Arquiteturas de continuidade de negócios do Azure HDInsight
Este artigo fornece alguns exemplos de arquiteturas de continuidade de negócios que você pode considerar para o Azure HDInsight. A tolerância à funcionalidade reduzida durante um desastre é uma decisão de negócios que varia de um aplicativo para outro. Pode ser aceitável que alguns aplicativos não estejam disponíveis, ou que estejam parcialmente disponíveis com funcionalidade reduzida ou processamento atrasado por algum período. Para outros aplicativos, qualquer funcionalidade reduzida pode ser inaceitável.
Observação
As arquiteturas apresentadas neste artigo não são exaustivas. Você deve criar suas próprias arquiteturas exclusivas após elaborar determinações objetivas em relação à continuidade dos negócios esperada, à complexidade operacional e ao custo da propriedade.
Apache Hive e Interactive Query
A Replicação do Hive V2 é recomendada para continuidade dos negócios em clusters de consulta Interativa e do Hive no HDInsight. As seções persistentes de um cluster Hive autônomo que precisam ser replicadas são a Camada de Armazenamento e o metastore do Hive. Os clusters do Hive em um cenário multiusuário com o Enterprise Security Package precisam do Microsoft Entra Domain Services e do Metastore do Ranger.
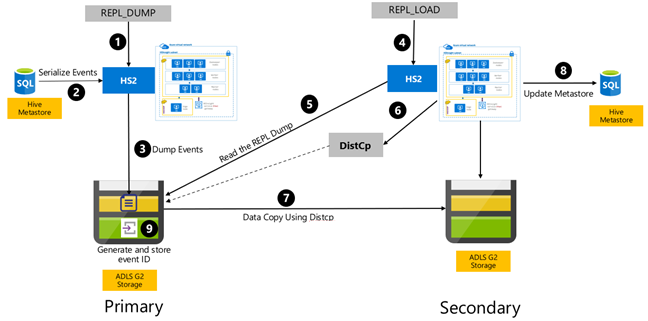
A replicação baseada em eventos do Hive é configurada entre os clusters primário e secundário. Isso consiste em duas fases distintas, inicialização e execuções incrementais:
A inicialização replica todo o Hive Warehouse, incluindo as informações de metastore do Hive do primário ao secundário.
As execuções incrementais são automatizadas no cluster primário, e os eventos gerados durante as execuções incrementais são executados novamente no cluster secundário. O cluster secundário se atualiza com os eventos gerados do cluster primário, garantindo que o cluster secundário seja consistente com os eventos do cluster primário após a replicação ser executada.
O cluster secundário é necessário apenas no momento da replicação para executar a cópia distribuída, DistCp, mas o armazenamento e os metastores precisam ser persistentes. Você pode optar por criar um cluster secundário com script sob demanda antes da replicação, executar o script de replicação nele e, em seguida, subdividi-lo após a replicação bem-sucedida.
O cluster secundário geralmente é de somente leitura. Você pode tornar o cluster secundário como de leitura/gravação, mas isso adiciona complexidade adicional que envolve a replicação das alterações do cluster secundário para o cluster primário.
RPO e RTO de replicação baseada em evento do Hive
RPO: a perda de dados é limitada ao último evento de replicação incremental bem-sucedido do primário para o secundário.
RTO: o tempo entre a falha e a retomada das transações upstream e downstream com o secundário.
O Apache Hive e as arquiteturas do Interactive Query
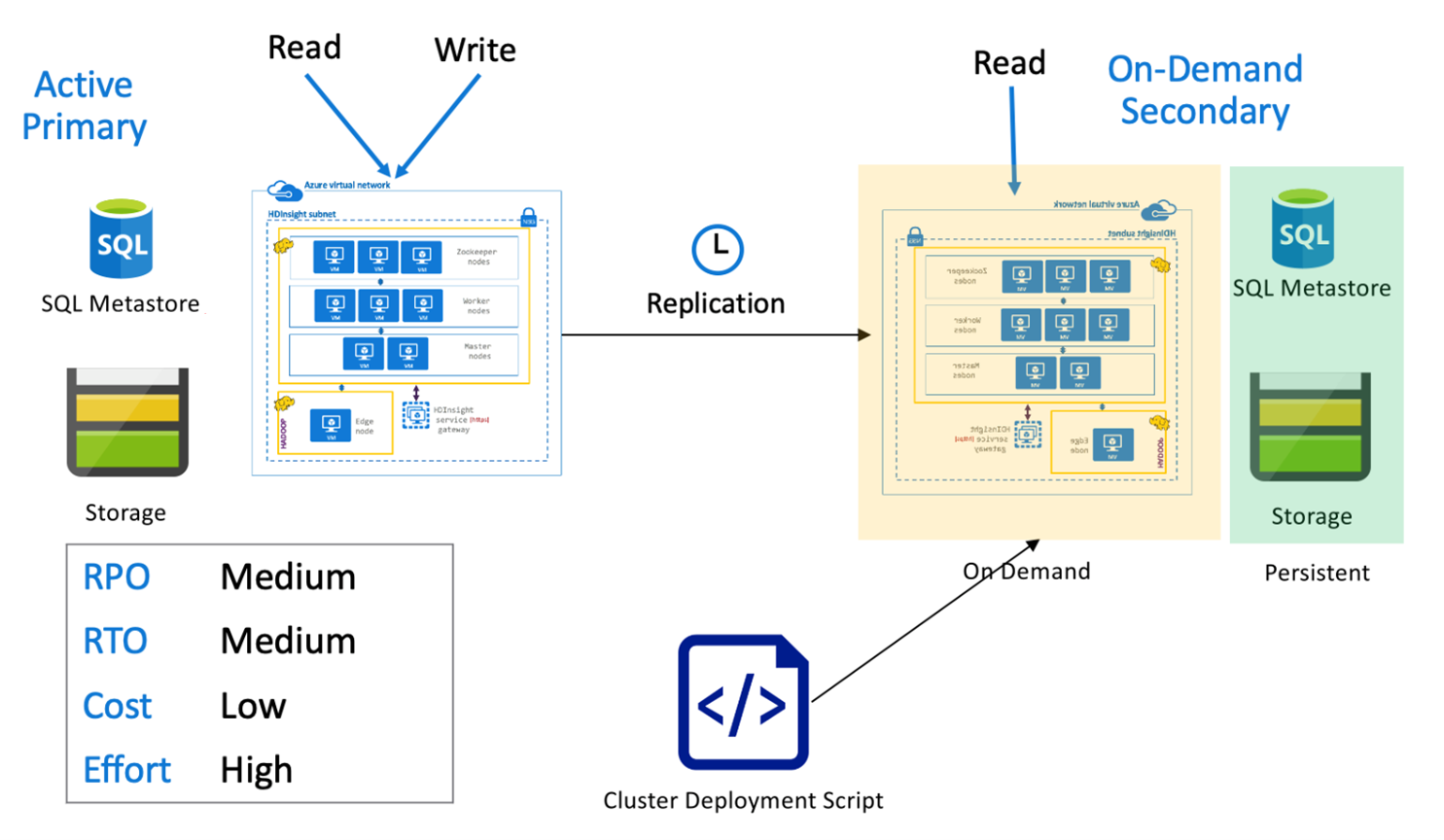
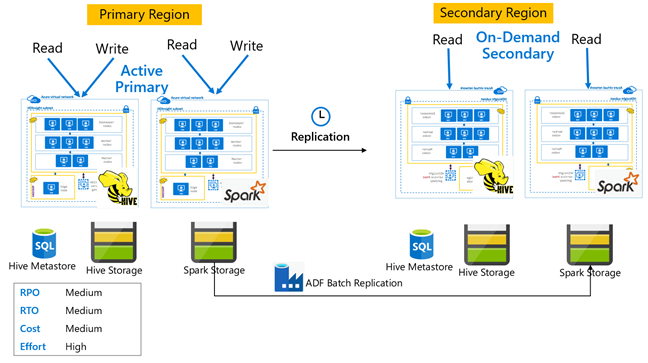
Primário ativo do Hive com secundário sob demanda
Em um primário ativo com a arquitetura secundária sob demanda, os aplicativos gravam na região primária ativa, enquanto nenhum cluster é provisionado na região secundária durante as operações normais. O Metastore do SQL e o Armazenamento na região secundária são persistentes, enquanto o cluster do HDInsight é armazenado em script e implantado sob demanda somente antes da execução da replicação do Hive agendada.
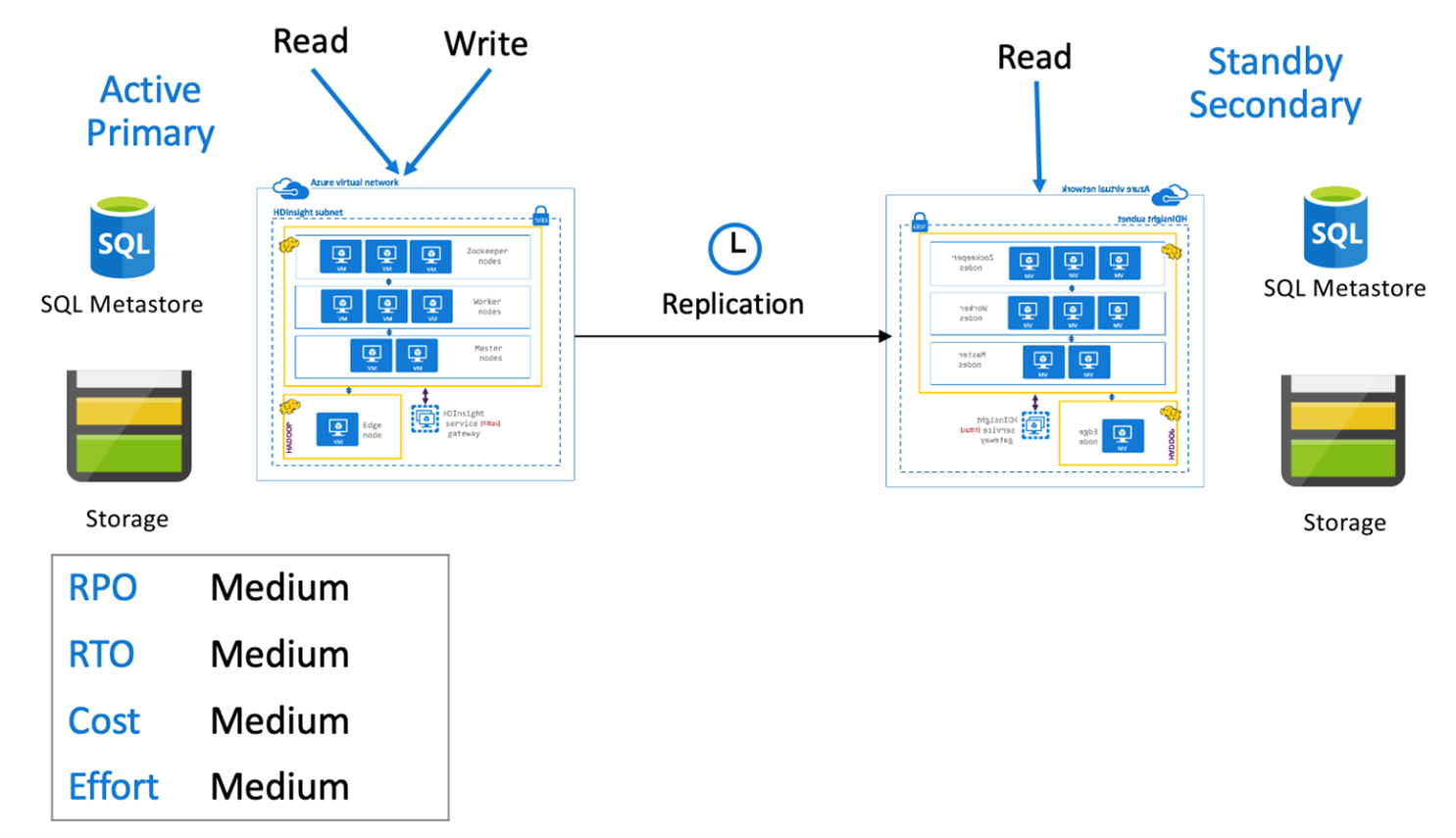
Ativo primário do Hive com secundário em espera
Em um primário ativo com o secundário em espera, os aplicativos gravam na região primária ativa enquanto um cluster secundário reduzido verticalmente em espera no modo somente leitura é executado durante as operações normais. Durante as operações normais, você pode optar por descarregar operações de leitura específicas de região para o secundário.
Para obter mais informações sobre a replicação do Hive e exemplos de código, consulte Replicação do Apache Hive em clusters do Azure HDInsight
Apache Spark
As cargas de trabalho do Spark podem ou não envolver um componente do Hive. Para permitir que as cargas de trabalho do Spark SQL leiam e gravem dados do Hive, os clusters Spark do HDInsight compartilham metastores personalizados do Hive dos clusters de consulta do Hive/Interactive na mesma região. Nesses cenários, a replicação entre regiões de cargas de trabalho do Spark também deve acompanhar a replicação de metastores e armazenamento do Hive. Os cenários de failover nesta seção se aplicam a ambos:
- Configuração Spark SQL em tabelas ACID usando o Hive Warehouse Connector (HWC) usando um cluster do Interactive Query do HDInsight.
- Carga de trabalho do Spark SQL em tabelas não ACID usando um cluster Hadoop do HDInsight.
Para cenários em que o Spark funciona no modo autônomo, os dados coletados e os Jars do Spark armazenados (para trabalhos do Livy) precisam ser replicados da região primária para a região secundária regularmente usando o DistCP do Azure Data Factory.
Recomendamos que você use sistemas de controle de versão para armazenar os notebooks e as bibliotecas do Spark onde possam ser facilmente implantados em clusters primários ou secundários. Verifique se as soluções baseadas e não baseadas em notebook estão preparadas para carregar as montagens de dados corretas no workspace primário ou secundário.
Se houver bibliotecas específicas do cliente que estão além do que o HDInsight fornece de forma nativa, elas deverão ser rastreadas e carregadas periodicamente no cluster secundário em espera.
RPO e RTO de replicação do Apache Spark
RPO: a perda de dados é limitada à última replicação incremental bem-sucedida (Spark e Hive) do primário para o secundário.
RTO: o tempo entre a falha e a retomada das transações upstream e downstream com o secundário.
Arquiteturas do Apache Spark
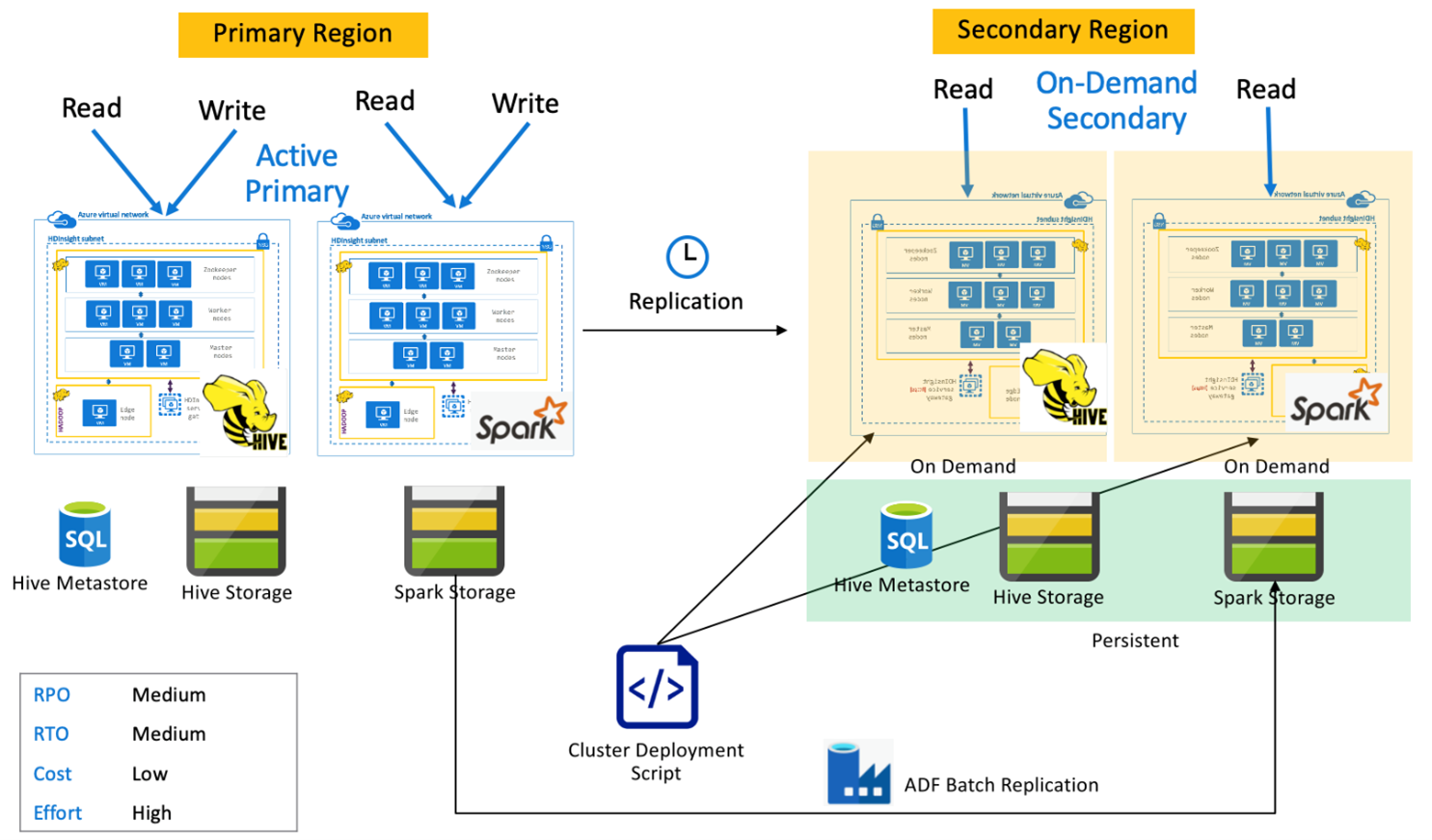
Primário ativo do Spark com secundário sob demanda
Os aplicativos leem e gravam em Clusters do Spark e do Hive na região primária, enquanto nenhum cluster é provisionado na região secundária durante operações normais. O Metastore do SQL, o Armazenamento do Hive e o Armazenamento do Spark são persistentes na região secundária. Os clusters do Spark e do Hive são armazenados em script e implantados sob demanda. A replicação do Hive é usada para replicar o Armazenamento e os Metastores do Hive, enquanto o DistCP do Azure Data Factory pode ser usado para copiar o armazenamento do Spark autônomo. Os clusters do Hive precisam ser implantados antes de cada execução de replicação do Hive por causa da computação DistCp de dependência.
Ativo primário do Spark com secundário em espera
Os aplicativos leem e gravam em clusters do Spark e do Hive na região primária, enquanto os clusters do Hive e do Spark em espera reduzidos verticalmente e no modo somente leitura são executados na região secundária durante as operações normais. Durante as operações normais, você pode optar por descarregar operações de leitura do Hive e do Spark específicas de região para o secundário.
HBase no Apache
A exportação do HBase e a Replicação do HBase são maneiras comuns de habilitar a continuidade dos negócios entre clusters do HBase do HDInsight.
A exportação do HBase é um processo de replicação em lote que usa o utilitário de exportação do HBase para exportar tabelas do cluster do HBase primário para seu armazenamento subjacente no Azure Data Lake Storage Gen 2. Os dados exportados podem ser acessados por meio do cluster secundário do HBase e importados para tabelas que devem estar no secundário. Enquanto a exportação do HBase oferece granularidade de nível de tabela, em situações de atualização incremental, o mecanismo de automação de exportação controla o intervalo de linhas incrementais a serem incluídas em cada execução. Para obter mais informações, consulte Backup e replicação do HBase do HDInsight.
A replicação do HBase usa replicação quase em tempo real entre clusters do HBase de forma totalmente automatizada. A replicação é feita no nível da tabela. Qualquer tabela ou tabela específica pode ser direcionada para replicação. A replicação do HBase é eventualmente consistente, o que significa que edições recentes em uma tabela na região primária podem não estar disponíveis imediatamente para todas as secundárias. É garantido que as secundárias se tornem eventualmente consistentes com a primária. A replicação do HBase pode ser configurada entre dois ou mais clusters do HBase do HDInsight se:
- O primário e o secundário estão na mesma rede virtual.
- O primário e o secundário estão em VNets emparelhadas e diferentes na mesma região.
- O primário e o secundário estão em VNets emparelhadas e diferentes em regiões diferentes.
Para obter mais informações, consulte Configurar a replicação de cluster do Apache HBase em redes virtuais do Azure.
Há algumas outras maneiras de executar backups de clusters do HBase, como copiar a pasta hbase, copiar as tabelas e por Instantâneos.
RPO e RTO do HBase
Exportação do HBase
- RPO: a perda de dados é limitada à última importação incremental em lote bem-sucedida pelo secundário a partir do primário.
- RTO: o tempo entre a falha do primário e a retomada das operações de E/S no secundário.
Replicação do HBase
- RPO: a perda de dados é limitada à última remessa de WalEdit recebida no secundário.
- RTO: o tempo entre a falha do primário e a retomada das operações de E/S no secundário.
Arquiteturas do HBase
A replicação do HBase pode ser configurada em três modos: Líder-Seguidor, Líder-Líder e Cíclico.
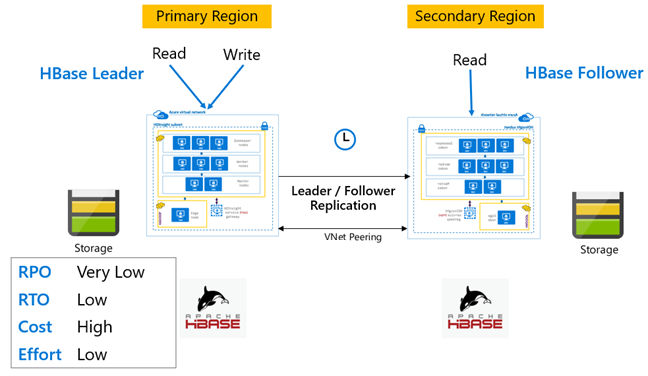
Replicação do HBase: Modelo Líder – Seguidor
Nessa configuração entre regiões, a replicação é unidirecional da região primária para a região secundária. Todas as tabelas ou tabelas específicas no primário podem ser identificadas para replicação unidirecional. Durante operações normais, o cluster secundário pode ser usado para atender solicitações de leitura em sua própria região.
O cluster secundário opera como um cluster do HBase normal que pode hospedar suas próprias tabelas e atender leituras e gravações de aplicativos regionais. No entanto, a gravação nas tabelas replicadas ou nas tabelas nativas para o secundário não é replicada de volta para o primário.
Replicação do HBase: modelo líder
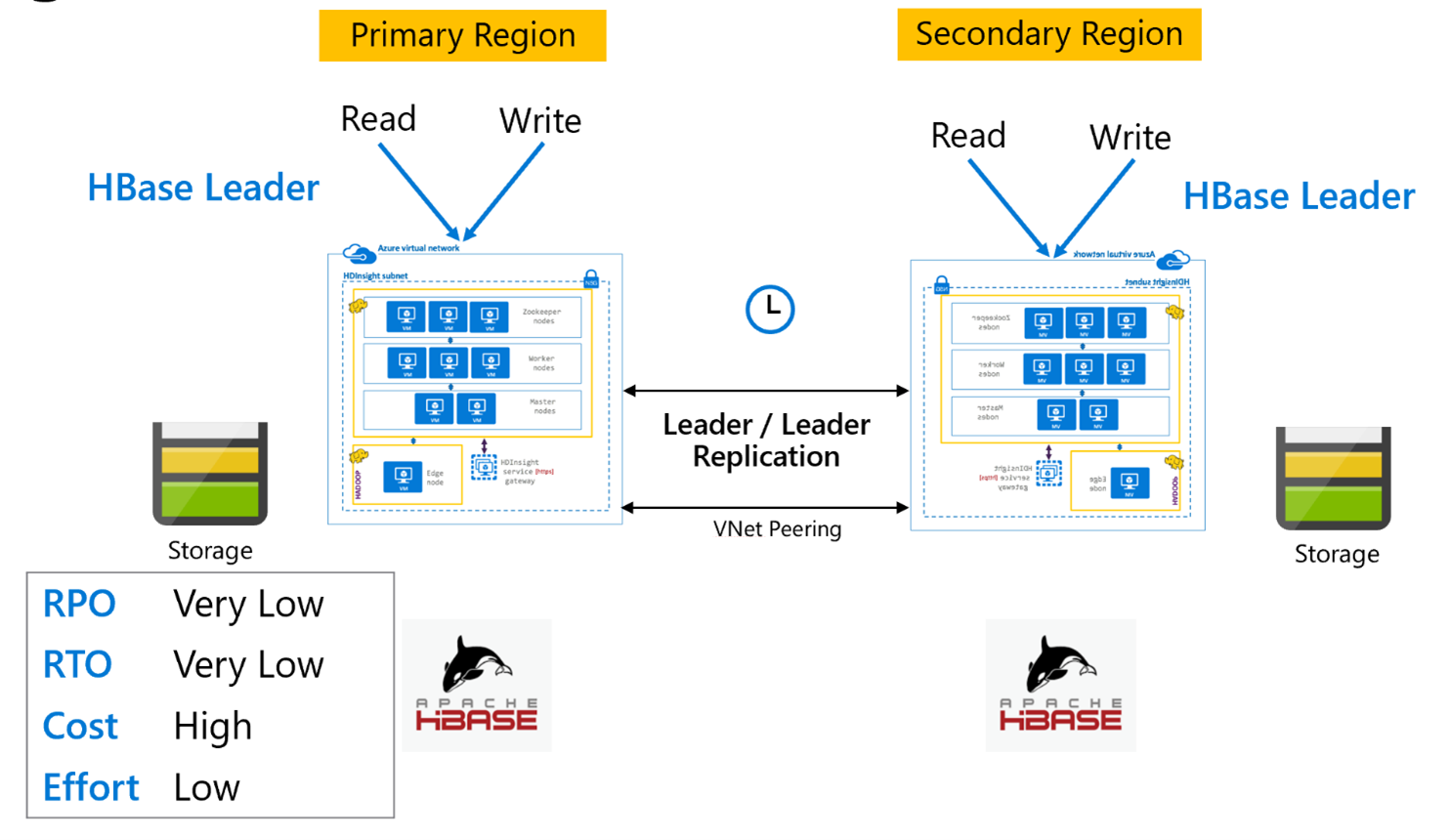
Essa configuração entre regiões é muito semelhante à configuração unidirecional, exceto que a replicação ocorre bidirecionalmente entre a região primária e a região secundária. Os aplicativos podem usar ambos os clusters em modo de leitura e gravação, e as atualizações são trocadas de forma assíncrona entre eles.
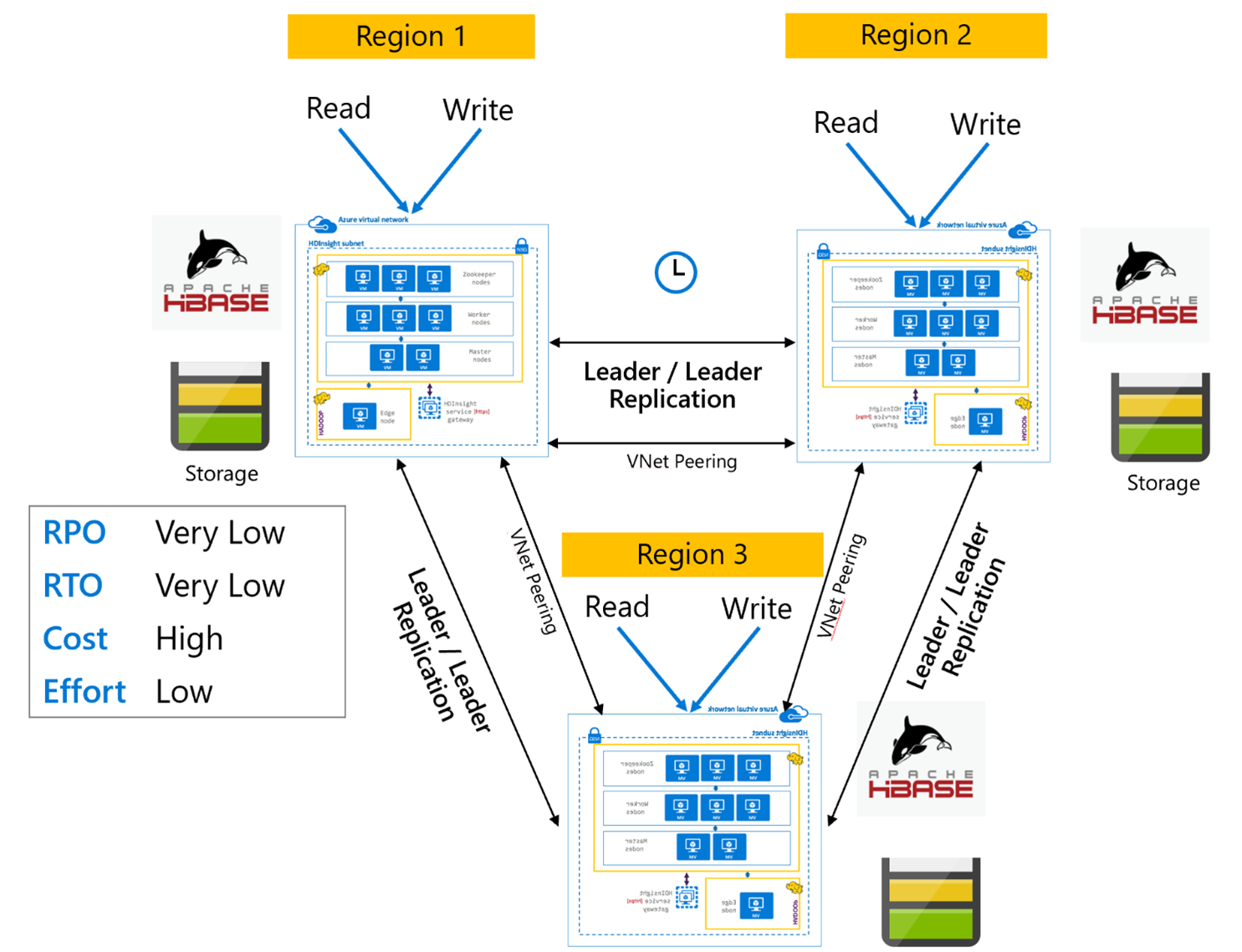
Replicação do HBase: várias regiões ou cíclicas
O modelo de replicação de várias regiões/cíclicas é uma extensão da replicação do HBase, e pode ser usado para criar uma arquitetura do HBase globalmente redundante com vários aplicativos que leem e gravam em clusters do HBase específicos da região. Os clusters podem ser configurados em várias combinações de líder/líder ou líder/seguidor, dependendo dos requisitos de negócios.
Apache Kafka
Para habilitar a disponibilidade entre regiões, o HDInsight 4.0 dá suporte ao Kafka MirrorMaker, que pode ser usado para manter uma réplica secundária do cluster Kafka primário em uma região diferente. O MirrorMaker atua como um par consumidor-produtor de alto nível, consome de um tópico específico no cluster primário e produz a um tópico com o mesmo nome no secundário. A replicação entre clusters para recuperação de desastre de alta disponibilidade usando o MirrorMaker vem com a presunção de que Produtores e Consumidores precisam fazer failover para o cluster de réplica. Para obter mais informações, consulte Usar o MirrorMaker para replicar tópicos do Apache Kafka com o Kafka no HDInsight
Dependendo do tempo de vida do tópico quando a replicação for iniciada, a replicação do tópico do MirrorMaker pode levar a deslocamentos diferentes entre os tópicos de origem e de réplica. Os clusters do HDInsight Kafka também dão suporte à replicação de partição de tópico, que é um recurso de alta disponibilidade no nível de cluster individual.
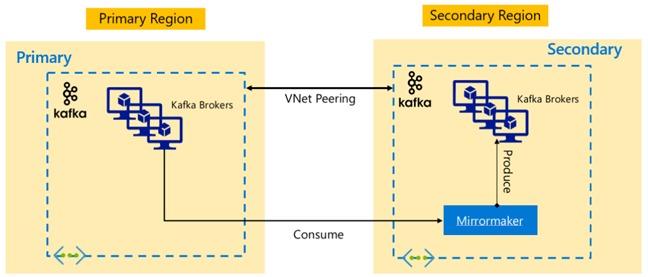
Arquiteturas do Apache Kafka
Replicação do Kafka: Ativo – Passivo
A configuração ativo-passivo habilita o espelhamento unidirecional assíncrono de ativo para passivo. Produtores e consumidores precisam estar cientes da existência de um cluster ativo e passivo, e devem estar prontos para fazer failover para o passivo caso o ativo falhe. Abaixo estão algumas vantagens e desvantagens da configuração do ativo-passivo.
Vantagens:
- A latência de rede entre clusters não afeta o desempenho do cluster ativo.
- Simplicidade de replicação unidirecional.
As desvantagens:
- O cluster passivo pode permanecer subutilizado.
- Complexidade de design ao incorporar o reconhecimento de failover em produtores e consumidores de aplicativos.
- Possível perda de dados durante a falha do cluster Ativo.
- Consistência eventual entre tópicos entre clusters ativos e passivos.
- Os failbacks para o Primário podem levar à inconsistência de mensagens nos tópicos.
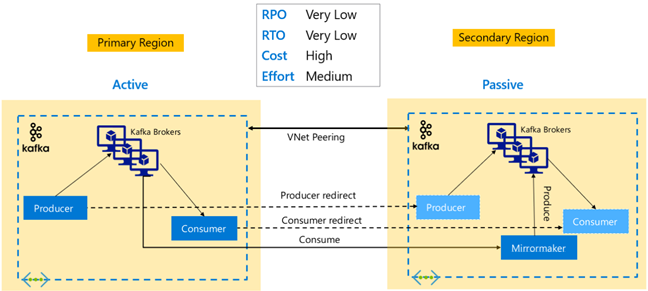
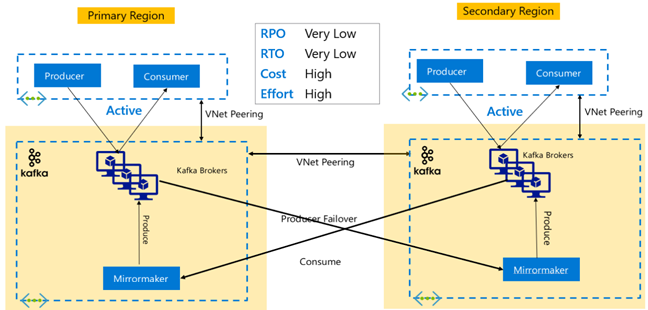
Replicação do Kafka: Ativo – Ativo
A configuração ativo-ativo envolve dois clusters do HDInsight Kafka separados regionalmente e emparelhados por VNet com replicação assíncrona bidirecional com o MirrorMaker. Nesse design, as mensagens consumidas pelos consumidores no primário também são disponibilizadas para os consumidores no secundário, e vice-versa. Abaixo estão algumas vantagens e desvantagens da configuração do ativo-ativo.
Vantagens:
- Devido ao estado duplicado, os failovers e os failbacks são mais fáceis de executar.
As desvantagens:
- A Configuração, o gerenciamento e o monitoramento são mais complexos do que no Ativo-Passivo.
- O problema da replicação circular precisa ser resolvido.
- A replicação bidirecional leva a custos de saída de dados regionais mais altos.
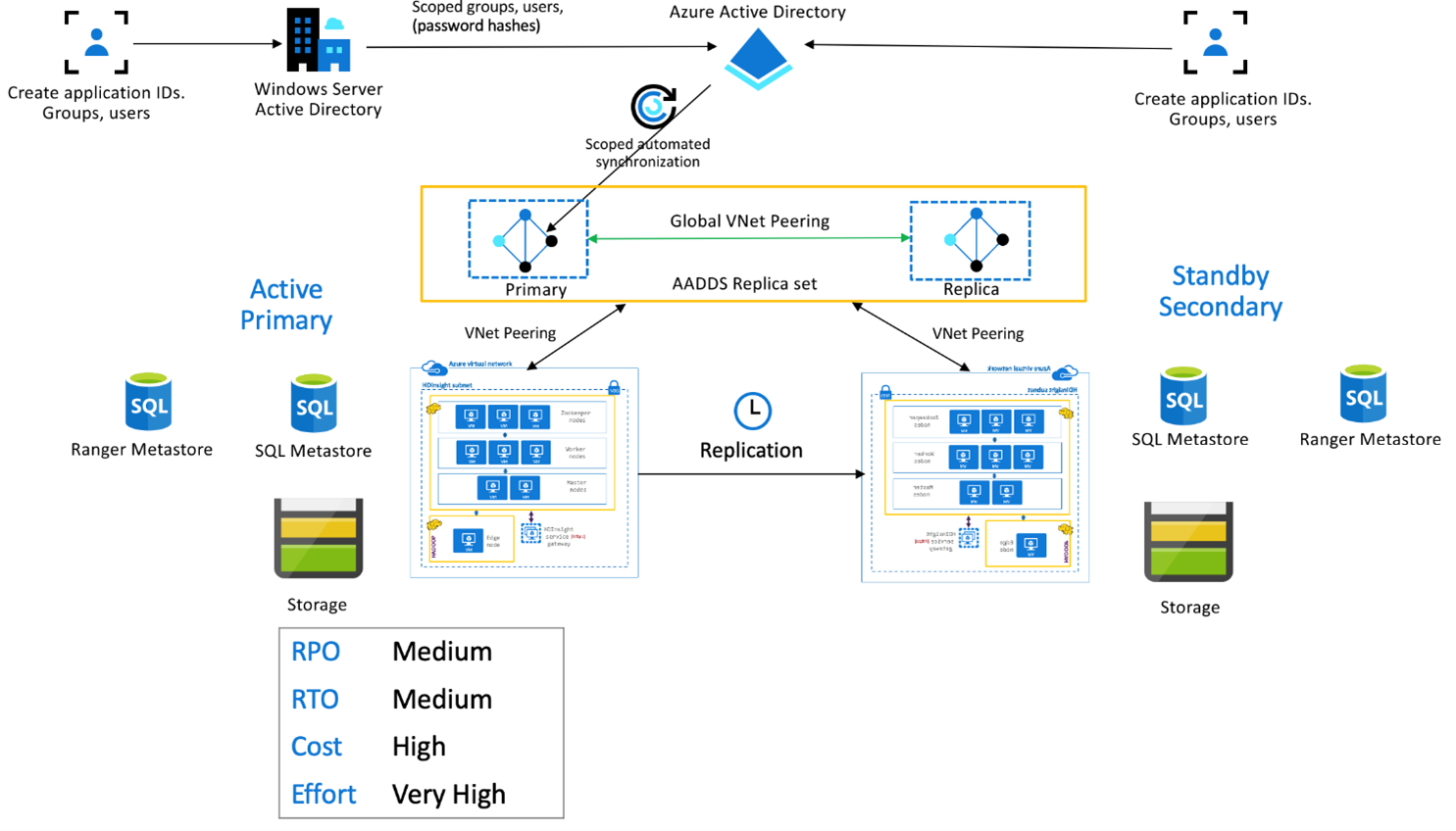
Enterprise Security Package do HDInsight
Essa configuração é usada para habilitar a funcionalidade de vários usuários no primário e no secundário, bem como em conjuntos de réplicas Microsoft Entra Domain Services, para garantir que os usuários possam se autenticar em ambos os clusters. Durante operações normais, as políticas do Ranger precisam ser configuradas no Secundário para garantir que os usuários estejam restritos às operações de Leitura. A arquitetura abaixo explica a aparência de uma configuração Primária Ativa do Hive – Secundária em Espera habilitada para ESP.
Replicação do Metastore do Ranger:
O Metastore do Ranger é usado para armazenar e atender com persistência às políticas do Ranger para controlar a autorização de dados. Recomendamos que você mantenha políticas independentes do Ranger no primário e secundário e mantenha o secundário como uma réplica de leitura.
Se o requisito for manter as políticas do Ranger sincronizadas entre o primário e o secundário, use a Importação/Exportação do Ranger para fazer backup periódico e importar políticas do Ranger do primário para o secundário.
A replicação de políticas do Ranger entre o primário e o secundário pode fazer com que o secundário se torne habilitado para gravação, o que pode levar a gravações involuntárias no secundário, gerando inconsistências de dados.
Próximas etapas
Para saber mais sobre os itens discutidos neste artigo, veja: