Enviar uma execução em lote para avaliar um fluxo
Uma execução em lote executa um prompt flow com um grande conjunto de dados e gera saídas para cada linha de dados. Para avaliar o desempenho do seu prompt flow com um grande conjunto de dados, você pode enviar uma execução em lote e usar métodos de avaliação para gerar pontuações e métricas de desempenho.
Após a conclusão do fluxo em lote, os métodos de avaliação são executados automaticamente para calcular as pontuações e métricas. Você pode usar as métricas de avaliação para avaliar a saída do seu fluxo em relação aos seus critérios de desempenho e metas.
Esse artigo descreve como enviar uma execução em lote e usar um método de avaliação para medir a qualidade da saída do seu fluxo. Você aprenderá a visualizar o resultado e as métricas da avaliação e como iniciar uma nova rodada de avaliação com um método diferente ou um subconjunto de variantes.
Pré-requisitos
Para executar um fluxo em lote com um método de avaliação, você precisa dos seguintes componentes:
Um prompt flow funcional do Azure Machine Learning cujo desempenho você deseja testar.
Um conjunto de dados de teste a ser usado na execução em lote.
Seu conjunto de dados de teste deve estar no formato CSV, TSV ou JSONL e deve ter cabeçalhos que correspondam aos nomes de entrada do seu fluxo. No entanto, você pode mapear diferentes colunas de conjuntos de dados para colunas de entrada durante o processo de configuração da execução de avaliação.
Crie e envie uma execução de lote de avaliação
Para enviar uma execução em lote, selecione o conjunto de dados para testar seu fluxo. Você também pode selecionar um método de avaliação para calcular as métricas para a saída do fluxo. Se não quiser usar um método de avaliação, você pode pular as etapas de avaliação e executar a execução em lote sem calcular nenhuma métrica. Você também pode executar uma rodada de avaliação mais tarde.
Para iniciar uma execução em lote com ou sem avaliação, selecione Avaliar na parte superior da página de prompt flow.
Na página Configurações básicas do assistente Execução em lote e avaliação, personalize o Nome de exibição da execução se desejar e, opcionalmente, forneça uma Descrição da execução e Marcas. Selecione Avançar.
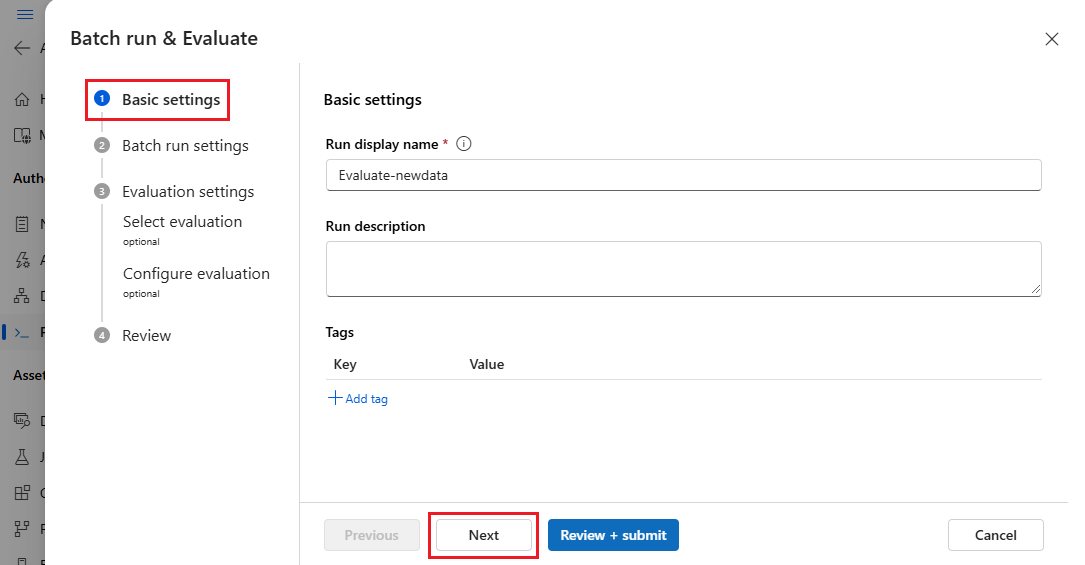
Na página Configurações de execução em lote, selecione o conjunto de dados a ser usado e configure o mapeamento de entrada.
O prompt flow oferece suporte ao mapeamento da entrada do fluxo para uma coluna de dados específica no seu conjunto de dados. Você pode atribuir uma coluna de conjunto de dados a uma determinada entrada usando
${data.<column>}. Se você quiser atribuir um valor constante a uma entrada, poderá inserir esse valor diretamente.
Você pode selecionar Revisar + enviar nesse ponto para pular as etapas de avaliação e executar o lote sem usar nenhum método de avaliação. A execução em lote gera saídas individuais para cada item no seu conjunto de dados. Você pode verificar as saídas manualmente ou exportá-las para análise posterior.
Caso contrário, para usar um método de avaliação para validar o desempenho dessa execução, selecione Próximo. Você também pode adicionar uma nova rodada de avaliação a uma execução em lote concluída.
Na página Selecionar avaliação, selecione uma ou mais avaliações personalizadas ou integradas para executar. Você pode selecionar o botão Exibir detalhes para ver mais informações sobre o método de avaliação, como as métricas geradas e as conexões e entradas necessárias.
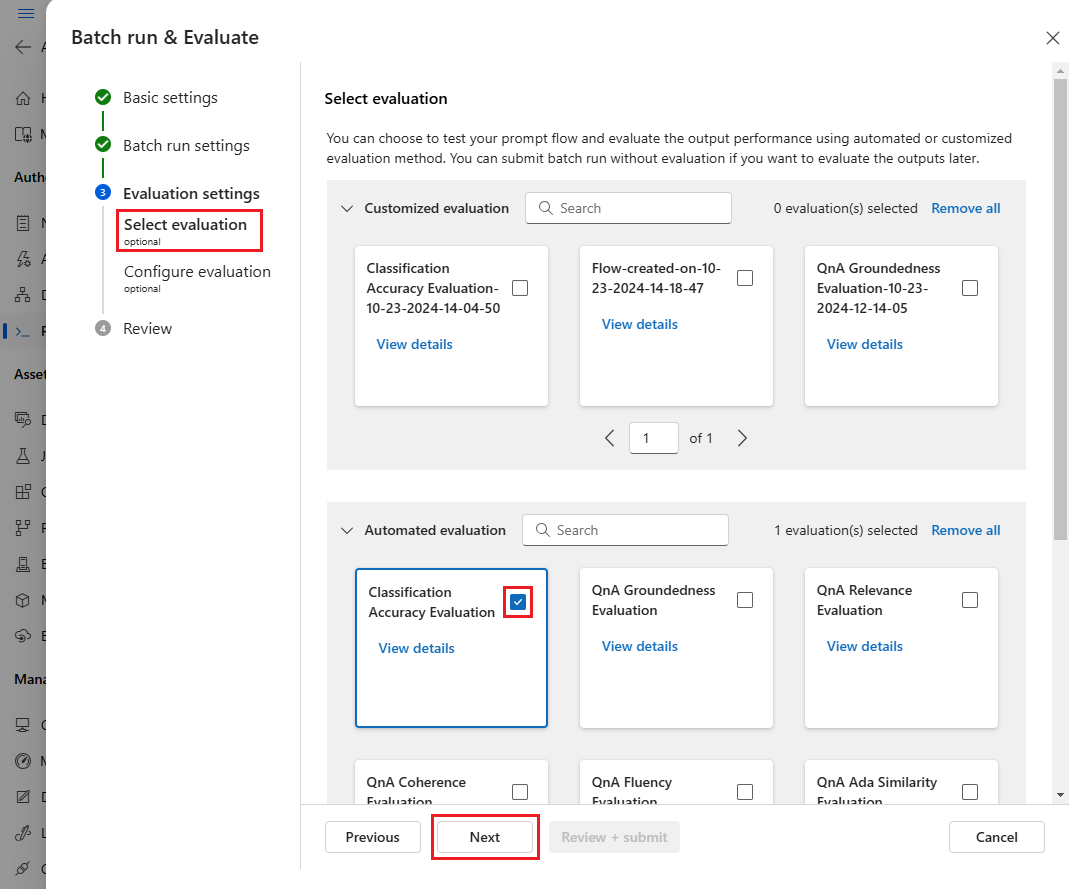
Em seguida, na tela Configurar avaliação, especifique as fontes de entradas necessárias para a avaliação. Por exemplo, a coluna de informações básicas pode vir de um conjunto de dados. Por padrão, a avaliação usa o mesmo conjunto de dados da execução geral do lote. No entanto, se os rótulos correspondentes ou os valores de verdade do alvo estiverem em um conjunto de dados diferente, você poderá usá-los.
Observação
Se o seu método de avaliação não exigir dados de um conjunto de dados, a seleção do conjunto de dados será uma configuração opcional que não afetará os resultados da avaliação. Você não precisa selecionar um conjunto de dados ou referenciar nenhuma coluna do conjunto de dados na seção de mapeamento de entrada.
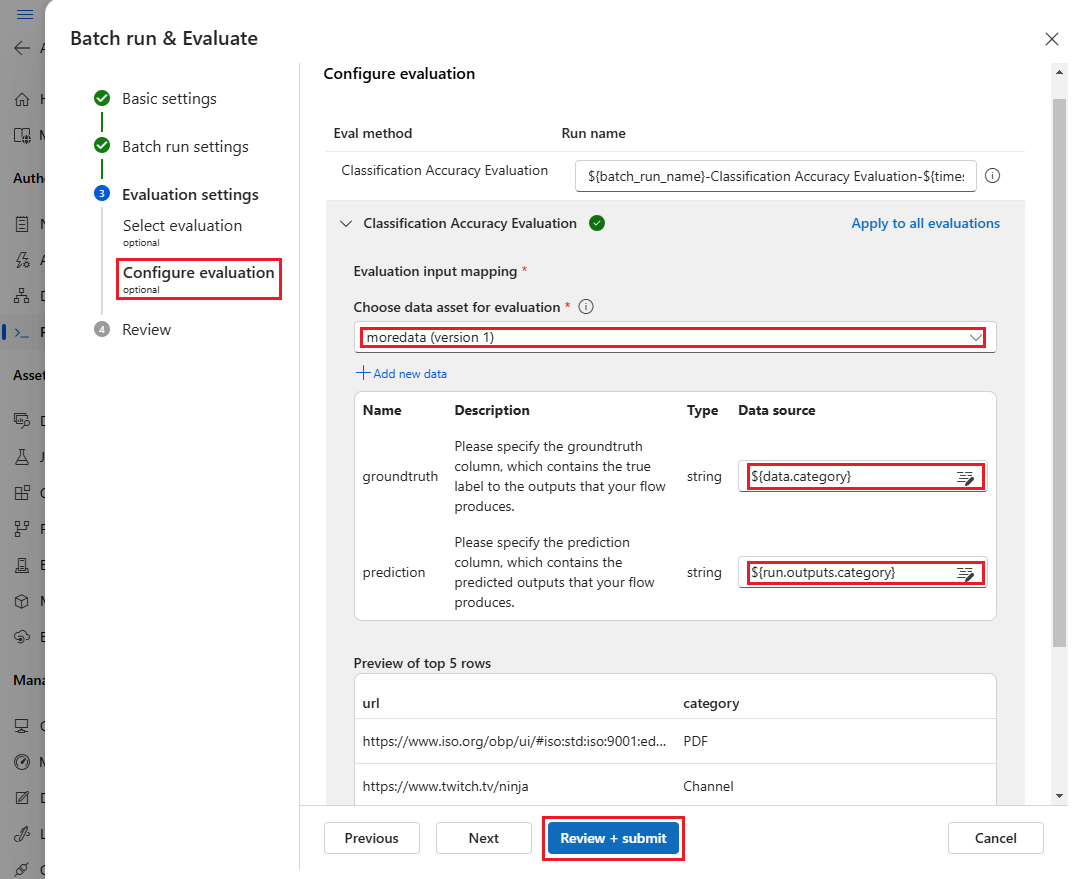
Na seção Mapeamento de entrada de avaliação, indique as fontes de entradas necessárias para a avaliação.
- Se os dados forem do seu conjunto de dados de teste, defina a fonte como
${data.[ColumnName]}. - Se os dados forem da sua saída de execução, defina a fonte como
${run.outputs.[OutputName]}.
- Se os dados forem do seu conjunto de dados de teste, defina a fonte como
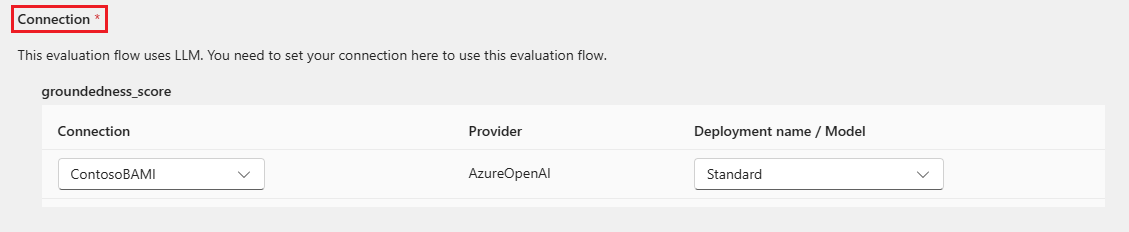
Alguns métodos de avaliação exigem Large Language Models (LLMs), como GPT-4 ou GPT-3, ou precisam de outras conexões para consumir credenciais ou chaves. Para esses métodos, você deve inserir os dados de conexão na seção Conexão na parte inferior dessa tela para poder usar o fluxo de avaliação. Para obter mais informações, veja Configurar uma conexão.
Selecione Revisar + enviar para revisar suas configurações e, em seguida, selecione Enviar para iniciar a execução em lote com avaliação.






Observação
- Alguns processos de avaliação usam muitos tokens, então é recomendável usar um modelo que suporte >=16k tokens.
- As execuções em lote têm uma duração máxima de 10 horas. Se uma execução em lote exceder esse limite, ela será encerrada e exibida como falha. Monitore sua capacidade de LLM para evitar estrangulamento. Se necessário, considere reduzir o tamanho dos dados. Se você ainda tiver problemas, preencha um formulário de comentários ou uma solicitação de suporte.
Exibir resultados e métricas da avaliação
Você pode encontrar a lista de execuções em lote enviadas na guia Execuções na página Prompt flow do Estúdio do Azure Machine Learning.
Para verificar os resultados de uma execução em lote, selecione a execução e, em seguida, selecione Visualizar saídas.
Na tela Visualizar saídas, a seção Execuções e métricas mostra os resultados gerais da execução em lote e da execução de avaliação. A seção Saídas mostra as entradas de execução linha por linha em uma tabela de resultados que também inclui ID da linha, Execução, Status e Métricas do sistema.
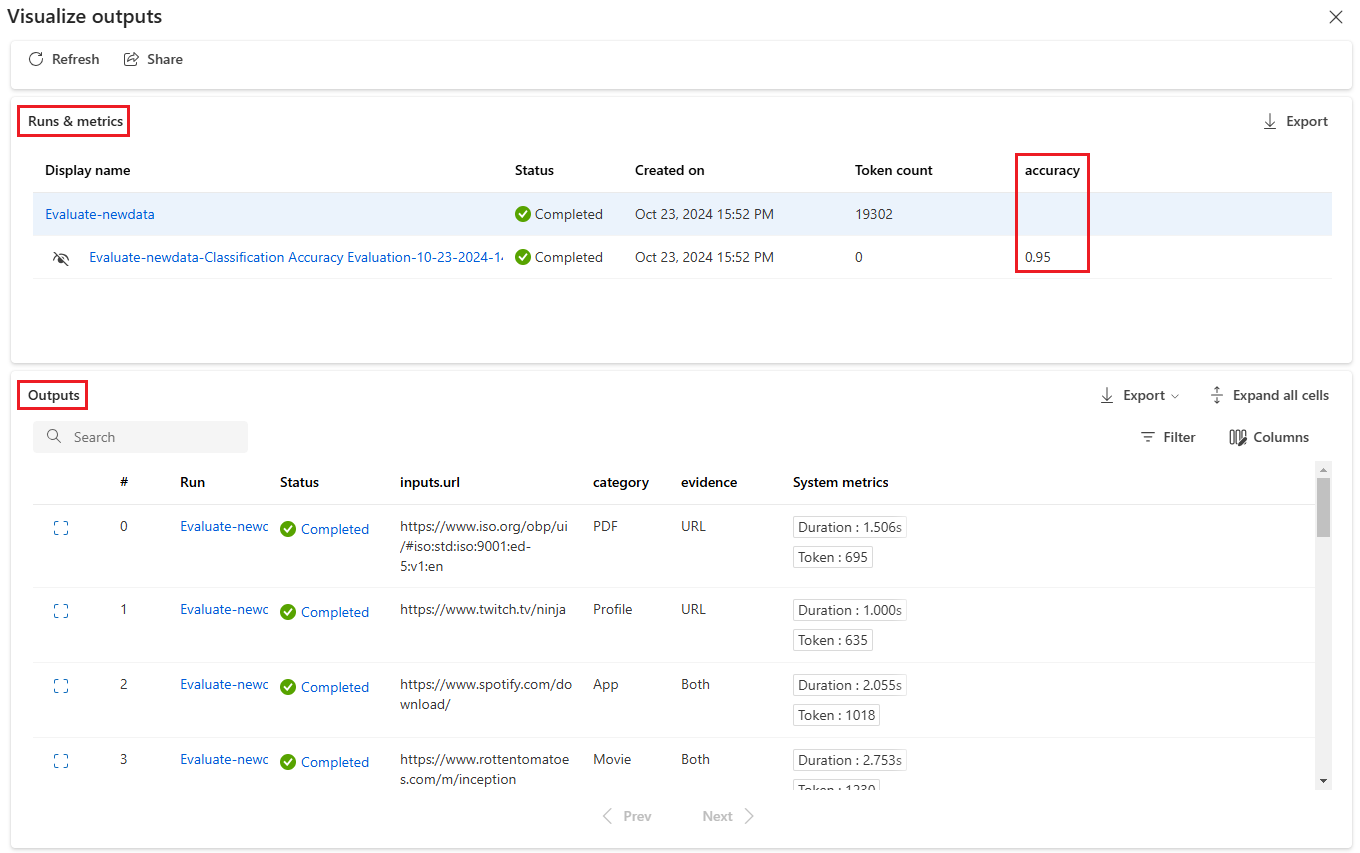
Se você habilitar o ícone Exibir ao lado da execução de avaliação na seção Execuções e métricas, a tabela Saídas também mostrará a pontuação ou nota da avaliação para cada linha.
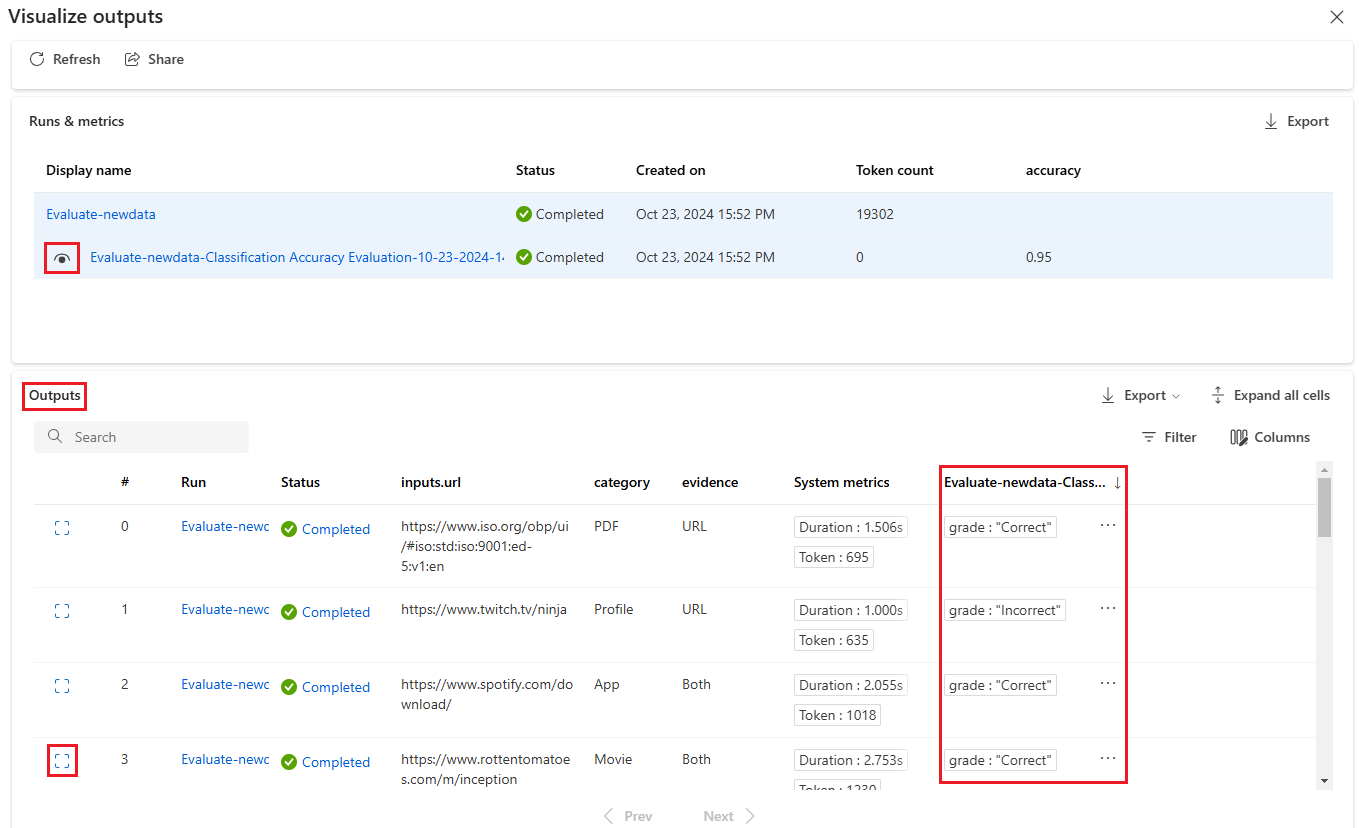
Selecione o ícone Exibir detalhes ao lado de cada linha na tabela Saídas para observar e depurar a Visualização de rastreamento e Detalhes para esse caso de teste. A visualização Rastreamento mostra informações como número de Tokens e duração para aquele caso. Expanda e selecione qualquer etapa para ver a Visão geral e as Entradas para essa etapa.
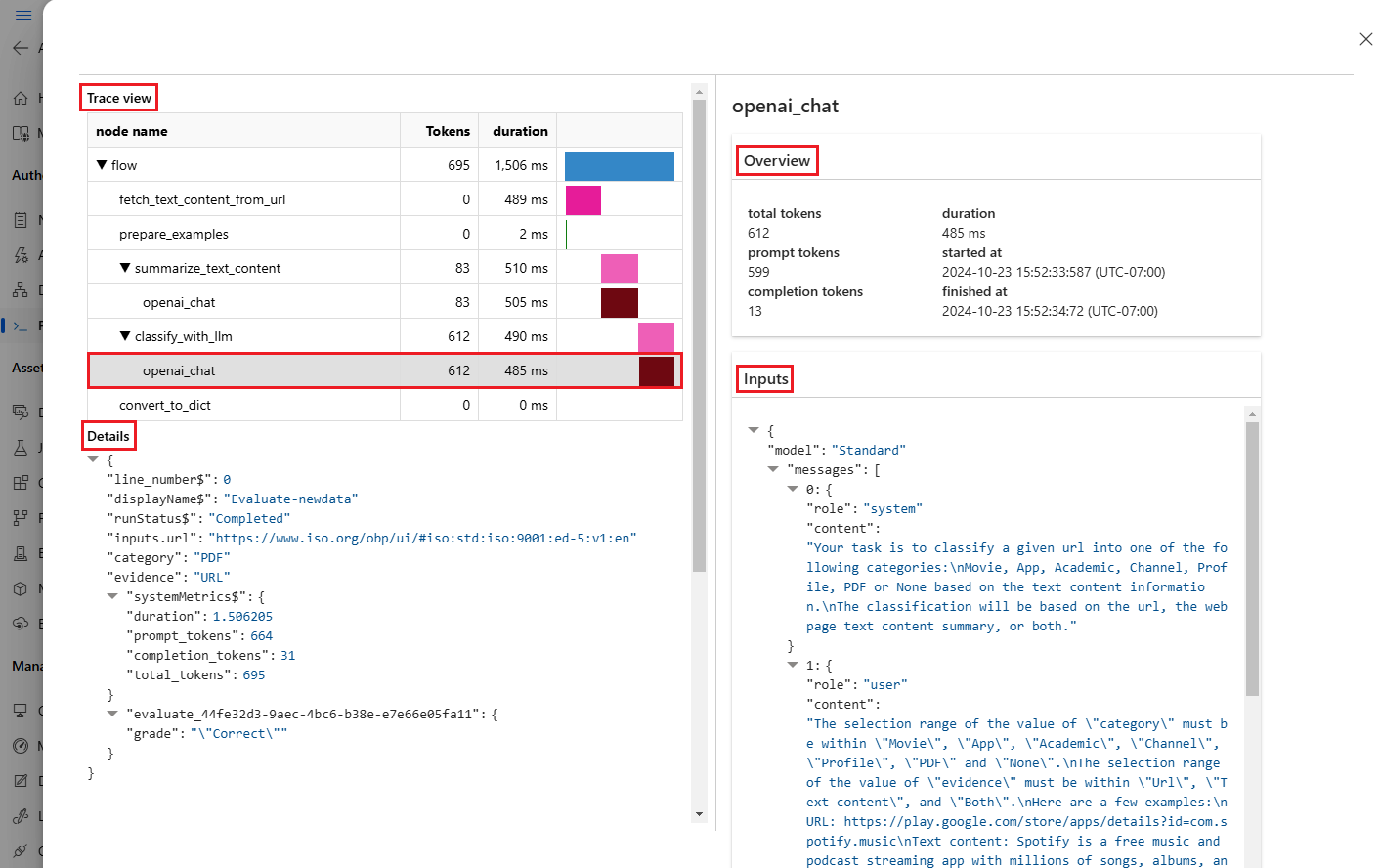




Você também pode visualizar os resultados da execução de avaliação do prompt flow que você testou. Em Exibir execuções em lote, selecione Exibir execuções em lote para ver a lista de execuções em lote do fluxo ou selecione Exibir saídas das últimas execuções em lote para ver as saídas da última execução.

Na lista de execuções em lote, selecione um nome de execução em lote para abrir a página de fluxo dessa execução.
Na página de fluxo de uma execução de avaliação, selecione Exibir saídas ou Detalhes para ver detalhes do fluxo. Você também pode Clonar o fluxo para criar um novo fluxo ou Implantá-lo como um ponto de extremidade online.

Na tela Detalhes:
A guia Visão geral mostra informações abrangentes sobre a execução, incluindo propriedades da execução, conjunto de dados de entrada, conjunto de dados de saída, marcas e descrição.
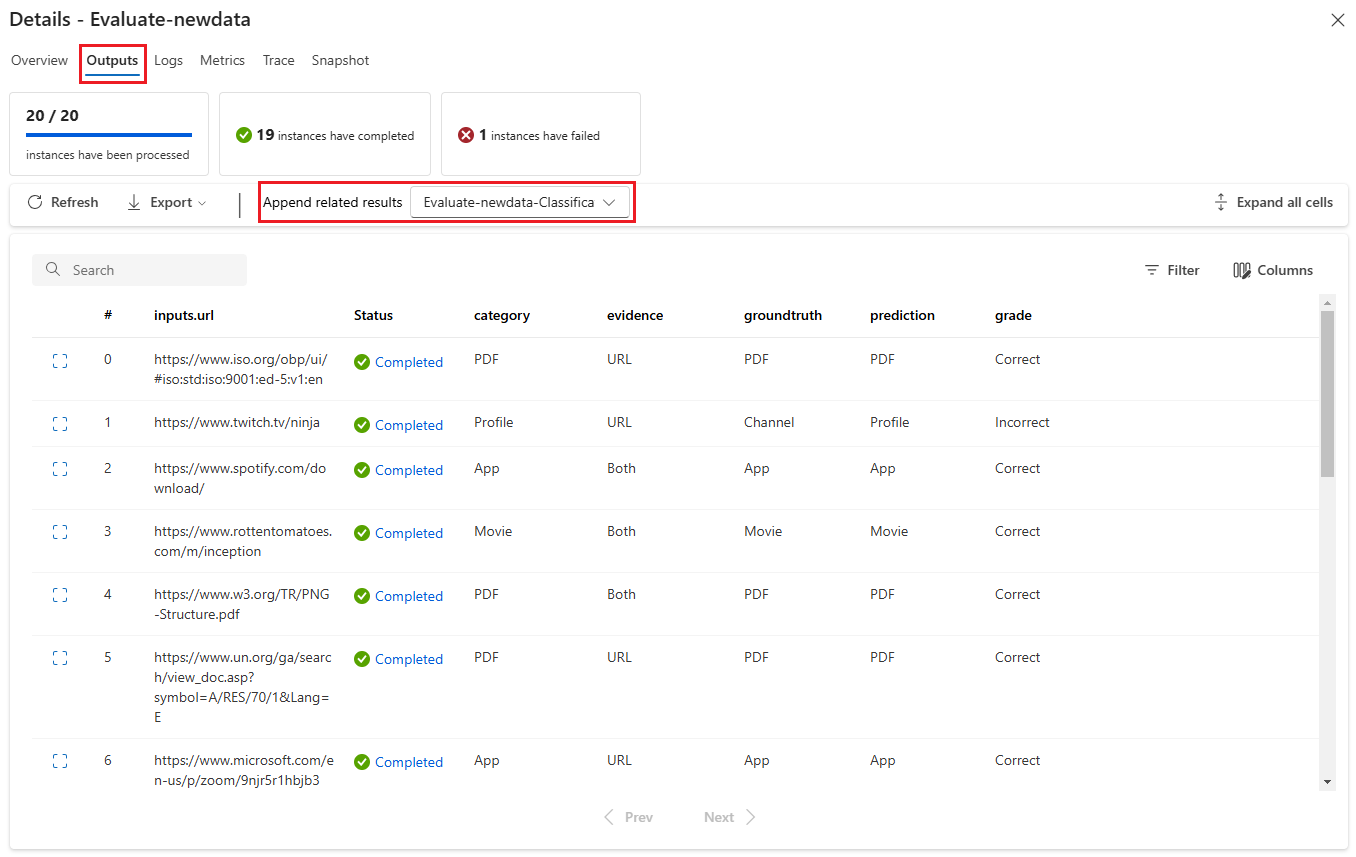
A guia Saídas mostra um resumo dos resultados na parte superior da página, seguido pela tabela de resultados da execução em lote. Se você selecionar a execução de avaliação ao lado de Anexar resultados relacionados, a tabela também mostrará os resultados da execução de avaliação.
A guia Logs mostra os logs de execução, que podem ser úteis para depuração detalhada de erros de execução. Você pode baixar os arquivos de log.
A guia Métricas fornece um link para as métricas da execução.
A aba Rastrear mostra informações detalhadas como número de Tokens e duração para cada caso de teste. Expanda e selecione qualquer etapa para ver a Visão geral e as Entradas para essa etapa.
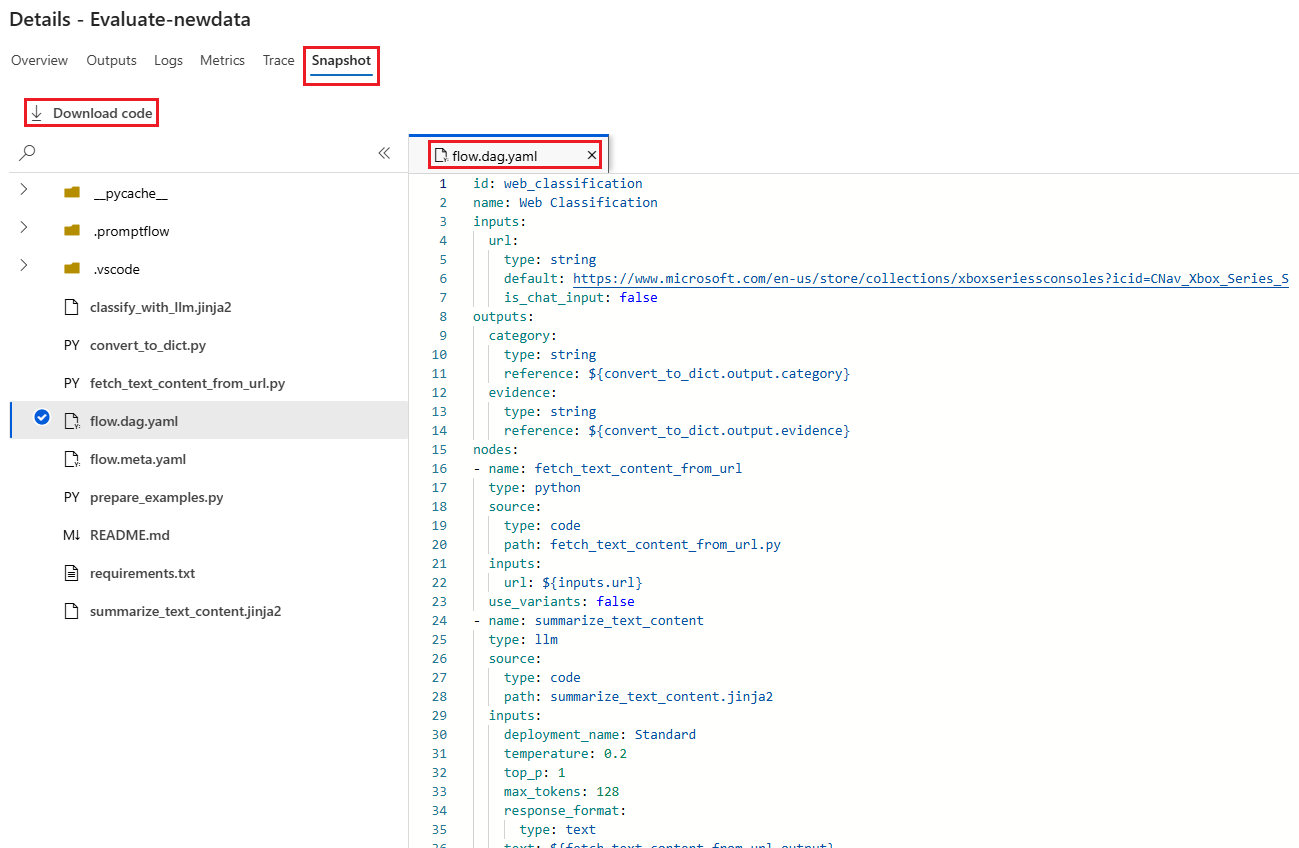
A guia Snapshot mostra os arquivos e o código da execução. Você pode ver a definição de fluxo flow.dag.yaml e baixar qualquer um dos arquivos.


Iniciar uma nova rodada de avaliação para a mesma execução
Você pode executar uma nova rodada de avaliação para calcular métricas para uma execução em lote concluída sem executar o fluxo novamente. Esse processo economiza o custo de execução repetida do fluxo e é útil nos seguintes cenários:
- Você não selecionou um método de avaliação ao enviar uma execução em lote e agora deseja avaliar o desempenho da execução.
- Você usou um método de avaliação para calcular uma determinada métrica e agora deseja calcular uma métrica diferente.
- A execução de avaliação anterior falhou, mas a execução em lote gerou saídas com sucesso e você deseja tentar a avaliação novamente.
Para iniciar outra rodada de avaliação, selecione Avaliar na parte superior da página de fluxo de execução em lote. O assistente Nova avaliação abre na tela Selecionar avaliação. Conclua a configuração e envie a nova execução de avaliação.
A nova execução aparece na lista Executar do prompt flow, e você pode selecionar mais de uma linha na lista e então selecionar Visualizar saídas para comparar as saídas e métricas.
Compare o histórico de execução da avaliação e as métricas
Se você modificar seu fluxo para melhorar seu desempenho, poderá enviar várias execuções em lote para comparar o desempenho das diferentes versões de fluxo. Você também pode comparar as métricas calculadas por diferentes métodos de avaliação para ver qual método é mais adequado para seu fluxo.
Para verificar o histórico de execuções em lote do seu fluxo, selecione Exibir execuções em lote na parte superior da sua página de fluxo. Você pode selecionar cada execução para verificar os detalhes. Você também pode selecionar várias execuções e selecionar Visualizar saídas para comparar as métricas e as saídas dessas execuções.

Entenda as métricas de avaliação integradas
O prompt flow do Azure Machine Learning fornece vários métodos de avaliação integrados para ajudar você a medir o desempenho da saída do seu fluxo. Cada método de avaliação calcula métricas diferentes. A tabela a seguir descreve os métodos de avaliação integrados disponíveis.
| Método de avaliação | Métrica | Descrição | Conexão necessária? | Entrada Requerida | Valores de pontuação |
|---|---|---|---|---|---|
| Avaliação de precisão da classificação | Precisão | Mede o desempenho de um sistema de classificação comparando suas saídas com a verdade básica | Não | previsão, verdade básica | No intervalo [0, 1] |
| Avaliação de fundamentação de perguntas e respostas | Fundamentação | Mede o grau de fundamentação das respostas previstas do modelo na fonte de entrada. Mesmo que as respostas do LLM sejam precisas, elas não têm fundamento se não forem verificáveis em relação à fonte. | Sim | pergunta, resposta, contexto (nenhuma verdade básica) | 1 a 5, com 1 = pior e 5 = melhor |
| Avaliação de Similaridade do QnA GPT | Similaridade com o GPT | Mede a similaridade entre as respostas da verdade básica fornecidas pelo usuário e a resposta prevista pelo modelo usando um modelo GPT | Sim | pergunta, resposta, verdade básica (contexto não necessário) | 1 a 5, com 1 = pior e 5 = melhor |
| Avaliação de relevância de perguntas e respostas | Relevância | Mede a relevância das respostas previstas do modelo para as perguntas feitas | Sim | pergunta, resposta, contexto (nenhuma verdade básica) | 1 a 5, com 1 = pior e 5 = melhor |
| Avaliação de coerência de perguntas e respostas | Coerência | Mede a qualidade de todas as frases na resposta prevista de um modelo e como elas se encaixam naturalmente | Sim | pergunta, resposta (nenhuma verdade básica ou contexto) | 1 a 5, com 1 = pior e 5 = melhor |
| Avaliação de fluência de perguntas e respostas | Fluência | Mede a correção gramatical e linguística da resposta prevista pelo modelo | Sim | pergunta, resposta (nenhuma verdade básica ou contexto) | 1 a 5, com 1 = pior e 5 = melhor |
| Avaliação de pontuações QnA F1 | Medida f | Mede a proporção do número de palavras compartilhadas entre a previsão do modelo e a verdade básica | Não | pergunta, resposta, verdade básica (contexto não necessário) | No intervalo [0, 1] |
| Avaliação de similaridade do Ada de perguntas e respostas | Similaridade do Ada | Calcula embeddings de nível de sentença (documento) usando a API de embeddings Ada para verdade básica e previsão e, em seguida, calcula a similaridade de cosseno entre eles (um número de ponto flutuante) | Sim | pergunta, resposta, verdade básica (contexto não necessário) | No intervalo [0, 1] |
Melhore o desempenho do fluxo
Se sua execução falhar, verifique a saída e os dados de log e depure qualquer falha de fluxo. Para corrigir o fluxo ou melhorar o desempenho, tente modificar o prompt de fluxo, a mensagem do sistema, os parâmetros de fluxo ou a lógica do fluxo.
Engenharia de prompts
A criação de prompt pode ser complexa. Para aprender sobre conceitos de construção de prompts, veja Visão geral dos prompts. Para aprender a construir um prompt que pode ajudar a atingir seus objetivos, veja Técnicas de engenharia de prompt.
Mensagem do sistema
Você pode usar a mensagem do sistema, às vezes chamada de metaprompt ou prompt do sistema, para orientar o comportamento de um sistema de IA e melhorar o desempenho do sistema. Para aprender como melhorar o desempenho do seu fluxo com mensagens do sistema, veja Criação passo a passo de mensagens do sistema.
Conjuntos de dados dourados
Criar um copiloto que usa LLMs normalmente envolve fundamentar o modelo na realidade usando conjuntos de dados de origem. Um conjunto de dados de ouro ajuda a garantir que os LLMs forneçam as respostas mais precisas e úteis às dúvidas dos clientes.
Um conjunto de dados de ouro é uma coleção de perguntas realistas de clientes e respostas elaboradas por especialistas que servem como uma ferramenta de garantia de qualidade para os LLMs que seu copiloto usa. Os conjuntos de dados dourados não são usados para treinar um LLM ou injetar contexto em um prompt de LLM, mas para avaliar a qualidade das respostas geradas pelo LLM.
Se o seu cenário envolver um copiloto, ou se você estiver criando seu próprio copiloto, veja Produzindo conjuntos de dados de ouro para obter orientações detalhadas e práticas recomendadas.