Carga de trabalho do SAP em cenários compatíveis com a máquina virtual do Azure
A criação da arquitetura de sistemas SAP NetWeaver, Business One Hybris ou S/4HANA no Azure abre muitas e diferentes oportunidades para o uso de diversas arquiteturas e ferramentas, na busca de uma implantação escalonável, eficiente e altamente disponível. Embora dependa do sistema operacional ou do gerenciador de banco de dados utilizado, existem restrições. Além disso, nem todos os cenários com suporte local têm suporte da mesma forma no Azure. Este documento irá orientar nas configurações sem alta disponibilidade com suporte e nas arquiteturas e configurações de alta disponibilidade usando exclusivamente as VMs do Azure.
Observação
O serviço de Instância Grande do HANA está no modo de descontinuação e não aceita mais novos clientes. Ainda é possível fornecer unidades para clientes existentes do HANA em Instâncias Grandes. Para obter alternativas, verifique as ofertas de VMs do Azure certificadas pelo HANA no Diretório de Hardware do HANA. Para cenários que tinham e ainda têm suporte para clientes existentes do HANA em Instâncias Grandes do HANA, verifique o artigo Cenários com suporte para Instâncias Grandes do HANA.
Restrições gerais da plataforma
O Azure tem várias plataformas chamadas VMs nativas do Azure que são oferecidas como serviço da primeira parte. Instâncias Grandes no HANA, que está no modo sunset, é uma dessas plataformas. Os Serviços VMware do Azure são outro desses serviços da primeira parte. Os Serviços VMware do Azure em geral não são compatíveis com o SAP para hospedar a carga de trabalho SAP. Consulte a nota de suporte do SAP #2138865 – Aplicativos SAP no VMware Cloud: Produtos com suporte e configurações de VM para obter mais detalhes sobre o suporte do VMware em diferentes plataformas.
Além do Active Directory local, o Azure oferece um serviço SaaS do Active Directory gerenciado com Microsoft Entra Domain Services (AD tradicional gerenciado pela Microsoft) e Microsoft Entra ID. Os componentes SAP hospedados no sistema operacional Windows geralmente dependem do uso do Windows Active Directory. Nesse caso, o Active Directory tradicional, hospedado localmente por você, ou o Microsoft Entra Domain Services (ainda em teste). Mas esses componentes SAP não podem funcionar com o Microsoft Entra ID nativo. O motivo é que ainda há lacunas maiores na funcionalidade entre o Active Directory em sua forma local ou em sua forma SaaS (Microsoft Entra Domain Services) e o Microsoft Entra ID nativo. Essa dependência é o motivo pelo qual as contas do Microsoft Entra não são suportadas para aplicativos baseados em SAP NetWeaver e S/4 HANA no sistema operacional Windows. As contas tradicionais do Active Directory precisam ser usadas nesses cenários.
| Serviço do AD | Aplicativos com suporte baseados no SAP NetWeaver e no S/4 HANA no sistema operacional Windows |
|---|---|
| Windows Active Directory local | Com suporte |
| Serviços de Domínio do Microsoft Entra | Com suporte |
| ID do Microsoft Entra | Sem suporte |
O acima não afeta o uso de contas do Microsoft Entra para cenários de logon único (SSO) com aplicativos SAP.
Configuração de duas camadas
Uma configuração de duas camadas no SAP é considerada como sendo criada fora de uma camada combinada do DBMS do SAP e da camada de aplicativo que é executada no mesmo servidor ou unidade da VM. A segunda camada é considerada como a camada de interface do usuário. Para uma configuração de duas camadas, o DBMS e a camada de aplicativo SAP compartilham os recursos da VM do Azure. Como resultado, você precisa configurar os diferentes componentes de forma que eles não disputem recursos. Também é necessário ter cuidado para não sobrecarregar os recursos da VM. Essa configuração não fornece nenhuma alta disponibilidade além dos contratos de Nível de Serviço do Azure dos diferentes componentes do Azure envolvidos.
Ela pode ser representada graficamente da seguinte forma:
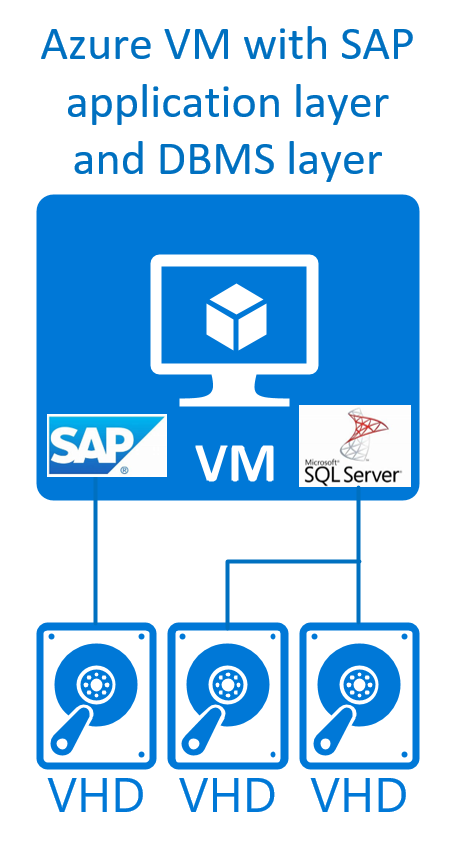
Essas configurações têm suporte para Windows, Red Hat, SUSE e Oracle Linux para os sistemas DBMS do SQL Server, Oracle, DB2, maxDB e SAP ASE, para casos de produção e não produção. Para o SAP HANA como DBMS, o SAP dá suporte a um cenário indicado na nota da SAP nº 1953429. Até agora, nenhuma das distribuições do Linux forneceu documentação de HA suficiente para configurar e operar um cluster do Pacemaker nessa configuração. Como resultado, esse tipo de configuração é compatível com o Azure apenas para casos que não são de produção e não exigem um cluster de failover de alta disponibilidade.
Há suporte para este tipo de configuração em todas as combinações de SO/DBMS com suporte no Azure. No entanto, é obrigatório definir a configuração do DBMS e dos componentes do SAP de modo que os respectivos componentes não disputem recursos de memória e CPU, excedendo os recursos físicos disponíveis. Isso precisa ser feito restringindo-se a memória que o DBMS tem permissão para alocar. Também é necessário limitar a Memória Estendida do SAP nas instâncias do aplicativo. Você também precisa monitorar o consumo geral de CPU da VM para garantir que os componentes não estejam maximizando os recursos da CPU.
Observação
Para sistemas SAP de produção, recomendamos configurações adicionais de alta disponibilidade e recuperação de desastre eventual, conforme descrito posteriormente neste documento
Configuração de três camadas
Nessas configurações, separa-se a camada de aplicativo do SAP e a camada DBMS em diferentes VMs. Normalmente, isso é feito para sistemas maiores e por para ser mais flexível nos recursos da camada de aplicativo do SAP. Na configuração mais simples, não há nenhuma alta disponibilidade além dos contratos de Nível de Serviço do Azure dos diferentes componentes do Azure envolvidos.
Assim seria sua representação gráfica:
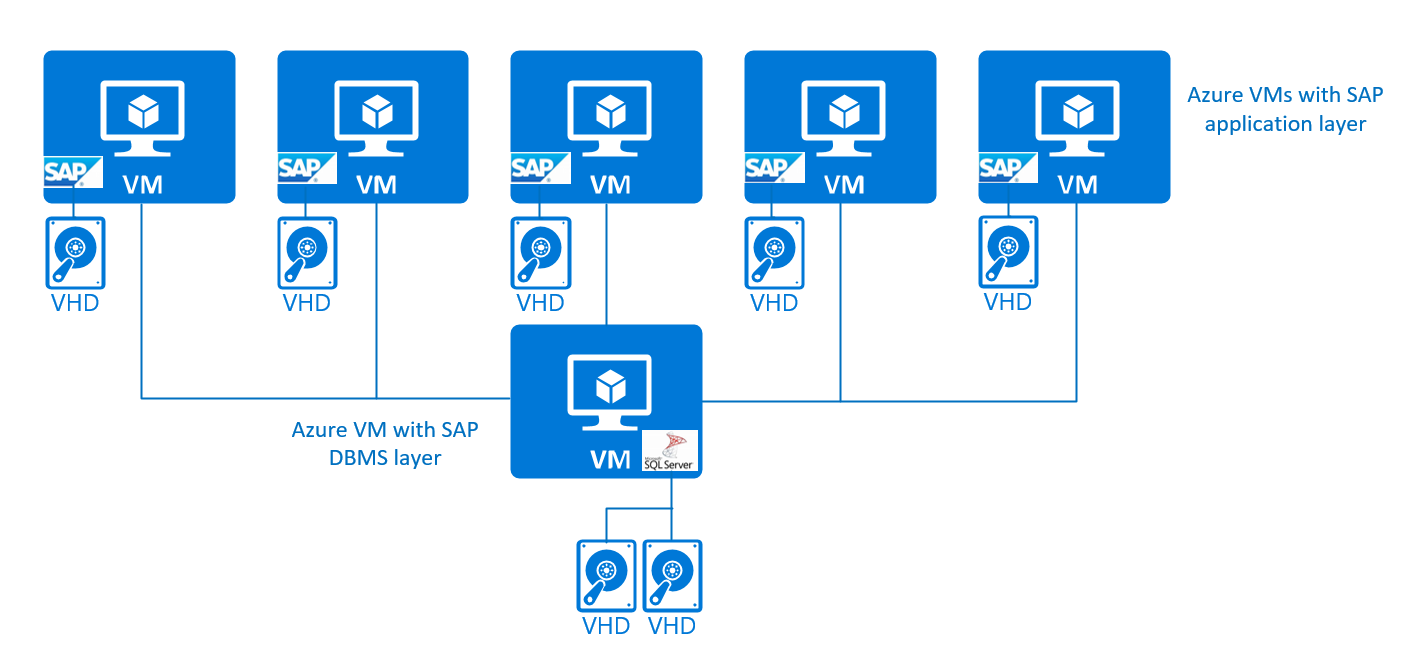
Esse tipo de configuração tem suporte no Windows, Red Hat, SUSE e Oracle Linux para os sistemas DBMS do SQL Server, Oracle, DB2, SAP HANA, maxDB e SAP ASE, para casos de produção e não produção. Para simplificar, não iremos distinguir entre os Serviços Centrais e as instâncias de diálogo do SAP na camada de aplicativo do SAP. Nessa configuração de três camadas simples, não haveria proteção de alta disponibilidade para os Serviços Centrais do SAP.
Observação
Para sistemas SAP de produção, recomendamos configurações adicionais de alta disponibilidade e recuperação de desastre eventual, conforme descrito posteriormente neste documento
Várias instâncias do DBMS por VM
Nesse tipo de configuração, você hospeda várias instâncias do DBMS por VM do Azure. A motivação pode ser ter menos sistemas operacionais para manter e, assim, a redução do custo. Outras motivações são aumentar a flexibilidade e a eficiência compartilhando recursos de uma VM maior ou uma unidade do SAP HANA em Instâncias Grandes entre várias instâncias do DBMS. Até agora, essas configurações eram exibidas principalmente para sistemas de não produção.
Tal configuração teria a seguinte aparência:
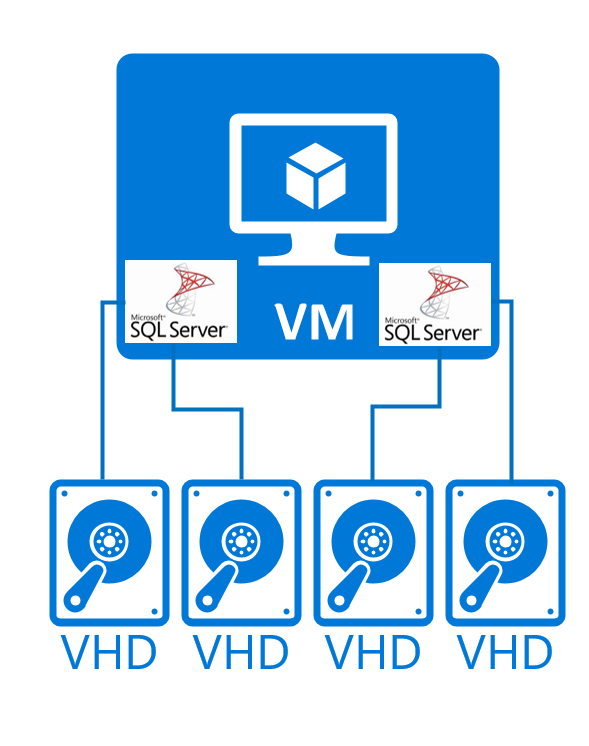
Esse tipo de implantação de DBMS tem suporte para:
- SQL Server no Windows
- IBM Db2. Descubra mais detalhes no artigo Múltiplas instâncias (Linux, UNIX)
- Para Oracle. Para obter detalhes, consulte Nota de suporte do SAP nº1778431 e notas do SAP respectivas
- Para o SAP HANA, há suporte para várias instâncias em uma VM – o SAP chama esse método de implantação de MCOS. Para obter detalhes, confira o artigo da SAP Vários sistemas SAP HANA em um host (macOS)
Ao executar várias instâncias de banco de dados em um host, é necessário certificar-se de que as diferentes instâncias não estão disputando recursos, excedendo, assim, os limites de recursos físicos da VM. Isso é importante principalmente para a memória na qual você precisa limitar a memória que qualquer uma das instâncias que compartilham a VM pode alocar. Isso também pode ser verdadeiro para os recursos de CPU que as diferentes instâncias de banco de dados podem aproveitar. Todos os sistemas de banco de dados mencionados têm configurações que permitem limitar a alocação de memória e os recursos de CPU no nível da instância. Para contar com suporte a essa configuração em VMs do Azure, espera-se que os discos ou os volumes usados para os arquivos de log de dados e de refazer dos bancos de dados gerenciados pelas diferentes instâncias sejam separados. Em outras palavras, os arquivos de log de dados ou refazer dos bancos de dados gerenciados por uma instância diferente do DBMS não devem compartilhar os mesmos discos ou volumes.
Observação
Para sistemas SAP de produção, recomendamos configurações adicionais de alta disponibilidade e recuperação de desastre eventual, conforme descrito posteriormente neste documento. Não há suporte para VMs com várias instâncias de DBMS com as configurações de alta disponibilidade descritas posteriormente neste documento.
Múltiplas instâncias de Diálogo do SAP em uma VM
Em muitos casos, várias instâncias de diálogo foram implantadas em servidores bare-metal, ou até mesmo em VMs executadas em nuvens privadas. O motivo para essas configurações era adaptar certas instâncias de diálogo do SAP a determinadas cargas de trabalho, funcionalidades de negócios ou tipos de carga de trabalho. O motivo para não isolar essas instâncias em VMs separadas era o esforço de manutenção e operações do sistema operacional. Ou, em vários casos, os custos no caso do hoster ou do operador da VM solicitar uma valor mensal por VM operada e administrada. No Azure, um cenário de hospedagem de várias instâncias de diálogo do SAP em uma única VM tem suporte para fins de produção e não produção nos sistemas operacionais Windows, Red Hat, SUSE e Oracle Linux. O parâmetro de kernel SAP PHYS_MEMSIZE disponível em kernels do Windows e Linux modernos, deverá ser definido se várias instâncias do Servidor de Aplicativos SAP estiverem em execução em uma única VM. Recomenda-se também limitar a expansão da Memória Estendida do SAP em sistemas operacionais, como o Windows, em que o crescimento automático da memória estendida do SAP é implementado. Isso pode ser feito com o parâmetro de perfil do SAP em/max_size_MB.
A configuração de três camadas, em que várias instâncias de diálogo do SAP são executadas em VMs do Azure pode ter a seguinte aparência:
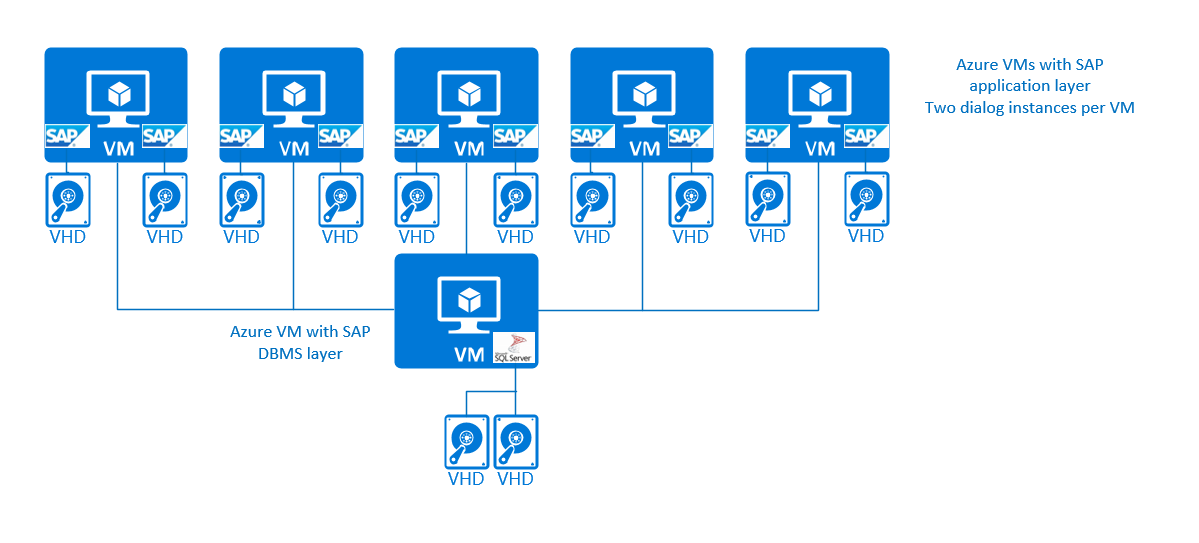
Para simplificar, não iremos distinguir entre os Serviços Centrais e as instâncias de diálogo do SAP na camada de aplicativo do SAP. Nessa configuração de três camadas simples, não haveria proteção de alta disponibilidade para os Serviços Centrais do SAP. Para sistemas de produção, não é recomendável deixar os Serviços Centrais do SAP desprotegidos. Para obter informações específicas nas assim chamadas configurações de múltiplos SID em relação às Instâncias Centrais do SAP e à alta disponibilidade dessas configurações, consulte as seções posteriores deste documento.
Proteção de Alta Disponibilidade para a camada do DBMS do SAP
Ao buscar implantar sistemas de produção do SAP, é necessário considerar o tipo de espera ativa das configurações de alta disponibilidade. Especialmente com o SAP HANA, onde os dados precisam ser carregados na memória antes de serem capazes de receberem o desempenho completo e a escalabilidade, a recuperação de serviço do Azure não é a medida ideal para a alta disponibilidade.
Em geral, a Microsoft dá suporte apenas a configurações de alta disponibilidade e pacotes de software descritos na seção de carga de trabalho do SAP. Você pode ler a mesma instrução na Nota do SAP nº 1928533. A Microsoft não dará suporte para outras estruturas de alta disponibilidade de software de terceiros que não estejam documentadas pela Microsoft com a carga de trabalho SAP. Nesses casos, o fornecedor dessa estrutura é a parte que fornecerá suporte para a configuração da alta disponibilidade, e você como cliente precisa contratá-lo para o processo de suporte. As exceções serão mencionadas neste artigo.
Em geral, a Microsoft dá suporte a um conjunto limitado de configurações de alta disponibilidade nas VMs do Azure ou em unidades de Instâncias Grandes do HANA.
Para as VMs do Azure, há suporte para as seguintes configurações de alta disponibilidade no nível do DBMS:
- Replicação do Sistema do SAP HANA com base no Linux Pacemaker no SUSE e no Red Hat. Consulte os artigos detalhados:
- Configurações n+m de Expansão do SAP HANA usando os Azure NetApp Files no SUSE e no Red Hat. Os detalhes estão listados nestes artigos:
- Cluster de Failover do SQL Server com base nos Serviços de Arquivo em Expansão do Windows. Embora a recomendação para sistemas de produção seja usar o SQL Server Always On em vez de clustering. SQL Server Always On fornece melhor disponibilidade usando armazenamento separado. Os detalhes estão descritos neste artigo:
- SQL Server Always On tem suporte com o sistema operacional Windows para SQL Server no Azure. Essa é a recomendação padrão para as Instâncias do SQL Server de produção no Azure. Os detalhes estão descritos nestes artigos:
- Oracle Data Guard para Windows e Oracle Linux. Os detalhes para o Oracle Linux podem ser encontrados neste artigo:
- A documentação detalhada do IBM Db2 HADR no SUSE e RHEL para SUSE e RHEL usando o Pacemaker está disponível aqui:
- Configuração do SAP ASE e do SAP maxDB conforme detalhado nos seguintes documentos:
- Os cenários de alta disponibilidade das Instâncias Grandes do HANA são detalhados em:
Importante
Não damos suporte a configurações de múltiplas instâncias de DBMS em uma VM para nenhum dos cenários descritos acima. Significa que, em cada um dos casos, apenas uma instância de banco de dados pode ser implantada por VM e protegida com os métodos de alta disponibilidade descritos. Não há suporte para a proteção de múltiplas instâncias de DBMS no mesmo cluster de failover do Windows ou do Pacemaker neste momento. E também só há suporte para o Oracle Data Guard para os casos de implantação de instância única por VM.
Vários sistemas de banco de dados permitem hospedar vários bancos de dados em uma instância DBMS. Assim como no SAP HANA, vários bancos de dados podem ser hospedados em MDC (vários contêineres de banco de dados). Há suporte para as configurações de vários bancos de dados caso estejam funcionando em um único recurso de cluster de failover. As configurações que não possuem suporte são aquelas em que vários recursos de cluster seriam necessários. Como para configurações em que você definiria vários Grupos de Disponibilidade do SQL Server em uma Instância do SQL Server.
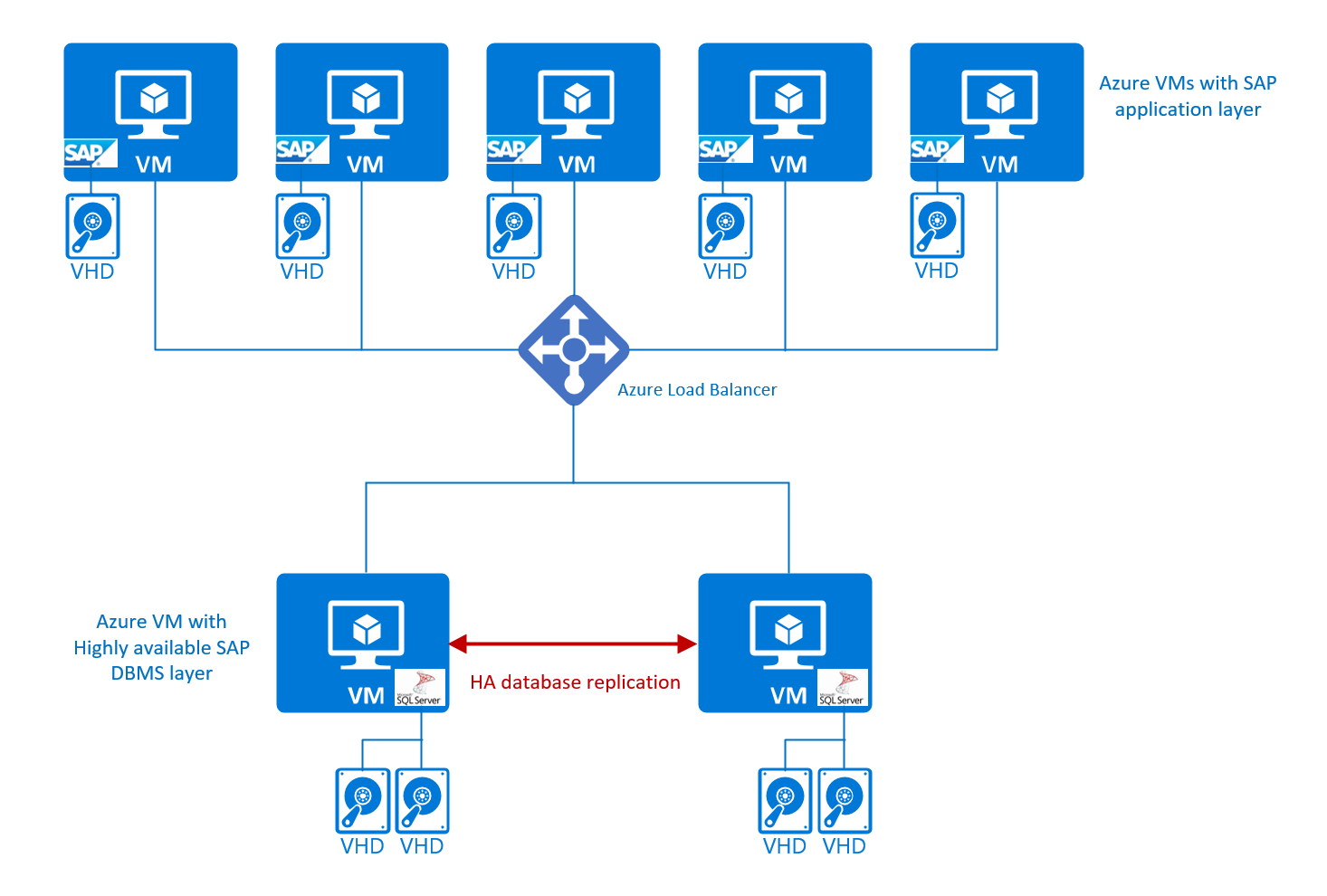
Dependendo do DBMS, e/ou dos sistemas operacionais, componentes como o balanceador de carga do Azure podem ou não serem necessários como parte da arquitetura da solução.
Especificamente para maxDB, a configuração de armazenamento precisa ser diferente. Com o maxDB, os arquivos de dados e de log precisam estar localizados no armazenamento compartilhado para as configurações da alta disponibilidade. Somente no caso do maxDB, o armazenamento compartilhado possui suporte para a alta disponibilidade. Para todos os outros DBMS, as pilhas de armazenamento separadas por nó são as únicas configurações de disco com suporte.
Há outras estruturas de alta disponibilidade conhecidas, e também sabe-se que elas são executadas no Microsoft Azure. No entanto, a Microsoft não testou essas estruturas. Se você quiser criar uma configuração de alta disponibilidade com essas estruturas, trabalhe com o provedor do software para:
- Desenvolver uma arquitetura de implantação
- Implantar a arquitetura
- Obter o suporte da arquitetura
Importante
O Microsoft Azure Marketplace oferece vários dispositivos de software que fornecem soluções de armazenamento além do armazenamento nativo do Azure. Esses dispositivos de software podem ser usados para criar compartilhamentos NFS e, teoricamente, poderiam ser usados nas implantações de expansão do SAP HANA em que seja necessário um nó em espera. Devido a vários motivos, nenhum desses aparelhos de software de armazenamento tem suporte para quaisquer das implantações de DBMS da Microsoft e do SAP no Azure. Não há qualquer suporte para implantações de DBMS em compartilhamentos SMB nesse momento. As implantações do DBMS em compartilhamentos NFS são limitadas a compartilhamentos NFS 4.1 no Azure NetApp Files.
Alta disponibilidade para Serviços Centrais do SAP
Os Serviços Centrais do SAP são um segundo ponto único de falha de sua configuração do SAP. Como resultado, você também precisaria proteger esses processos de Serviços Centrais. A oferta documentada e com suporte para leituras de carga de trabalho do SAP é a seguinte:
- Servidor de Cluster de Failover do Windows usando Serviços de Arquivo de Expansão do Windows para sapmnt e diretório de transporte global. Os detalhes estão descritos no artigo:
- Clustering de uma instância do SAP ASCS/SCS em um cluster de failover do Windows usando o arquivo compartilhado de cluster no Azure
- Preparar a infraestrutura do Azure para alta disponibilidade do SAP usando um cluster de failover do Windows e compartilhamento de arquivos para instâncias ASCS/SCS do SAP
- Servidor de Cluster de Failover do Windows usando compartilhamento SMB com base no Azure NetApp Files para sapmnt e diretório de transporte global. Os detalhes estão listadas no artigo:
- Servidor de Cluster de Failover do Windows baseado em SIOS
Datakeeper. Embora documentado pela Microsoft, você precisa de uma relação de suporte com o SIOS para poder se envolver com o suporte SIOS ao usar essa solução. Os detalhes estão descritos no artigo: - Pacemaker no sistema operacional SUSE com a criação de um compartilhamento NFS altamente disponível usando duas VMs SUSE e
drdbpara a replicação de arquivos. Mais detalhes estão documentados no artigo - Sistema operacional Pacemaker SUSE com compartilhamentos NFS fornecidos pelo Azure NetApp Files. Os detalhes estão documentados em
- Pacemaker no sistema operacional Red Hat com compartilhamento NFS hospedado em um cluster
glusterfs. Os detalhes podem ser encontrados nos artigos - Pacemaker no sistema operacional Red Hat com compartilhamento NFS hospedado no Azure NetApp Files. Os detalhes são descritos no artigo
Das soluções listadas, você precisa de uma relação de suporte com o SIOS para dar suporte ao produto Datakeeper, e para se envolver com o SIOS diretamente se forem encontrados problemas. Dependendo do modo como você licenciou o Windows, o Red Hat e/ou o sistema operacional SUSE, você também pode precisar ter um contrato de suporte com seu provedor de sistema operacional para obter suporte total das configurações de alta disponibilidade listadas.
A configuração também pode ser exibida assim:
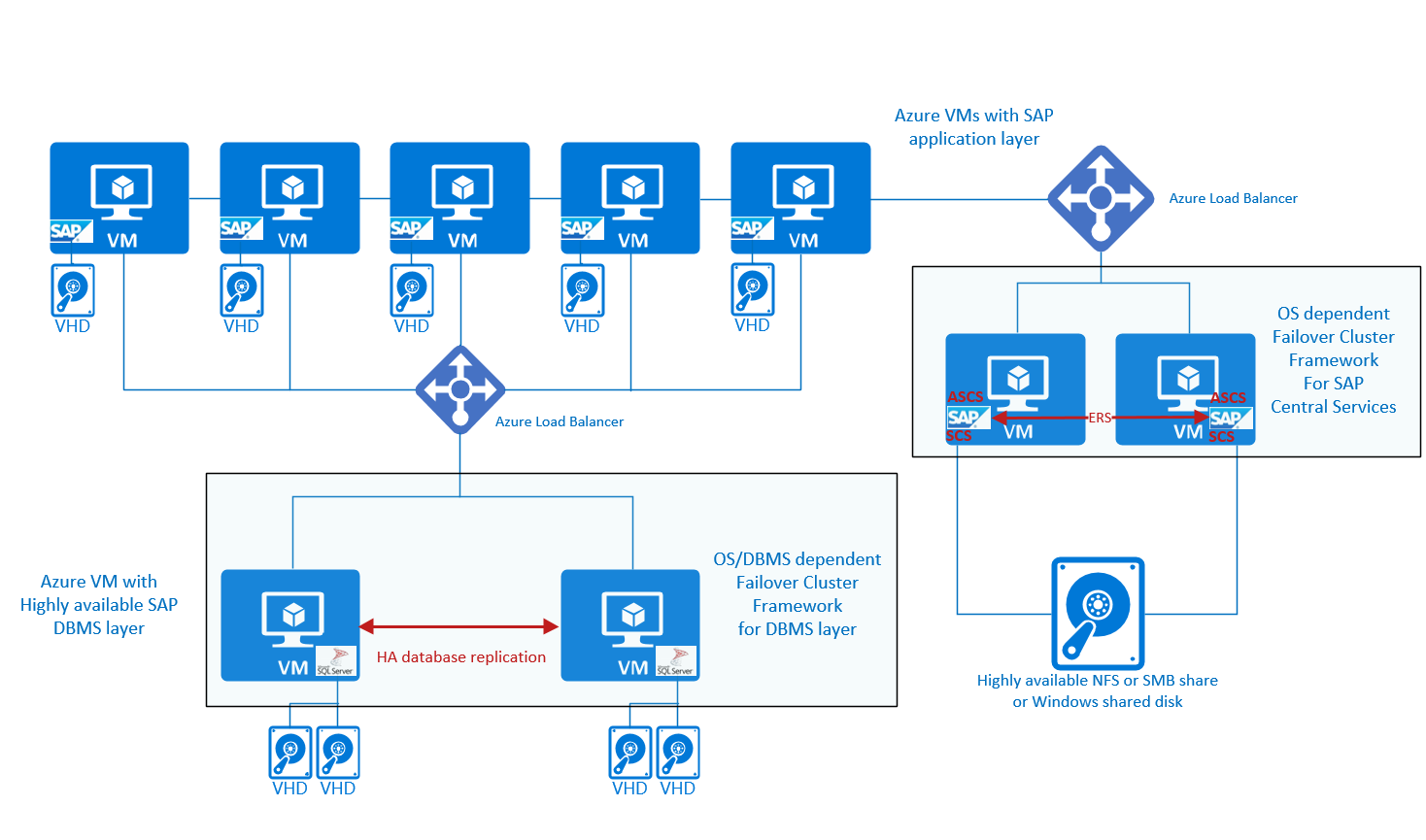
No lado direito dos gráficos são mostrados os Serviços Centrais do SAP de alta disponibilidade. Além de proteger os serviços do SAP Central com uma estrutura de cluster de failover que pode fazer failover em cenários de falha. Há necessidade de um compartilhamento NFS ou SMB altamente disponível ou de um disco compartilhado do Windows para garantir que o sapmnt e o diretório de transporte global estejam disponíveis, independentemente da existência de uma só VM. Algumas soluções adicionais, como o Servidor de Cluster de Failover do Windows e o Pacemaker, exigirão que um Azure Load Balancer direcione ou redirecione o tráfego para um nó íntegro.
Na lista apresentada, não há nenhuma menção do sistema operacional Oracle Linux. O Oracle Linux não oferece suporte ao Pacemaker como uma estrutura de cluster. Se quiser implantar seu sistema SAP no Oracle Linux e precisar de uma estrutura de alta disponibilidade, você precisará trabalhar com fornecedores terceirizados. Um dos fornecedores é o SIOS, com sua Protection Suite para Linux com suporte do SAP no Azure. Para obter mais informações, leia a Noa do SAP nº 1662610 – Detalhes de suporte para a Protection Suite para Linux do SIOS para obter mais detalhes.
Armazenamento com suporte com os cenários de Serviços Centrais do SAP listados acima
Como apenas um subconjunto de tipos do armazenamento do Azure está fornecendo compartilhamentos NFS ou SMB altamente disponíveis, essa qualidade, para o uso em nossos cenários de cluster de serviços centrais SAP, é uma lista de tipos de armazenamento com suporte
- O Servidor de Cluster de Failover do Windows com Servidor de Arquivos de Expansão pode ser implantado em todos os tipos de armazenamento do nativos do Azure, exceto o Azure NetApp Files. No entanto, a recomendação é aproveitar o Armazenamento Premium devido a contratos de nível de serviço superiores em taxa de transferência e IOPS.
- O Servidor de Cluster de Failover do Windows com SMB no Azure NetApp Files possui suporte no Azure NetApp Files. Os compartilhamentos SMB hospedados nos serviços de Arquivo Premium do Azure também têm suporte para esse cenário. Não há suporte para arquivos padrão do Azure
- O Servidor de Cluster de Failover do Windows com disco compartilhado do Windows baseado no SIOS
Datakeeperpode ser implantado em todos os tipos de armazenamento nativos do Azure, exceto no Azure NetApp Files. No entanto, a recomendação é aproveitar o Armazenamento Premium devido a contratos de nível de serviço superiores em taxa de transferência e IOPS. - O SUSE ou o Pacemaker do Red Hat que usa compartilhamentos NFS no Azure NetApp Files.
- SUSE ou Red Hat Pacemaker que usa compartilhamentos NFS em Arquivos Premium do Azure usando LRS ou ZRS com suporte. Não há suporte para arquivos padrão do Azure
- O Pacemaker do SUSE que usa uma configuração
drdbentre duas VMs possui suporte utilizando tipos de armazenamento nativos do Azure, exceto o Azure NetApp Files. No entanto, recomendamos usar um dos serviços de primeira parte com Arquivos Premium do Azure ou Azure NetApp Files. - O Pacemaker do Red Hat que utiliza
glusterfspara fornecer o compartilhamento NFS tem suporte usando os tipos de armazenamento nativos do Azure, exceto o Azure NetApp Files. No entanto, recomendamos usar um dos serviços de primeira parte com Arquivos Premium do Azure ou Azure NetApp Files.
Importante
O Microsoft Azure Marketplace oferece vários dispositivos de software que fornecem soluções de armazenamento além do armazenamento nativo do Azure. Esses dispositivos de software de armazenamento podem ser usados para criar compartilhamentos de NFS ou SMB, e poderiam também, teoricamente, ser usados nos Serviços Centrais do SAP de cluster de failover. Essas soluções não são diretamente suportadas para a carga de trabalho do SAP pela Microsoft. Se você decidir usar uma solução desse tipo para criar seu compartilhamento NFS ou SMB, o suporte para a configuração do Serviço Central do SAP precisará ser fornecido por terceiros que possuam o software no dispositivo de software de armazenamento.
Clusters de failover dos Serviços Centrais do SAP com Múltiplos SIDs
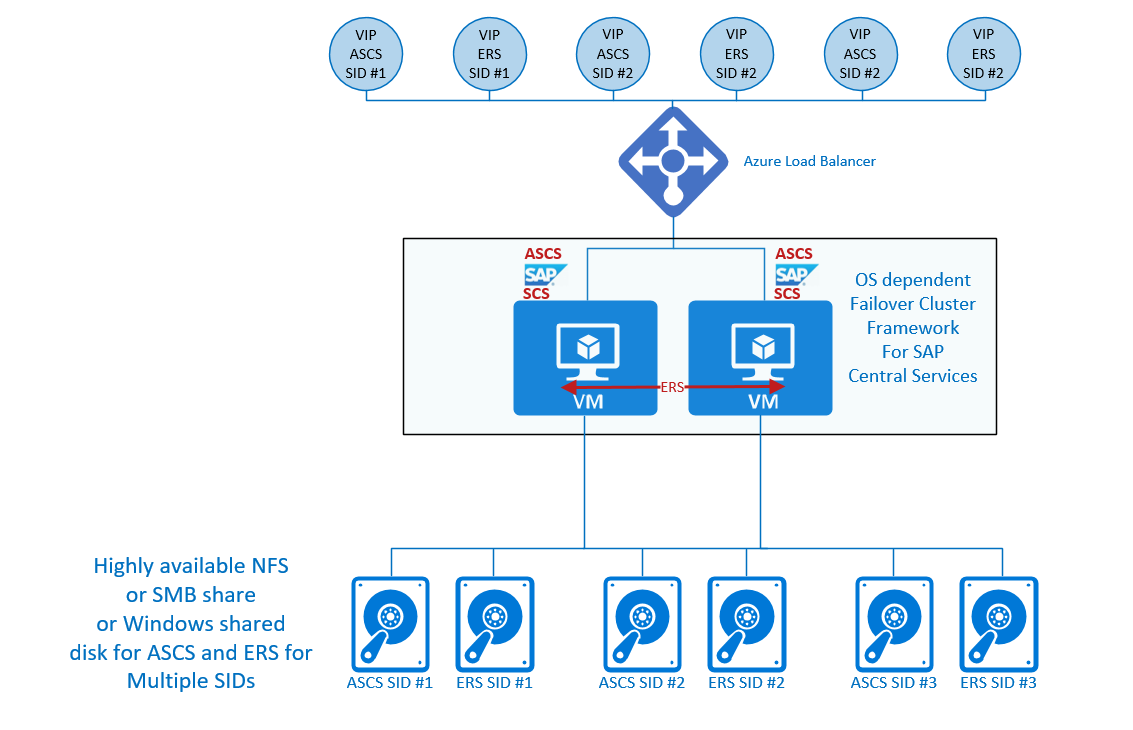
Para reduzir o número de VMs necessárias em grandes cenários do SAP, o SAP permite executar instâncias de seus Serviços Centrais de vários sistemas SAP diferentes na configuração do cluster de failover. Imagine casos em que você tenha 30 sistemas de produção NetWeaver ou S/4HANA ou mais. Sem o clustering de múltiplos SIDs, essas configurações demandariam 60 VMs ou mais, em 30 configurações de cluster ou mais de failover do Windows ou Pacemaker. A implantação de vários Serviços Centrais do SAP em dois nós numa configuração de cluster de failover pode reduzir significativamente o número de VMs. No entanto, a implantação de várias instâncias de Serviços Centrais do SAP em uma única configuração de cluster de dois nós também possui algumas desvantagens. Os problemas relacionados a uma única VM na configuração do cluster se aplicam a vários sistemas SAP. A manutenção no SO convidado em execução na configuração do cluster requer mais coordenação, já que vários sistemas SAP de produção são afetados. Ferramentas como o SAP LaMa não dão suporte a clustering de múltiplos SID no processo de clonagem do sistema.
No Azure, uma configuração de cluster de múltiplos SID possui suporte para o sistema operacional Windows com ENSA1 e ENSA2. A recomendação é não combinar a ENSA1 (Arquitetura de Serviço de Replicação de Enfileiramento) mais antiga com a nova arquitetura (ENSA2) em um cluster de múltiplos SID. Os detalhes sobre essa arquitetura estão documentados nos artigos
- Alta disponibilidade de vários SIDs da instância do SAP ASCS/SCS com clustering de failover do Windows Server e disco compartilhado no Azure
- Alta disponibilidade de vários SIDs da instância do SAP ASCS com clustering de failover do Windows Server e compartilhamento de arquivos no Azure
Para o SUSE, também há suporte para um cluster com múltiplos SID baseado no Pacemaker. Até agora, a configuração tem suporte para:
- Um máximo de cinco instâncias do SAP ASCS/SCS
- A antiga arquitetura Ice do servidor de replicação de enfileiramento (ENSA1)
- Configurações de cluster do Pacemaker de dois nós
A configuração está documentada em Alta disponibilidade do SAP NetWeaver nas VMs do Azure no SUSE Linux Enterprise Server para aplicativos SAP com múltiplos SID
Um cluster com múltiplos SID com servidor de replicação de enfileiramento possui o seguinte esquema
Cenários de expansão do SAP HANA
Os cenários de expansão do SAP HANA têm suporte para um subconjunto das VMs do Azure com certificação para HANA, conforme listado no diretório de hardware do SAP HANA. Todas as VMs marcadas com 'Sim' na coluna 'Clustering' podem ser usadas para a expansão de OLAP ou do S/4HANA. As configurações sem espera têm suporte com os tipos do Armazenamento do Azure de:
- O armazenamento Premium do Azure v1, incluindo o Acelerador de Gravação do Azure para o volume /hana/log
- Armazenamento Premium do Azure v2
- Disco Ultra
- Azure NetApp Files
As configurações de expansão do SAP HANA para OLAP ou S/4HANA com nó(s) em espera têm suporte exclusivo com o NFS compartilhado hospedado no Azure NetApp Files.
Para obter mais informações sobre as configurações exatas de armazenamento com ou sem nó em espera, leia os artigos:
- Configurações de armazenamento de máquina virtual do SAP HANA no Azure
- Implantar um sistema de expansão SAP HANA com o nó em espera em VMs do Azure usando Azure NetApp Files no SUSE Linux Enterprise Server
- Implantar um sistema de expansão SAP HANA com o nó em espera em VMs do Azure usando Azure NetApp Files no Red Hat Enterprise Linux
- Nota de suporte do SAP nº 2080991
Cenário de Recuperação de Desastre
Há uma variedade de cenários de recuperação de desastres com suporte. Definimos arquiteturas de desastre como arquiteturas que devem compensar uma região toda do Azure que esteja fora da rede. Isso significa que é necessário que o destino da recuperação de desastre tenha uma região de destino do Azure diferente para executar sua estrutura do SAP. Separamos os métodos e as configurações na camada DBMS e na camada não DBMS.
Camada DBMS
Para a camada do DBMS, as configurações que usam os mecanismos de replicação nativos do DBMS, como o Always On, o Oracle Data Guard, o DB2 HADR, o SAP ASE Always on ou replicação do sistema HANA possuem suporte. É obrigatório que o fluxo de replicação nesses casos seja assíncrono, ao invés de síncrono, como nos cenários típicos de alta disponibilidade que são implantados em uma única região do Azure. Um exemplo típico dessa configuração de recuperação de desastre do DBMS com suporte é descrito no artigo Disponibilidade do SAP HANA nas regiões do Azure. O segundo gráfico nessa seção mostra um cenário tendo o HANA como exemplo. Os bancos de dados principais com suporte para aplicativos do SAP são capazes de serem implantados em um cenário como esse.
Há suporte para usar uma VM menor como instância de destino na região de recuperação de desastre, pois essa VM não experimenta o tráfego completo de carga de trabalho. Ao fazer isso, é necessário manter em mente as seguintes considerações:
- Os tipos de VM menores não permitem tantos discos conectados quanto VMs menores
- VMs menores têm menos taxa de transferência de rede e armazenamento
- O redimensionamento entre famílias de VMs pode ser problemático quando as diferentes VMs são coletadas em um conjunto de disponibilidade do Azure ou quando o redimensionamento deve ocorrer entre a família da série M e a família Mv2 de VMs
- O consumo de CPU e memória para a instância do banco de dados poder receber o fluxo de alterações com atraso mínimo e recursos suficientes de CPU e memória para aplicar essas alterações com atraso mínimo nos dados
Maiores detalhes sobre as limitações de diferentes tamanhos de VM podem ser encontrados na página Tamanhos de VM
Outro método com suporte para implantar um destino de DR é ter uma segunda instância de DBMS instalada em uma VM que executa uma instância de DBMS de não produção de uma instância do SAP de não produção. Isso pode ser um pouco mais desafiador, pois você precisa descobrir o que é preciso na memória, recursos de CPU, largura de banda de rede e largura de banda de armazenamento para as instâncias de destino específicas que devem funcionar como instância principal no cenário de DR. Principalmente no HANA, é altamente recomendável que você configure a instância que funciona como destino de DR em um host compartilhado, para que os dados não sejam pré-carregados nessa referida instância.
Observação
O uso de Azure Site Recovery não foi testado para implantações de DBMS na carga de trabalho do SAP. Como resultado, não há suporte para a camada DBMS de sistemas do SAP neste momento. Não há suporte para outros métodos de replicação da Microsoft e do SAP que não estejam listados. O uso de software de terceiros para replicar a camada DBMS de sistemas do SAP entre diferentes regiões do Azure precisa ter suporte do fornecedor do software, e não terá suporte por meio dos canais de suporte da Microsoft e do SAP.
Camada não DBMS
Para a camada de aplicativo SAP e compartilhamentos eventuais ou para os locais de armazenamento necessários, os dois principais cenários são usados pelos clientes:
- Os destinos de recuperação de desastre na segunda região do Azure não estão sendo usados para nenhuma finalidade de produção ou de não produção. Nesse cenário, as VMs que funcionam como destino de recuperação de desastre idealmente não são implantadas, e a imagem e as alterações nas imagens da camada de aplicativo do SAP de produção são replicadas para a região de recuperação de desastre. Uma funcionalidade que pode executar tal tarefa é o Azure Site Recovery. O Azure Site Recovery dá suporte a cenários de replicação de Azure para Azure como este.
- Os destinos de recuperação de desastre são as VMs que estão realmente em uso por sistemas de não produção. Toda a estrutura do SAP é distribuída entre duas regiões diferentes do Azure, geralmente com sistemas de produção em uma região, e sistemas de não produção em outra região. Em muitas implantações de clientes, o cliente tem um sistema de não produção equivalente a um sistema de produção. O cliente tem instâncias de aplicativo de produção pré-instaladas nos sistemas de não produção da camada de aplicativo. Em um evento de failover, as instâncias que não são de produção seriam desligadas, os nomes virtuais das VMs de produção seriam movidos para as VMs que não são de produção (após a atribuição de novos endereços IP no DNS) e as instâncias de produção pré-instaladas seriam iniciadas
Clusters dos Serviços Centrais do SAP
Os clusters dos Serviços Centrais do SAP que usam discos compartilhados (Windows), compartilhamentos SMB (Windows) ou compartilhamentos NFS são um pouco mais difíceis de replicar. No lado Windows, o Windows Replication Storage é uma possível solução. No Linux, a ressincronização é uma solução viável. Além disso, a replicação entre regiões do Azure NetApp Files é uma solução viável.
Cenários sem suporte
Há uma lista de cenários que não possuem suporte para carga de trabalho do SAP nas arquiteturas do Azure. O termo sem suporte significa que a SAP e a Microsoft não dão suporte a essas configurações e precisarão encaminhá-las aos terceiros que fornecem o software para estabelecer essas arquiteturas. Duas das categorias são:
- Dispositivos de software de armazenamento: há vários dispositivos de software de armazenamento no mercado. Alguns dos fornecedores oferecem documentação própria sobre como usar esses dispositivos de software de armazenamento no Azure relacionados a softwares do SAP. O suporte a configurações ou implantações que envolvem esses dispositivos de software de armazenamento precisa ser providenciado pelo fornecedor desses dispositivos. Esse fato também é mencionado na Nota de suporte do SAP nº 2015553
- Estruturas de alta disponibilidade: Somente o Pacemaker e o cluster de failover do Windows Server são estruturas de alta disponibilidade com suporte para carga de trabalho do SAP no Azure. Como mencionado anteriormente, a solução
Datakeeperdo SIOS é descrita e documentada pela Microsoft. No entanto, os componentesDatakeeperdo SIOS precisam ter suporte fornecido pelo SIOS como o fornecedor desses componentes. O SAP também listou outras estruturas de alta disponibilidade certificadas em várias notas do SAP. Algumas delas foram certificadas pelo terceiro fornecedor para o Azure também. No entanto, o suporte para as configurações que usam esses produtos precisa ser fornecido pelo fornecedor do produto. Fornecedores diferentes possuem integração diferente aos processos de suporte do SAP. Você deve esclarecer qual processo de suporte funciona melhor para o fornecedor específico antes de decidir usar o produto nas configurações do SAP implantadas no Azure. - Não há suporte para os clusters de discos compartilhados em que os arquivos de banco de dados residem, com a exceção de maxDB. Para todos os outros bancos de dados, a solução com suporte é ter locais de armazenamento separados em vez de um compartilhamento SMB ou NFS, ou um disco compartilhado para configurar cenários de alta disponibilidade
Outros cenários, que não possuem suporte, são cenários como:
- Cenários de implantação que apresentam uma latência de rede maior entre a camada de aplicativo SAP e a camada do SAP DBMS, como NetWeaver, S/4HANA e
Hybris. Isso inclui:- Implantar uma das camadas no local enquanto a outra camada é implantada no Azure
- Implantando a camada de aplicativo do SAP de um sistema em uma região do Azure diferente da camada DBMS
- Implantar uma camada em datacenters que estão colocalizados no Azure e a outra camada do Azure, exceto quando esse padrão de arquitetura é fornecido por um serviço nativo do Azure
- Implantar dispositivos de rede virtual entre a camada de aplicativo do SAP e a camada do DBMS
- Usar o armazenamento hospedado em datacenters colocalizados no datacenter do Azure para a camada do SAP DBMS ou para o diretório de transporte global do SAP
- Implantar as duas camadas com dois fornecedores de nuvem diferentes. Por exemplo, implantar a camada do DBMS na infraestrutura de nuvem do Oracle e a camada de aplicativo no Azure
- Configurações de cluster do Pacemaker do HANA com Múltiplas Instâncias
- Configurações de cluster do Windows com discos compartilhados por meio de SOFS ou SMB em ANF para bancos de dados do SAP com suporte no Windows. Em vez disso, recomendamos o uso de replicação de alta disponibilidade nativa dos bancos de dados específicos usando pilhas de armazenamento separadas
- A implantação de bancos de dados SAP com suporte no Linux com arquivos de banco de dados localizados em compartilhamentos NFS com base no ANF, com exceção do SAP HANA, do Oracle no Oracle Linux e do Db2 no SUSE e no Red Hat
- Implantação do Oracle DBMS em qualquer outro SO convidado além do Windows e do Oracle Linux. Confira também a Nota de suporte do SAP nº 2039619
O(s) cenário(s) que não testamos e, portanto, não temos experiência com lista como:
- Azure Site Recovery replicando as VMs da camada de DBMS. Como resultado, recomendamos o uso da funcionalidade de replicação assíncrona nativa do banco de dados para uma possível configuração de recuperação de desastre
Próximas etapas
Veja as próximas etapas em Planejamento e implementação de Máquinas Virtuais do Azure para SAP NetWeaver