Azure Traffic Manager com o Azure Site Recovery
O Gerenciador de Tráfego do Azure permite que você controle a distribuição do tráfego entre os pontos de extremidade do aplicativo. Um ponto de extremidade é qualquer serviço para a Internet hospedado dentro ou fora do Azure.
O Gerenciador de Tráfego usa o DNS (Sistema de Nomes de Domínio) para direcionar solicitações de cliente ao ponto de extremidade mais apropriado com base em um método de roteamento de tráfego e a integridade dos pontos de extremidade. O Gerenciador de Tráfego oferece uma variedade de métodos de roteamento de tráfego e opções de monitoramento de ponto de extremidade para atender às diferentes necessidades dos aplicativos e modelos de failover automático. Os clientes se conectam diretamente ao ponto de extremidade selecionado. O Gerenciador de Tráfego não é um proxy ou um gateway, e não vê o tráfego que passa entre o cliente e o serviço.
Este artigo descreve como é possível combinar o roteamento inteligente do Monitor de Tráfego do Azure com os avançados recursos de migração e recuperação de desastre do Azure Site Recovery.
Failover local para Azure
Para o primeiro cenário, considere a Empresa A que tem toda a infraestrutura de aplicativos em execução no ambiente local. Por motivos de conformidade e continuidade dos negócios, a Empresa A decide usar o Azure Site Recovery para proteger seus aplicativos.
A Empresa A está executando aplicativos com pontos de extremidade públicos e quer a capacidade de redirecionar diretamente o tráfego para o Azure em um evento de desastre. O método de roteamento de tráfego Prioridade no Gerenciador de Tráfego do Microsoft Azure permite que a Empresa A implemente facilmente esse padrão de failover.
A configuração é a seguinte:
- A Empresa A cria um perfil do Gerenciador de Tráfego.
- Utilizando o método de roteamento Prioridade, a Empresa A cria dois pontos de extremidade – Primário para locais e Failover para Azure. Para o Primário é atribuída a Prioridade 1 e para Failover é atribuída a Prioridade 2.
- Como o ponto de extremidade Primário está hospedado fora do Azure, o ponto de extremidade é criado como um ponto de extremidade Externo.
- Com o Azure Site Recovery, o site do Azure não possui máquinas virtuais ou aplicativos em execução antes do failover. Portanto, o ponto de extremidade do Failover também é criado como um ponto de extremidade Externo.
- Por padrão, o tráfego de usuários é direcionado para o aplicativo local porque esse ponto de extremidade tem a prioridade mais alta associada a ele. Nenhum tráfego será direcionado para o Azure se o ponto de extremidade Primário estiver íntegro.
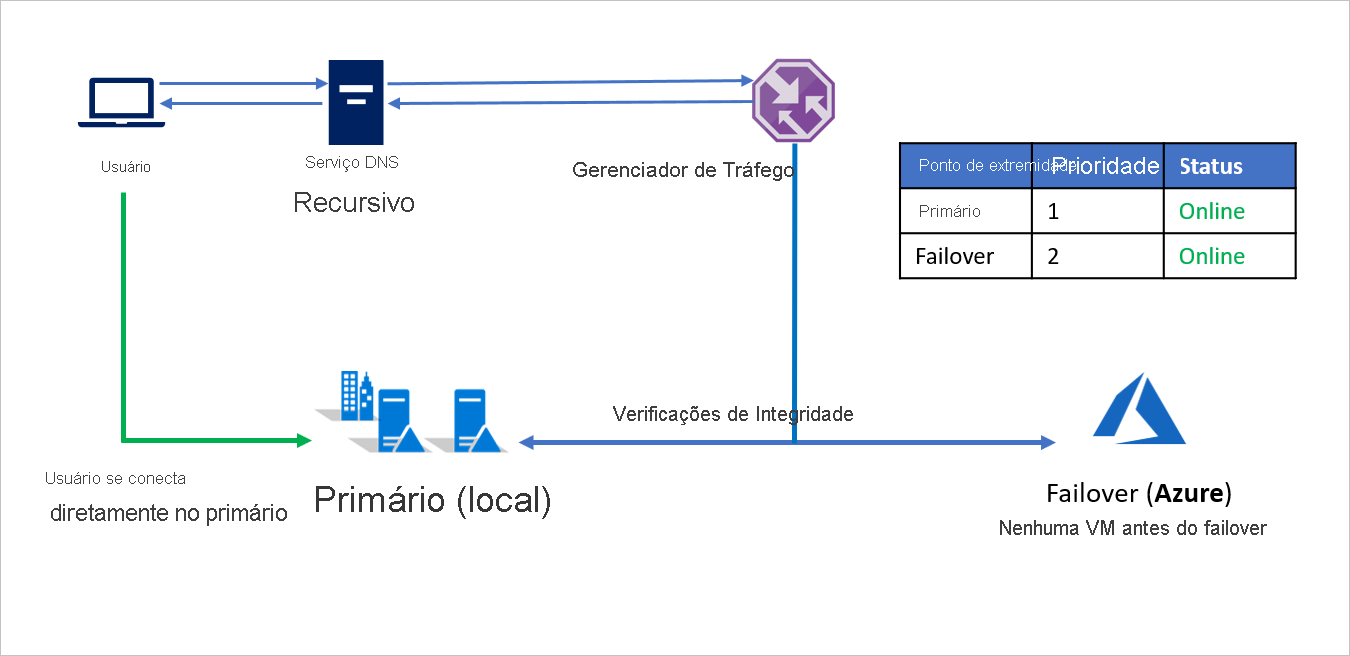
Em um evento de desastre, a Empresa A poderá disparar um failover para o Azure e recuperar os aplicativos no Azure. Quando o Gerenciador de Tráfego do Microsoft Azure detecta que o ponto de extremidade Primário não está mais íntegro, ele automaticamente usa o ponto de extremidade do Failover na resposta DNS e os usuários conectam-se ao aplicativo recuperado no Azure.
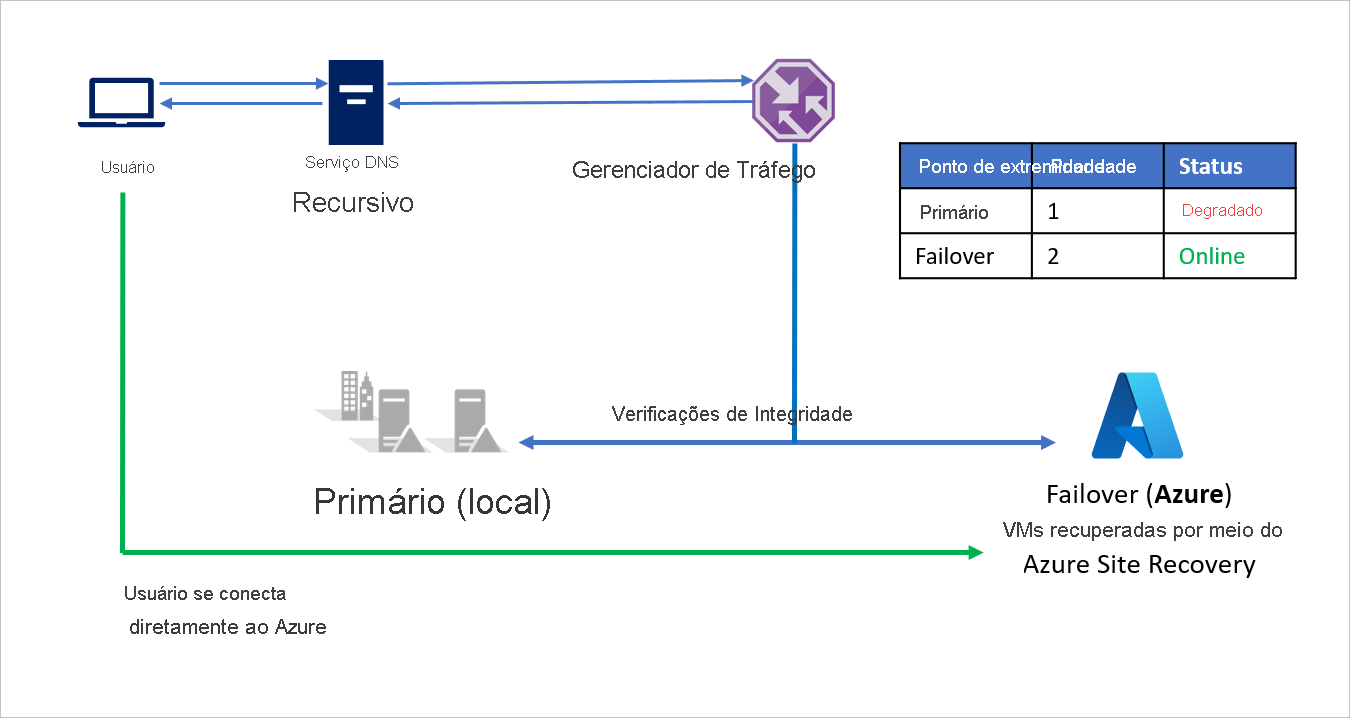
Dependendo dos requisitos de negócios, a Empresa A pode escolher uma maior ou menor frequência de investigação para alternar entre local para Azure em um evento de desastre e garantir um tempo de inatividade mínimo para os usuários.
Quando o desastre estiver contido, a Empresa A poderá fazer failback do Azure para seu ambiente local (VMware ou Hyper-V) usando o Azure Site Recovery. Porém, quando o Gerenciador de Tráfego detecta que o ponto de extremidade Primário está novamente adequado, ele automaticamente usa o ponto de extremidade Primário em suas respostas DNS.
Local para a migração do Azure
Além da recuperação de desastre, o Azure Site Recovery também permite migrações para o Azure. Usando os avançador recursos de failover de teste do Azure Site Recovery, os clientes podem avaliar o desempenho do aplicativo no Azure sem afetar o ambiente local. E quando os clientes estiverem prontos para migrar, poderão escolher migrar toda a carga de trabalho ou escolher migrar e escalar gradualmente.
O método de roteamento Ponderado do Gerenciador de Tráfego do Microsoft Azure pode ser usado para direcionar alguma parte do tráfego de entrada para o Azure, enquanto direciona a maioria para o ambiente local. Esta abordagem pode ajudar a avaliar o desempenho de escala, já que é possível continuar aumentando o peso atribuído ao Azure na medida em que você migra cada vez mais as cargas de trabalho para o Azure.
Por exemplo, a Empresa B escolhe migrar em fases, movendo parte do ambiente de aplicativo enquanto mantém o resto no local. Durante os estágios iniciais, quando a maior parte do ambiente está no local, um peso maior é atribuído ao ambiente local. O gerenciador de tráfego retorna um ponto de extremidade com base em pesos atribuídos aos pontos de extremidades disponíveis.
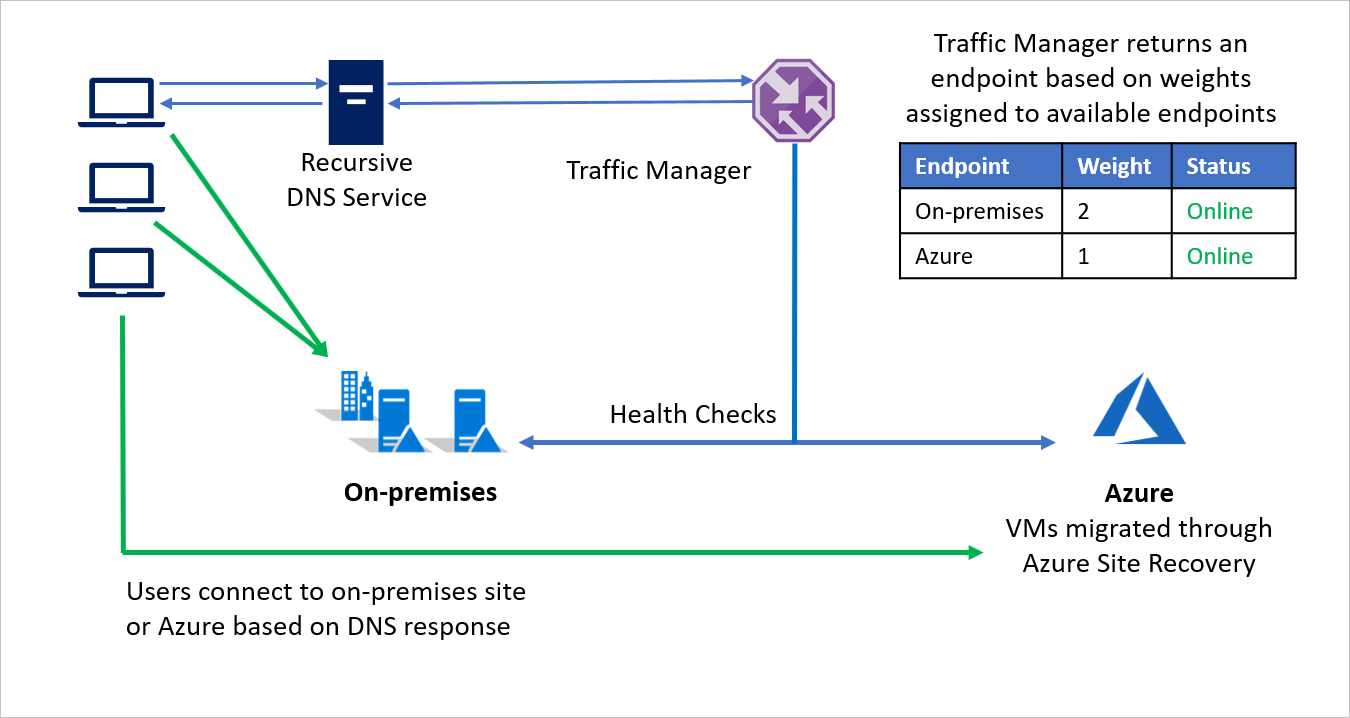
Durante a migração, ambos os pontos de extremidade estão ativos e a maior parte do tráfego é direcionada para o ambiente local. Na medida em que a migração prossegue, um peso maior poderá ser atribuído ao ponto de extremidade no Azure e, finalmente, o ponto de extremidade local poderá ser desativado após a migração.
Failover do Azure para Azure
Para esse exemplo, considere a Empresa C que possui toda sua infraestrutura de aplicativo em execução no Azure. Por razões de conformidade e continuidade dos negócios, a Empresa C decide usar o Azure Site Recovery para proteger os aplicativos.
A Empresa C está executando aplicativos com pontos de extremidade públicos e quer a capacidade de redirecionar diretamente o tráfego para uma região do Azure diferente em um evento de desastre. O método de roteamento de tráfego Prioridade permite que a Empresa C implemente facilmente esse padrão de failover.
A configuração é a seguinte:
- A Empresa C cria um perfil do Gerenciador de Tráfego.
- Utilizando o método de roteamento Prioridade, a Empresa C cria dois pontos de extremidade – Primário para a região de origem (Leste da Ásia do Azure) e Failover para a região de recuperação (Sudeste Asiático do Azure). Para o Primário é atribuída a Prioridade 1 e para Failover é atribuída a Prioridade 2.
- Como o ponto de extremidade Primário é hospedado no Azure, o ponto de extremidade pode ser como um ponto de extremidade do Azure.
- Com o Azure Site Recovery, o site do Azure de recuperação não possui máquinas virtuais ou aplicativos em execução antes do failover. Portanto, o ponto de extremidade do Failover pode ser criado como um ponto de extremidade Externo.
- Por padrão, o tráfego de usuários é direcionado para o aplicativo da região de origem (Leste da Ásia), pois esse ponto de extremidade possui a prioridade mais alta associada a ele. Nenhum tráfego será direcionado para a região de recuperação, se o ponto de extremidade Primário estiver íntegro.
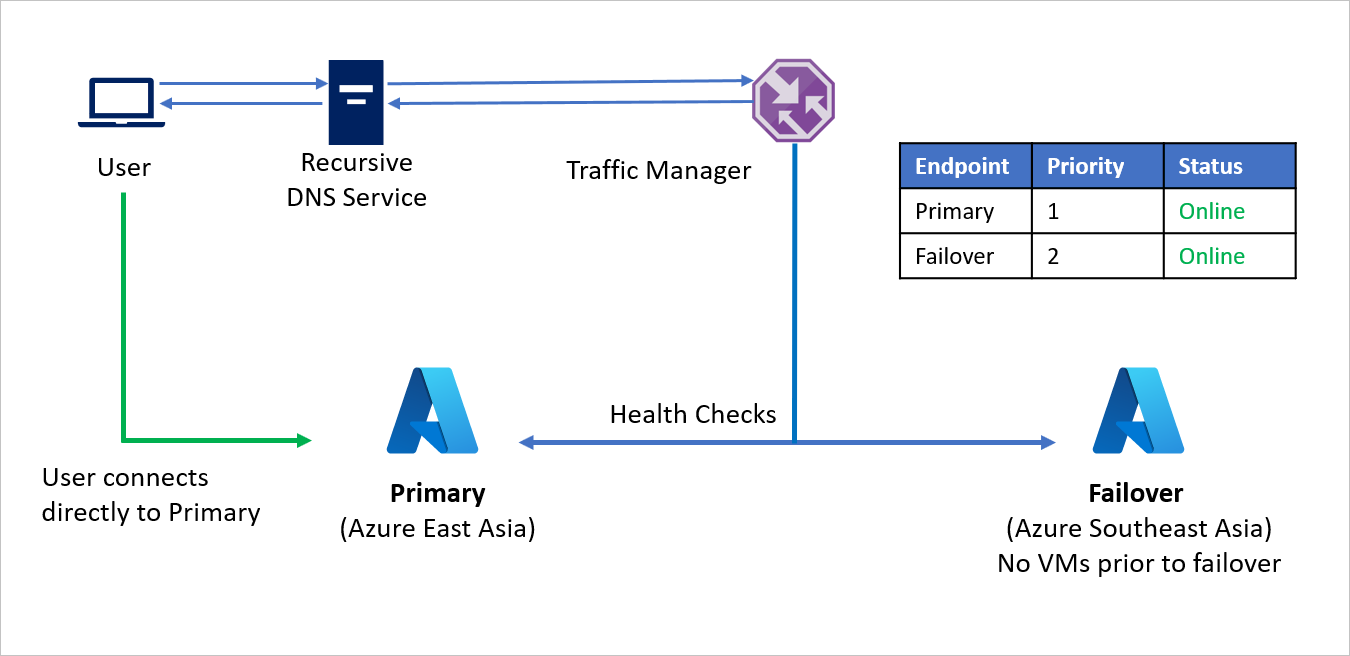
Em um evento de desastre, a Empresa C poderá disparar um failover e recuperar os aplicativos na região de recuperação do Azure. Quando o Gerenciador de Tráfego do Microsoft Azure detecta que o ponto de extremidade primário não está mais íntegro, ele automaticamente usa o ponto de extremidade do Failover na resposta DNS e os usuários conectam-se ao aplicativo recuperado na região de recuperação do Azure (Sudeste Asiático).
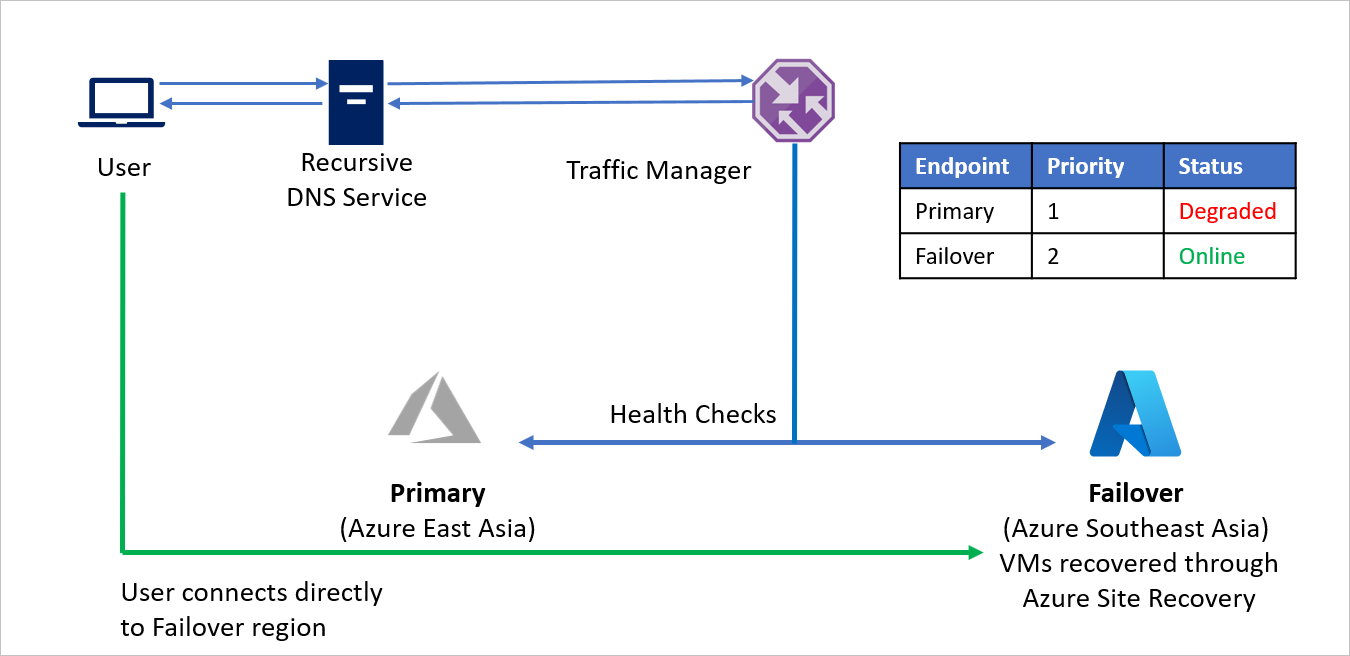
Dependendo dos requisitos de negócios, a Empresa C pode escolher uma maior ou menor frequência de investigação para alternar entre as regiões de origem e de recuperação e garantir um tempo de inatividade mínimo para os usuários.
Quando o desastre estiver contido, a Empresa C poderá fazer failback da região do Azure de recuperação para a região do Azure de origem, usando o Azure Site Recovery. Porém, quando o Gerenciador de Tráfego detecta que o ponto de extremidade Primário está novamente adequado, ele automaticamente usa o ponto de extremidade Primário em suas respostas DNS.
Proteger aplicativos empresariais de várias regiões
As empresas globais geralmente aperfeiçoam a experiência do cliente, adaptando os aplicativos para atender às necessidades regionais. A redução de latência e localização pode resultar em infraestrutura de aplicativos dividida em regiões. As empresas também estão vinculadas às leis de dados regionais em determinadas áreas e optam por isolar uma parte de sua infraestrutura de aplicativo dentro dos limites regionais.
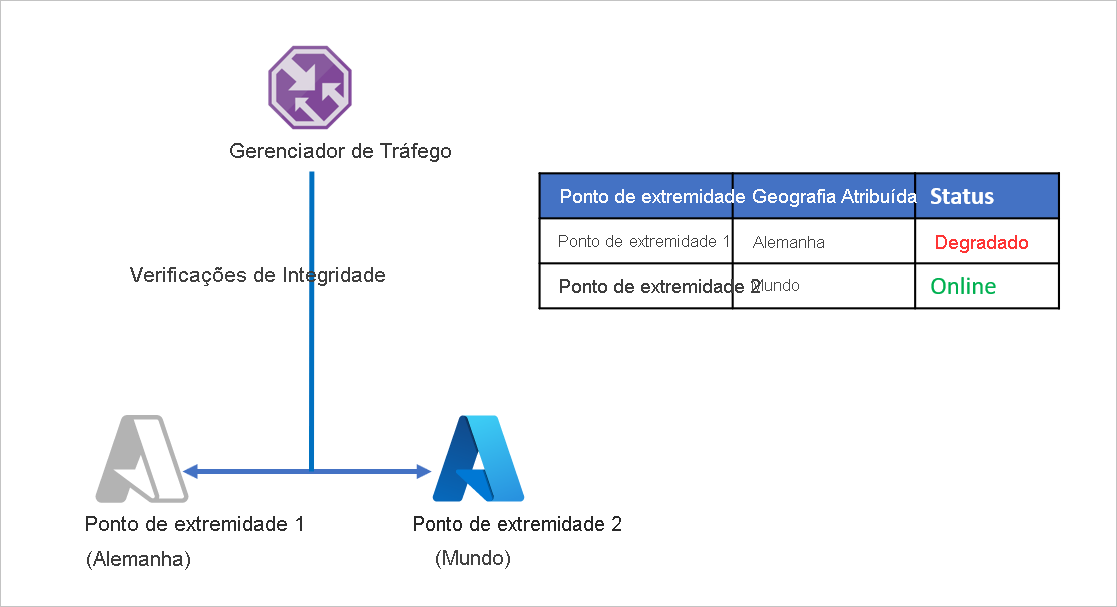
Consideremos um exemplo em que a Empresa D dividiu os pontos de extremidade do aplicativo para atender separadamente a Alemanha e o resto do mundo. A Empresa D utiliza o método de roteamento Geográfico do Gerenciador de Tráfego do Microsoft Azure para essa configuração. Qualquer tráfego originado da Alemanha é direcionado para o Ponto de extremidade 1 e qualquer tráfego originado fora da Alemanha é direcionado para o Pronto de extremidade 2.
O problema com essa configuração é que, se o Ponto de extremidade 1 parar de funcionar por qualquer razão, não haverá redirecionamento de tráfego para o Ponto de extremidade 2. O tráfego originado da Alemanha continua sendo direcionado para o Ponto de extremidade 1 independentemente da integridade do ponto de extremidade, deixando os usuários da Alemanha sem acesso ao aplicativo da Empresa D. Da mesma forma, se o Ponto de extremidade 2 estiver offline, não haverá redirecionamento de tráfego para o Ponto de extremidade 1.
Para evitar esse problema e garantir a resiliência do aplicativo, a Empresa D usa perfis aninhados do Gerenciador de Tráfego com o Azure Site Recovery. Em uma configuração de perfil aninhada, o tráfego não é direcionado para nós de extremidade individuais, mas, em vez disso, para outros perfis do Gerenciador de Tráfego. Veja como essa configuração funciona:
- Em vez de utilizar roteamento geográfico com pontos de extremidade individuais, a Empresa D usa roteamento Geográfico com perfis do Gerenciador de Tráfego.
- Cada perfil do Gerenciador de Tráfego filho utiliza o roteamento Prioridade com um ponto de extremidade primário e de recuperação, portanto, roteamento Primário de aninhamento dentro do roteamento Geográfico.
- Para habilitar a resiliência do aplicativo, cada distribuição de carga de trabalho utiliza o Azure Site Recovery para fazer failover para uma região de recuperação com base em um evento de desastre.
- Quando o Gerenciador de Tráfego pai recebe uma consulta DNS, é direcionado ao Gerenciador de Tráfego filho relevante que responde à consulta com um ponto de extremidade disponível.
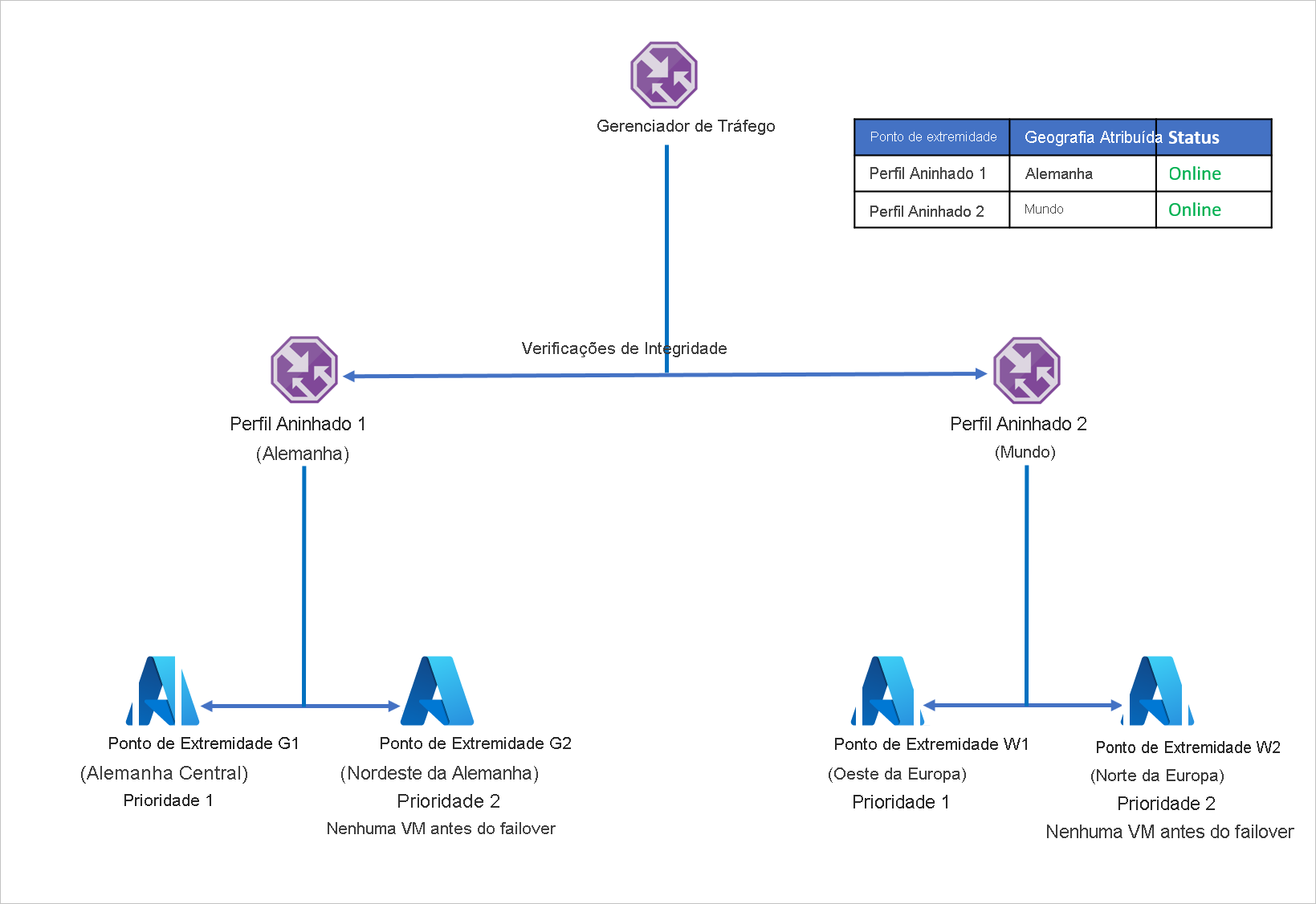
Por exemplo, se o ponto de extremidade no Centro da Alemanha falhar, o aplicativo poderá ser recuperado rapidamente no Nordeste da Alemanha. O novo ponto de extremidade manipula o tráfego originado da Alemanha com um tempo de inatividade mínimo para os usuários. Da mesma forma, uma interrupção do ponto de extremidade na Europa Ocidental pode ser manipulada pela recuperação da carga de trabalho do aplicativo para o Norte da Europa, com o Gerenciador de Tráfego do Microsoft Azure manipulando redirecionamentos de DNS para o ponto de extremidade disponível.
A configuração acima pode ser expandida para incluir quantas combinações de região e pontos de extremidades forem necessários. O Gerenciador de Tráfego permite até 10 níveis de perfis aninhados e não permite loops dentro da configuração aninhada.
Considerações de RTO (Objetivo do Tempo de Recuperação)
Na maioria das organizações, adicionar ou modificar registros DNS é tratado por uma equipe separada ou por alguém externo à organização. Isso torna a tarefa de alterar registros DNS muito desafiador. O tempo necessário para atualizar registros DNS por outras equipes ou organizações que gerenciam a infraestrutura DNS varia de organização para organização e impacta o RTO da aplicação.
Utilizando o Gerenciador de Tráfego, você poderá enviar o trabalho necessário para atualizações de DNS. Nenhuma ação de script ou manual é necessária no momento do failover real. Essa abordagem ajuda na comutação rápida (e, portanto, na redução de RTO), assim como a evitar erros na alteração de DNS que consomem muito tempo em um evento de desastre. Com o Gerenciador de Tráfego, mesmo a etapa de failback é automatizada, o que, de outra forma, teria que ser gerenciada separadamente.
Definir o intervalo de investigação correto através de verificações de integridade de intervalo básico ou rápido pode reduzir consideravelmente o RTO durante o failover e reduzir o tempo de inatividade para os usuários.
Também é possível otimizar o valor de tempo de vida de DNS para o perfil do Gerenciador de Tráfego. O tempo de vida é o valor para o qual uma entrada de DNS seria armazenada em cache por um cliente. Para um registro, o DNS não seria consultado duas vezes no período de tempo de vida. Cada registro DNS possui um tempo de vida associado a ele. Reduzir esse valor resulta em mais consultas de DNS para o Gerenciador de Tráfego, mas pode reduzir o RTO ao descobrir interrupções mais rápido.
O tempo de vida no cliente também não aumenta se o número de resolvedores de DNS entre o cliente e o servidor DNS autorizado aumentar. Os resolvedores de DNS "contam regressivamente" o tempo de vida e transmitem apenas um valor de tempo de vida que reflete o tempo decorrido desde que o registro foi armazenado em cache. Isso garante que o registro DNS seja atualizado no cliente após o tempo de vida, independentemente do número de Resolvedores de DNS na cadeia.
Próximas etapas
- Saiba mais sobre métodos de roteamento do Gerenciador de Tráfego.
- Saiba mais sobre perfis aninhados do Gerenciador de Tráfego.
- Saiba mais sobre monitoramento do ponto de extremidade.
- Saiba mais sobre planos de recuperação para automatizar o failover de aplicativo.