Criar sistemas avançados de geração de recuperação aumentada
Este artigo explora a geração aumentada por recuperação (RAG) de forma aprofundada. Descrevemos o trabalho e as considerações necessárias para que os desenvolvedores criem uma solução RAG pronta para produção.
Para saber mais sobre duas opções para criar um aplicativo de "chat sobre seus dados", um dos principais casos de uso para IA gerativa em empresas, consulte Aumentar LLMs com RAG ou ajuste fino.
O diagrama a seguir ilustra as etapas ou fases do RAG:
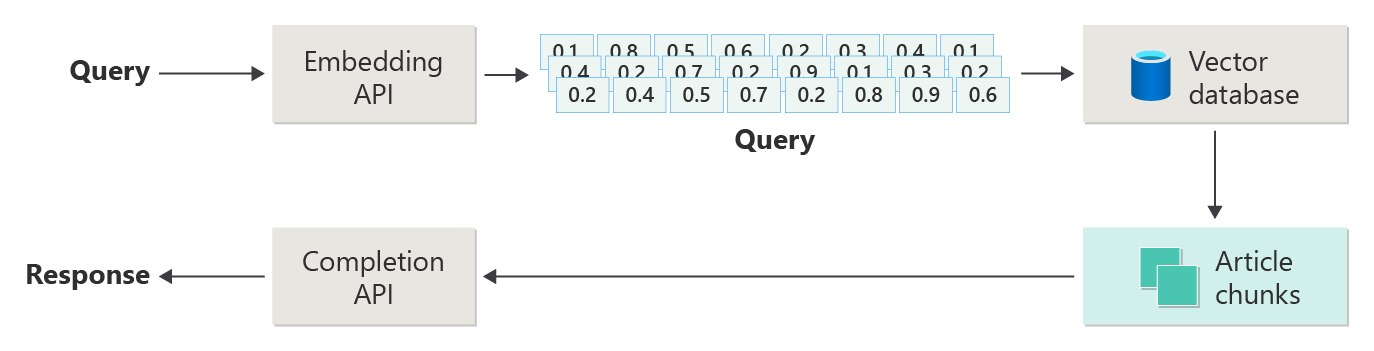
Esta representação é chamada RAG ingênuo. É uma maneira útil de entender inicialmente os mecanismos, funções e responsabilidades necessários para implementar um sistema de chat baseado em RAG.
Mas uma implementação do mundo real tem muito mais etapas de pré-processamento e pós-processamento para preparar os artigos, consultas e respostas para uso. O diagrama a seguir é uma representação mais realista de um RAG, às vezes chamado RAG avançado :

Este artigo fornece uma estrutura conceitual para entender as fases de pré-processamento e pós-processamento em um sistema de chat baseado em RAG do mundo real:
- Fase de ingestão
- Fase do pipeline de inferência
- Fase de avaliação
Ingestão
A ingestão consiste principalmente em armazenar os documentos da sua organização para que possam ser facilmente recuperados para responder à pergunta de um usuário. O desafio é garantir que as partes dos documentos que melhor correspondem à consulta do usuário estejam localizadas e usadas durante a inferência. A correspondência é realizada principalmente por meio de incorporações vetorizadas e uma pesquisa de similaridade de cosseno. No entanto, a correspondência é facilitada pela compreensão da natureza do conteúdo (por exemplo, padrões e formas) e pela estratégia de organização dos dados (a estrutura dos dados quando são armazenados no banco de dados vetorial).
Para a ingestão, os desenvolvedores precisam considerar as seguintes etapas:
- Pré-processamento e extração de conteúdo
- Estratégia de agrupamento
- Organização em partes
- Estratégia de atualização
Pré-processamento e extração de conteúdo
Conteúdo limpo e preciso é uma das melhores maneiras de melhorar a qualidade geral de um sistema de bate-papo baseado em RAG. Para obter conteúdo limpo e preciso, comece analisando a forma e a forma dos documentos a serem indexados. Os documentos estão em conformidade com padrões de conteúdo especificados, como documentação? Se não, que tipos de perguntas os documentos podem responder?
No mínimo, crie etapas no pipeline de ingestão para:
- Padronizar formatos de texto
- Lidar com caracteres especiais
- Remover conteúdo não relacionado e desatualizado
- Conta para conteúdo versionado
- Considere a experiência de conteúdo (guias, imagens, tabelas)
- Extrair metadados
Algumas dessas informações (como metadados, por exemplo) podem ser úteis se forem mantidas com o documento no banco de dados vetorial para ser usado durante o processo de recuperação e avaliação no pipeline de inferência. Ele também pode ser combinado com o trecho de texto para influenciar a incorporação vetorial do trecho.
Estratégia de agrupamento
Como desenvolvedor, você deve decidir como dividir um documento maior em partes menores. O agrupamento pode melhorar a relevância do conteúdo suplementar enviado para a LLM, a fim de responder de forma precisa às consultas do usuário. Considere também como usar os trechos após a recuperação. Os designers de sistema devem pesquisar técnicas comuns do setor e fazer algumas experimentações. Você pode até mesmo testar sua estratégia em uma capacidade limitada em sua organização.
Os desenvolvedores devem considerar:
- Otimização do tamanho dos blocos: Determine o tamanho ideal do bloco e como designar um bloco. Por seção? Por parágrafo? Por frase?
- Pedaços sobrepostos e janelas deslizantes: Determinar se o conteúdo deve ser dividido em pedaços discretos ou se os pedaços se sobrepõem? Você pode até mesmo fazer as duas coisas, em um design de janela deslizante.
- Small2Big: Quando o agrupamento é feito em um nível granular, como uma única frase, o conteúdo está organizado de forma que seja fácil encontrar as frases vizinhas ou o parágrafo que contém a frase? Recuperar essas informações e fornecê-las à LLM pode fornecer mais contexto para responder às consultas do usuário. Para obter mais informações, consulte a próxima seção.
Organização em partes
Em um sistema RAG, organizar estrategicamente seus dados no banco de dados vetor é uma chave para a recuperação eficiente de informações relevantes para aumentar o processo de geração. Aqui estão os tipos de estratégias de indexação e recuperação que você pode considerar:
- índices hierárquicos: essa abordagem envolve a criação de várias camadas de índices. Um índice de nível superior (um índice de resumo) restringe rapidamente o espaço de pesquisa a um subconjunto de partes potencialmente relevantes. Um índice de segundo nível (um índice de partes) fornece ponteiros mais detalhados para os dados reais. Esse método pode acelerar significativamente o processo de recuperação porque reduz o número de entradas a serem digitalizadas no índice detalhado filtrando primeiro pelo índice de resumo.
- índices especializados: dependendo da natureza dos dados e das relações entre partes, você pode usar índices especializados, como bancos de dados relacionais ou baseados em grafo:
- Os índices baseados em grafos são úteis quando os chunks têm informações ou relacionamentos interconectados que podem aprimorar a recuperação, como redes de citação ou gráficos de conhecimento.
- bancos de dados relacionais poderão ser eficazes se as partes forem estruturadas em um formato tabular. Use consultas SQL para filtrar e recuperar dados com base em atributos ou relações específicos.
- índices híbridos: uma abordagem híbrida combina vários métodos de indexação para aplicar seus pontos fortes à sua estratégia geral. Por exemplo, você pode usar um índice hierárquico para filtragem inicial e um índice baseado em grafo para explorar dinamicamente as relações entre partes durante a recuperação.
Otimização de alinhamento
Para aprimorar a relevância e a precisão das partes recuperadas, alinhe-as de perto com os tipos de pergunta ou consulta que respondem. Uma estratégia é gerar e inserir uma pergunta hipotética para cada trecho, representando a pergunta que ele é mais adequado para responder. Isso ajuda de várias maneiras:
- Correspondência aprimorada: durante a recuperação, o sistema pode comparar a consulta de entrada com essas perguntas hipotéticas para encontrar a correspondência ideal, melhorando a relevância dos segmentos recuperados.
- Dados de treinamento para modelos de machine learning: esses pares de perguntas e partes podem ser dados de treinamento para melhorar os modelos de machine learning que são os componentes subjacentes do sistema RAG. O sistema RAG aprende quais tipos de perguntas são melhor respondidas por cada trecho.
- tratamento de consulta direta: se uma consulta de usuário real corresponder de perto a uma pergunta hipotética, o sistema poderá recuperar e usar rapidamente a parte correspondente e acelerar o tempo de resposta.
A pergunta hipotética de cada segmento age como um rótulo que orienta o algoritmo de recuperação, tornando-o mais focado e ciente do contexto. Esse tipo de otimização é útil quando as partes abrangem uma ampla gama de tópicos ou tipos de informações.
Estratégias de atualização
Se sua organização indexa documentos que são atualizados com frequência, é essencial manter um corpus atualizado para garantir que o componente do recuperador possa acessar as informações mais atuais. O componente recuperador é a lógica no sistema que executa a consulta no banco de dados vetorial e, em seguida, retorna os resultados. Aqui estão algumas estratégias para atualizar o banco de dados vetor nestes tipos de sistemas:
Atualizações incrementais
- Intervalos regulares: agendar atualizações em intervalos regulares (por exemplo, diários ou semanais), dependendo da frequência das alterações nos documentos. Esse método garante que o banco de dados seja atualizado periodicamente em um agendamento conhecido.
- Atualizações baseadas em gatilho: implemente um sistema no qual uma atualização dispara a reindexação. Por exemplo, qualquer modificação ou adição de um documento inicia automaticamente a reindexação nas seções afetadas.
atualizações parciais:
- Reindexação seletiva: Em vez de reindexar um banco de dados inteiro, atualize apenas as partes alteradas do corpus. Essa abordagem pode ser mais eficiente do que a reindexação completa, especialmente para grandes conjuntos de dados.
- Codificação delta: armazene apenas as diferenças entre os documentos existentes e suas versões atualizadas. Essa abordagem reduz a carga de processamento de dados, evitando a necessidade de processar dados inalterados.
Controle de versão.
- Instantâneo: mantenha as versões do corpus de documentos em diferentes momentos. Essa técnica fornece um mecanismo de backup e permite que o sistema reverta ou se refira a versões anteriores.
- Controle de versão do documento: use um sistema de controle de versão para rastrear sistematicamente as alterações do documento para manter o histórico de alterações e simplificar o processo de atualização.
Atualizações em tempo real
- Processamento em fluxo contínuo: Quando a pontualidade das informações for crítica, use tecnologias de processamento em fluxo contínuo para atualizações em tempo real do banco de dados vetorial, à medida que as alterações são feitas no documento.
- Consulta em tempo real: em vez de depender apenas de vetores pré-indexados, use uma abordagem de consulta de dados em tempo real para respostas atualizadas up-to, possivelmente combinando dados em tempo real com resultados armazenados em cache para eficiência.
técnicas de otimização :
Processamento em lote: O processamento em lote acumula alterações para aplicá-las com menos frequência, otimizando os recursos e reduzindo a sobrecarga.
abordagens híbridas: combine várias estratégias:
- Use atualizações incrementais para pequenas alterações.
- Use reindexação total para atualizações importantes.
- Documente as alterações estruturais feitas no corpus.
Escolher a estratégia de atualização correta ou a combinação certa depende de requisitos específicos, incluindo:
- Tamanho do corpus do documento
- Frequência de atualização
- Necessidades de dados em tempo real
- Disponibilidade de recursos
Avalie esses fatores com base nas necessidades do aplicativo específico. Cada abordagem tem compensações em complexidade, custo e latência de atualização.
Pipeline de inferência
Seus artigos são fragmentados, vetorizados e armazenados em um banco de dados vetorial. Agora, concentre-se em resolver os desafios de conclusão.
Para obter as conclusões mais precisas e eficientes, você deve considerar muitos fatores:
- A consulta do usuário é escrita de forma a obter os resultados que o usuário está procurando?
- A consulta do usuário viola alguma das políticas da organização?
- Como você reescreve a consulta do usuário para melhorar as chances de encontrar as correspondências mais próximas no banco de dados vetor?
- Como avaliar os resultados da consulta para garantir que as partes do artigo se alinhem à consulta?
- Como avaliar e modificar os resultados da consulta antes de passá-los para o LLM para garantir que os detalhes mais relevantes sejam incluídos na conclusão?
- Como você avalia a resposta do LLM para garantir que a conclusão do LLM responda à consulta original do usuário?
- Como você garante que a resposta do LLM esteja em conformidade com as políticas da organização?
Todo o pipeline de inferência é executado em tempo real. Não há uma maneira correta de projetar suas etapas de pré-processamento e pós-processamento. Você provavelmente escolherá uma combinação de lógica de programação e outras chamadas LLM. Uma das considerações mais importantes é a troca entre a criação do pipeline mais preciso e compatível possível e o custo e a latência necessários para fazer isso acontecer.
Vamos identificar estratégias específicas em cada estágio do pipeline de inferência.
Etapas de pré-processamento de consulta
O pré-processamento de consulta ocorre imediatamente após o usuário enviar sua consulta:

O objetivo dessas etapas é garantir que o usuário faça perguntas que estejam dentro do escopo do seu sistema e preparar a consulta do usuário para aumentar a probabilidade de localizar as melhores partes de artigo possíveis usando a similaridade cossina ou a pesquisa "vizinho mais próximo".
Verificação de política: esta etapa envolve a lógica que identifica, remove, sinaliza ou rejeita determinado conteúdo. Alguns exemplos incluem a remoção de dados pessoais, a remoção de expletivos e a identificação de tentativas de "jailbreak". jailbreaking refere-se a tentativas do usuário de contornar ou manipular as diretrizes internas de segurança, ética ou operacional do modelo.
Reformulação de consultas: esta etapa pode envolver desde a expansão de acrônimos e remoção de gírias até a reformulação da pergunta de forma mais abstrata para extrair conceitos e princípios de alto nível (solicitação de retorno).
Uma variação na solicitação de retorno é HyDE (Hipotéticos de Inserções de Documentos). O HyDE usa o LLM para responder à pergunta do usuário, cria uma inserção para essa resposta (a inserção hipotética de documentos) e usa a inserção para executar uma pesquisa no banco de dados vetor.
Subconsultas
A etapa de processamento de subconsultas baseia-se na consulta original. Se a consulta original for longa e complexa, poderá ser útil dividi-la programaticamente em várias consultas menores e combinar todas as respostas.
Por exemplo, uma pergunta sobre descobertas científicas em física pode ser: "Quem fez contribuições mais significativas para a física moderna, Albert Einstein ou Niels Bohr?"
Dividir consultas complexas em subconsultas as torna mais gerenciáveis:
- Subconsulta 1: "Quais são as principais contribuições de Albert Einstein para a física moderna?"
- Subconsulta 2: "Quais são as principais contribuições de Niels Bohr para a física moderna?"
Os resultados dessas subconsultas detalham as principais teorias e descobertas de cada físico. Por exemplo:
- Para Einstein, as contribuições podem incluir a teoria da relatividade, o efeito fotoelétrico e E=mc^2.
- Para Bohr, as contribuições podem incluir o modelo de Bohr do átomo de hidrogênio, o trabalho de Bohr sobre mecânica quântica e o princípio da complementaridade de Bohr.
Quando essas contribuições são descritas, elas podem ser avaliadas para determinar mais subconsultas. Por exemplo:
- Subconsulta 3: "Como as teorias de Einstein afetaram o desenvolvimento da física moderna?"
- Subconsulta 4: "Como as teorias de Bohr afetaram o desenvolvimento da física moderna?"
Essas subconsultas exploram a influência de cada cientista na física, como:
- Como as teorias de Einstein levaram a avanços na cosmologia e na teoria quântica
- Como o trabalho de Bohr contribuiu para entender a estrutura atômica e a mecânica quântica
Combinar os resultados dessas subconsultas pode ajudar o modelo de linguagem a formar uma resposta mais abrangente sobre quem fez contribuições mais significativas para a física moderna com base em seus avanços teóricos. Esse método simplifica a consulta complexa original acessando componentes mais específicos e respondíveis e, em seguida, sintetizando essas descobertas em uma resposta coerente.
Roteador de consulta
Sua organização pode optar por dividir seu corpus de conteúdo em vários repositórios de vetores ou em sistemas de recuperação inteiros. Nesse cenário, você pode usar um roteador de consulta. Um roteador de consulta seleciona o banco de dados ou índice mais apropriado para fornecer as melhores respostas para uma consulta específica.
Um roteador de consulta normalmente funciona em um ponto depois que o usuário formula a consulta, mas antes de enviar a consulta para sistemas de recuperação.
Aqui está um fluxo de trabalho simplificado para um roteador de consulta:
- Análise de consulta: o LLM ou outro componente analisa a consulta de entrada para entender seu conteúdo, contexto e o tipo de informação que provavelmente é necessário.
- Seleção de índice: com base na análise, o roteador de consulta seleciona um ou mais índices de vários índices disponíveis. Cada índice pode ser otimizado para diferentes tipos de dados ou consultas. Por exemplo, alguns índices podem ser mais adequados para consultas factuais. Outros índices podem se destacar em fornecer opiniões ou conteúdo subjetivo.
- Despacho de consulta: a consulta é enviada para o índice selecionado.
- Agregação de resultados: As respostas dos índices selecionados são obtidas e possivelmente agregadas ou processadas para formar uma resposta abrangente.
- geração de respostas: a etapa final envolve a geração de uma resposta coerente com base nas informações recuperadas, possivelmente integrando ou sintetizando conteúdo de várias fontes.
Sua organização pode usar vários mecanismos de recuperação ou índices para os seguintes casos de uso:
- de especialização de tipo de dados: alguns índices podem ser especializados em artigos de notícias, outros em artigos acadêmicos e outros em conteúdo geral da Web ou bancos de dados específicos, como para informações médicas ou legais.
- Otimização do tipo de consulta: Certos índices podem ser otimizados para consultas factuais rápidas (por exemplo, datas ou eventos). Outros podem ser melhores para usar para tarefas de raciocínio complexas ou para consultas que exigem um conhecimento profundo do domínio.
- diferenças algorítmicas: algoritmos de recuperação diferentes podem ser usados em mecanismos diferentes, como pesquisas de similaridade baseadas em vetor, pesquisas tradicionais baseadas em palavra-chave ou modelos de compreensão semântica mais avançados.
Imagine um sistema baseado em RAG que é usado em um contexto de consultoria médica. O sistema tem acesso a vários índices:
- Um índice de pesquisa médica otimizado para explicações detalhadas e técnicas
- Um índice de estudo de caso clínico que fornece exemplos reais de sintomas e tratamentos
- Um índice geral de informações de saúde para consultas básicas e informações de saúde pública.
Se um usuário fizer uma pergunta técnica sobre os efeitos bioquímicos de um novo medicamento, o roteador de consulta poderá priorizar o índice de artigos de pesquisa médica devido à sua profundidade e foco técnico. Para uma pergunta sobre sintomas típicos de uma doença comum, no entanto, o índice geral de saúde pode ser escolhido por seu conteúdo amplo e facilmente compreensível.
Etapas de processamento pós-recuperação
O processamento pós-recuperação ocorre depois que o componente retriever recupera partes de conteúdo relevantes do banco de dados vetor:

Com as partes de conteúdo do candidato recuperadas, a próxima etapa é validar a utilidade da parte do artigo ao aumentar o prompt LLM antes de preparar o prompt a ser apresentado à LLM.
Aqui estão alguns aspectos a serem considerados:
- Incluir muitas informações suplementares pode resultar em ignorar as informações mais importantes.
- Incluir informações irrelevantes pode influenciar negativamente a resposta.
Outra consideração é a agulha em um problema de de palheiro, termo que se refere a uma peculiaridade conhecida de algumas LLMs em que o conteúdo no início e no final de um prompt tem maior peso para a LLM do que o conteúdo no meio.
Por fim, considere o comprimento máximo da janela de contexto do LLM e o número de tokens necessários para completar prompts extraordinariamente longos (especialmente para consultas em grande escala).
Para lidar com esses problemas, um pipeline de processamento pós-recuperação pode incluir as seguintes etapas:
- Os resultados da filtragem: nesta etapa, verifique se as partes do artigo retornadas pelo banco de dados vetor são relevantes para a consulta. Se não estiverem, o resultado é ignorado quando o prompt LLM é composto.
- Reclassificação: ordene as partes do artigo recuperadas do armazenamento vetorial para garantir que os detalhes relevantes estejam próximos às bordas (o início e o fim) do prompt.
- Compressão de prompt: use um modelo menor e econômico para compactar e resumir vários trechos de artigo em um único prompt compactado antes de enviar o prompt para a LLM.
Etapas de processamento pós-conclusão
O processamento pós-conclusão ocorre depois que a consulta do usuário e todas as partes de conteúdo são enviadas para a LLM:

A validação de precisão ocorre após a conclusão do prompt da LLM. Um pipeline de processamento pós-conclusão pode incluir as seguintes etapas:
- Verificação de fatos: a intenção é identificar declarações específicas feitas no artigo que são apresentadas como fatos e, em seguida, verificar esses fatos quanto à precisão. Se a etapa de verificação de fatos falhar, talvez seja apropriado reconsultar o LLM esperando obter uma resposta melhor ou enviar uma mensagem de erro ao usuário.
- Verificação de política: a última linha de defesa para garantir que as respostas não contenham conteúdo prejudicial, seja para o usuário ou para a organização.
Avaliação
Avaliar os resultados de um sistema não determinístico não é tão simples quanto executar os testes de unidade ou testes de integração com os quais a maioria dos desenvolvedores está familiarizada. Você precisa considerar vários fatores:
- Os usuários estão satisfeitos com os resultados que estão obtendo?
- Os usuários estão obtendo respostas precisas às suas perguntas?
- Como capturar comentários do usuário? Você tem alguma política em vigor que limite quais dados você pode coletar sobre os dados do usuário?
- Para o diagnóstico de respostas insatisfatórias, você tem visibilidade de todo o trabalho que foi feito para responder à pergunta? Você mantém um log de cada estágio no pipeline de inferência de entradas e saídas para que possa executar a análise de causa raiz?
- Como você pode fazer alterações no sistema sem regressão ou degradação de resultados?
Capturando e agindo de acordo com o feedback dos usuários
Conforme descrito anteriormente, talvez seja necessário trabalhar com a equipe de privacidade da sua organização para criar mecanismos de captura de feedback, telemetria e log para análise forense e de causa raiz de uma sessão de consulta.
O próximo passo é desenvolver um pipeline de avaliação. Um pipeline de avaliação ajuda a lidar com a complexidade e a demanda intensiva de tempo na análise de comentários literais e nas causas fundamentais das respostas fornecidas por um sistema de IA. Essa análise é crucial porque envolve investigar todas as respostas para entender como a consulta de IA produziu os resultados, verificar a adequação das partes de conteúdo usadas na documentação e as estratégias empregadas na divisão desses documentos.
Ele também envolve considerar quaisquer etapas adicionais de pré-processamento ou pós-processamento que possam aprimorar os resultados. Esse exame detalhado geralmente descobre lacunas de conteúdo, especialmente quando não há documentação adequada para resposta à consulta de um usuário.
A criação de um pipeline de avaliação torna-se essencial para gerenciar a escala dessas tarefas efetivamente. Um pipeline eficiente usa ferramentas personalizadas para avaliar métricas que se aproximam da qualidade das respostas fornecidas pela IA. Esse sistema simplifica o processo de determinar por que uma resposta específica foi dada à pergunta de um usuário, quais documentos foram usados para gerar essa resposta e a eficácia do pipeline de inferência que processa as consultas.
Conjunto de dados dourado
Uma estratégia para avaliar os resultados de um sistema não determinístico como um sistema de chat RAG é usar um conjunto de dados dourado. Um conjunto de dados de qualidade é um conjunto de perguntas e respostas aprovadas, metadados (como tópico e tipo de pergunta), referências a documentos de origem que podem servir de verdade básica para respostas e até variações (frases diferentes para capturar a diversidade de como os usuários podem fazer as mesmas perguntas).
Um conjunto de dados dourado representa o "melhor cenário de caso". Os desenvolvedores podem avaliar o sistema para ver o desempenho dele e, em seguida, fazer testes de regressão quando implementam novos recursos ou atualizações.
Avaliação dos danos
A modelagem de danos é uma metodologia que visa prever danos potenciais, detectar deficiências em um produto que possam representar riscos para os indivíduos e desenvolver estratégias proativas para mitigar esses riscos.
Uma ferramenta projetada para avaliar o impacto da tecnologia, particularmente os sistemas de IA, contaria com vários componentes-chave com base nos princípios da modelagem de danos, conforme descrito nos recursos fornecidos.
Os principais recursos de uma ferramenta de avaliação de danos podem incluir:
identificação de partes interessadas: a ferramenta pode ajudar os usuários a identificar e categorizar vários stakeholders afetados pela tecnologia, incluindo usuários diretos, partes indiretamente afetadas e outras entidades, como gerações futuras ou fatores não humanos, como preocupações ambientais.
categorias e descrições de danos: a ferramenta pode incluir uma lista abrangente de possíveis danos, como perda de privacidade, sofrimento emocional ou exploração econômica. A ferramenta pode orientar o usuário em vários cenários, ilustrar como a tecnologia pode causar esses danos e ajudar a avaliar as consequências intencionais e não intencionais.
avaliações de gravidade e probabilidade: a ferramenta pode ajudar os usuários a avaliar a gravidade e a probabilidade de cada dano identificado. O usuário pode priorizar os problemas a serem resolvidos primeiro. Os exemplos incluem avaliações qualitativas apoiadas por dados, quando disponíveis.
estratégias de mitigação: a ferramenta pode sugerir possíveis estratégias de mitigação depois de identificar e avaliar os danos. Os exemplos incluem alterações no design do sistema, adição de proteções e soluções tecnológicas alternativas que minimizam os riscos identificados.
Mecanismos de comentários: a ferramenta deve incorporar mecanismos para coletar comentários dos stakeholders para que o processo de avaliação de danos seja dinâmico e responsivo a novas informações e perspectivas.
Documentação e relatório: para transparência e responsabilidade, a ferramenta pode facilitar relatórios detalhados que documentam o processo de avaliação de danos, descobertas e possíveis ações de mitigação de risco tomadas.
Esses recursos podem ajudá-lo a identificar e reduzir riscos, mas também ajudam você a criar sistemas de IA mais éticos e responsáveis, considerando um amplo espectro de impactos desde o início.
Para obter mais informações, consulte estes artigos:
Testar e verificar as salvaguardas
Este artigo descreve vários processos que visam atenuar a possibilidade de um sistema de chat baseado em RAG ser explorado ou comprometido. Red-teaming desempenha um papel crucial na garantia de que as mitigações sejam eficazes. A prática de Red-teaming envolve simular as ações de um potencial adversário para identificar fraquezas ou vulnerabilidades no aplicativo. Essa abordagem é especialmente vital para lidar com o risco significativo de jailbreak.
Os desenvolvedores precisam avaliar rigorosamente as proteções do sistema de bate-papo baseado em RAG em vários cenários de diretrizes para testá-las e verificá-las com eficácia. Essa abordagem não apenas garante a robustez, mas também ajuda você a ajustar as respostas do sistema para seguir estritamente os padrões éticos e os procedimentos operacionais definidos.
Considerações finais para o design do aplicativo
Aqui está uma pequena lista de coisas a serem consideradas e outras conclusões deste artigo que podem afetar suas decisões de design de aplicativo:
- Reconheça a natureza não determinística da IA generativa em seu design. Planeje a variabilidade nas saídas e configure mecanismos para garantir a consistência e a relevância nas respostas.
- Avalie os benefícios do pré-processamento de prompts do usuário em relação ao possível aumento na latência e nos custos. Simplificar ou modificar prompts antes do envio pode melhorar a qualidade da resposta, mas pode adicionar complexidade e tempo ao ciclo de resposta.
- Para melhorar o desempenho, investigue estratégias para paralelizar solicitações LLM. Essa abordagem pode reduzir a latência, mas requer um gerenciamento cuidadoso para evitar maior complexidade e possíveis implicações de custo.
Se você quiser começar a experimentar a criação de uma solução de IA gerativa imediatamente, recomendamos que você dê uma olhada em Introdução ao chat usando sua própria amostra de dados para Python. O tutorial também está disponível para .NET, Javae javaScript.