Como usar a replicação do Apache Hive em clusters do Azure HDInsight
No contexto de bancos de dados e warehouses, a replicação é o processo de duplicação de entidades de um warehouse para outro. A duplicação pode ser aplicada a um banco de dados inteiro ou a um nível menor, como uma tabela ou partição. O objetivo é ter uma réplica que seja alterada sempre que a entidade base for alterada. A replicação no Apache Hive se concentra na recuperação de desastres e oferece replicação de cópia primária unidirecional. Nos clusters do HDInsight, a replicação do Hive pode ser usada para replicar unidirecionalmente o metastore do Hive e o data lake subjacente associado no Azure Data Lake Storage Gen2.
A replicação do Hive evoluiu ao longo dos anos com versões mais recentes, proporcionando melhor funcionalidade e com uso mais rápido e menos intenso de recursos. Neste artigo, discutiremos a replicação do Hive (Replv2), que tem suporte nos tipos de cluster HDInsight 3.6 e HDInsight 4.0.
Vantagens do replv2
A ReplicaçãoV2 do Hive (também chamada de Replv2Replv2) tem as seguintes vantagens em relação à primeira versão que usou o Hive IMPORT-EXPORT:
- Replicação incremental baseada em eventos
- Replicação pontual
- Requisitos de largura de banda reduzidos
- Redução no número de cópias intermediárias
- O estado de replicação é mantido
- Replicação restrita
- Suporte para um modelo de hub e spoke
- Suporte para tabelas ACID (no HDInsight 4.0)
Fases de replicação
A replicação baseada em eventos do Hive é configurada entre os clusters primário e secundário. Essa replicação consiste em duas fases distintas: inicialização e execuções incrementais.
Inicialização
A inicialização deve ser executada uma vez para replicar o estado de base dos bancos de dados do primário para o secundário. Você pode configurar a inicialização, se necessário, para incluir um subconjunto das tabelas no banco de dados de destino em que a replicação deve ser habilitada.
Execuções incrementais
Após a inicialização, as execuções incrementais são automatizadas no cluster primário, e os eventos gerados durante essas execuções são executados novamente no cluster secundário. Quando o cluster secundário alcança o cluster primário, o secundário se torna consistente com os eventos do primário.
Comandos de replicação
O Hive oferece um conjunto de comandos REPL – DUMP, LOAD, e STATUS para orquestrar o fluxo de eventos. O comando DUMP gera um log local de todos os eventos de DDL/DML no cluster primário. O comando LOAD é uma abordagem para copiar lentamente metadados e dados registrados para a saída de despejo de replicação extraída e é executado no cluster de destino. O comando STATUS é executado do cluster de destino para fornecer o último ID de evento que a carga de replicação mais recente foi replicada com sucesso.
Definir origem de replicação
Antes de começar a replicação, verifique se o banco de dados que será replicado está definido como a origem de replicação. Você pode usar o comando DESC DATABASE EXTENDED <db_name> para determinar se o parâmetro repl.source.for está definido com o nome da política.
Se a política estiver agendada e o parâmetro repl.source.for não estiver definido, você precisará primeiro definir esse parâmetro usando ALTER DATABASE <db_name> SET DBPROPERTIES ('repl.source.for'='<policy_name>').
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source.for'='replpolicy1')
Despejar metadados no data lake
O comando REPL DUMP [database name]. => location / event_id é usado na fase de inicialização para despejar metadados relevantes para Azure Data Lake Storage Gen2. O event_id especifica o evento mínimo para o qual os metadados relevantes foram colocados no Azure Data Lake Storage Gen2.
repl dump tpcds_orc;
Saída de exemplo:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0 | 2925 |
Carregar dados no cluster de destino
O comando REPL LOAD [database name] FROM [ location ] { WITH ( ‘key1’=‘value1’{, ‘key2’=‘value2’} ) } é usado para carregar dados no cluster de destino para a inicialização e as fases incrementais da replicação. O [database name] pode ser o mesmo que a origem ou um nome diferente no cluster de destino. O [location] representa o local da saída do comando REPL DUMP anterior. Isso significa que o cluster de destino deve ser capaz de se comunicar com o cluster de origem. A cláusula WITH foi adicionada principalmente para impedir uma reinicialização do cluster de destino, permitindo a replicação.
repl load tpcds_orc from '/tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0';
Saída do último ID do evento replicado
O comando REPL STATUS [database name] é executado em clusters de destino e gera a última replicação event_id. O comando também permite que os usuários saibam para qual estado seu cluster de destino é replicado. Você pode usar a saída desse comando para construir o próximo comando REPL DUMP para replicação incremental.
repl status tpcds_orc;
Saída de exemplo:
| last_repl_id |
|---|
| 2925 |
Despejar dados e metadados relevantes no data lake
O comando REPL DUMP [database name] FROM [event-id] { TO [event-id] } { LIMIT [number of events] } é usado para despejar metadados e dados relevantes no Azure Data Lake Storage. Esse comando é usado na fase incremental e é executado no warehouse de origem. O FROM [event-id] é necessário para a fase incremental e o valor de event-id pode ser derivado executando o comando REPL STATUS [database name] no warehouse de destino.
repl dump tpcds_orc from 2925;
Saída de exemplo:
| dump_dir | last_repl_id |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-466466agadd0 | 2960 |
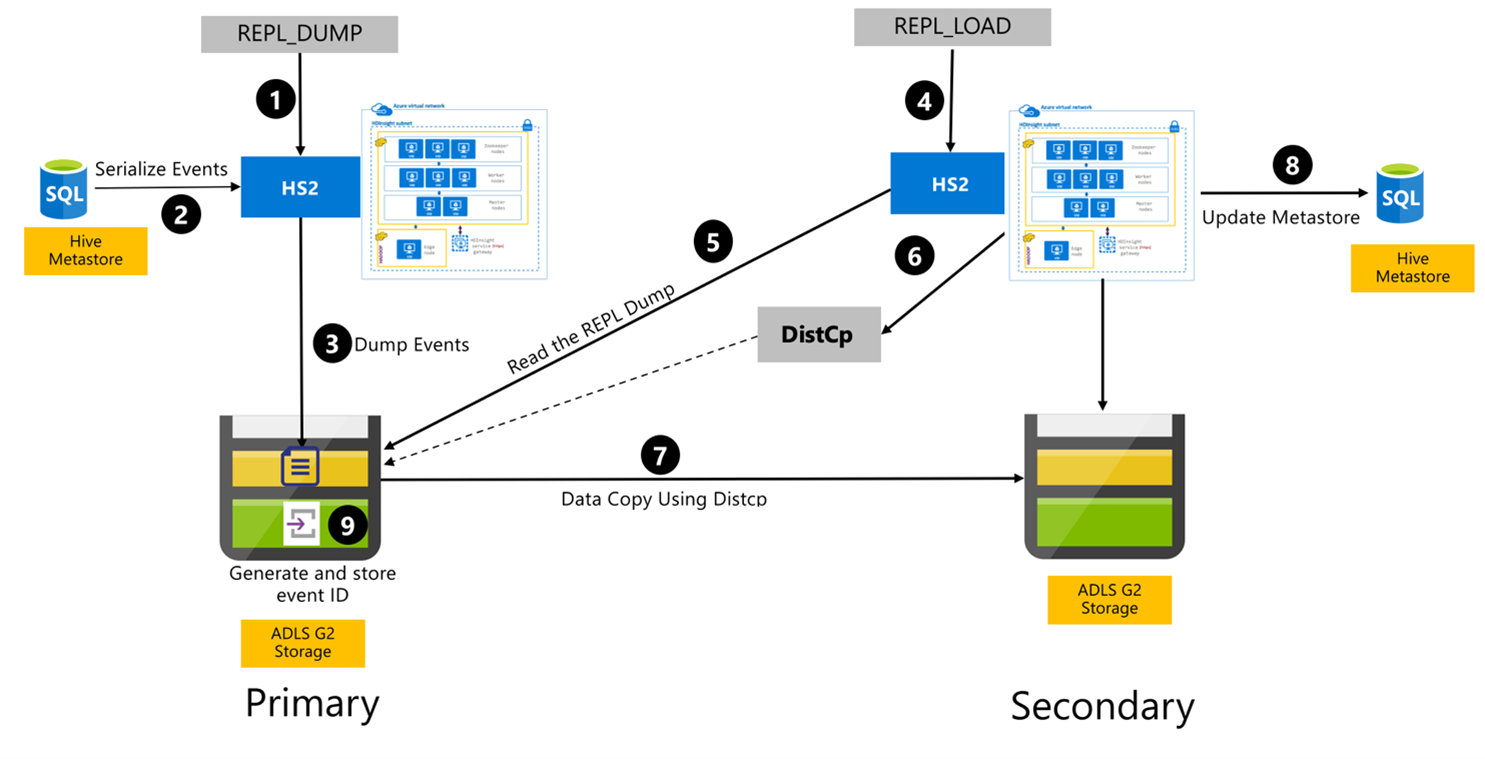
Processo de replicação Hive
As etapas a seguir são os eventos sequenciais que ocorrem durante o processo de replicação do Hive.
Verifique se as tabelas a serem replicadas estão definidas como a origem da replicação para determinada política.
O comando
REPL_DUMPé emitido para o cluster primário com restrições associadas, como nome do banco de dados, intervalo de ID do evento e URL de armazenamento do Azure Data Lake Storage Gen2.O sistema serializa um despejo de todos os eventos rastreados do metastore para o mais recente. Esse despejo é armazenado na conta de armazenamento do Azure Data Lake Storage Gen2 no cluster primário na URL especificada pelo
REPL_DUMP.O cluster primário persiste nos metadados de replicação para o armazenamento do Azure Data Lake Storage Gen2 do cluster primário. O caminho é configurável na interface do usuário de configuração do Hive no Ambari. O processo fornece o caminho em que os metadados são armazenados e o ID do evento de DML/DDL rastreado mais recente.
O comando
REPL_LOADé emitido a partir do cluster secundário. O comando aponta para o caminho configurado na etapa 3.O cluster secundário lê o arquivo de metadados com eventos rastreados criados na etapa 3. Verifique se o cluster secundário tem conectividade de rede com o armazenamento do Azure Data Lake Storage Gen2 do cluster primário em que os eventos rastreados de
REPL_DUMPsão armazenados.O cluster secundário gera a computação de cópia distribuída (
DistCP).O cluster secundário copia dados do armazenamento do cluster primário.
O metastore no cluster secundário é atualizado.
O último ID do evento rastreado é armazenado no metastore primário.
A replicação incremental segue o mesmo processo e requer o último ID do evento replicado como entrada. Isso leva a uma cópia incremental desde o último evento de replicação. As replicações incrementais normalmente são automatizadas com uma frequência predeterminada para alcançar os RPOs (objetivos de ponto de recuperação) necessários.
Padrões de replicação
A replicação normalmente é configurada de forma unidirecional entre o primário e o secundário, em que o primário atende às solicitações de leitura e gravação. O cluster secundário atende apenas às solicitações de leitura. As gravações são permitidas no secundário se houver um desastre, mas a replicação inversa deve ser configurada de volta para o primário.
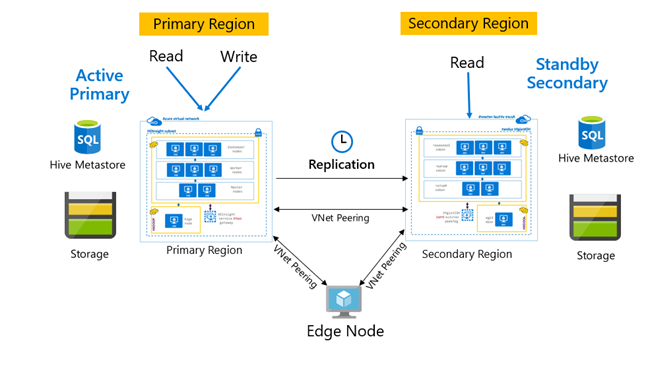
Há muitos padrões adequados para a replicação do Hive, incluindo primário – secundário, hub e spoke e retransmissão.
No ativo primário do HDInsight – o secundário em espera é um padrão comum de BCDR (continuidade dos negócios e recuperação de desastres) e o HiveReplicationV2 pode usar esse padrão com clusters HDInsight Hadoop separados de modo regional com emparelhamento VNet. Uma máquina virtual comum emparelhada com ambos os clusters pode ser usada para hospedar os scripts de automação de replicação. Para saber mais sobre possíveis padrões de BCDR do HDInsight, consulte a documentação de continuidade dos negócios do HDInsight.
Replicação do Hive com Enterprise Security Package
Nos casos em que a replicação do Hive é planejada em clusters Hadoop do HDInsight com o Enterprise Security Package, você precisa considerar os mecanismos de replicação para o metastore do Ranger e o Microsoft Entra Domain Services.
Use o recurso de conjuntos de réplicas do Microsoft Entra Domain Services para criar mais de um conjunto de réplicas do Microsoft Entra Domain Services por locatário do Microsoft Entra em várias regiões. Cada conjunto de réplicas individual precisa ser emparelhado com o HDInsight VNets em suas respectivas regiões. Nessa configuração, as alterações no Microsoft Entra Domain Services, incluindo configuração, identidade e credenciais do usuário, grupos, objetos de política de grupo, objetos de computador e outras alterações são aplicadas a todos os conjuntos de réplicas no domínio gerenciado usando a replicação do Microsoft Entra Domain Services.
As políticas de Ranger podem ser periodicamente submetidas a backup e replicadas do primário para o secundário usando a funcionalidade Importar-Exportar do Ranger. Você pode optar por replicar todas ou um subconjunto de políticas do Ranger, dependendo do nível de autorizações que está buscando implementar no cluster secundário.
Código de exemplo
A sequência de código a seguir fornece um exemplo de como a inicialização e a replicação incremental podem ser implementadas em uma tabela de exemplo chamada tpcds_orc.
Defina a tabela como a origem para uma política de replicação.
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source. for'='replpolicy1');Despejo de inicialização no cluster primário.
repl dump tpcds_orc with ('hive.repl.rootdir'='/tmpag/hiveag/replag');Saída de exemplo:
dump_dir last_repl_id /tmpag/hiveag/replag/675d1bea-2361-4cad-bcbf-8680d305a27a 2925 Carga de inicialização no cluster secundário.
repl load tpcds_orc from '/tmpag/hiveag/replag 675d1bea-2361-4cad-bcbf-8680d305a27a';Verifique o status
REPLno cluster secundário.repl status tpcds_orc;last_repl_id 2925 Despejo incremental no cluster primário.
repl dump tpcds_orc from 2925 with ('hive.repl.rootdir'='/tmpag/hiveag/ replag');Saída de exemplo:
dump_dir last_repl_id /tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31 2960 Carga incremental no cluster secundário.
repl load tpcds_orc from '/tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31';Verifique o status
REPLno cluster secundário.repl status tpcds_orc;last_repl_id 2960
Próximas etapas
Para saber mais sobre os itens discutidos neste artigo, veja: