Disponibilidade do SAP HANA entre regiões do Azure
Este artigo descreve os cenários relacionados à disponibilidade do SAP HANA em diferentes regiões do Azure. Devido à distância entre regiões do Azure, a configuração da disponibilidade do SAP HANA em várias regiões do Azure envolve considerações especiais.
Por que implantar em várias regiões do Azure?
As regiões do Azure geralmente são separadas por grandes distâncias. Dependendo da região geopolítica, a distância entre as regiões do Azure pode ser de centenas de quilômetros ou mesmo milhares de quilômetros, como nos Estados Unidos. Devido à distância, o tráfego entre os recursos implantados em duas regiões do Azure diferentes passa por uma latência na viagem de ida e volta de rede significativa. A latência é significativa o suficiente para excluir troca de dados síncrona entre duas instâncias do SAP HANA sob cargas de trabalhos típicas do SAP.
Por outro lado, as organizações geralmente têm um requisito de distância entre o local do datacenter primário e um datacenter secundário. Um requisito de distância ajuda a fornecer disponibilidade se ocorrer um desastre natural em um local geográfico mais amplo. São exemplos os furacões que atingiram o Caribe e a Flórida em setembro e outubro de 2017. Sua organização pode ter pelo menos um requisito de distância mínima. Para a maioria dos clientes do Azure, essa definição de distância mínima requer a criação de disponibilidade em Regiões do Azure. Como a distância entre duas regiões do Azure é muito grande para usar o modo de replicação síncrona do HANA, os requisitos de RTO e RPO poderão forçá-lo a implantar configurações de disponibilidade dentro de uma região e, em seguida, complementar com implantações adicionais em uma segunda região.
Outro aspecto a considerar nesse cenário é o failover e o redirecionamento de cliente. A suposição é que um failover entre instâncias do SAP HANA em duas regiões do Azure diferentes é sempre um failover manual. Como o modo de replicação de sistema do SAP HANA é configurado como assíncrono, há um potencial de que os dados confirmados na instância do HANA primário ainda não tenham feito a instância do HANA secundário. Portanto, o failover automático não é uma opção para configurações onde a replicação for assíncrona. Mesmo com failover controlado manualmente, como em um exercício de failover, será necessário tomar medidas para certificar-se de que todos os dados confirmados no lado primário chegaram à instância secundária antes de movimentar manualmente para a outra região do Azure.
A Rede Virtual do Azure usa um intervalo de endereço IP diferente. Os endereços IP são implantados na segunda região do Azure. Por isso, você o precisa alterar a configuração de cliente do SAP HANA ou, preferencialmente, precisa criar as etapas para alterar a resolução de nome. Dessa forma, os clientes esão redirecionados para o endereço IP do servidor do novo site secundário. Para obter mais informações, consulte o artigo do SAP sobre a Recuperação da conexão do cliente após tomada de controle.
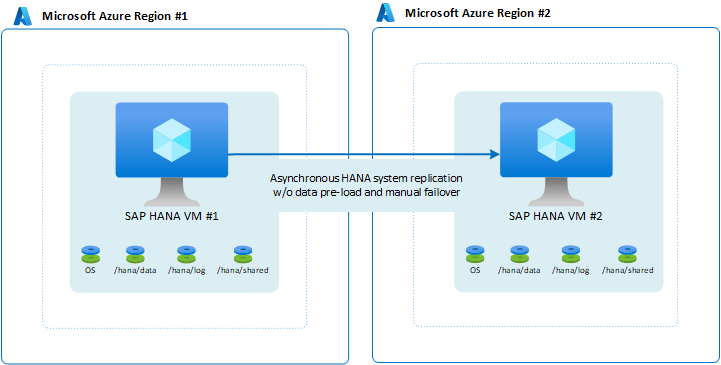
Disponibilidade simples entre duas regiões do Azure
Você pode optar por não implementar nenhuma configuração de disponibilidade dentro de uma única região, mas ainda ter a demanda para que a carga de trabalho seja atendida se ocorrer um desastre. Casos típicos para esses cenários são sistemas não de produção. Embora seja sustentável ter o sistema inoperante por meio dia ou mesmo por um dia, não é possível permitir que o sistema fique indisponível por 48 horas ou mais. Para tornar a instalação mais barata, execute outro sistema que seja ainda menos importante na VM. O outro sistema funciona como destino. Você pode dimensionar a VM na região secundária para que seja menor e optar por não pré-carregar os dados. Como o failover é manual e implica muitas outras etapas para failover na pilha de aplicativo completa, o tempo adicional para encerrar a VM, redimensioná-la e então iniciá-la novamente, é aceitável.
Se você estiver usando o cenário de compartilhamento do destino de DR com um sistema de QA em uma VM, será necessário levar essas considerações em conta:
- Há dois modos de operação com delta_datashipping e logreplay, que estão disponível para esse cenário
- Ambos os modos de operação têm requisitos de memória diferentes sem pré-carregamento de dados
- O Delta_datashipping pode exigir drasticamente menos memória sem a opção de pré-carga que o logreplay poderia exigir. Consulte o capítulo 4.3 do documento SAP Como executar a replicação de sistema para o SAP HANA
- O requisito de memória do modo de operação logreplay sem pré-carregamento não é determinístico e depende das estruturas columnstore carregadas. Em casos extremos, você pode exigir 50% da memória da instância primária. A memória para o modo de operação logreplay é independente se você optar por ter os conjunto de dados pré-carregados ou não.
Observação
Nessa configuração, não é possível fornecer um RPO=0, pois o modo de replicação de sistema do HANA é assíncrono. Se for necessário fornecer um RPO=0, essa configuração não será a configuração preferencial.
Uma pequena alteração que você pode fazer na configuração pode ser configurar os dados como pré-carregamento. No entanto, dada a natureza manual do failover e o fato de que as camadas de aplicativo também precisam se mover para a segunda região, não é adequado pré-carregar dados.
Combinar disponibilidade dentro de uma região e entre regiões
Uma combinação de disponibilidade dentro e entre regiões pode ser conduzida por estes fatores:
- Um requisito para RPO=0 dentro de uma região do Azure.
- A organização não quer ou não pode ter operações globais sendo afetadas por uma grande catástrofe natural que afeta uma região maior. Esse foi o caso de alguns furacões que atingiram o Caribe nos últimos anos.
- Regulamentos que exigem distâncias entre sites primários e secundários que estão claramente além do que as áreas de disponibilidade do Azure podem fornecer.
Nesses casos, você pode configurar o que a SAP chama de configuração de replicação de sistema multicamadas do SAP HANA usando a replicação do sistema HANA. A arquitetura seria semelhante a:

A SAP lançou a replicação de sistema de vários destinos com o SPS3 do HANA 2.0. A replicação do sistema de vários destinos traz algumas vantagens em cenários de atualização. Por exemplo, o site de recuperação de desastres (região 2) não é afetado quando o site de HA secundário está inativo para manutenção ou atualizações. Você pode encontrar mais informações sobre a replicação de sistema de vários destinos do HANA no Portal de ajuda do SAP. Uma possível arquitetura com a replicação de vários destinos se pareceria com:

Se a organização tiver requisitos de prontidão para alta disponibilidade na segunda região do Azure (recuperação de desastre), a arquitetura se parecerá com:

Usar logreplay como modo de operação, essa configuração fornece um RPO = 0, com baixo RTO, dentro da região primária. A configuração também fornece o RPO razoável se uma mudança para a segunda região estiver envolvida. Os tempos do RTO na segunda região dependem de se os dados são ou não pré-carregados. Muitos clientes usam a VM na região secundária para executar um sistema de teste. Nesse caso de uso, os dados não podem ser pré-carregados.
Importante
Os modos de operação entre as diferentes camadas precisam ser homogêneos. Não é possível usar o logreplay como modo de operação entre o nível 1 e o nível 2 e delta_datashipping para fornecer o nível 3. Você só pode escolher um ou outro modo de operação que precisa ser consistente para todas as camadas. Uma vez que delta_datashipping não é adequado para dar a você um RPO = 0, o modo de operação somente razoável para tal configuração de várias camadas permanece logreplay. Para obter detalhes sobre os modos de operação e algumas restrições, consulte o artigo Modos de operação para replicação de sistema do SAP HANA.
Próximas etapas
Para obter orientação passo a passo sobre como definir essas configurações no Azure, consulte: