Tutorial: Migrar o servidor de aplicativos do JBoss EAP para Máquinas Virtuais do Azure com alta disponibilidade e recuperação de desastre
Este tutorial mostra uma maneira simples e eficaz de implementar alta disponibilidade e recuperação de desastre (HA/DR) para Java usando o JBoss EAP em VMs (Máquinas Virtuais) do Azure. A solução ilustra como alcançar um Objetivo de Tempo de Recuperação (RTO) e um Objetivo de Ponto de Recuperação (RPO) baixos usando um aplicativo Jakarta EE simples orientado a banco de dados em execução no servidor de aplicativos do JBoss EAP. HA/DR é um tópico complexo, com muitas soluções possíveis. A melhor solução dependerá das suas necessidades específicas. Para conhecer outras maneiras de implementar HA/DR, consulte os recursos ao final deste artigo.
Neste tutorial, você aprenderá a:
- Configure o cluster do JBoss EAP em VMs do Azure.
- Use as práticas recomendadas otimizadas do Azure para entender a alta disponibilidade e recuperação de desastre.
- Configure um grupo de failover do Microsoft Azure SQL Database em regiões emparelhadas.
- Configure a recuperação de desastre para o cluster usando o Azure Site Recovery.
- Configure um Gerenciador de Tráfego do Azure.
- Teste o failover do primário para o secundário.
O diagrama a seguir ilustra a arquitetura que você cria:

O Gerenciador de Tráfego do Azure verifica a integridade de suas regiões e roteia o tráfego de acordo com a camada de aplicativo. A região primária tem uma implantação completa do cluster do JBoss EAP. Assim que a região primária for protegida pelo Azure Site Recovery, você poderá restaurar a região secundária durante o failover. Como resultado, a região primária está processando ativamente as solicitações de rede dos usuários, enquanto a região secundária é passiva e ativada para receber tráfego somente quando a região primária sofre uma interrupção do serviço.
O Gerenciador de Tráfego do Azure detecta a integridade do aplicativo implantado no cluster do JBoss EAP para implementar o roteamento condicional. O RTO de failover geográfico da camada de aplicativo depende do tempo para desligar o cluster primário, restaurar o cluster secundário, iniciar as VMs e executar o cluster secundário do JBoss EAP. O RPO depende da política de replicação do Azure Site Recovery e do banco de dados SQL do Azure porque os dados do cluster são armazenados e replicados no armazenamento local das VMs e os dados do aplicativo são persistentes e replicados no grupo de failover do banco de dados SQL do Azure.
O diagrama anterior mostra a região Primária e a região Secundária como as duas regiões que compõem a arquitetura HA/DR. Elas precisam ser regiões associadas do Azure. Para obter mais informações sobre regiões associadas, consulte Replicação entre regiões no Azure. O artigo usa Leste dos EUA e Oeste dos EUA como as duas regiões, mas elas podem ser regiões associadas que façam sentido para o seu cenário. Para obter a lista de associações de região, consulte a seção Regiões associadas do Azure de Replicação entre regiões do Azure.
A camada do banco de dados consiste em um grupo de failover do Banco de Dados SQL do Azure com um servidor primário e um servidor secundário. O ponto de extremidade do ouvinte de leitura/gravação sempre aponta para o servidor primário e está conectado ao cluster do JBoss EAP em cada região. Um failover geográfico alterna todos os bancos de dados secundários no grupo para a função primária. Para RPO de failover geográfico e RTO do Banco de Dados SQL do Azure, consulte Visão geral da continuidade dos negócios.
Este tutorial foi escrito com o Azure Site Recovery e o serviço de Banco de Dados SQL do Azure porque depende dos recursos de HA desses serviços. Outras opções de banco de dados são possíveis, mas os recursos de HA de qualquer banco de dados escolhido devem ser considerados.
Pré-requisitos
- Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
- Verifique se a função
Contributorexiste na assinatura. Você pode verificar a atribuição pelas etapas em Listar atribuições de função do Azure usando o portal do Azure. - Prepare uma máquina local com Windows, GNU/Linux ou macOS instalado.
- Instale e configure o Git.
- Instale uma implementação do Java SE, versão 17 ou posterior; por exemplo, o build da Microsoft do OpenJDK.
- Instale o Maven, versão 3.9.3 ou posterior.
Configurar um grupo de failover do Banco de Dados SQL do Azure em regiões associadas
Nesta seção, você cria um grupo de failover do banco de dados SQL do Azure em regiões associadas para uso com seus clusters e aplicativo JBoss EAP.
Primeiro, crie o Banco de Dados primário do SQL do Azure seguindo as etapas do portal do Azure em Início Rápido: criar um banco de dados individual - Banco de Dados SQL do Azure. Siga as etapas até, mas não incluindo, a seção Limpar recursos. Use as instruções a seguir ao ler o artigo e, em seguida, retorne a este artigo depois de criar e configurar o Banco de Dados SQL do Azure.
Quando chegar à seção Crie um único banco de dados, use as seguintes etapas:
Na etapa 4 de criação de um novo grupo de recursos, anote o valor do nome do grupo de recursos no campo - por exemplo,
sqlserver-rg-gzh032124.Na etapa 5 para o nome do banco de dados, anote o valor de Nome do banco de dados; por exemplo,
mySampleDatabase.Na etapa 6 para criar o servidor, sigas estas etapas:
- Preencha um nome de servidor exclusivo; por exemplo,
sqlserverprimary-gzh032124. - Para a localização , selecione (EUA) Leste dos EUA.
- Em Método de autenticação, selecione Usar autenticação do SQL.
- Anote o valor de Logon de administrador do servidor; por exemplo,
azureuser. - Anote o valor da senha .
- Preencha um nome de servidor exclusivo; por exemplo,
Na etapa 8, em Ambiente de carga de trabalho, selecione Desenvolvimento. Leia a descrição e considere outras opções para sua carga de trabalho.
Na etapa 10, para Camada de computação, selecione Provisionada.
Na etapa 11, para Redundância de armazenamento de backup, selecione Armazenamento de backup com redundância local. Considere outras opções para seus backups. Para obter mais informações, consulte a seção Redundância de armazenamento de backup de Backups automatizados no Banco de Dados SQL do Azure.
Na etapa 14, na configuração das regras de firewall , para Permitir que serviços e recursos do Azure acessem este servidor, selecione Sim.
Quando você chegar à seção Consultar o banco de dados, use as seguintes etapas em vez das etapas do outro artigo:
Na etapa 3, insira as informações de entrada do administrador do servidor de autenticação SQL para entrar.
Observação
Se o login falhar com uma mensagem de erro semelhante a Cliente com o endereço IP 'xx.xx.xx.xx' não tem permissão para acessar o servidor, selecione Permitir IP xx.xx.xx.xx no servidor <seu-nome-sqlserver> ao final da mensagem de erro. Aguarde até que as regras de firewall do servidor concluam a atualização e selecione OK novamente.
Depois de executar a consulta de exemplo na etapa 5, limpe o editor e insira a seguinte consulta, depois selecione Executar novamente:
CREATE TABLE ispn_entry_sessions_javaee_cafe_war ( id VARCHAR(255) PRIMARY KEY, -- ID Column to hold cache entry ids data VARBINARY(MAX), -- Data Column to hold cache entry data timestamp BIGINT, -- Timestamp Column to hold cache entry timestamps segment INT );Após uma execução bem-sucedida, você verá a mensagem Consulta bem-sucedida: Linhas afetadas: 0.
A tabela
ispn_entry_sessions_javaee_cafe_wardo banco de dados é usada para armazenar dados de sessão para o seu cluster do JBoss EAP.
Em seguida, crie um grupo de failover do Banco de Dados SQL do Azure seguindo as etapas do portal do Azure em Configurar um grupo de failover para o Banco de Dados SQL do Azure. Você só precisa das seguintes seções: Criar grupo de failover e Testar recuperação panejada. Use as etapas a seguir ao ler o artigo e, em seguida, retorne a este artigo depois de criar e configurar o grupo de failover do Banco de Dados SQL do Azure:
Quando você chegar à seção Criar grupo de failover, use as seguintes etapas:
Na etapa 5 para criar o grupo de failover, insira e anote o nome exclusivo do grupo de failover; por exemplo,
failovergroup-gzh032124.Na etapa 5 para configurar o servidor, selecione a opção para criar um novo servidor secundário e siga estas etapas:
- Insira um nome de servidor exclusivo; por exemplo,
sqlserversecondary-gzh032124. - Digite o mesmo administrador e senha do servidor primário.
- Para Localização, selecione (EUA) Oeste dos EUA 2.
- Certifique-se de que Permitir que os serviços do Azure acessem o servidor esteja selecionado.
- Insira um nome de servidor exclusivo; por exemplo,
Na etapa 5 para configurar os Bancos de dados dentro do grupo, selecione o banco de dados que você criou no servidor primário; por exemplo,
mySampleDatabase.
Depois de concluir todas as etapas na seção Testar recuperação planejada, mantenha a página do grupo de failover aberta e use-a para o teste de failover dos clusters JBoss EAP posteriormente.
Observação
Este artigo orienta você a criar um banco de dados único do Banco de Dados SQL do Azure com autenticação SQL para simplificar, pois a configuração de HA/DR em que este artigo se concentra já é muito complexa. Uma prática mais segura é usar a autenticação do Microsoft Entra para o SQL do Azure para autenticar a conexão do servidor de banco de dados.
Configurar o cluster do JBoss EAP primário em VMs do Azure
Nesta seção, você criará clusters principais do JBoss EAP em VMs do Azure usando a oferta JBoss EAP Cluster em VMs. O cluster secundário é restaurado do cluster primário durante o failover usando o Azure Site Recovery posteriormente.
Implantar o cluster do JBoss EAP primário
Primeiro, abra a oferta do Cluster JBoss EAP em VMs no navegador e selecione Criar. Você deve ver o painel Noções básicas da oferta.
Siga estas etapas para preencher o painel Noções básicas:
- Certifique-se de que o valor mostrado em Assinatura seja o mesmo que tem as funções listadas na seção de pré-requisitos.
- Você deve implantar a oferta em um grupo de recursos vazio. No campo do grupo de recursos
, selecione Criar novo e preencha um valor exclusivo para o grupo de recursos - por exemplo,. - Em Detalhes da instância, em Região, selecione Leste dos EUA.
- Forneça uma senha em Senha e use o mesmo valor para Confirmar senha.
- Para Número de máquinas virtuais a serem criadas, entrada 3.
- Deixe os outros campos com seus valores padrão.
- Selecione Avançar para ir para o painel de Configurações do JBoss EAP.

Use as seguintes etapas para preencher o painel Configurações do JBoss EAP:
- Preencha a senha do JBoss EAP para Senha do JBoss EAP. Use o mesmo valor para Confirmar a senha. Anote o valor para uso posterior.
- Deixe os outros campos com seus valores padrão.
- Selecione Avançar para acessar o painel Azure Application Gateway.

Use as seguintes etapas para preencher o painel Azure Application Gateway:
- Em Conectar-se ao Gateway de Aplicativo do Azure?, selecione Sim.
- Deixe os outros campos com seus valores padrão.
- Selecione Avançar para acessar o painel Rede.

Você deve ver todos os campos pré-preenchidos com os valores padrão no painel Rede. Selecione Avançar para acessar o painel Banco de Dados.

Siga estas etapas para preencher o painel Banco de dados:
- Em Conectar a um banco de dados?, selecione Sim.
- Para Escolher o tipo de banco de dados, selecione Microsoft SQL Server.
- Em Nome JNDI, insira java:jboss/datasources/JavaEECafeDB.
- Para Cadeia de conexão da fonte de dados (jdbc:sqlserver://<host>:<port>; database=<database>), substitua os espaços reservados pelos valores que você anotou na seção anterior para o grupo de failover do banco de dados SQL do Azure; por exemplo,
jdbc:sqlserver://failovergroup-gzh032124.database.windows.net:1433;database=mySampleDatabase. - Em Nome de usuário do banco de dados, insira o nome de entrada do administrador do servidor e o nome do grupo de failover que você anotou na seção anterior; por exemplo,
azureuser@failovergroup-gzh032124. - Insira a senha de login do administrador do servidor que você anotou antes para Senha do banco de dados. Insira o mesmo valor para Confirmar senha.
- Selecione Examinar + criar.
- Aguarde até que Execução da validação final... seja concluída com êxito e selecione Criar.

Depois de alguns instantes, você deverá ver a página Implantação, onde Implantação em andamento é exibido.
Observação
Se você encontrar problemas durante a Execução da validação final..., corrija-o e tente novamente.
Dependendo das condições da rede e de outras atividades na região selecionada, a implantação pode levar até 35 minutos para ser concluída. Depois disso, você deverá ver o texto Sua implantação está concluída exibido na página de implantação.
Verificar a funcionalidade da implantação
Use as etapas a seguir para verificar a funcionalidade da implantação de um cluster JBoss EAP em VMs do Azure a partir do console de gerenciamento da Plataforma de Aplicativos Empresariais do Red Hat JBoss :
Na página Sua implantação está concluída, selecione Saídas.
Selecione o ícone de cópia ao lado de adminConsole.
Cole a URL em um navegador da Web conectado à Internet e pressione Enter. Você verá a tela familiar de entrada do console de gerenciamento da Red Hat JBoss Enterprise Application Platform, conforme mostrado na captura de tela a seguir.
Preencha jbossadmin para o Nome de usuário administrador do JBoss EAP Forneça o valor da senha do JBoss EAP que você especificou antes para Senha e selecione Entrar.
Você deve ver a página de boas-vindas familiar do console de gerenciamento da Red Hat JBoss Enterprise Application Platform , conforme mostrado na captura de tela a seguir.
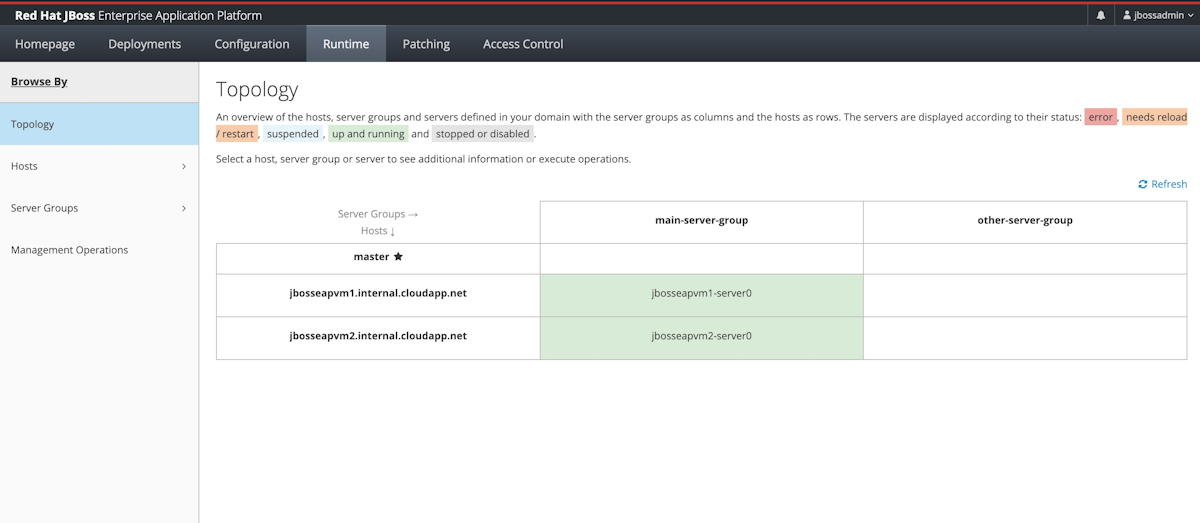
Selecione a guia Runtime. No painel de navegação, selecione Topologia. Você deverá ver que o cluster contém um mestre do controlador de domínio e dois nós de trabalho, conforme mostrado na seguinte captura de tela:




Deixe o console de gerenciamento aberto. Use-o para implantar um aplicativo de exemplo no cluster JBoss EAP na próxima seção.
Configurar o cluster
Use as seguintes etapas para configurar sessões distribuídas de banco de dados para todos os servidores de aplicativos:
Selecione Configuração no painel de navegação. Em seguida, selecione Perfis>ha>Infinspan>Web.
Na coluna Cache, selecione Adicionar cache distribuído.
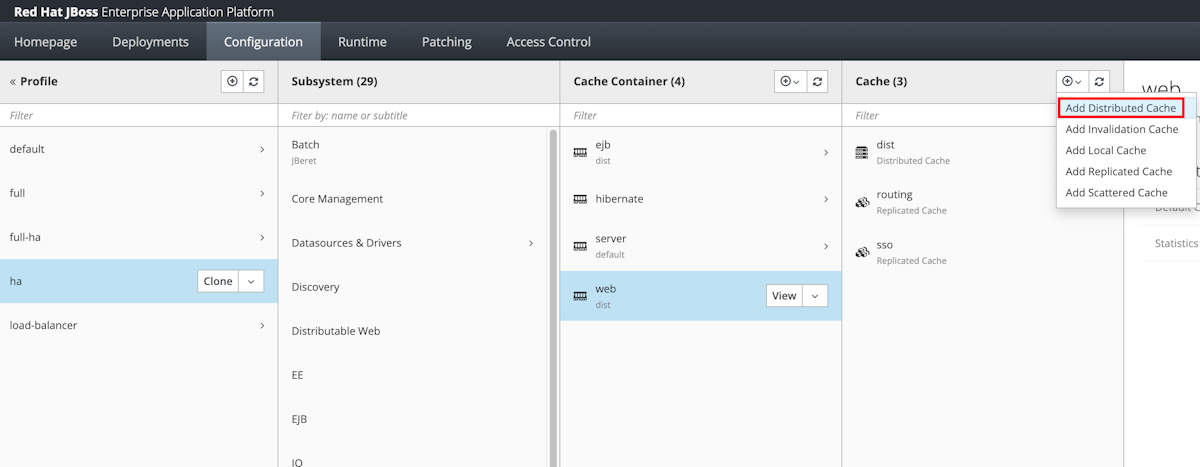
Em Nome, insira azure-session e selecione Adicionar.
Você deverá ver a mensagem sessão do cache distribuído do Azure adicionada com êxito. Se você não vir esta mensagem, verifique a central de notificações. Você deve ver esta mensagem antes de prosseguir.
Depois que o cache for adicionado, selecione azure-session>Exibir.
Selecione Repositório.
Altere o menu suspenso para exibir JDBC e depois selecione Adicionar.
Para a fonte de dados , selecione dataSource-mssqlserver e, em seguida, selecione Adicionar.
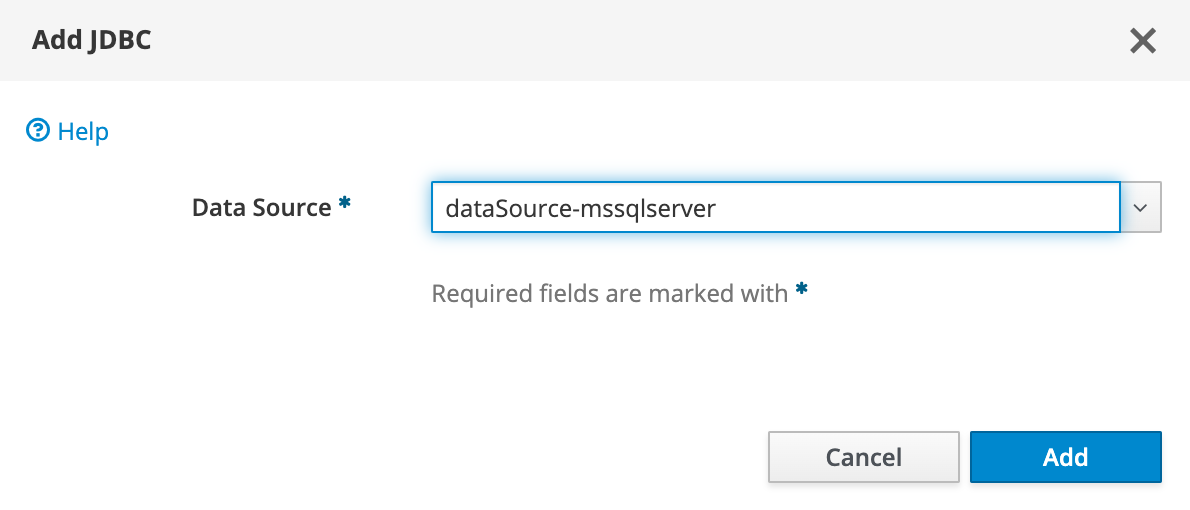
Você deverá ver a mensagem JDBC adicionado com êxito. Se você não vir esta mensagem, verifique a central de notificações. Você deve ver esta mensagem antes de prosseguir.
Na página Armazenar: JDBC, selecione Editar. Defina os seguintes valores de propriedade:
- Defina Dialeto como SQL_SERVER.
- Defina Passivation como DESLIGADO.
- Defina Limpar como DESLIGADO.
- Defina Compartilhado como LIGADO.
Selecione Salvar.
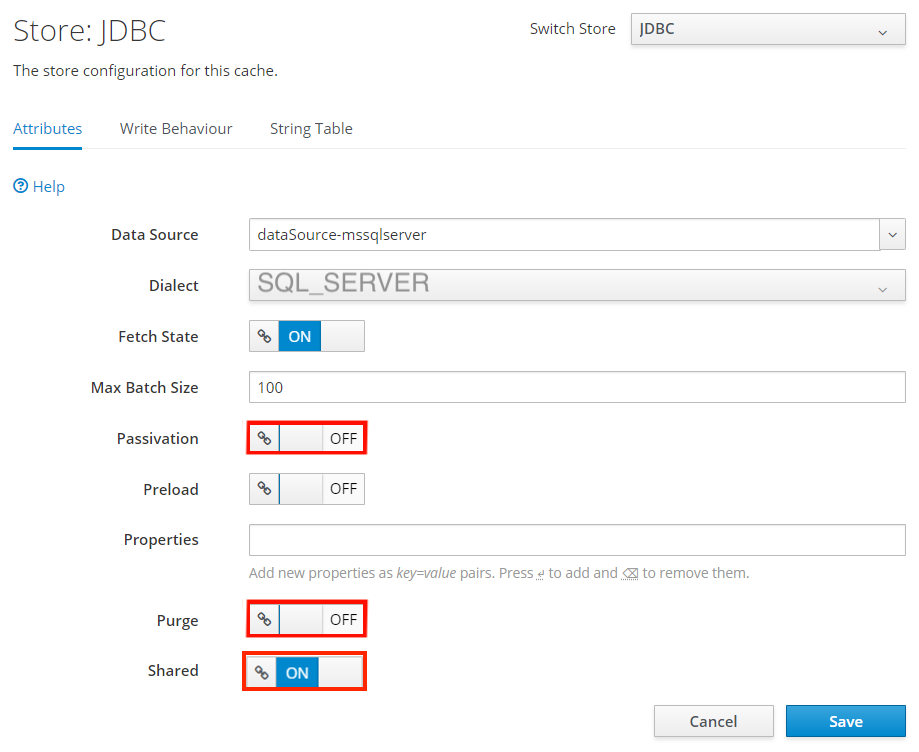
Você deverá ver a mensagem JDBC modificado com êxito. Se você não vir esta mensagem, verifique a central de notificações. Você deve ver esta mensagem antes de prosseguir.
Edite a tabela de cadeias de caracteres selecionando Tabela de cadeira de caracteres>Editar. Preencha os valores a seguir e selecione Salvar:
- Defina Prefixo como ispn_entry_sessions.
- Defina Coluna ID / Nome da coluna ID como id.
- Defina Coluna ID / Tipo de coluna ID como VARCHAR(255).
- Defina Coluna de dados / Nome da coluna de dados como dados.
- Defina Coluna de dados / Tipo de coluna de dados como VARBINARY(MAX).
- Defina Coluna carimbo de data/hora / Nome da coluna carimbo de data/hora como carimbo de data/hora.
- Defina Coluna de carimbo de data/hora / Tipo de coluna de carimbo de data/hora como BIGINT.

Qualquer erro de digitação aqui pode causar falha em todo o sistema. Inspecione cuidadosamente os valores preenchidos antes de prosseguir.
Selecione Salvar.
Você deverá ver a mensagem Tabela de cadeia de caracteres modificada com êxito. Se você não vir esta mensagem, verifique a central de notificações. Você deve ver esta mensagem antes de prosseguir.
Selecione Configuração no painel de navegação superior. Em seguida, selecione Perfis>ha>Web distribuível>Exibir.
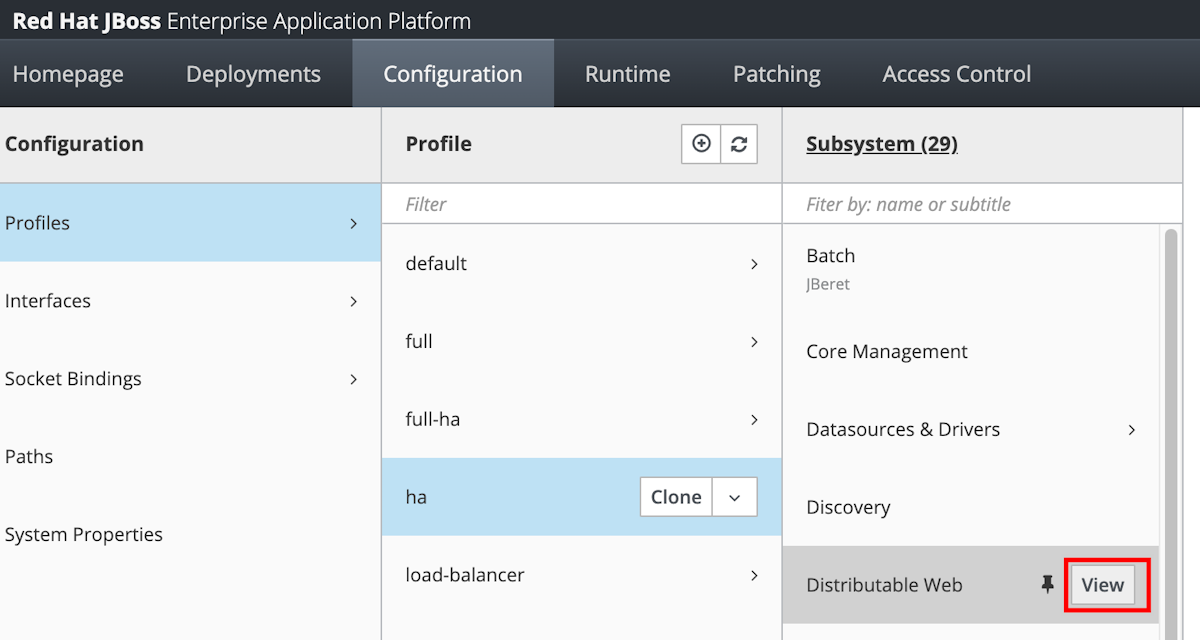
Selecione Infinspan SSO>padrão>Editar.
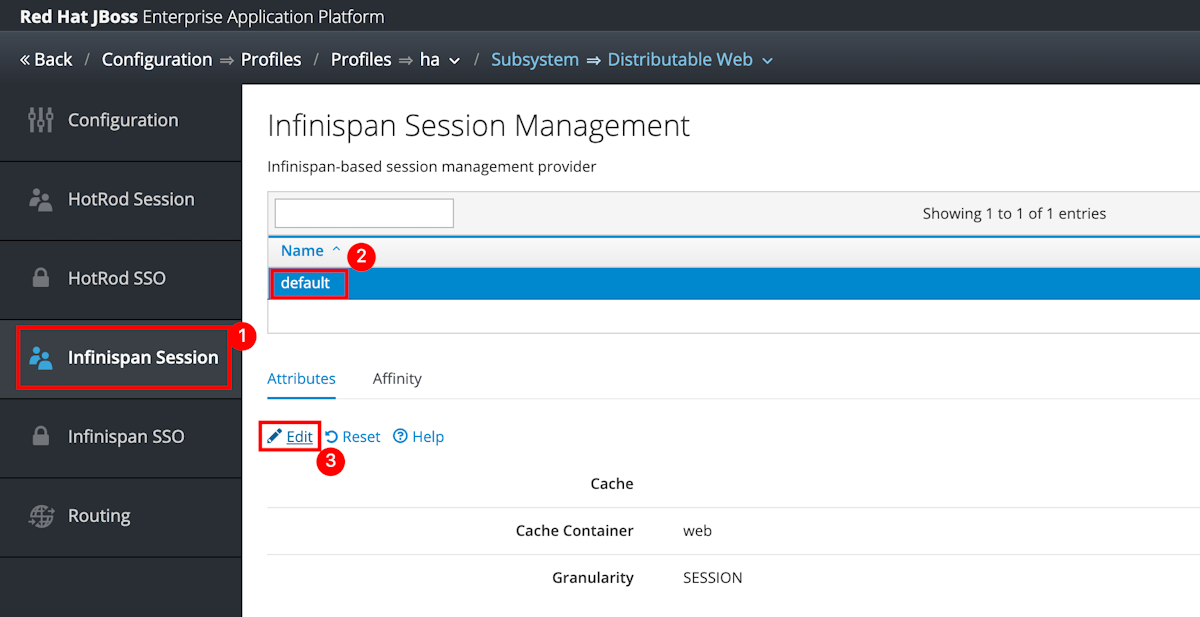
Defina o valor de Cache como azure-session e, em seguida, selecione Salvar.
Você deverá ver a mensagem Padrão de gerenciamento de logon único do Infinispan modificado com êxito. Se você não vir esta mensagem, verifique a central de notificações. Você deve ver esta mensagem antes de prosseguir.
Use a topologia para recarregar ou reiniciar os servidores afetados.
Selecione Runtime no painel de navegação e selecione Topologia.
Para cada linha na coluna do grupo de servidores principal, selecione o servidor e selecione Recarregar.
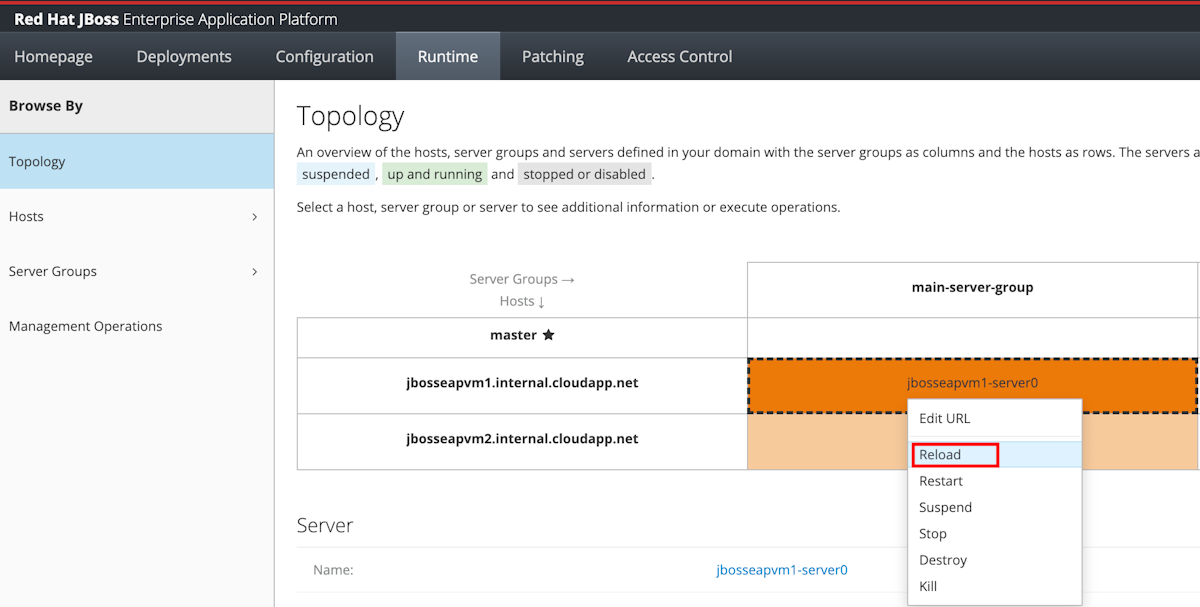
As células recarregadas agora devem mostrar a cor verde.







Implantar o aplicativo no cluster JBoss EAP
Use as etapas a seguir para implantar o aplicativo de amostra JavaEE Cafe no cluster Red Hat JBoss EAP:
Use as etapas a seguir para criar a amostra do Java EE Cafe. Estas etapas pressupõem que você tenha um ambiente local com o Git e o Maven instalados.
Use o seguinte comando para clonar o código-fonte do GitHub e confira a marca correspondente a esta versão do artigo:
git clone https://github.com/Azure/rhel-jboss-templates.git --branch 20240904 --single-branchSe você vir uma mensagem de erro com o texto
You are in 'detached HEAD' state, poderá ignorá-la com segurança.Use o seguinte comando para compilar o código fonte:
mvn clean install --file rhel-jboss-templates/eap-coffee-app/pom.xmlEsse comando cria o arquivo rhel-jboss-templates/eap-coffee-app/target/javaee-cafe.war. Você carrega este arquivo na próxima etapa.
Use as etapas a seguir no console de gerenciamento do Red Hat JBoss Enterprise Application Platform para carregar o javaee-cafe.war no Repositório de Conteúdo .
Na guia Implantações do console de gerenciamento do Red Hat JBoss EAP, selecione Repositório de Conteúdo no painel de navegação.
Selecione Adicionar e, em seguida, selecione Carregar Conteúdo.
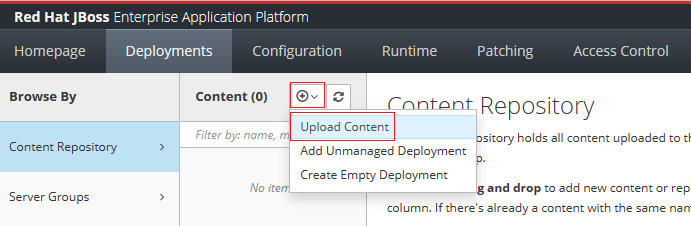
Use o seletor de arquivos do navegador para selecionar o arquivo javaee-cafe.war.
Selecione Avançar.
Aceite os padrões na próxima tela e selecione Concluir.
Selecione Exibir conteúdo.
Use as seguintes etapas para implantar um aplicativo no
main-server-group:No Repositório de Conteúdo , selecione javaee-cafe.war.
Abra o menu suspenso e selecione Implantar.
Selecione main-server-group como o grupo de servidores para implantar javaee-cafe.war.
Selecione Implantar para iniciar a implantação. Você deverá ver uma página semelhante à seguinte captura de tela:



Agora você concluiu a implantação do aplicativo JavaEE. Use as seguintes etapas para acessar o aplicativo e validar todas as configurações:
Na caixa de pesquisa na parte superior do portal do Azure, insira Grupos de Recursos e selecione Grupos de Recursos nos resultados da pesquisa.
Selecione o nome do grupo de recursos; por exemplo,
jboss-eap-cluster-eastus-gzh032124.Selecione o recurso de Gateway de Aplicativo no grupo de recursos.
Copie o endereço IP público do front-end do painel Visão geral.
Crie uma URL com o endereço IP e o caminho; por exemplo,
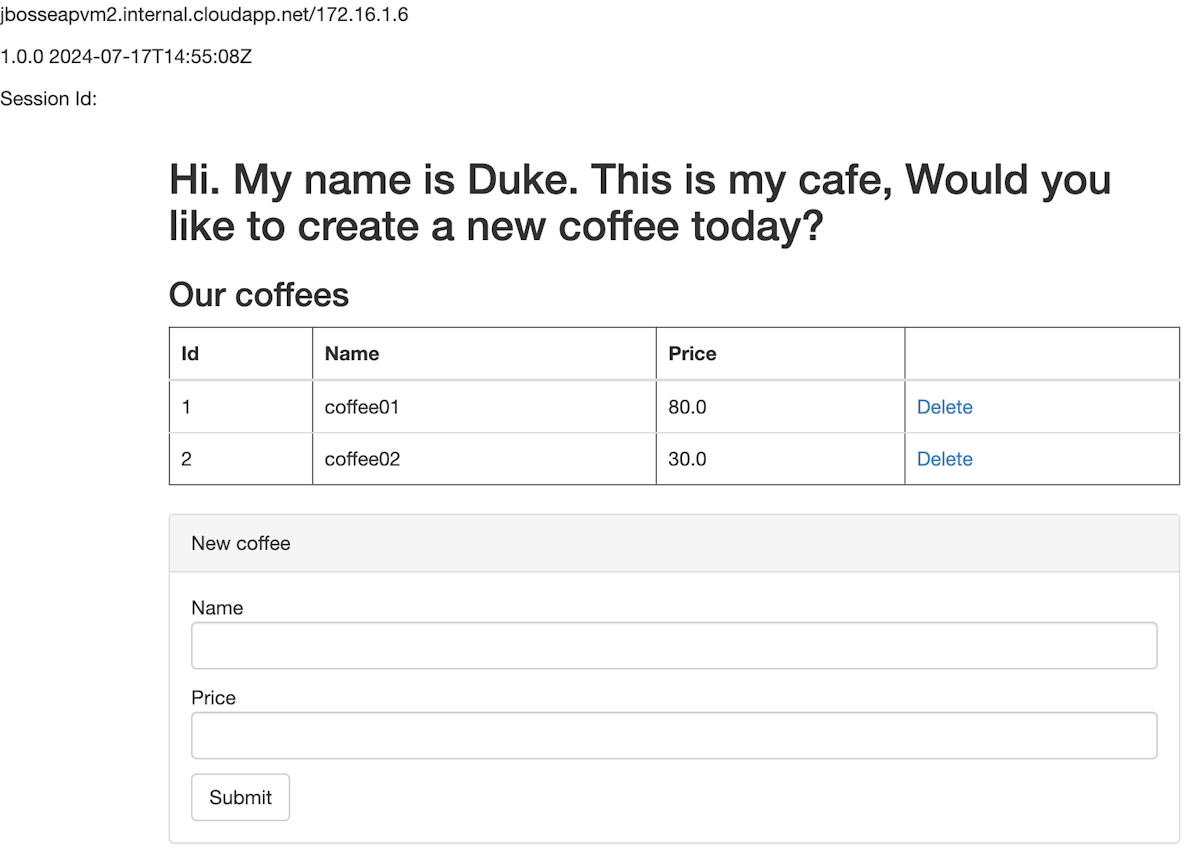
http://40.88.26.22/javaee-cafe.Cole a URL na barra de navegação do navegador da Web e pressione Enter. Você deverá ver a página inicial do aplicativo JavaEE Cafe.
Crie dois cafés com nomes e preços diferentes. Você deverá ver uma página semelhante à captura de tela a seguir:

Configurar o cluster do JBoss EAP secundário em VMs do Azure
Implantar o cluster do JBoss EAP secundário
Siga as etapas em Implantar o cluster JBoss EAP primário para implantar o cluster JBoss EAP secundário na região emparelhada. Este exemplo usa Oeste dos EUA 2. Quando você usa a oferta, o cluster do JBoss EAP secundário é configurado para que você possa usar o Azure Site Recovery para restaurar a topologia.
Abra a oferta do Cluster JBoss EAP em VMs no navegador e selecione Criar. Você deve ver o painel Noções básicas da oferta.
Siga estas etapas para preencher o painel Noções básicas:
No campo do grupo de recursos
, selecione Criar novo e preencha um valor exclusivo para o grupo de recursos - por exemplo,. Em Detalhes da instância, em Região, selecione Oeste dos EUA 2.
Deixe os outros iguais ao cluster primário.
Para o painel de configurações do JBoss EAP, mantenha-o igual ao cluster primário.
No painel Gateway de Aplicativo do Azure, mantenha-o igual ao cluster primário.
Para o painel Rede, abra a configuração de Rede virtual e insira o espaço de endereço, que é o mesmo valor do cluster primário.

No painel Banco de dados, execute as seguintes etapas:
- Mantenha-o igual ao cluster primário.
- Selecione Examinar + criar.
- Aguarde até que Execução da validação final... seja concluída com êxito e selecione Criar.
Depois de alguns instantes, você deverá ver a página Implantação, onde Implantação em andamento é exibido.
Limpar recursos não utilizados na região secundária
Use as seguintes etapas para limpar recursos no grupo de recursos denominado jboss-eap-cluster-westus-gzh032124 que não são usados e serão replicados pelo serviço do Azure Site Recovery na região primária posteriormente. Essa abordagem pode parecer um desperdício, mas garante que o grupo de recursos secundário tenha a configuração idêntica ao primário. Soluções de nível de produção usariam mais tecnologias de infraestrutura como código para garantir configuração idêntica, mas esse tema está além do escopo deste artigo.
Na caixa de pesquisa na parte superior do portal do Azure, insira Grupos de Recursos e, em seguida, selecione Grupos de Recursos nos resultados da pesquisa.
Selecione o nome do grupo de recursos para sua região secundária recém-criada.
Ao lado da área de texto rotulada Filtro para qualquer campo..., selecione o X para remover todos os filtros.
Selecione Adicionar filtro. Defina Filtro como Tipo. Defina Operador como Igual a.
Selecione o menu suspenso ao lado do campo Valor.
Alterne a caixa de seleção Selecionar tudo até que nenhum valor esteja selecionado.
Verifique se todos os seguintes tipos estão selecionados:
- Máquina virtual
- Disco
- Ponto de extremidade privado
- Interface de rede
- Conta de armazenamento
Selecione o menu suspenso ao lado do campo Valor para fechar o menu suspenso. Você deve ver 5 tipos de recursos como o valor de Valor.
Escolha Aplicar.
Marque a caixa de seleção ao lado do rótulo Nome na parte superior da lista filtrada.
Selecione Excluir.
Insira excluir para confirmar a exclusão, selecione Excluir. Monitore o processo pelas notificações até que ele seja concluído.
Configurar a recuperação de desastre para o cluster usando o Azure Site Recovery
Nesta seção, você configura a recuperação de desastre para VMs do Azure no cluster primário usando o Azure Site Recovery, de acordo com as etapas em Tutorial: Configurar a recuperação de desastre para VMs do Azure. Você só precisa das seguintes seções: Criar um cofre dos Serviços de Recuperação e Habilitar replicação. Preste atenção às etapas a seguir ao longo do artigo e, em seguida, volte a este artigo depois que o cluster primário estiver protegido:
Quando você chegar à seção Criar um cofre de Serviços de recuperação, siga estas etapas:
Na etapa 5 de Grupo de recursos, crie um grupo de recursos com um nome exclusivo em sua assinatura; por exemplo,
recovery-service-westus-gzh032124.Na etapa 6 de Nome do cofre, dê um nome ao cofre; por exemplo,
recovery-service-vault-westus-gzh032124.Na etapa 7 de Região, selecione Oeste dos EUA 2.
Antes de selecionar Examinar + criar na etapa 8, selecione Avançar: redundância. No painel Redundância, selecione Redundância geográfica como Redundância de armazenamento de backup e Habilitar como Restauração entre regiões.
Observação
Selecione Redundância geográfica para Redundância de armazenamento de backup e Habilitar para Restauração entre regiões no painel Redundância. Caso contrário, o armazenamento do cluster primário não poderá ser replicado para a região secundária.
Habilite o Site Recovery de acordo com as etapas na seção Habilitar o Site Recovery.
Quando você chegar à seção Habilitar replicação, siga estas etapas:
Siga as etapas abaixo para selecionar as configurações de origem:
Em Região, selecione Leste dos EUA.
Em Grupo de recursos, selecione o recurso em que o cluster primário está implantado; por exemplo,
jboss-eap-cluster-eastus-gzh032124.Observação
Se o grupo de recursos desejado não estiver listado, você poderá selecionar Oeste dos EUA 2 para Região e, em seguida, voltar para Leste dos EUA.
Deixe os outros campos com seus valores padrão
Selecione o VMs. Em Máquinas virtuais, selecione todas as VMs listadas; por exemplo, há 3 VMs implantadas no cluster primário para este tutorial.
Use as seguintes etapas ao analisar as configurações de replicação:
Em Local de destino, selecione Oeste dos EUA 2.
Para Grupo de recursos de destino, selecione o grupo de recursos em que o cofre de recuperação de serviço é implantado; por exemplo,
jboss-eap-cluster-westus-gzh032124.Se o grupo de recursos esperado não for exibido, selecione outra região e retorne para Oeste dos EUA 2.
Anote a nova rede virtual de failover e a sub-rede de failover, que são mapeadas a partir das que estão na região primária.
Deixe os valores padrão para os outros campos.
Para Gerenciar use as seguintes etapas:
Em Política de replicação, use a política padrão Política de 24 horas de retenção. Você também pode criar uma política para sua empresa.
Deixe os valores padrão para os outros campos.
Para Revisar use as seguintes etapas:
Depois de selecionar Habilitar replicação, observe a mensagem Criando recursos do Azure. Não feche esta folha. exibida na parte inferior da página. Basta aguardar até que o painel feche automaticamente. Você irá para a página Site Recovery.
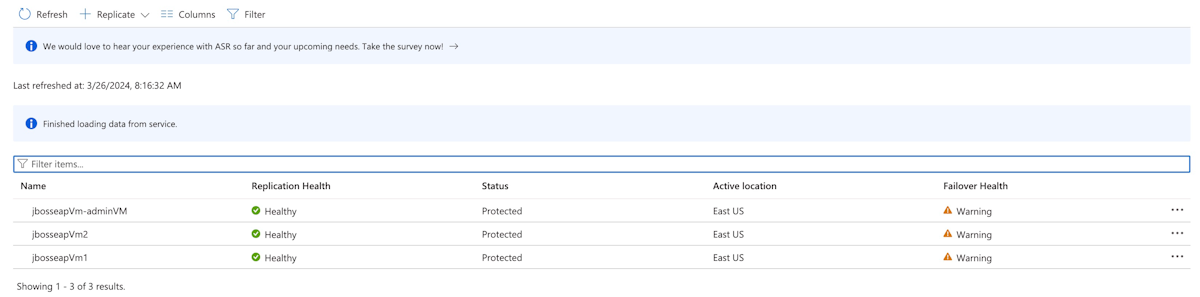
Em Itens Protegidos, selecione Itens Replicados. Inicialmente, não há itens listados porque a replicação ainda está em andamento. A replicação leva tempo para ser concluída (cerca de 1 hora no caso deste tutorial). Atualize a página periodicamente até ver que todas as VMs estão Protegidas, conforme mostrado na captura de tela a seguir:

Em seguida, crie um plano de recuperação para incluir todos os itens replicados, para todos façam failover juntos. Siga as instruções em Criar um plano de recuperação, com a seguinte personalização:
- Na etapa 2, insira um nome para o plano; por exemplo,
recovery-plan-gzh032124. - Na etapa 3, selecione Leste dos EUA para Origem e Oeste dos EUA 2 para Destino.
- Na etapa 4 para Selecionar itens, selecione todos os itens protegidos, por exemplo, as 3 VMs protegidas para este tutorial.
Mantenha a página aberta para utilizar mais tarde ao testar o failover.
Configurar um Gerenciador de Tráfego do Azure
Nesta seção, você cria um Gerenciador de Tráfego do Azure para distribuir o tráfego para seus aplicativos voltados para o público nas regiões do Azure. O ponto de extremidade primário aponta para o endereço IP público do Gateway de Aplicativo na região primária e o ponto de extremidade secundário aponta para o endereço IP público do Gateway de Aplicativo na região secundária.
Crie um perfil do Gerenciador de Tráfego do Azure seguindo as instruções em Início Rápido: Criar um perfil do Gerenciador de Tráfego usando o portal do Azure. Você só precisa das seguintes seções: Criar um perfil do Gerenciador de Tráfego e Adicionar pontos de extremidade do Gerenciador de Tráfego. Siga estas etapas ao percorrer essas seções e, em seguida, retorne a este artigo depois de criar e configurar o Gerenciador de Tráfego do Azure.
Quando chegar à seção Criar um perfil do Gerenciador de Tráfego, na etapa 2 Criar um perfil do Gerenciador de Tráfego, use as seguintes etapas:
- Anote o nome de perfil exclusivo do Gerenciador de tráfego em Nome - por exemplo,
tm-profile-gzh032124. - Em Grupo de recursos, anote o novo nome do grupo de recursos - por exemplo,
myResourceGroupTM1.
- Anote o nome de perfil exclusivo do Gerenciador de tráfego em Nome - por exemplo,
Quando você chegar à seção Adicionar pontos de extremidade do Gerenciador de Tráfego, execute as seguintes etapas:
Depois de abrir o perfil do Gerenciador de Tráfego na etapa 2, na página Configuração, execute as seguintes etapas:
Em Vida útil (TTL) do DNS, digite 10.
Em Configurações de failover de ponto de extremidade rápido, use os seguintes valores:
- Para Investigação interna, selecione 10.
- Em Número tolerado de falhas, digite 3.
- Para Tempo limite de investigação, 5.
Selecione Salvar. Aguarde a conclusão.
Na etapa 4 para adicionar o ponto de extremidade primário
myPrimaryEndpoint, execute as seguintes etapas:Para Tipo de recurso de destino, selecione Endereço IP público.
Selecione o menu suspenso Escolher endereço IP público e insira o nome do endereço IP público do Gateway de Aplicativo na região Leste dos EUA. Você deve ver uma correspondência de entrada. Selecione-a para Endereço IP público.
Na etapa 6 para adicionar um ponto de extremidade secundário de failover
myFailoverEndpoint, execute as seguintes etapas:Para Tipo de recurso de destino, selecione Endereço IP público.
Selecione o menu suspenso Escolher endereço IP público e insira o nome do endereço IP público do Gateway de Aplicativo na região Oeste dos EUA 2. Você deve ver uma correspondência de entrada. Selecione-a para Endereço IP público.
Aguarde. Selecione Atualizar até que o Status do Monitor do ponto de extremidade
myPrimaryEndpointseja Online e o Status do Monitor do ponto de extremidademyFailoverEndpointseja Degradado.
Em seguida, use as seguintes etapas para verificar se o aplicativo de exemplo implantado no cluster do JBoss EAP primário pode ser acessado no perfil do Gerenciador de Tráfego:
Selecione Visão geral do perfil do Gerenciador de Tráfego que você criou.
Verifique e copie o nome DNS do perfil do Gerenciador de Tráfego. Acrescente /javaee-cafe/ a ele. Por exemplo,
http://tm-profile-gzh032124.trafficmanager.net/javaee-cafe/.Abra o URL em uma nova guia do navegador. Verifique se o café que você criou antes está listado na página.
Se sua interface do usuário não for semelhante, solucione e resolva o problema antes de continuar. Mantenha o console aberto e use-o para o teste de failover mais tarde.
Agora você pode configurar o perfil do Gerenciador de Tráfego. Mantenha a página aberta para que possa usá-la posteriormente para monitorar a alteração de status do endpoint em um evento de failover.
Testar o failover do primário para o secundário
As etapas nesta seção testam o failover fazendo failover manualmente em seu servidor e cluster do banco de dados SQL do Azure do primário para o secundário e, em seguida, usando novamente o portal do Azure.
Failover para o site secundário
Primeiro, siga as próximas etapas para fazer failover do Banco de Dados SQL do Azure do servidor primário para o servidor secundário:
- Mude para a guia do navegador do grupo de failover do Banco de Dados SQL do Azure; por exemplo,
failovergroup-gzh032124. - Selecione Failover>Sim.
- Aguarde a conclusão.
Em seguida, execute as etapas a seguir para fazer failover do cluster do JBoss EAP com o plano de recuperação:
Na caixa de pesquisa na parte superior do portal do Azure, digite Recovery Services vault e selecione Recovery Services vault nos resultados da pesquisa.
Selecione o nome do cofre dos Serviços de Recuperação; por exemplo,
recovery-service-vault-westus-gzh032124.Em Gerenciar, selecione Planos de Recuperação (Site Recovery). Selecione o plano de recuperação que você criou; por exemplo,
recovery-plan-gzh032124.Selecione Failover. Selecione Eu entendo o risco. Ignorar teste de failover.. Mantenha os padrões nos outros valores. Selecione OK.
Observação
Como opção, você pode executar o Teste de failover e Limpar failover de teste para que tudo funcione conforme o esperado antes de testar o Failover. Para obter mais informações, consulte Tutorial: Executar um exercício de recuperação de desastres para VMs do Azure. Este tutorial usa o Failover diretamente para simplificar o exercício.
Monitore o failover pelas notificações até que ele seja concluído. O exercício deste tutorial leva cerca de 10 minutos.
Confirmar o failover
Verifique se as etapas da seção anterior foram concluídas com sucesso. Em seguida, use as seguintes etapas para confirmar o failover:
Na caixa de pesquisa no topo do portal do Azure, digite Cofres de serviços de recuperação e selecione-o nos resultados da pesquisa.
Selecione o cofre de Serviços de recuperação - por exemplo,
recovery-service-vault-westus-gzh032124.Na seção Gerenciar, selecione Planos de recuperação (Site Recovery).
Selecione o plano de recuperação; por exemplo,
recovery-plan-gzh032124.Selecione Confirmar e depois OK.
Monitore as notificações até que elas sejam concluídas.

Selecione Itens no plano de recuperação. Você deverá ver 3 itens listados como Failover confirmado.

Desabilitar a replicação
Execute as etapas a seguir para desabilitar a replicação de itens no plano de recuperação e excluir o plano de recuperação:
- Para cada item em Itens no plano de recuperação, clique com o botão direito no item e selecione Desabilitar replicação.
- Se você precisar fornecer um ou mais motivos para desabilitar a proteção para esta máquina virtual, selecione uma de sua preferência; por exemplo, Concluí a migração do meu aplicativo. Selecione OK.
- Repita a etapa 1 até desabilitar a replicação para todos os itens.
- Monitore o processo pelas notificações até que ele seja concluído.
- Selecione Visão geral>Excluir. Selecione Sim para confirmar a exclusão.
Proteger novamente o site de failover
Agora a região secundária é o site de failover e está ativa, portanto, você deve protegê-la novamente na região primária.
Primeiro, limpe os recursos no grupo de recursos denominado jboss-eap-cluster-eastus-gzh032124 que não são mais usados.
Na caixa de pesquisa na parte superior do portal do Azure, insira Grupos de Recursos e, em seguida, selecione Grupos de Recursos nos resultados da pesquisa.
Selecione o nome do grupo de recursos para sua região secundária recém-criada.
Ao lado da área de texto rotulada Filtro para qualquer campo..., selecione o X para remover todos os filtros.
Selecione Adicionar filtro. Defina Filtro como Tipo. Defina Operador como Igual a.
Selecione o menu suspenso ao lado do campo Valor.
Alterne a caixa de seleção Selecionar tudo até que nenhum valor esteja selecionado.
Verifique se todos os seguintes tipos estão selecionados:
- Máquina virtual
- Disco
- Ponto de extremidade privado
- Interface de rede
- Conta de armazenamento
Selecione o menu suspenso ao lado do campo Valor para fechar o menu suspenso. Você deve ver 5 tipos de recursos como o valor de Valor.
Escolha Aplicar.
Marque a caixa de seleção ao lado do rótulo Nome na parte superior da lista filtrada.
Selecione Excluir.
Insira excluir para confirmar a exclusão, selecione Excluir. Monitore o processo pelas notificações até que ele seja concluído.
Em seguida, use as mesmas etapas em Configurar a recuperação de desastre para o cluster usando o Azure Site Recovery na região primária, exceto pelas seguintes diferenças:
Para Criar um cofre dos Serviços de recuperação, siga estas etapas:
- Selecione o grupo de recursos implantado na região primária; por exemplo,
jboss-eap-cluster-eastus-gzh032124. - Insira um nome diferente para o 'service vault', por exemplo,
recovery-service-vault-eastus-gzh032124. - Selecione Leste dos EUA em Região.
- Selecione o grupo de recursos implantado na região primária; por exemplo,
Em Habilitar replicação, siga estas etapas:
Em Região, em Origem, selecione Oeste dos EUA 2.
Em Configurações de replicação, siga estas etapas:
Em Grupo de recursos de destino, selecione o grupo de recursos existente implantado na região primária; por exemplo,
jboss-eap-cluster-eastus-gzh032124.Em Rede virtual de failover, selecione a rede virtual existente na região primária.
Para Criar um plano de recuperação, para Origem, selecione Oeste dos EUA 2 e, para Destino, selecione Leste dos EUA.
Observação
Observe o Azure Site Recovery permite a nova proteção de VMs quando a VM de destino existe. Para obter mais informações, consulte a Proteger novamente a VM do Tutorial: Fazer failover de VMs do Azure para uma região secundária. Contudo, isso não funciona quando as únicas alterações entre o disco de origem e o disco de destino são sincronizadas para o cluster do JBoss EAP, com base no resultado da verificação. Este tutorial estabelece uma nova replicação do site secundário para o site primário após o failover, no qual todos os discos são copiados da região com failover para a região primária. Para obter mais informações, consulte a seção O que acontece durante a nova proteção? em Nova proteção de máquinas virtuais do Azure com failover para a região primária.
Fazer failback para o primário primário
Siga as mesmas etapas na seção Failover para o site secundário para fazer failback para o site primário, incluindo o servidor de banco de dados e o cluster, exceto pelas seguintes diferenças:
Selecione o cofre do serviço de recuperação implantado na região primária; por exemplo,
recovery-service-vault-eastus-gzh032124.Selecione o grupo de recursos implantado na região primária; por exemplo,
jboss-eap-cluster-eastus-gzh032124.Na seção Confirmar o failover, selecione o cofre dos Serviços de recuperação implantado na região primária - por exemplo,
recovery-service-vault-eastus-gzh032124.No perfil do Gerenciador de Tráfego, você verá que o ponto de extremidade
myPrimaryEndpointse torna Online e o ponto de extremidademyFailoverEndpointse torna Degradado.Na seção Proteger novamente o site de failover, use as seguintes etapas:
A região primária é o site de failover e está ativa, portanto, você deve protegê-la novamente na região secundária.
Limpe o recurso implantado em sua região secundária; por exemplo, recursos implantados no
jboss-eap-cluster-westus-gzh032124.Use as mesmas etapas na seção Configurar a recuperação de desastre para o cluster usando o Azure Site Recovery para proteger a região primária na região secundária, exceto pelas seguintes etapas:
Pule as etapas em Criar um cofre dos Serviços de recuperação porque você já criou um cofre dos Serviços de recuperação - por exemplo,
recovery-service-vault-westus-gzh032124.Em Habilitar replicação>Configurações de replicação>Rede virtual de failover, selecione a rede virtual existente na região secundária.
Limpar os recursos
Se você não for continuar usando os clusters do JBoss EAP e outros componentes, siga estas etapas para excluir os grupos de recursos para limpar os recursos usados neste tutorial:
Insira o nome do grupo de recursos dos servidores do banco de dados SQL do Azure (por exemplo,
sqlserver-rg-gzh032124) na caixa de pesquisa na parte superior do portal do Azure. Em seguida, selecione o grupo de recursos correspondente nos resultados da pesquisa.Selecione Excluir grupo de recursos.
Em Inserir nome do grupo de recursos para confirmar a exclusão, insira o nome do grupo de recursos.
Selecione Excluir.
Repita as etapas 1 a 4 para o grupo de recursos do Gerenciador de Tráfego; por exemplo,
myResourceGroupTM1.Na caixa de pesquisa na parte superior do portal do Azure, insira Cofres dos Serviços de Recuperação e selecione Cofres dos Serviços de Recuperação nos resultados da pesquisa.
Selecione o nome do cofre dos Serviços de Recuperação; por exemplo,
recovery-service-vault-westus-gzh032124.Em Gerenciar, selecione Planos de Recuperação (Site Recovery). Selecione o plano de recuperação que você criou; por exemplo,
recovery-plan-gzh032124.Use as mesmas etapas na seção Desabilitar a replicação para remover bloqueios em itens replicados.
Repita as etapas 1 a 4 para o grupo de recursos do cluster do JBoss EAP primário; por exemplo,
jboss-eap-cluster-westus-gzh032124.Repita as etapas 1 a 4 para o grupo de recursos do cluster do JBoss EAP secundário; por exemplo,
jboss-eap-cluster-eastus-gzh032124.
Próximas etapas
Neste tutorial, você configura uma solução HA/DR que consiste em uma camada de infraestrutura de aplicativo ativa-passiva com uma camada de banco de dados ativa-passiva em que as duas camadas abrangem dois sites geograficamente diferentes. No primeiro site, a camada de infraestrutura de aplicativo e a camada de banco de dados estão ativas. No segundo site, o domínio secundário é restaurado com o serviço Azure Site Recovery e o banco de dados secundário permanece em espera.
Continue a explorar as seguintes referências para ver outras opções para criar soluções de HA/DR e executar o JBoss EAP no Azure: