Instalar e configurar o SAP HANA (Instâncias Grandes) do Azure
Neste artigo, vamos ver como validar, configurar e instalar o SAP HANA em Instâncias Grandes (HLI) no Azure (também conhecido como Infraestrutura BareMetal).
Pré-requisitos
Antes de ler este artigo, familiarize-se com:
Veja também:
- Conectar máquinas virtuais do Azure a Grandes Instâncias do HANA
- Conecte uma rede virtual em Instâncias Grandes do HANA
Planejar sua instalação
A instalação do SAP HANA é sua responsabilidade. Você pode começar a instalar um novo SAP HANA no servidor do Azure (Instâncias Grandes) depois de estabelecer a conectividade entre suas redes virtuais do Azure e as unidades de HANA em Instâncias Grandes.
Observação
De acordo com a política da SAP, a instalação do SAP HANA deve ser executada por alguém que tenha sido aprovado no exame Certified SAP Technology Associate, no exame de certificação de Instalação do SAP HANA ou que seja um integrador de sistema (SI) certificado pela SAP.
Ao planejar a instalação do HANA 2.0, consulte a Nota de suporte SAP nº 2235581 – SAP HANA: sistemas operacionais com suporte. Certifique-se de que o sistema operacional (SO) tenha suporte à versão do SAP HANA que você está instalando. O sistema operacional com suporte para o HANA 2.0 é mais restrito do que o sistema operacional com suporte para o HANA 1.0. Confirme se a versão do sistema operacional em que você está interessado tem suporte para essa Instância Grande do HANA específica. Use esta lista; selecione o HLI para ver os detalhes da lista de sistemas operacionais com suporte para essa unidade.
Antes de começar a instalação do HANA, você deve validar o seguinte:
- Unidades de HLI
- Configuração do sistema operacional
- Configuração de rede
- Configuração de armazenamento
Validar a(s) unidade(s) do HANA em Instância Grande
Depois de receber as Instâncias Grandes do HANA da Microsoft, estabeleça acesso e conectividade a elas. Em seguida, valide as configurações a seguir e ajuste conforme necessário.
Verifique no portal do Azure se as instâncias estão aparecendo com os SKUs e o sistema operacional corretos. Para mais informações, consulte Controle do HANA em Instâncias Grandes do Azure por meio do portal do Azure.
Registre o sistema operacional da instância com o provedor do seu sistema operacional. Essa etapa inclui o registro do sistema operacional SUSE Linux em uma instância da Ferramenta de Gerenciamento de Assinatura (SMT) do SUSE implantada em uma VM do Azure.
A Instância Grande do HANA pode se conectar a essa instância SMT. (Para obter mais informações, consulte Como configurar o servidor SMT para o SUSE Linux). Se estiver usando o sistema operacional Red Hat, ele precisa ser registrado com o Gerenciador de Assinaturas do Red Hat ao qual você precisa se conectar. Para obter mais informações, consulte os comentários em O que é o SAP HANA no Azure (Instâncias Grandes)?.
Essa etapa é necessária para a aplicação de patch do sistema operacional, que é responsabilidade do cliente. No caso do SUSE, consulte a documentação sobre como instalar e configurar o SMT.
Verifique se há novos patches e correções da versão específica do sistema operacional. Verifique se a Instância Grande do HANA tem os patches mais recentes. Algumas vezes, os patches mais recentes não estão incluídos. Por conta disso, não deixe de conferir.
Verifique as Notas SAP relevantes para a instalação e configuração do SAP HANA na versão específica do sistema operacional. A Microsoft nem sempre configura um HLI de maneira completa. Mudanças nas recomendações em notas e configurações do SAP dependentes de cenários individuais pode tornar essa atividade impossível.
Portanto, leia as notas do SAP relacionadas ao SAP HANA para a sua versão exata do Linux. Também verifique e aplique as configurações necessárias da versão do sistema operacional caso ainda não o tenha feito.
Verifique especificamente os seguintes parâmetros e ajuste-os para:
- net.core.rmem_max = 16777216
- net.core.wmem_max = 16777216
- net.core.rmem_default = 16777216
- net.core.wmem_default = 16777216
- net.core.optmem_max = 16777216
- net.ipv4.tcp_rmem = 65536 16777216 16777216
- net.ipv4.tcp_wmem = 65536 16777216 16777216
A partir do SLES12 SP1 e do Red Hat Enterprise Linux (RHEL) 7.2, esses parâmetros devem ser definidos em um arquivo de configuração no diretório /etc/sysctl.d. Por exemplo, deve-se criar um arquivo de configuração com o nome 91-NetApp-HANA.conf. Para versões mais antigas do SLES e RHEL, esses parâmetros devem ser definidos como in/etc/sysctl.conf.
Para todas as versões do RHEL começando com o RHEL 6.3, tenha em mente:
- O parâmetro sunrpc.tcp_slot_table_entries = 128 deve ser definido como in/etc/modprobe.d/sunrpc-local.conf. Se o arquivo não existir, crie-o primeiro adicionando a entrada:
- options sunrpc tcp_max_slot_table_entries=128
Verifique a hora do sistema da Instância Grande do HANA. As instâncias são implantadas com um fuso horário do sistema. Esse fuso horário representa o local da região do Azure em que o carimbo de Instância Grande do HANA está localizado. Você pode alterar a hora do sistema ou o fuso horário das instâncias que possui.
Se você solicitar mais instâncias para seu locatário, precisará adaptar o fuso horário das instâncias recém-entregues. A Microsoft não tem nenhum insight sobre o fuso horário do sistema configurado com as instâncias após a entrega. Portanto, as instâncias recém-implantadas podem não estar definidas para o mesmo fuso horário daquelas que você alterou. Você pode adaptar o fuso horário das instâncias que foram entregues conforme julgar necessário.
Verifique etc/hosts. Conforme as folhas são entregues, elas têm diferentes endereços IP atribuídos para finalidades diferentes. É importante verificar o arquivo etc/hosts quando as unidades são adicionadas a um locatário existente. O arquivo etc/hosts dos sistemas recém-implantados pode não ser mantido corretamente com os endereços IP dos sistemas entregues anteriormente. Confirme se uma instância implantada recentemente é capaz de resolver os nomes das unidades que você implantou anteriormente em seu locatário.
Sistema operacional
O espaço de troca da imagem do sistema operacional fornecida é definido como 2 GB, de acordo com a Nota de suporte SAP n° 1999997 – Perguntas frequentes: memória do SAP HANA. Caso deseje uma configuração diferente, você deverá defini-la por conta própria.
SUSE Linux Enterprise Server 12 SP1 para aplicativos SAP é a distribuição do Linux instalada para SAP HANA no Azure (Instâncias Grandes). Essa distribuição fornece recursos específicos do SAP, incluindo parâmetros predefinidos para executar o SAP no SLES de modo eficaz.
Para obter vários recursos úteis relacionados à implantação SAP HANA no SLES, consulte:
- Biblioteca de recursos/white papers no site do SUSE.
- SAP no SUSE na SAP Community Network (SCN).
Esses recursos incluem informações sobre como configurar a alta disponibilidade e a proteção de segurança específica para operações SAP, e muito mais.
Aqui estão mais recursos para o SAP no SUSE:
- SAP HANA no Site do SUSE Linux
- Práticas recomendadas para o SAP: replicação de enfileiramento – SAP NetWeaver no SUSE Linux Enterprise 12
- ClamSAP – proteção antivírus de SLES para SAP (incluindo SLES 12 para aplicativos SAP)
Os documentos a seguir são notas de suporte da SAP aplicáveis à implementação do SAP HANA no SLES 12:
- Nota de suporte SAP n° 1944799 – diretrizes do SAP HANA para instalação do sistema operacional SLES
- Nota de suporte SAP n° 2205917 – configurações de SO recomendadas para o banco de dados do SAP HANA para SLES 12 para aplicativos SAP
- Nota de suporte SAP n° 1984787 – SUSE Linux Enterprise Server 12: notas de instalação
- Nota de suporte SAP n° 171356 – software SAP no Linux: informações gerais
- Nota de suporte SAP n° 1391070 – Soluções UUID do Linux
Red Hat Enterprise Linux para SAP HANA é outra oferta para execução do SAP HANA em instâncias grandes de HANA. As versões do RHEL 7.2 e 7.3 estão disponíveis e são compatíveis. Para obter mais informações sobre o SAP no Red Hat, consulte SAP HANA no site do Red Hat Linux.
Os documentos a seguir são notas de suporte da SAP aplicáveis à implementação do SAP HANA no Red Hat:
- Nota de suporte SAP n° 2009879 – Diretrizes SAP HANA para o sistema operacional RHEL (Red Hat Enterprise Linux)
- Nota de suporte SAP n° 2292690 – Banco de dados SAP HANA: configurações de sistema operacional recomendadas para RHEL 7
- Nota de suporte SAP n° 1391070 – Soluções UUID do Linux
- Nota de suporte SAP n° 2228351 – Linux: banco de dados SAP HANA SPS 11 revisão 110 (ou superior) em RHEL 6 ou SLES 11
- Nota de suporte SAP n° 2397039 – Perguntas frequentes: SAP em RHEL
- Nota de suporte SAP n° 2002167 – Red Hat Enterprise Linux 7.x: instalação e atualização
Sincronização da hora
Os aplicativos SAP criados na arquitetura do SAP NetWeaver são sensíveis às diferenças de hora nos vários componentes do sistema SAP. Provavelmente, os despejos de memória curtos do SAP ABAP com o título de erro ZDATE_LARGE_TIME_DIFF são familiares. Isso ocorre porque esses despejos curtos aparecem quando a hora do sistema de diferentes servidores ou máquinas virtuais (VMs) apresenta uma divergência muito grande.
No caso do SAP HANA no Azure (instâncias grandes), a sincronização de tempo feita no Azure não se aplica às unidades de computação dos carimbos de data/hora das Instâncias Grandes. Ela também não se aplica à execução de aplicativos SAP em VMs nativas do Azure, pois o Azure garante a correta sincronização da hora do sistema.
Como resultado, você precisa configurar um servidor de horário separado. Esse servidor será usado por servidores de aplicativos SAP em execução em VMs do Azure. Ele também será usado pelas instâncias de banco de dados do SAP HANA em execução nas Instâncias Grandes do HANA. A infraestrutura de armazenamento nos carimbos de Instância Grande tem seu horário sincronizado com os servidores de protocolo de tempo de rede (NTP).
Rede
Ao projetar suas redes virtuais do Azure e conectar essas redes virtuais às instâncias grandes do HANA, siga as recomendações descritas em:
- Visão geral e arquitetura do SAP HANA (Instâncias Grandes) no Azure
- Infraestrutura e conectividade do SAP HANA (Instâncias Grandes) do Azure
Há alguns detalhes que vale a pena mencionar sobre a rede de unidades individuais. Cada unidade de Instância Grande do HANA é fornecida com dois ou três endereços IP atribuídos a duas ou três portas do controlador de interface de rede (NIC). Três endereços IP são usados em configurações de expansão do HANA e no cenário de replicação de sistema do HANA. Um dos endereços IP atribuídos ao NIC da unidade está fora do pool de IPs do Servidor descrito na Visão geral e arquitetura do SAP HANA (Instâncias Grandes) no Azure.
Para obter mais informações sobre detalhes de Ethernet para a sua arquitetura, consulte cenários com suporte para HLI (Instâncias Grandes do HANA).
Armazenamento
O layout de armazenamento do SAP HANA (Instâncias Grandes) é configurado pelo SAP HANA no Gerenciamento de Serviços do Azure usando as diretrizes recomendadas do SAP.
Os tamanhos aproximados dos volumes diferentes com os diferentes SKUs do HANA em Instâncias Grandes estão documentados na Visão geral e arquitetura do SAP HANA (Instâncias Grandes) no Azure.
As convenções de nomenclatura dos volumes de armazenamento são listadas na seguinte tabela:
| Uso de armazenamento | Nome da montagem | Nome do volume |
|---|---|---|
| Dados do HANA | /hana/data/SID/mnt0000<m> | IP de Armazenamento: /hana_data_SID_mnt00001_tenant_vol |
| Log do HANA | /hana/log/SID/mnt0000<m> | IP de Armazenamento: /hana_log_SID_mnt00001_tenant_vol |
| Backup de log do HANA | /hana/log/backups | IP de Armazenamento: /hana_log_backups_SID_mnt00001_tenant_vol |
| HANA compartilhado | /hana/shared/SID | IP de Armazenamento: /hana_shared_SID_mnt00001_tenant_vol/shared |
| usr/sap | /usr/sap/SID | IP de Armazenamento: /hana_shared_SID_mnt00001_tenant_vol/usr_sap |
SID é a ID do Sistema da instância do HANA.
Locatário é uma enumeração interna das operações durante a implantação de um locatário.
Usr/sap do HANA compartilham o mesmo volume. A nomenclatura dos pontos de montagem inclui a ID do sistema das instâncias do HANA, bem como o número de montagem. Em implantações de expansão, há somente uma montagem, como mnt00001. No caso de implantações escaláveis, haverá tantas montagens quantos forem os nós primários e de trabalho.
Para os ambientes escaláveis, os dados, o log e os volumes de backup de log são compartilhados e anexados a cada nó na configuração de expansão. Para configurações que sejam de várias instâncias do SAP, um conjunto diferente de volumes é criado e anexado à unidade de Instância Grande do HANA. Para obter detalhes do layout de armazenamento do seu cenário, consulte os cenários com suporte para HLI.
As Instâncias Grandes do HANA vêm com um generoso volume de disco para HANA/data e um volume para HANA/log/backup. Tornamos o HANA/data tão grande porque os instantâneos de armazenamento usam o mesmo volume de disco. Quanto mais instantâneos de armazenamento são tirados, mais espaço é consumido pelos instantâneos nos volumes de armazenamento atribuídos.
O volume de HANA/log/backup não deve ser o volume dos backups de banco de dados. Ele é dimensionado para ser usado como volume de backup para os backups de log de transações do HANA. Para obter mais informações, consulte Alta disponibilidade e recuperação de desastre do SAP HANA (Instâncias Grandes) do Azure.
Você pode aumentar seu armazenamento adquirindo capacidade extra em incrementos de 1 TB. Esse armazenamento adicional pode ser incluído como novos volumes para o HANA em Instâncias Grandes.
Durante a integração com o SAP HANA no Gerenciamento de Serviços do Azure, o cliente especifica uma UID (ID de usuário) e uma GID (ID do grupo) para o usuário sidadm e o grupo sapsys (por exemplo: 1000,500). Durante a instalação do sistema SAP HANA, você deverá usar esses mesmos valores. Como você deseja implantar várias instâncias do HANA em uma unidade, você obterá vários conjuntos de volumes (um conjunto para cada instância). Como resultado, no momento da implantação, é necessário definir:
- O SID das diferentes instâncias do HANA (o sidadm é derivado dele).
- Os tamanhos de memória das diferentes instâncias do HANA. O tamanho de memória por instância define o tamanho dos volumes em cada conjunto de volumes individual.
De acordo com as recomendações do provedor de armazenamento, as seguintes opções de montagem são configuradas para todos os volumes montados (exclui o LUN de inicialização):
- nfs rw, vers=4, hard, timeo=600, rsize=1048576, wsize=1048576, intr, noatime, lock 0 0
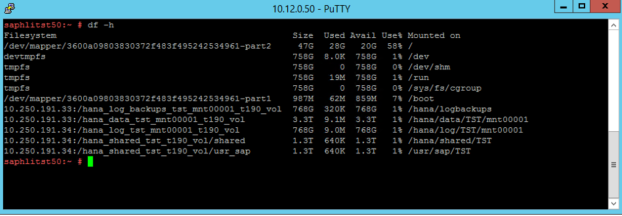
Esses pontos de montagem são configurados em /etc/fstab, conforme mostrado nas capturas de tela a seguir:

O resultado do comando df -h em uma unidade de Instância Grande do HANA de S72m se parece com o seguinte:
O controlador de armazenamento e os nós nos carimbos de Instância Grande são sincronizados com os servidores NTP. É importante sincronizar o SAP HANA no Azure (Instâncias Grandes) e nas VMs do Azure em um servidor NTP. Isso elimina um descompasso de tempo significativo entre a infraestrutura e as unidades de computação no Azure ou em carimbos de Instância Grande.
Para otimizar o SAP HANA para o armazenamento usado de forma subjacente, defina os seguintes parâmetros de configuração do SAP HANA:
- max_parallel_io_requests 128
- async_read_submit on
- async_write_submit_active on
- async_write_submit_blocks all
Para as versões 1.0 do SAP HANA até SPS12, esses parâmetros podem ser definidos durante a instalação do banco de dados SAP HANA, conforme descrito em Nota SAP nº 2267798 – configuração do banco de dados SAP HANA.
Você também pode configurar os parâmetros após a instalação do banco de dados SAP HANA usando a estrutura hdbparam.
O armazenamento usado no HANA em Instâncias Grandes tem uma limitação de tamanho de arquivo. A limitação de tamanho é de 16 TB por arquivo. Ao contrário das limitações de tamanho de arquivo nos sistemas de arquivos EXT3, o HANA não reconhece implicitamente a limitação de armazenamento imposta pelo armazenamento do SAP HANA em Instâncias Grandes. Como resultado, o HANA não criará automaticamente um novo arquivo de dados quando o limite de tamanho de arquivo de 16 TB for atingido. Como o HANA tenta aumentar o arquivo para além de 16 TB, o HANA relatará erros e o servidor de índice falhará no final.
Importante
Para evitar que o HANA tente aumentar os arquivos de dados além do limite de tamanho de arquivo de 16 TB do armazenamento de Instância Grande do HANA, você precisa definir os seguintes parâmetros no arquivo de configuração global.ini do SAP HANA:
Com o SAP HANA 2.0, a estrutura hdbparam foi preterida. Como resultado, os parâmetros devem ser definidos usando comandos SQL. Para obter mais informações, consulte Nota SAP nº 2399079: eliminação de hdbparam no HANA 2.
Consulte os cenários com suporte para HLI para saber mais sobre o layout de armazenamento para sua arquitetura.
Próximas etapas
Siga as etapas de instalação do SAP HANA no Azure (Instâncias Grandes).