existente no Azure Synapse para um pool padrão do workspace:
- Acesse o workspace do Azure Synapse: entre no Azure. Navegue até o workspace do Azure Synapse, acesse Pools de Análise e selecione Pools do Apache Spark.
- Localize o pool do Spark: em Pools do Apache Spark, localize o pool do Spark que você deseja mover para o Fabric e verifique as Propriedades do pool.
- Obtenha propriedades: obtenha as propriedades do pool do Spark, como a versão do Apache Spark, a família de tamanho do nó, o tamanho do nó ou o dimensionamento automático. Confira Considerações do pool do Spark para ver as diferenças.
- Crie um pool personalizado do Spark no Fabric:
- Acesse seu workspace do Fabric e selecione Configurações do workspace.
- Acesse Engenharia/Ciência de Dados e selecione Configurações do Spark.
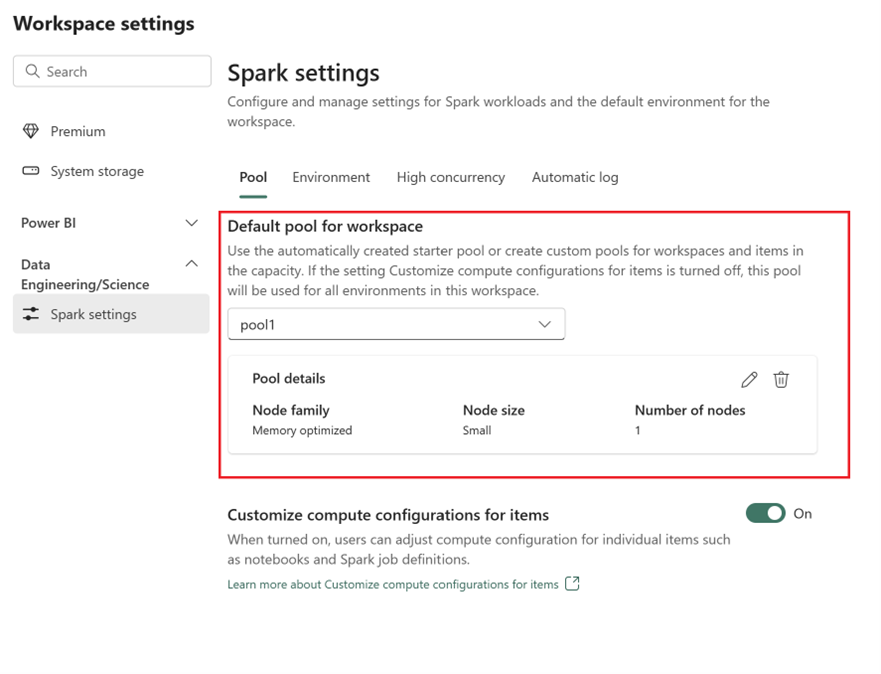
- Na guia Pool e na seção Pool padrão do workspace, expanda o menu suspenso e selecione Novo pool.
- Crie seu pool personalizado com os valores de destino correspondentes. Preencha o nome, a família de nós, o tamanho do nó, o dimensionamento automático e as opções de alocação de executor dinâmico.
- Selecione a versão do runtime:
- Acesse a guia Ambiente e selecione a Versão do Runtime necessária. Confira os runtimes disponíveis aqui.
- Desabilite a opção Definir ambiente padrão.
Observação
Nessa opção, não há suporte para bibliotecas ou configurações no nível de pool. No entanto, você pode ajustar a configuração de computação de itens individuais, como notebooks e definições de trabalho do Spark, e adicionar bibliotecas embutidas. Se você precisar adicionar bibliotecas e configurações personalizadas a um ambiente, considere um ambiente personalizado.
Opção 2: do pool do Spark ao ambiente personalizado
Com ambientes personalizados, você pode configurar propriedades e bibliotecas personalizadas do Spark. Para criar um ambiente personalizado:
- Acesse o workspace do Azure Synapse: entre no Azure. Navegue até o workspace do Azure Synapse, acesse Pools de Análise e selecione Pools do Apache Spark.
- Localize o pool do Spark: em Pools do Apache Spark, localize o pool do Spark que você deseja mover para o Fabric e verifique as Propriedades do pool.
- Obtenha propriedades: obtenha as propriedades do pool do Spark, como a versão do Apache Spark, a família de tamanho do nó, o tamanho do nó ou o dimensionamento automático. Confira Considerações do pool do Spark para ver as diferenças.
- Crie um pool personalizado do Spark:
- Acesse seu workspace do Fabric e selecione Configurações do workspace.
- Acesse Engenharia/Ciência de Dados e selecione Configurações do Spark.
- Na guia Pool e na seção Pool padrão do workspace, expanda o menu suspenso e selecione Novo pool.
- Crie seu pool personalizado com os valores de destino correspondentes. Preencha o nome, a família de nós, o tamanho do nó, o dimensionamento automático e as opções de alocação de executor dinâmico.
- Crie um item de ambiente se não tiver um.
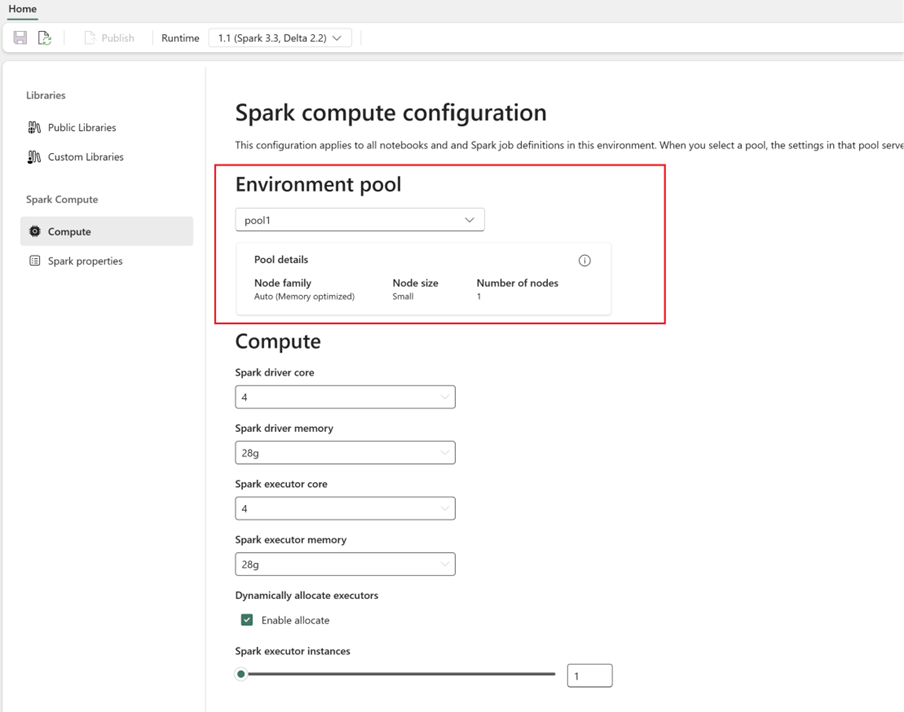
- Configure a computação do Spark:
- No Ambiente, acesse Computação do Spark>Computação.
- Selecione o pool recém-criado para o novo ambiente.
- Você pode configurar núcleos e memória de driver e executores.
- Selecione uma versão de runtime para o ambiente. Confira os runtimes disponíveis aqui.
- Clique em Salvar e Publicar alterações.
Saiba mais sobre como criar e usar um ambiente.