Aumentar modelos de linguagem grande com geração aumentada por recuperação ou ajuste fino
Em uma série de artigos, discutimos os mecanismos de recuperação de conhecimento que os LLMs (grandes modelos de linguagem) usam para gerar respostas. Por padrão, uma LLM tem acesso apenas aos seus dados de treinamento. Mas você pode aumentar o modelo para incluir dados em tempo real ou dados privados.
O primeiro mecanismo é a geração aumentada por recuperação (RAG). RAG é uma forma de pré-processamento que combina a pesquisa semântica com a preparação contextual. A ativação contextual é discutida em detalhes em Conceitos e considerações importantes para a criação de soluções geradoras de IA.
O segundo mecanismo é o ajuste fino. No ajuste fino, um LLM é treinado ainda mais em um conjunto de dados específico após o treinamento amplo inicial. A meta é adaptar o LLM para ter um desempenho melhor em tarefas ou entender os conceitos relacionados ao conjunto de dados. Esse processo ajuda o modelo a se especializar ou melhorar sua precisão e eficiência no tratamento de tipos específicos de entrada ou domínios.
As seções a seguir descrevem esses dois mecanismos com mais detalhes.
Noções básicas sobre o RAG
A RAG geralmente é usada para habilitar o cenário de "chat sobre meus dados". Nesse cenário, uma organização tem um corpus potencialmente grande de conteúdo textual, como documentos, documentação e outros dados proprietários. Ele usa esse corpus como base para respostas aos prompts do usuário.
De forma geral, você cria uma entrada de banco de dados para cada documento ou para uma parte de um documento chamada segmento. O segmento é indexado na incorporação, ou seja, um vetor (matriz) de números que representam facetas do documento. Quando um usuário envia uma consulta, você pesquisa documentos semelhantes no banco de dados e envia a consulta e os documentos para o LLM para compor uma resposta.
Observação
Usamos o termo geração aumentada por recuperação (RAG) de forma acomodativa. O processo de implementação de um sistema de chat baseado em RAG, conforme descrito neste artigo, pode ser aplicado tanto se você deseja usar os dados externos como apoio (RAG) quanto se for a peça central da resposta (RCG). A distinção sutil não é tratada na maioria das leituras relacionadas ao RAG.
Criando um índice de documentos vetorizados
A primeira etapa para criar um sistema de chat baseado em RAG é criar um repositório de dados de vetor que contenha a inserção de vetor do documento ou parte. Considere o diagrama a seguir, que descreve as etapas básicas para criar um índice vetorizado de documentos.

O diagrama representa um pipeline de dados. O pipeline é responsável pela ingestão, processamento e gerenciamento de dados que o sistema usa. O fluxo de trabalho inclui o pré-processamento de dados a serem armazenados no banco de dados vetorial e garantir que os dados alimentados no LLM estejam no formato correto.
Todo o processo é impulsionado pela noção de uma inserção, que é uma representação numérica de dados (normalmente palavras, frases, frases ou até documentos inteiros) que captura as propriedades semânticas da entrada de uma maneira que pode ser processada por modelos de machine learning.
Para criar uma inserção, envie a parte do conteúdo (frases, parágrafos ou documentos inteiros) para a API de Inserções OpenAI do Azure. A API retorna um vetor. Cada valor no vetor representa uma característica (dimensão) do conteúdo. As dimensões podem incluir matéria de tópico, significado semântico, sintaxe e gramática, uso de palavras e frases, relações contextuais, estilo ou tom. Juntos, todos os valores do vetor representam o espaço dimensional do conteúdo. Se você pensar em uma representação 3D de um vetor que tenha três valores, um vetor específico estará em uma área específica do plano do plano XYZ. E se você tiver 1.000 valores ou até mais? Embora não seja possível para os humanos desenhar um grafo de 1.000 dimensões em uma folha de papel para torná-lo mais compreensível, os computadores não têm problemas em entender esse grau de espaço dimensional.
A próxima etapa do diagrama mostra o armazenamento do vetor e do conteúdo (ou um ponteiro para o local do conteúdo) e outros metadados em um banco de dados vetor. Um banco de dados vetor é como qualquer tipo de banco de dados, mas com duas diferenças:
- Os bancos de dados vetoriais usam um vetor como índice para pesquisar dados.
- Os bancos de dados vetoriais implementam um algoritmo chamado pesquisa por similaridade de cosseno, também chamado de vizinho mais próximo. O algoritmo usa vetores que correspondem mais de perto aos critérios de pesquisa.
Com o corpus de documentos armazenados em um banco de dados vetor, os desenvolvedores podem criar um componente recuperador para recuperar documentos que correspondam à consulta do usuário. Os dados são usados para fornecer ao LLM o que ele precisa para responder à consulta do usuário.
Respondendo consultas usando seus documentos
Primeiro, um sistema RAG usa a pesquisa semântica para localizar artigos que podem ser úteis para a LLM quando ele compõe uma resposta. A próxima etapa é enviar os artigos correspondentes com o prompt original do usuário para a LLM para compor uma resposta.
Considere o diagrama a seguir como uma implementação simples de RAG (às vezes chamada RAG ingênuo ):
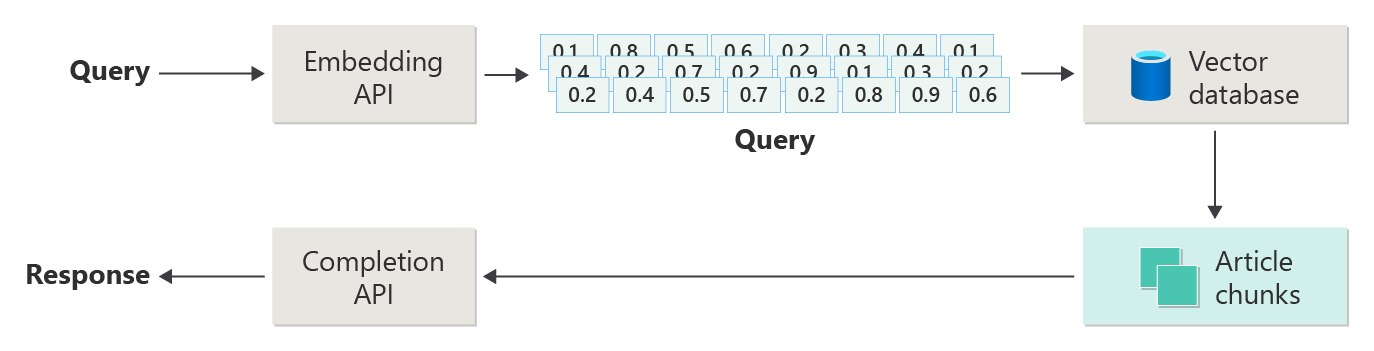
No diagrama, um usuário envia uma consulta. A primeira etapa é criar uma inserção para que o prompt do usuário retorne um vetor. A próxima etapa é pesquisar no banco de dados vetorial os documentos (ou partes de documentos) que são uma correspondência de vizinho mais próximo.
similaridade cossina é uma medida que ajuda a determinar o quão semelhantes são dois vetores. Basicamente, a métrica avalia o cosseno do ângulo entre eles. Uma semelhança do cosseno próxima de 1 indica um alto grau de similaridade (um ângulo pequeno). Uma similaridade próxima de -1 indica dissimilaridade (um ângulo de quase 180 graus). Essa métrica é crucial para tarefas como similaridade de documento, em que a meta é localizar documentos com conteúdo ou significado semelhantes.
Algoritmos do vizinho mais próximo funcionam encontrando os vetores mais próximos (vizinhos) para um ponto no espaço vetorial. No algoritmo de k vizinhos mais próximos (KNN), k refere-se ao número de vizinhos mais próximos a serem considerados. Essa abordagem é amplamente usada na classificação e regressão, em que o algoritmo prevê o rótulo de um novo ponto de dados com base no rótulo majoritário de seus k vizinhos mais próximos no conjunto de treinamento. KNN e similaridade de cosseno são frequentemente usados juntos em sistemas como mecanismos de recomendação, onde o objetivo é encontrar itens mais semelhantes às preferências de um usuário, representados como vetores no espaço de incorporação.
Você tira os melhores resultados dessa pesquisa e envia o conteúdo correspondente com o prompt do usuário para gerar uma resposta que (espero) é informada pela correspondência de conteúdo.
Desafios e considerações
Um sistema RAG tem seu conjunto de desafios de implementação. A privacidade de dados é fundamental. O sistema deve lidar com dados do usuário com responsabilidade, especialmente quando recupera e processa informações de fontes externas. Os requisitos computacionais também podem ser significativos. Tanto o processo de recuperação quanto os processos de geração são intensivos em recursos. Garantir a precisão e a relevância das respostas ao gerenciar preconceitos nos dados ou no modelo é outra consideração crítica. Os desenvolvedores devem enfrentar esses desafios com cuidado para criar sistemas RAG eficientes, éticos e valiosos.
Criar sistemas avançados de geração aumentada por recuperação fornece mais informações sobre a construção de pipelines de dados e inferência para implementar um sistema de RAG pronto para produção.
Se você quiser começar a experimentar a criação de uma solução de IA generativa imediatamente, recomendamos dar uma olhada em Introdução ao chat usando seu próprio exemplo de dados para Python. O tutorial também está disponível para .NET, Javae javaScript.
Ajustando um modelo
No contexto de um LLM, o ajuste fino é o processo de ajustar os parâmetros do modelo treinando-o em um conjunto de dados específico do domínio depois que o LLM foi inicialmente treinado em um conjunto de dados grande e diversificado.
Os LLMs são treinados (pré-treinados) em um amplo conjunto de dados, compreendendo a estrutura da linguagem, o contexto e uma ampla gama de conhecimentos. Este estágio envolve o aprendizado de padrões gerais de linguagem. O ajuste fino está adicionando mais treinamento ao modelo pré-treinado com base em um conjunto de dados menor e específico. Esta fase secundária de treinamento visa adaptar o modelo para um melhor desempenho em tarefas específicas ou entender domínios específicos, aumentando sua precisão e relevância para essas aplicações especializadas. Durante o ajuste fino, os pesos do modelo são ajustados para prever ou entender melhor as nuances desse conjunto de dados menor.
Algumas considerações:
- Especialização: o ajuste fino adapta o modelo a tarefas específicas, como análise de documentos jurídicos, interpretação de texto médico ou interações de atendimento ao cliente. Essa especialização torna o modelo mais eficaz nessas áreas.
- Eficiência: É mais eficiente ajustar um modelo pré-treinado para uma tarefa específica do que treinar um modelo do zero. O ajuste fino requer menos dados e menos recursos computacionais.
- Adaptabilidade : O ajuste fino permite a adaptação a novas tarefas ou domínios que não faziam parte dos dados de treinamento originais. A adaptabilidade de LLMs os torna ferramentas versáteis para vários aplicativos.
- Melhor Desempenho: Para tarefas diferentes dos dados nos quais o modelo foi originalmente treinado, o ajuste fino pode levar a um melhor desempenho. O ajuste fino ajusta o modelo para entender a linguagem, o estilo ou a terminologia específica que é usada no novo domínio.
- Personalização: em alguns aplicativos, o ajuste fino pode ajudar a personalizar as respostas ou previsões do modelo para atender às necessidades ou preferências específicas de um usuário ou organização. No entanto, o ajuste fino tem desvantagens e limitações específicas. Entender esses fatores pode ajudá-lo a decidir quando optar por ajuste fino versus alternativas como RAG.
- Requisito de dados: o ajuste fino requer um conjunto de dados suficientemente grande e de alta qualidade específico para a tarefa ou domínio de destino. Coletar e organizar esse conjunto de dados pode ser desafiador e consumir muitos recursos.
- Risco de sobreajuste: O sobreajuste é um risco, especialmente com uma base de dados pequena. O sobreajuste faz com que o modelo tenha bom desempenho nos dados de treinamento, mas apresente mau desempenho em dados novos e não vistos. A generalização é reduzida quando ocorre um sobreajuste.
- custo e recursos: embora seja menos intensivo em recursos do que treinar do zero, o fine-tuning ainda requer recursos computacionais, especialmente para modelos grandes e conjuntos de dados. O custo pode ser proibitivo para alguns usuários ou projetos.
- Manutenção e atualização: modelos afinados podem precisar de atualizações regulares para permanecerem eficazes à medida que as informações específicas do domínio forem alteradas ao longo do tempo. Essa manutenção contínua requer recursos e dados extras.
- Desvio do modelo: como o modelo é ajustado para tarefas específicas, ele pode perder parte do reconhecimento de linguagem e da versatilidade em geral. Esse fenômeno é chamado de desvio do modelo.
Personalize um modelo por meio de ajuste fino, que explica como ajustar um modelo. Em um alto nível, você fornece um conjunto de dados JSON de possíveis perguntas e respostas preferenciais. A documentação sugere que há melhorias perceptíveis ao fornecer de 50 a 100 pares de perguntas e respostas, mas o número certo varia muito no caso de uso.
Ajuste fino versus RAG
Na superfície, pode parecer que há um pouco de sobreposição entre ajuste fino e RAG. A escolha entre o ajuste fino e a geração aumentada por recuperação depende dos requisitos específicos da tarefa, incluindo expectativas de desempenho, disponibilidade de recursos e a necessidade de especificidade de domínio versus generalização.
Quando usar o ajuste fino em vez de RAG:
- Desempenho específico da tarefa: o ajuste fino é a escolha preferida quando é crítico alcançar alto desempenho em uma tarefa específica, e há dados suficientes do domínio para treinar o modelo de forma eficaz, sem riscos significativos de sobreajuste.
- Controle sobrede dados: se você tiver dados proprietários ou altamente especializados que diferem significativamente dos dados nos quais o modelo base foi treinado, o ajuste fino permite incorporar esse conhecimento exclusivo ao modelo.
- Necessidade limitada de atualizações em tempo real: se a tarefa não exigir que o modelo seja constantemente atualizado com as informações mais recentes, o ajuste fino poderá ser mais eficiente, pois os modelos de RAG normalmente precisam de acesso a bancos de dados externos atualizados ou da Internet para extrair dados recentes.
Quando preferir RAG em vez de ajuste fino:
- conteúdo dinâmico ou conteúdo em evolução: o RAG é mais adequado para tarefas em que ter as informações mais atuais é essencial. Como os modelos RAG podem extrair dados de fontes externas em tempo real, eles são mais adequados para aplicativos como geração de notícias ou responder a perguntas sobre eventos recentes.
- Generalização sobre especialização: se o objetivo for manter um desempenho forte em diversos tópicos em vez de se destacar em um domínio estreito, a RAG poderá ser preferível. Ele usa bases de conhecimento externas, permitindo gerar respostas em diversos domínios sem o risco de sobreajuste a um conjunto de dados específico.
- Restrições de recurso: para organizações com recursos limitados para coleta de dados e treinamento de modelo, usar uma abordagem RAG pode oferecer uma alternativa econômica ao ajuste fino, especialmente se o modelo base já tiver um desempenho razoável nas tarefas desejadas.
Considerações finais para o design do aplicativo
Aqui está uma pequena lista de coisas a serem consideradas e outras conclusões deste artigo que podem influenciar suas decisões de design de aplicativo:
- Decida entre ajuste fino e RAG com base nas necessidades específicas do aplicativo. O ajuste fino pode oferecer melhor desempenho para tarefas especializadas, enquanto a RAG pode fornecer flexibilidade e conteúdo atualizado para aplicativos dinâmicos.