O que são os pipelines de implantação?
Observação
Os artigos desta seção descrevem como implantar conteúdo em seu aplicativo. Para controle de versão, confira a documentação de integração do Git.
A ferramenta de pipelines de implantação do Microsoft Fabric fornece aos criadores de conteúdo um ambiente de produção em que eles podem colaborar com outros para gerenciar o ciclo de vida do conteúdo organizacional. Os pipelines de implantação permitem que os criadores desenvolvam e testem o conteúdo no serviço antes que ele chegue aos usuários. Consulte a lista completa de tipos de itens com suporte que você pode implantar.
Observação
- A nova interface do usuário do pipeline de Implantação está em versão prévia no momento. Para ativar ou usar a nova interface do usuário, confira Começar usando a nova interface do usuário.
- Alguns dos itens para pipelines de implantação estão em versão prévia. Para saber mais, confira a lista de itens compatíveis.
Saiba como usar pipelines de implantação
Você pode aprender a usar a ferramenta de pipelines de implantação seguindo esses links.
Criar e gerenciar um pipeline de implantação do Power BI – Um módulo do Learn que explica todo o processo de criação de um pipeline de implantação.
Introdução aos pipelines de implantação – Um artigo que explica como criar um pipeline e as funções importantes, como implantação, comparação de conteúdo em diferentes fases e criação de regras de implantação.
Itens com suporte
Quando você implanta conteúdo de um estágio de pipeline para outro, o conteúdo copiado poderá conter os seguintes itens:
- Ativador
- Painel
- Pipeline de dados(versão prévia)
- Fluxos de Dados Gen2(versão prévia)
- Datamart(versão prévia)
- Ambiente(prévia)
- Banco de dados Eventhouse e KQL
- EventStream(pré-visualização)
- Conjunto de consultas KQL
- Lakehouse(versão prévia)
- banco de dados espelhado(versão prévia)
- Notebook
- Aplicativo da organização (versão prévia)
- Relatório paginado
- Fluxo de dados do Power BI
- Painel em tempo real
- Relatório (com base em modelos semânticos com suporte)
- Modelo semântico (que se origina de um arquivo .pbix e não é um conjunto de dados PUSH)
- Banco de Dados SQL (versão prévia)
- Warehouse(versão prévia)
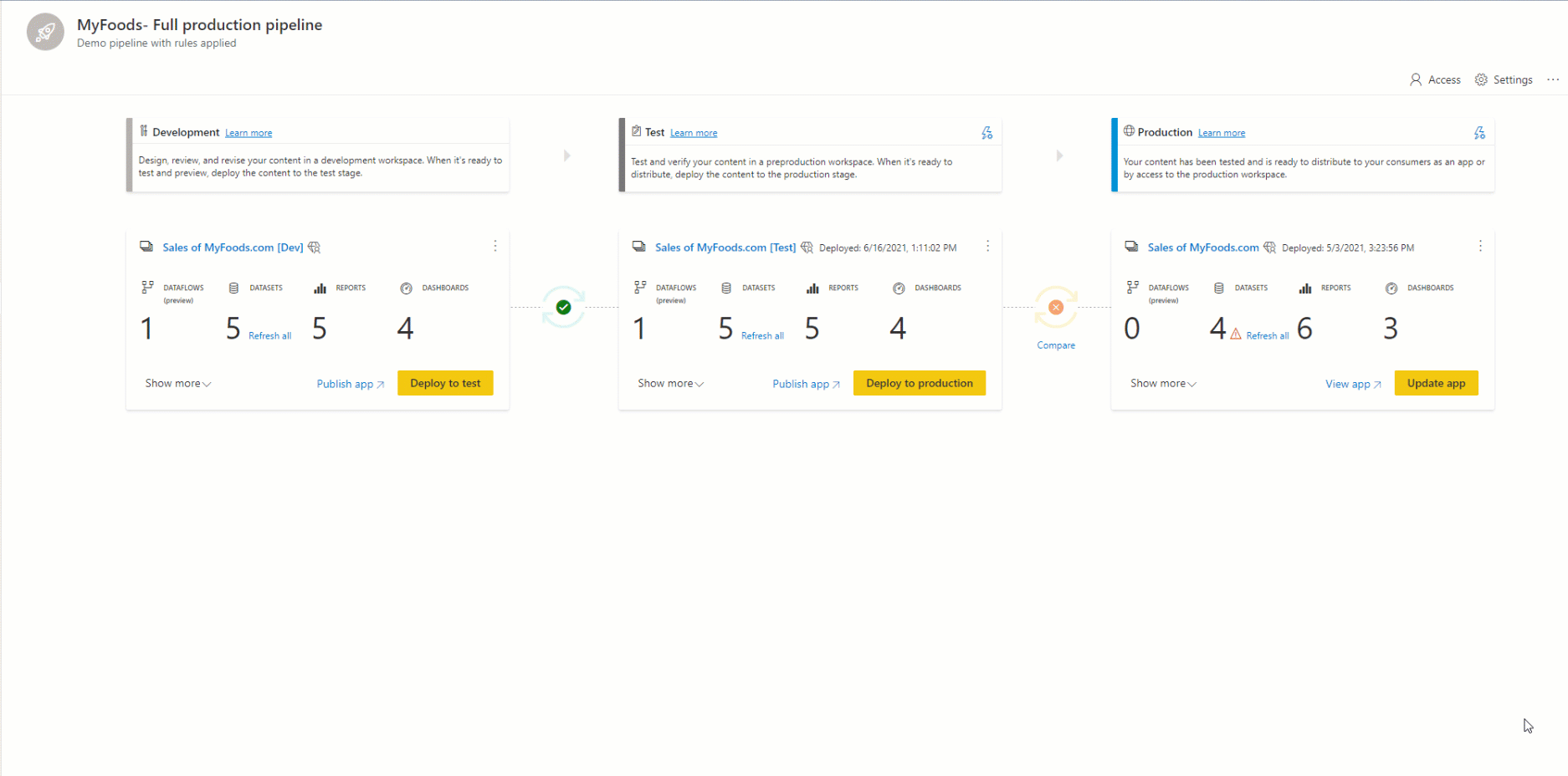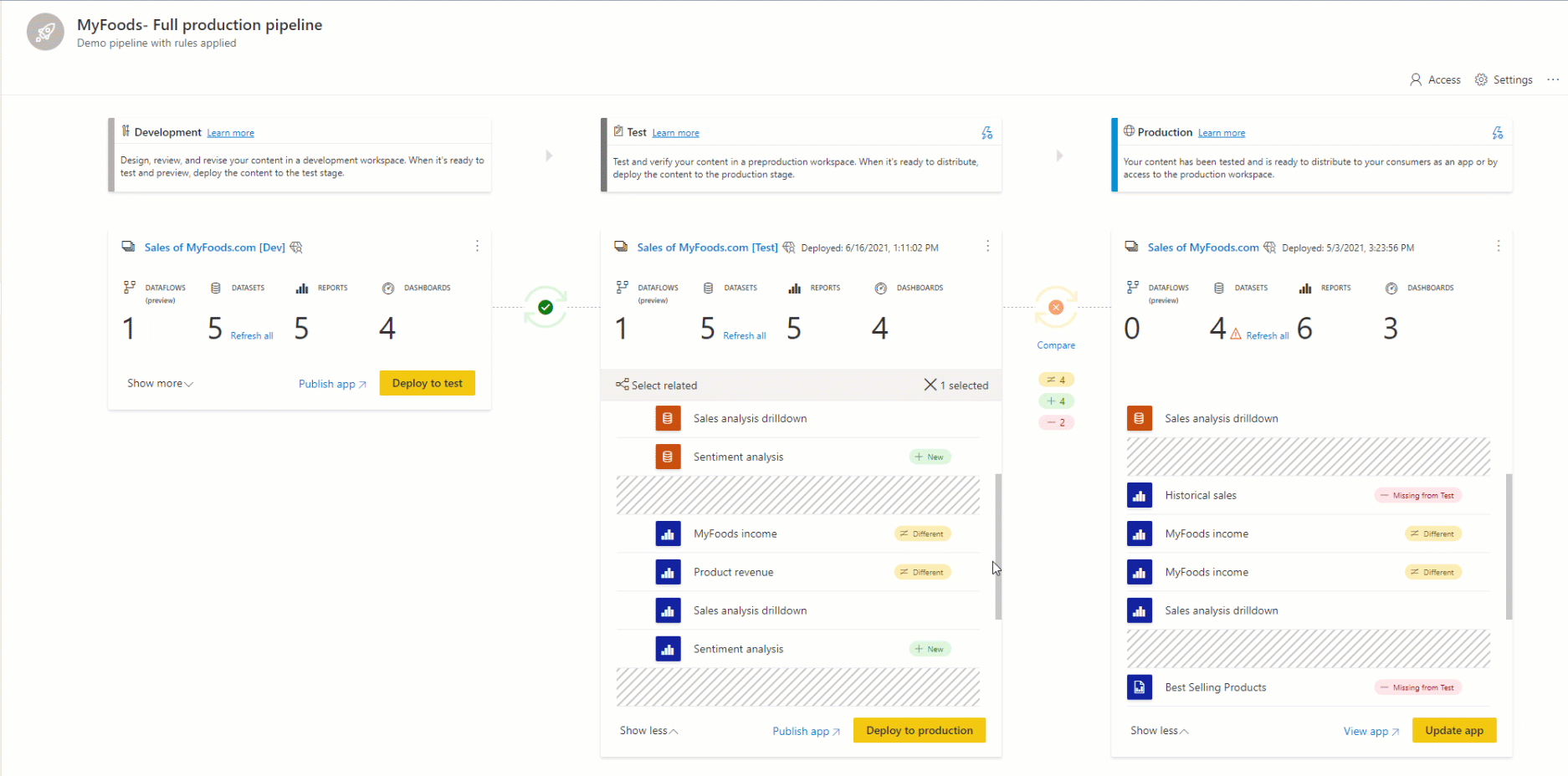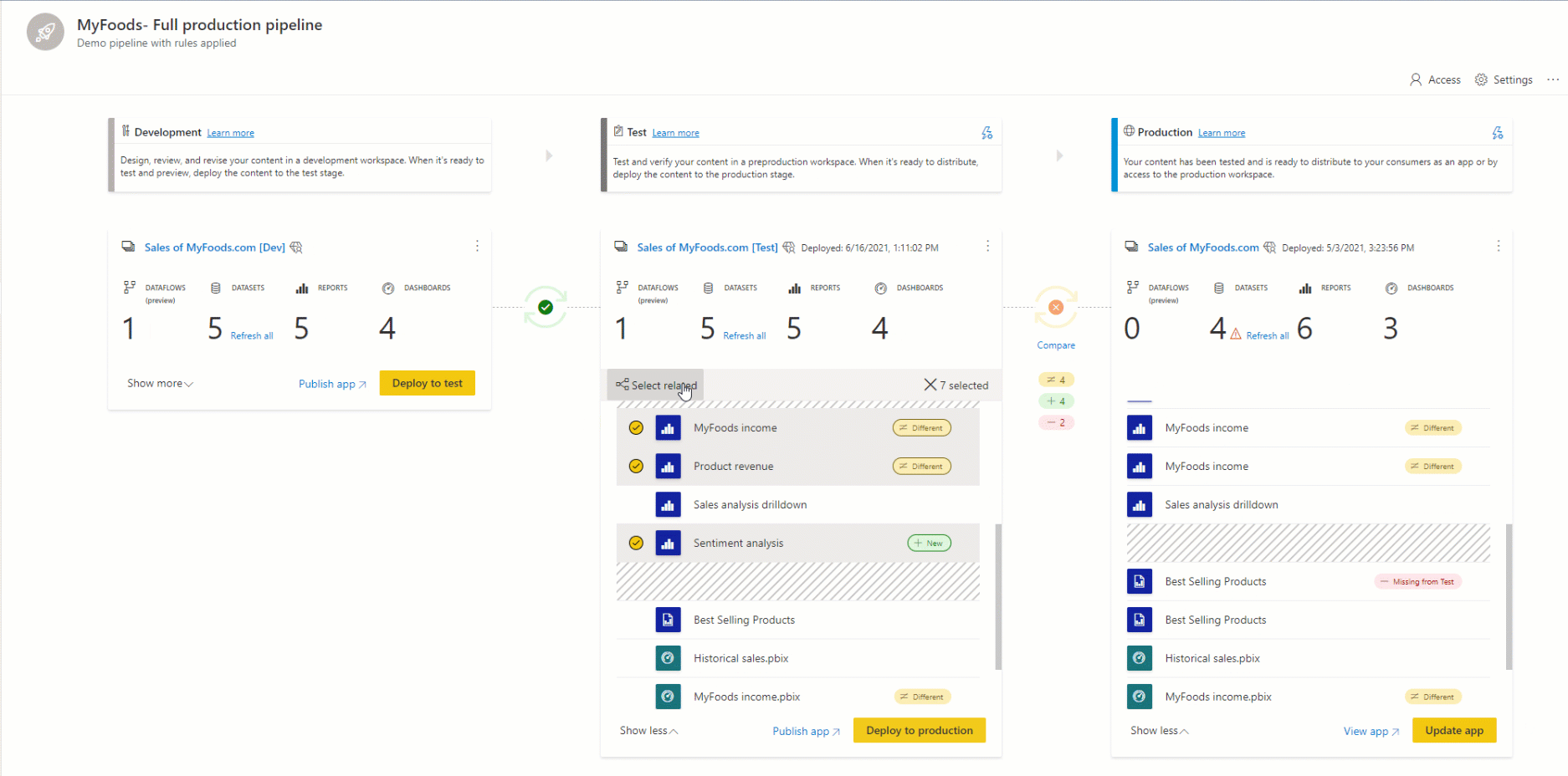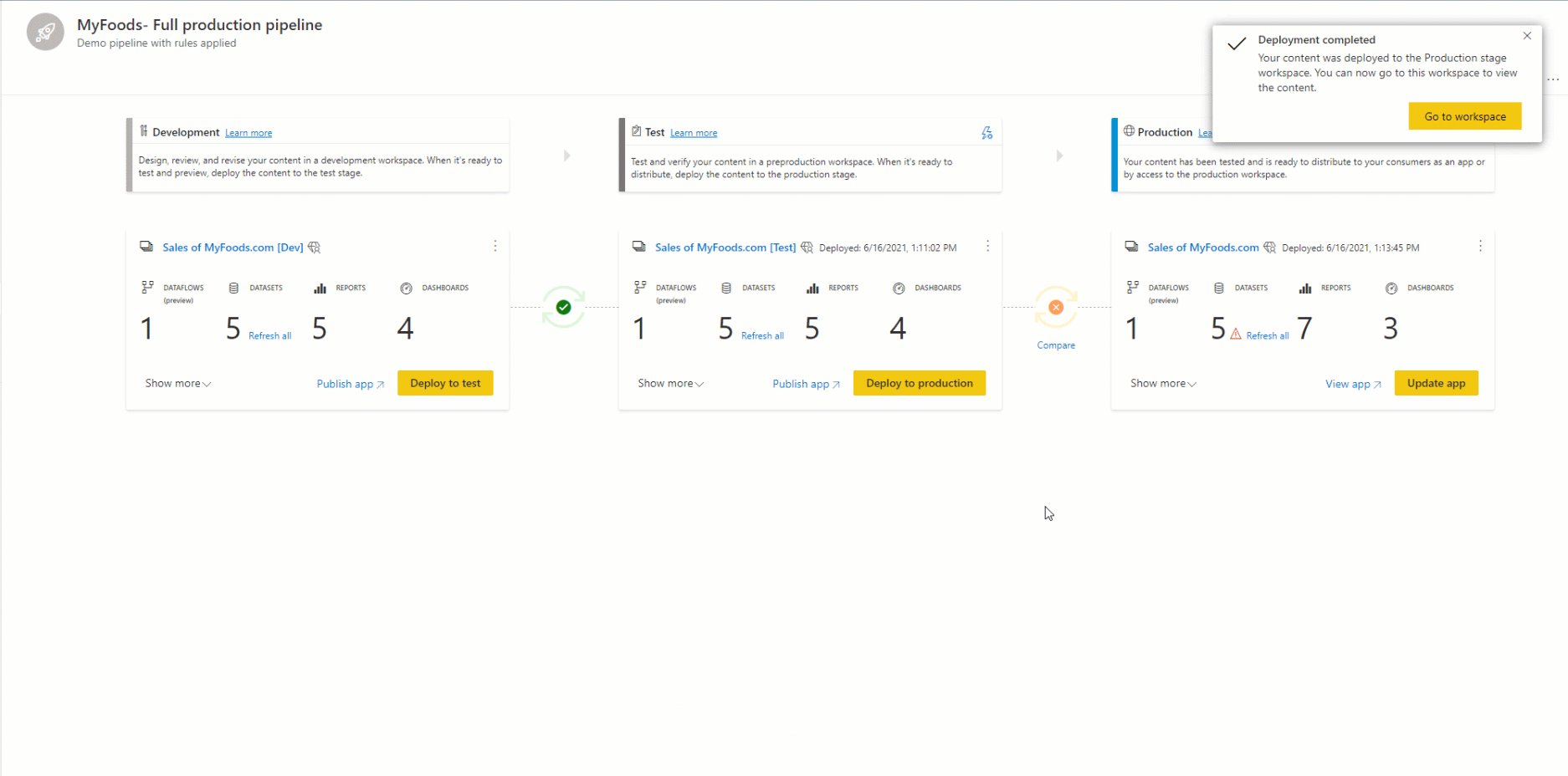
Estrutura do pipeline
Você decide quantas fases deseja ter no seu pipeline de implantação. Pode haver de duas a dez fases. Quando você cria um pipeline, os três estágios típicos padrão são dados como ponto de partida, mas você pode adicionar, excluir ou renomear as fases para atender às suas necessidades. Independentemente de quantos estágios existam, os conceitos gerais são os mesmos:
-
A primeira fase na implantação é quando você faz upload de novos conteúdos com seus colegas criadores. Você pode projetar, criar e desenvolver aqui ou em uma fase diferente.
-
Depois de fazer todas as alterações necessárias no conteúdo, você estará pronto para entrar no estágio de teste. Faça upload do conteúdo modificado para que ele possa ser movido para essa fase de teste. Aqui estão três exemplos do que pode ser feito no ambiente de teste:
Compartilhar conteúdo com testadores e revisores
Carregar e executar testes com volumes maiores de dados
Testar o seu aplicativo para ver a aparência dos usuários finais
-
Depois de testar o conteúdo, use o estágio de produção para compartilhar a versão final do conteúdo com usuários corporativos em toda a organização.
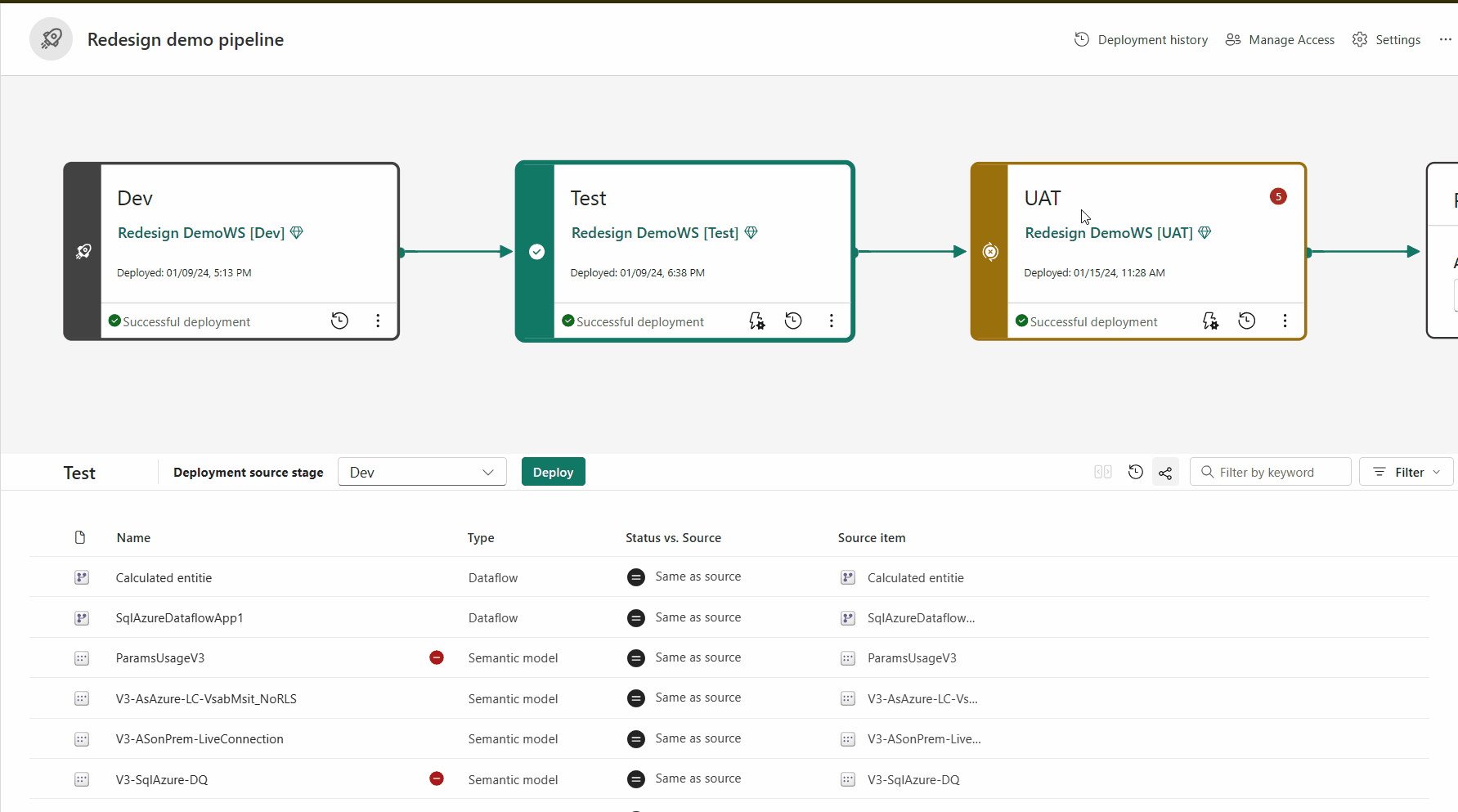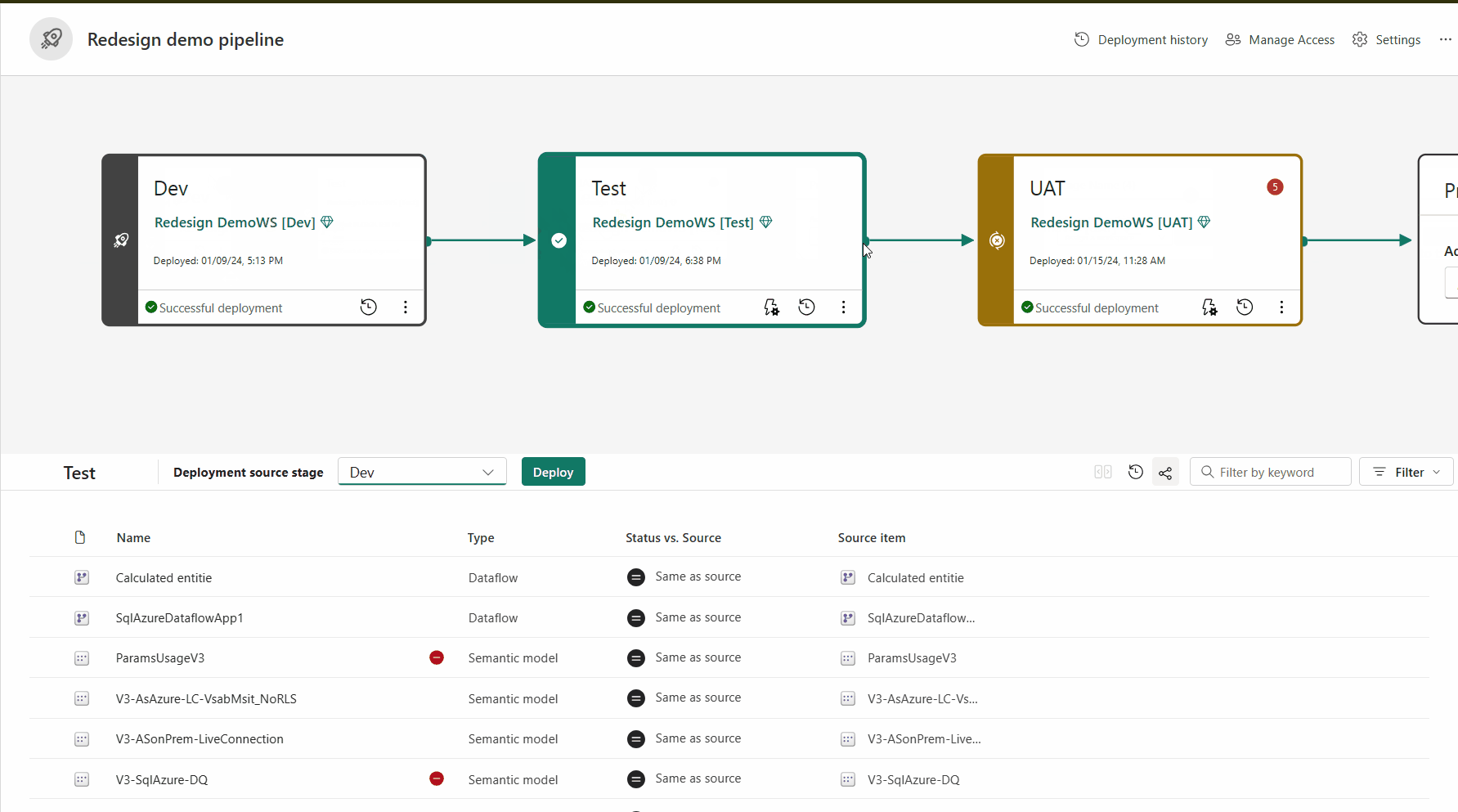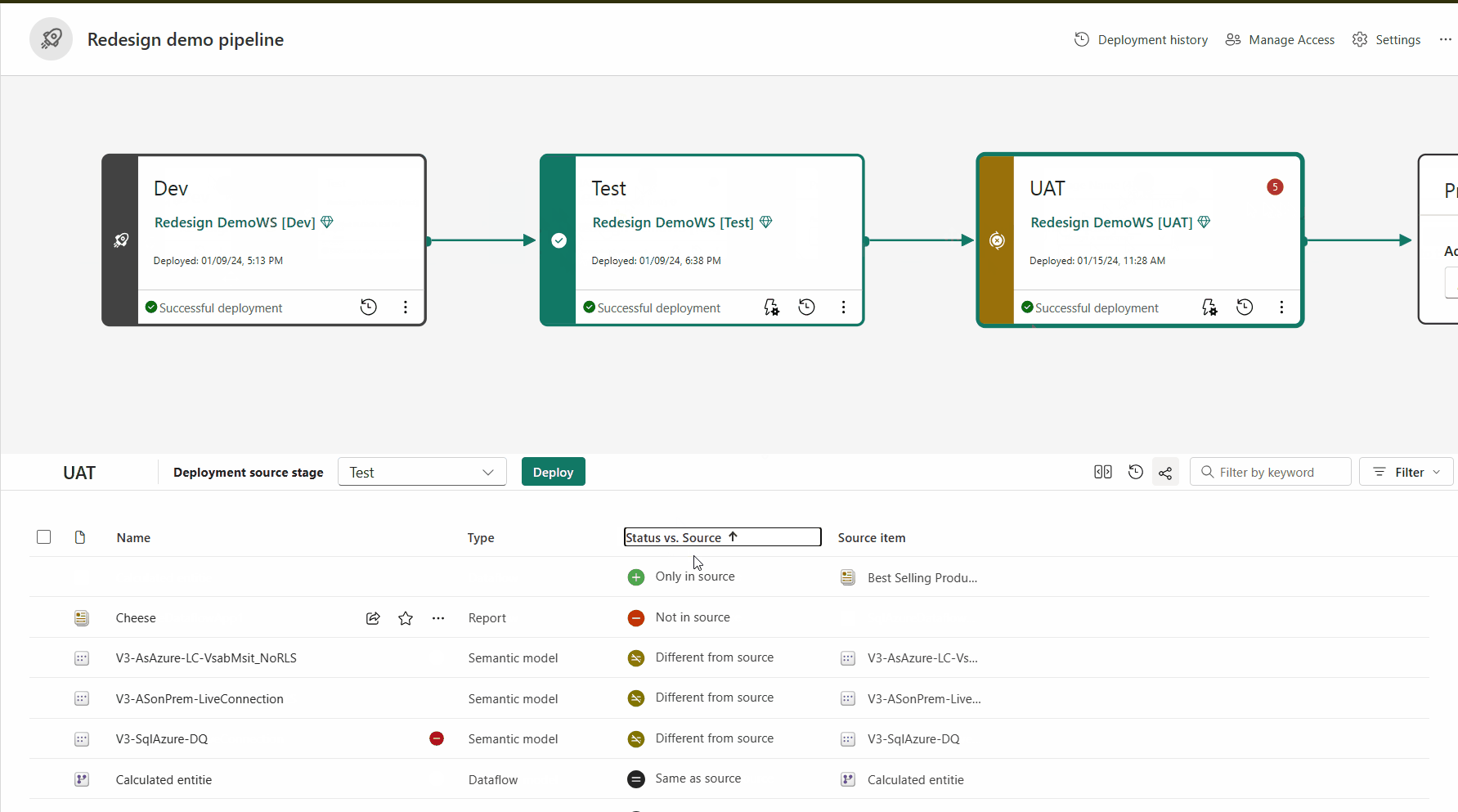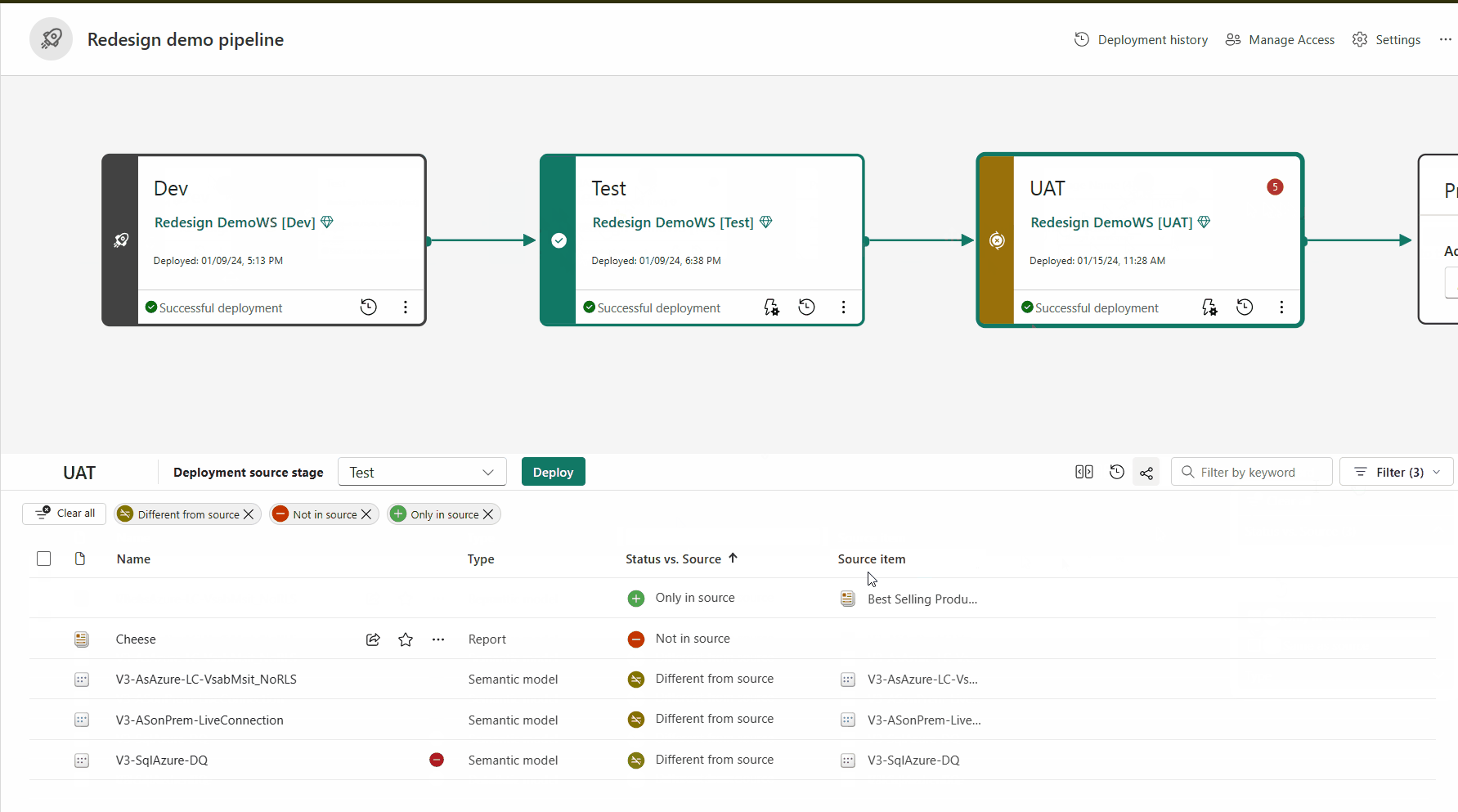
Emparelhamento de itens
O emparelhamento é o processo pelo qual um item (como um relatório, painel ou modelo semântico) em um estágio do pipeline de implantação está associado ao mesmo item no estágio adjacente. O emparelhamento ocorre quando você atribui um workspace a um estágio de implantação ou quando implanta um novo conteúdo não pago de um estágio para outro (uma implantação limpa).
É importante entender como funciona o emparelhamento, para entender quando os itens são copiados, quando eles são substituídos e quando uma implantação falha ao usar a função de implantação.
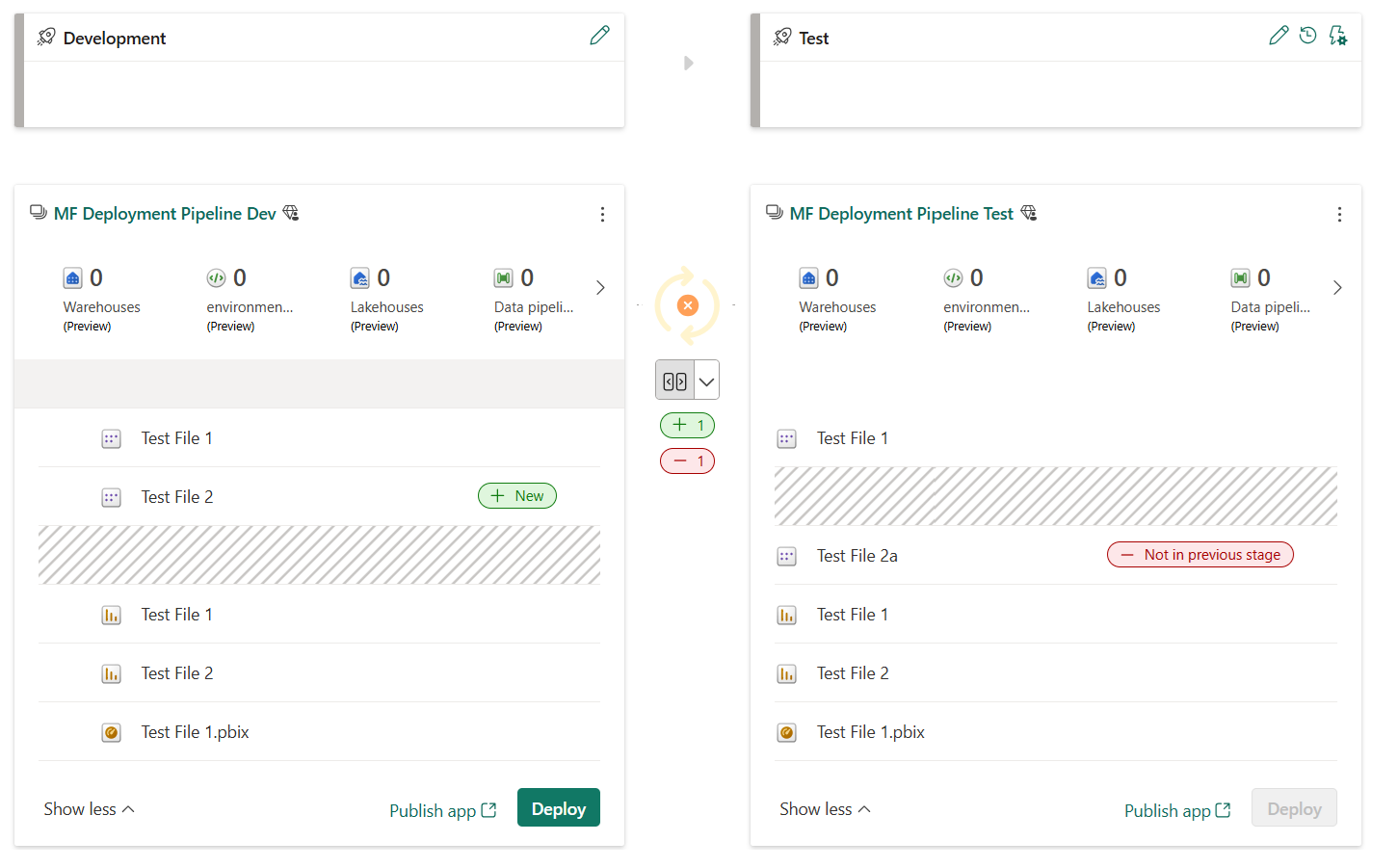
Se os itens não estiverem emparelhados, mesmo que pareçam ser iguais (com o mesmo nome, tipo e pasta), eles não substituem uma implantação. Em vez disso, uma cópia duplicada é criada e emparelhada com o item na fase anterior.
Os itens emparelhados aparecem na mesma linha na lista de conteúdo do pipeline. Os itens que não estão emparelhados aparecem em uma linha sozinhos:
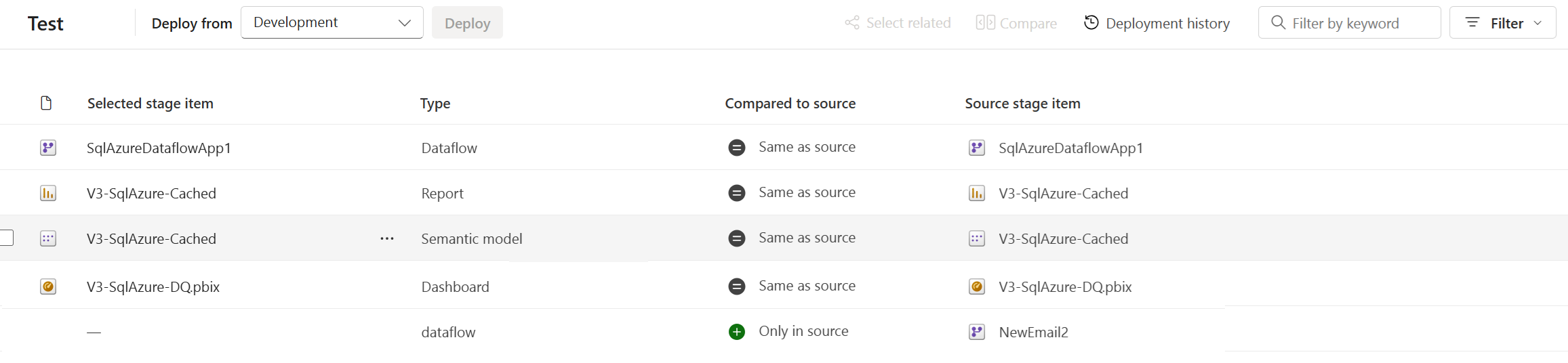
- Os itens emparelhados permanecem emparelhados mesmo se você alterar seus nomes. Portanto, itens emparelhados podem ter nomes diferentes.
- Os itens adicionados depois que o workspace é atribuído a um pipeline não são emparelhados automaticamente. Portanto, você pode ter itens idênticos em workspaces adjacentes que não estão emparelhados.
Para obter uma explicação detalhada de quais itens são emparelhados e como o emparelhamento funciona, confira Emparelhamento de itens.
Método de implantação
Para implantar conteúdo em outra fase, pelo menos um item deve ser selecionado. Quando você implanta o conteúdo de uma fase para outra, os itens que estão sendo copiados da fase de origem substituem o item emparelhado na fase em que você está de acordo com as regras de emparelhamento. Os itens que não existem na fase de origem permanecem como estão.
Depois de selecionar Implantar, você receberá uma mensagem de confirmação.
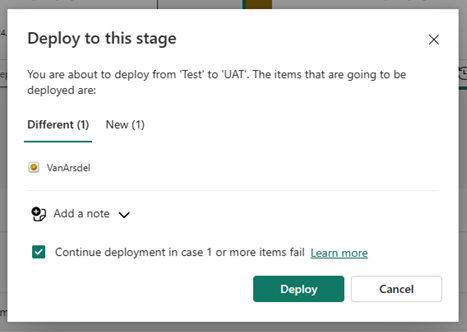
Saiba mais sobre quais propriedades de item são copiadas para a próxima fase e quais propriedades não são copiadas, em Entenda o processo de implantação.
Automação
Você também pode implantar conteúdo programaticamente usando as APIs REST de pipelines de implantação. Você pode saber mais sobre esse processo em Automatizar seu pipeline de implantação usando as APIs e DevOps.