Pesquisa de texto completo no Azure AI Search
A pesquisa de texto completo é uma abordagem na recuperação de informações que corresponde ao texto sem formatação armazenado em um índice. Por exemplo, dada uma cadeia de caracteres de consulta "hotéis em San Diego na praia", o mecanismo de pesquisa procura cadeias de caracteres tokenizadas com base nesses termos. Para tornar as verificações mais eficientes, as cadeias de caracteres de consulta passam por uma análise lexical: reduzir todos os termos, remover palavras irrelevantes como "o" e reduzir os termos para formas raiz primitivas. Quando os termos correspondentes são encontrados, o mecanismo de pesquisa recupera documentos, os classifica em ordem de relevância e retorna os principais resultados.
A execução da consulta pode ser complexa. Este artigo é para desenvolvedores que precisam de uma compreensão mais profunda de como a pesquisa de texto completo funciona no Azure AI Search. Para consultas de texto, o Azure AI Search produzirá facilmente os resultados esperados na maioria dos cenários, mas, ocasionalmente, você poderá obter um resultado que pode parecer "estranho". Nessas situações, ter experiência nos quatro estágios da execução da consulta do Lucene (análise léxica, análise da consulta, correspondência de documentos e pontuação) pode ajudá-lo a identificar alterações específicas nos parâmetros de consulta ou na configuração de índice que proporcionarão o resultado desejado.
Observação
O Azure AI Search usa o Apache Lucene para pesquisa de texto completo, mas a integração do Lucene não é completa. Vamos seletivamente expor e estender a funcionalidade do Lucene para habilitar os cenários importantes para o Azure AI Search.
Diagrama e visão geral da arquitetura
A execução de consulta possui quatro fases:
- Análise da consulta
- Análise léxica
- Recuperação de documentos
- Pontuação
Uma consulta de pesquisa de texto completo começa com a análise do texto da consulta para extrair os termos e operadores de pesquisa. Existem dois analisadores para que você possa escolher entre velocidade e complexidade. O próximo é uma fase de análise, na qual os termos de consulta individual, às vezes, são divididos e reconstituídos em novos formulários. Esta etapa ajuda a lançar uma rede mais ampla sobre o que poderia ser considerado como uma possível correspondência. Em seguida, o mecanismo de pesquisa examina o índice para encontrar documentos com termos e pontuações correspondentes a cada correspondência. Um conjunto de resultados é classificado por uma pontuação de relevância atribuída a cada documento correspondente individual. Aqueles no topo da lista com a classificação são retornados para o aplicativo de chamada.
O diagrama a seguir ilustra os componentes usados para processar uma solicitação de pesquisa.
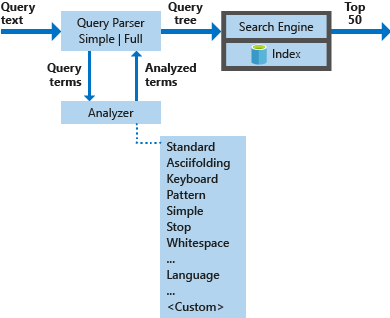
| Principais componentes | Descrição funcional |
|---|---|
| Analisadores de consulta | Separam os termos de consulta de operadores de consulta e criam a estrutura da consulta (uma árvore de consulta) a ser enviada para o mecanismo de pesquisa. |
| Analisadores | Executam a análise léxica dos termos de consulta. Esse processo pode envolver a transformação, remoção ou expansão dos termos de consulta. |
| Index | Uma estrutura de dados eficiente usada para armazenar e organizar termos pesquisáveis extraídos de documentos indexados. |
| Mecanismo de pesquisa | Recupera e atribui uma pontuação aos documentos correspondentes com base no conteúdo do índice invertido. |
Anatomia de uma solicitação de pesquisa
Uma solicitação de pesquisa é uma especificação completa do que deve ser retornado em um conjunto de resultados. Na forma mais simples, é uma consulta vazia sem qualquer tipo de critério. Um exemplo mais realista inclui parâmetros, vários termos de consulta, talvez com escopo para determinados campos, com possivelmente uma expressão de filtro e as regras de ordenação.
O exemplo a seguir é uma solicitação de pesquisa que você pode enviar ao Azure AI Search usando a API REST.
POST /indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
Para essa solicitação, o mecanismo de pesquisa faz as operações a seguir:
Encontra os documentos em que o preço é pelo menos US $60 e menor que US $300.
Executa a consulta. Neste exemplo, a consulta de pesquisa consiste de frases e termos:
"Spacious, air-condition* +\"Ocean view\""(os usuários normalmente não inserem pontuação, mas incluí-la no exemplo permite explicar como os analisadores tratam a pontuação).Para essa consulta, o mecanismo de pesquisa examina a descrição e os campos de título especificados em "searchFields" para documentos que contenham
"Ocean view", além do termo"spacious"ou termos que começam com o prefixo"air-condition". O parâmetro "searchMode" é usado para corresponder todo termo (padrão) ou todos eles, para casos em que um termo não for explicitamente solicitado (+).Ordena o conjunto resultante de hotéis por proximidade de uma localização geográfica indicada e retorna os resultados para o aplicativo de chamada.
A maioria deste artigo é sobre o processamento da consulta da pesquisa: "Spacious, air-condition* +\"Ocean view\"". Filtragem e ordenação estão fora do escopo. Para obter mais informações, consulte as documentação de referência da API de pesquisa.
Estágio 1: Análise da consulta
Conforme observado, a cadeia de caracteres de consulta é a primeira linha da solicitação:
"search": "Spacious, air-condition* +\"Ocean view\"",
O analisador de consulta separa os operadores (como * e + no exemplo) dos termos de pesquisa e desconstrói a consulta de pesquisa em subconsultas de um tipo com suporte:
- consulta de termo para termos independentes (espaçoso, por exemplo)
- consulta de frase para termos entre aspas (vista para o mar, por exemplo)
-
consulta de prefixo por termos seguidos por um operador de prefixo
*(ar-condicio, por exemplo)
Para obter uma lista completa dos tipos de consulta com suporte, veja sintaxe da consulta do Lucene
Os operadores associados com uma subconsulta determinam se a consulta deve ser obrigatoriamente satisfeita ou não para um documento ser considerado uma correspondência. Por exemplo, +"Ocean view" é "obrigatória" devido ao operador +.
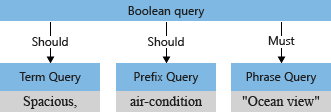
O analisador de consulta reestrutura as subconsultas em uma árvore de consulta (uma estrutura interna que representa a consulta) passada para o mecanismo de pesquisa. No primeiro estágio da análise de consulta, a árvore de consulta se parece com isto.
Analisadores com suporte: simples e Lucena completa
O Azure AI Search apresenta duas linguagens de consulta diferentes, simple (padrão) e full. Ao definir o parâmetro queryType com sua solicitação de pesquisa, você informa ao analisador de consulta a linguagem de consulta que você escolheu para que ele saiba como interpretar os operadores e a sintaxe.
A linguagem de consulta simples é intuitiva e robusta, geralmente adequada para interpretar a entrada do usuário conforme inserida, sem processamento no lado do cliente. Ela oferece suporte a operadores de consulta familiares de mecanismos de pesquisa.
A linguagem de consulta Lucene completa, que você obtém definindo
queryType=full, estende a linguagem de consulta simples padrão, adicionando suporte para mais operadores e tipos de consulta como caractere curinga, difusa, regex e consultas com escopo de campo. Por exemplo, uma expressão regular enviada na sintaxe de consulta simples será interpretada como uma cadeia de caracteres de consulta e não é uma expressão. A solicitação de exemplo neste artigo usa a linguagem de consulta Lucene completa.
Impacto do modo de pesquisa no analisador
Outro parâmetro de solicitação de pesquisa que afeta a análise é o parâmetro "searchMode". Ele controla o operador padrão para consultas boolianas: qualquer (padrão) ou todos.
Quando "searchMode=any", que é o padrão, o delimitador de espaço entre espaçoso e ar-condicio for OR (||), tornando o texto da consulta de exemplo equivalente a:
Spacious,||air-condition*+"Ocean view"
Operadores explícitos, como + em +"Ocean view", não são ambíguos na construção de consulta booliana (o termo deve corresponder). Menos óbvio é como interpretar os demais termos: espaçoso e ar-condicio. O mecanismo de pesquisa deve localizar correspondências para vista para o mar e espaçoso e ar-condicio? Ou deve encontrar vista para o mar mais qualquer um dos demais termos?
Por padrão ("searchMode=any"), o mecanismo de pesquisa assume a interpretação mais ampla. Cada campo deve ter uma correspondência, refletindo a semântica de "ou". A árvore de consulta inicial ilustrada anteriormente, com as duas operações de “não obrigatório”, mostra o padrão.
Agora, considere que definimos "searchMode=all". Nesse caso, o espaço é interpretado como uma operação "e". Cada um dos demais termos deve estar presente no documento para ser qualificado como uma correspondência. O exemplo de consulta resultante será interpretado da seguinte maneira:
+Spacious,+air-condition*+"Ocean view"
Uma árvore de consulta modificada para esta consulta seria a seguinte, onde um documento correspondente é a interseção de todas as três subconsultas:

Observação
Escolher "searchMode=any" em vez de "searchMode=all" é uma decisão melhor ao executar consultas representativas. Os usuários mais propensos a incluir operadores (comum ao pesquisar repositórios de documentos) podem encontrar resultados mais intuitivos se "searchMode=all" informar construções de consulta boolianas. Para obter mais informações sobre a interação entre "searchMode" e os operadores, consulte sintaxe de consulta simples.
Estágio 2: Análise léxica
Os analisadores léxicos processam consultas de termo e consultas de frase depois que a árvore de consulta é estruturada. Um analisador aceita as entradas de texto fornecidas pelo analisador, processa o texto e, em seguida, envia de volta os termos com token a serem incorporados na árvore de consulta.
A forma mais comum de análise léxica é a *análise linguística e ela transforma consultas baseadas em termos em regras específicas para um idioma específico:
- Reduzindo um termo de consulta para a raiz de uma palavra
- Removendo palavras não-essenciais (palavras irrelevantes, como "o/a" ou "e" em português)
- Dividir uma palavra composta em componentes
- Colocando letras minúsculas em uma palavra de letras maiúsculas
Todas essas operações tendem a apagar as diferenças entre a entrada de texto fornecida pelo usuário e os termos armazenados no índice. Essas operações vão além do processamento de texto e exigem um conhecimento profundo do próprio idioma. Para adicionar essa camada de reconhecimento linguístico, o Azure AI Search dá suporte a uma longa lista de analisadores de idioma da Lucene e da Microsoft.
Observação
Os requisitos de análise podem variar de básicos a elaborados dependendo do seu cenário. Você pode controlar a complexidade da análise léxica selecionando um dos analisadores predefinidos ou criando seu próprio analisador personalizado. O escopo dos analisadores inclui campos pesquisáveis e são especificados como parte de uma definição do campo. Isso permite que você varie a análise léxica baseada no campo. Se não for especificado, o analisador padrão para Lucene é usado.
Em nosso exemplo, antes da análise, a árvore de consulta inicial tem o termo "Espaçoso," com um "E" maiúsculo e uma vírgula que o analisador de consulta interpreta como parte do termo de consulta (uma vírgula não é considerada um operador de linguagem de consulta).
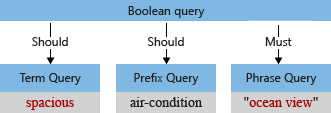
Quando o analisador padrão processa o termo, ele colocará "vista para o mar" e "espaçoso" em letras minúsculas e removerá o caractere de vírgula. A árvore de consulta modificada tem a seguinte aparência:
Testando os comportamentos do analisador
O comportamento de um analisador pode ser testado usando a API de análise. Forneça o texto que você deseja analisar para ver quais termos o analisador irá gerar. Por exemplo, para ver como o analisador padrão processaria o texto "ar-condicio", você pode emitir a solicitação a seguir:
{
"text": "air-condition",
"analyzer": "standard"
}
O analisador padrão quebra o texto de entrada nos dois tokens a seguir, associando atributos como deslocamentos inicial e final (usados para realçar ocorrências), bem como sua posição (usada para correspondência de frase):
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
Exceções para análise léxica
A análise léxica só se aplica a tipos de consultas que exigem termos completos – uma consulta de termo ou uma consulta de frase. Ela não se aplica aos tipos de consulta com termos incompletos – consulta de prefixo, consulta de caractere curinga, consulta regex – ou a uma consulta difusa. Esses tipos de consulta, incluindo a consulta de prefixo com o termo air-condition* em nosso exemplo, são adicionados diretamente à árvore de consulta, ignorando o estágio de análise. A única transformação realizada em termos de consulta desses tipos é colocá-los em letras minúsculas.
Estágio 3: Recuperação de documentos
A recuperação de documentos se refere à procura de documentos com correspondência de termos no índice. Este estágio é melhor compreendido por meio de um exemplo. Vamos começar com um índice de hotéis com o esquema simples a seguir:
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
Suponhamos ainda que esse índice contém os quatro documentos a seguir:
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
Como os termos são indexados
Para entender a recuperação, é útil conhecer algumas noções básicas sobre indexação. A unidade de armazenamento é um índice invertido, um para cada campo pesquisável. Dentro de um índice invertido está uma lista classificada de todos os termos de todos os documentos. Cada termo é mapeado para a lista de documentos nos quais ele ocorre, tão evidente no exemplo a seguir.
Para produzir os termos de um índice invertido, o mecanismo de pesquisa executa a análise léxica do o conteúdo dos documentos, de forma semelhante ao que acontece durante o processamento da consulta:
- As entradas de texto são passadas para um analisador, em letras minúsculas, sem pontuação e assim por diante, dependendo da configuração do analisador.
- Os tokens são o resultado da análise lexical.
- Termos são adicionados ao índice.
É comum, mas não obrigatório, usar os mesmo analisadores para operações de indexação para que os termos da consulta pareçam mais com os termos dentro do índice.
Observação
O Azure AI Search permite especificar diferentes analisadores para indexação e pesquisa através dos parâmetros de campo adicionais indexAnalyzer e searchAnalyzer. Se não forem especificados, o analisador definido com a propriedade analyzer é usado para indexação e pesquisa.
Índice invertido para documentos de exemplo
Retornando ao nosso exemplo, para o campo título, o índice invertido tem esta aparência:
| Termo | Lista de documentos |
|---|---|
| atman | 1 |
| praia | 2 |
| hotel | 1, 3 |
| mar | 4 |
| playa | 3 |
| resort | 3 |
| retiro | 4 |
No campo título, apenas hotel aparece em dois documentos: 1, 3.
Para o campo descrição, o índice é o seguinte:
| Termo | Lista de documentos |
|---|---|
| air | 3 |
| e | 4 |
| praia | 1 |
| condicionado | 3 |
| confortável | 3 |
| distance | 1 |
| ilha | 2 |
| kauaʻi | 2 |
| local | 2 |
| norte | 2 |
| mar | 1, 2, 3 |
| de | 2 |
| on | 2 |
| silencioso | 4 |
| quartos | 1, 3 |
| reservado | 4 |
| beira-mar | 2 |
| espaçoso | 1 |
| o | 1, 2 |
| até | 1 |
| view | 1, 2, 3 |
| a pé | 1 |
| por | 3 |
Correspondência de termos de consulta com os termos indexados
Considerando os índices invertidos acima, vamos voltar para a consulta de exemplo e ver como documentos com correspondência são encontrados para a nossa consulta de exemplo. Lembre-se de que a árvore de consulta final tem esta aparência:
Durante a execução de consulta, consultas individuais são executadas nos campos pesquisáveis de independente.
A pesquisa do termo, "espaçoso", corresponde ao documento 1 (Hotel Atman).
A consulta de prefixo, "ar-condicio *", não corresponde a nenhum documento.
Esse é um comportamento que às vezes confunde os desenvolvedores. Embora o termo ar condicionado exista no documento, ele é dividido em dois termos pelo analisador padrão. Não esqueça que as consultas de prefixo, contendo termos parciais, não são analisadas. Portanto, os termos com o prefixo "ar-condicio" são pesquisados no índice invertido e não são encontrados.
A consulta de frase, "vista para o mar", procura os termos "mar" e "vista para o" e verifica a proximidade dos termos no documento original. Os documentos 1, 2 e 3 correspondem a essa consulta no campo descrição. Observe que o documento 4 possui o termo mar termo no título, mas não é considerado uma correspondência, pois estamos procurando a frase "vista para o mar" em vez de palavras individuais.
Observação
Uma consulta de pesquisa é executada de forma independente em relação a todos os campos pesquisáveis no índice do Azure AI Search, a menos que você limite os campos definidos com o parâmetro searchFields, conforme ilustrado na solicitação de pesquisa de exemplo. Os documentos correspondentes em qualquer um dos campos selecionados são retornados.
De modo geral, para a consulta em questão, os documentos que correspondem são 1, 2, 3.
Estágio 4: Pontuação
Todos os documentos em um conjunto de resultados de pesquisa recebe uma pontuação de relevância. A função da pontuação de relevância é classificar com uma pontuação mais alta os documentos que melhor respondem a uma pergunta do usuário melhor conforme expressa pela consulta de pesquisa. A pontuação é calculada com base nas propriedades estatísticas dos termos com correspondência. A fórmula da pontuação é basicamente TF/IDF (frequência do termo sobre frequência inversa do documento). Em consultas que contêm termos comuns e raros, TF/IDF fornece resultados que contêm o termo raro. Por exemplo, em um índice hipotético com todos os artigos da Wikipédia, de documentos que correspondem à consulta o presidente, os documentos com correspondência para presidente são considerados mais relevantes do que os documentos com correspondência para o.
Exemplo de pontuação
Lembre-se dos três documentos que correspondem à nossa consulta de exemplo:
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
O documento 1 foi o que melhor correspondeu à consulta, pois tanto o termo espaçoso como a frase solicitada vista para o mar ocorrem no campo descrição. Os próximos dois documentos correspondem apenas à frase vista para o mar. Pode ser surpreendente que as pontuações de relevância para os documentos 2 e 3 sejam diferentes, mesmo que ambos tenham correspondido à consulta da mesma maneira. Isso ocorre porque a fórmula de pontuação tem mais componentes do que simplesmente TF/IDF. Nesse caso, o documento 3 recebeu uma pontuação ligeiramente mais alta porque sua descrição é mais curta. Saiba mais sobre a Fórmula de pontuação prática do Lucene para entender como o tamanho do campo e outros fatores podem influenciar a pontuação de relevância.
Alguns tipos de consulta (caractere curinga, prefixo, regex) sempre contribuem com uma pontuação constante para a pontuação total do documento. Isso permite que as correspondências encontradas por meio da expansão de consulta sejam incluídas nos resultados, mas sem afetar a classificação.
Um exemplo ilustra por que isso é importante. Pesquisas com caractere curinga, inclusive pesquisas de prefixo são ambíguas por definição, porque a entrada é uma cadeia de caracteres parcial com correspondências possíveis em um grande número de termos diferentes (considere uma entrada de "pass *", com correspondências encontradas em "passeios", "passagem" e "passarela"). Dada a natureza desses resultados, não é possível inferir de maneira razoável quais termos são mais valiosos do que outros. Por esse motivo, podemos ignorar as frequências dos termos ao pontuar resultados em consultas dos tipos caractere curinga, prefixo e regex. Em uma solicitação de pesquisa de várias partes que inclui termos parciais e completos, os resultados da entrada parcial são incorporados com uma pontuação de constante para evitar desvios em relação às correspondências potencialmente inesperadas.
Ajuste de relevância
Existem duas maneiras de ajustar as pontuações de relevância no Azure AI Search:
Perfis de pontuação melhoram a classificação dos documentos na lista classificada de resultados com base em um conjunto de regras. Em nosso exemplo, podemos considerar a possibilidade de que os documentos correspondentes no campo de título são mais relevante do que os documentos correspondentes no campo descrição. Além disso, se o índice tiver um campo preço para cada hotel, poderíamos promover documentos com preços mais baixos. Saiba mais sobre adicionar perfis de pontuação em um índice de pesquisa.
Incremento de termo (disponível apenas na sintaxe da consulta Lucene completo) fornece um operador de incremento
^que pode ser aplicado a qualquer parte da árvore de consulta. Em nosso exemplo, em vez de pesquisar no prefixo air-condition*, um usuário poderia pesquisar o termo exato air-condition ou o prefixo, mas os documentos que correspondem ao termo exato são classificados mais elevados aplicando incremento à consulta do termo: air-condition^2||air-condition*. Saiba mais sobre incremento do termo em uma consulta.
Pontuação em um índice distribuído
Todos os índices do Azure AI Search são automaticamente divididos em vários fragmentos, permitindo distribuir rapidamente o índice entre vários nós rapidamente ao escalar ou reduzir verticalmente o serviço. Quando uma solicitação de pesquisa é emitida, ela é emitida em relação a cada fragmento de forma independente. Os resultados de cada fragmento são então mesclados e ordenados conforme a pontuação (se nenhuma outra ordem for definida). É importante saber que a função de pontuação faz a ponderação da frequência do termo de consulta em relação a sua frequência de documento inversa em todos os documentos dentro do fragmento, não em todos os fragmentos!
Isso significa que uma pontuação de relevância pode ser diferentes para documentos idênticos se estes estiverem em fragmentos diferentes. Felizmente, essas diferenças tendem a desaparecer conforme aumenta o número de documentos no índice devido a uma distribuição de termo mais uniforme. Não é possível supor em qual fragmento qualquer documento especificado será colocado. No entanto, supondo que uma chave de documento não é alterado, ela sempre será atribuída ao mesmo fragmento.
Em geral, a pontuação de documentos não é o melhor atributo para classificar documentos se a estabilidade da classificação for importante. Por exemplo, considerando dois documentos com uma pontuação idêntica, não existe garantia de qual aparece primeiro nas execuções posteriores da mesma consulta. A pontuação de documento deve dar somente uma noção geral de relevância do documento em relação a outros documentos no conjunto de resultados.
Conclusão
O sucesso dos mecanismos de pesquisa comercial gerou expectativas para a pesquisa de texto completo em dados particulares. Para quase qualquer tipo de experiência de pesquisa, esperamos que o mecanismo entenda a nossa intenção, mesmo quando os termos estão incorretos ou incompletos. Esperamos até correspondências com base em termos equivalentes ou sinônimos que nem especificamos.
Do ponto de vista técnico, a pesquisa de texto completo é altamente complexa, exigindo uma análise linguística sofisticada e uma abordagem sistemática para processamento de forma a extrair, expandir e transformar os termos da consulta para fornecer um resultado relevante. Devido às complexidades inerentes, existem vários fatores que podem afetar o resultado de uma consulta. Por esse motivo, investir tempo para entender os mecanismos de pesquisa de texto completo oferece benefícios tangíveis quando se tenta trabalhar com resultados inesperados.
Este artigo explorou a pesquisa de texto completo no contexto do Azure AI Search. Esperamos que todas essas informações sejam o suficiente para você reconhecer possíveis causas e resoluções para resolver problemas comuns de consulta.
Próximas etapas
Criar o índice de exemplo, experimentar consultas diferentes e examinar os resultados. Para obter instruções, confira Criar e consultar um índice no portal do Azure.
Experimente usar outra sintaxe de consulta com base na seção de exemplo Pesquisar documentos ou da Sintaxe de consulta simples no gerenciador de pesquisa no portal do Azure.
Analise os perfis de pontuação para ajustar a classificação no seu aplicativo de pesquisa.
Saiba como aplicar analisadores léxicos específico do idioma.
Configurar analisadores personalizados para o mínimo de processamento ou processamento especializado em campos específicos.
Confira também
API REST para pesquisar documentos