Encontrar clientes semelhantes com IA (versão preliminar)
[Este artigo faz parte da documentação de pré-lançamento e está sujeito a alterações.]
Encontre clientes semelhantes em sua base de clientes usando a inteligência artificial. Você precisa de pelo menos um segmento criado para usar este recurso. Expandir os critérios de um segmento existente ajuda a encontrar clientes que sejam semelhantes a esse segmento.
Nota
Encontrar clientes semelhantes usa meios automatizados para avaliar os dados e fazer previsões com base nesses dados. Portanto, pode ser usado como um método de criação de perfil, já que esse termo é definido por várias leis e regulamentos de privacidade. O uso desse recurso pelos clientes para processar dados pode estar sujeito a essas leis ou regulamentos. Você é responsável por garantir que o uso do Dynamics 365 Customer Insights - Data, incluindo as previsões, esteja em conformidade com todas as leis e regulamentos aplicáveis, incluindo leis relacionadas a privacidade, dados pessoais, dados biométricos, proteção de dados e confidencialidade das comunicações.
Localizar clientes semelhantes
Vá para Insights>Segmentos e selecione o segmento no qual deseja basear o novo segmento. Esse é o seu segmento de origem.
Selecione Encontrar clientes semelhantes.
Revise o nome sugerido para o seu novo segmento e altere-o, se necessário.
Opcionalmente, adicione marcas ao novo segmento.
Revise os campos que definem seu novo segmento. Esses campos definem a base na qual o sistema tentará encontrar clientes semelhantes ao seu segmento de origem. O sistema seleciona os campos recomendados por padrão. Se necessário, adicione mais campos. Os campos que podem reduzir significativamente o desempenho do modelo são excluídos automaticamente:
- Campos com os seguintes tipos de dados: StringType, BooleanType, CharType, LongType, IntType, DoubleType, FloatType, ShortType
- Campos com cardinalidade (o número de elementos em um campo) menor que 2 ou maior que 30
Escolha de deseja incluir Todos os clientes, exceto o segmento de origem ou somente os clientes em um segmento diferente em seu novo segmento.
Por padrão, o sistema sugere incluir apenas 20% do tamanho do público-alvo em sua saída. Edite esse limite, conforme necessário. Aumentar o limite reduzirá a precisão.
Inclua clientes em seu segmento de origem marcando a caixa de seleção Incluir membros do segmento de origem além dos clientes com atributos semelhantes.
Selecione Executar na parte inferior da página para iniciar uma tarefa de classificação binária (um método de aprendizado de máquina) que analisa o conjunto de dados.
Ver o segmento semelhante
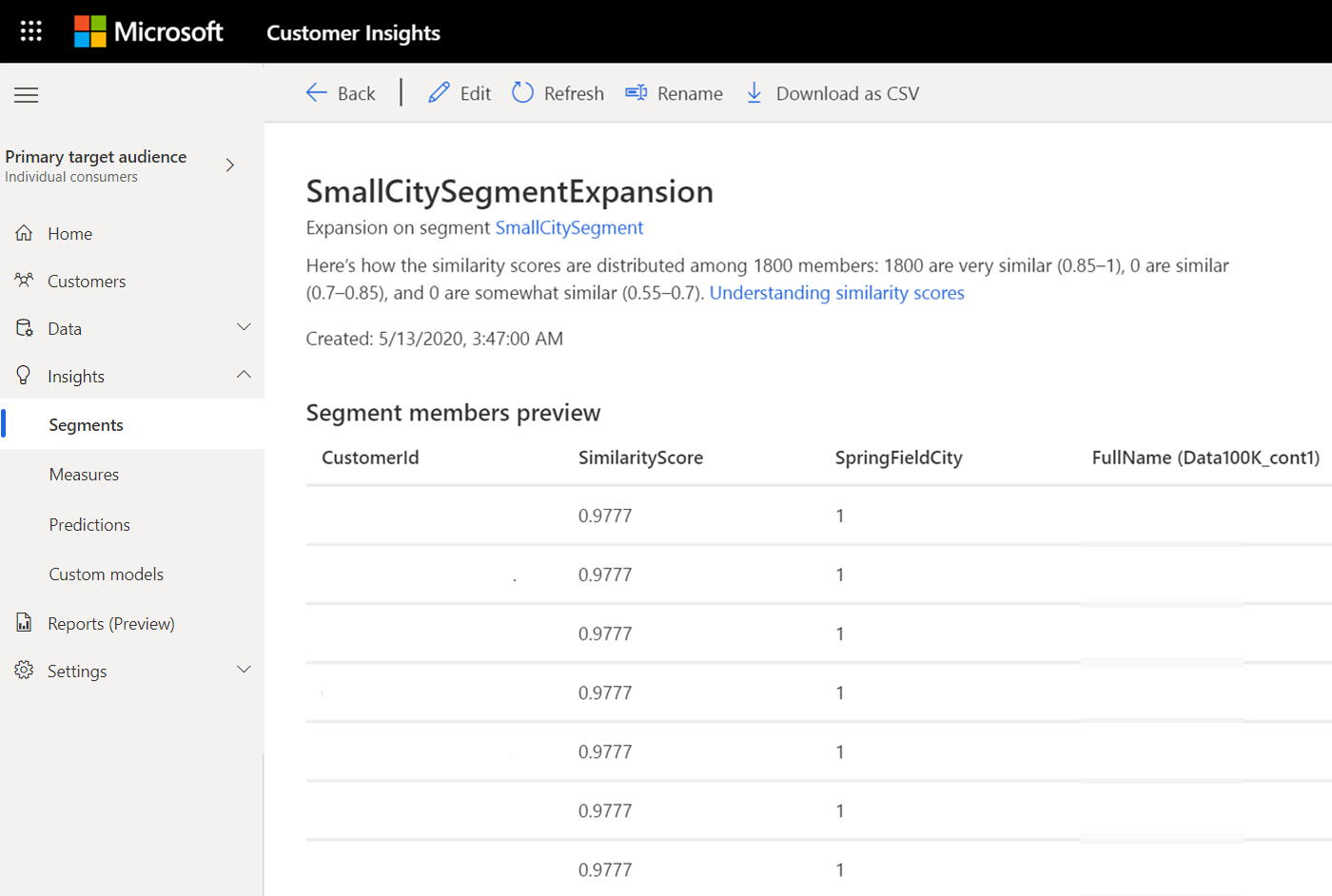
Após o processamento do segmento semelhante, você encontrará o novo segmento listado na página Insights>Segmentos com o tipo Expansão.
Selecione Exibir para ver a distribuição do resultado nas pontuações de similaridade e os valores da pontuação de similaridade em Visualização dos membros do segmento.
Gerenciar um segmento semelhante
Trabalhe e gerencie um segmento semelhante da mesma maneira que faz com outros segmentos. Por exemplo, exporte o segmento ou crie uma medida.
Edite, atualize, renomeie, baixe e exclua um segmento semelhante. Editar um segmento semelhante reprocessa seus dados. O segmento criado anteriormente é atualizado com dados atualizados.
Sobre pontuações de similaridade
O modelo de machine learning de classificação binário atribui uma pontuação aos clientes no segmento semelhante. A pontuação é baseada na semelhança com os clientes no segmento de origem.
- Pontuações de similaridade abaixo de 0,55 são clientes classificados pelo sistema como não similar para clientes no segmento de origem
- As pontuações de similaridade entre 0,55 - 0,7 são classificados como um pouco semelhante
- As pontuações de similaridade entre 0,7 - 0,85 são classificados como um pouco semelhante
- Pontuações de similaridade entre 0,85 - 1 são clientes classificados pelo sistema como muito parecido
Clientes com pontuações de similaridade abaixo de 0,4 não são incluídos na saída do modelo. O sistema não os considera semelhantes o suficiente para o segmento de origem.