Criar, desenvolver e manter notebooks do Synapse
Um notebook no Azure Synapse Analytics (um notebook do Synapse) é uma interface da Web para você criar arquivos que contêm visualizações, textos narrativos e códigos ao vivo. Os notebooks são um bom lugar para validar ideias e fazer experimentos rápidos para obter insights de seus dados. Os notebooks também são amplamente usados na preparação e visualização de dados, no aprendizado de máquina e em outros cenários de Big Data.
Com um notebook Synapse, você pode:
- Começar a trabalhar com um mínimo de configuração.
- Ajude a manter os dados protegidos com recursos internos de segurança corporativa.
- Analise dados em formatos brutos (como CSV, TXT, JSON, etc.), formatos de arquivo processados (Parquet, Delta Lake, ORC etc.) e arquivos de dados tabulares do SQL no Spark e SQL.
- Seja produtivo com recursos de criação aprimorados e visualização de dados interna.
Este artigo descreve como usar notebooks no Synapse Studio.
Criar um notebook
Você pode criar um notebook ou importar um existente para um espaço de trabalho do Synapse no Pesquisador de Objetos. Selecione o menu Desenvolver. Selecione o botão + e o Notebook ou clique com o botão direito do mouse em Notebooks e selecione Novo notebook ou Importar. Os notebooks Synapse podem reconhecer arquivos IPYNB padrão do Jupyter Notebook.
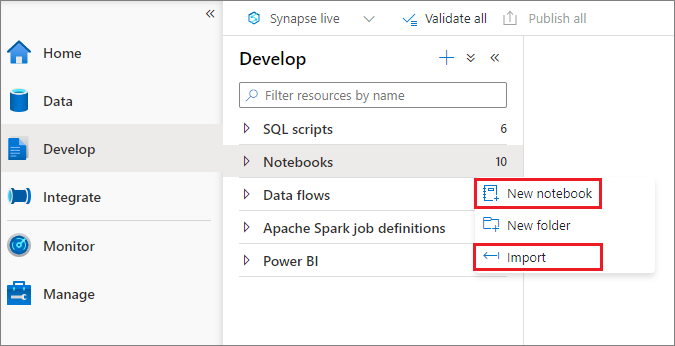
Desenvolver notebooks
Os notebooks consistem em células, que são blocos individuais de código ou texto que você pode executar de forma independente ou em grupo.
As seções a seguir descrevem as operações para o desenvolvimento de notebooks:
- Adicionar uma célula
- Definir uma linguagem principal
- Usar vários idiomas
- Usar tabelas temporárias para referenciar dados entre linguagens
- Usar IntelliSense de estilo IDE
- Usar snippets de código
- Formatar célula de texto usando botões da barra de ferramentas
- Desfazer ou refazer uma operação de célula
- Comentar em uma célula de código
- Mover uma célula
- Copiar uma célula
- Excluir uma célula
- Recolher entrada de célula
- Recolher saída de célula
- Usar uma estrutura de tópicos de notebook
Observação
Nos notebooks, uma instância SparkSession é criada automaticamente para você e armazenada em uma variável chamada spark. Há também uma variável para SparkContext chamada sc. Os usuários podem acessar essas variáveis diretamente, mas não devem alterar os valores dessas variáveis.
Adicionar uma célula
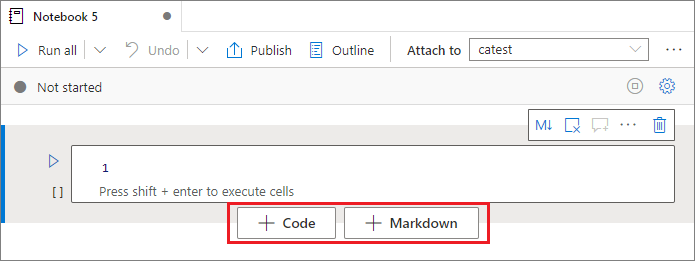
Há várias maneiras de adicionar uma nova célula ao notebook:
Passe o mouse sobre o espaço entre duas células e selecione Código ou Markdown.
Use teclas de atalho no modo de comando. Select a tecla A para inserir uma célula acima da célula atual. Select a tecla B para inserir uma célula abaixo da célula atual.
Definir uma linguagem principal
Os notebooks Synapse dão suporte a quatro linguagens do Apache Spark:
- PySpark (Python)
- Spark (Scala)
- Spark SQL
- .NET Spark (C#)
- SparkR (R)
Você pode definir a linguagem principal de células recém-adicionadas na lista suspensa Linguagem na barra de comandos superior.
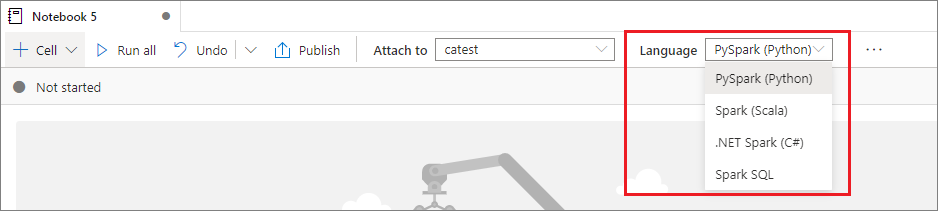
Usar várias linguagens
Você pode usar várias linguagens em um notebook especificando o comando magic da linguagem correto no início de uma célula. A tabela a seguir lista os comandos magic para alternar entre linguagens de célula.
| Comando magic | Linguagem | Descrição |
|---|---|---|
%%pyspark |
Python | Execute uma consulta em Python em SparkContext. |
%%spark |
Scala | Execute uma consulta em Scala em SparkContext. |
%%sql |
Spark SQL | Executar uma consulta em Spark SQL em SparkContext. |
%%csharp |
.NET para Spark C# | Execute uma consulta .NET para Spark C# em SparkContext. |
%%sparkr |
R | Execute uma consulta em R em SparkContext. |
A imagem a seguir mostra um exemplo de como você pode escrever uma consulta em PySpark usando o comando magic %%pyspark ou uma consulta em Spark SQL usando o comando magic %%sql em um notebook do Spark (Scala). A linguagem principal do notebook está definida como PySpark.
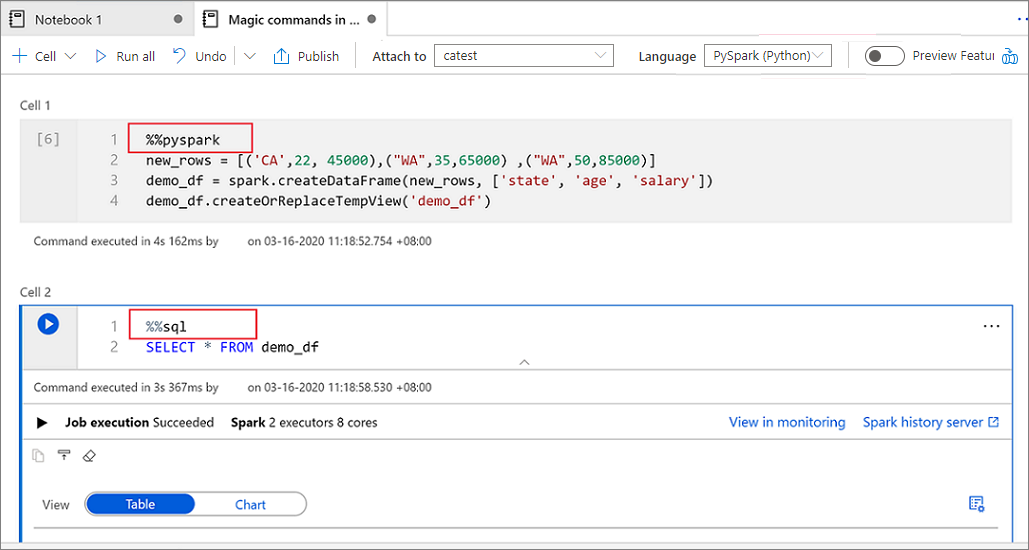
Usar tabelas temporárias para referenciar dados entre linguagens
Você não pode referenciar dados ou variáveis diretamente em linguagens diferentes em um notebook do Synapse. No Spark, você pode referenciar uma tabela temporária entre as linguagens. Veja um exemplo de como ler um DataFrame do Scala no PySpark e no Spark SQL usando uma tabela temporária do Spark como uma solução alternativa:
Na célula 1, leia um DataFrame do conector do pool de SQL usando o Scala e crie uma tabela temporária:
%%spark val scalaDataFrame = spark.read.sqlanalytics("mySQLPoolDatabase.dbo.mySQLPoolTable") scalaDataFrame.createOrReplaceTempView( "mydataframetable" )Na célula 2, consulte os dados com o Spark SQL:
%%sql SELECT * FROM mydataframetableNa célula 3, use os dados no PySpark:
%%pyspark myNewPythonDataFrame = spark.sql("SELECT * FROM mydataframetable")
Usar IntelliSense de estilo IDE
Os notebooks Synapse são integrados ao editor Monaco para colocar o IntelliSense de estilo IDE ao editor de célula. Os recursos de realce de sintaxe, marcador de erros e preenchimento de código automático ajudam você a escrever código e identificar problemas mais rapidamente.
Os recursos do IntelliSense estão em níveis diferentes de maturidade para linguagens diferentes. Use a tabela a seguir para ver o que é suportado.
| Languages | Realce da sintaxe | Marcador de erro de sintaxe | Conclusão de código de sintaxe | Conclusão de código de variável | Conclusão de código de função do sistema | Conclusão do código de função do usuário | Recuo Inteligente | Dobramento de código |
|---|---|---|---|---|---|---|---|---|
| PySpark (Python) | Sim | Sim | Sim | Sim | Sim | Sim | Sim | Sim |
| Spark (Scala) | Sim | Sim | Sim | Sim | Sim | Sim | Não | Sim |
| Spark SQL | Sim | Sim | Sim | Sim | Sim | Não | No | No |
| .NET para Spark (C#) | Sim | Sim | Sim | Sim | Sim | Sim | Sim | Sim |
É necessário ter uma sessão ativa do Spark para se beneficiar do preenchimento do código variável, preenchimento do código da função do sistema e preenchimento do código da função de usuário para .NET para Spark (C#).
Usar trechos de código
Os notebooks do Synapse fornecem trechos de código que facilitam a inserção de padrões de código usados com frequência. Esses padrões incluem configurar sua sessão do Spark, ler dados como um DataFrame do Spark e desenhar gráficos usando Matplotlib.
Os trechos aparecem em teclas de atalho do IntelliSense de estilo IDE misturados com outras sugestões. O conteúdo dos trechos de código é alinhado com a linguagem da célula de código. Você pode ver os trechos disponíveis inserindo snippet ou qualquer palavra-chave que aparece no título do trecho no editor da célula de código. Por exemplo, inserindo read, você pode ver a lista de trechos para ler os dados de várias fontes de dados.

Formatar célula de texto usando botões da barra de ferramentas
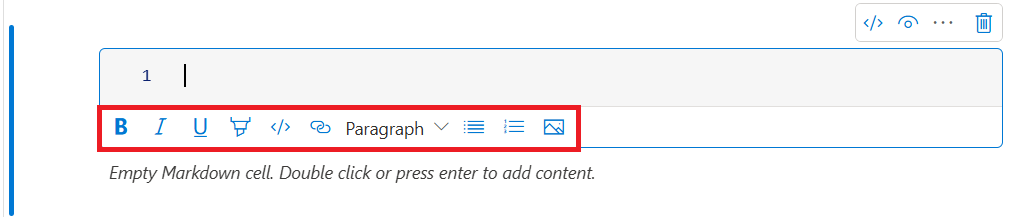
Você pode usar os botões de formatação da barra de ferramentas de células de texto para realizar ações de Markdown comuns. Essas ações incluem colocar o texto em negrito, colocar o texto em itálico, criar parágrafos e títulos por meio de um menu suspenso, inserir código, inserir uma lista não ordenada, inserir uma lista ordenada, inserir um hiperlink e inserir uma imagem de uma URL.
Desfazer ou refazer uma operação de célula
Para revogar as operações de célula mais recentes, selecione o botão Desfazer ou Refazer ou selecione a tecla Z ou Shift + Z. Agora você pode desfazer ou refazer até as últimas 10 operações de células históricas.

As operações de célula com suporte incluem:
- Inserir ou excluir uma célula. Você pode revogar operações de exclusão selecionando Desfazer. Essa ação mantém o conteúdo do texto junto com a célula.
- Reordenar células.
- Ativar ou desativar uma célula de parâmetro.
- Converter entre uma célula de código e uma célula Markdown.
Observação
Você não pode desfazer operações de texto ou operações de comentário em uma célula.
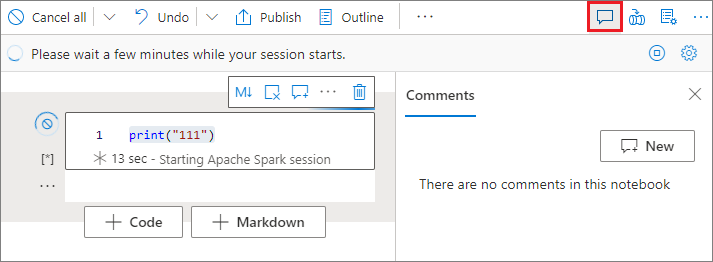
Comentar em uma célula de código
Selecione o botão Comentários na barra de ferramentas do notebook para abrir o painel Comentários.
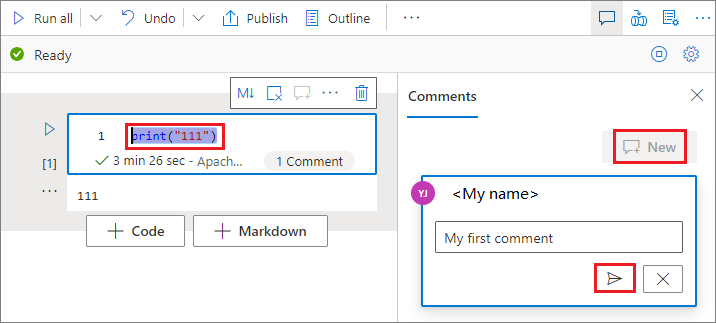
Selecione o código na célula de código, selecione Novo no painel Comentários, adicione os comentários e depois clique no botão Postar comentário.
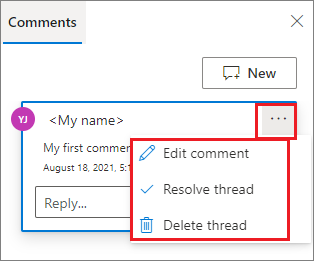
Se necessário, você pode executar Editar comentários, Resolver thread e Excluir ações de thread selecionando as reticências Mais (...) ao lado do seu comentário.
Mover uma célula
Para mover uma célula, selecione o lado esquerdo da célula e arraste a célula para a posição desejada.
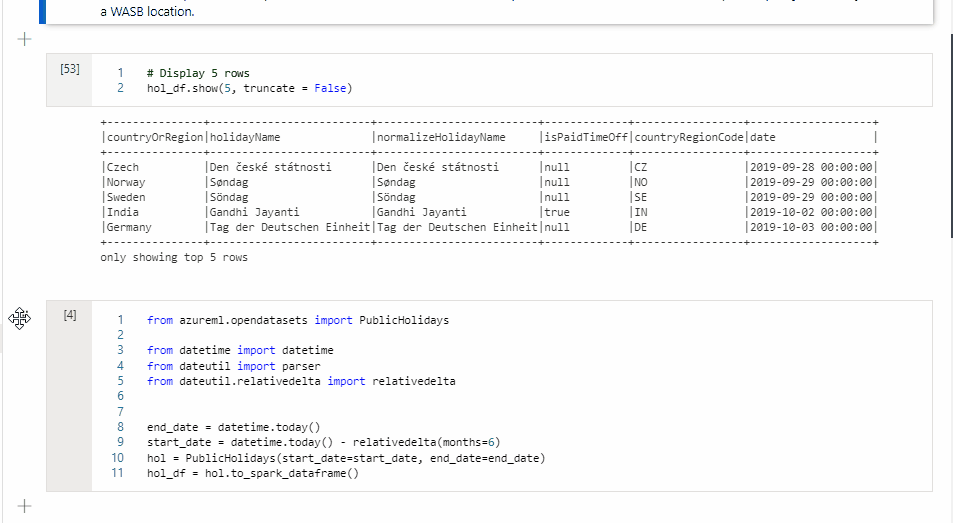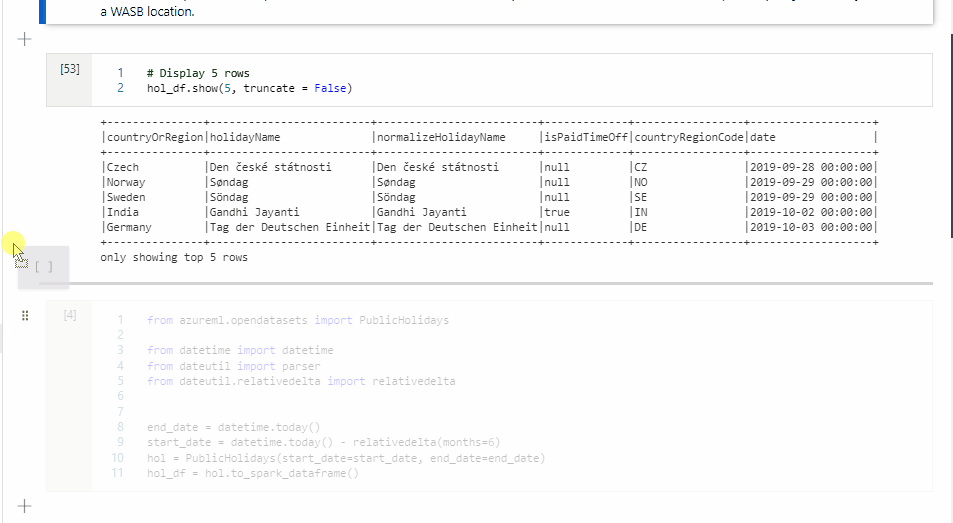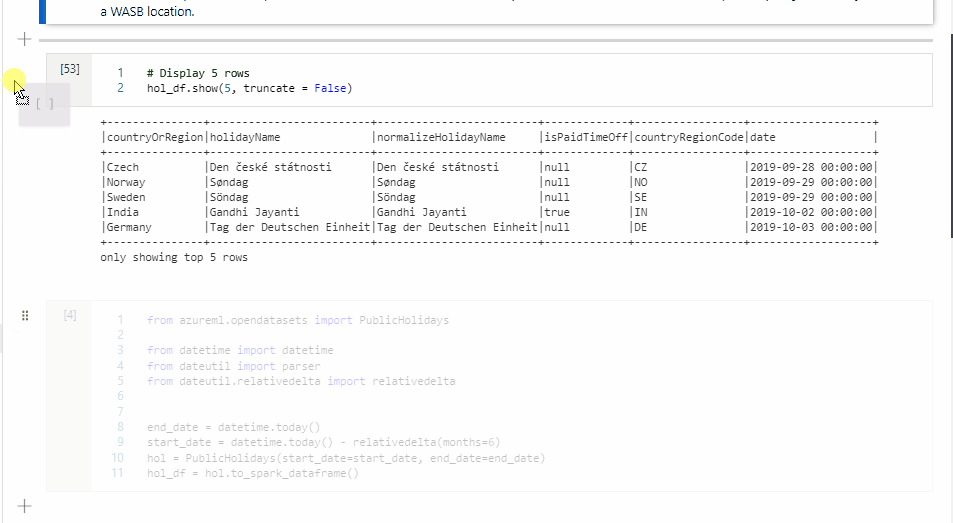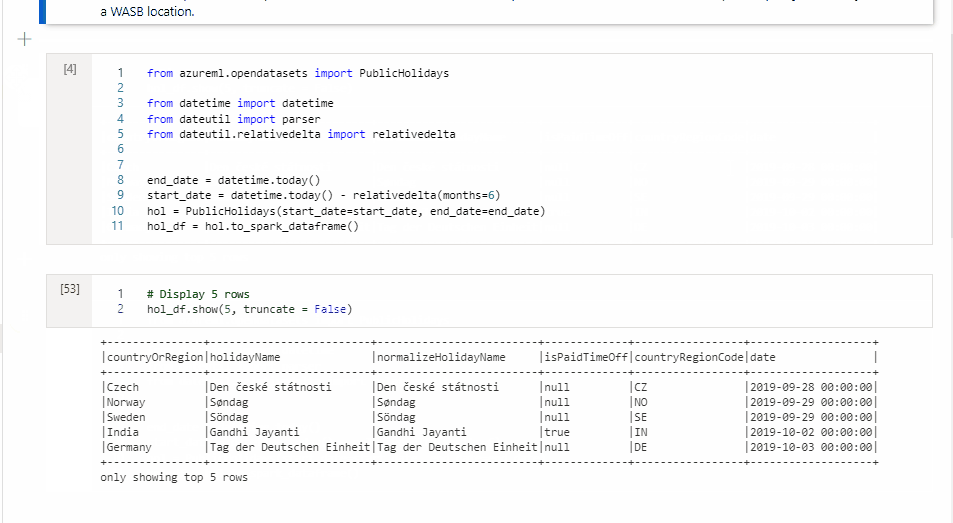
Copiar uma célula
Para copiar uma célula, primeiro crie uma nova célula e selecione todo o texto na célula original, copie o texto e cole-o na nova célula. Quando a célula estiver no modo de edição, os atalhos de teclado tradicionais para selecionar todo o texto ficam limitados à célula.
Dica
Os notebooks do Synapse também fornecem snippets de padrões de código comumente usados.
Excluir uma célula
Para excluir uma célula, selecione o botão Excluir à direita da célula.
Também poderá usar teclas de atalho no modo de comando. Selecione Shift + D para excluir a célula atual.
Recolher entrada de célula
Para recolher a entrada da célula atual, selecione as reticências Mais comandos (...) na barra de ferramentas da célula e selecione Ocultar entrada. Para expandir a entrada, selecione Mostrar entrada enquanto a célula estiver recolhida.
Recolher saída de célula
Para recolher a saída da célula atual, selecione as reticências Mais comandos (...) na barra de ferramentas da célula e selecione Ocultar saída. Para expandir a saída, selecione Mostrar saída enquanto a saída da célula estiver recolhida.
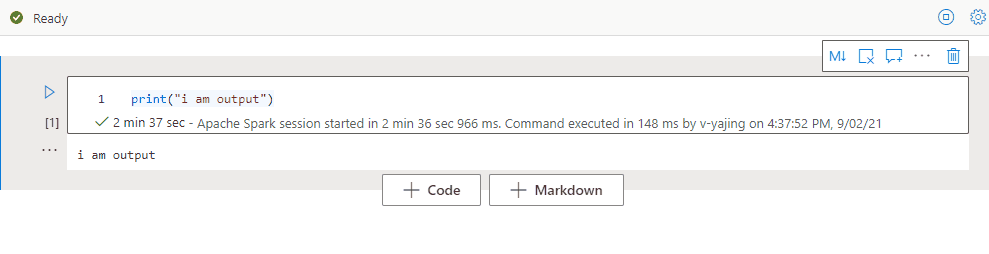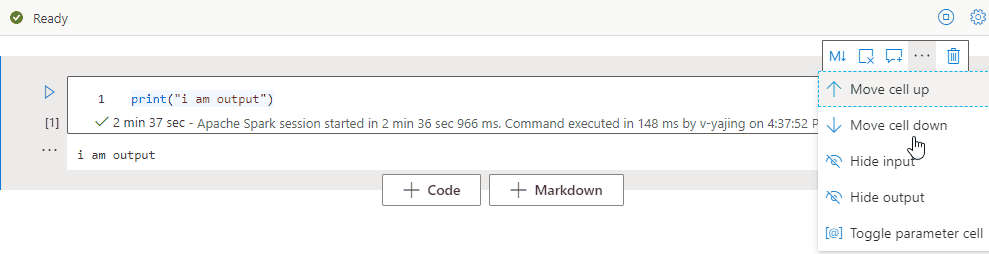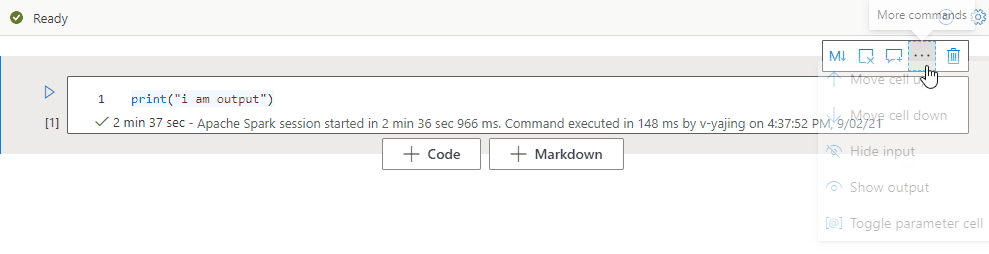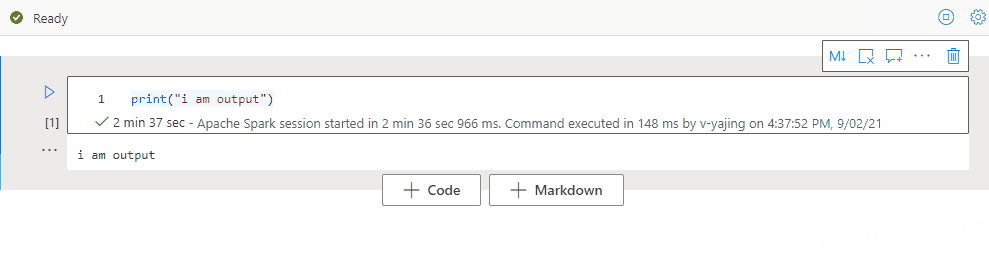
Usar uma estrutura de tópicos de notebook
A estrutura de tópicos (sumário) apresenta o primeiro cabeçalho de Markdown de qualquer célula Markdown em uma janela da barra lateral para navegação rápida. A barra lateral de estrutura de tópicos pode ser redimensionada e recolhida para se ajustar à tela da melhor maneira possível. Para abrir ou ocultar a barra lateral, selecione o botão Estrutura de tópicos na barra de comandos do notebook.
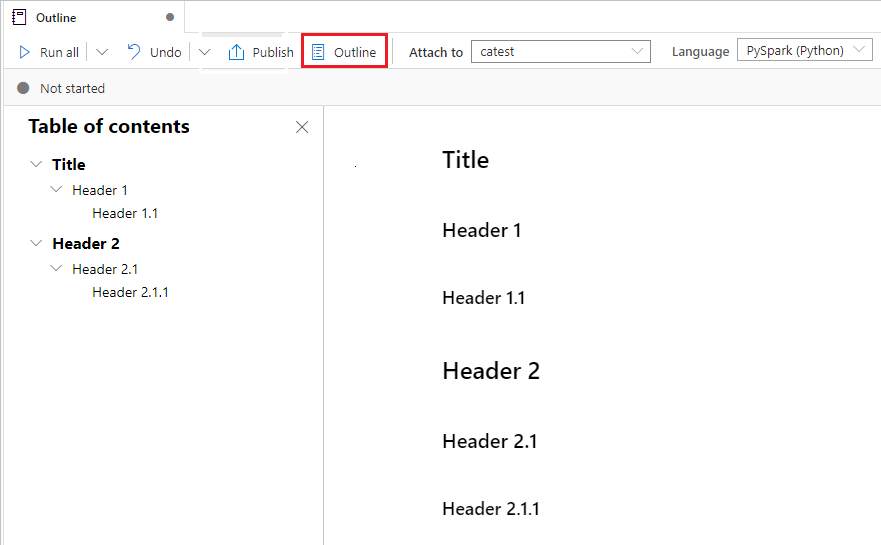
Executar um notebook
Você pode executar as células de código em seu notebook individualmente ou todas de uma vez. O status e o progresso de cada célula aparecem no notebook.
Observação
A exclusão de um notebook não cancela automaticamente os trabalhos que estiverem em execução no momento. Se precisar cancelar um trabalho, visite o hub de Monitoramento e cancele-o manualmente.
Executar uma célula
Há várias maneiras de executar o código em uma célula:
Passe o mouse sobre a célula que você deseja executar e selecione o botão Executar célula ou pressione Ctrl + Enter.

Use teclas de atalho no modo de comando. Selecione Shift + Enter para executar a célula atual e selecionar a célula abaixo dela. Selecione Alt + Enter para executar a célula atual e inserir uma célula abaixo dela.
Executar todas as células
Para executar todas as células do notebook atual em sequência, selecione o botão Executar tudo.

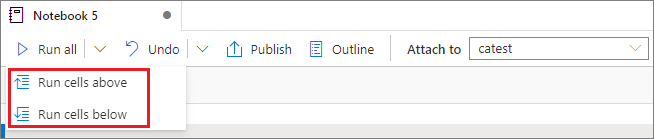
Executar todas as células acima ou abaixo
Para executar todas as células acima da atual em sequência, expanda a lista suspensa do botão Executar tudo e selecione Executar células acima. Selecione Executar células abaixo para executar todas as células abaixo da atual em sequência.
Cancelar todas as células em execução
Para cancelar as células em execução ou as células aguardando na fila, selecione o botão Cancelar tudo.

Referenciar a um notebook
Para referenciar outro notebook no contexto do notebook atual, use o comando mágico %run <notebook path>. Todas as variáveis definidas no bloco de anotações de referência estão disponíveis no notebook atual.
Veja um exemplo:
%run /<path>/Notebook1 { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }
A referência do Notebook funciona tanto no modo interativo quanto nos pipelines.
O comando magic %run tem estas limitações:
- O comando dá suporte a chamadas aninhadas, mas não a chamadas recursivas.
- O comando dá suporte à passagem de um caminho absoluto ou nome de notebook apenas como um parâmetro. Ele não dá suporte a caminhos relativos.
- O comando atualmente só dá suporte a quatro tipos de valor de parâmetro:
int,float,boolestring. Ele não dá suporte a operações de substituição variável. - Os notebooks referenciados devem ser publicados. É necessário publicar os notebooks para referenciá-los, a menos que você selecione a opção para habilitar uma referência de notebook não publicada. O Synapse Studio não reconhece os notebooks não publicados do repositório Git.
- Os notebooks referenciados não dão suporte à instrução cuja profundidade seja maior que cinco.
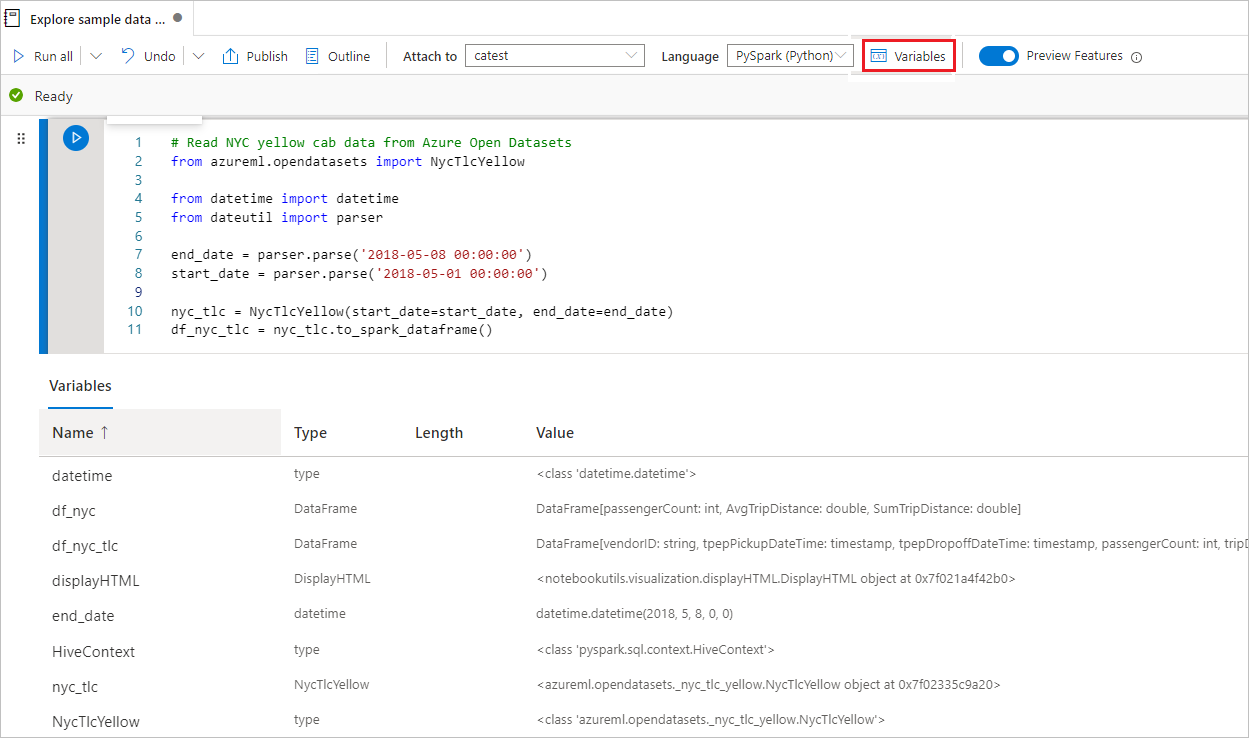
Usar o Gerenciador de Variáveis
Um notebook do Synapse fornece um gerenciador de variáveis interno na forma de uma tabela que lista variáveis na sessão Spark atual para células do PySpark (Python). A tabela inclui colunas para nome, tipo, comprimento e valor da variável. Mais variáveis aparecem automaticamente à medida que são definidas nas células de código. Selecionar cada cabeçalho de coluna classifica as variáveis na tabela.
Para abrir ou ocultar o gerenciador de variáveis, você pode selecionar o botão Variáveis na barra de comandos do notebook.
Observação
O gerenciador de variáveis dá suporte apenas ao Python.
Usar o indicador de status de célula
Um status passo a passo de uma execução de célula aparece abaixo da célula para ajudar você a ver seu progresso atual. Após a conclusão da execução da célula, um resumo com a duração total e a hora de término é exibido e fica lá para referência futura.

Usar o indicador de progresso do Spark
Um notebook do Synapse é baseado exclusivamente no Spark. As células de código são executadas remotamente no pool do Apache Spark sem servidor. Um indicador de progresso do trabalho do Spark com uma barra de progresso em tempo real ajuda você a entender o status de execução do trabalho.
O número de tarefas para cada trabalho ou estágio ajuda você a identificar o nível paralelo do seu trabalho do Spark. Você também pode analisar mais detalhadamente a interface do usuário do Spark de um trabalho (ou fase) específico selecionando o link no nome do trabalho (ou fase).
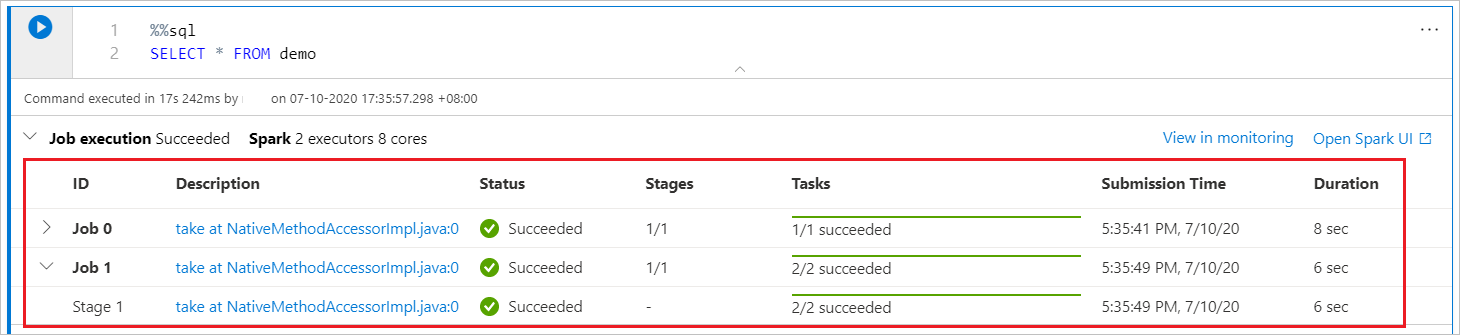
Configurar uma sessão do Spark
No painel Configurar sessão, o qual você pode encontrar selecionando o ícone de engrenagem na parte superior do bloco de notas, você pode especificar a duração do tempo limite, o número e o tamanho dos executores a serem atribuídos à sessão atual do Spark. Reinicie a sessão do Spark para que as alterações de configuração entrem em vigor. Todas as variáveis do notebook em cache serão limpas.
Também é possível criar uma configuração na configuração do Apache Spark ou selecionar uma configuração existente. Para saber detalhes, confira Gerenciar configuração do Apache Spark.
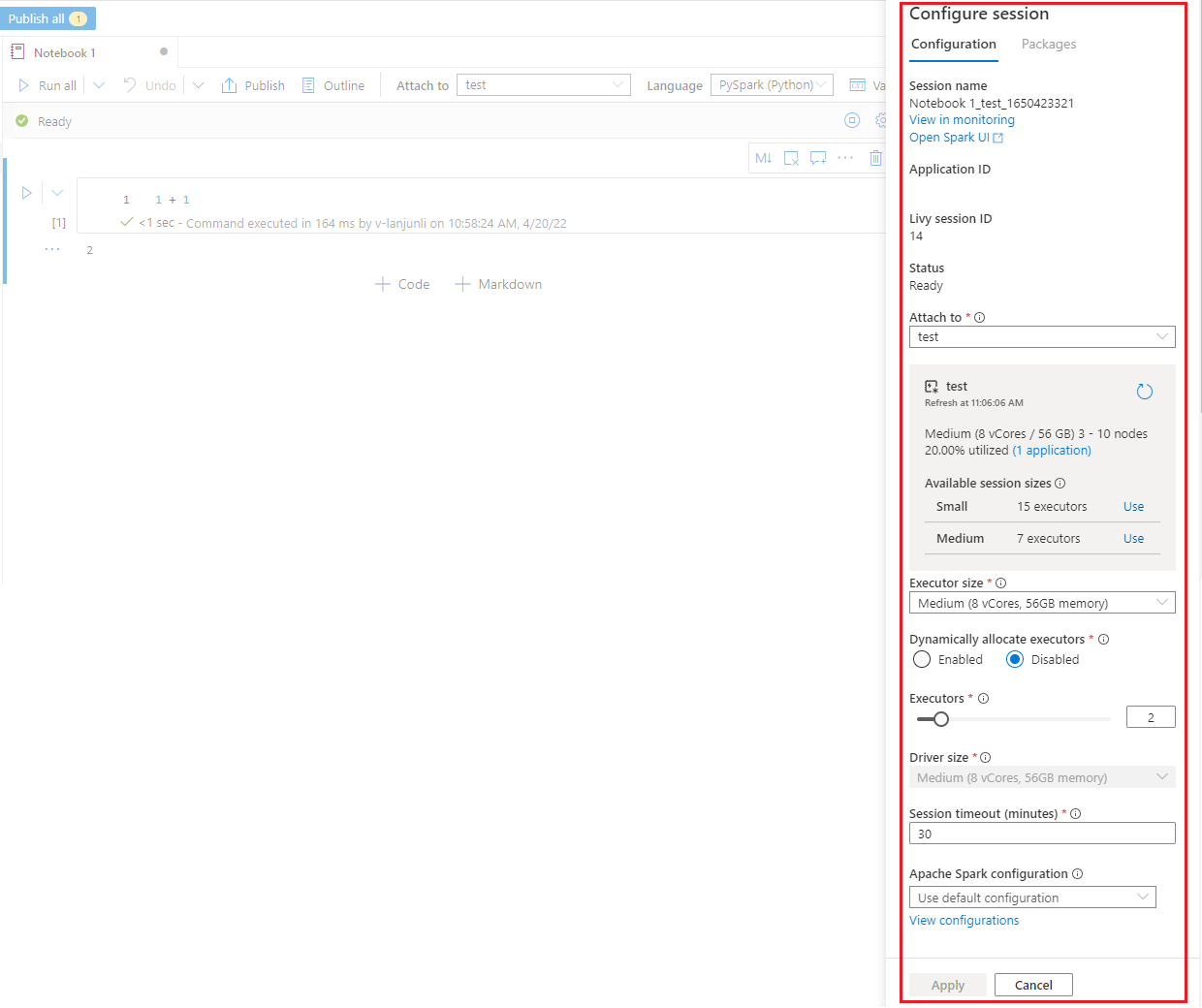
Comando magic para configurar uma sessão do Spark
Você também pode especificar as configurações de sessão do Spark por meio de um comando magic %%configure. Para que as configurações entrem em vigor, reinicie a sessão do Spark.
Recomendamos que você execute %%configure no início do notebook. Veja um exemplo. Para obter a lista completa de parâmetros válidos, consulte as informações do Livy no GitHub.
%%configure
{
//You can get a list of valid parameters to configure the session from https://github.com/cloudera/livy#request-body.
"driverMemory":"28g", // Recommended values: ["28g", "56g", "112g", "224g", "400g", "472g"]
"driverCores":4, // Recommended values: [4, 8, 16, 32, 64, 80]
"executorMemory":"28g",
"executorCores":4,
"jars":["abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path>/myjar.jar","wasb[s]://<containername>@<accountname>.blob.core.windows.net/<path>/myjar1.jar"],
"conf":{
//Example of a standard Spark property. To find more available properties, go to https://spark.apache.org/docs/latest/configuration.html#application-properties.
"spark.driver.maxResultSize":"10g",
//Example of a customized property. You can specify the count of lines that Spark SQL returns by configuring "livy.rsc.sql.num-rows".
"livy.rsc.sql.num-rows":"3000"
}
}
Veja algumas considerações quanto ao comando magic %%configure:
- Recomendamos que você use o mesmo valor para
driverMemoryeexecutorMemoryem%%configure. Também recomendamos quedriverCoreseexecutorCorestenham o mesmo valor. - Você pode usar
%%configureem pipelines do Synapse, mas se ele não estiver definido na primeira célula de código, a execução de pipeline falhará porque não é possível reiniciar a sessão. - O comando
%%configureusado emmssparkutils.notebook.runé ignorado, mas o comando usado em%run <notebook>continua a ser executado. - Você deve usar as propriedades de configuração padrão do Spark no corpo de
"conf". Não damos suporte para a referência de primeiro nível nas propriedades de configuração do Spark. - Algumas propriedades especiais do Spark não entrarão em vigor no corpo de
"conf", incluindo"spark.driver.cores","spark.executor.cores","spark.driver.memory","spark.executor.memory"e"spark.executor.instances".
Configuração de sessão parametrizada de um pipeline
Você pode usar a configuração de sessão parametrizada para substituir o valor do comando magic %%configure por parâmetros de execução de pipeline (atividade do notebook). Ao preparar uma célula de código %%configure, você pode substituir valores padrão usando um objeto como este:
{
"activityParameterName": "parameterNameInPipelineNotebookActivity",
"defaultValue": "defaultValueIfNoParameterFromPipelineNotebookActivity"
}
O exemplo a seguir mostra valores padrão de 4 e "2000", que também são configuráveis:
%%configure
{
"driverCores":
{
"activityParameterName": "driverCoresFromNotebookActivity",
"defaultValue": 4
},
"conf":
{
"livy.rsc.sql.num-rows":
{
"activityParameterName": "rows",
"defaultValue": "2000"
}
}
}
O notebook usa o valor padrão se você executar o notebook diretamente no modo interativo ou se a atividade do notebook do pipeline não fornecer nenhum parâmetro que corresponda a "activityParameterName".
Durante o modo de execução do pipeline, você pode usar a guia Configurações para definir as configurações de uma atividade de notebook do pipeline.
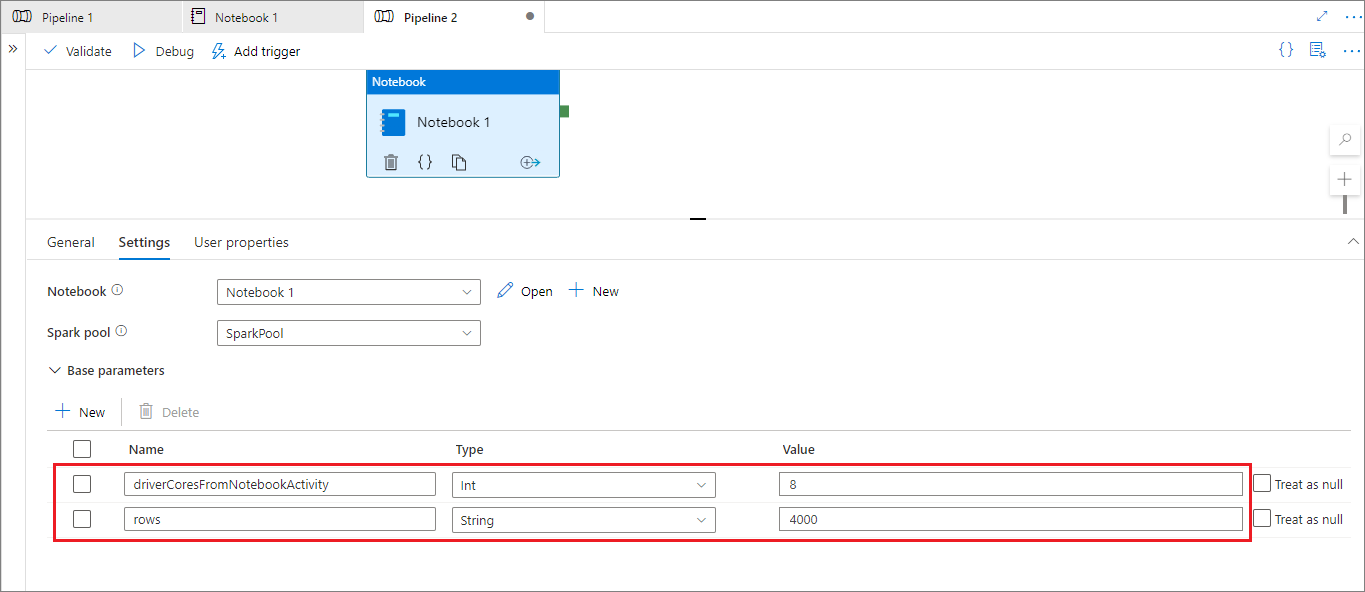
Caso queira alterar a configuração da sessão, o nome do parâmetro da atividade de notebook do pipeline deve ser o mesmo que activityParameterName no notebook. Neste exemplo, durante uma execução de pipeline, 8 substitui driverCores em %%configure e 4000 substitui livy.rsc.sql.num-rows.
Se uma execução de pipeline falhar depois que usar o comando magic %%configure, você pode encontrar mais informações do erro executando a célula do magic %%configure no modo interativo do notebook.
Trazer dados para um notebook
Você pode carregar dados do Azure Data Lake Storage Gen2, Armazenamento de Blobs do Azure e de pools de SQL, como mostrado nos exemplos de código abaixo.
Ler um arquivo CSV do Azure Data Lake Storage Gen2 como um DataFrame do Spark
from pyspark.sql import SparkSession
from pyspark.sql.types import *
account_name = "Your account name"
container_name = "Your container name"
relative_path = "Your path"
adls_path = 'abfss://%s@%s.dfs.core.windows.net/%s' % (container_name, account_name, relative_path)
df1 = spark.read.option('header', 'true') \
.option('delimiter', ',') \
.csv(adls_path + '/Testfile.csv')
Ler um arquivo CSV do Armazenamento de Blobs do Azure como um DataFrame do Spark
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow Spark to access from Azure Blob Storage remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
df = spark.read.option("header", "true") \
.option("delimiter","|") \
.schema(schema) \
.csv(wasbs_path)
Ler dados da conta de armazenamento primária
Você pode acessar os dados na conta de armazenamento principal diretamente. Não é necessário fornecer as chaves secretas. No Data Explorer, clique com o botão direito do mouse em um arquivo e selecione Novo notebook para ver um novo notebook com o extrator de dados gerado automaticamente.
Usar widgets de IPython
Os widgets são objetos do Python com eventos que têm uma representação no navegador, geralmente como um controle deslizante ou caixa de texto. Os widgets do IPython funcionam apenas em ambientes Python. Atualmente, não há suporte para eles em outras linguagens (por exemplo, Scala, SQL ou C#).
Etapas para usar widgets do IPython
Importe o módulo
ipywidgetspara usar a estrutura de Widgets do Jupyter:import ipywidgets as widgetsUse a função
displayde nível superior para renderizar um widget ou deixar uma expressão do tipowidgetna última linha da célula de código:slider = widgets.IntSlider() display(slider)slider = widgets.IntSlider() sliderExecute a célula. O widget aparece na área de saída.
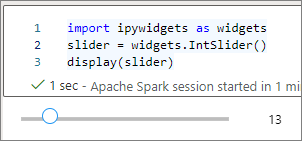
Você pode usar várias chamadas a display() para renderizar várias vezes a mesma instância de widget, mas elas permanecem em sincronia:
slider = widgets.IntSlider()
display(slider)
display(slider)
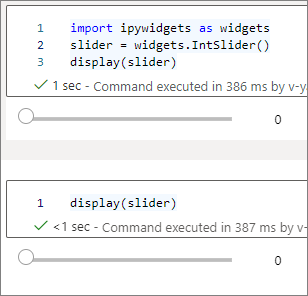
Para renderizar dois widgets independentes, crie duas instâncias de widget:
slider1 = widgets.IntSlider()
slider2 = widgets.IntSlider()
display(slider1)
display(slider2)
Widgets com suporte
| Tipo de widget | Widgets: |
|---|---|
| Numérico |
IntSlider, FloatSlider, FloatLogSlider, IntRangeSlider, FloatRangeSlider, IntProgress, FloatProgress, BoundedIntText, BoundedFloatText, IntText, FloatText |
| Booliano |
ToggleButton, Checkbox, Valid |
| Seleção |
Dropdown, RadioButtons, Select, SelectionSlider, SelectionRangeSlider, ToggleButtons, SelectMultiple |
| String |
Text, Text area, Combobox, Password, Label, HTML, HTML Math, Image, Button |
| Reprodução (animação) |
Date picker, Color picker, Controller |
| Contêiner/Layout |
Box, HBox, VBox, GridBox, Accordion, Tabs, Stacked |
Limitações conhecidas
A tabela a seguir lista widgets que não têm suporte no momento, juntamente com soluções alternativas:
Funcionalidade Solução alternativa Widget OutputEm vez disso, use a função print()para escrever texto nostdout.widgets.jslink()Use a função widgets.link()para vincular dois widgets parecidos.Widget FileUploadNão disponível. A função
displayglobal fornecida pelo Azure Synapse Analytics não dá suporte à exibição de vários widgets em uma chamada (ou seja,display(a, b)). Esse comportamento é diferente da funçãodisplaydo IPython.Se você fechar um notebook que contenha um widget do IPython, não poderá exibir ou interagir com ele até executar a célula correspondente novamente.
Salvar notebooks
Você pode salvar um único notebook ou todos eles em seu espaço de trabalho:
Para salvar as alterações feitas em um único notebook, selecione o botão Publicar na barra de comandos do notebook.

Para salvar todos os notebooks em seu espaço de trabalho, selecione o botão Publicar tudo na barra de comandos do espaço de trabalho.

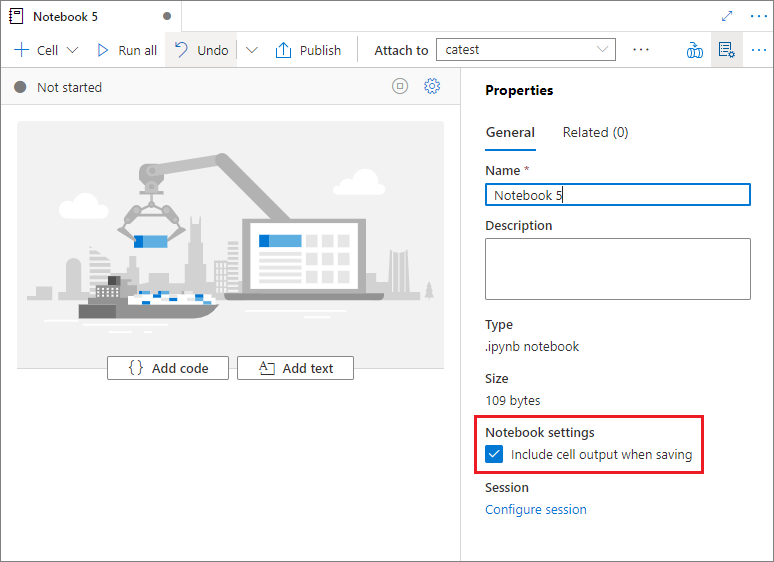
No painel Propriedades do notebook, você pode configurar se deseja incluir a saída da célula ao salvar.
Usar comandos magic
Você pode usar seus comandos magic do Jupyter conhecidos nos notebooks Synapse. Confira as listas a seguir de comandos magic disponíveis no momento. Fale para nós dos seus casos de uso no GitHub para que possamos continuar a criar mais comandos magic e atender às suas necessidades.
Observação
Apenas os comandos magic a seguir têm suporte em pipelines do Synapse: %%pyspark, %%spark, %%csharp e %%sql.
Comandos magic disponíveis para linhas:
%lsmagic, %time, %timeit, %history, %run, %load
Comandos magic disponíveis para células:
%%time, %%timeit, %%capture, %%writefile, %%sql, %%pyspark, %%spark, %%csharp, %%html, %%configure
Referenciar um notebook não publicado
Referenciar um notebook não publicado é útil quando você quer depurar localmente. Quando você habilita esse recurso, uma execução de notebook busca o conteúdo atual no cache da Web. Se você executar uma célula que inclui uma instrução de referência de notebook, faça referência aos notebooks presentes no navegador do notebook atual em vez de uma versão salva em um cluster. Outros notebooks podem referenciar as alterações no editor do notebook sem exigir que você publique (modo dinâmico) ou confirme (modo Git) as alterações. Usando essa abordagem, você pode evitar a poluição de bibliotecas comuns durante o processo de desenvolvimento ou depuração.
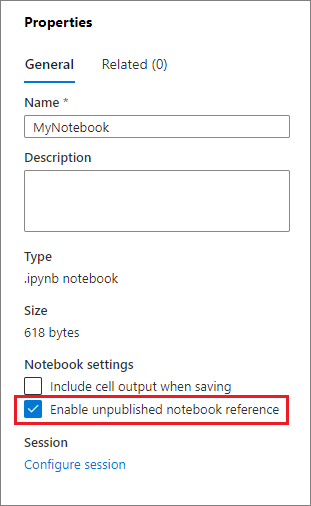
Você pode habilitar a referência a um notebook não publicado selecionando a caixa de seleção apropriada no painel Propriedades.
A tabela a seguir compara os casos. Embora %run e mssparkutils.notebook.run tenham o mesmo comportamento aqui, a tabela usa %run como exemplo.
| Case | Desabilitar | Habilitar |
|---|---|---|
| Modo dinâmico | ||
Nb1 (publicado) %run Nb1 |
Executar a versão publicada do Nb1 | Executar a versão publicada do Nb1 |
Nb1 (novo) %run Nb1 |
Erro | Executar um novo Nb1 |
Nb1 (publicado anteriormente, editado) %run Nb1 |
Executar a versão publicada do Nb1 | Executar a versão editada do Nb1 |
| Modo Git | ||
Nb1 (publicado) %run Nb1 |
Executar a versão publicada do Nb1 | Executar a versão publicada do Nb1 |
Nb1 (novo) %run Nb1 |
Erro | Executar um novo Nb1 |
Nb1 (não publicado, confirmado) %run Nb1 |
Erro | Executar um Nb1 confirmado |
Nb1 (publicado anteriormente, confirmado) %run Nb1 |
Executar a versão publicada do Nb1 | Executar a versão confirmada do Nb1 |
Nb1 (publicado anteriormente, novo no branch atual) %run Nb1 |
Executar a versão publicada do Nb1 | Executar um novo Nb1 |
Nb1 (não publicado, confirmado anteriormente, editado) %run Nb1 |
Erro | Executar a versão editada do Nb1 |
Nb1 (anteriormente publicado e confirmado, editado) %run Nb1 |
Executar a versão publicada do Nb1 | Executar a versão editada do Nb1 |
Em resumo:
- Se você desabilitar a referência a um notebook não publicado, sempre execute a versão publicada.
- Se você habilitar a referência a um notebook não publicado, a execução de referência sempre adotará a versão atual do notebook que aparece na UX do notebook.
Gerenciar sessões ativas
É possível reutilizar suas sessões de notebook sem precisar iniciar novas. Em notebooks do Synapse, você pode gerenciar suas sessões ativas em uma única lista. Para abrir a lista, selecione as reticências (...) e selecione Gerenciar sessões.
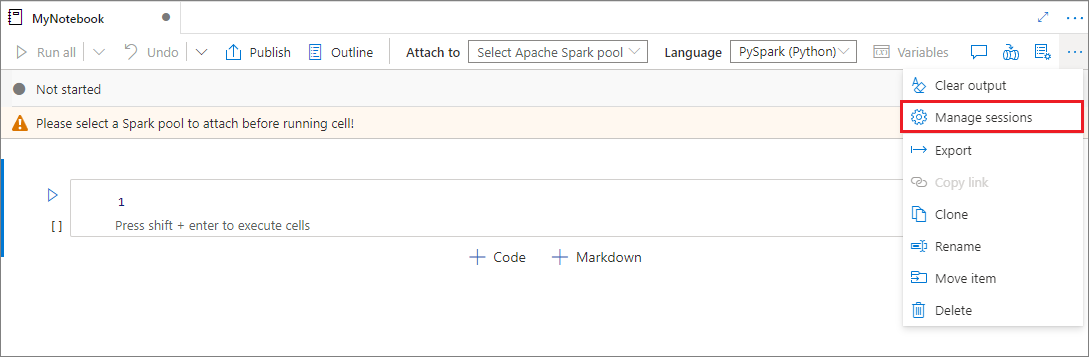
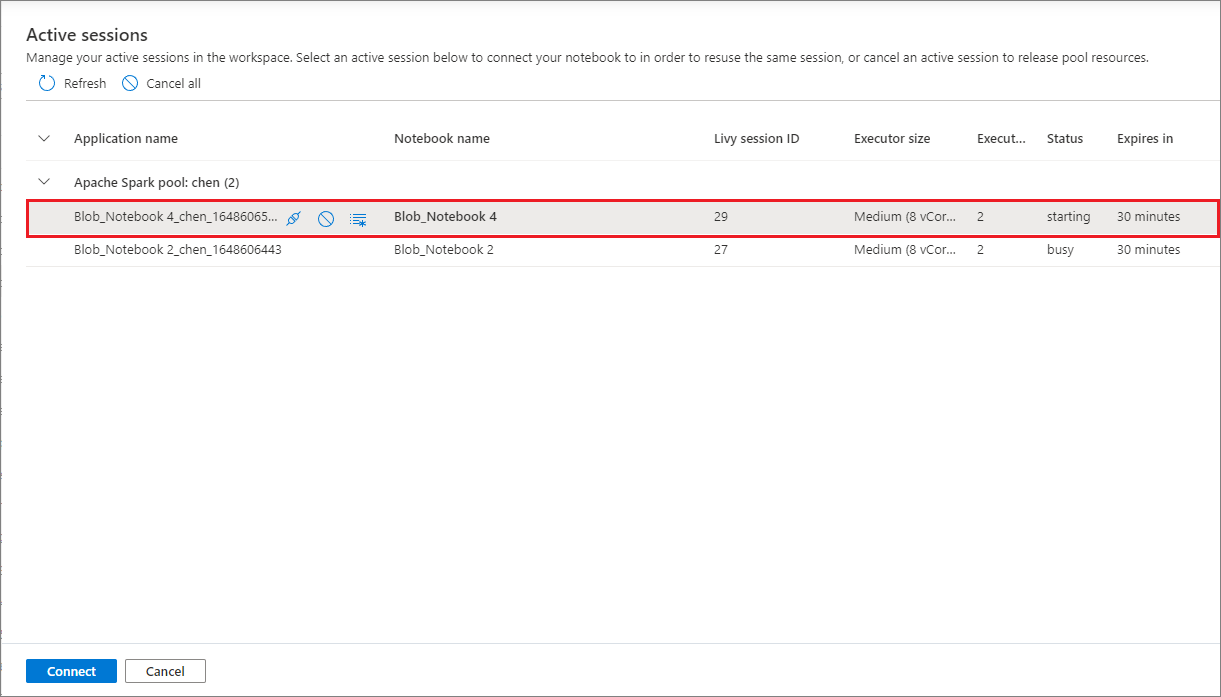
O painel Sessões ativas lista todas as sessões no espaço de trabalho atual que você iniciou a partir de um notebook. A lista mostra as informações da sessão e os notebooks correspondentes. As ações Desanexar com o notebook, Interromper a sessão e Exibir no monitoramento estão disponíveis aqui. Você também pode conectar facilmente um notebook selecionado a uma sessão ativa que iniciou a partir de outro notebook. Em seguida, a sessão é desanexada do notebook anterior (se não estiver no modo ocioso) e anexada à atual.
Usar logs do Python em um notebook
É possível encontrar logs do Python e definir diferentes níveis de log e formatos usando o seguinte o código de exemplo:
import logging
# Customize the logging format for all loggers
FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
formatter = logging.Formatter(fmt=FORMAT)
for handler in logging.getLogger().handlers:
handler.setFormatter(formatter)
# Customize the log level for all loggers
logging.getLogger().setLevel(logging.INFO)
# Customize the log level for a specific logger
customizedLogger = logging.getLogger('customized')
customizedLogger.setLevel(logging.WARNING)
# Logger that uses the default global log level
defaultLogger = logging.getLogger('default')
defaultLogger.debug("default debug message")
defaultLogger.info("default info message")
defaultLogger.warning("default warning message")
defaultLogger.error("default error message")
defaultLogger.critical("default critical message")
# Logger that uses the customized log level
customizedLogger.debug("customized debug message")
customizedLogger.info("customized info message")
customizedLogger.warning("customized warning message")
customizedLogger.error("customized error message")
customizedLogger.critical("customized critical message")
Exibir o histórico de comandos de entrada
Os notebooks do Synapse dão suporte ao comando magic %history para imprimir o histórico de comandos de entrada da sessão atual. O comando magic %history é semelhante ao comando Jupyter IPython padrão e funciona para vários contextos de linguagem em um notebook.
%history [-n] [range [range ...]]
No código anterior, -n é o número de execução de impressão. O valor range pode ser:
-
N: imprimir código da célulaNthexecutada. -
M-N: imprimir código deMthpara a célulaNthexecutada.
Por exemplo, para imprimir o histórico de entrada da primeira para a segunda célula executada, use %history -n 1-2.
Integrar um notebook
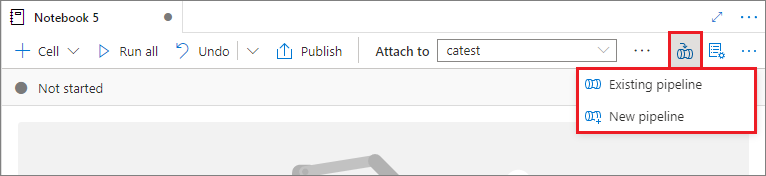
Adicionar um notebook a um pipeline
Para adicionar um notebook a um pipeline existente ou criar um novo pipeline, selecione o botão Adicionar ao pipeline no canto superior direito.
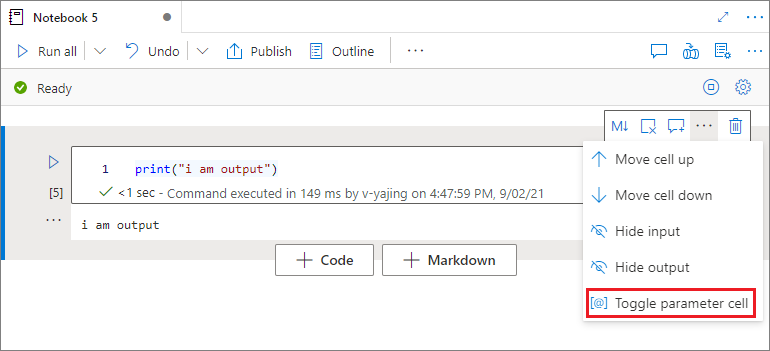
Designar uma célula de parâmetro
Para parametrizar seu notebook, selecione as reticências (...) para acessar mais comandos na barra de ferramentas da célula. Em seguida, selecione Alternar célula de parâmetro para designar a célula como a célula de parâmetro.
O Azure Data Factory procura a célula de parâmetro e trata essa célula como padrão para os parâmetros passados no momento da execução. O mecanismo de execução adiciona uma nova célula abaixo da célula com parâmetros de entrada para substituir os valores padrão.
Atribuir valores de parâmetros de um pipeline
Após criar um notebook com parâmetros, você poderá executá-lo a partir de um pipeline usando a atividade do notebook do Fabric. Após adicionar a atividade à tela do pipeline, você poderá definir os valores dos parâmetros na seção Parâmetros de base da guia Configurações.
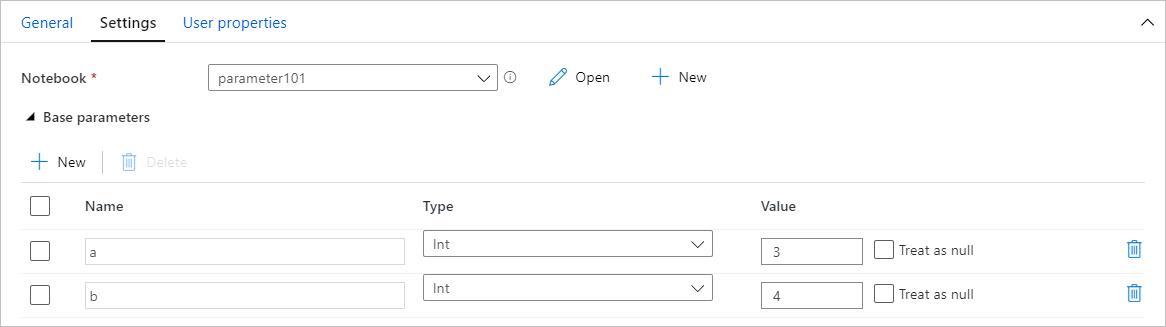
Ao atribuir valores de parâmetro, você pode usar a linguagem de expressão de pipeline ou variáveis do sistema.
Usar teclas de atalho
Semelhantemente aos Jupyter Notebooks, os notebooks Synapse têm uma interface de usuário modal. O teclado realiza coisas diferentes, dependendo de qual modo a célula do notebook está. Os notebooks do Synapse dão suporte aos dois modos seguintes de uma célula de código:
Modo de comando: uma célula está no modo de comando quando nenhum cursor de texto solicita que você digite. Quando uma célula está no modo de comando, você pode editar o notebook como um todo, mas não pode digitar em células individuais. Entre no modo de comando selecionando a tecla ESC ou usando o mouse para selecionar fora da área do editor de uma célula.

Modo de edição: quando uma célula está no modo de edição, um cursor de texto solicita que você digite na célula. Entre no modo de edição selecionando a tecla ENTER ou usando o mouse para selecionar a área do editor de uma célula.

Teclas de atalho no modo de comando
| Ação | Atalhos do notebook do Synapse |
|---|---|
| Executar a célula atual e selecionar abaixo | Shift+Enter |
| Executar a célula atual e inserir abaixo | Alt+Enter |
| Executar a célula atual | Ctrl+Enter |
| Selecionar célula acima | Para cima |
| Selecionar célula abaixo | Para baixo |
| Selecionar célula anterior | K |
| Selecionar próxima célula | J |
| Inserir célula acima | Um |
| Inserir célula abaixo | B |
| Excluir células selecionadas | Shift+D |
| Mudar para o modo de edição | Enter |
Teclas de atalho no modo de edição
| Ação | Atalhos do notebook do Synapse |
|---|---|
| Mover cursor para cima | Para cima |
| Mover cursor para baixo | Para baixo |
| Desfazer | Ctrl+Z |
| Refazer | Ctrl+Y |
| Inserir/remover comentário | Ctrl+/ |
| Excluir palavra anterior | Ctrl+Backspace |
| Excluir palavra seguinte | Ctrl+Delete |
| Ir para o início da célula | Ctrl+Home |
| Ir para o final da célula | Ctrl+End |
| Ir uma palavra para a esquerda | CTRL+Seta para a esquerda |
| Ir uma palavra para a direita | CTRL+Seta para a direita |
| Selecionar tudo | Ctrl+A |
| Recuar | Ctrl+] |
| Desfazer recuo | Ctrl+[ |
| Alternar para o modo de comando | Esc |
Conteúdo relacionado
- Notebooks de exemplo do Synapse
- Início Rápido: Criar um Pool do Apache Spark no Azure Synapse Analytics usando ferramentas da Web
- O que é Apache Spark no Azure Synapse Analytics?
- Use .NET para Apache Spark com Azure Synapse Analytics
- Documentação do .NET para Apache Spark
- Documentação do Azure Synapse Analytics