Moldar os resultados da pesquisa ou modificar a composição dos resultados da pesquisa na Pesquisa de IA do Azure
Este artigo explica a composição dos resultados de pesquisa e como moldá-los de acordo com seus cenários. Os resultados da pesquisa são retornados em uma resposta de consulta. A forma de uma resposta é determinada pelos parâmetros da própria consulta. Os parâmetros incluem:
- Número de correspondências encontradas no índice (
count) - Número de correspondências retornadas na resposta (50 por padrão, configurável por meio de
top) ou por página (skipetop) - Uma pontuação de pesquisa para cada resultado, usada para classificação (
@search.score) - Campos incluídos nos resultados da pesquisa (
select) - Lógica de classificação (
orderby) - Realce dos termos em um resultado, correspondendo ao termo inteiro ou parcial no corpo
- Elementos opcionais do classificador semântico (
answersna parte superior,captionspara cada correspondência)
Os resultados da pesquisa podem incluir campos de nível superior, mas a maior parte da resposta consiste em documentos correspondentes em uma matriz.
Clientes e APIs para definir a resposta da consulta
Você pode usar os seguintes clientes para configurar uma resposta de consulta:
- Gerenciador de Pesquisa no portal do Azure, usando a exibição JSON para que você possa especificar qualquer parâmetro com suporte
- Documentos – POST (APIs REST)
- Método SearchClient.Search (SDK do Azure para .NET)
- Método do SearchClient.Search (SDK do Azure para Python)
- Método SearchClient.Search (Azure para JavaScript)
- Método SearchClient.Search (Azure para Java)
Composição do resultado
Os resultados são, em sua maioria, tabulares, compostos por campos de todos os campos retrievable ou limitados apenas aos campos especificados no parâmetro select. As linhas são os documentos correspondentes, normalmente classificados em ordem de relevância, a menos que a lógica da consulta impeça a classificação por relevância.
Você pode escolher quais campos estão nos resultados da pesquisa. Embora um documento de pesquisa possa ter um grande número de campos, normalmente apenas alguns são necessários para representar cada documento nos resultados. Em uma solicitação de consulta, acrescente select=<field list> para especificar quais campos retrievable devem aparecer na resposta.
Escolha os campos que oferecem um contraste e um diferencial entre os documentos, fornecendo informações suficientes para incentivar o usuário a clicar na resposta. Em um site de comércio eletrônico, pode ser um nome de produto, uma descrição, uma marca, uma cor, um tamanho, um preço e uma classificação. Para o índice interno hotels-sample, podem ser os campos "selecionados" no seguinte exemplo:
POST /indexes/hotels-sample-index/docs/search?api-version=2024-07-01
{
"search": "sandy beaches",
"select": "HotelId, HotelName, Description, Rating, Address/City",
"count": true
}
Dicas para resultados inesperados
Ocasionalmente, a saída da consulta não é o que você espera ver. Por exemplo, você pode achar que alguns resultados parecem estar duplicados, ou um resultado que deveria aparecer próximo à parte superior está posicionado mais abaixo nos resultados. Quando os resultados da consulta forem inesperados, use estas modificações de consulta para verificar se os resultados melhoram:
Altere
searchMode=any(padrão) parasearchMode=allpara exigir correspondências em todos os critérios, em vez de em qualquer um dos critérios. Isso é especialmente verdadeiro quando os operadores boolianos estão incluídos na consulta.Use diferentes analisadores léxicos ou personalizados para tentar alterar o resultado da consulta. O analisador padrão quebra as palavras hifenizadas e reduz as palavras à raiz, o que geralmente melhora a robustez da resposta de consulta. No entanto, caso você precise preservar hifens ou caso as cadeias de caracteres incluam caracteres especiais, talvez seja necessário configurar analisadores personalizados para garantir que o índice contenha tokens no formato correto. Veja mais informações em Pesquisa de termo parcial e padrões com caracteres especiais (hifens, curinga, regex, padrões).
Contagem de correspondências
O parâmetro count retorna o número de documentos no índice que são considerados uma correspondência para a consulta. Para retornar a contagem, adicione count=true à solicitação de consulta. Não há um valor máximo imposto pelo serviço de pesquisa. Dependendo de sua consulta e do conteúdo de seus documentos, a contagem pode ser tão alta quanto todos os documentos no índice.
A contagem é precisa quando o índice está estável. Se o sistema estiver adicionando, atualizando ou excluindo documentos ativamente, a contagem será aproximada, excluindo todos os documentos que não estiverem totalmente indexados.
A contagem não será afetada pela manutenção de rotina ou outras cargas de trabalho no serviço de pesquisa. No entanto, se você tiver várias partições e uma única réplica, poderá experimentar flutuações de curto prazo na contagem de documentos (vários minutos) à medida que as partições forem reiniciadas.
Dica
Para verificar as operações de indexação, você pode confirmar se o índice contém o número esperado de documentos adicionando count=true a uma consulta de pesquisa search=* vazia. O resultado é a contagem completa de documentos em seu índice.
Ao testar a sintaxe da consulta, count=true pode informar rapidamente se suas modificações estão retornando resultados maiores ou menores, o que pode ser um feedback útil.
Número de resultados na resposta
A Pesquisa de IA do Azure usa a paginação do lado do servidor para impedir que as consultas recuperem muitos documentos ao mesmo tempo. Os parâmetros de consulta que determinam o número de resultados em uma resposta são top e skip.
top refere-se ao número de resultados da pesquisa em uma página.
skip é um intervalo de top e informa ao mecanismo de pesquisa quantos resultados devem ser ignorados antes de obter o próximo conjunto.
O tamanho de página padrão é 50, enquanto o tamanho máximo de página é 1.000. Se você especificar um valor maior que 1.000 e houver mais de 1.000 resultados encontrados no índice, somente os primeiros 1.000 resultados serão retornados. Se o número de correspondências exceder o tamanho da página, a resposta incluirá informações para recuperar a próxima página de resultados. Por exemplo:
"@odata.nextLink": "https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01"
As principais correspondências são determinadas pela pontuação de pesquisa, supondo que a consulta seja uma pesquisa de texto completo ou semântica. Caso contrário, as principais correspondências serão uma ordem arbitrária para consultas de correspondência exata (em que @search.score=1.0 uniforme indica classificação arbitrária).
Defina top para substituir o padrão de 50. Nas APIs de visualização mais recentes, se você estiver usando uma consulta híbrida, poderá especificar maxTextRecallSize para retornar até 10.000 documentos.
Para controlar a paginação de todos os documentos retornados em um conjunto de resultados, use top e skip em conjunto. Essa consulta retorna o primeiro conjunto de 15 documentos correspondentes e uma contagem do total de correspondências.
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 0
}
Essa consulta retorna o segundo conjunto, ignorando os primeiros 15 para obter os próximos 15 (16 a 30):
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 15
}
Se houver mudanças no índice subjacente, talvez os resultados de consultas paginadas não sejam estáveis. A paginação altera o valor de skip de cada página, mas cada consulta é independente e opera na exibição atual dos dados conforme a existência deles no índice no momento da consulta. Em outras palavras, não há cache ou instantâneo dos resultados, como aqueles encontrados em bancos de dados de uso geral.
Veja a seguir um exemplo que mostra como duplicatas podem surgir. Imagine um índice com quatro documentos:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
{ "id": "4", "rating": 1 }
Agora imagine que você quer dois resultados por vez, ordenados pela classificação. Você executaria esta consulta para obter a primeira página de resultados: $top=2&$skip=0&$orderby=rating desc, produzindo os seguintes resultados:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
No serviço, suponha que um quinto documento seja adicionado ao índice entre as chamadas de consulta: { "id": "5", "rating": 4 }. Logo em seguida, você executa uma consulta para buscar a segunda página, $top=2&$skip=2&$orderby=rating desc, e este é o resultado:
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
Observe que o documento 2 é recuperado duas vezes. Isso ocorre porque o novo documento 5 tem um valor de classificação maior, então é classificado antes do documento 2 e chega na primeira página. Embora possa ser inesperado, esse é o comportamento comum do mecanismo de pesquisa.
Paginação por meio de um grande número de resultados
Uma técnica alternativa para paginação é usar uma ordem de classificação e um filtro de intervalo como uma solução alternativa para skip.
Nesta solução alternativa, a classificação e o filtro são aplicados a um campo de ID de documento ou a outro campo exclusivo para cada documento. O campo exclusivo deve ter a atribuição de filterable e sortable no índice de pesquisa.
Emita uma consulta para retornar uma página inteira de resultados classificados.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc" }Escolha o último resultado retornado pela consulta de pesquisa. Um exemplo de resultado com apenas um valor de ID é mostrado aqui.
{ "id": "50" }Use esse valor de ID em uma consulta de intervalo para obter a próxima página de resultados. Esse campo de ID deve ter valores exclusivos. Caso contrário, a paginação poderá incluir resultados duplicados.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc", "filter": "id ge 50" }A paginação termina quando a consulta retorna zero resultados.
Observação
Os atributos filterable e sortable só podem ser habilitados quando um campo é adicionado pela primeira vez a um índice; eles não podem ser habilitados em um campo existente.
Ordenando resultados
Em uma consulta de pesquisa de texto completo, os resultados podem ser classificados por:
- uma pontuação de pesquisa
- uma pontuação de reclassificador semântico
- uma ordem de classificação em um campo
sortable
Você também pode aumentar todas as correspondências encontradas em campos específicos adicionando um perfil de pontuação.
Ordenação por pontuação de pesquisa
Para consultas de pesquisa de texto completo, os resultados são classificados por uma pontuação de pesquisa automaticamente usando um algoritmo BM25, calculado com base na frequência do termo, no tamanho do documento e no tamanho médio do documento.
O intervalo @search.score não está associado ou vai de 0 até (mas não incluindo) 1,00 em serviços mais antigos.
Para qualquer um dos algoritmos, um @search.score igual a 1,00 indica um conjunto de resultados sem pontuação ou sem classificação, em que a pontuação 1,0 é uniforme em todos os resultados. Os resultados não pontuados ocorrem quando a forma de consulta é a pesquisa difusa, consultas com curinga ou com regex ou uma pesquisa vazia (search=*). Se você precisar impor uma estrutura de classificação em resultados não pontuados, considere uma expressão orderby para atingir esse objetivo.
Ordenar pelo reclassificador semântico
Se você estiver usando o classificador semântico, o @search.rerankerScore determinará a ordem de classificação dos resultados.
O intervalo @search.rerankerScore é de 1 a 4,00, em que uma pontuação mais alta indica uma correspondência semântica mais forte.
Ordenar com orderby
Para aplicativos que exigem ordenação consistente, você pode definir uma expressão orderby em um campo. Somente os campos que são indexados como “classificáveis” podem ser usados para ordenar os resultados.
Campos comumente usados em uma orderby incluem classificação, data e local. A filtragem por local requer que a expressão de filtro chame a geo.distance() função, além do nome do campo.
Os campos numéricos (Edm.Double, Edm.Int32, Edm.Int64) são classificados em ordem numérica (por exemplo, 1, 2, 10, 11, 20).
Os campos de cadeia de caracteres (subcampos Edm.String, Edm.ComplexType) são classificados na ordem de classificação ASCII ou na ordem de classificação Unicode, dependendo do idioma.
O conteúdo numérico em campos de cadeia de caracteres é classificado em ordem alfabética (1, 10, 11, 2, 20).
As cadeias de caracteres maiúsculas são classificadas à frente da letra minúscula (APPLE, Apple, BANANA, Banana, apple, banana). Você pode atribuir um normalizador de texto para pré-processar o texto antes de classificar para alterar esse comportamento. O uso do gerador de tokens em minúsculas em um campo não exerce nenhum efeito sobre o comportamento de classificação porque a Pesquisa de IA do Azure classifica em uma cópia do campo não analisada.
Cadeias de caracteres que começam com diacríticos aparecem por último (Äpfel, Öffnen, Üben)
Aumentar a relevância usando um perfil de pontuação
Outra abordagem que promove a consistência na ordem é usar um perfil de pontuação personalizado. Os perfis de pontuação oferecem maior controle sobre a classificação de itens nos resultados da pesquisa, com a capacidade de impulsionar as correspondências encontradas em campos específicos. A lógica de pontuação extra ajuda a substituir pequenas diferenças entre as réplicas, pois as pontuações de pesquisa de cada documento estão mais distantes. Recomendamos o algoritmo de classificação para essa abordagem.
Realce de ocorrência
O realce de ocorrência é a formatação de texto (como negrito ou realce em amarelo) aplicada aos termos correspondentes do resultado, facilitando a identificação da correspondência. O destaque é útil para campos de conteúdo mais longo, como um campo de descrição, em que a correspondência não é imediatamente óbvia.
O realce é aplicado a termos individuais. Não há funcionalidade de realce do conteúdo de um campo inteiro. Se quiser realçar uma frase, você precisará fornecer os termos (ou frase) correspondentes em uma cadeia de caracteres de consulta entre aspas. Essa técnica é descrita mais adiante, nesta seção.
As instruções de realce de ocorrência são incluídas na solicitação de consulta. As consultas que disparam expansão no mecanismo, como pesquisa difusa e curinga, têm suporte limitado para o realce de ocorrência.
Requisitos para realce de ocorrência
- Os campos devem ser
Edm.StringeCollection(Edm.String) - Os campos devem ser atribuídos em
searchable
Especificar o realce na solicitação
Para retornar termos realçados, inclua o parâmetro realçar na solicitação de consulta. O parâmetro é definido como uma lista de campos delimitada por vírgula.
Por padrão, a marcação de formato é <em>, mas você pode substituir a marca usando os parâmetros highlightPreTag e highlightPostTag. O código do cliente lida com a resposta (por exemplo, aplicando uma fonte em negrito ou um plano de fundo amarelo).
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "divine secrets",
"highlight": "title, original_title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>"
}
Por padrão, o Azure AI Search retorna até cinco destaques por campo. Para ajustar esse número, acrescente um traço seguido por um inteiro. Por exemplo, "highlight": "description-10" retorna até 10 termos realçados no conteúdo correspondente no campo de descrição.
Resultados realçados
Quando o realce é adicionado à consulta, a resposta inclui um @search.highlights para cada resultado, de modo que o código do aplicativo possa direcionar essa estrutura. A lista de campos especificados para "realce" é incluída na resposta.
Em uma pesquisa de palavra-chave, cada termo é verificado de modo independente. Uma consulta de "segredos divinos" retornará correspondências em qualquer documento que contenha um dos dois termos.
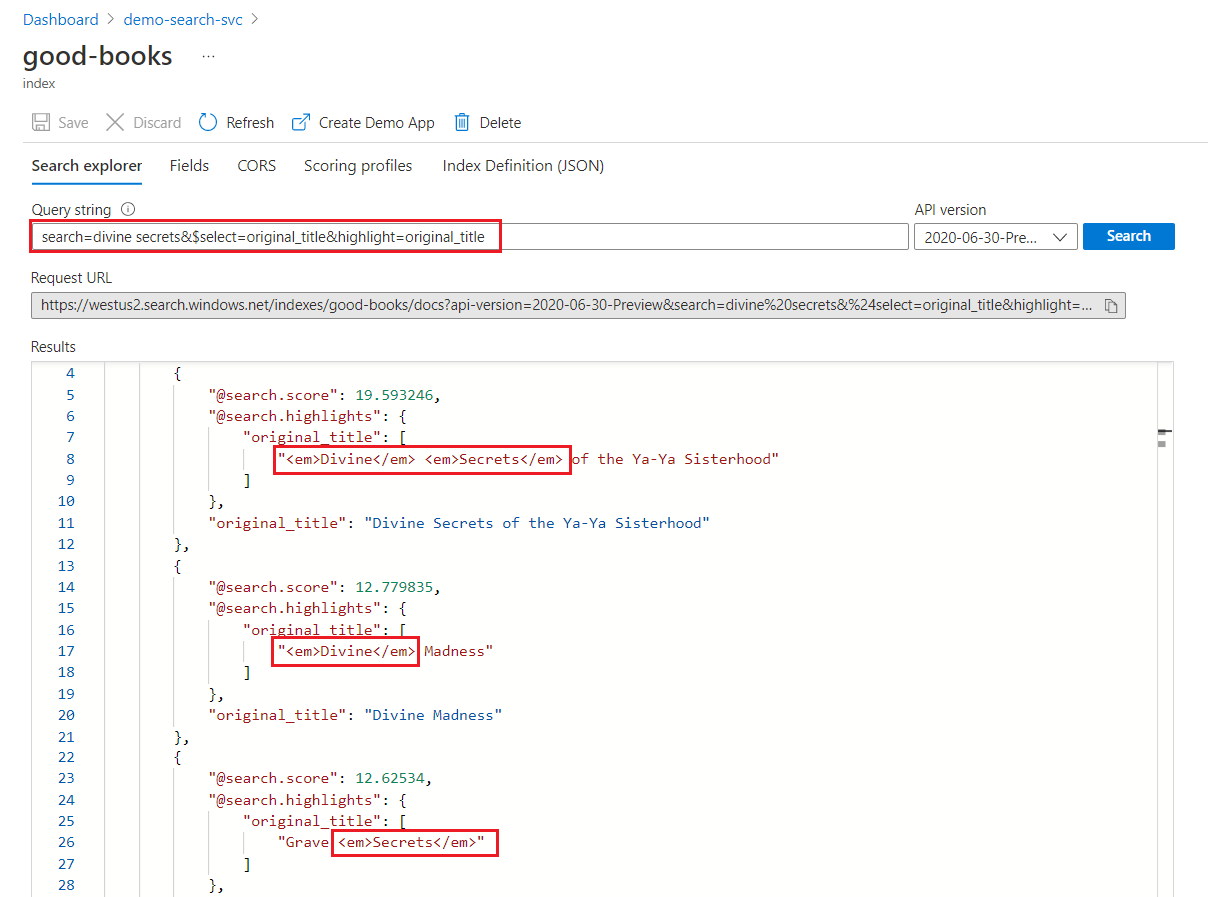
Realce de pesquisa de palavra-chave
Dentro de um campo realçado, a formatação é aplicada a termos inteiros. Por exemplo, em uma correspondência de "The Divine Secrets of the Ya-Ya Sisterhood", a formatação é aplicada a cada termo separadamente, mesmo que eles sejam consecutivos.
"@odata.count": 39,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"original_title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
],
"title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
},
{
"@search.score": 12.779835,
"@search.highlights": {
"original_title": [
"<em>Divine</em> Madness"
],
"title": [
"<em>Divine</em> Madness (Cherub, #5)"
]
},
"original_title": "Divine Madness",
"title": "Divine Madness (Cherub, #5)"
},
{
"@search.score": 12.62534,
"@search.highlights": {
"original_title": [
"Grave <em>Secrets</em>"
],
"title": [
"Grave <em>Secrets</em> (Temperance Brennan, #5)"
]
},
"original_title": "Grave Secrets",
"title": "Grave Secrets (Temperance Brennan, #5)"
}
]
Realce de pesquisa de frase
A formatação de termo inteiro se aplica até mesmo a uma pesquisa de frase, em que vários termos estão entre aspas duplas. O exemplo a seguir é a mesma consulta, exceto que "segredos divinos" é enviado como uma frase entre aspas (alguns clientes REST exigem que você escape das aspas internas com uma barra invertida \"):
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "\"divine secrets\"",
"select": "title,original_title",
"highlight": "title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>",
"count": true
}
Como os critérios agora têm ambos os termos, apenas uma correspondência foi encontrada no índice de pesquisa. A resposta à consulta anterior tem a seguinte aparência:
{
"@odata.count": 1,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"title": [
"<b>Divine</b> <b>Secrets</b> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
}
]
}
Realce de frase em serviços mais antigos
Os serviços de pesquisa criados antes de 15 de julho de 2020 implementam uma experiência de realce diferente para consultas de frase.
Para os exemplos a seguir, suponha uma cadeia de consulta que inclua a frase entre aspas "super bowl". Antes de julho de 2020, qualquer termo na frase era realçado:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is <em>super</em> awesome with a <em>bowl</em> of chips"
]
Para serviços de pesquisa criados após julho de 2020, somente as frases que correspondem à consulta de frase completa são retornadas em @search.highlights:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is super awesome with a bowl of chips"
]
Próximas etapas
Para gerar rapidamente uma página de pesquisa para o cliente, considere estas opções:
Criar aplicativo de demonstração, no portal do Azure, cria uma página HTML com uma barra de pesquisa, faceted navigation e uma área de miniaturas, se você tiver imagens.
Adicionar pesquisa a um aplicativo do ASP.NET Core (MVC) é um tutorial e exemplo de código que cria um cliente funcional.
Adicionar pesquisa a aplicativos Web é um tutorial em C# e um exemplo de código que usa as bibliotecas React JavaScript para a experiência do usuário. O aplicativo é implantado usando os Aplicativos Web Estáticos do Azure e implementa a paginação.