Tutorial: Migrar o Servidor de Aplicativos do WebSphere para Máquinas Virtuais do Azure com alta disponibilidade e recuperação de desastre
Este tutorial mostra uma maneira simples e eficaz de implementar alta disponibilidade e recuperação de desastre (HA/DR) para Java usando o Servidor de Aplicativos WebSphere em VMs (Máquinas Virtuais) do Azure. A solução ilustra como obter um RTO (Objetivo de Tempo de Recuperação) baixo e um RPO (Objetivo de Ponto de Recuperação) usando um aplicativo Jakarta EE baseado em banco de dados simples em execução no Servidor de Aplicativos webSphere. HA/DR é um tópico complexo, com muitas soluções possíveis. A melhor solução depende de seus requisitos exclusivos. Para obter outras maneiras de implementar a HA/DR, consulte os recursos no final deste artigo.
Neste tutorial, você aprenderá a:
- Use as melhores práticas otimizadas do Azure para obter alta disponibilidade e recuperação de desastre.
- Configure um grupo de failover do Banco de Dados SQL do Microsoft Azure em regiões associadas.
- Configure o cluster WebSphere primário em VMs do Azure.
- Configure a recuperação de desastre para o cluster usando o Azure Site Recovery.
- Configure um Gerenciador de Tráfego do Azure.
- Teste o failover do primário para o secundário.
O diagrama a seguir ilustra a arquitetura que você cria:

O Gerenciador de Tráfego do Azure verifica a integridade de suas regiões e roteia o tráfego de acordo com a camada de aplicativo. A região primária tem uma implantação completa do cluster WebSphere. Depois que a região primária for protegida por do Azure Site Recovery, você poderá restaurar a região secundária durante o failover. Como resultado, a região primária está atendendo ativamente solicitações de rede dos usuários, enquanto a região secundária é passiva e ativada para receber tráfego somente quando a região primária experimenta uma interrupção de serviço.
O Gerenciador de Tráfego do Azure detecta a integridade do aplicativo implantado no IBM HTTP Server para implementar o roteamento condicional. O RTO de geo-failover da camada de aplicação depende do tempo necessário para desligar o cluster primário, restaurar o cluster secundário, iniciar as VMs e executar o cluster secundário do WebSphere. O RPO depende da política de replicação do Azure Site Recovery e do Banco de Dados SQL do Azure. Essa dependência ocorre porque os dados do cluster são armazenados e replicados no armazenamento local das VMs e os dados do aplicativo são mantidos e replicados no grupo de failover do Banco de Dados SQL do Azure.
O diagrama anterior mostra região primária e região secundária como as duas regiões que compõem a arquitetura de HA/DR. Elas precisam ser regiões associadas do Azure. Para obter mais informações sobre regiões associadas, consulte Replicação entre regiões no Azure. O artigo usa o Leste dos EUA e Oeste dos EUA como as duas regiões, mas elas podem ser regiões emparelhadas que façam sentido para o seu cenário. Para obter a lista de associações de região, consulte a seção Regiões associadas do Azure de Replicação entre regiões do Azure.
A camada de banco de dados consiste em um grupo de failover do Banco de Dados SQL do Azure com um servidor primário e um servidor secundário. O ponto de extremidade do ouvinte de leitura/gravação sempre aponta para o servidor primário e está conectado ao cluster do WebSphere em cada região. Um failover geográfico alterna todos os bancos de dados secundários no grupo para a função primária. Para obter o RPO e o RTO de failover geográfico do Banco de Dados SQL do Azure, consulte Visão geral da continuidade dos negócios com o Banco de Dados SQL do Azure.
Este tutorial foi escrito com o Azure Site Recovery e o serviço banco de dados SQL do Azure porque o tutorial depende dos recursos de HA desses serviços. Outras opções de banco de dados são possíveis, mas você deve considerar os recursos de HA de qualquer banco de dados escolhido.
Pré-requisitos
- Uma assinatura do Azure. Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
- Verifique se a função
Contributorexiste na assinatura. Você pode verificar a atribuição seguindo as etapas em Listar atribuições de função do Azure usando o portal do Azure. - Prepare um computador local com Windows, Linux ou macOS instalados.
- Instalar e configurar Git.
- Instale uma implementação do Java SE, versão 17 ou posterior; por exemplo, o build da Microsoft do OpenJDK.
- Instale maven, versão 3.9.3 ou posterior.
Configurar um grupo de failover do Banco de Dados SQL do Azure em regiões associadas
Nesta seção, você criará um grupo de failover do Banco de Dados SQL do Azure em regiões emparelhadas para uso com seus clusters e aplicativos do WebSphere. Em uma seção posterior, você configurará o WebSphere para armazenar seus dados de sessão nesse banco de dados. Essa prática faz referência ao tópico Criar uma tabela para persistência de sessão.
Primeiro, crie o Banco de Dados SQL do Azure primário seguindo as etapas do portal do Azure em Início Rápido: Criar um banco de dados individual – Banco de Dados SQL do Azure. Siga as etapas até, mas não incluindo, a seção "Limpar recursos". Use as seguintes instruções ao percorrer o artigo e retorne a este artigo depois de criar e configurar o Banco de Dados SQL do Azure:
Quando chegar à seção Criar um único banco de dados, siga as etapas seguintes:
- Na etapa 4 para criar um novo grupo de recursos, salve o valor Nome do grupo de recursos; por exemplo,
myResourceGroup. - Na etapa 5 para o nome do banco de dados, salve o valor Nome do banco de dados; por exemplo,
mySampleDatabase. - Na etapa 6 para criar o servidor, use as seguintes etapas:
- Preencha um nome de servidor exclusivo - por exemplo,
sqlserverprimary-mjg022624. - Em Local, selecione (EUA) Leste dos EUA.
- Em Método de autenticação, selecione Usar autenticação do SQL.
- Salve o valor de Logon do administrador do servidor; por exemplo,
azureuser. - Salve o valor da Senha.
- Preencha um nome de servidor exclusivo - por exemplo,
- Na etapa 8, em Ambiente de carga de trabalho, selecione Desenvolvimento. Examine a descrição e considere outras opções para sua carga de trabalho.
- Na etapa 11, em Redundância de armazenamento de backup, selecione Armazenamento de backup com redundância local. Considere outras opções para seus backups. Para obter mais informações, consulte a seção Redundância de armazenamento de backup de Backups automatizados no Banco de Dados SQL do Azure.
- Na etapa 14, na configuração de Regras de firewall, em Permitir que serviços e recursos do Azure acessem este servidor, selecione Sim.
- Na etapa 4 para criar um novo grupo de recursos, salve o valor Nome do grupo de recursos; por exemplo,
Ao acessar a seção Consultar o banco de dados, siga estas etapas:
Na etapa 3, insira as informações de entrada do administrador do servidor de autenticação SQL para entrar.
Nota
Se a entrada falhar e gerar uma mensagem de erro semelhante a Cliente com endereço IP "xx.xx.xx.xx" não tem permissão para acessar o servidor, selecione IP da lista de permissões xx.xx.xx.xx no servidor <your-sqlserver-name> ao final da mensagem de erro. Aguarde até que as regras de firewall do servidor concluam a atualização e selecione OK novamente.
Depois de executar a consulta de exemplo na etapa 5, desmarque o editor e insira a seguinte consulta e selecione Executar novamente:
CREATE TABLE sessions ( ID VARCHAR(128) NOT NULL, PROPID VARCHAR(128) NOT NULL, APPNAME VARCHAR(128) NOT NULL, LISTENERCNT SMALLINT, LASTACCESS BIGINT, CREATIONTIME BIGINT, MAXINACTIVETIME INT, USERNAME VARCHAR(256), SMALL VARBINARY(MAX), MEDIUM VARCHAR(MAX), LARGE VARBINARY(MAX) );Após uma execução bem-sucedida, você deverá ver a mensagem Consulta bem-sucedida: linhas afetadas: 0.
A tabela de banco de dados
sessionsé usada para armazenar dados de sessão para seu aplicativo WebSphere. Os dados de cluster do WebSphere, incluindo logs de transações, são persistidos no armazenamento local de VMs em que o cluster é implantado.
Em seguida, crie um grupo de failover para o Banco de Dados SQL do Azure seguindo as etapas do portal do Azure mencionadas em Configurar um grupo de failover para o Banco de Dados SQL do Azure. Você só precisa das seguintes seções: Criar grupo de failover e Testar recuperação panejada. Use as seguintes etapas ao percorrer o artigo e retorne a este artigo depois de criar e configurar o grupo de failover do Banco de Dados SQL do Azure:
Na seção Criar grupo de failover, siga estas etapas:
- Na etapa 5 para criar o grupo de failover, insira e salve o nome exclusivo do grupo de failover; por exemplo,
failovergroup-mjg022624. - Na etapa 5 para configurar o servidor, selecione a opção para criar um novo servidor secundário e, em seguida, use as seguintes etapas:
- Insira um nome de servidor exclusivo – por exemplo,
sqlserversecondary-mjg022624. - Insira o mesmo administrador de servidor e senha que o servidor primário.
- Para Localização, selecione (EUA) Oeste dos EUA.
- Certifique-se de que Permitir que os serviços do Azure acessem o servidor está selecionado.
- Insira um nome de servidor exclusivo – por exemplo,
- Na etapa 5 para configurar os Bancos de Dados no grupo, selecione o banco de dados que você criou no servidor primário, por exemplo,
mySampleDatabase.
- Na etapa 5 para criar o grupo de failover, insira e salve o nome exclusivo do grupo de failover; por exemplo,
Depois de concluir todas as etapas na seção Testar recuperação panejada, mantenha a página do grupo de failover aberta e use-a para o teste de failover dos clusters WebSphere posteriormente.
Nota
Este artigo orienta você a criar um banco de dados único do Banco de Dados SQL do Azure com autenticação SQL. Uma prática mais segura é usar a autenticação do Microsoft Entra para o SQL do Azure para autenticar a conexão do servidor de banco de dados. A autenticação SQL é necessária para que o cluster WebSphere se conecte ao banco de dados para persistência de sessão posteriormente. Para obter mais informações, consulte Configuração para persistência de sessão de banco de dados.
Configurar o cluster websphere primário em VMs do Azure
Nesta seção, você cria os clusters primários do WebSphere em VMs do Azure usando a oferta Cluster do IBM WebSphere Application Server em VMs do Azure. O cluster secundário é restaurado do cluster primário durante o failover usando o Azure Site Recovery posteriormente.
Implantar o cluster WebSphere primário
Primeiro, abra a oferta Cluster do IBM WebSphere Application Server em VMs do Azure em seu navegador e selecione Criar. Você deve ver o painel Noções básicas da oferta.
Siga estas etapas para preencher o painel Noções básicas:
- Certifique-se de que o valor mostrado em Assinatura seja o mesmo que tem as funções listadas na seção de pré-requisitos.
- No campo do grupo de recursos
, selecione Criar novo e preencha um valor exclusivo para o grupo de recursos, por exemplo,. - Em Detalhes da instância, em Região, selecione Leste dos EUA.
- Para Implantar com direito existente do WebSphere ou com licença de avaliação?, selecione Avaliação para este tutorial. Também é possível selecionar Autorizado e informar sua credencial IBMid.
- Selecione Li e aceito o Contrato de Licença da IBM.
- Deixe os padrões dos outros campos.
- Selecione Avançar para acessar o painel Configuração do cluster.

Use as seguintes etapas para preencher o painel de configuração do cluster
- Em Senha de administrador da VM, forneça uma senha. Para melhor segurança, considere usar Chave Pública SSH como o tipo de autenticação da VM.
- Em Senha de administrador do WebSphere, forneça uma senha. Salve o nome de usuário e a senha do Administrador do WebSphere.
- Deixe os padrões dos outros campos.
- Selecione Avançar para acessar o painel Load Balancer.

Use as etapas a seguir para preencher o painel do balanceador de carga :
- Em Senha de administrador da VM, forneça uma senha. Para obter uma melhor segurança, considere usar chave pública SSH como autenticação de VM.
- Em Senha de administrador do IBM HTTP Server, forneça uma senha.
- Deixe os padrões dos outros campos.
- Selecione Avançar para acessar o painel Rede.

Você deve ver todos os campos pré-preenchidos com os padrões no painel Rede. Selecione Avançar para acessar o painel Banco de Dados.

As etapas a seguir mostram como preencher o painel Banco de Dados:
- Em Conectar a um banco de dados?, selecione Sim.
- Em Escolher tipo de banco de dados, selecione Microsoft SQL Server.
- Para Nome JNDI, insira jdbc/WebSphereCafeDB.
- Para Cadeia de conexão da fonte de dados (jdbc:sqlserver://<host>:<port>; database=<database>), substitua os espaços reservados pelos valores que você salvou na seção anterior para o grupo de failover do Banco de Dados SQL do Azure; por exemplo,
jdbc:sqlserver://failovergroup-mjg022624.database.windows.net:1433;database=mySampleDatabase. - Em Nome de usuário do banco de dados, insira o nome de entrada do administrador do servidor e o nome do grupo de failover que você salvou na seção anterior; por exemplo,
azureuser@failovergroup-mjg022624.Nota
Tenha cuidado extra para usar o nome de host do servidor de banco de dados correto e o nome de usuário do banco de dados para o grupo de failover, em vez do nome de host do servidor e do nome de usuário do banco de dados primário ou de backup. Ao usar os valores do grupo de failover, você está, na verdade, pedindo que o WebSphere se comunique com o grupo de failover. No entanto, no que diz respeito ao WebSphere, é apenas uma conexão de banco de dados normal.
- Digite a senha de entrada do administrador do servidor que você salvou anteriormente para Senha do Banco de Dados. Insira o mesmo valor para Confirmar senha.
- Mantenha as configurações padrão para os outros campos.
- Selecione Examinar + criar.
- Aguarde até que Execução da validação final... seja concluída com êxito e selecione Criar.

Nota
Este artigo orienta você a se conectar a um Banco de Dados SQL do Azure com autenticação SQL. Uma prática mais segura é usar a autenticação do Microsoft Entra para o SQL do Azure para autenticar a conexão do servidor de banco de dados. A autenticação SQL é necessária para que o cluster WebSphere se conecte ao banco de dados para persistência de sessão posteriormente. Para obter mais informações, consulte Configuração para persistência de sessão de banco de dados.
Depois de alguns instantes, você deverá ver a página Implantação, onde Implantação em andamento é exibido.
Nota
Se você vir algum problema durante a execução da validação final ..., corrija-o e tente novamente.
Dependendo das condições de rede e de outras atividades em sua região selecionada, a implantação pode levar até 25 minutos para ser concluída. Depois disso, você deverá ver o texto Sua implantação está concluída exibida na página de implantação.
Verificar a implantação do cluster
Você implantou um IHS (IBM HTTP Server) e um Dmgr (WebSphere Deployment Manager) no cluster. O IHS atua como balanceador de carga para todos os servidores de aplicativos no cluster. O Dmgr fornece um console Web para a configuração do cluster.
Use as seguintes etapas para verificar se o console do IHS e do Dmgr funciona antes de passar para a próxima etapa:
Retorne à página Implantação e selecione Saídas.
Copie o valor da propriedade ihsConsole. Abra essa URL em uma nova guia do navegador. Observe que não usamos
httpspara o IHS neste exemplo. Você deverá ver uma página de boas-vindas do IHS sem nenhuma mensagem de erro. Se não vir, resolva o problema antes de continuar. Mantenha o console aberto e use-o para verificar a implantação do aplicativo do cluster mais tarde.
Copie e salve o valor da propriedade adminSecuredConsole. Abra-o em uma nova guia do navegador. Aceite o aviso do navegador para o certificado TLS autoassinado. Não utilize em produção um certificado TLS autoassinado.
Você verá a página de login do WebSphere Integrated Solutions Console. Entre no console com o nome de usuário e a senha do administrador do WebSphere que você salvou anteriormente. Se você não conseguir entrar, deverá solucionar o problema antes de continuar. Mantenha o console aberto e use-o para uma configuração adicional do cluster WebSphere mais tarde.

Use as etapas a seguir para obter o nome do endereço IP público do IHS. Use-o quando configurar o Gerenciador de Tráfego do Azure mais tarde.
- Abra o grupo de recursos em que o cluster está implantado, por exemplo, selecione Visão geral para voltar para o painel Visão geral da página de implantação e selecione Ir para o grupo de recursos.
- Na tabela de recursos, localize a coluna Tipo. Selecione-o para classificar por tipo de recurso.
- Localize o recurso Endereço IP público com prefixo
ihs, copie e salve seu nome.
Configurar o cluster
Primeiro, use as seguintes etapas para habilitar a opção Sincronizar alterações com nós para que qualquer configuração possa ser sincronizada automaticamente com todos os servidores de aplicativos:
- Volte para o WebSphere Integrated Solutions Console e conecte-se novamente, se estiver desconectado.
- No painel de navegação, selecione Administração do Sistema>Preferências do Console.
- No painel Preferências do Console, selecione Sincronizar alterações com nós e, em seguida, selecione Aplicar. Você deverá ver a mensagem Suas preferências foram alteradas.
Em seguida, use as seguintes etapas para configurar sessões distribuídas de banco de dados para todos os servidores de aplicativos:
- No painel de navegação, selecione Servidores>Tipos de Servidor>servidores de aplicativos WebSphere.
- No painel servidores de aplicativos
, você deverá ver três servidores de aplicativos listados. Para cada servidor de aplicativos, use as seguintes instruções para configurar as sessões distribuídas do banco de dados: - Na tabela sob o texto Você pode administrar os seguintes recursos, selecione o hiperlink para o servidor de aplicativos, que começa com
MyCluster. - Na seção Configurações do Contêiner, selecione Gerenciamento de sessão.
- Na seção Propriedades Adicionais, selecione Configurações de ambiente distribuído.
- Em Sessões distribuídas, selecione Banco de dados (com suporte somente para contêiner da Web.).
- Selecione banco de dados e siga as etapas seguintes:
- Em Nome JNDI da fonte de dados), insira jdbc/WebSphereCafeDB.
- Em ID de usuário, insira o nome de entrada do administrador do servidor e o nome do grupo de failover que você salvou na seção anterior; por exemplo,
azureuser@failovergroup-mjg022624. - Preencha a senha de entrada de administrador do SQL Server do Azure que você salvou anteriormente em Senha.
- Em Nome do espaço da tabela, insira sessions.
- Selecione Usar esquema de várias linhas.
- Selecione OK. Você acessará novamente o painel Configurações do ambiente distribuído.
- Na seção Propriedades Adicionais, selecione Parâmetros de ajuste personalizados.
- Para Nível de ajuste, selecione Baixo (otimizar para failover).
- Selecione OK.
- Em Mensagens, selecione Salvar. Aguarde até a conclusão.
- Selecione Servidores de aplicativos na barra de navegação estrutural superior. Você voltará ao painel Servidores de aplicativos.
- Na tabela sob o texto Você pode administrar os seguintes recursos, selecione o hiperlink para o servidor de aplicativos, que começa com
- No painel de navegação, selecione Servidores>Clusters>Clusters de Servidores de Aplicativos WebSphere.
- No painel clusters do servidor de aplicativos
WebSphere, você deverá ver o cluster listado. Marque a caixa de seleção ao lado de MyCluster. - Selecione Ripplestart.
- Aguarde até que o cluster seja reiniciado. Você pode selecionar o ícone Status e, se a nova janela não mostrar Iniciado, volte para o console e atualize a página da Web depois de um tempo. Repita a operação até ver Iniciado. Você poderá ver Início Parcial antes de atingir o estado Iniciado
Mantenha o console aberto e use-o para implantação de aplicativo mais tarde.
Implantar um aplicativo de exemplo
Esta seção mostra como implantar e executar um aplicativo CRUD Java/Jakarta EE de exemplo em um cluster WebSphere para teste de failover para recuperação em caso de desastre posteriormente.
Você configurou servidores de aplicativos para usar a fonte jdbc/WebSphereCafeDB de dados para armazenar dados de sessão anteriormente, o que permite failover e balanceamento de carga em um cluster de servidores de aplicativos WebSphere. O aplicativo de exemplo também configura um esquema de persistência para persistir os dados do aplicativo coffee na mesma fonte de dados jdbc/WebSphereCafeDB.
Primeiro, use os seguintes comandos para baixar, compilar e empacotar o exemplo:
git clone https://github.com/Azure-Samples/websphere-cafe
cd websphere-cafe
git checkout 20240326
mvn clean package
Se você vir uma mensagem sobre estar no estado Detached HEAD, essa mensagem pode ser ignorada com segurança.
O pacote deve ser gerado com sucesso e estar localizado em <parent-path-to-your-local-clone>/websphere-cafe/websphere-cafe-application/target/websphere-cafe.ear. Se você não vir o pacote, resolva o problema antes de continuar.
Em seguida, use as seguintes etapas para implantar o aplicativo de exemplo no cluster:
- Volte para o Console de Soluções Integradas do WebSphere e entre novamente se você estiver desconectado.
- No painel de navegação, selecione Aplicativos>Tipos de Aplicativos>Aplicativos empresariais do WebSphere.
- No painel Aplicativos Empresariais, selecione Instalar>Escolher Arquivo. Em seguida, encontre o pacote em <parent-path-to-your-local-clone>/websphere-cafe/websphere-cafe-application/target/websphere-cafe.ear e selecione Abrir. Selecione Próxima>Próxima>Próxima.
- No painel Mapear módulos para servidores, pressione Ctrl e selecione todos os itens listados em Clusters e servidores. Marque a caixa de seleção ao lado de websphere-cafe.war. Escolha Aplicar. Selecione Avançar até que o botão Concluir apareça.
- Selecione Concluir>Salvare aguarde até a conclusão. Selecione OK.
- Selecione o aplicativo
websphere-cafeinstalado e, em seguida, selecione Iniciar. Aguarde até ver mensagens indicando que o aplicativo foi iniciado com êxito. Se você não conseguir ver a mensagem de sucesso, deverá identificar e corrigir o problema antes de continuar.
Agora, use as seguintes etapas para verificar se o aplicativo está em execução conforme o esperado:
Volte para o console do IHS. Acrescente a raiz de contexto
/websphere-cafe/do aplicativo implantado à barra de endereços; por exemplo,http://ihs70685e.eastus.cloudapp.azure.com/websphere-cafe/, e pressione Enter. Você deverá ver a página de boas-vindas do aplicativo de exemplo.Crie um novo café com um nome e um preço - por exemplo, Café 1 com preço US $ 10 - que é mantido na tabela de dados do aplicativo e na tabela de sessão do banco de dados. A interface do usuário que você vê deve ser semelhante à seguinte captura de tela:
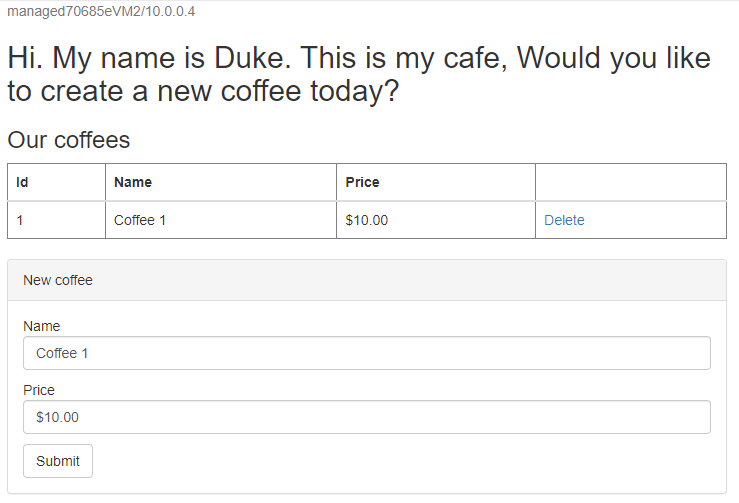

Se sua interface do usuário não for semelhante, solucione o problema antes de continuar.
Configurar a recuperação de desastre para o cluster usando o Azure Site Recovery
Nesta seção, você configurará a recuperação de desastre para VMs do Azure no cluster primário usando o Azure Site Recovery, seguindo as etapas no Tutorial: Configurar a recuperação de desastre para VMs do Azure. Você só precisa das seguintes seções: Criar um cofre dos Serviços de Recuperação e Habilitar replicação. Preste atenção às seguintes etapas durante o artigo e retorne a este artigo depois que o cluster primário estiver protegido:
Na seção Criar um cofre dos Serviços de Recuperação, siga estas etapas:
Na etapa 5 do grupo de recursos , crie um novo grupo de recursos com um nome exclusivo em sua assinatura - por exemplo,
was-cluster-westus-mjg022624.Na etapa 6 de Nome do cofre, dê um nome ao cofre; por exemplo,
recovery-service-vault-westus-mjg022624.Na etapa 7 de Região, selecione Oeste dos EUA.
Antes de selecionar Examinar + criar na etapa 8, selecione Next: Redundancy. No painel Redundância, selecione Redundância geográfica para Redundância de Armazenamento de Backup e Habilitar para Restauração entre Regiões.
Nota
No painel Redundância, selecione Redundância geográfica para Redundância de Armazenamento de Backup e Habilitar para Restauração entre Regiões. Caso contrário, o armazenamento do cluster primário não poderá ser replicado para a região secundária.
Habilite o Site Recovery seguindo as etapas na seção Habilitar o Site Recovery.
Quando você chegar à seção Habilitar replicação, siga estas etapas:
- Na seção Selecione as configurações de origem, siga as etapas a seguir:
Em Região, selecione Leste dos EUA.
Para grupo de recursos, selecione o recurso em que o cluster primário está implantado , por exemplo,
was-cluster-eastus-mjg022624.Nota
Se o grupo de recursos desejado não estiver listado, você poderá selecionar o Oeste dos EUA para a região primeiro e, em seguida, alternar de volta para o Leste dos EUA.
Deixe os padrões dos outros campos. Selecione Avançar.
- Na seção Selecione as VMs, para Máquinas virtuais, selecione as cinco VMs listadas e, em seguida, selecione Avançar.
- Na seção Revisar configurações de replicação, siga estas etapas:
- Para Loca de destino, selecione Oeste dos EUA.
- Para Grupo de recursos de destino, selecione o grupo de recursos em que o cofre de recuperação de serviço é implantado; por exemplo,
was-cluster-westus-mjg022624. - Anote a nova rede virtual de failover e a sub-rede de failover, que são mapeadas a partir das que estão na região primária.
- Mantenha os valores padrão para os outros campos.
- Selecione Avançar.
- Na seção Gerenciar, use as seguintes etapas:
- Em Política de replicação, use a política padrão Política de 24 horas de retenção. Você também pode criar uma nova política para sua empresa.
- Deixe os valores padrão nos outros campos.
- Selecione Avançar.
- Na seção Revisar, siga estas etapas:
Depois de selecionar Habilitar replicação, observe a mensagem Criando recursos do Azure. Não feche esta folha. exibida na parte inferior da página. Não faça nada e aguarde até que o painel seja fechado automaticamente. Você é redirecionado para a página do
Site Recovery. Em Itens protegidos, selecione Itens replicados. Inicialmente, não há itens listados porque a replicação ainda está em andamento. A replicação leva cerca de uma hora para ser concluída. Atualize a página periodicamente até ver que todas as VMs estão no estado Protegido, conforme mostrado na captura de tela de exemplo a seguir:
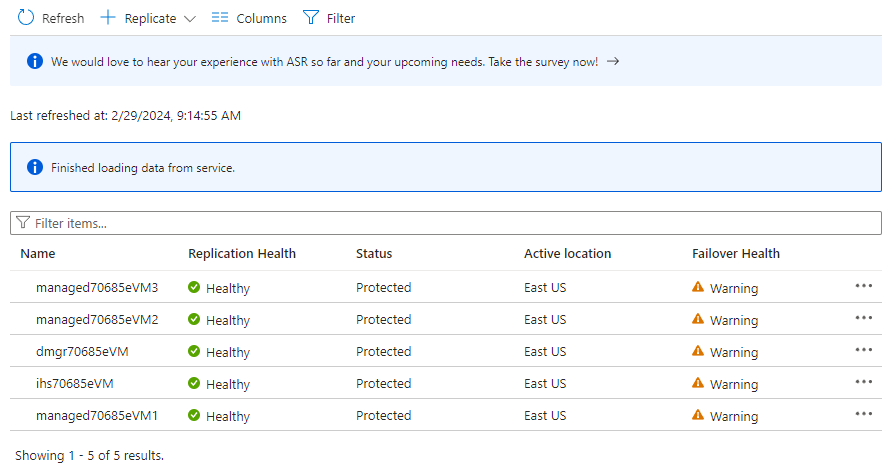
- Na seção Selecione as configurações de origem, siga as etapas a seguir:

Em seguida, crie um plano de recuperação para incluir todos os itens replicados, para todos façam failover juntos. Use as instruções em Criar um plano de recuperação, com as seguintes personalizações:
- Na etapa 2, insira um nome para o plano , por exemplo,
recovery-plan-mjg022624. - Na etapa 3, para de Origem, selecione Leste dos EUA e, para de Destino, selecione Oeste dos EUA.
- Na etapa 4 para Selecionar itens, selecione as cinco VMs protegidas deste tutorial.
Em seguida, você cria um plano de recuperação. Mantenha a página aberta para usá-la para o teste de failover posteriormente.
Configuração de rede adicional para a região secundária
Você também precisa de mais configurações de rede para habilitar e proteger o acesso externo à região secundária em um evento de failover. Use as seguintes etapas para esta configuração:
Crie um endereço IP público para o Dmgr na região secundária seguindo as instruções em Início Rápido: Criar um endereço IP público usando o portal do Azure, com as seguintes personalizações:
- Para Grupo de recursos, selecione o grupo de recursos em que o cofre de recuperação de serviço é implantado; por exemplo,
was-cluster-westus-mjg022624. - Para Região, selecione (EUA) Oeste dos EUA.
- Para Name, insira um valor , por exemplo,
dmgr-public-ip-westus-mjg022624. - Para o rótulo de nome DNS , insira um valor exclusivo — por exemplo,
dmgrmjg022624.
- Para Grupo de recursos, selecione o grupo de recursos em que o cofre de recuperação de serviço é implantado; por exemplo,
Crie outro endereço IP público para IHS na região secundária seguindo o mesmo guia, com as seguintes personalizações:
- Para Grupo de recursos, selecione o grupo de recursos em que o cofre de recuperação de serviço é implantado; por exemplo,
was-cluster-westus-mjg022624. - Para Região, selecione (EUA) Oeste dos EUA.
- Para Name, insira um valor , por exemplo,
ihs-public-ip-westus-mjg022624. Anote- o. - Para o rótulo de nome DNS , insira um valor exclusivo - por exemplo,
ihsmjg022624.
- Para Grupo de recursos, selecione o grupo de recursos em que o cofre de recuperação de serviço é implantado; por exemplo,
Crie um grupo de segurança de rede na região secundária seguindo as instruções na seção Criar um grupo de segurança de rede seção de Criar, alterar ou excluir um grupo de segurança de rede, com as seguintes personalizações:
- Para Grupo de recursos, selecione o grupo de recursos em que o cofre de recuperação de serviço é implantado; por exemplo,
was-cluster-westus-mjg022624. - Para Name, insira um valor , por exemplo,
nsg-westus-mjg022624. - Para Região, selecione Oeste dos EUA.
- Para Grupo de recursos, selecione o grupo de recursos em que o cofre de recuperação de serviço é implantado; por exemplo,
Crie uma regra de segurança de entrada para o grupo de segurança de rede seguindo as instruções na seção Criar uma regra de segurança do mesmo artigo, com as seguintes personalizações:
- Na etapa 2, selecione o grupo de segurança de rede que você criou , por exemplo,
nsg-westus-mjg022624. - Na etapa 3, selecione Regras de segurança de entrada.
- Na etapa 4, personalize as seguintes configurações:
- Para Intervalos de porta de destino, insira 9060,9080,9043,9443,80.
- Para Protocolo, selecione TCP.
- Em Nome, insira ALLOW_HTTP_ACCESS.
- Na etapa 2, selecione o grupo de segurança de rede que você criou , por exemplo,
Associe o grupo de segurança de rede a uma sub-rede conforme as instruções na seção Associar ou dissociar um grupo de segurança de rede de/para uma sub-rede do mesmo artigo, com as seguintes personalizações:
- Na etapa 2, selecione o grupo de segurança de rede que você criou , por exemplo,
nsg-westus-mjg022624. - Selecione Associar para associar o grupo de segurança de rede à sub-rede de failover que você anotou anteriormente.
- Na etapa 2, selecione o grupo de segurança de rede que você criou , por exemplo,
Configurar um Gerenciador de Tráfego do Azure
Nesta seção, você criará um Gerenciador de Tráfego do Azure para distribuir o tráfego para seus aplicativos voltados para o público nas regiões globais do Azure. O ponto de extremidade primário aponta para o endereço IP público do IHS na região primária. O ponto de extremidade secundário aponta para o endereço IP público do IHS na região secundária.
Crie um perfil do Gerenciador de Tráfego do Azure seguindo as instruções em Início Rápido: Criar um perfil do Gerenciador de Tráfego usando o portal do Azure. Você só precisa das seguintes seções: Criar um perfil do Gerenciador de Tráfego e Adicionar pontos de extremidade do Gerenciador de Tráfego. Ignore as seções que estão sendo orientadas para criar recursos do Serviço de Aplicativo. Use as etapas a seguir à medida que passar por essas seções e retorne a este artigo depois de criar e configurar o Gerenciador de Tráfego do Azure.
Na seção Criar um perfil do Gerenciador de Tráfego, na etapa 2, para Criar perfil do Gerenciador de Tráfego, use os seguintes passos:
- Salve o nome de perfil exclusivo do Gerenciador de Tráfego para Nome; por exemplo,
tmprofile-mjg022624. - Em Grupo de recursos, salve o novo nome do grupo de recursos; por exemplo,
myResourceGroupTM1.
- Salve o nome de perfil exclusivo do Gerenciador de Tráfego para Nome; por exemplo,
Quando você chegar à seção Adicionar pontos de extremidade do Gerenciador de Tráfego, execute as seguintes etapas:
- Depois de abrir o perfil do Gerenciador de Tráfego na etapa 2, na página Configuração, use as seguintes etapas:
- Em Vida útil (TTL) do DNS, digite 10.
- Em Configurações do monitor de ponto de extremidade, para Caminho, insira /websphere-cafe/, que é a raiz de contexto do aplicativo de amostra implantado.
- Em Configurações de failover de ponto de extremidade rápido, use os seguintes valores:
- Para Investigação interna, selecione 10.
- Para Número Tolerado de Falhas, insira 3.
- Para Tempo limite da investigação, use 5.
- Selecione Salvar. Aguarde até que ele seja concluído.
- Na etapa 4 para adicionar o ponto de extremidade primário
myPrimaryEndpoint, siga os seguintes passos:- Para Tipo de recurso de destino, selecione Endereço IP público.
- Selecione a lista suspensa Escolher endereço IP público e insira o nome do endereço IP público do IHS na região Leste dos EUA que você salvou anteriormente. Você deve ver uma correspondência de entrada. Selecione-a para Endereço IP público.
- Na etapa 6 para adicionar um failover/ponto de extremidade secundário
myFailoverEndpoint, execute as seguintes etapas:- Para Tipo de recurso de destino, selecione Endereço IP público.
- Selecione a lista suspensa Escolher endereço IP público e insira o nome do endereço IP público do IHS na região Oeste dos EUA que você salvou anteriormente. Você deve ver uma correspondência de entrada. Selecione-a para Endereço IP público.
- Aguarde um pouco. Selecione Atualizar até que o Status do Monitor do ponto de extremidade
myPrimaryEndpointseja Online e o Status do Monitor do ponto de extremidademyFailoverEndpointseja Degradado.
- Depois de abrir o perfil do Gerenciador de Tráfego na etapa 2, na página Configuração, use as seguintes etapas:
Em seguida, use as seguintes etapas para verificar se o aplicativo de exemplo implantado no cluster websphere primário está acessível no perfil do Gerenciador de Tráfego:
Selecione Visão Geral para o perfil do Gerenciador de Tráfego que você criou.
Selecione e copie o nome do DNS (sistema de nomes de domínio) do perfil do Gerenciador de Tráfego e acrescente-o com
/websphere-cafe/, por exemplo,http://tmprofile-mjg022624.trafficmanager.net/websphere-cafe/.Abra o URL em uma nova guia do navegador. Você deve ver o café que você criou anteriormente listado na página.
Crie outro café com um nome e um preço diferentes - por exemplo, Coffee 2 com preço 20 - que é mantido na tabela de dados do aplicativo e na tabela de sessão do banco de dados. A interface do usuário que você vê deve ser semelhante à seguinte captura de tela:
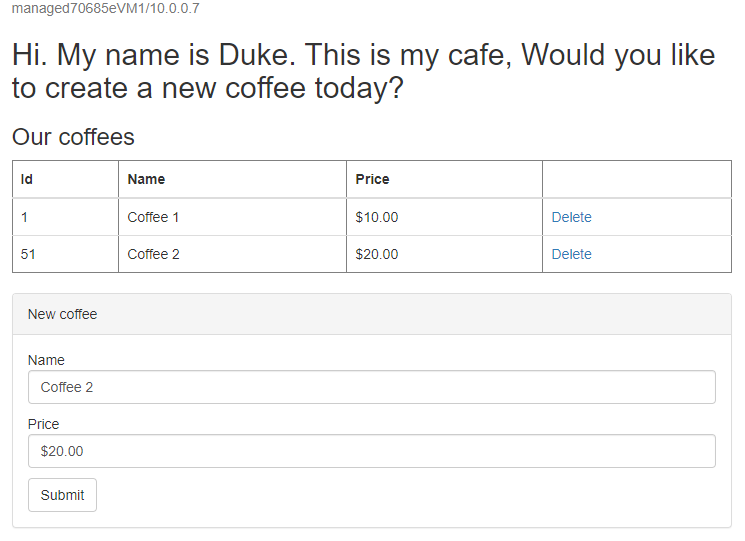

Se sua interface do usuário não for semelhante, solucione o problema antes de continuar. Mantenha o console aberto e use-o para o teste de failover mais tarde.
Agora você configura o perfil do Gerenciador de Tráfego. Mantenha a página aberta e use-a para monitorar a alteração de status do ponto de extremidade em um evento de failover posteriormente.
Testar o failover do primário para o secundário
Para testar o failover, faça o failover manual do servidor do Banco de Dados SQL do Azure e do cluster e, em seguida, faça failback usando o portal do Azure.
Failover para o site secundário
Primeiro, use as seguintes etapas para fazer failover do Banco de Dados SQL do Azure do servidor primário para o servidor secundário:
- Mude para a guia do navegador do grupo de failover do Banco de Dados SQL do Azure; por exemplo,
failovergroup-mjg022624. - Selecione Failover>Sim.
- Aguarde até que ele seja concluído.
Em seguida, use os seguintes passos para realizar o failover do cluster WebSphere conforme o plano de recuperação.
Na caixa de pesquisa na parte superior do portal do Azure, insira Cofres dos Serviços de Recuperação e selecione Cofres dos Serviços de Recuperação nos resultados da pesquisa.
Selecione o nome do cofre dos Serviços de Recuperação; por exemplo,
recovery-service-vault-westus-mjg022624.Em Gerenciar, selecione Planos de Recuperação (Site Recovery). Selecione o plano de recuperação criado – por exemplo,
recovery-plan-mjg022624.Selecione Failover. Selecione Eu entendo o risco. Ignorar teste de failover.. Deixe os valores padrão para outros campos e selecione OK.
Nota
Como opção, você pode executar o Teste de failover e Limpar failover de teste para que tudo funcione conforme o esperado antes de testar o Failover. Para obter mais informações, consulte Tutorial: Realizar um teste de recuperação de desastre para VMs do Azure. Este tutorial testa o Failover diretamente para simplificar o exercício.
Monitore o failover pelas notificações até que ele seja concluído. Leva cerca de 10 minutos para fazer o exercício neste tutorial.
Como opção, você pode exibir detalhes do trabalho de failover selecionando o evento de failover; por exemplo, Failover de 'recovery-plan-mjg022624' está em andamento... - a partir das notificações.
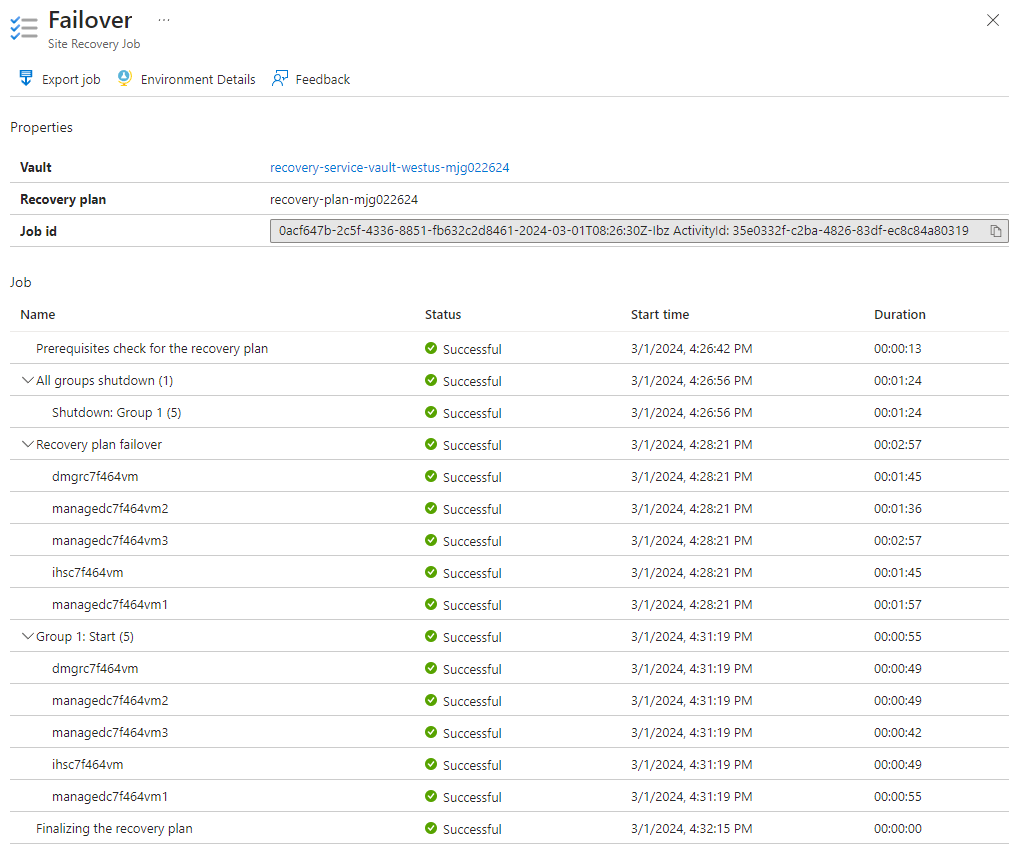




Em seguida, use as seguintes etapas para habilitar o acesso externo ao Console de Soluções Integradas do WebSphere e ao aplicativo de exemplo na região secundária:
- Na caixa de pesquisa no topo do portal do Azure, digite grupos de recursos e depois selecione grupos de recursos nos resultados da pesquisa.
- Selecione o nome do grupo de recursos para sua região secundária , por exemplo,
was-cluster-westus-mjg022624. Classifique os itens por Tipo na página Grupo de Recursos. - Selecione Adaptador de Rede com o prefixo
dmgr. Selecione Configurações de IP>ipconfig1. Selecione Associar endereço IP público. Para endereço IP público, selecione o endereço IP público prefixado comdmgr. Esse endereço é aquele que você criou anteriormente. Neste artigo, o endereço é nomeadodmgr-public-ip-westus-mjg022624. Selecione Salvare aguarde até que o processo seja concluído. - Volte para o grupo de recursos e selecione o Adaptador de Rede com o prefixo
ihs. Selecione Configurações de IP>ipconfig1. Selecione para associar o endereço IP público. Para endereço IP público, selecione o endereço IP público prefixado comihs. Esse endereço é aquele que você criou anteriormente. Neste artigo, o endereço é nomeadoihs-public-ip-westus-mjg022624. Selecione Salvare aguarde até que isso seja concluído.
Agora, use as seguintes etapas para verificar se o failover funciona conforme o esperado:
Localize o rótulo de nome DNS para o endereço IP público do Dmgr que você criou anteriormente. Abra a URL do Dmgr WebSphere Integrated Solutions Console em uma nova guia do navegador. Use
https. Por exemplo,https://dmgrmjg022624.westus.cloudapp.azure.com:9043/ibm/console. Atualize a página até ver a página de entrada de boas-vindas.Entre no console com o nome de usuário e a senha do administrador do WebSphere salvos anteriormente e use as seguintes etapas:
No painel de navegação, selecione Servidores>Todos os servidores. No painel de servidores do Middleware, você deverá ver quatro servidores listados, incluindo três servidores de aplicativos WebSphere que fazem parte do cluster do WebSphere
MyClustere 1 servidor Web que é um IHS. Atualize a página até que veja que todos os servidores foram iniciados.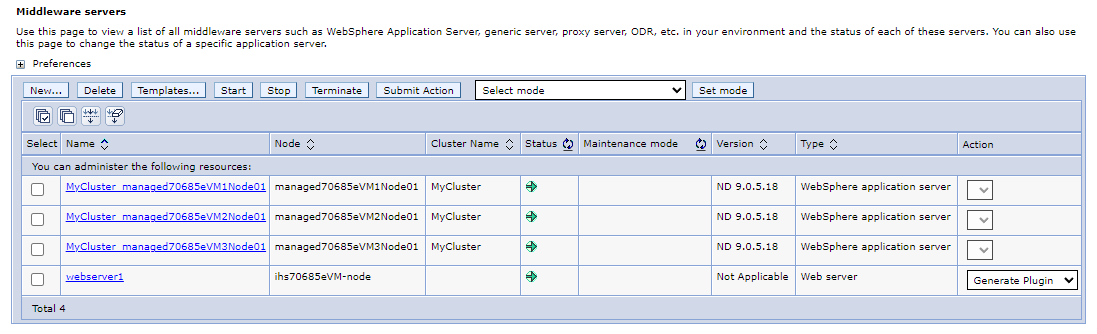
No painel de navegação, selecione Aplicativos>Tipos de Aplicativos>Aplicativos empresariais do WebSphere. No painel Aplicativos Empresariais, você deve ver 1 aplicativo -
websphere-cafe- listado e iniciado.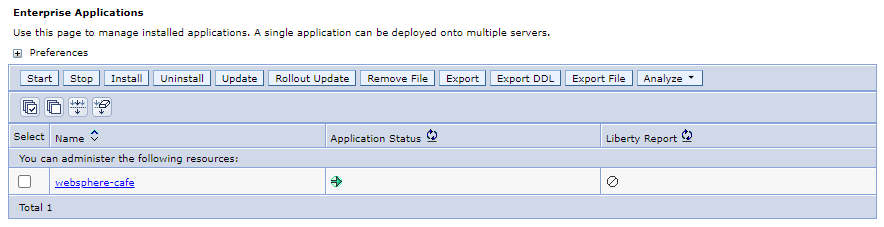
Para validar a configuração do cluster na região secundária, siga as etapas na seção Configurar o cluster. Você verá que as configurações para Sincronizar alterações com nós e Sessões distribuídas são replicadas para o cluster de failover, conforme mostrado nas seguintes capturas de tela:
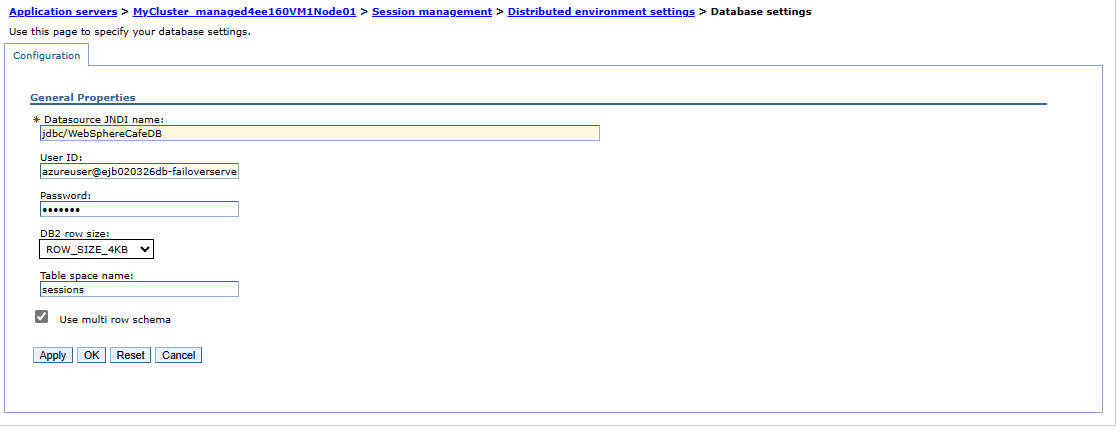
Localize o rótulo de nome DNS para o endereço IP público do IHS que você criou anteriormente. Abra o URL do console IHS anexado com o contexto raiz
/websphere-cafe/. Observe que você não deve usarhttps. Este exemplo não usahttpspara IHS , por exemplo,http://ihsmjg022624.westus.cloudapp.azure.com/websphere-cafe/. Você verá dois cafés que criou listados anteriormente na página.Mude para a guia do navegador do perfil do Gerenciador de Tráfego e atualize a página até ver que o valor de Status do Monitor do ponto de extremidade
myFailoverEndpointse torna Online e o valor de Status do Monitor do ponto de extremidademyPrimaryEndpointse torna Degradado.Mude para a guia do navegador com o nome DNS do perfil do Gerenciador de Tráfego; por exemplo,
http://tmprofile-mjg022624.trafficmanager.net/websphere-cafe/. Atualize a página e você deverá ver os mesmos dados persistidos na tabela de dados do aplicativo e na tabela de sessão exibida. A interface do usuário que você vê deve ser semelhante à seguinte captura de tela: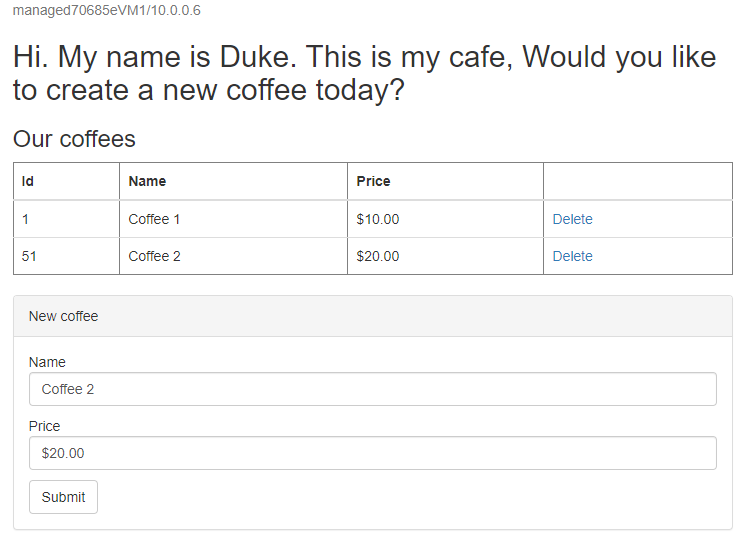
Se você não observar esse comportamento, pode ser porque o Gerenciador de Tráfego está demorando para atualizar o DNS para apontar para o site de failover. O problema também pode ser que o navegador tenha armazenado em cache o resultado da resolução de nomes DNS que aponta para o site com falha. Aguarde um pouco e atualize a página novamente.





Confirmar o failover
Execute as etapas a seguir para confirmar o failover depois de obter o resultado do failover:
Na caixa de pesquisa na parte superior do portal do Azure, insira Cofres dos Serviços de Recuperação e selecione Cofres dos Serviços de Recuperação nos resultados da pesquisa.
Selecione o nome do cofre dos Serviços de Recuperação; por exemplo,
recovery-service-vault-westus-mjg022624.Em Gerenciar, selecione Planos de Recuperação (Site Recovery). Selecione o plano de recuperação criado – por exemplo,
recovery-plan-mjg022624.Selecione Confirmar>OK.
Monitore a confirmação pelas notificações até que ela seja concluída.
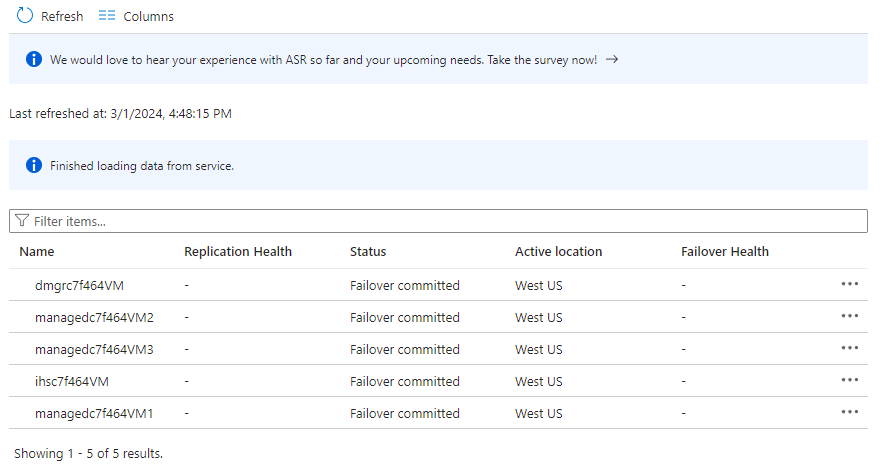
Selecione Itens no plano de recuperação. Você deverá ver 5 itens listados como Failover confirmado.



Desabilitar a replicação
Use as seguintes etapas para desabilitar a replicação de itens no plano de recuperação e, em seguida, excluir o plano de recuperação:
Para cada item em Itens no plano de recuperação, selecione o botão de reticências (...) e, em seguida, selecione Desabilitar Replicação.
Se for solicitado que você forneça um motivo para desabilitar a proteção para essa máquina virtual, selecione uma que você prefira, por exemplo, terminei de migrar meu aplicativo. Selecione OK.
Repita a etapa 1 até desabilitar a replicação para todos os itens.
Monitore o processo em notificações até que ele seja concluído.
Selecione Visão geral>Excluir. Selecione Sim para confirmar a exclusão.

Preparar-se para failback: proteja novamente o site de failover
A região secundária agora é o site de failover e está ativa. Você deve protegê-lo novamente em sua região primária.
Primeiro, use as etapas a seguir para limpar os recursos que não são usados e que o serviço Azure Site Recovery vai replicar em sua região primária mais tarde. Você não pode simplesmente excluir o grupo de recursos, pois a recuperação do site restaura recursos no grupo de recursos existente.
- Na caixa de pesquisa na parte superior do portal do Azure, insira Grupos de Recursos e selecione Grupos de Recursos nos resultados da pesquisa.
- Selecione o nome do grupo de recursos para sua região primária , por exemplo,
was-cluster-eastus-mjg022624. Classifique os itens por Tipo na página Grupo de Recursos. - Use as seguintes etapas para excluir as máquinas virtuais:
- Selecione o filtro Tipo e, em seguida, selecione Máquina virtual na lista suspensa Valor.
- Escolha Aplicar.
- Selecione todas as máquinas virtuais, selecione Excluire, em seguida, insira excluir para confirmar a exclusão.
- Selecione Excluir.
- Monitore o processo em notificações até que ele seja concluído.
- Use as seguintes etapas para excluir os discos:
- Selecione o filtro Tipo e, em seguida, selecione Discos na lista suspensa Valor.
- Escolha Aplicar.
- Selecione todos os discos, selecione Excluire, em seguida, insira excluir para confirmar a exclusão.
- Selecione Excluir.
- Monitore o processo em notificações e aguarde até que ele seja concluído.
- Use as etapas a seguir para excluir os pontos de extremidade:
- Selecione o filtro Tipo, selecione Ponto de extremidade privado na lista suspensa Valor.
- Selecione e Aplicar.
- Selecione todos os pontos de extremidade privados, selecione Excluir e digite delete para confirmar a exclusão.
- Selecione Excluir.
- Monitore o processo em notificações até que ele seja concluído. Ignore esta etapa se o tipo Ponto de extremidade privado não estiver listado.
- Use as seguintes etapas para excluir as interfaces de rede:
- Selecione o filtro Tipo e > selecione Adaptador de Rede na lista suspensa Valor.
- Selecione . Aplicar.
- Selecione todas as interfaces de rede, selecione Excluire, em seguida, insira excluir para confirmar a exclusão.
- Selecione Excluir. Monitore o processo em notificações até que ele seja concluído.
- Use as seguintes etapas para excluir contas de armazenamento:
- Selecione o filtro Tipo e > selecione Conta de armazenamento na lista suspensa Valor.
- Escolha Aplicar.
- Selecione todas as contas de armazenamento, selecione Excluire, em seguida, insira excluir para confirmar a exclusão.
- Selecione Excluir. Monitore o processo em notificações até que ele seja concluído.
Em seguida, use as mesmas etapas na seção Configurar a recuperação de desastre para o cluster usando o Azure Site Recovery para a região primária, exceto pelas seguintes diferenças:
- Na seção Criar um cofre dos Serviços de Recuperação, siga estas etapas:
- Selecione o grupo de recursos implantado na região primária , por exemplo,
was-cluster-eastus-mjg022624. - Insira um nome diferente para o cofre de serviço; por exemplo,
recovery-service-vault-eastus-mjg022624. - Para a Região , selecione Leste dos EUA .
- Selecione o grupo de recursos implantado na região primária , por exemplo,
- Em Habilitar replicação, siga estas etapas:
- Em Região, em Origem, selecione Oeste dos EUA.
- Em Configurações de replicação, siga estas etapas:
- Em Grupo de recursos de destino, selecione o grupo de recursos existente implantado na região primária; por exemplo,
was-cluster-eastus-mjg022624. - Em Rede virtual de failover, selecione a rede virtual existente na região primária.
- Em Grupo de recursos de destino, selecione o grupo de recursos existente implantado na região primária; por exemplo,
- Para Criar um plano de recuperação, para Origem, selecione Oeste dos EUA, e para Destino, selecione Leste dos EUA.
- Ignore as etapas na seção Configuração de rede adicional para a região secundária porque você criou e configurou esses recursos anteriormente.
Nota
Você pode notar que o Azure Site Recovery dá suporte à nova proteção de VM quando a VM de destino existe. Para obter mais informações, consulte a seção Proteger novamente a VM do tutorial : fazer failover de VMs do Azure para uma região secundária. Devido à abordagem que estamos adotando para o WebSphere, esse recurso não funciona. O motivo é que as únicas alterações entre o disco de origem e o disco de destino são sincronizadas para o cluster WebSphere, com base no resultado da verificação. Para substituir a funcionalidade do recurso de reproteção da VM, este tutorial inicia uma nova replicação do site secundário para o site primário após o failover. Os discos inteiros são copiados da região que sofreu failover para a região primária. Para obter mais informações, consulte a seção O que acontece durante a nova proteção? de Nova proteção de máquinas virtuais do Azure com failover para a região primária.
Fazer failback para o primário primário
Siga as mesmas etapas na seção Failover para o site secundário para fazer failback para o site primário, incluindo o servidor de banco de dados e o cluster, exceto pelas seguintes diferenças:
- Selecione o cofre do serviço de recuperação implantado na região primária; por exemplo,
recovery-service-vault-eastus-mjg022624. - Selecione o grupo de recursos implantado na região primária , por exemplo,
was-cluster-eastus-mjg022624. - Depois de habilitar o acesso externo ao Console de Soluções Integradas do WebSphere e ao aplicativo de exemplo na região primária, reveja as guias do navegador para o Console de Soluções Integradas do WebSphere e o aplicativo de exemplo para o cluster primário que você abriu anteriormente. Verifique se eles funcionam conforme o esperado. Dependendo de quanto tempo levou para o failback, talvez você não veja os dados da sessão exibidos na seção Novo café da interface do usuário do aplicativo de exemplo, caso ele tenha expirado mais de uma hora antes.
- Na seção Confirmar o failover, selecione o cofre dos Serviços de Recuperação implantado na região primária; por exemplo,
recovery-service-vault-eastus-mjg022624. - No perfil do Gerenciador de Tráfego, você verá que o ponto de extremidade
myPrimaryEndpointse torna Online e o ponto de extremidademyFailoverEndpointse torna Degradado. - Na seção Preparar-se para failback: proteja novamente o site de failover, siga estas etapas:
- A região primária é o site de failover e está ativa, portanto, você deve protegê-la novamente na região secundária.
- Limpe o recurso implantado em sua região secundária; por exemplo, recursos implantados no
was-cluster-westus-mjg022624. - Use as mesmas etapas da seção Configurar a recuperação de desastre para o cluster usando o Azure Site Recovery para proteger a região primária a partir da região secundária, exceto pelas seguintes alterações:
- Ignore as etapas na seção Criar um cofre dos Serviços de Recuperação, porque você criou um anteriormente; por exemplo,
recovery-service-vault-westus-mjg022624. - Em Habilitar replicação>Configurações de replicação>Rede virtual de failover, selecione a rede virtual existente na região secundária.
- Ignore as etapas na seção Configurações adicionais de rede para a região secundária porque você criou e configurou esses recursos anteriormente.
- Ignore as etapas na seção Criar um cofre dos Serviços de Recuperação, porque você criou um anteriormente; por exemplo,
Limpar recursos
Se você não quiser continuar a usar os clusters do WebSphere e outros componentes, use as seguintes etapas para excluir os grupos de recursos para limpar os recursos usados neste tutorial:
- Insira o nome do grupo de recursos dos servidores do Banco de Dados SQL do Azure - por exemplo,
myResourceGroup- na caixa de pesquisa na parte superior do portal do Azure e selecione o grupo de recursos correspondente nos resultados da pesquisa. - Selecione Excluir grupo de recursos.
- Em Inserir nome do grupo de recursos para confirmar a exclusão, insira o nome do grupo de recursos.
- Selecione Excluir.
- Repita as etapas 1 a 4 para o grupo de recursos do Gerenciador de Tráfego , por exemplo,
myResourceGroupTM1. - Na caixa de pesquisa na parte superior do portal do Azure, insira Cofres dos Serviços de Recuperação e selecione Cofres dos Serviços de Recuperação nos resultados da pesquisa.
- Selecione o nome do cofre dos Serviços de Recuperação; por exemplo,
recovery-service-vault-westus-mjg022624. - Em Gerenciar, selecione Planos de Recuperação (Site Recovery). Selecione o plano de recuperação criado – por exemplo,
recovery-plan-mjg022624. - Use as mesmas etapas na seção Desabilitar a replicação para remover bloqueios em itens replicados.
- Repita as etapas 1 a 4 para o grupo de recursos do cluster WebSphere primário – por exemplo,
was-cluster-westus-mjg022624. - Repita as etapas 1 a 4 para o grupo de recursos do cluster WebSphere secundário, por exemplo,
was-cluster-eastus-mjg022624.
Próximas etapas
Neste tutorial, você configura uma solução de HA/DR que consiste em uma camada de infraestrutura de aplicativo ativo-passivo com uma camada de banco de dados ativo-passivo e na qual ambas as camadas abrangem dois sites geograficamente diferentes. No primeiro site, a camada de infraestrutura do aplicativo e a camada de banco de dados estão ativas. No segundo site, o domínio secundário é restaurado com o serviço Azure Site Recovery e o banco de dados secundário está em espera.
Continue explorando as seguintes referências para obter mais opções para criar soluções de HA/DR e executar o WebSphere no Azure: