Monitoramento de modelo para aplicativos de IA generativos (versão prévia)
O monitoramento de modelos em produção é uma parte essencial do ciclo de vida da IA. As alterações nos dados e no comportamento do consumidor podem influenciar seu aplicativo de IA gerador ao longo do tempo, resultando em sistemas desatualizados que afetam negativamente os resultados dos negócios e expõem as organizações a riscos de conformidade, econômicos e de reputação.
Importante
O monitoramento de modelo para aplicativos de IA generativos está atualmente em versão prévia pública. Essas visualizações são fornecidas sem um contrato de nível de serviço e não são recomendadas para cargas de trabalho de produção. Alguns recursos podem não ter suporte ou podem ter restrição de recursos. Para obter mais informações, consulte Termos de Uso Complementares de Versões Prévias do Microsoft Azure.
O monitoramento de modelo do Azure Machine Learning para aplicativos de IA generativos facilita o monitoramento de seus aplicativos LLM em produção para segurança e qualidade em uma cadência para garantir que ele esteja fornecendo o máximo impacto nos negócios. O monitoramento, em última análise, ajuda a manter a qualidade e a segurança de seus aplicativos de IA generativos. As funcionalidades e integrações incluem:
- Coletar dados de produção usando o coletor de dados de modelo.
- Métricas de avaliação de IA responsável, como aterramento, coerência, fluência, relevância e similaridade, que são interoperáveis com métricas de avaliação de fluxo de prompt do Azure Machine Learning.
- Capacidade de configurar alertas para violações com base em destinos organizacionais e executar o monitoramento de forma recorrente
- Consumir resultados em uma dashboard avançada dentro de um workspace no Estúdio do Azure Machine Learning.
- Integração com as métricas de avaliação de fluxo de prompt do Azure Machine Learning, análise de dados de produção coletados para fornecer alertas oportunos e visualização das métricas ao longo do tempo.
Para ver os conceitos básicos de monitoramento de modelo geral, consulte Monitoramento de modelos com o Azure Machine Learning (versão prévia). Neste artigo, você aprenderá a monitorar um aplicativo de IA gerador apoiado por um ponto de extremidade online gerenciado. As etapas são:
- Configurar os pré-requisitos
- Criar seu monitor
- Confirmar status de monitoramento
- Consumir resultados de monitoramento
Métricas da avaliação
As métricas são geradas pelos seguintes modelos de linguagem GPT de última geração configurados com instruções de avaliação específicas (modelos de prompt) que atuam como modelos de avaliador para tarefas de sequência para sequência. Essa técnica tem mostrado resultados empíricos fortes e alta correlação com o julgamento humano em comparação com as métricas de avaliação de IA generativas padrão. Forme mais informações sobre a avaliação de fluxo de prompt, consulte Enviar teste em massa e avaliar um fluxo (versão prévia) para obter mais informações sobre a avaliação do fluxo de prompt.
Esses modelos GPT têm suporte e serão configurados como seu recurso OpenAI do Azure:
- GPT-3.5-Turbo
- GPT-4
- GPT-4-32k
Há suporte para as métricas a seguir. Para obter informações mais detalhadas sobre cada métrica, consulte Monitoramento de descrições de métricas de avaliação e casos de uso
- Aterramento: avalia o quão bem as respostas geradas do modelo se alinham com as informações da fonte de entrada.
- Relevância: avalia até que ponto as respostas geradas pelo modelo são pertinentes e diretamente relacionadas às perguntas fornecidas.
- Coerência: avalia o quão bem o modelo de linguagem pode produzir fluxos de saída sem problemas, lê naturalmente e se assemelha à linguagem humana.
- Fluência: avalia a proficiência da linguagem da resposta prevista de uma IA generativa. Ela avalia a adequação do texto gerado às regras gramaticais, às estruturas sintáticas e ao uso adequado do vocabulário, resultando em respostas linguisticamente corretas e naturais.
- Similaridade: avalia a similaridade entre uma frase de verdade (ou documento) e a frase de previsão gerada por um modelo de IA.
Requisitos de configuração de métrica
As seguintes entradas (nomes de coluna de dados) são necessárias para medir a qualidade e a segurança da geração:
- texto do prompt – o prompt original especificado (também conhecido como "entradas" ou "pergunta")
- texto de conclusão – a conclusão final da chamada à API retornada (também conhecida como "saídas" ou "resposta")
- texto de contexto – todos os dados de contexto enviados para a chamada à API, juntamente com o prompt original. Por exemplo, se você espera obter resultados de pesquisa somente de determinadas fontes de informações certificadas/site, você pode definir nas etapas de avaliação. Essa é uma etapa opcional que pode ser configurada por meio do prompt flow.
- texto da verdade básica – o texto definido pelo usuário como a "fonte da verdade" (opcional)
Quais parâmetros são configurados em seu ativo de dados determina quais métricas você pode produzir, de acordo com esta tabela:
| Metric | Prompt | Completion | Context | Verdade básica |
|---|---|---|---|---|
| Coerência | Obrigatório | Obrigatório | - | - |
| Fluência | Obrigatório | Obrigatório | - | - |
| Fundamentação | Obrigatório | Obrigatória | Obrigatório | - |
| Relevância | Obrigatório | Obrigatória | Obrigatório | - |
| Similaridade | Obrigatório | Obrigatória | - | Obrigatório |
Pré-requisitos
- Recurso OpenAI do Azure: Você deve ter um recurso OpenAI do Azure criado com cota suficiente. Esse recurso é usado como ponto de extremidade de avaliação.
- Identidade gerenciada: Crie uma UAI (Identidade Gerenciada Atribuída pelo Usuário) e anexe-a ao workspace usando as diretrizes em Anexar identidade gerenciada atribuída pelo usuário usando a CLI v2com acesso de função suficiente, conforme definido na próxima etapa.
- Acesso à função Para atribuir uma função com as permissões necessárias, você precisa ter o proprietário ou a permissão Microsoft.Authorization/roleAssignments/write em seu recurso. A atualização de conexões e permissões pode levar vários minutos para entrar em vigor. Essas funções adicionais devem ser atribuídas ao seu UAI:
- Recurso: Workspace
- Função:Cientista de Dados do Azure Machine Learning
- Conexão de workspace: seguindo essas diretrizes, você usa uma identidade gerenciada que representa as credenciais para o ponto de extremidade do OpenAI do Azure usado para calcular as métricas de monitoramento. NÃO exclua a conexão depois de usada no fluxo.
- Versão da API: 2023-03-15-preview
- Implantação de fluxo de prompt: Crie um runtime de fluxo de prompt seguindo estas diretrizes, execute seu fluxo e verifique se sua implantação está configurada usando este artigo como um guia
- Entradas e saídas de fluxo: você precisa nomear as saídas de fluxo adequadamente e lembrar esses nomes de coluna ao criar o monitor. Neste artigo, usamos o seguinte:
- Entradas (obrigatório): "prompt"
- Saídas (obrigatório): "conclusão"
- Saídas (opcional): "contexto" | "verdade básica"
- Coleta de dados: na "Implantação" (Etapa 2 do assistente de implantação do prompt flow), a alternância 'coleta de dados de inferência' deve ser habilitada usando o Coletor de Dados do Modelo
- Saídas: nas Saídas (Etapa 3 do assistente de implantação do prompt flow), confirme se você selecionou as saídas necessárias listadas acima (por exemplo, conclusão | contexto | ground_truth) que atendam aos seus requisitos de configuração de métrica
- Entradas e saídas de fluxo: você precisa nomear as saídas de fluxo adequadamente e lembrar esses nomes de coluna ao criar o monitor. Neste artigo, usamos o seguinte:
Observação
Se a instância de computação estiver atrás de uma VNet, consulte o tópico sobre Isolamento de rede no fluxo de prompts.
Criar seu monitor
Crie seu monitor na página Visão geral do monitoramento 
Configurar definições básicas de monitoramento
No assistente de criação de monitoramento, altere o tipo de tarefa do modelo para solicitação e conclusão, conforme mostrado por (A) na captura de tela.

Configurar ativo de dados
Se você tiver usado o Coletor de Dados do Modelo, selecione seus dois ativos de dados (saídas e de entradas).

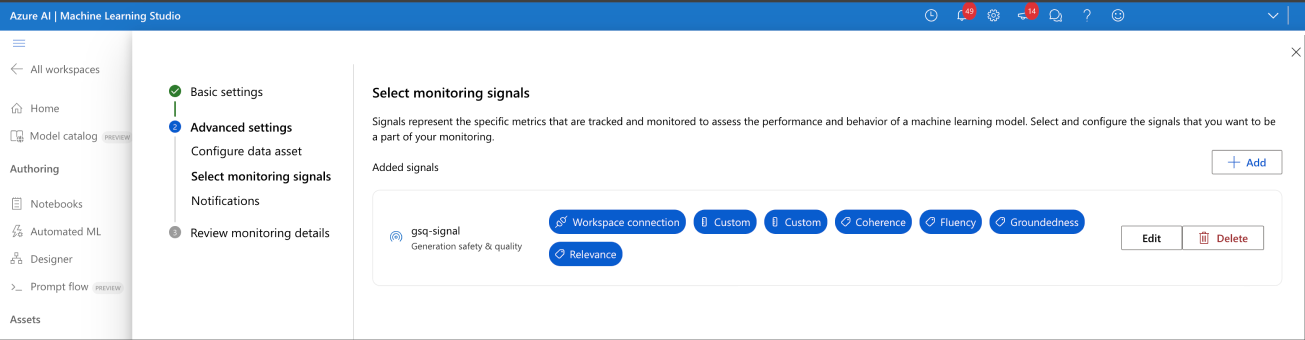
Selecionar sinais de monitoramento

- Configure a conexão de workspace (A) na captura de tela.
- Você precisa configurar a conexão do workspace corretamente ou verá isso:

- Você precisa configurar a conexão do workspace corretamente ou verá isso:
- Insira o nome de implantação do avaliador do Azure OpenAI (B).
- (Opcional) Junte suas saídas e entradas de dados de produção: suas entradas e saídas do modelo de produção são unidas automaticamente pelo serviço de Monitoramento (C). Você pode personalizar isso se necessário, mas nenhuma ação é necessária. Por padrão, a coluna de junção é correlationid.
- (Opcional) Configurar limites de métrica: uma pontuação aceitável por instância é fixada em 3/5. Você pode ajustar sua taxa de passagem de % geral aceitável entre o intervalo [1,99] %

Insira manualmente os nomes de coluna do fluxo de prompt (E). Os nomes padrão são ("prompt" | "completion" | "context" | "ground_truth"), mas você pode configurá-lo de acordo com seu ativo de dados.
(opcional) Definir taxa de amostragem (F)
Depois de configurado, o sinal não mostrará mais um aviso.

Configurar notificações
Nenhuma ação é necessária. Você pode configurar mais destinatários, se necessário.

Confirmar a configuração do sinal de monitoramento
Quando configurado com sucesso, seu monitor deverá ter a seguinte aparência: 
Confirmar status de monitoramento
Se a configuração for bem-sucedida, o trabalho do pipeline de monitoramento mostrará o seguinte: 
Consumir resultados
Página de visão geral do monitor
Sua visão geral do monitor fornece uma visão geral do desempenho do sinal. Você pode inserir a página de detalhes do sinal para obter mais informações.

Página de detalhes do sinal
A página de detalhes do sinal permite exibir métricas ao longo do tempo (A) e exibir histogramas de distribuição (B).

Resolver alertas
Só é possível ajustar os limites de sinal. A pontuação aceitável é fixa em 3/5 e só é possível ajustar o campo "taxa de aprovação de % geral aceitável".
